第二章 MySql
目录
一、如何定位慢查询
二、那这个SQL语句执行很慢,如何分析呢?
三、了解过索引吗?什么是索引?
四、索引的底层数据结构了解过嘛 ?
四、红黑树是什么?
五、红黑树与普通二叉树的区别
六、红黑树的五大特性(规则)
七、红黑树的应用场景
八、B树(B-Tree)
九、B+树
十、B树和B+树的区别是什么呢?
十一、什么是聚簇索引什么是非聚簇索引?
十二、知道什么是回表查询吗?
十三、知道什么叫覆盖索引吗?
十四、mysql超大分页怎么处理?
十五、索引创建原则有哪些?
十六、什么情况下索引会失效?
十七、sql优化的经验?
十八、你平时对SQL语句做了哪些优化呢?
十九、事务的特性是什么?可以详细说一下吗?
二十、并发事务带来哪些问题?
二十一、怎么解决并发事务的问题?MYSQL的默认隔离级别?
二十二、undo log和redo log的区别是什么?
二十三、事务中的隔离性是如何保证的呢?(MVCC)
二十四、mysql主从同步原理?
二十五、你们项目用过MySQL的分库分表吗?
一、如何定位慢查询
参考回答:嗯,我们当时在做压力测试时发现有些接口响应时间非常慢,超过了2秒。因为我们的系统部署了运维监控系统Skywalking,在它的报表展示中可以看到哪个接口慢,并且能分析出接口中哪部分耗时较多,包括具体的SQL执行时间,这样就能定位到出现问题的SQL。
如果没有这种监控系统,MySQL本身也提供了慢查询日志功能。可以在MySQL的系统配置文件中开启慢查询日志,并设置SQL执行时间超过多少就记录到日志文件,比如我们之前项目设置的是2秒,超过这个时间的SQL就会记录在日志文件中,我们就可以在那里找到执行慢的SQL。
方案一:开源工具
-
调试工具:Arthas
-
运维工具:Prometheus、Skywalking
方案二:MySQL自带慢日志
慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认10秒)的所有SQL语句的日志。
