探秘Transformer系列之(33)--- DeepSeek MTP
探秘 Transformer系列之(33)— DeepSeek MTP
文章目录
- 探秘 Transformer系列之(33)--- DeepSeek MTP
- 0x00 概述
- 0x01 EAGLE
- 1.1 研究背景
- 1.2 思路
- 1.3 架构
- 1.4 流程
- 1.5 训练
- 1.6 升级
- 1.6.1 EAGLE-2
- 1.6.2 EAGLE-3
- 1.7 HASS
- 1.7.1 动机
- 1.7.2 方案
- 0x02 Multi-token Prediction
- 2.1 研究背景
- 2.2 思路
- 2.3 原理
- 2.4 方案
- 2.5 训练
- 2.6 讨论
- 0x03 DeepSeek MTP
- 3.1 架构
- 3.2 流程
- 3.3 公式
- 3.4 实现
- 3.4.1 MTP Module
- 3.4.2 Output Head
- 3.4.3 Transformer Block
- 3.4.4 MTP 功能
- 3.5 训练
- 3.6 推理
- 0xEE 个人信息
- 0xFF 参考
0x00 概述
MTP(Multi-token Prediction)的总体思路是:让模型使用n个独立的输出头来预测接下来的n个token,这n个独立的输出头共享同一个模型主干。这样通过解码阶段的优化,将1-token的生成,转变成multi-token的生成,从而提升训练和推理的性能。
在DeepSeek之前也有几个MTP方案,其侧重点各自不同。
- 侧重推理时解码加速。比如论文“MEDUSA: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads”、论文“EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty”等。这些方案通过一次生成多个token,实现成倍的加速来提升推理性能。
- 侧重训练时提高效率。比如论文“Better & Faster Large Language Models via Multi-token Prediction]”。具体而言,该方案通过一次生成多个后续token,可以一次学习多个位置的label,这样在训练时可以提供更丰富、更密集的训练信号,进而有效提升样本的利用效率,提升训练速度,同时也可以提升模型性能。Deep Seek MTP 也属于此类。
我们接下来进行学习。
注:
- 论文“Blockwise Parallel Decoding for Deep Autoregressive Models"是MTP的早期之作,因为在前文已经介绍过,所以这里不再赘述。
- 全部文章列表在这里,估计最终在35篇左右,后续每发一篇文章,会修改此文章列表。探秘Transformer系列之文章列表
- 本系列是对论文、博客和代码的学习和解读,借鉴了很多网上朋友的文章,在此表示感谢,并且会在参考中列出。因为本系列参考文章太多,可能有漏给出处的现象。如果原作者发现,还请指出,我在参考文献中进行增补。
0x01 EAGLE
论文“EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty”提出了一种投机采样框架 EAGLE,该框架在特征层进行自回归,并引入了提前一个时间步的 token 序列来解决特征预测的不确定性。EAGLE的核心创新点在于它为了提高小模型能力,把大模型的最后一个hidden state(或者说feature)也添加到了小模型里面。具体来说,就是小模型在训练时,需要把大模型t-1位置输出的 [feature, token] 都送进去,预测的时候也要求小模型和大模型 [feature, token]进行对齐。
1.1 研究背景
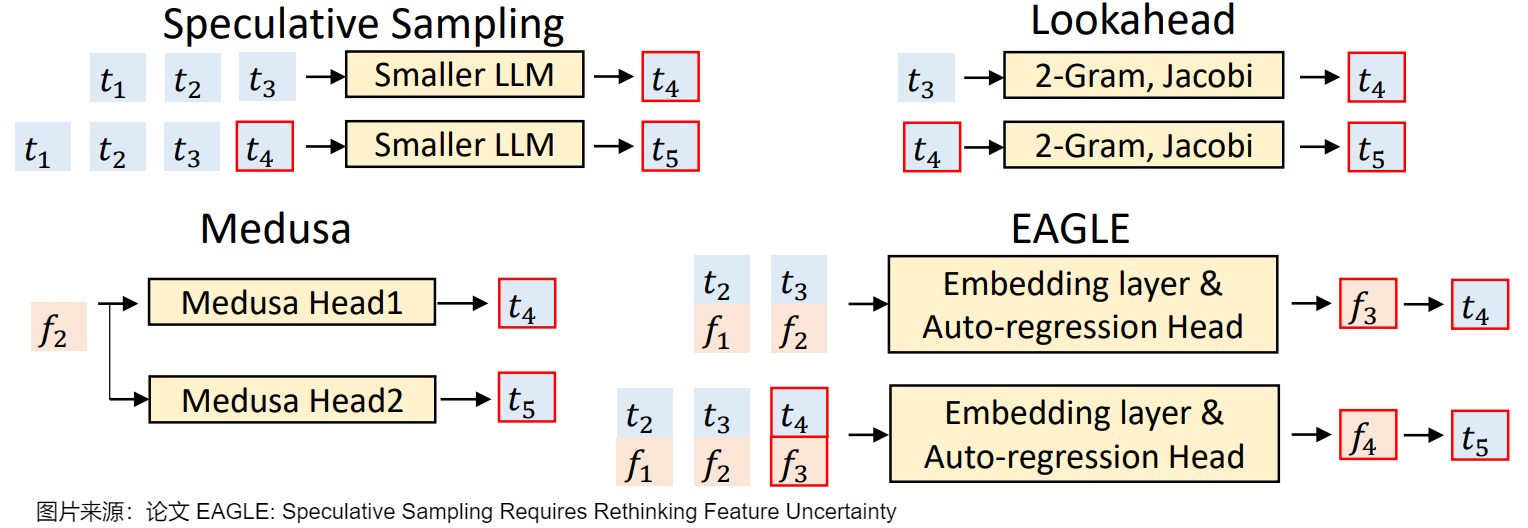
LLM 是逐个 token 生成文本的,即生成下一个 token 需要依赖前面已经生成的 token。这种串行的模式导致自回归编码过程计算量大、耗时,是LLM应用的主要瓶颈,因此有众多方案对其进行改进。EAGLE 论文中用下图把 EAGLE 和其它一些投机方案做了对比, 𝑡 𝑖 𝑡_𝑖 ti 表示第 𝑖 次输入的 token, f 𝑖 f_𝑖 fi 表示 𝑡 𝑖 𝑡_𝑖 ti经过 LLM 后在倒数第二层的输出(即 LM Head 之前的输出)。我们就由此入手,看看其研究背景。
-
投机采样(Speculative Sampling)使用一个较小的草稿模型快速生成多个 token,然后使用原始的目标 LLM 并行验证这些 token。其缺点是需要合适的草稿模型,并且草稿模型的质量直接影响加速效果。
-
Lookahead使用 n-gram 和 Jacobi 迭代来预测 token。其缺点是草稿质量较低,加速效果有限,并且只适用于贪婪解码。
-
Medusa使用多个 MLP 基于目标 LLM 的倒数第二层特征 (second-to-top-layer feature) 来预测 token,图上就是使用 f 2 f_2 f2来预测 t 4 t_4 t4和 t 5 t_5 t5。缺点是草稿质量仍然不高,加速效果有限,并且在非贪婪解码 (non-greedy decoding) 下不能保证输出分布与目标LLM一致。
-
EAGLE 作者认为通过目标模型本身的特征向量预测下一个 token 更准确,所以草稿模型使用与目标模型基本相同的结构,利用了目标模型输出的特征向量作为草稿模型输入。即,EAGLE 创新性地选择对 𝑓 做 Autoregressive Decoding,将 Speculative Decoding 前移至了特征层(即倒数第二层)。对应图上就是使用 ( f 1 , f 2 ) (f_1,f_2) (f1,f2)来预测 f 3 f_3 f3,同时把token序列 ( t 2 , t 3 ) (t_2,t_3) (t2,t3)再前进一步,利用 p 4 = L M H e a d ( f 3 ) p_4=LM\ Head(f_3) p4=LM Head(f3)得到 t 4 t_4 t4。
1.2 思路
EAGLE 作者提出了两个核心观点:
- 在特征层(feature level)进行自回归预测,然后通过 LM Head 得到 token,比直接预测 token 更简单,效果更好。特征指的是 LLM 倒数第二层的输出的embedding,也就是在进入 LM Head 之前的隐状态。隐状态相较于 token 层更有规律性,而且会拥有比最终结果更多的暗知识(dark knowledge)。只采样 token 的方法显然就直接忽略了这些暗知识。
- 采样过程中的不确定性限制了特征预测的性能。因为 LLM 会对 token 的概率分布进行采样,所以LLM 的输出是带有随机性的。这种随机性会导致特征序列的预测变得不确定。例如,给定相同的输入「I」,接下来可能按概率采样输出「always」或者「am」,在这一步不同的选择会造就两个完全不同的意思、两个完全不同的逻辑,这就导致了特征预测的不确定性。
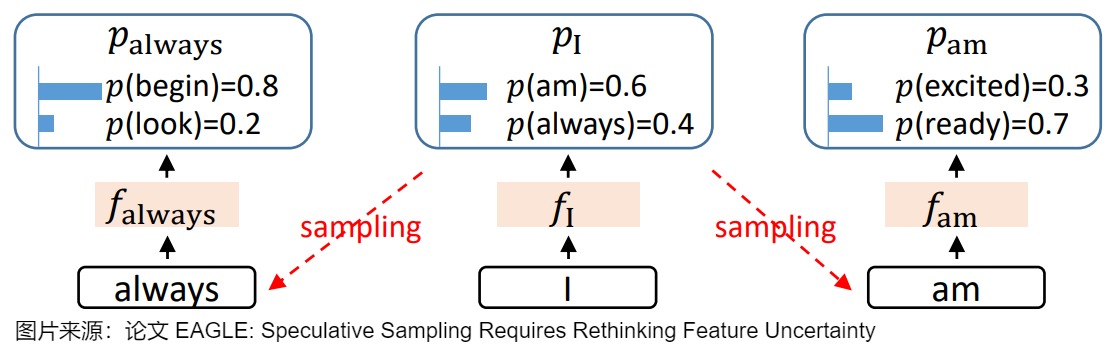
因此,EAGLE 的核心思想如下:
- 在特征层进行自回归。使用一个轻量级的自回归模型来预测目标 LLM 的特征序列,而不是直接预测 token。
- 保留特征层可以更好的克服采样过程中的不确定性。通过引入前一个时间步的 token 序列来解决特征预测中的不确定性,这使得模型能够以最小的额外计算成本精确预测倒数第二层的特征。即,在预测当前特征时,不仅考虑之前的特征序列,还考虑之前已经采样的 token 序列。如上图,在输出 I 之后,会按概率采样输出 am 或是 always。在进一步寻找 always 的后续输出时,如果能保留 I 的特征层输出,就能保留住采样过程中丢掉的关于 am 的信息。
1.3 架构
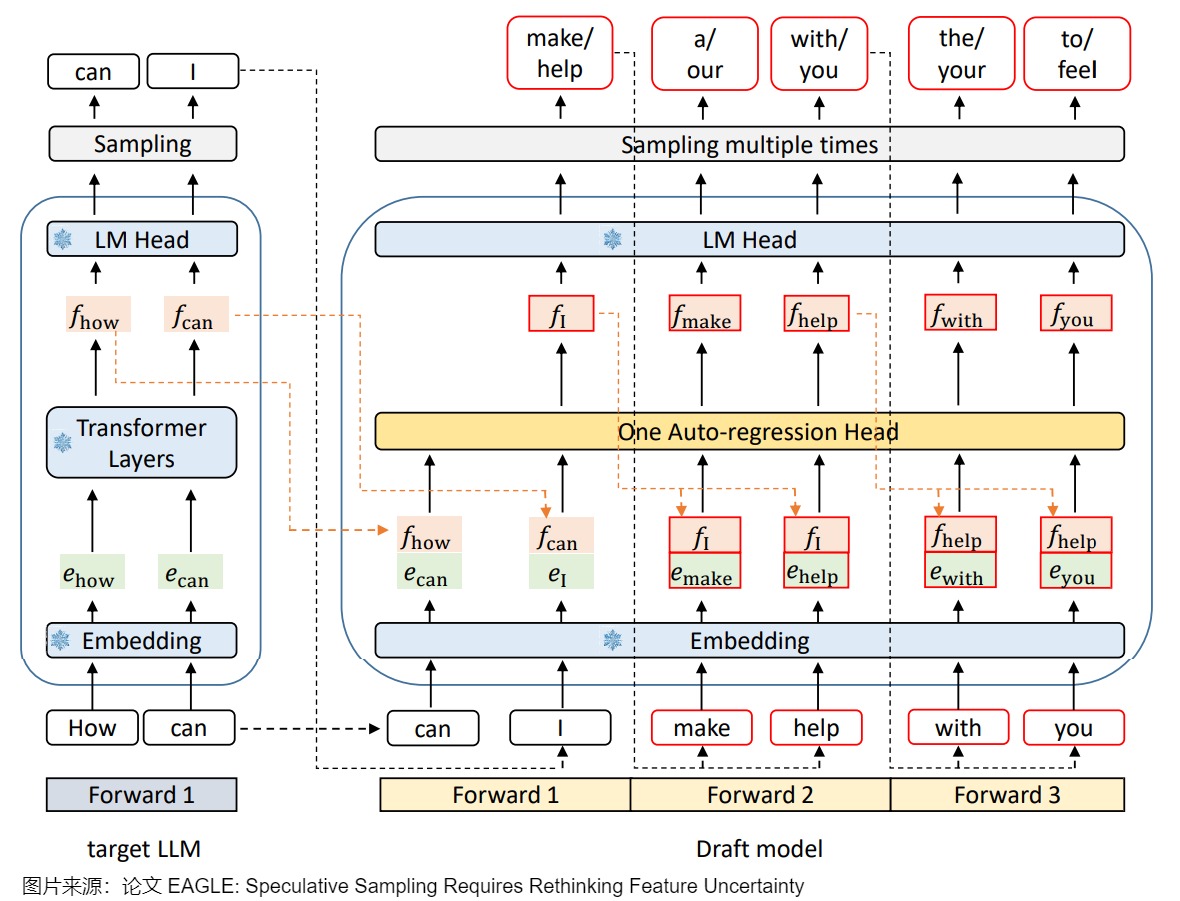
