聚集索引 vs. 非聚集索引
聚集索引 vs. 非聚集索引
以下内容为上一节MYSQL 索引与数据结构笔记的扩展延申
文章目录
- 聚集索引 vs. 非聚集索引
- 一、概念与存储结构
- 二、InnoDB 聚集索引详解
- 三、辅助索引(非聚集)的存储与回表
- 四、MyISAM 与 InnoDB 的引擎差异
- 五、性能对比与适用场景
- 总结
一、概念与存储结构
| 特性 | 聚集索引(Clustered Index) | 非聚集索引(Non-clustered / Secondary Index) |
|---|---|---|
| 对应引擎 | InnoDB(默认) | 所有存储引擎都支持;MyISAM 仅支持非聚集 |
| 逻辑含义 | 数据行按索引主键的顺序物理存储 | 索引叶子页只存索引列 + 主键值,数据行另存 |
| 叶子节点存储 | 完整行数据(整行列值) | 仅 (索引列值, 主键列值),再回聚簇索引取整行 |
| 对应文件 | .ibd(单文件,含数据与索引) | 索引:MyISAM .MYI;数据:MyISAM .MYD |
| 查询效率 | 主键查找 → 一次 B+ 树遍历即可命中整行 | 二级索引查找 → 得到主键 → 再一次聚簇索引查找(“回表”) |
| 维护开销 | 插入/删除时直接在数据树上操作 | 插入/删除时需同时维护数据树和所有二级索引树 |
二、InnoDB 聚集索引详解
- 表数据即主键 B+ 树叶子
- 在 InnoDB 中,每张表都会以其主键构建一棵 聚簇 B+ 树。
- 叶子节点 中存放整行记录(所有列值),页面大小默认为 16 KB。
- 页级存储
- 索引页(Index Page):内部节点只存“键+子页指针”;叶子页存整行数据的记录。
- 页目录(Slot Directory):位于页面尾部,记录每条记录在页面中的偏移,支持常数时间的页面内随机定位。
- 点查(主键)
- 访问过程:根页 → 内部页 → 叶子页,一旦命中即可直接读取整行。
- 最多 ≈ log m N \approx\log_{m}N ≈logmN 次页面 I/O,其中 m m m(分支因子)非常大(几百至上千),通常高度仅 3–4 层。
三、辅助索引(非聚集)的存储与回表
- 二级索引叶子页
- 叶子节点仅存