如果要开启慢查询日志,需要在MySQL的配置文件(/etc/my.cnf)中配置如下信息:
#开启MVSQL慢日志查询开关 slow query log=1 #设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志 long query time=2
配置完毕之后,通过以下指令重新启动MySQL服务器进行测试,查看日志文件中记录的信息/var/lib/mysql/localhost-slow.log.
# 使用 systemd (较新系统如 CentOS 7+, Ubuntu 16.04+): sudo systemctl restart mysqld # 或 sudo systemctl restart mysql # 使用 service (较旧系统): sudo service mysql restart # 或 sudo service mysqld restart

可以在不重启的情况下动态设置:
-- 开启慢查询日志 SET GLOBAL slow_query_log = 'ON';
-- 设置慢查询阈值(单位:秒) SET GLOBAL long_query_time = 2;
-- 设置慢查询日志文件路径 SET GLOBAL slow_query_log_file = '/var/log/mysql/mysql-slow.log';
!!请注意,动态设置会在服务重启后失效,而配置文件中的设置会永久生效。
二、那这个SQL语句执行很慢,如何分析呢?
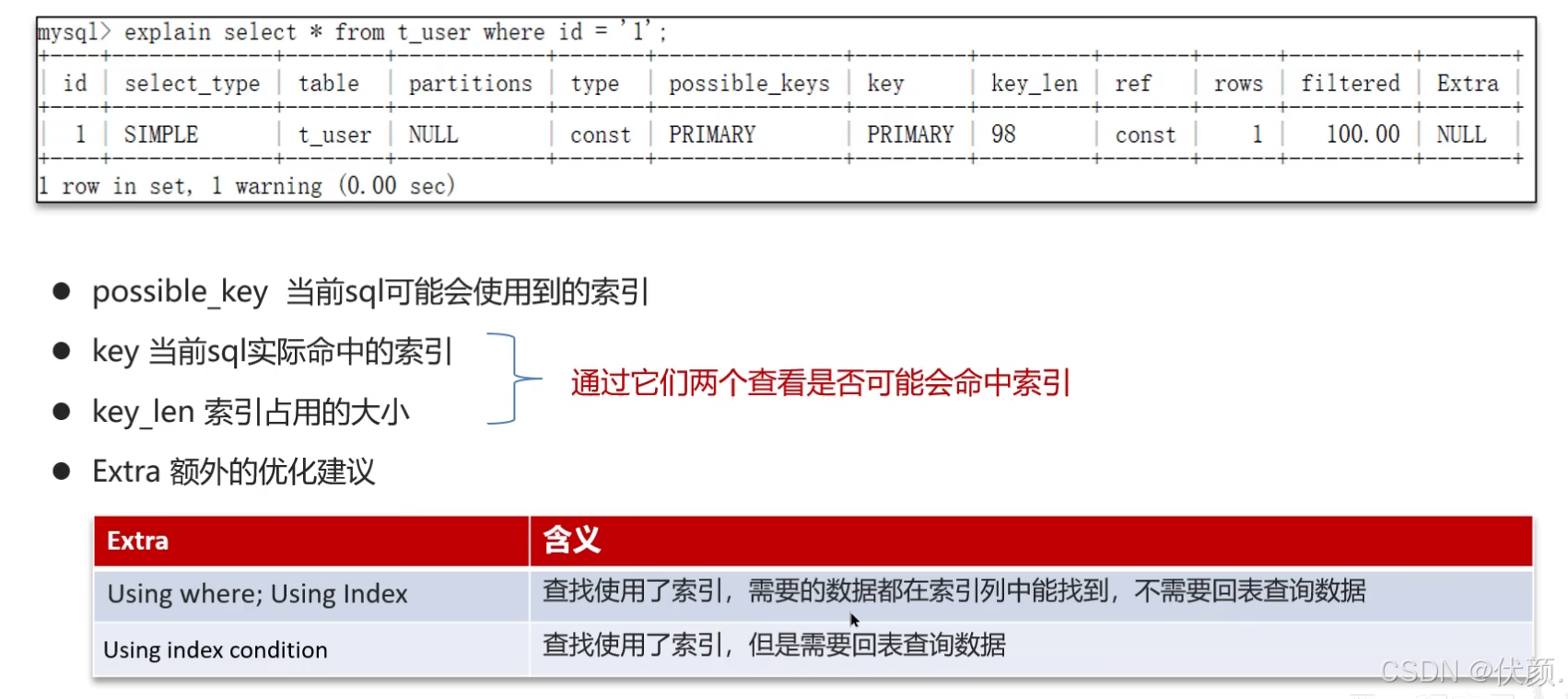
如果一条SQL执行很慢,我们通常会使用MySQL的
EXPLAIN命令来分析这条SQL的执行情况。
通过
key和key_len可以检查是否命中了索引,如果已经添加了索引,也可以判断索引是否有效。通过
type字段可以查看SQL是否有优化空间,比如是否存在全索引扫描或全表扫描。通过
