MapReduce 原理深度剖析:从任务执行到参数配置
在大数据处理领域,MapReduce 是一个经典且高效的分布式计算框架,它将复杂的大规模数据处理任务拆分成多个简单的子任务,在集群环境下并行执行。下面将通过详细拆解其核心组件 MapTask 和 ReduceTask 的执行流程,结合 Java 代码示例,带你深入理解 MapReduce 的运行原理。
一、MapReduce 原理简单版本概述
MapReduce 的核心思想可以概括为 “分而治之”。它将输入数据切分成多个数据块,每个数据块交给一个 MapTask 处理,MapTask 对数据进行转换和过滤,输出中间结果。这些中间结果经过 Shuffle 过程进行分区、排序和合并后,传递给 ReduceTask。ReduceTask 对相同 Key 的中间结果进行聚合处理,最终输出处理结果。
二、MapTask 执行阶段详解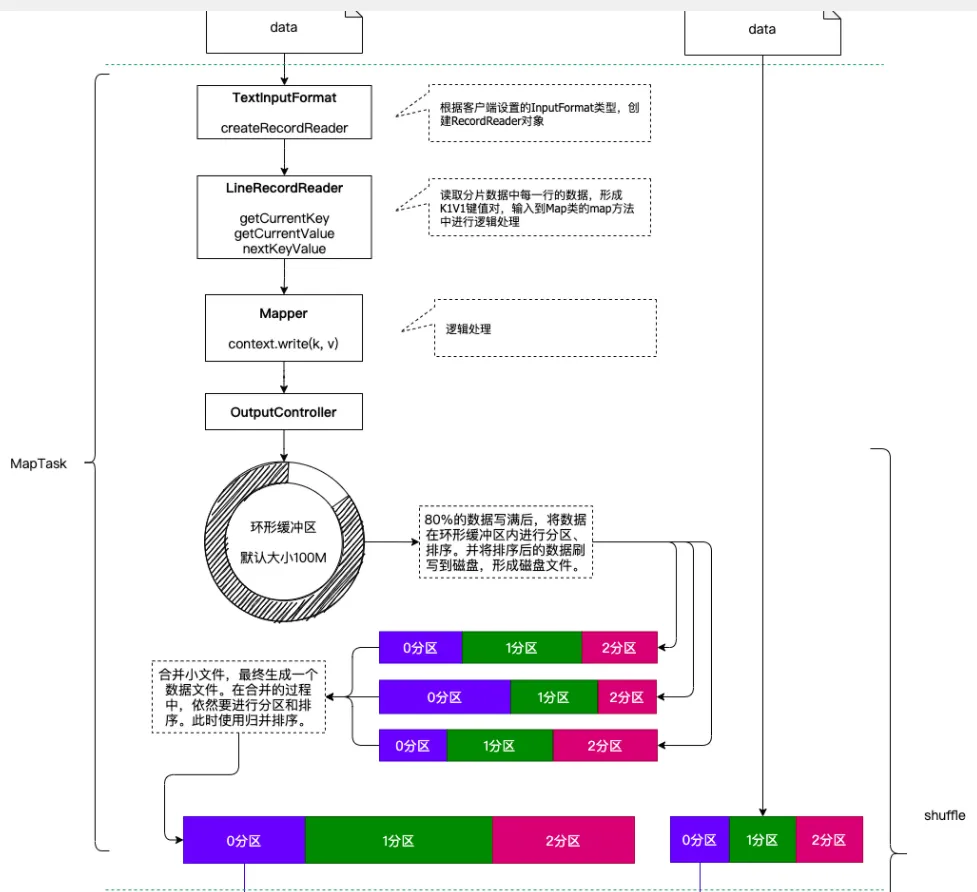
数据分片:MapReduce 会将输入数据按照一定的规则(如文件大小)切分成多个数据分片(InputSplit),每个 MapTask 负责处理一个或多个数据分片。
数据读取:MapTask 通过 InputFormat 组件从对应的 InputSplit 中读取数据,将其解析成 Key - Value 对形式。例如,在处理文本文件时,通常以每行文本的偏移量作为 Key,每行文本内容作为 Value。
Map 函数处理:MapTask 调用用户自定义的 map 函数,对读取到的每一个 Key - Value 对进行处理,输出新的 Key - Value 对作为中间结果。例如,在单词统计任务中,map 函数会将每行文本切分成单词,然后输出单词作为 Key,值为 1。
分区处理:MapTask 会根据分区规则(默认使用 HashPartitioner,根据 Key 的哈希值计算分区号),将 map 函数输出的中间结果分配到不同的分区中,每个分区的数据将发送到对应的 ReduceTask 进行处理。