Eagle 需要训练一个小的 draft 模型,这是自己设计的模型,主要包括嵌入层(Embedding layer)、语言模型头(LM Head)和由全连接层和 Decoder 层组成的自回归头(Autoregression Head)。论文作者将 embedding 和 特征 𝑓 拼接在一起作为 Draft Model 的输入。全连接层将拼接后的向量降维至特征维度,Decoder 层负责预测下一个特征。这样可以保留最终输出 token 中遗失的其它信息。为了一次验证多个 sequence,论文采用了 Tree Attention 来生成树状结构的草稿,这样可以在一个前向传播过程中生成多个 token。草稿模型中需要训练的部分是自回归头,嵌入层和语言模型头使用目标 LLM 的参数,不需要额外的训练。
技术细节大致如下图所示。EAGLE使用一层transformer layer+冻结的LM head(大模型的输出头)。绿色块表示token embedding,橙色块表示特征,红色框表示草稿模型的预测,带有雪花状图标的蓝色模块表示使用目标LLM参数,这些参数不受训练。下图三次前向传播使用的是同一个模型,可以共享一份KV Cache。
因为第一次前向传播无法加速,所以需要通过一次前向传播才能得到后续 EAGLE 所需要的特征。这里也就能看出上面对比图中,EAGLE 为何要从 𝑡 2 𝑡_2 t2 画起。
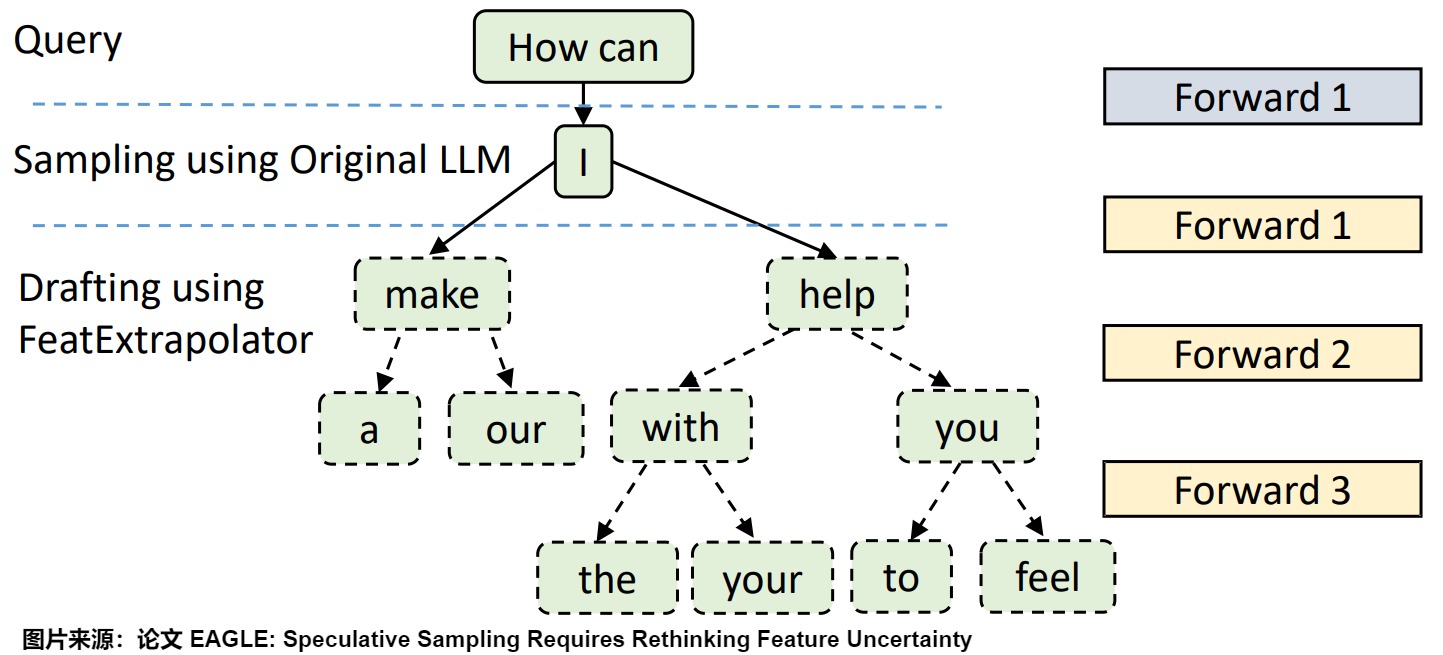
下图给出了每一步的预测结果。
1.4 流程
EAGLE也是draft-and-verify 的基本范式,其基本流程如下。
草稿阶段(Drafting Phase)的输入是之前的特征序列和提前一个时间步的 token 序列,输出是一个由多个 token 组成的草稿树 (draft tree)。该阶段的处理过程如下:
- 将 token 序列转换为 embedding 序列。
- 将 embedding 序列和特征序列拼接在一起。
- 使用一个自回归头 (Autoregression Head) 来预测下一个特征。
- 使用 LM Head 将预测的特征转换为 token 的概率分布,并从中采样得到下一个 token。
- 将预测的特征和采样的 token 添加到输入序列中,继续进行自回归预测。
验证阶段(Verification Phase)的输入是草稿树,输出被接受的 token 序列。EAGLE在验证阶段采用了与投机采样相同的策略。在草稿阶段生成的词元需要通过目标LLM的验证,只有在接受概率下才被采纳,否则会被拒绝并重新采样。这种机制保证了最终生成的词元分布与目标LLM一致。该阶段的处理过程如下:
- 前向传播:使用目标 LLM 对草稿树进行一次前向传播,得到每个 token 的概率分布。
- 验证:从根节点开始,逐层递归地对草稿树中的 token 进行验证。对于每个 token 计算其接受概率,接受概率取决于草稿模型对该词元的概率预测和目标 LLM 对该词元的概率预测。接受概率通常是
min(1, p_target(t) / p_draft(t))。 这个公式的含义是,当目标模型的预测概率大于草稿模型时,该词元被接受;当目标模型的预测概率小于草稿模型时,该词元以一定概率被接受,接受概率等于两个概率之比。 - 接受:如果一个词元以其接受概率被接受,那么这个词元会被添加到最终的输出序列中。
- 拒绝/重采样:如果一个词元被拒绝,那么这个词元会被丢弃,并且会基于目标 LLM 的概率分布
p_target(t)重新采样一个新的词元。 - 合并:最终,被接受的 token 会被合并成一个序列,作为最终的输出。
具体也可以参考下图的对比。
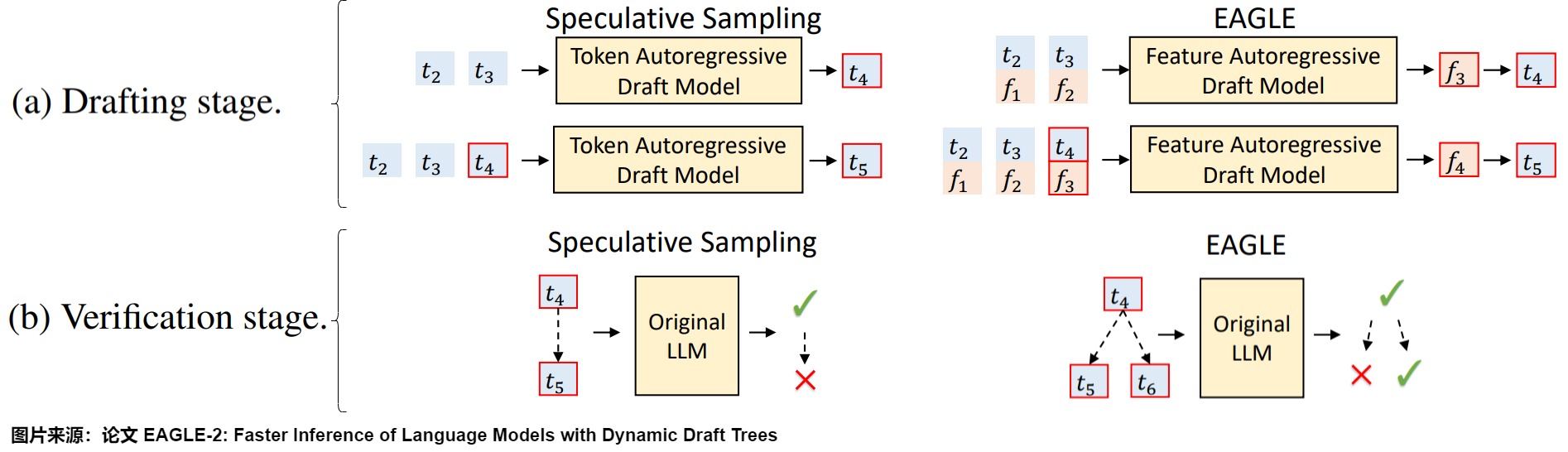
因为小模型除了transformer层数和大模型不同,其他完全一致,包括自回归生成的流程也完全一致。所以EAGLE最大的优势就是对部署极度友好。
1.5 训练
训练中,用了两个 loss。
- Classification Loss(分类损失)使用交叉熵损失 (Cross Entropy Loss) 来衡量预测 token 分布(自回归头输出的特征)和真实 token 分布(原模型特征在经过 LM Head 之后的分类)之间的差异。这是要求两个模型的概率分布对齐。
- Regression Loss(回归损失)使用 Smooth L1 Loss 来衡量预测特征和真实特征之间的差异。这是要求两个模型的feature对齐。由于小模型在推理阶段是自回归的,约束feature能够让小模型的输入更加稳定,从而在一定程度上避免测试时出现OOD(out of distribution)的情况,这样小模型在长距离自回归生成中会拥有更高的准确率。

如果只约束输出token一致而不约束feature,在训练时只使用大模型的feature,但是推理时,小模型用的是自己上一个时间步的feature,该feature和大模型feature是有偏差的,在测试时很可能出现“虽然token预测对了,但是feature和大模型不一样”的情况,从而导致长距离的推理精度受到影响。具体可以参见下图:EAGLE使用目标模型的特征进行训练,而在推理中,草稿模型使用自己的特征。图上的f表示特征,e表示嵌入。上标表示变量的来源,t和d表示目标模型和草稿模型。下标用来索引特征或嵌入的位置。例如, f 2 t f_2^t f2t表示位置2中来自目标模型的特征。 因此,后续其它研究人员都对此做出了改进,比如HASS和CORAL。HASS使用了Multi-step training让模型见过推理阶段的数据分布+增大数据量。
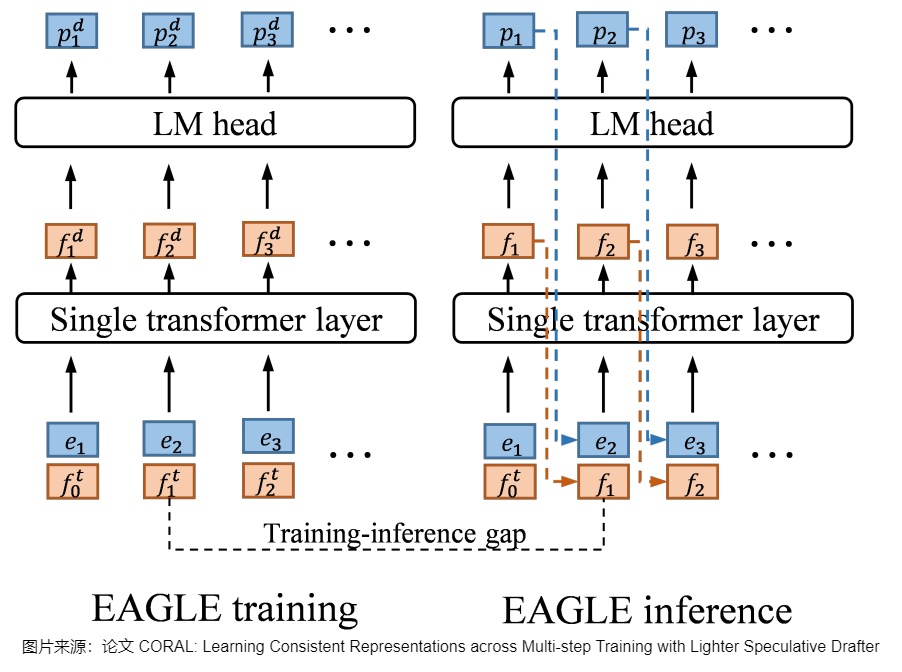
另外,EAGLE作者在论文中也提到,MoE 模型和 Speculative Decoding 配合不好。因为在 Vanilla Inference 阶段,每个 token 只会需要两个 experts 的权重。但 Speculative Decoding 的 verification 阶段需要同时验证多个 token,可能导致激活更多的专家模型,读取更多专家的权重,这就会削弱 MoE 的优势,从而导致加速比的下降。而且,MoE 模型的专家选择过程会引入额外的依赖关系,也可能使得并行计算变得更加困难。
1.6 升级
1.6.1 EAGLE-2
作者还对EAGLE进行升级,得到了EAGLE-2。论文是“EAGLE-2: Faster Inference of Language Models with Dynamic Draft Trees”。EAGLE-2提出了动态草稿树投机采样:依据草稿模型的置信度动态调整草稿树的结构,最高可以将大语言模型的推理速度提高5倍,同时不改变大语言模型的输出分布,确保无损。
思路
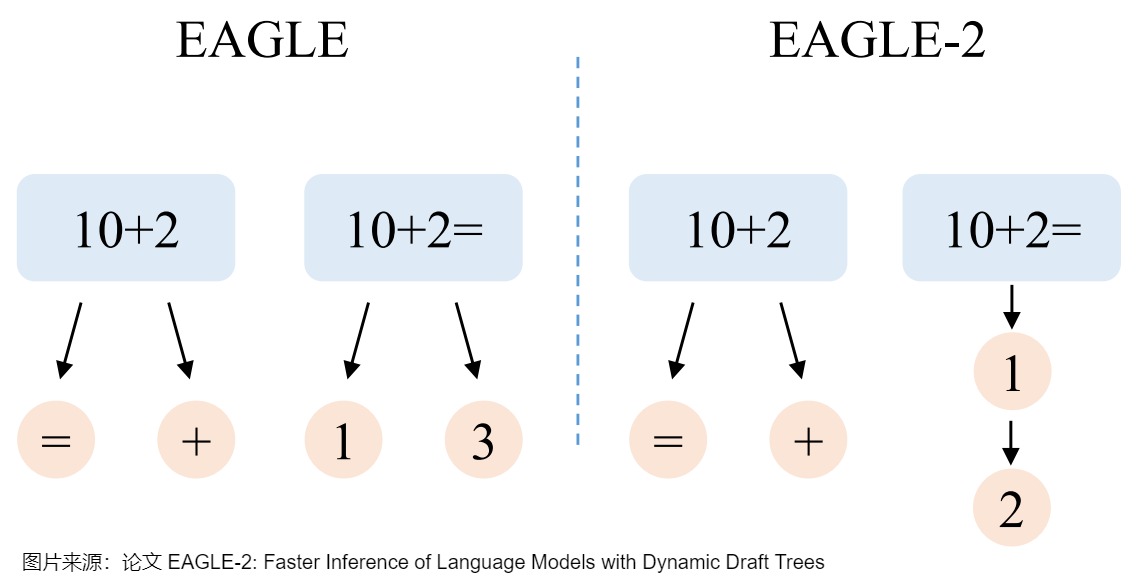
EAGLE和Medusa等方法使用静态的草稿树,隐式地假设草稿token的接受率和上下文无关。
- 当上文是“10+2”时,下一个token难以预测。于是,EAGLE在这个位置添加两个候选token以增加草稿命中率,“10+2=”和“10+2+”有一个正确即可。
- 当上文是“10+2=”时,下一个token明显是“1”,但是EAGLE使用静态的草稿结构,仍然添加两个候选“1”和“3”,“10+2=3”不可能通过大语言模型的检查,存在浪费。EAGLE-2旨在解决这一问题,如下图右侧所示,当上文是“10+2=”时,EAGLE-2只增加一个候选token“1”,将节约出的token用于让草稿树更深,这样“10+2=12”可以通过大语言模型的检查,进而可以一次生成更多的token。
方案
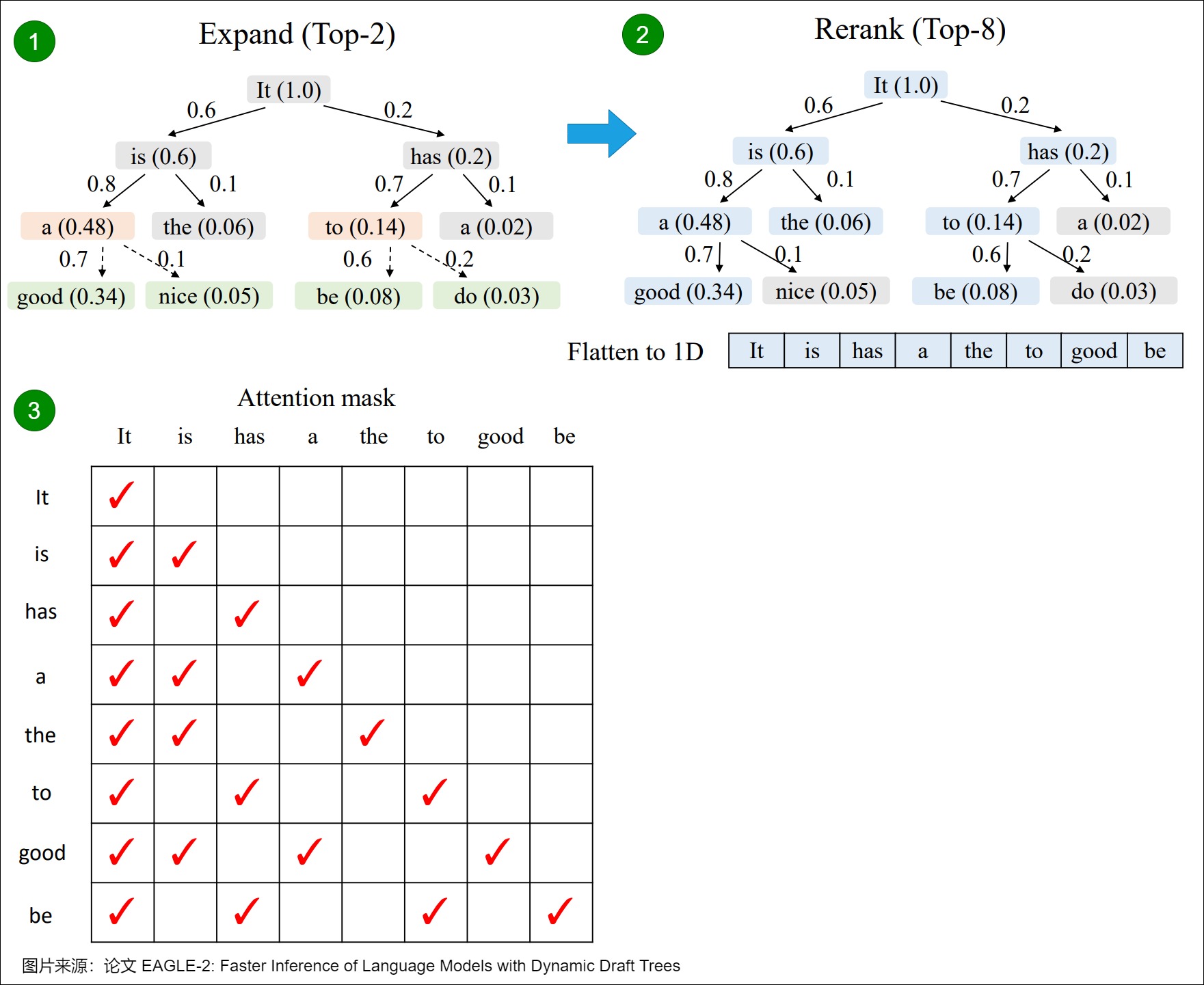
为了保证无损,一个草稿token被接受的前提是它的祖先节点都被接受,所以EAGLE-2将一个节点的价值定义为它和它祖先的接受率的乘积,用置信度的乘积来近似。EAGLE-2包括两个阶段,扩展和重排:
-
扩展阶段加深加大草稿树。在扩展阶段,EAGLE-2选择草稿树最后一层价值最高的m个节点(token)进行扩展。这些token被送入草稿模型,然后将草稿模型的输出作为子节点连接到输入节点,加深加大草稿树。
