PostgreSQL 序列(Sequence) 与 Oracle 序列对比
PostgreSQL 序列(Sequence) 与 Oracle 序列对比
PostgreSQL 和 Oracle 都提供了序列(Sequence)功能,但在实现细节和使用方式上存在一些重要差异。以下是两者的详细对比:
一 基本语法对比
1.1 创建序列
PostgreSQL:
CREATE [ { TEMPORARY | TEMP } | UNLOGGED ] SEQUENCE [ IF NOT EXISTS ] name[ AS data_type ][ INCREMENT [ BY ] increment ][ MINVALUE minvalue | NO MINVALUE ] [ MAXVALUE maxvalue | NO MAXVALUE ][ START [ WITH ] start ] [ CACHE cache ] [ [ NO ] CYCLE ][ OWNED BY { table_name.column_name | NONE } ]
Oracle:
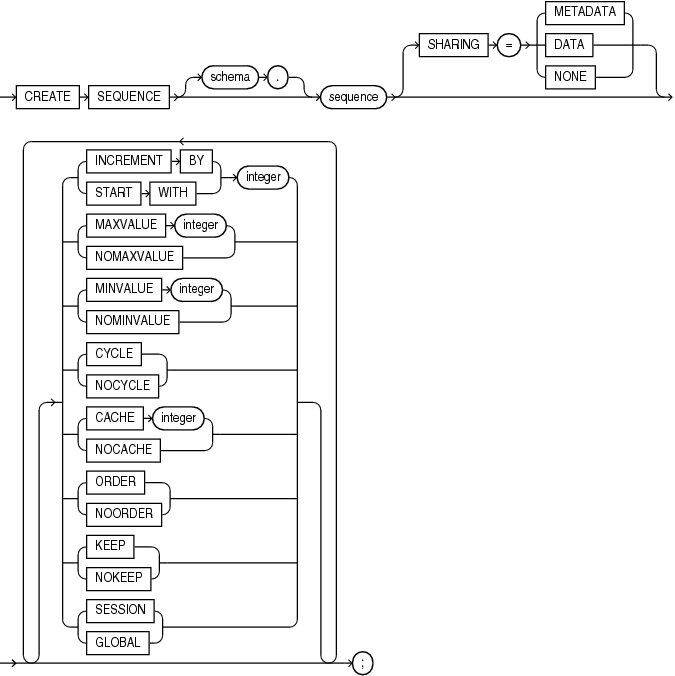
1.2 主要差异点
| 特性 | PostgreSQL | Oracle |
|---|---|---|
| 默认START值 | 1 | 1 |
| 默认INCREMENT | 1 | 1 |
| CACHE默认值 | 1 | 20 |
| OWNED BY选项 | 支持,可关联到表字段 | 不支持 |
| ORDER选项 | 不支持 | 支持,保证有序获取 |
二 功能特性对比
2.1 序列操作函数
PostgreSQL:
nextval('seq_name')- 获取下一个值currval('seq_name')- 获取当前值setval('seq_name', value)- 设置当前值
Oracle:
seq_name.NEXTVAL- 获取下一个值seq_name.CURRVAL- 获取当前值- 没有直接的
setval等价函数,需要通过ALTER SEQUENCE实现
2.2 事务行为
| 特性 | PostgreSQL | Oracle |
|---|---|---|
| 事务回滚 | nextval()调用不回滚 | nextval()调用不回滚 |
| 会话独立性 | 序列状态是全局的 | CURRVAL是会话特定的 |
| 并发访问 | 高并发下可能成为瓶颈 | 高并发性能更好(因默认CACHE=20) |
2.3 与表的集成
PostgreSQL:
- 使用
SERIAL/BIGSERIAL伪类型自动创建序列 - 显式关联:
DEFAULT nextval('seq_name') - 支持
OWNED BY将序列与表字段关联
Oracle:
- 使用
IDENTITY列(12c+)或触发器模拟自增 - 显式使用:
DEFAULT seq_name.NEXTVAL - 没有直接的序列-表关联机制
三 高级特性对比
3.1 缓存机制
PostgreSQL:
- 默认CACHE=1,可能在高并发下成为瓶颈
- 可设置较大CACHE值提高性能
- 服务器崩溃可能导致缓存值丢失(产生间隔)
Oracle:
- 默认CACHE=20,更适合高并发环境
- 同样存在服务器崩溃导致缓存值丢失的问题
- 提供NOORDER/ORDER选项控制顺序性
3.2 循环与限制
PostgreSQL:
- 支持CYCLE/NO CYCLE
- 可以设置MINVALUE和MAXVALUE
Oracle:
- 同样支持CYCLE/NOCYCLE
- 当达到MAXVALUE时,默认会报错(NOCYCLE)
3.3 分布式环境
PostgreSQL:
- 无内置的分布式序列支持
- 需要应用层解决(如使用UUID或时间戳组合)
Oracle:
- 提供RAC环境下的ORDER选项保证全局有序
- 仍有性能限制,不适合极高并发分布式场景
四 实际使用示例对比
4.1 基本使用
PostgreSQL:
CREATE SEQUENCE customer_id_seq START 1000;
INSERT INTO customers VALUES (nextval('customer_id_seq'), 'John Doe');
Oracle:
CREATE SEQUENCE customer_id_seq START WITH 1000;
INSERT INTO customers VALUES (customer_id_seq.NEXTVAL, 'John Doe');
4.2 表关联使用
PostgreSQL:
CREATE TABLE orders (id BIGSERIAL PRIMARY KEY, -- 自动创建序列details TEXT
);-- 或显式关联
CREATE SEQUENCE order_seq OWNED BY orders.id;
CREATE TABLE orders (id BIGINT DEFAULT nextval('order_seq') PRIMARY KEY,details TEXT
);
Oracle:
-- 12c+方式
CREATE TABLE orders (id NUMBER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,details VARCHAR2(4000)
);-- 传统方式
CREATE SEQUENCE order_seq;
CREATE TABLE orders (id NUMBER DEFAULT order_seq.NEXTVAL PRIMARY KEY,details VARCHAR2(4000)
);
五 性能与最佳实践
5.1 PostgreSQL 优化建议
- 适当增加CACHE值(如100-1000)减少序列争用
- 考虑使用IDENTITY列(PostgreSQL 10+)替代SERIAL
- 极高并发场景考虑其他ID生成方案(UUID等)
5.2 Oracle 优化建议
- 在RAC环境中使用ORDER选项需谨慎(影响性能)
- 合理设置CACHE大小平衡性能与序列间隔
- 考虑使用IDENTITY列(12c+)简化设计
六 总结
| 对比维度 | PostgreSQL优势 | Oracle优势 |
|---|---|---|
| 语法简洁性 | SERIAL类型更简单 | IDENTITY列(12c+)更标准化 |
| 功能丰富性 | OWNED BY关联有用 | ORDER选项适合RAC环境 |
| 默认性能 | 默认CACHE=1较保守 | 默认CACHE=20更适合高并发 |
| 分布式支持 | 无特别优化 | RAC环境下有ORDER选项支持 |
| 与表集成 | SERIAL和OWNED BY提供更好集成 | 12c+的IDENTITY列集成度好 |
两者序列功能都非常成熟,选择时主要考虑:
- 已有数据库平台
- 并发需求程度
- 是否需要分布式支持
- 开发团队的熟悉程度
PostgreSQL的序列更适合简单集成的场景,而Oracle在高并发和企业级环境中提供更多调优选项。
更多详细内容请查看官方文档:
https://docs.oracle.com/en/database/oracle/oracle-database/12.2/sqlrf/CREATE-SEQUENCE.html#SQLRF01314