(索引列, 主键值),不存整行数据。 - 上层内部页与聚簇索引类似,只存键和子指针。
- 叶子节点仅存
- 回表流程
- 第一步:在二级索引 B+ 树中定位到所有符合条件的主键值。
- 第二步:对每个主键,再在聚簇索引树(数据树)中按主键查找整行。
- 额外 I/O:每个匹配行都可能触发一次额外的页面读取,开销较大。
- 覆盖索引
- 若查询的所有字段都包含在二级索引 (
SELECT a,b WHERE a=…) 且a,b都在索引定义中,则 无需回表,直接在索引页读出即可,“覆盖”了查询字段。
- 若查询的所有字段都包含在二级索引 (
四、MyISAM 与 InnoDB 的引擎差异
| InnoDB | MyISAM | |
|---|---|---|
| 数据与索引文件 | 一个 .ibd 文件(数据页与索引页共用) | .MYD 存数据、.MYI 存索引 |
| 聚集索引支持 | ✔(主键强制聚集) | ✘(所有索引均为非聚集) |
| 回表 | 二级索引需回聚簇索引 | 二级索引需回数据文件 |
- InnoDB:只需访问
.ibd,主键查找一次 B+ 树即可;二级索引→回表→再一次 B+ 树查找。 - MyISAM:所有索引都非聚集,均需回表读取
.MYD文件。
五、性能对比与适用场景
| 操作类型 | 聚集索引(主键) | 非聚集索引(辅助) |
|---|---|---|
| 主键点查 | 最少 I/O(直接命中叶页) | 必回表,I/O ×2 |
| 范围查询 | 顺序读取叶页链表 | 同样可链表顺序,但每叶页回表 |
| 大数据写入 | 分裂/合并成本固定 | 需同时更新多棵树 |
| 低基数过滤 | 无感 | 索引命中率低,等同全表扫描 |
- 何时用聚集:主键/ID 查找最优;数据写入本身又需物理排序时(如时间序列)。
- 何时用非聚集:针对某列做大量条件过滤/排序时;并且该列选择性高、覆盖索引可用。
下面给出一个完整示例,演示如何:
- 创建带有聚集索引与非聚集索引的表
- 插入测试数据
- 查看索引信息
- 用
EXPLAIN分析各种查询的执行计划
-- 1. 创建示例表(InnoDB 引擎,主键聚集索引 + 二级非聚集索引)
DROP TABLE IF EXISTS users;