-
重排阶段修剪草稿树,丢弃部分节点(token)。在重排阶段,EAGLE-2按照价值对整棵草稿树进行重排序,保留前n个节点(token)。草稿token的置信度在0-1之间,两个节点价值相同时,优先保留浅层节点,因此重排后保留的草稿树一定是连通的,这保证了语义上的连贯性。而且,重排后草稿树变小,也降低了原始大语言模型验证的计算量。
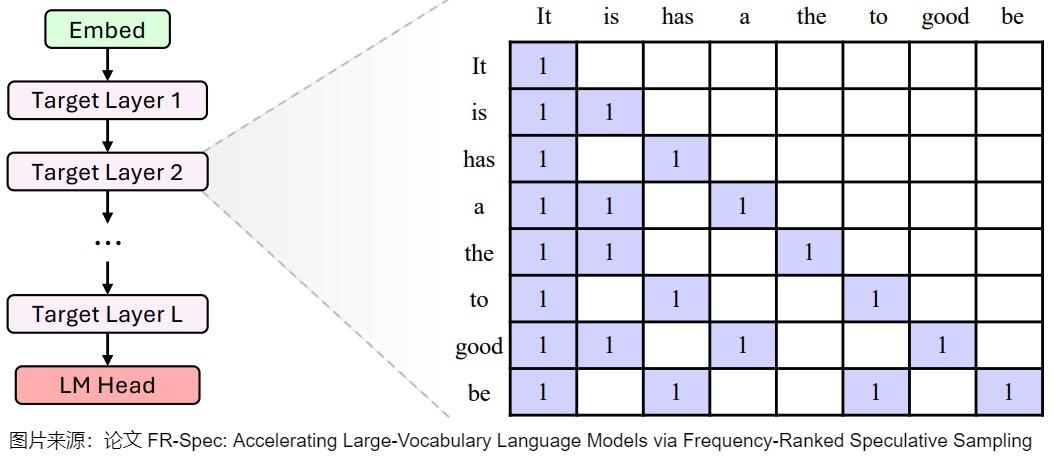
下面是一个简单的例子。图中,扩展(Expand)阶段的黄色框表示被选中进行扩展的节点,绿色框为以这些节点为输入时草稿模型的预测。重排(Rerank)阶段的蓝色框表示被保留的节点,之后它们被展平成一维作为原始大语言模型的输入。为了保证计算结果的正确性,EAGLE-2 也会根据树的结构调整attention mask,确保每一个token只能看到它的祖先节点,不受其他分支的影响。比如,”a”只能看到它的祖先“It”和“is”,看不到另一个分支的“has”。EAGLE-2也同时调整位置编码,确保和标准自回归解码的一致性。
下图是草稿流程。当prompt P=“It”时,波束宽度=2,搜索深度=3。EAGLE-2挑选出顶部K=8个概率标记(紫色)作为草稿树。
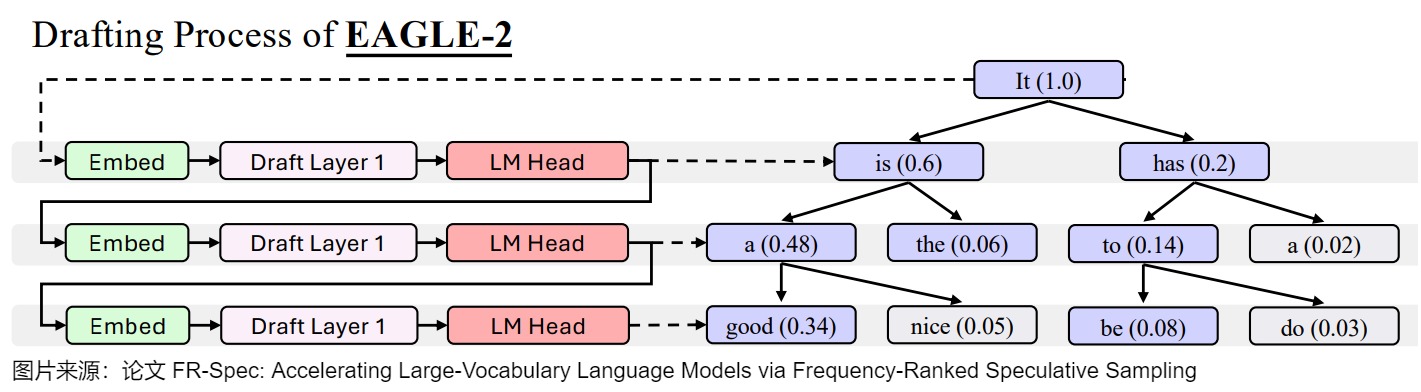
下图是验证流程。
1.6.2 EAGLE-3
EAGLE的作者后来又对方案做了进一步升级,得到了EAGLE-3。EAGLE、Medusa 等投机采样方法都重用目标模型的最后一层特征作为草稿模型的提示,但 EAGLE-3 的作者们发现这存在缺陷。大语言模型的最后一层特征经过线性变换可以得到下一个 token 的分布。最后一层特征只有下一个 token 的信息,失去了目标模型的全局性质。因此,EAGLE-3 不再使用目标模型的最后一层特征作为辅助信息,而是混合目标模型的低层、中层、高层信息来作为草稿模型的输入。
1.7 HASS
为解决上述的训练和解码阶段不一致问题,论文“LEARNING HARMONIZED REPRESENTATIONS FOR SPECULATIVE SAMPLING”提出了协调投机采样(HASS),旨在通过训练阶段学习协调的表征来解决上述问题。该方法包含两部分:
- 为了让草稿模型在训练阶段感知到解码目标,HASS 将推荐系统中的排序蒸馏思想扩展到投机采样,即协调目标蒸馏;
- 为了解决训练和解码间的上下文不一致,HASS 提出了一种多步的对齐训练策略,即协调上下文对齐。
结合这两部分,HASS 显著提高了 LLM 的推理速度。在无需额外推理开销的情况下,也保持了草稿模型训练的高效。
1.7.1 动机
投机采样的实际性能取决于两个因素:草稿模型的解码成本及其与目标 LLM 的对齐程度。为了获得与目标 LLM 高度对齐的高效草稿模型,之前的工作提出利用目标 LLM 的上下文信息。例如,EAGLE 使用目标 LLM 的 hidden states 作为草稿模型的输入特征。然而,这些方法在训练和解码阶段引入了不一致的上下文,如下图所示。在训练期间,草稿模型总是能获取到目标 LLM 在先前时间步的 hidden states。但在解码期间,草稿模型却无法获取到未被验证时间步的目标 LLM 的 hidden states,这导致了训练和解码阶段的上下文不一致。这一问题可以看作是投机采样中在特征层面的 exposure bias。
训练和解码阶段之间还存在目标上的不一致。在解码阶段,草稿模型的目标是生成目标 LLM 会赋予高概率的 token。在这种情况下,草稿模型应更关注于召回这些高概率 token,而对它们之间的具体顺序则可以稍微放松。另外,大部分 LLM 在应用时采取核采样或 top-k 采样。在这些解码策略中,高概率 token 对输出起着更重要的作用。因此,为了获得高效的草稿模型,它的训练目标应考虑到解码阶段的这些特性。而现有的涉及训练草稿模型的投机采样方法普遍忽视了这些解码目标。
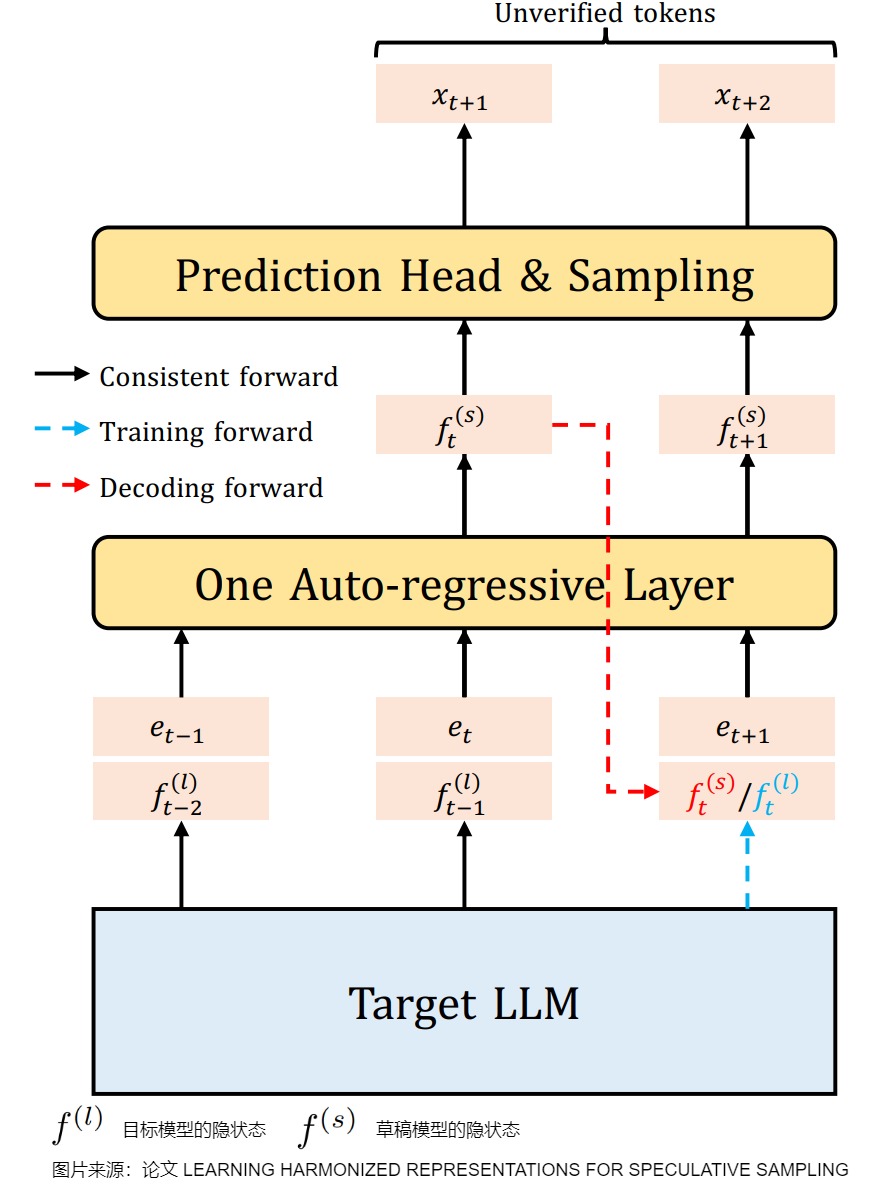
1.7.2 方案
协调目标蒸馏(Harmonized Objective Distillation)
HASS 通过引入推荐系统中的排序蒸馏思想,优先考虑草稿模型解码时更重要的一些 token。具体来说,排序蒸馏的目标是训练学生模型,使其对教师模型中排名靠前的项赋予更高的排序。在投机采样中,草稿模型是学生模型,而目标 LLM 是教师模型。具有类似特性的草稿模型在解码阶段将获得更高的接收率。设 K 个概率最高的 token 组成的集合为 Ω ^ ⊂ Ω \hat \Omega \subset \Omega Ω^⊂Ω ,其中 Ω \Omega Ω代表整个词汇表。HASS 在训练时使用以下的 Top-K 蒸馏损失:
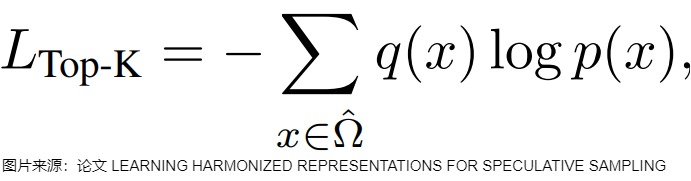
q 和 p 分别表示目标 LLM 和草稿模型预测下一个词的条件概率分布。在结合 EAGLE 时,训练阶段可以从目标 LLM 的 hidden states 中获取 Ω ^ \hat \Omega Ω^,这意味着结合 Top-K 损失训练有着和 EAGLE 一样的训练效率。
协调上下文对齐(Harmonized Context Alignment)
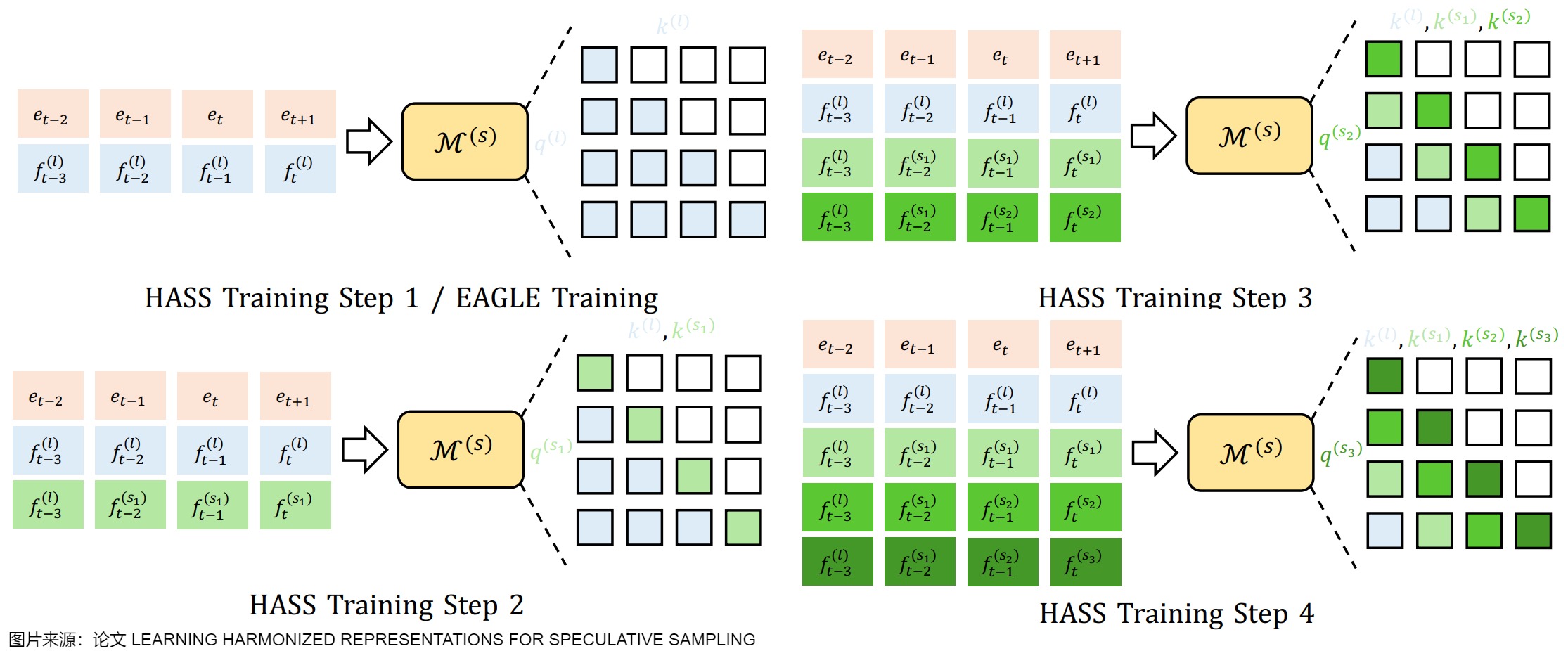
HASS 采用了多步的对齐训练策略,使草稿模型在训练和解码阶段的上下文保持一致。具体来说,HASS 将训练过程分为 n 步,使草稿模型能够利用与解码阶段一致的上下文特征。过程如下:
- 第一步与 EAGLE 的训练相同。在时间步 t+1,草稿模型以目标LLM的特征 f t ( l ) f_t^{(l)} ft(l)作为输入并生成草稿模型特征 f t + 1 s 1 f_{t+1}^{s_1} ft+1s1。这一步中,注意力掩码与因果掩码一致,不做修改。
- 第二步利用了来自第一步的特征。在时间步 t+1 的自注意力机制中,使用 f t ( s 1 ) f_t^{(s_1)} ft(s1)来生成 query。key 和 value 由 f : t ( l ) ⊕ f t ( s 1 ) f_{:t}^{(l)} \oplus f_t^{(s_1)} f:t(l)⊕ft(s1)生成,其中 ⊕ \oplus ⊕表示拼接操作, f : t ( l ) f_{:t}^{(l)} f:t(l) 表示早于时间步 t 的特征。注意力掩码被修改以确保 f t ( s 1 ) f_t^{(s_1)} ft(s1)看到的前一个特征始终是 f i − 1 ( l ) f_{i-1}^{(l)} fi−1(l),如下图中的“HASS Training Step 2“所示。
- 对于第 j 步(j ≥ 3),前一步生成的特征 f t ( s j − 1 ) f_t^{(s_{j-1})} ft(sj−1) 用于生成时间步 t+1 的query,而 key 和 value 由 f : t − j + 2 ( l ) ⊕ f t − j + 2 ( s 1 ) ⊕ ⋯ ⊕ f t ( s j − 1 ) ) f_{:t-j+2}^{(l)}\oplus f_{t-j+2}^{(s_1)}\oplus\cdots\oplus f_t^{(s_{j-1})}) f:t−j+2(l)⊕ft−j+2(s1)⊕⋯⊕ft(sj−1))生成。
HASS 的训练开销是 EAGLE 的 n 倍,但解码开销不变。
训练目标函数如下图所示。

0x02 Multi-token Prediction
论文“Better & Faster Large Language Models via Multi-token Prediction”的核心思路是,让模型在训练时,一次性预测多个未来token,而不是仅仅预测下一个token。
2.1 研究背景
该论文认为,在训练阶段时,传统的token-by-token生成方案有几个问题:
- “预测下一个token”的目标是学习单个token的出现概率,这是一种局部感知的训练方法,难以学习长距离的依赖关系和全局语义。
- 训练时,每次只用下一个token的预测结果来计算损失、更新模型,效率不高。
- 为了克服局部性问题,模型需要大量的训练数据,这导致训练效率低下。
因此,该论文希望在训练阶段通过预测多步token,让模型可以获得更丰富的监督信号,迫使模型学到更长的token依赖关系,从而更好理解上下文,避免陷入局部决策的学习模式。同时,通过一次预测多个token,相当于一次预估可生成多个<predict, label>样本,能收集到多个loss来更新模型,有助于模型加速收敛,也能大大提高样本的利用效率。在推理阶段也可以并行预估多个token,提升推理速度。
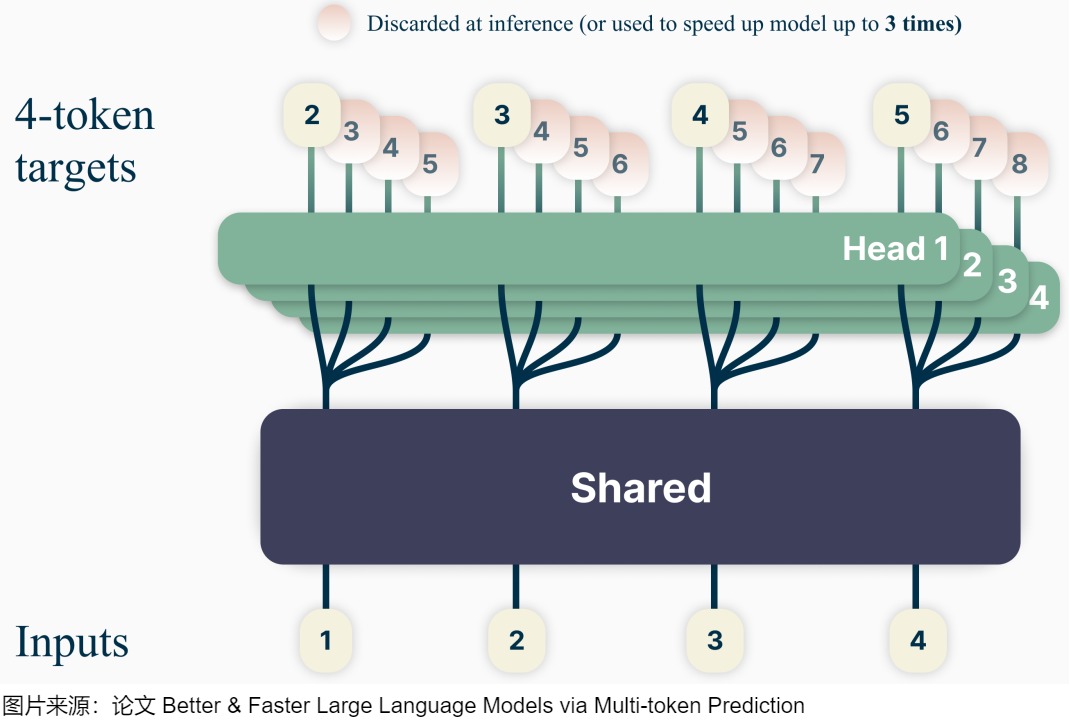
如下图所示,论文的模型和 Blockwise Parallel Decoding 中基本一样,也是多个 Head 共享 Backbone,Head 1 用于预测下一个 Token,Head 2 用于预测下下一个,Head 3 用于预测之后第 3 个,Head 4 用于预测之后的第 4 个,比如输入 1,2,3,4,Head 1 对应的输出为 2,3,4,5,Head 4 对应的输出为 5,6,7,8。与BPD相比,论文除了将模型结构更具体化成transformer的block外,还保留了在训练时的前后依赖关系。
此处需要注意一点:当输入[1]时,会同时预测后续4个词,即为图中的粉红色[2,3,4,5]。当输入[1,2] 时,会同时预测后续4个词,即为图中的粉红色[3,4,5,6]。即,在预测[3,4,5,6]时,输入的是[1,2],而不是单单[2]。图上简化了这一步。而且,图上实际是将这些数据( [1], [1,2], [1,2,3], [1,2,3,4] )组成一个batch,同时并行计算。
2.2 思路
人类在理解语言时,通常会考虑多个词之间的关系,而不是只关注单个词。这启发了作者尝试多token预测的方法。作者将 next-token prediction 扩展为一种多词元预测机制。给定相同的输入序列,模型将通过单次前向传播生成从 x t + 1 x_{t+1} xt+1到 x t + n x_{t+n} xt+n 的 n 个 tokens。请注意,这并不意味着在单个 Softmax 输出的概率分布上同时选择 n 个 tokens,因为 Softmax 是为分类分布(categorical distributions)设计的,其建模的是多个互斥选项中单个离散事件的概率,不支持从单个概率分布中同时选择多个 tokens。因此,Softmax 在每个时间步(time step)只能生成单个 token,要预测多个 tokens 需要多个 Softmax 层,每层专门负责生成独立的 token。
上述多词元预测的损失函数应该首先被分解为多个单词元(token)预测操作头,然后每个单词元(token)预测头会运行独立的 Softmax 来选择对应词元。
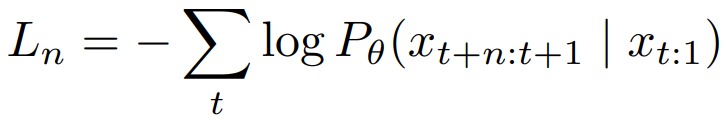
然后,论文引入了中间潜在表征(intermediate latent representation) z t : 1 z_{t:1} zt:1来表示大语言模型中的隐藏表征,这种方式将输入序列 x t : 1 x_{t:1} xt:1与输出序列解耦,使模型能够通过单次前向传播将 x t : 1 x_{t:1} xt:1编码为 z t : 1 z_{t:1} zt:1,并在后续所有生成过程中重复使用该表征。
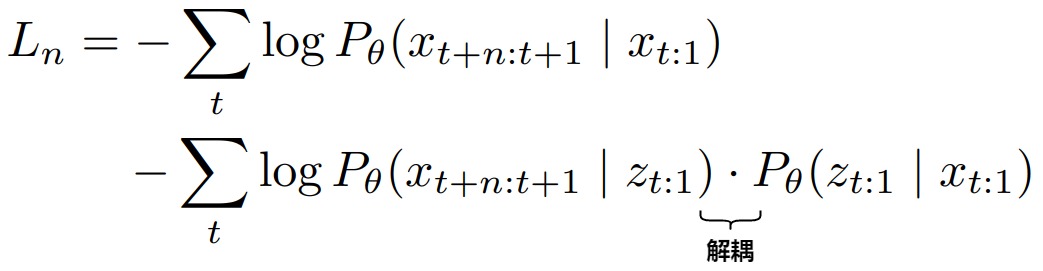
随后, x t + n : t + 1 x_{t+n:t+1} xt+n:t+1与 z t : 1 z_{t:1} zt:1 之间的条件概率会被进一步分解为 n 个独立的单步条件概率(如用蓝色标注的内容所示),每个条件概率代表一个单词元生成步骤。

2.3 原理
论文从两个角度对为何MTP有效进行了分析。
-
Lookahead reinforces choice points。在文本中,某些token不是很重要,因此允许出现一些差异,而不影响文本剩余部分的意思。但有些token具有高级语义性质,这些文本决定了文本(答案)的正确与否(论文把这些token称之为choice points)。实际上,MTP隐式的为这些影响后续决策的关键 token 赋予更高的权重。这一机制促使模型在文本生成中更好地捕捉到这些关键 token,从而生成更连贯和有意义的文本。
-
Information-theoretic argument。MTP 增加了模型对连续标记之间相对互信息的关注。这种变化使模型更倾向于关注序列长依赖关系,从而提升对复杂语境的建模能力,可以更快地学习到语言的全局结构,提高样本效率。
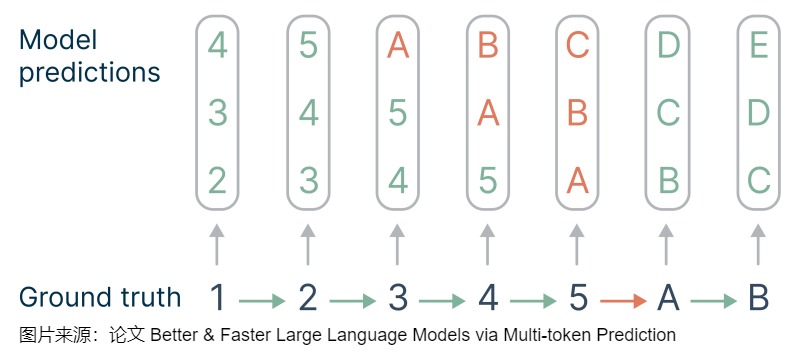
关于第一点,论文给出样例图如下。假设要一次预估3个token,token之间包含一定的"不连贯性",这就给预测带来了难易的区别。比如预估2345、BCDE都是比较容易的,但从5→A是一个转折,属于比较难预估的。这种重要的决策点应该在loss中隐式的占有更多的权重。针对下图,loss项涉及到3处关键点:3→A,4→B,5→C。MTP会给决策点赋予的权重比单步预估平均多了 n ( n + 1 ) 2 \frac{n(n+1)}{2} 2n(n+1)。
关于第二点。论文认为,基于teacher-forcing的训练阶段时,模型可以看到下一个token的groud truth,但在预估阶段看不到真实token,这样导致teacher-forcing 在短预估表现较好,却忽略了长依赖的生成序列结构,可能造成错误累计。给定输入 𝐶 ,令 𝑋 表示下一个token, 𝑌 表示未来第二个token,那么单步预估考虑的是 𝐻(𝑥) , 𝑛=2 的多步预估考虑的是 𝐻(𝑋)+𝐻(𝑌) ,具体如下:
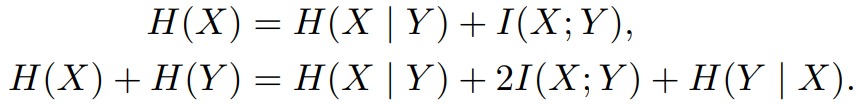
因为在预估接下来的位置时还会出现,所以去掉 𝐻(𝑌|𝑋),然后我们可以发现2-token预估增加了互信息 𝐼(𝑋;𝑌) 的重要性,权重为2。因此当预估的 𝑋 和文本后续内容联系更相关时,MTP的优势更大。
2.4 方案
下图为模型的网络结构,MTP在训练时基于同一个模型躯干,以及四个相互独立的output heads,模型可以同时预测四个token。具体细节如下:
- 主干网络就是训练好的decoder-only的多层Transformer的网络,用于提取输入文本的特征表示。𝑡 个输入token 𝑥 𝑡 : 1 = 𝑥 𝑡 , . . . , 𝑥 1 𝑥_{𝑡:1}=𝑥_𝑡,...,𝑥_1 xt:1=xt,...,x1 经过主干网络计算,最终将 x t : 1 x_{t:1} xt:1 编码为隐层表示 z 𝑡 : 1 z_{𝑡:1} zt:1,并且输出。
- z 𝑡 : 1 z_{𝑡:1} zt:1上面接了多个彼此独立的输出Head,这些Head并行工作,每个Head负责预估一个token, H e a d i Head_i Headi将中间隐藏表征 z t : 1 z_{t:1} zt:1映射到 x t + i x_{t+i} xt+i。𝐻𝑒𝑎𝑑1 负责预估 next token, 𝐻𝑒𝑎𝑑2 负责预估 next next token, 以此类推。对于下图来说,在训练时,一个共享的transformer的主网络,上面接入4个并行预估头,针对输入token 𝑡 𝑖 𝑡_𝑖 ti 分别预估后续的 𝑡 𝑖 + 1 𝑡_{𝑖+1} ti+1, 𝑡 𝑖 + 2 𝑡_{𝑖+2} ti+2, 𝑡 𝑖 + 3 𝑡_{𝑖+3} ti+3 , 𝑡 𝑖 + 4 𝑡_{𝑖+4} ti+4 。具体来说,输入是token 1、2、3、4 这四个token,头1预测位置1(对应token 1)的接下来4个tokens:2、3、4、5,头2预测位置2(对应token 2)接下来的4个token:3、4、5、6。在推理时,可以只保留头1,其可以从token 1来预测token 2、3、4、5,也可以加上其它三个头来加速推理。
