人工智能基础知识笔记十四:文本转换成向量
1、简介
在机器学习中,将文字转换为向量(即文本向量化)是处理自然语言数据的关键步骤,因为机器学习模型(如神经网络、SVM等)只能处理数值型输入,无法直接处理原始文本。
将文本转成向量的主要作用如下:
模型输入要求
机器学习模型基于数学运算(如矩阵乘法、梯度下降),需要数值输入,文本必须转换为向量才能被处理。保留语义信息
好的向量表示能捕捉单词、句子或文档的语义(如相似性、上下文关系),例如“猫”和“狗”的向量距离应比“猫”和“汽车”更近。降维与稀疏性处理
原始文本(如One-Hot编码)会生成高维稀疏向量,向量化方法可以压缩维度并提升计算效率。迁移学习与泛化
预训练的词向量(如Word2Vec)能共享语言知识,提升模型在小数据集上的表现。
2、文本向量化的主要方法
2.1、基于词频/统计的方法
2.1.1、Bag-of-Words (BoW)
方法:统计每个词在文档中的出现频率,忽略顺序。
优点:简单、计算快。
缺点:丢失上下文和词序;高维稀疏;无法处理语义。
场景:文本分类初探、简单基线模型。
2.1.2、TF-IDF (Term Frequency-Inverse Document Frequency)
原理:加权词频,降低常见词的权重。
公式:
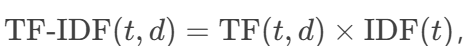

优点:抑制高频无意义词(如“的”“是”)。
缺点:仍无法捕捉语义。
场景:搜索引擎排名、关键词提取。
2.2、基于词嵌入(Word Embedding)
2.2.1、Word2Vec
原理:通过预测上下文学习词向量。
Skip-gram:用中心词预测周围词。
CBOW:用周围词预测中心词。
公式(Skip-gram目标函数):
![]()
优点:捕捉语义类比关系;低维稠密(通常50-300维)。
缺点:无法处理多义词;未登录词需重新训练。
场景:词相似度计算、推荐系统。
2.2.2、GloVe (Global Vectors)
原理:基于全局词共现矩阵的统计信息。
公式:

优点:结合全局统计,比Word2Vec更稳定。
缺点:仍无法解决多义词。
场景:大规模语料的通用任务。
2.3、基于上下文的动态嵌入
2.3.1、ELMo (Embeddings from Language Models)
原理:双向LSTM生成上下文相关的词向量。
公式:

优点:解决多义词问题;捕捉复杂语法。
缺点:计算复杂度高;需预训练。
场景:问答系统、语义角色标注。
2.2.2、BERT (Bidirectional Encoder Representations from Transformers)
原理:基于Transformer的掩码语言模型(MLM)和下一句预测(NSP)。
公式(MLM损失):

优点:最先进的语义表示;支持多种任务。
缺点:资源消耗大;需微调。
场景:机器翻译、情感分析。
2.4、其他方法
2.4.1、FastText
原理:将词拆分为子词(n-gram)学习向量。
公式:
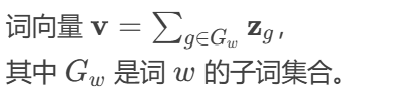
优点:解决未登录词问题;适合形态丰富的语言。
缺点:向量维度较高。
场景:社交媒体文本(含拼写错误)。
2.4.2、Doc2Vec
原理:扩展Word2Vec,直接生成文档向量。
公式(PV-DM模型):
文档向量 d与词向量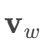 拼接后预测上下文。
拼接后预测上下文。优点:保留文档整体语义。
缺点:长文档效果可能下降。
场景:文档聚类、新闻分类。
3、总结
| 方法 | 原理 | 优点 | 缺点 | 适用场景 |
| BoW | 词频统计 | 简单快速 | 忽略语义和词序 | 基线文本分类 |
| TF-IDF | 加权词频 | 降低高频词权重 | 无语义信息 | 信息检索 |
| Word2Vec | 预测上下文 | 语义类比关系 | 多义词问题 | 词相似度计算 |
| GloVe | 全局共现矩阵分解 | 统计稳定性 | 需大语料 | 通用语义任务 |
| BERT | Transformer双向编码 | 上下文相关;SOTA性能 | 计算资源大 | 复杂NLP任务(如NER) |
| FastText | 子词向量求和 | 处理未登录词 | 维度较高 | 形态丰富语言(如德语) |
传统方法(BoW/TF-IDF):适合轻量级任务,无需语义理解。
词嵌入(Word2Vec/GloVe):平衡效率与语义,推荐中等复杂度任务。
动态嵌入(BERT/ELMo):资源充足时优先选择,尤其适合多义词和深层语义任务。
特殊需求:处理未登录词用FastText,长文档用Doc2Vec或BERT的[CLS]向量。