CREATE TABLE users (user_id INT NOT NULL,username VARCHAR(50) NOT NULL,email VARCHAR(100) NULL,created DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,PRIMARY KEY (user_id), -- 聚集索引KEY idx_username (username), -- 二级非聚集索引KEY idx_created (created) -- 另一二级非聚集索引
) ENGINE=InnoDBDEFAULT CHARSET=utf8mb4COMMENT='用户表:演示聚集 & 非聚集索引';-- 2. 批量插入测试数据
INSERT INTO users (user_id, username, email, created) VALUES(1, 'alice', 'alice@example.com', '2025-05-01 08:00:00'),(2, 'bob', 'bob@example.com', '2025-05-02 09:30:00'),(3, 'charlie', 'charlie@example.com', '2025-05-03 10:15:00'),(4, 'david', 'david@example.com', '2025-05-04 11:45:00'),(100,'eve', 'eve@example.com', '2025-05-05 12:00:00'),(150,'mallory', 'mallory@example.com', '2025-05-06 13:30:00'),(200,'trent', 'trent@example.com', '2025-05-07 14:00:00');
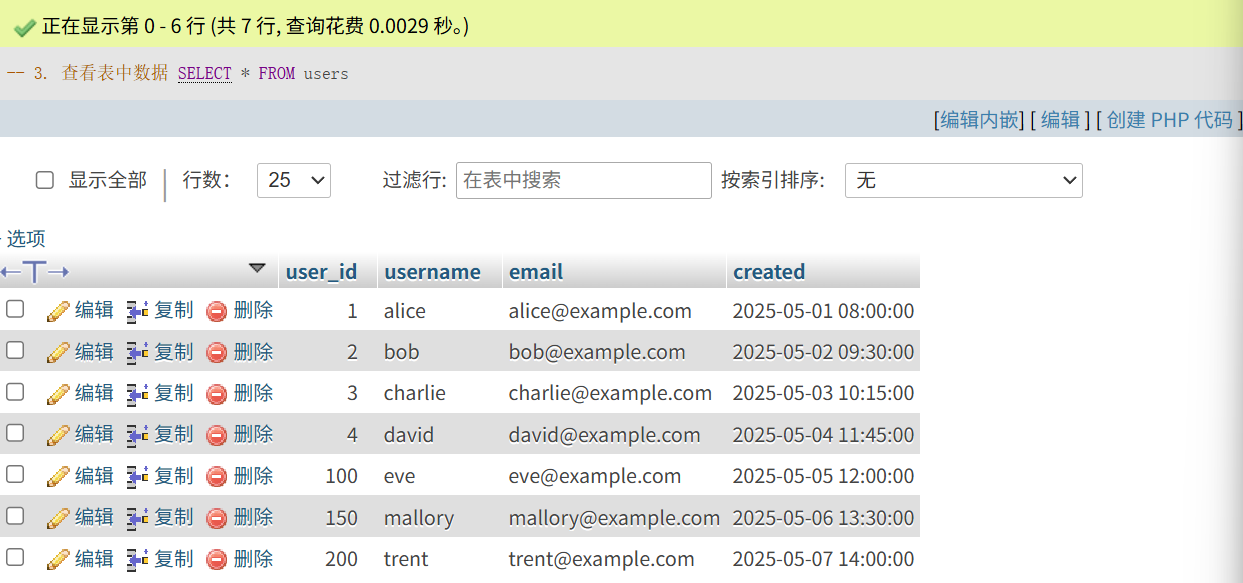
-- 3. 查看表中数据
SELECT * FROM users
-- 4. 查看索引信息
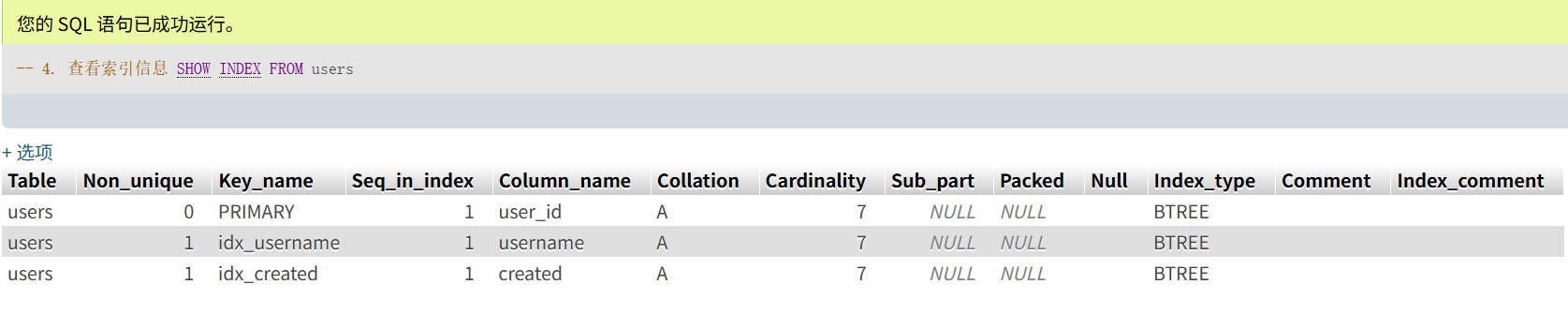
SHOW INDEX FROM users
-- 5. EXPLAIN:主键点查 (走聚集索引,一次 B+ 树定位)
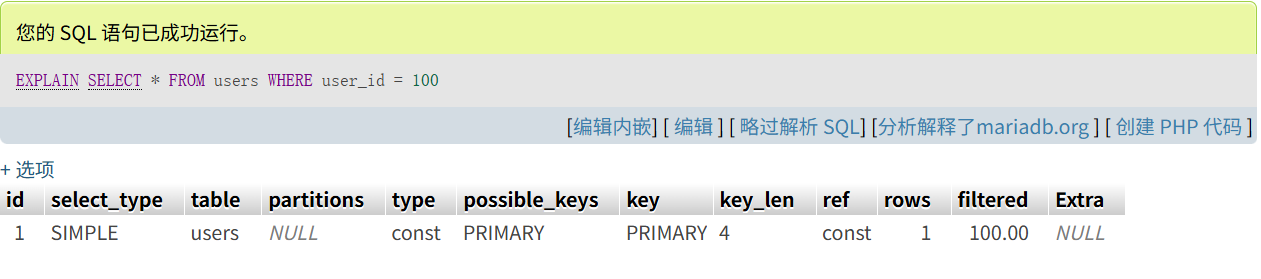