- Head 是一个Transformer层,且每个Head的Transformer层是独立的,非共享的,经过这层处理后的结果记作: f h i ( z 𝑡 : 1 ) f_{h_i}(z_{𝑡:1}) fhi(zt:1)。
- 最后再将 f h i ( z 𝑡 : 1 ) f_{h_i}(z_{𝑡:1}) fhi(zt:1) 送入到词表投影层(包括1个解嵌入投影矩阵+1个Softmax)来预估每个词的概率分布。最终通过某种采样方法(如:greedy,beam search等)生成token。注意,这个词表投影层是原预训练网络(original model)的投影矩阵,在多Head之间是共享的。
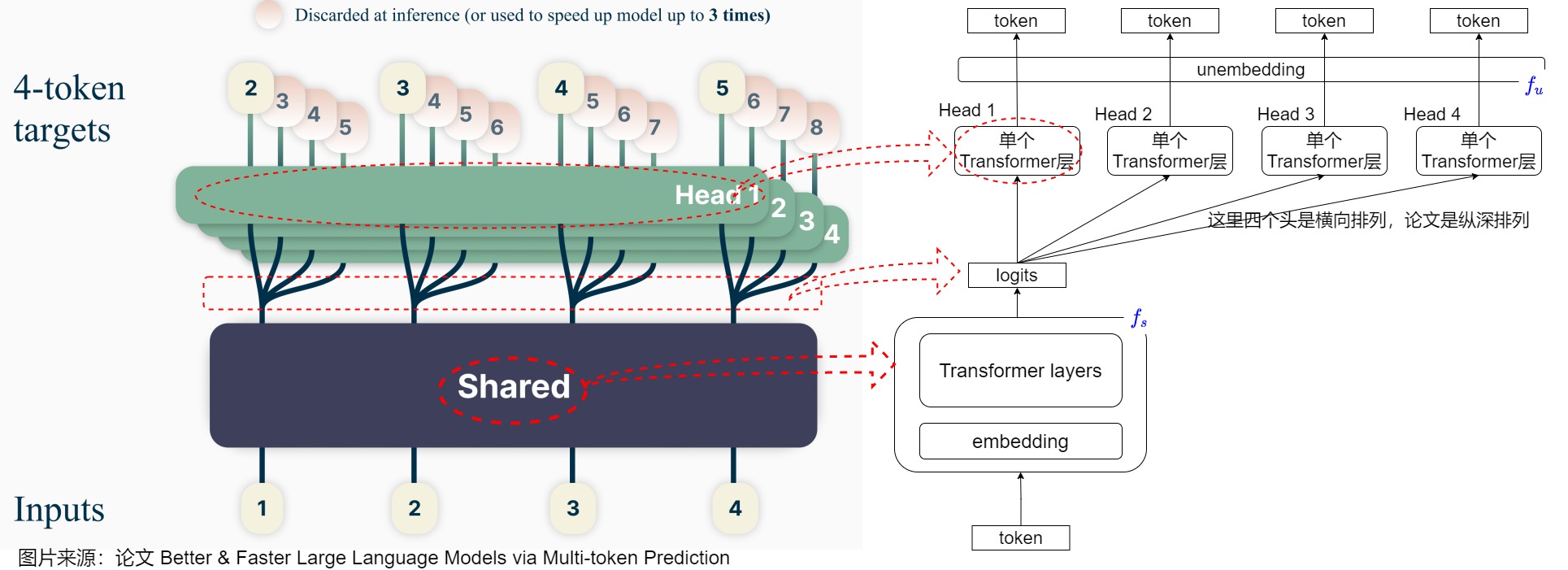
我们再来看看共享组件与独立组件背后的设计考量:
- 共享的 f s f_s fs:这种方式只需单次前向传播即可获得 z t : 1 z_{t:1} zt:1,从而生成 n 个词元,相比传统的 next-token prediction 具有更高的计算效率。
- 共享的解嵌入矩阵 f u f_u fu:解嵌入矩阵非常大,维度数量为 d×V(d 为隐藏层维度,V 为词表大小,通常为 5 万~ 20 万),共享参数能大大减少参数量且对性能的影响有限。
- 独立的输出头:这是架构中唯一独立的部分。每个词元都需要一个独立 Softmax,因此无法共享所有组件。使用独立的输出头能够使得 n 个词元的生成过程相互解耦。一方面,这种设计支持并行生成词元,可以提升训练效率;但另一方面,独立生成词元可能导致输出缺乏连贯性或一致性。此外,模型可能会出现模式崩溃(mode collapse),倾向于生成通用的、高频的词汇,而非细致的响应,从而降低输出的多样性和丰富性。
2.5 训练
训练阶段不会增加额外的开销。只是增加了一个辅助损失。另外,多个头都会并行计算loss,这样可以提升样本利用效率和加速模型收敛。下面是损失函数的推导。

2.6 讨论
作者进行了大量的实验论证在训练时使用多token同时预测的好处,具体结论如下:
- 多token同时预测的训练方法只对参数量大的语言模型有效。
- 在推理时使用多token同时预测能够加速。
- 多token预测的训练方法能够提升全局语境的理解。
- 具体设计添加个并行token生成head需要根据数据集而定。
- 多token同时预测对摘要任务有用,对选择题、数学题表现欠佳。
0x03 DeepSeek MTP
DeepSeek之前的MTP实现方式有一个问题:n 个词元是独立生成的,可能导致模型过度关注局部的模式,忽略了长程的依赖关系,最终可能导致输出不连贯甚至模式崩溃(mode collapse)。为了解决这个问题,DeepSeek 通过保持每个词元预测的完整因果链来实现多词元预测,这种做法一方面提高了预测效率,另一方面也可以让模型具有更好的上下文理解能力,关注到更多的token。
3.1 架构
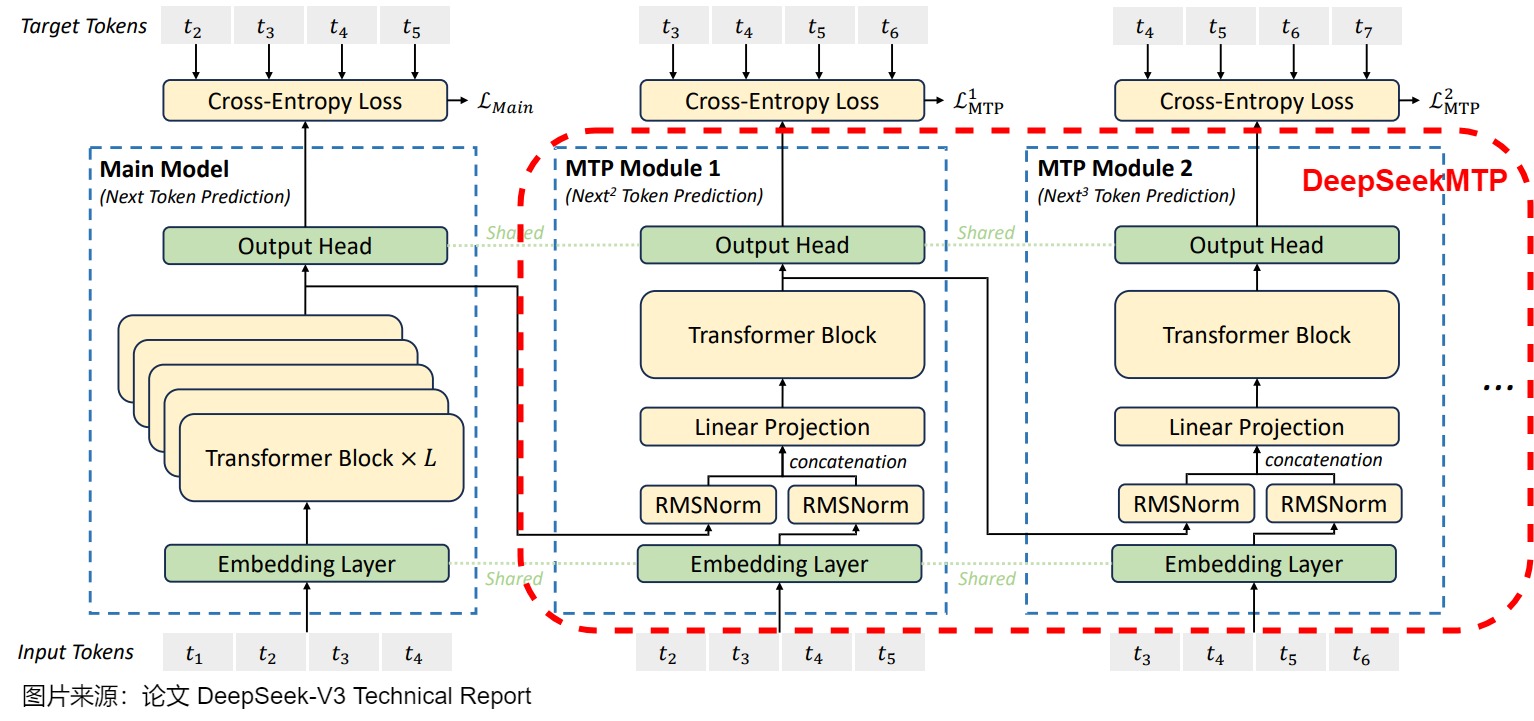
下图是DeepSeek MTP的网络结构,图上的一些具体结构和标识如下:
- 箭头代表causal chain,即token的因果流动链。
- t i t_i ti 代表第 i 个token。
- 主模型(Main Model)会预测下一个token,MTP Module 1预测再下一个token( N e x t 2 T o k e n P r e d i c t i o n Next^2\ Token\ Prediction Next2 Token Prediction),MTP Module 2预测第三个token( N e x t 3 T o k e n P r e d i c t i o n Next^3\ Token\ Prediction Next3 Token Prediction)。
- embedding和outhead两层是共享的。
- Main Model中的Transformer block一共 L 层,而 MTP Module 中的 Transformer Block 都只有一层(在预测时候可能导致信息提取程度不足)。
- 图上蓝色字意思是:该输出是从Transformer Block的最后一层传出来的,这样后续词语token的预测loss,能梯度回传到所有transformer block,可以最大程度覆盖主模型的所有神经元。
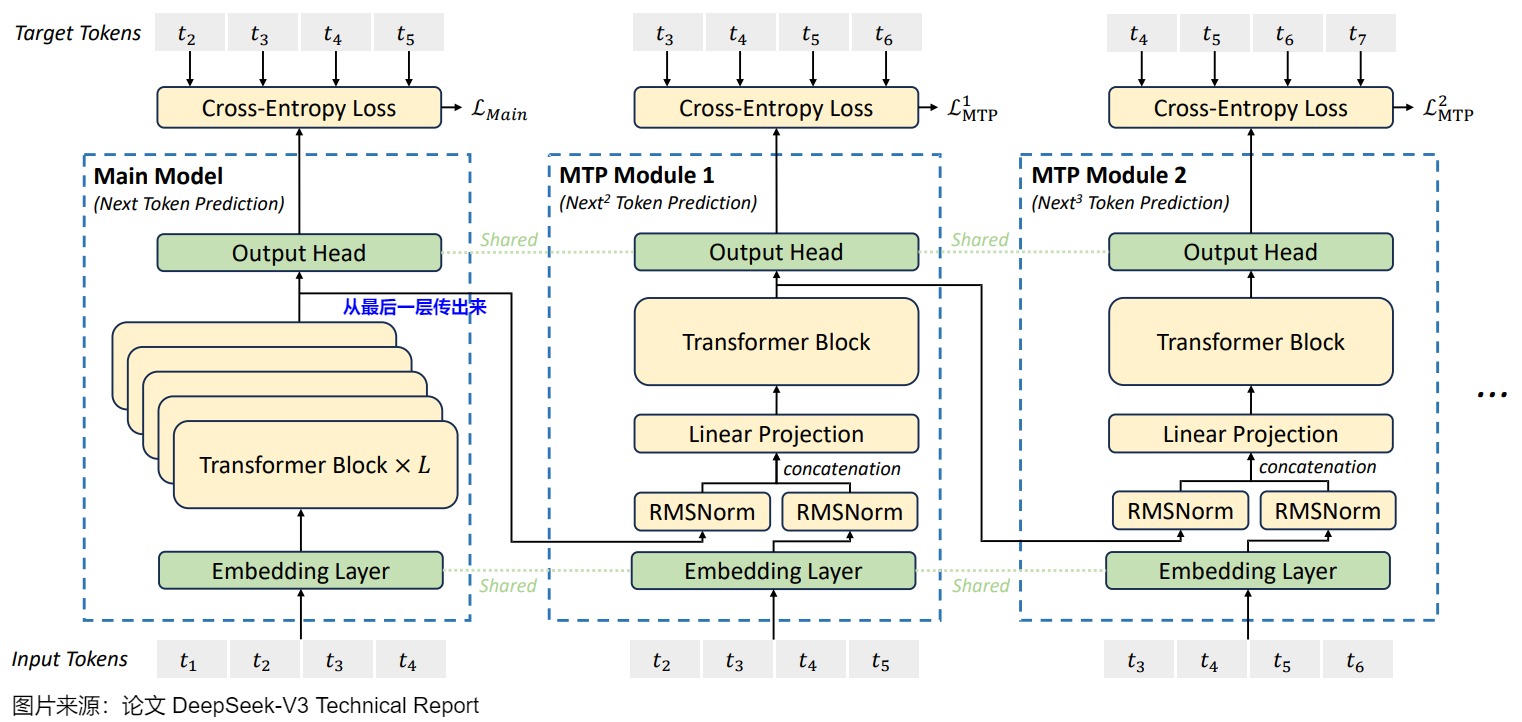
注:DeepSeek MTP主要是用于训练阶段,这点要记牢,否则会对论文中图例的理解造成困难。上图要表达的是并行训练。
3.2 流程
上面的网络结构图比较难懂,我们用单个token为例来看看具体流程。
当Main Module输入token t 1 t_1 t1时,Main model会预测 t 2 t_2 t2,MTP Module 1会依据隐向量 h 1 0 h_1^0 h10(第 1 个token在Main Model的输出)和输入的token t 2 t_2 t2预测出 t 3 t_3 t3,MTP Module 2会依据隐向量 h 1 1 h_1^1 h11(第 1 个token在 MTP Module 1 的输出)和输入的token t 3 t_3 t3预测出 t 4 t_4 t4。即,对于整个模型来说,输入了token t 1 t_1 t1就可以预测出来 t 2 , t 3 , t 4 t_2, t_3, t_4 t2,t3,t4。
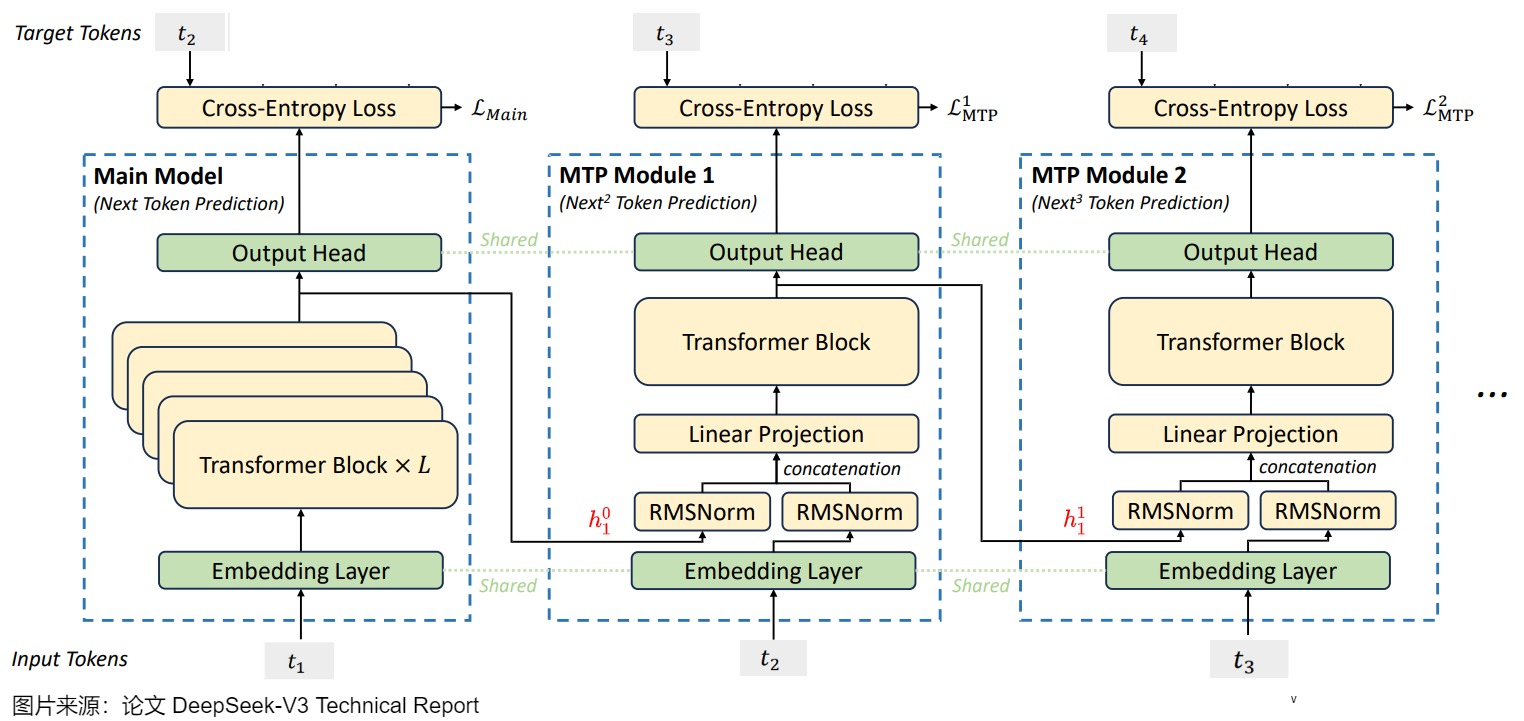
当Main Module输入token t 1 t_1 t1和 t 2 t_2 t2时,Main model会预测 t 3 t_3 t3,MTP Module 1会依据隐向量 h 2 0 h_2^0 h20(第 2 个token在 Main Module 的输出 )和输入的token t 3 t_3 t3预测出 t 4 t_4 t4,MTP Module 2会依据隐向量 h 2 1 h_2^1 h21(第 2 个token在MTP Module 1 的输出)和输入的token t 4 t_4 t4预测出 t 5 t_5 t5。
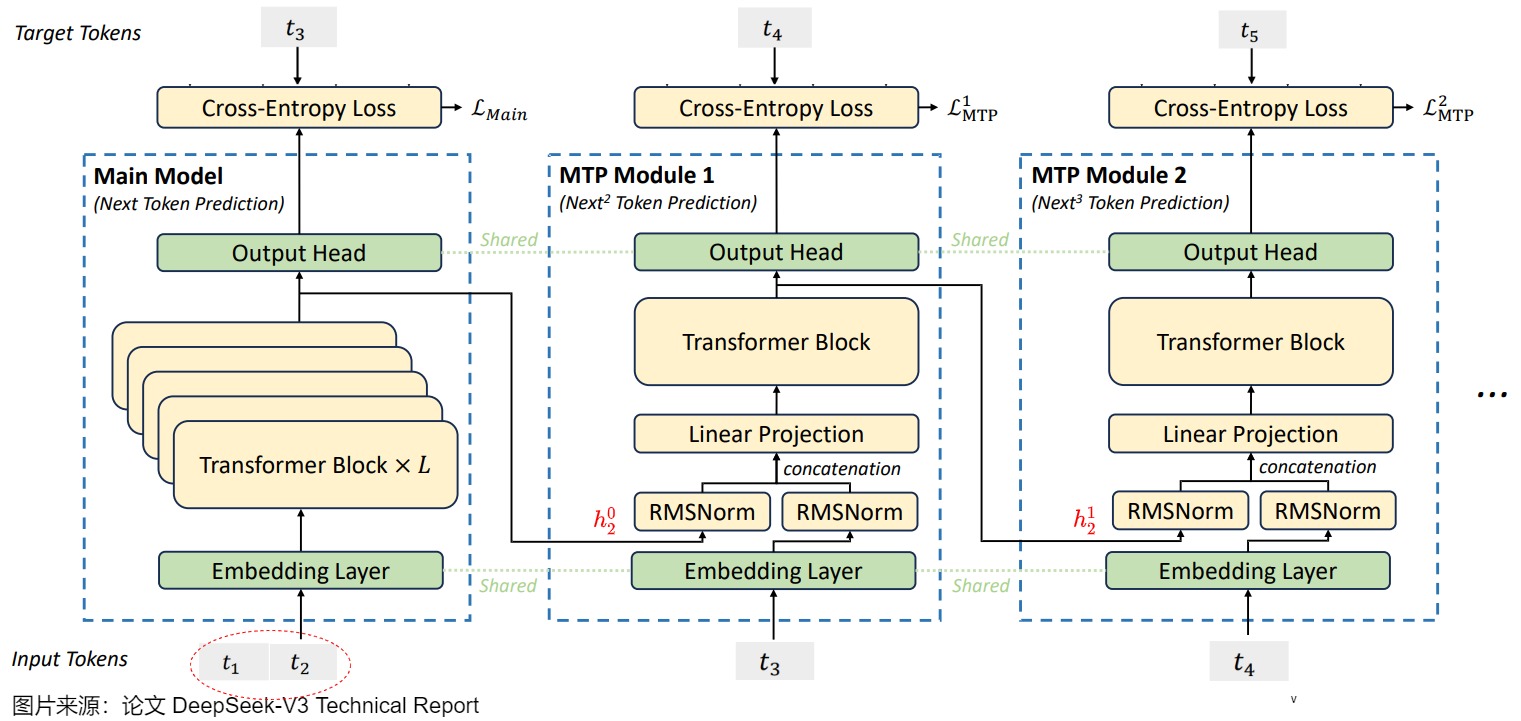
当Main Module输入token t 1 t_1 t1、 t 2 t_2 t2和 t 3 t_3 t3时,Main model会预测 t 4 t_4 t4,MTP Module 1会依据隐向量 h 3 0 h_3^0 h30(第 3 个token在 Main Module 的输出 )和输入的token t 4 t_4 t4预测出 t 5 t_5 t5,MTP 5Module 2会依据隐向量 h 3 1 h_3^1 h31(第 3 个token在MTP Module 1 的输出)和输入的token t 5 t_5 t5预测出 t 6 t_6 t6。
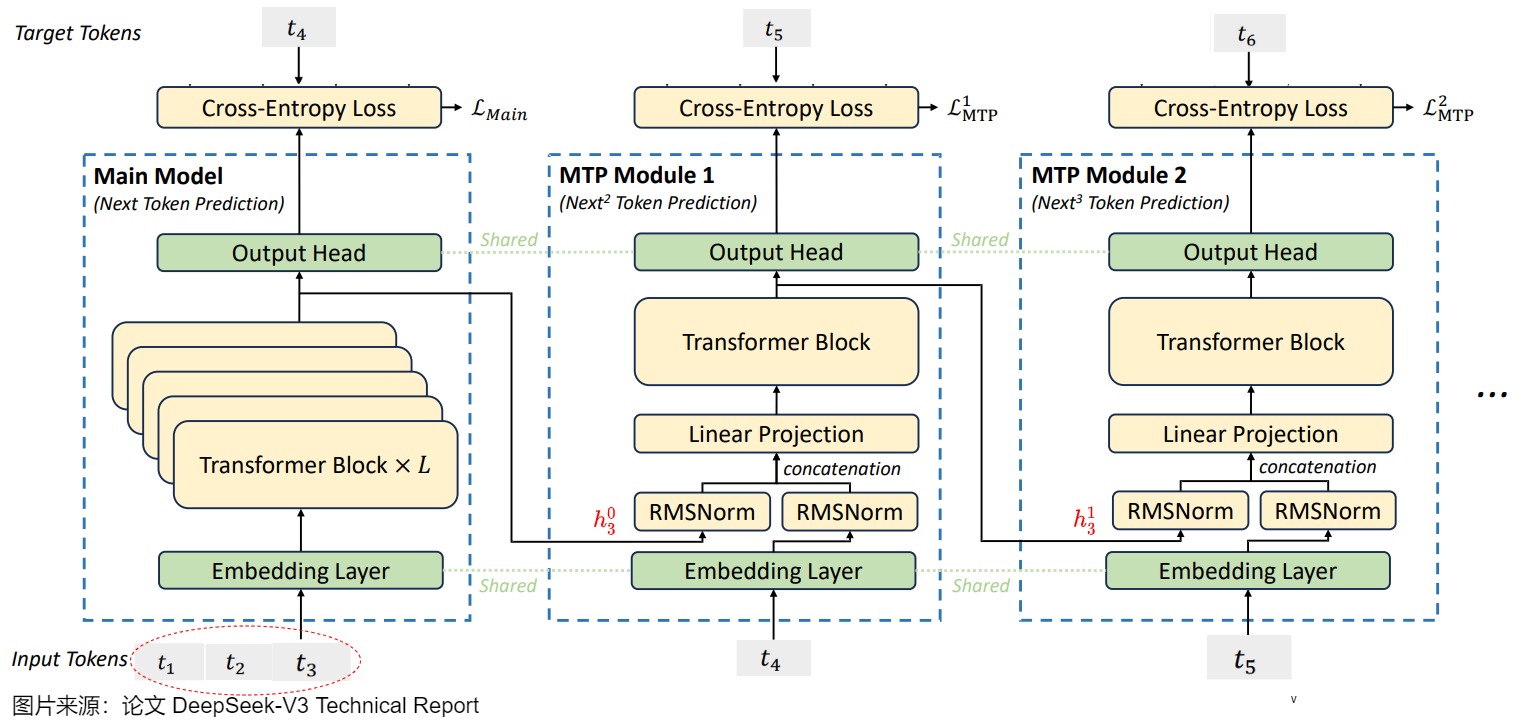
因此,我们可知,对于Main Module输入的第 i(假定 i 从 1 开始)个token t i t_i ti 和第 𝑘 个预测深度,MTP Module k 会依据 第 𝑘−1 个MTP Module 隐层输出 h 𝑖 𝑘 − 1 ℎ_𝑖^{𝑘−1} hik−1 和本模块输入的第 𝑖+𝑘 位置的token t i + k t_{i+k} ti+k进行预测,预测第 k+1 个位置( N e x t k + 1 Next^{k+1} Nextk+1)上的token。同时也可以看到,DeepSeek的实现相对于之前的方法增加了causal chain的连接关系,同时在embedding层增加了残差链接。
我们接下来看看整个样本序列同时输入的情况。在下图中,主模块中的每个输入token用不同颜色标识,其目标token或者说预测token、以及两个MTP Module的辅助输入token也用同样颜色标识。