extra建议可以判断是否出现回表情况,如果出现,可以尝试添加索引或修改返回字段来优化。
可以采用EXPLAIN 或者 DESC命令获取 MySQL 如何执行 SELECT 语句的信息


三、了解过索引吗?什么是索引?
-
索引(index)是帮助MySQL高效获取数据的数据结构(有序)
-
提高数据检索的效率,降低数据库的IO成本(不需要全表扫描)
-
通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗
嗯,索引在项目中非常常见,它是一种帮助MySQL高效获取数据的数据结构,主要用来提高数据检索效率,降低数据库的I/O成本。同时,索引列可以对数据进行排序,降低数据排序的成本,也能减少CPU的消耗。
四、索引的底层数据结构了解过嘛 ?
-
MySQL的InnoDB引擎采用的B+树的数据结构来存储索引
-
阶数更多,路径更短
-
磁盘读写代价B+树更低,非叶子节点只存储指针,叶子阶段存储数据
-
B+树便于扫库和区间查询,叶子节点是一个双向链表
MySQL的默认存储引擎InnoDB使用的是B+树作为索引的存储结构。选择B+树的原因包括:节点可以有更多子节点,路径更短;磁盘读写代价更低,非叶子节点只存储键值和指针,叶子节点存储数据;B+树适合范围查询和扫描,因为叶子节点形成了一个双向链表。
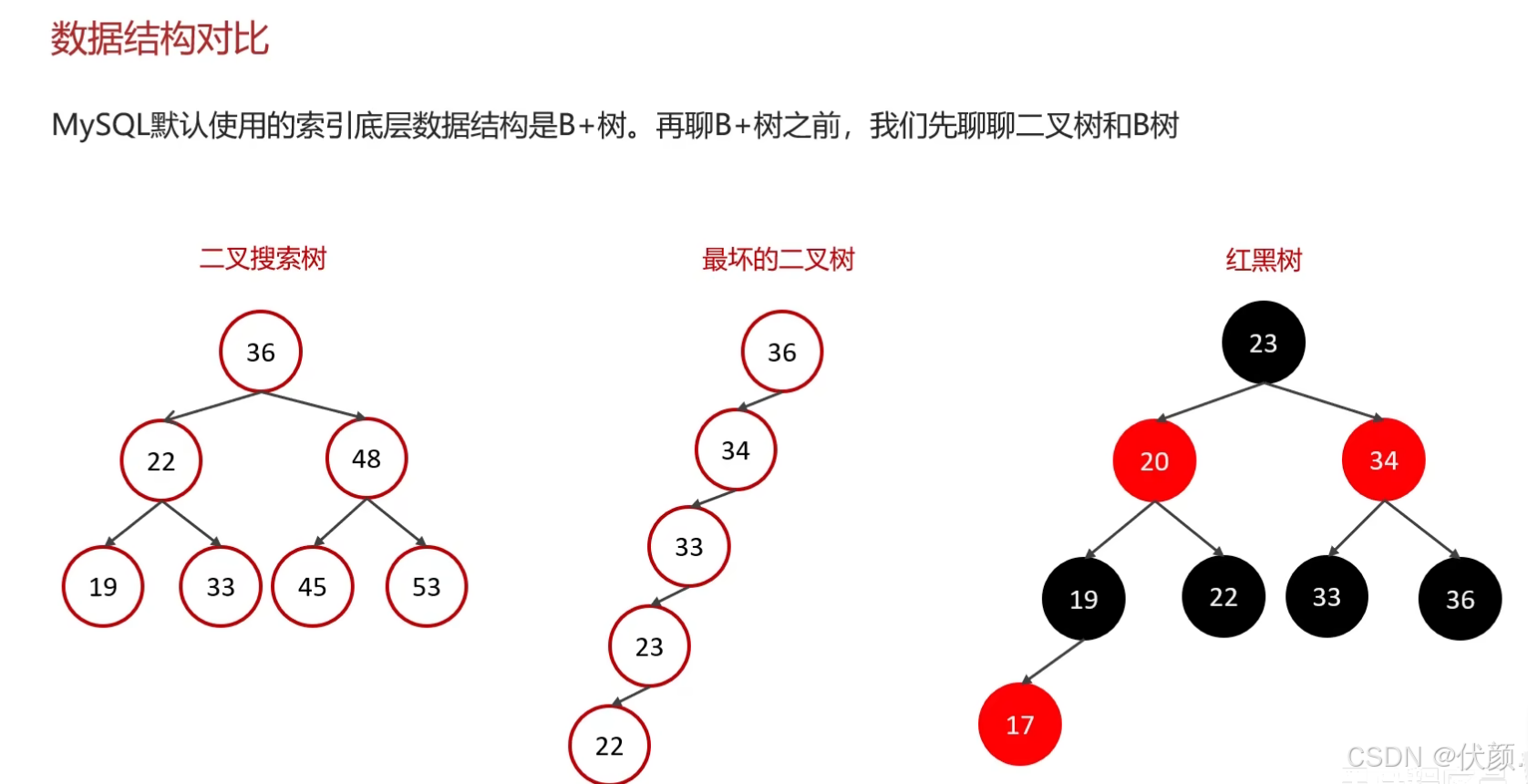
四、红黑树是什么?
红黑树是一种自平衡的二叉查找树,它通过在普通二叉查找树的基础上,增加额外的颜色属性(红或黑)和一系列平衡规则,确保树始终保持相对平衡,从而保证查找、插入和删除操作的最坏时间复杂度为O(log n)。
五、红黑树与普通二叉树的区别
| 特性 | 普通二叉查找树 | 红黑树 |
|---|---|---|
| 平衡性 | 可能退化为链表(O(n)) | 始终保持近似平衡(O(log n)) |