排序与溢写:在每个分区内,MapTask 会对数据进行排序(快速排序算法),并将排序后的数据溢写到磁盘上的临时文件中。当内存缓冲区中的数据达到一定阈值(默认 80%)时,就会触发溢写操作。
文件合并:MapTask 将所有溢写的小文件合并成一个大文件,合并过程中同样会进行排序(归并排序),最终生成有序的分区数据。
三、ReduceTask 的执行流程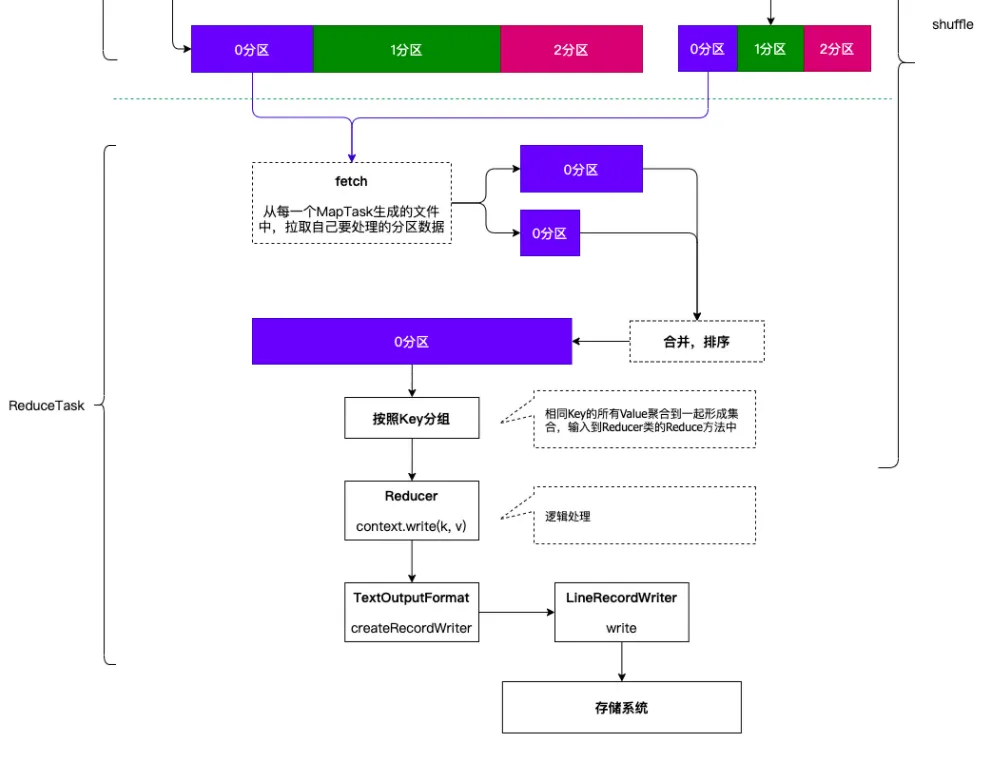
数据拉取:ReduceTask 根据分区信息,从各个 MapTask 所在节点拉取对应分区的数据。ReduceTask 有少量复制线程(默认 5 个,可通过mapreduce.reduce.shuffle.parallelcopies属性修改),能够并行获取数据,提高拉取效率 。
数据合并与排序:ReduceTask 将拉取到的来自多个 MapTask 的数据进行合并,并使用归并排序算法对合并后的数据进行排序,确保相同 Key 的数据相邻。这一步是外部排序,适用于数据量较大无法全部加载到内存的情况。
分组处理:按照 Key 相同的原则对排序后的数据进行分组,使得具有相同 Key 的 Value 值形成一个集合。
Reduce 函数调用:对于每一组数据,ReduceTask 调用用户自定义的 reduce 函数reduce(k, iterable<v> values, context),其中 k 是分组的 Key,values 是该 Key 对应的 Value 集合。在 reduce 函数中,用户可以对数据进行聚合、统计等操作。例如在单词统计中,对每个单词对应的 Value 集合进行求和,得到单词出现的总次数。
结果输出准备:处理后的数据交由 ReduceTask,ReduceTask 调用 FileOutputFormat 组件进行结果输出的准备工作。
结果写出:FileOutputFormat 组件中的 write 方法将最终处理结果写出到输出文件中。