EXPLAIN
SELECT * FROM users
WHERE user_id = 100
-- 6. EXPLAIN:二级索引点查 (走非聚集索引 + 回表)
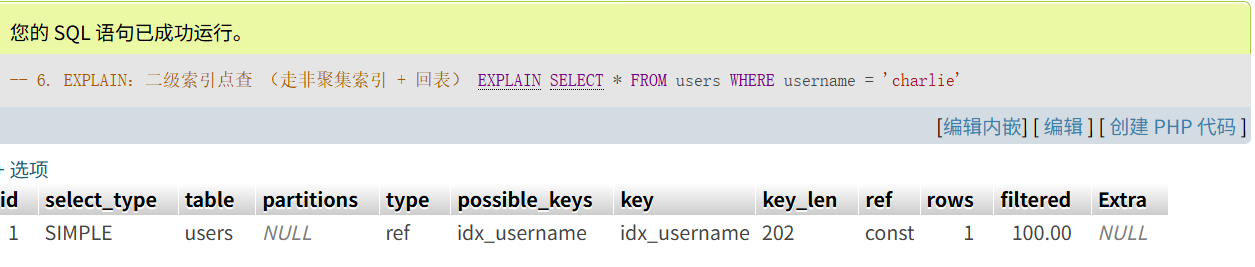
EXPLAIN
SELECT * FROM users
WHERE username = 'charlie'
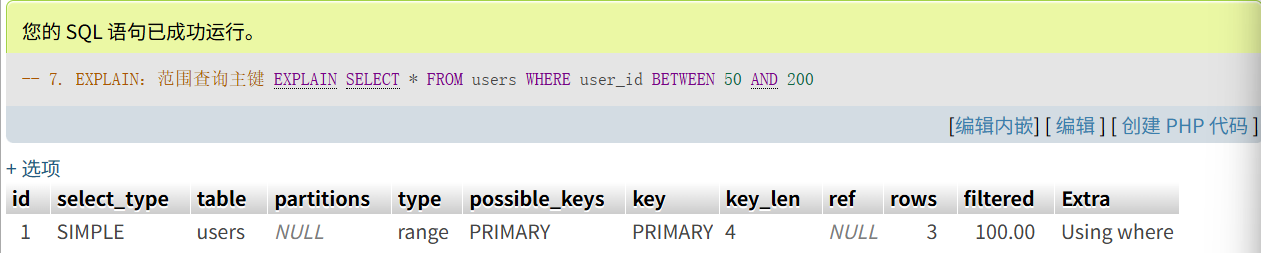
-- 7. EXPLAIN:范围查询主键
EXPLAIN
SELECT * FROM users
WHERE user_id BETWEEN 50 AND 200
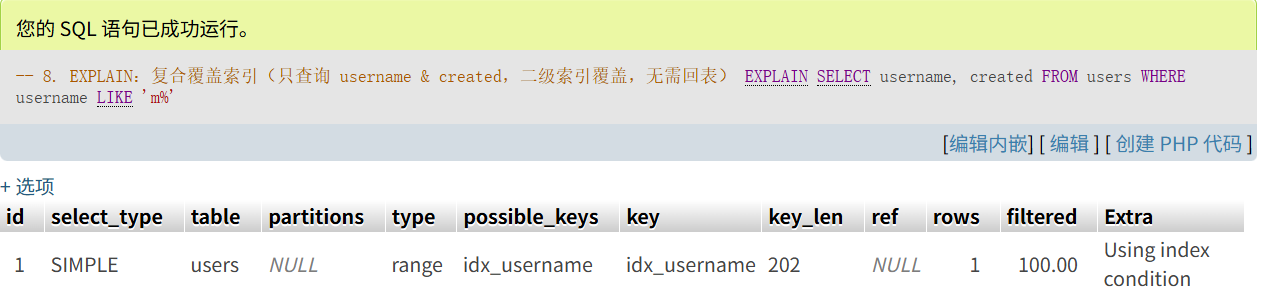
-- 8. EXPLAIN:复合覆盖索引(只查询 username & created,二级索引覆盖,无需回表)
EXPLAIN
SELECT username, created FROM users
WHERE username LIKE 'm%'
- 查看
SHOW INDEX输出Key_name列:PRIMARY、idx_username、idx_createdColumn_name列:分别对应user_id、username、createdIndex_type:均为BTREE
- 主键点查
type: const、key: PRIMARY→ 一次聚集索引定位即命中。
- 二级索引点查
type: ref、key: idx_username→ 先用二级索引定位到主键,再回聚簇索引取整行(会额外一次 I/O)。
- 范围查询
type: range→ B+ 树定位到开始叶子页后,顺链遍历满足范围的叶子页。
- 覆盖索引
- 查询字段全部包含在某二级索引定义中,无需回表:
Extra: Using index表示“覆盖索引”,性能更佳。
- 查询字段全部包含在某二级索引定义中,无需回表:
总结
- 聚集索引:将数据 和 索引聚合存储在一起,InnoDB 默认采用此方式,点查最优。
- 非聚集索引:将索引与数据分离,额外维护二级 B+ 树,查询非索引字段时需 回表,但可做覆盖索引优化。
Extra: Using index表示“覆盖索引”,性能更佳。