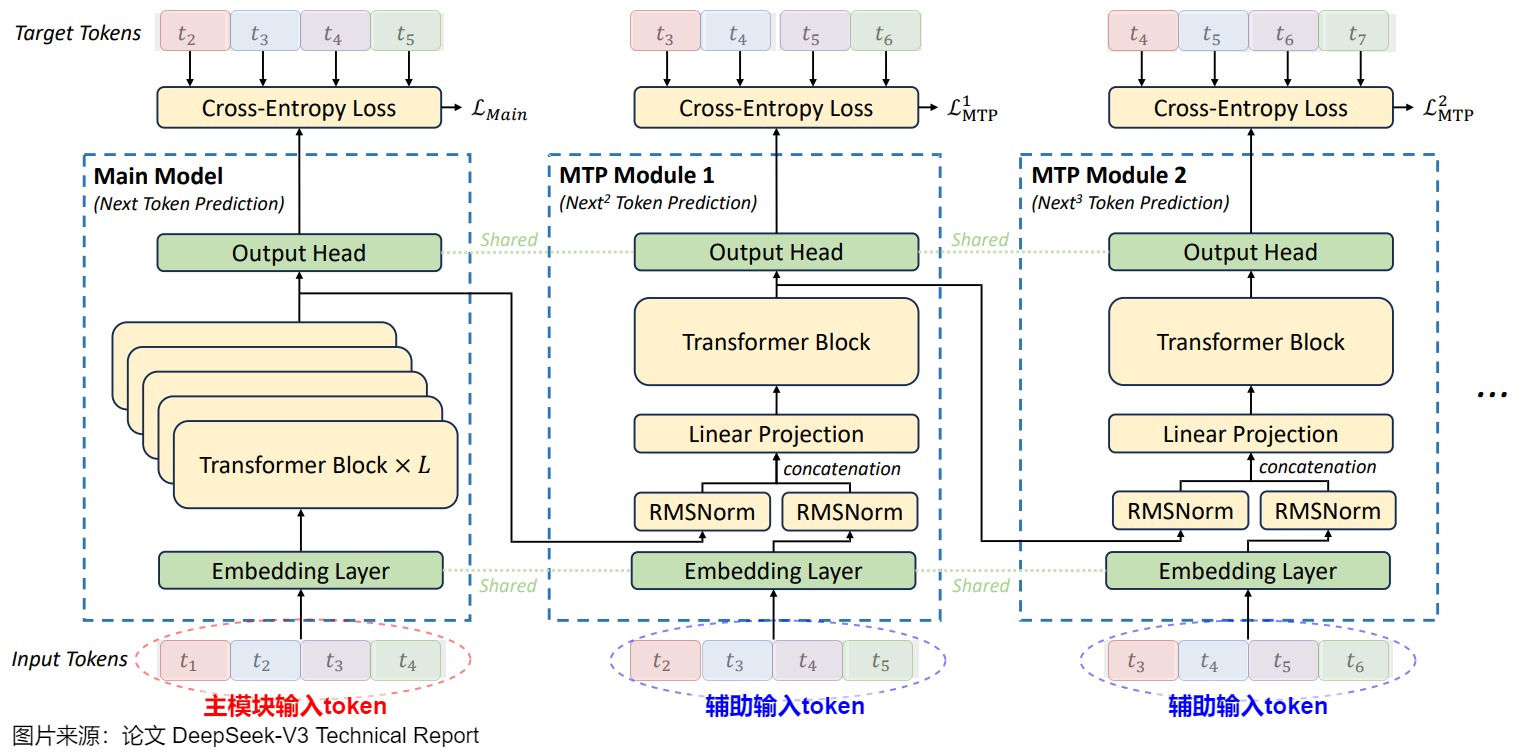
从上图可以看出,第 i 个 MTP Module 的输入 token,是第 i+1 个 token 到第 n 个 token,n 是当前生成的总长度。而它不仅需要 token 的 embedding,还需要 token 在前一个模型计算得到的 hidden states。比如 MTP Module 1 的输入,是 token 2 到 5 的 embedding 和 main model 最后一层输出的 token 2 到 5 的 hidden states。这也就意味着MTP有几个优势:
-
密集监督信号。 MTP 将每个 token 的监督信号从单步预测扩展为多步,使每个 token 参与 了k + 1 次预测(主模型 1 次,MTP 模块 k 次),数据利用率提升 k 倍。
-
显式长距离依赖学习。通过顺序模块(如 MTP 模块 1 预测未来 1 步,模块 2 预测未来 2 步),模型被迫预规划不同跨度的上下文关系(如当前 token 与未来 10 步 token 的关联),强化长距离依赖建模能力;
-
因果链的逐层扩展。每个 MTP 模块在 decoder-only 架构下,通过 Masked Self-Attention 确保预测仅依赖前文信息,形成从短期到长期的因果链扩展。
-
实际是串行生成。在完成 DeepSeek-V3 的 prefill 时,需要输出最后一层的 hidden states,才能进行第 1 个 MTP 的 prefill;第一个 MTP 输出最后一层的 hidden states,才能进行第 2 个 MTP 的 prefill,以此类推。因此,多个 MTP 的多次 prefill 计算是串行的。这意味着每增加 1 个 MTP Module,每次推理的时候就要多一轮串行的 prefill,并且多一份 kv cache。一个主模型加 N 个小模型的推理,可能会严重影响计算调度的效率,可能这也是为什么 DeepSeek-V3 只输出了 1 个 MTP Module 的原因。
我们来看看DeepSeek MTP和EAGLE之间的对比。
- EAGLE更注重于推理阶段的加速,而Deep Seek MTP的动机是提高训练的质量、进而提高LLM的能力,尤其是长距离的预测能力和加速比。因此Deep Seek MTP在训练时没有使用太多特殊技巧,而是小模型会获取和大模型一样的海量数据来训练,这是EAGLE等后训练策略无论如何都无法比拟的优势。
- EAGLE三次前向传播使用的是同一个模型,可以共享一份KV Cache。上图中,MTP module 1和MTP module 2不是同一个模型,无法共享KV Cache。即,EAGLE 在多步推理时,只使用到了一个草稿模型做自回归推理;DeepSeek MTP 在多步推理时,其实是多个草稿模型进行串行推理,每一个 MTP 层,都是一个草稿模型。在 MTP modules 间引入依赖关系破坏了并行性,但也使文本生成更加连贯,更适合对话和推理等场景。
3.3 公式
我们再通过论文中的公式进行对单个MTP Module进行分析。第 i 个 token 的 Transformer 输入如下:
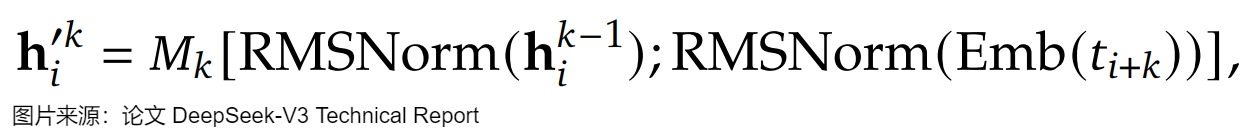
其中:
-
T 是序列总长度。
-
k 是 MTP module 的索引。
-
h t ’ k h_t’^k ht’k是两部分的拼接:
- h i k − 1 h^{k-1}_{i} hik−1 是来自上一步的表征,即第 𝑖 个token在第 𝑘 预测深度上输出的表征。拼接 R M S N o r m ( E m b ( h t k − 1 ) ) RMSNorm( Emb(h_t^{k-1})) RMSNorm(Emb(htk−1))的作用是:其代表了上一个token的上下文表征。
- E m b ( t i + k ) Emb(t_{i+k}) Emb(ti+k) 是第 (i+k) 个词元(token)的嵌入层输出。拼接 R M S N o r m ( E m b ( t i + k ) ) RMSNorm( Emb(t_{i+k})) RMSNorm(Emb(ti+k))的作用是:使用原始输入的ground truth,也就是 t i + k t_{i+k} ti+k,这样类似 Teacher Forcing 模式,对下个Token的预测效果更好。
通过拼接前一层表征与当前 token 嵌入,逐步整合短期语义与长期依赖,可以生成更丰富的中间表征。另外,MTP Module 的 Transformer Block 只有一层,其参数偏少。正是因为在更丰富的中间表征的辅助下,只需要很少的参数就能够完成对一些token的准确预测。
-
RMSNorm 算子对两个表征向量进行归一化处理,使它们的数值更具可比性。随后通过拼接算子[·;·]生成 2d 维度的表征。
-
最终通过线性投影矩阵 M k M_k Mk 将维度从 2d 映射回 d,供 Transformer block 使用。
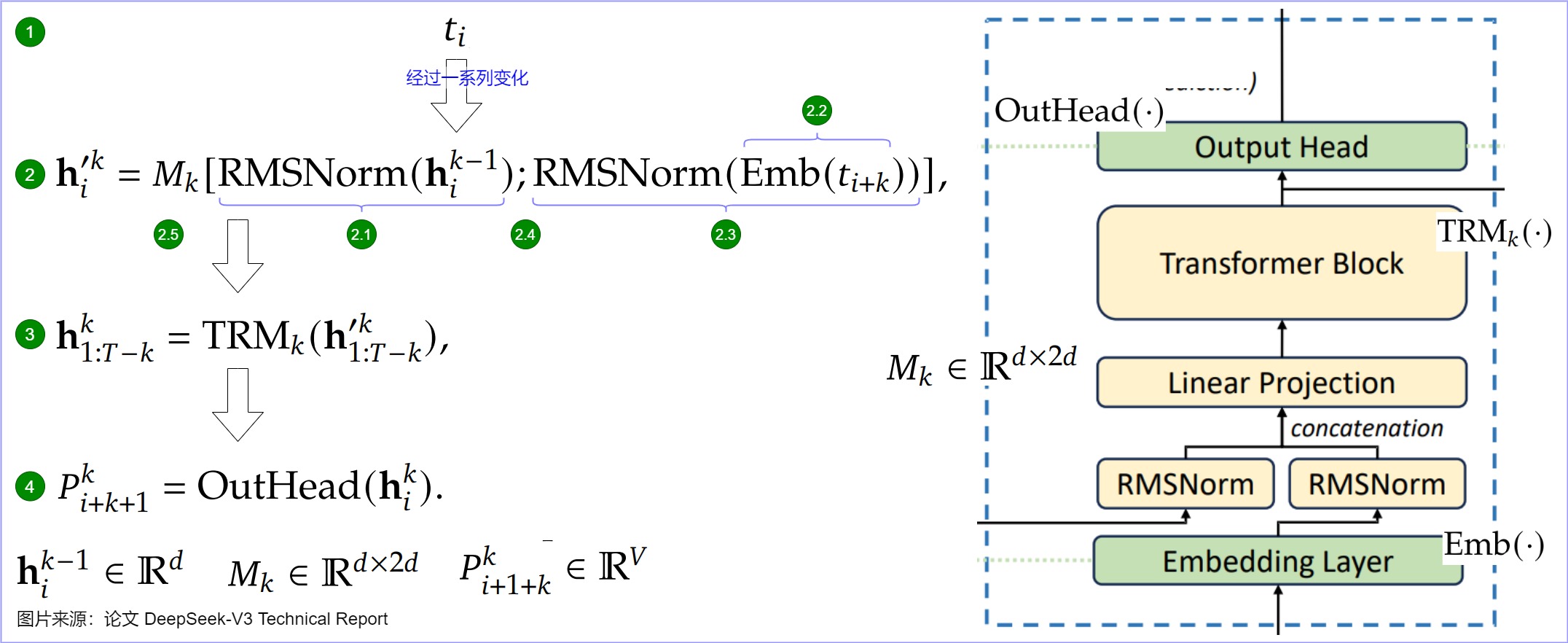
对于第 𝑖 个token 𝑡 𝑖 𝑡_𝑖 ti和第 𝑘 个预测深度,该token在MTP Module k中的流经路径如下:
- 输入token首先接入一层共享的embedding layer,经过一系列处理(Main model,以及之前的MTP Module)之后,得到第 𝑘−1 层的的隐层输出 h i k − 1 h_i^{k-1} hik−1,这是第 𝑖 个token在第 𝑘 - 1 预测深度上输出的表征,对应图上标号1。
- 将第 𝑘−1 层的的隐层输出 h i k − 1 h_i^{k-1} hik−1做归一化处理,对应图上标号2.1。
- 将MTP Module k的输入辅助token,即第 𝑖+𝑘 位置的token做嵌入化,得到 embedding(对应图上标号2.2),再对 embedding 做归一化处理(对应图上标号2.3)。
- 因为transformer block只接受一个token的向量,所以需要将两个归一化的结果进行拼接(对应图上标号2.4的’;"),输入给线性层 M k M_k Mk,做线性变换(把串联之后的2d维度的向量,映射到d维度,就是TRM层的输入维度)之后得到 h i ′ k h_i^{'k} hi′k。
- 再将 h i ′ k h_i^{'k} hi′k 输入到Transformer层,获得第 𝑘 个预测深度的输出: h 1 : T − k k h^k_{1:T-k} h1:T−kk(对应图上标号3)。关于下标切片分为的作用,有两种可能:
- 因为T 是序列总长度,因此第 𝑘 预测深度最长处理的输入token位置 𝑖 应该满足 𝑖+𝑘≤𝑇。 所以第 𝑘 预测头能接受的 𝑖 的范围为: 𝑖≤𝑇−𝑘 ,也就是 𝑖∈[1,𝑇−𝑘] ,即切片范围。
- 下标1:T-k 表示其包含了从token 1到 token T-k 的表征。
- 从中提取出第 i 个元素 h i k h_i^k hik,将其通过一个各Module共享的映射矩阵 𝑂𝑢𝑡𝐻𝑒𝑎𝑑变换,再过 𝑠𝑜𝑓𝑡𝑚𝑎𝑥(.) 处理,计算出词表 𝑉 维度的输出概率(对应图上标号4)。 h i k h_i^k hik 的 𝑙𝑎𝑏𝑒𝑙 是对应 𝑖+1+𝑘 位置的token。
3.4 实现
我们使用vLLM的代码来进行学习。
3.4.1 MTP Module
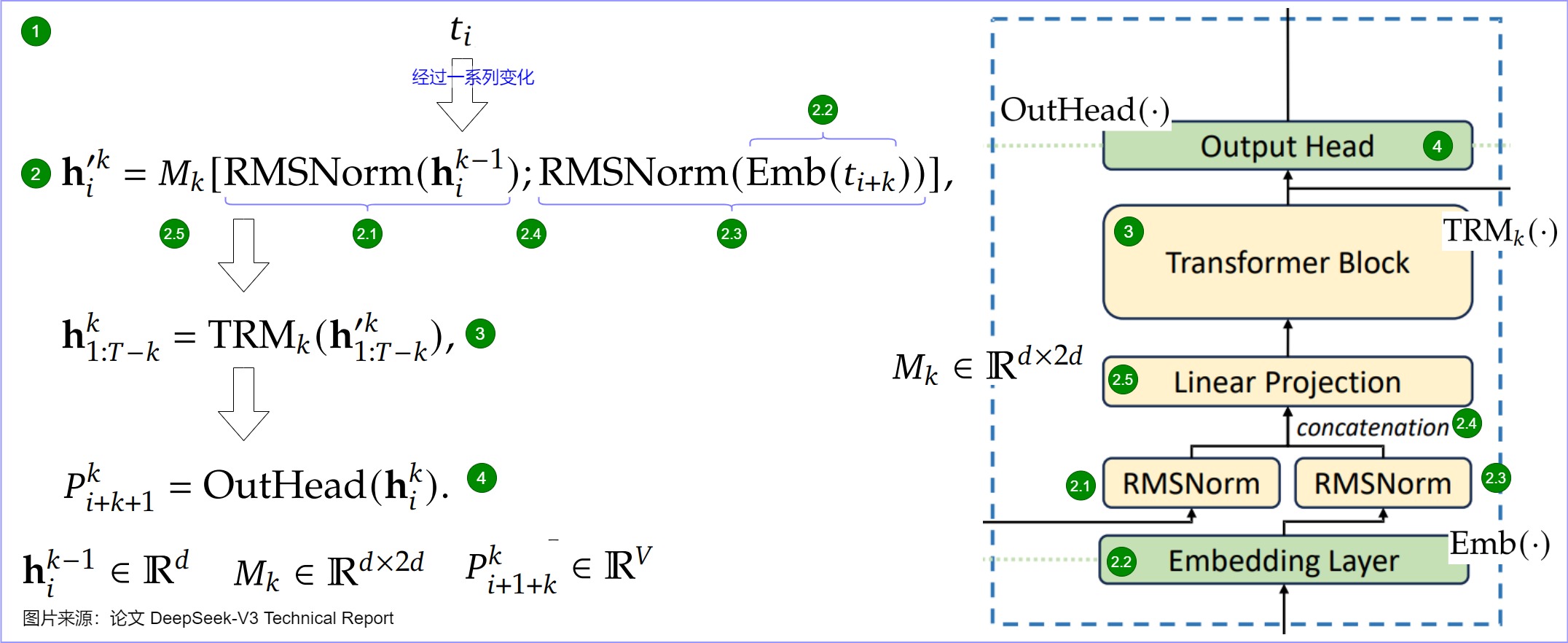
类 DeepSeekMultiTokenPredictorLayer 是 MTP Module 的实现。其公式和架构对应下图。
DeepSeekMultiTokenPredictorLayer 的代码如下。
class DeepSeekMultiTokenPredictorLayer(nn.Module):def __init__(self,config: PretrainedConfig,prefix: str,model_config: ModelConfig,cache_config: Optional[CacheConfig] = None,quant_config: Optional[QuantizationConfig] = None,) -> None:super().__init__()self.embed_tokens = VocabParallelEmbedding( # 图上标号2.2config.vocab_size,config.hidden_size,)self.enorm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps) # 图上标号2.1self.hnorm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps) # 图上标号2.3self.eh_proj = nn.Linear(config.hidden_size * 2, # 图上标号2.5config.hidden_size,bias=False)self.shared_head = SharedHead(config=config, quant_config=quant_config) # 图上标号4self.mtp_block = DeepseekV2DecoderLayer(config, prefix, model_config, # 图上标号30cache_config, quant_config)def forward(self,input_ids: torch.Tensor,positions: torch.Tensor,previous_hidden_states: torch.Tensor,inputs_embeds: Optional[torch.Tensor] = None,spec_step_index: int = 0,) -> torch.Tensor:if inputs_embeds is None:inputs_embeds = self.embed_tokens(input_ids)assert inputs_embeds is not None# masking inputs at position 0, as not needed by MTPinputs_embeds[positions == 0] = 0inputs_embeds = self.enorm(inputs_embeds)previous_hidden_states = self.hnorm(previous_hidden_states)hidden_states = self.eh_proj(torch.cat([inputs_embeds, previous_hidden_states], dim=-1))hidden_states, residual = self.mtp_block(positions=positions,hidden_states=hidden_states,residual=None)hidden_states = residual + hidden_statesreturn hidden_states
3.4.2 Output Head
类 SharedHead 是 Output Head 的实现。
class SharedHead(nn.Module):def __init__(self,config: PretrainedConfig,quant_config: Optional[QuantizationConfig] = None,) -> None:super().__init__()self.norm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)self.head = ParallelLMHead(config.vocab_size,config.hidden_size,quant_config=quant_config)def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:return self.norm(hidden_states)
具体使用是在 DeepSeekMultiTokenPredictor 类的 compute_logits() 函数中。
logits = self.logits_processor(mtp_layer.shared_head.head,mtp_layer.shared_head(hidden_states),sampling_metadata)
ParallelLMHead 代码如下。
class ParallelLMHead(VocabParallelEmbedding):"""Parallelized LM head.Output logits weight matrices used in the Sampler. The weight and biastensors are padded to make sure they are divisible by the number ofmodel parallel GPUs.Args:num_embeddings: vocabulary size.embedding_dim: size of hidden state.bias: whether to use bias.params_dtype: type of the parameters.org_num_embeddings: original vocabulary size (without LoRA).padding_size: padding size for the vocabulary."""def __init__(self,num_embeddings: int,embedding_dim: int,bias: bool = False,params_dtype: Optional[torch.dtype] = None,org_num_embeddings: Optional[int] = None,padding_size: int = DEFAULT_VOCAB_PADDING_SIZE,quant_config: Optional[QuantizationConfig] = None,prefix: str = ""):super().__init__(num_embeddings, embedding_dim, params_dtype,org_num_embeddings, padding_size, quant_config,prefix)self.quant_config = quant_configif bias:self.bias = Parameter(torch.empty(self.num_embeddings_per_partition,dtype=params_dtype))set_weight_attrs(self.bias, {"output_dim": 0,"weight_loader": self.weight_loader,})else:self.register_parameter("bias", None)def tie_weights(self, embed_tokens: VocabParallelEmbedding):"""Tie the weights with word embeddings."""# GGUF quantized embed_tokens.if self.quant_config and self.quant_config.get_name() == "gguf":return embed_tokenselse:self.weight = embed_tokens.weightreturn selfdef forward(self, input_):del input_raise RuntimeError("LMHead's weights should be used in the sampler.")
3.4.3 Transformer Block
DeepseekV2DecoderLayer 是 Transformer Block,对应上图的标号3。
class DeepseekV2DecoderLayer(nn.Module):def __init__(self,config: PretrainedConfig,prefix: str,model_config: ModelConfig,cache_config: Optional[CacheConfig] = None,quant_config: Optional[QuantizationConfig] = None,) -> None:super().__init__()self.hidden_size = config.hidden_sizerope_theta = getattr(config, "rope_theta", 10000)rope_scaling = getattr(config, "rope_scaling", None)max_position_embeddings = getattr(config, "max_position_embeddings",8192)# DecoderLayers are created with `make_layers` which passes the prefix# with the layer's index.layer_idx = int(prefix.split(sep='.')[-1])self.layer_idx = layer_idxif model_config.use_mla:attn_cls = DeepseekV2MLAAttentionelse:attn_cls = DeepseekV2Attentionself.self_attn = attn_cls(config=config,hidden_size=self.hidden_size,num_heads=config.num_attention_heads,qk_nope_head_dim=config.qk_nope_head_dim,qk_rope_head_dim=config.qk_rope_head_dim,v_head_dim=config.v_head_dim,q_lora_rank=config.q_lora_rankif hasattr(config, "q_lora_rank") else None,kv_lora_rank=config.kv_lora_rank,rope_theta=rope_theta,rope_scaling=rope_scaling,max_position_embeddings=max_position_embeddings,cache_config=cache_config,quant_config=quant_config,prefix=f"{prefix}.self_attn",)if (config.n_routed_experts is not Noneand layer_idx >= config.first_k_dense_replaceand layer_idx % config.moe_layer_freq == 0):self.mlp = DeepseekV2MoE(config=config,quant_config=quant_config,prefix=f"{prefix}.mlp",)else:self.mlp = DeepseekV2MLP(hidden_size=config.hidden_size,intermediate_size=config.intermediate_size,hidden_act=config.hidden_act,quant_config=quant_config,prefix=f"{prefix}.mlp",)self.input_layernorm = RMSNorm(config.hidden_size,eps=config.rms_norm_eps)self.post_attention_layernorm = RMSNorm(config.hidden_size,eps=config.rms_norm_eps)self.routed_scaling_factor = config.routed_scaling_factordef forward(self,positions: torch.Tensor,hidden_states: torch.Tensor,residual: Optional[torch.Tensor],) -> torch.Tensor:# Self Attentionif residual is None:residual = hidden_stateshidden_states = self.input_layernorm(hidden_states)else:hidden_states, residual = self.input_layernorm(hidden_states, residual)hidden_states = self.self_attn(positions=positions,hidden_states=hidden_states,)if hidden_states.dtype == torch.float16:# Fix FP16 overflow# We scale both hidden_states and residual before# rmsnorm, and rmsnorm result would not affect by scale.hidden_states *= 1. / self.routed_scaling_factorif self.layer_idx == 0:# The residual is shared by all layers, we only scale it on# first layer.residual *= 1. / self.routed_scaling_factor# Fully Connectedhidden_states, residual = self.post_attention_layernorm(hidden_states, residual)hidden_states = self.mlp(hidden_states)if isinstance(self.mlp,DeepseekV2MLP) and hidden_states.dtype == torch.float16:# Fix FP16 overflow# Scaling the DeepseekV2MLP output, it is the input of# input_layernorm of next decoder layer.# The scaling of DeepseekV2MOE output would be done in the forward# of DeepseekV2MOEhidden_states *= 1. / self.routed_scaling_factorreturn hidden_states, residual
3.4.4 MTP 功能
DeepSeekMultiTokenPredictor 可以理解为若干 MTP Module 的集合。
class DeepSeekMultiTokenPredictor(nn.Module):def __init__(self, *, vllm_config: VllmConfig, prefix: str = ""):super().__init__()config = vllm_config.model_config.hf_configself.mtp_start_layer_idx = config.num_hidden_layersself.num_mtp_layers = config.num_nextn_predict_layers# to map the exact layer index from weightsself.layers = torch.nn.ModuleDict({str(idx):DeepSeekMultiTokenPredictorLayer(config,f"{prefix}.layers.{idx}",model_config=vllm_config.model_config,cache_config=vllm_config.cache_config,quant_config=vllm_config.quant_config,)for idx in range(self.mtp_start_layer_idx,self.mtp_start_layer_idx + self.num_mtp_layers)})self.logits_processor = LogitsProcessor(config.vocab_size)def forward(self,input_ids: torch.Tensor,positions: torch.Tensor,previous_hidden_states: torch.Tensor,inputs_embeds: Optional[torch.Tensor] = None,spec_step_idx: int = 0,) -> torch.Tensor:current_step_idx = (spec_step_idx % self.num_mtp_layers)return self.layers[str(self.mtp_start_layer_idx + current_step_idx)](input_ids,positions,previous_hidden_states,inputs_embeds,current_step_idx,)def compute_logits(self,hidden_states: torch.Tensor,sampling_metadata: SamplingMetadata,spec_step_idx: int = 0,) -> torch.Tensor:current_step_idx = (spec_step_idx % self.num_mtp_layers)mtp_layer = self.layers[str(self.mtp_start_layer_idx +current_step_idx)]logits = self.logits_processor(mtp_layer.shared_head.head,mtp_layer.shared_head(hidden_states),sampling_metadata)return logits
DeepSeekMTP 则是把 DeepSeekMultiTokenPredictor 做了封装,对外呈现出 MTP 功能。
class DeepSeekMTP(nn.Module):def __init__(self, *, vllm_config: VllmConfig, prefix: str = ""):super().__init__()self.config = vllm_config.model_config.hf_configself.model = DeepSeekMultiTokenPredictor(vllm_config=vllm_config,prefix=maybe_prefix(prefix, "model"))def forward(self,input_ids: torch.Tensor,positions: torch.Tensor,previous_hidden_states: torch.Tensor,intermediate_tensors: Optional[IntermediateTensors] = None,inputs_embeds: Optional[torch.Tensor] = None,spec_step_idx: int = 0,) -> torch.Tensor:hidden_states = self.model(input_ids, positions,previous_hidden_states, inputs_embeds,spec_step_idx)return hidden_statesdef compute_logits(self,hidden_states: torch.Tensor,sampling_metadata: SamplingMetadata,spec_step_idx: int = 0,) -> Optional[torch.Tensor]:return self.model.compute_logits(hidden_states, sampling_metadata,spec_step_idx)def load_weights(self, weights: Iterable[Tuple[str,torch.Tensor]]) -> Set[str]:stacked_params_mapping = [("gate_up_proj", "gate_proj", 0),("gate_up_proj", "up_proj", 1),]expert_params_mapping = FusedMoE.make_expert_params_mapping(ckpt_gate_proj_name="gate_proj",ckpt_down_proj_name="down_proj",ckpt_up_proj_name="up_proj",num_experts=self.config.n_routed_experts)params_dict = dict(self.named_parameters())loaded_params: Set[str] = set()for name, loaded_weight in weights:if "rotary_emb.inv_freq" in name:continuespec_layer = get_spec_layer_idx_from_weight_name(self.config, name)if spec_layer is None:continuename = self._rewrite_spec_layer_name(spec_layer, name)for (param_name, weight_name, shard_id) in stacked_params_mapping:# Skip non-stacked layers and experts (experts handled below).if weight_name not in name:continue# We have mlp.experts[0].gate_proj in the checkpoint.# Since we handle the experts below in expert_params_mapping,# we need to skip here BEFORE we update the name, otherwise# name will be updated to mlp.experts[0].gate_up_proj, which# will then be updated below in expert_params_mapping# for mlp.experts[0].gate_gate_up_proj, which breaks load.if (("mlp.experts." in name) and name not in params_dict):continuename = name.replace(weight_name, param_name)# Skip loading extra bias for GPTQ models.if name.endswith(".bias") and name not in params_dict:continueparam = params_dict[name]weight_loader = param.weight_loaderweight_loader(param, loaded_weight, shard_id)breakelse:for mapping in expert_params_mapping:param_name, weight_name, expert_id, shard_id = mappingif weight_name not in name:continuename = name.replace(weight_name, param_name)param = params_dict[name]weight_loader = param.weight_loaderweight_loader(param,loaded_weight,name,shard_id=shard_id,expert_id=expert_id)breakelse:# Skip loading extra bias for GPTQ models.if name.endswith(".bias") and name not in params_dict:continueparam = params_dict[name]weight_loader = getattr(param, "weight_loader",default_weight_loader)weight_loader(param, loaded_weight)loaded_params.add(name)return loaded_paramsdef _rewrite_spec_layer_name(self, spec_layer: int, name: str) -> str:"""Rewrite the weight name to match the format of the original model.Add .mtp_block for modules in transformer layer block for spec layer"""spec_layer_weight_names = ["embed_tokens", "enorm", "hnorm", "eh_proj", "shared_head"]spec_layer_weight = Falsefor weight_name in spec_layer_weight_names:if weight_name in name:spec_layer_weight = Truebreakif not spec_layer_weight:# treat rest weights as weights for transformer layer blockname = name.replace(f"model.layers.{spec_layer}.",f"model.layers.{spec_layer}.mtp_block.")return name
3.5 训练
DeepSeek 模型中,多词元预测主要用于训练阶段,因此,会针对每个 MTP module 均应用交叉熵损失函数来计算每个MTP Module Head的损失,然后,所有 MTP module 的损失值会被整合为一个额外附加的训练目标。具体如下:
- t i t_{i} ti 表示第 i 个位置的真实词元(ground-truth token),而 p i k [ t i ] p^{k}_{i}[t_i] pik[ti] 则是第 k 个 MTP module 对 t i t_i ti的预测概率。
- 2+k:T+1是lable的范围。2+k 是起始下标。以下图为例。输入 t 1 t_1 t1 时候,Main Model 预测 t 2 t_2 t2,MTP Model 1 是预测 next next的token,即预测 t 3 t_3 t3,以此类推, MTP Model k 预测的第一个token是 𝑡 2 + 𝑘 𝑡_{2+𝑘} t2+k。T+1是结束下标。所有sequence样本默认在原序列上外增加一个eos token,所以token下标为序列长度 𝑇+1。
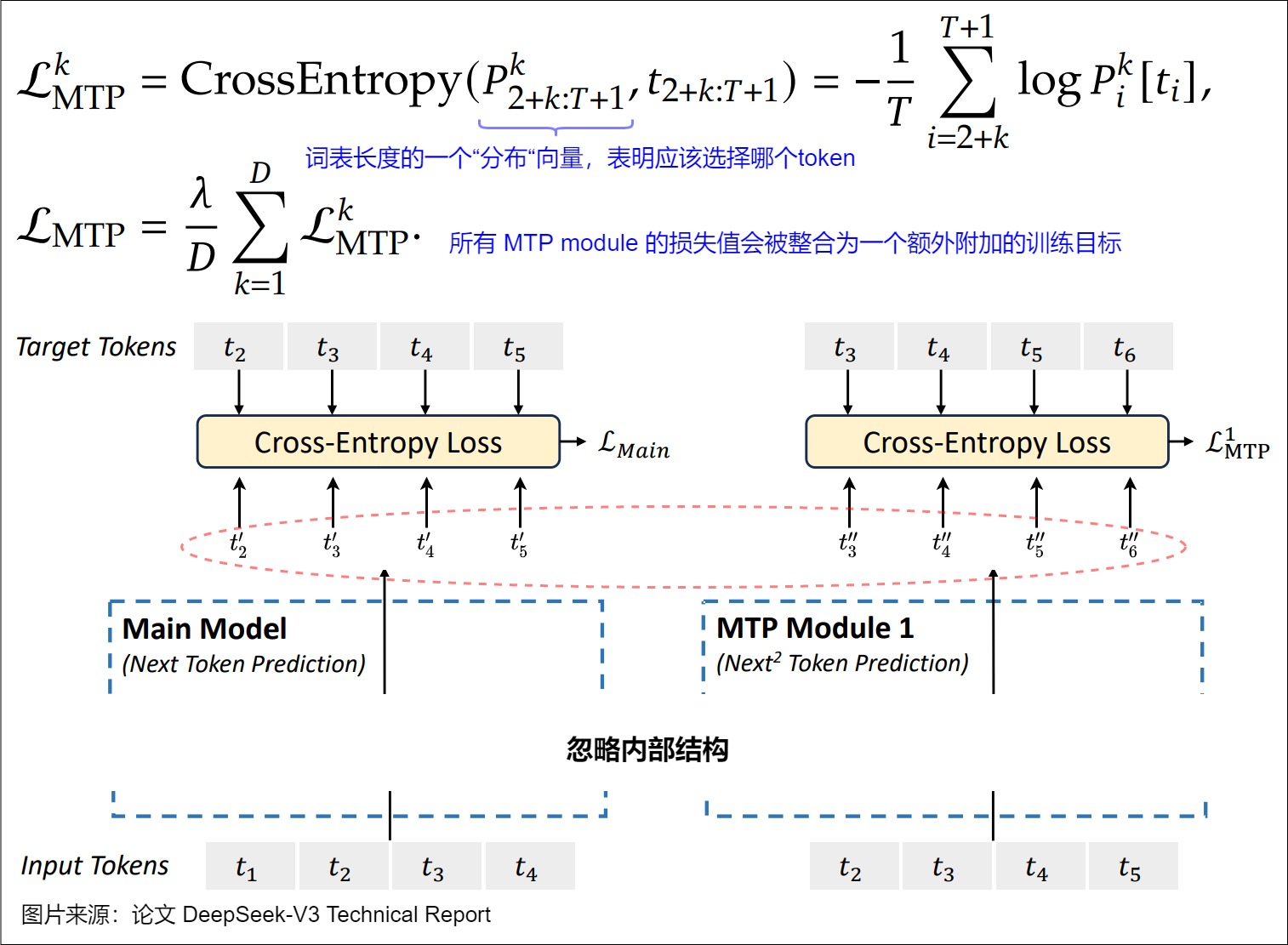
另外需要注意的是,MTP依然使用Teacher Forcing模式进行训练。正常应该是拿上一个状态的输出(也就是图中的 𝑡 2 ′ 𝑡'_2 t2′等)作为MTP Module 输入,但在序列建模训练中,直接用样本中的ground truth作为输入,效果会更好。因为如果拿预估的状态 𝑡 2 ′ 𝑡'_2 t2′作为输入,随着时间的推移,预估错误会持续累加,导致效果有损。但是,这里还是可以做对比来进行学习,当然这种对比只是近似对比或者逻辑意义上的对比。如果是标准的Teacher forcing,则在MTP Module 1预测 t 6 t_6 t6时,MTP Module输入中对预测 t 6 t_6 t6起作用的应该是 t 2 t_2 t2, t 3 t_3 t3, t 4 t_4 t4, t 5 t_5 t5。而在MTP中,实际上只是 t 5 t_5 t5这一个token起作用。
3.6 推理
MTP的设计主要是为了训练过程能加速收敛,更充分的使用训练样本。一次预测了 𝑛 个token,就相当于训练数据量翻了 𝑛 倍。最适合应用在模型急需收敛的预训练阶段。而在推理阶段,一般来说,DeepSeek V3推理可以有两种方法:
- 仅保留 main model 进行预测。直接把MTP Model头全部丢弃,模型变成了一个Predict Next Token 的 Main Model。然后部署模型做推理,这就跟正常LLM模型推理一样。没有什么加速效果。
- MTP 技术可与推测解码(speculative decoding)结合,以加快推理速度。保留MTP Model 做self-speculative decoding,这样充分使用多Head预测能力,提升推理加速性能。
0xEE 个人信息
★★★★★★关于生活和技术的思考★★★★★★
微信公众账号:罗西的思考
如果您想及时得到个人撰写文章的消息推送,或者想看看个人推荐的技术资料,敬请关注。

0xFF 参考
deepseek技术解读(2)-MTP(Multi-Token Prediction)的前世今生 姜富春
Better & Faster Large Language Models via Multi-token Prediction
Speculative Decoding 论文阅读合订本 灰瞳六分仪
【论文解读】EAGLE:在特征层进行自回归的投机采样框架 tomsheep
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
[读书笔记]Multi-token prediction 多词预测 迷途小书僮
从 EAGLE 到 MTP,图解 DeepSeek-V3 Multi-Token Prediction 实现思考 [边际效应] solrex
DeepSeek V3
Blockwise Parallel Decoding for Deep Autoregressive Models
Better & Faster Large Language Models via Multi-token Prediction
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
Deepseek-v3技术报告-图的逐步解析-3-不容易看懂的MTP-公式有拼写错误 迷途小书僮
[Deepseek v3技术报告学习] 3. Multi-Token Prediction Duludulu
DeepSeek-V2 MLA KV Cache 真的省了吗?(2) pika-jy
DeepSeek-V2 MLA KV Cache 真的省了吗? pika-jy
DeepSeek-V3 MTP 工程实现思考 极客博哥
投机推理番外一:特征层 speculative decoding CV算法与MLSys
投机解码——What makes for efficient speculative decoding? 密排六方橘子
LEARNING HARMONIZED REPRESENTATIONS FOR SPECULATIVE SAMPLING
CORAL: Learning Consistent Representations across Multi-step Training with Lighter Speculative Drafter
EAGLE-2: Faster Inference of Language Models with Dynamic Draft Trees
无损加速最高5x,EAGLE-2让RTX 3060的生成速度超过A100 机器之心Pro
「DeepSeek-V3 技术解析」:多词元预测技术(Multi-Token Prediction, MTP) Baihai IDP
小红书提出大模型推理加速算法 HASS 刷新 SOTA
LEARNING HARMONIZED REPRESENTATIONS FOR SPECULATIVE SAMPLING
为什么 DeepSeek-MTP 那么设计并且work 不熬夜的五星
Better & Faster Large Language Models via Multi-token Prediction
DeepSeek中的Multi-Token Prediction 长乐未央
理解DeepSeek中的Multi-Token Prediction (MTP) 扫帚的影子
【Deepseek技术原理】第二篇:史上最详细图解模型结构MTP和启发思考 罗辑
【论文解读】MTP:让LLM一次性预测多个token tomsheep
LLM推理加速(1):Multi-Token Prediction 悦大
[LLM 投机推理] 超越 Medusa 的投机采样—— EAGLE 1/2 论文解读 阿杰
DeepSeek-V3 MTP 工程实现思考 极客博哥