| 节点属性 | 只有键值 | 键值+颜色(红/黑) |
| 插入/删除 | 可能导致不平衡 | 通过旋转和变色保持平衡 |
| 查找效率 | 不稳定 | 稳定高效 |

六、红黑树的五大特性(规则)
-
节点非红即黑:每个节点要么是红色,要么是黑色
-
根节点为黑:根节点必须是黑色
-
红色节点的子节点必须为黑:不能有两个连续的红色节点
-
黑高相同:从任一节点到其每个叶子节点的路径上,黑色节点的数量相同
-
叶子节点(NIL)为黑:所有叶子节点(空节点)被视为黑色
七、红黑树的应用场景
红黑树广泛应用于需要高效查找、插入和删除操作的场景:
-
C++ STL中的
map和set(通常用红黑树实现) -
Java中的
TreeMap和TreeSet -
Linux内核的进程调度
-
文件系统的目录结构
-
数据库索引(如MySQL的某些索引类型)
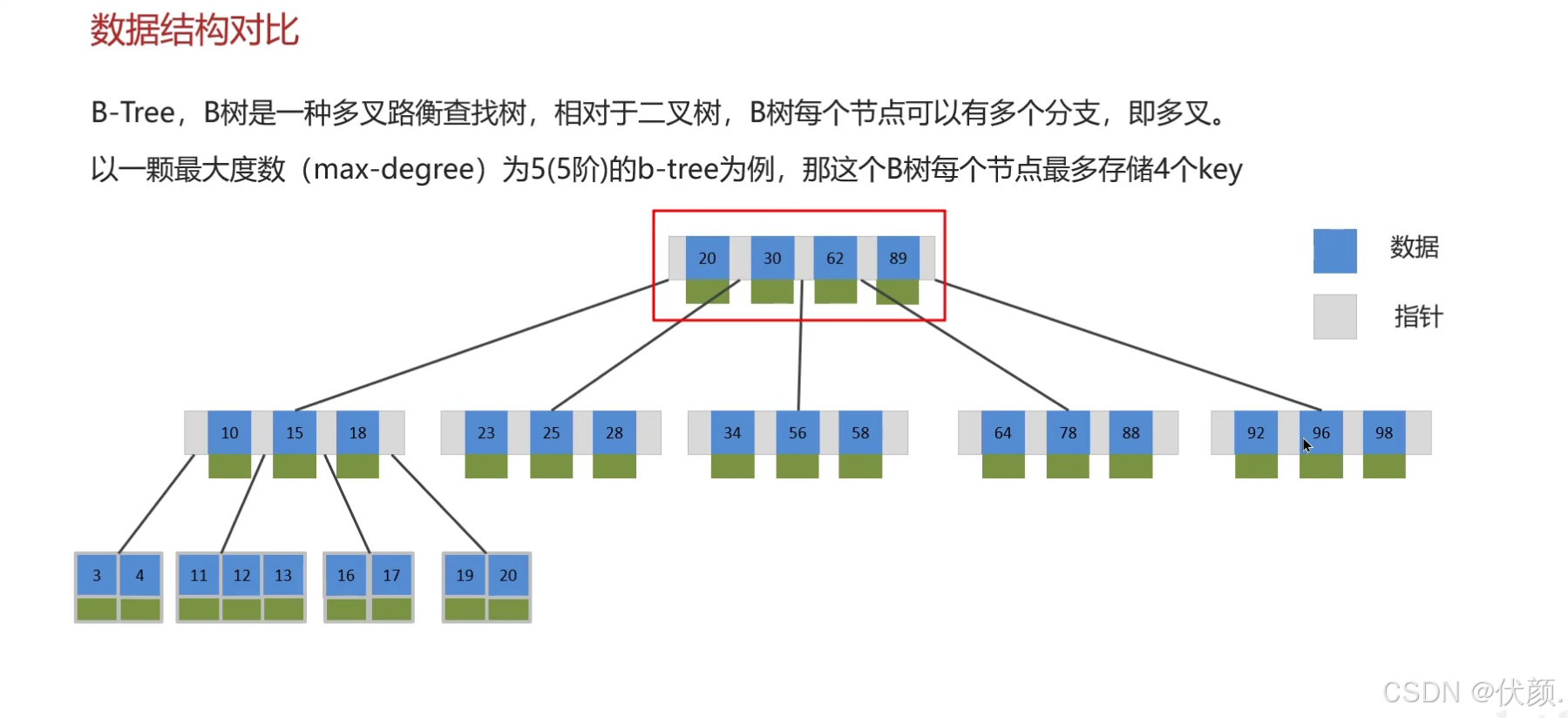
八、B树(B-Tree)
B树是一种多路平衡查找树,设计用于减少磁盘I/O操作,特别适合在存储系统(如数据库和文件系统)中组织大量数据。
B树特性:
-
多路分支:每个节点可以有多个子节点(通常远多于2个)
-
平衡性:所有叶子节点位于同一层次
-
节点存储:每个非叶子节点存储键和指针(不存储实际数据或存储部分数据)
-
阶数(m):定义B树的"宽度",m阶B树表示:
-
阶数
m表示B树中单个节点最多能拥有的子节点数量 -
每个节点最多包含
m-1个key -
根节点至少有2个子节点
-
每个非叶子节点(除根节点)至少有
⌈m/2⌉个子节点
-
-
一棵m阶的B树具有以下性质:
-
每个节点最多有m个子节点
-
除根节点外,每个非叶子节点至少有⌈m/2⌉个子节点
-
根节点至少有2个子节点(除非它是叶子节点)
-
所有叶子节点都位于同一层
-
非叶子节点若有k个子节点,则包含k-1个键
-
-
B树的操作
-
查找操作
从根节点开始,通过比较键值决定向下搜索的路径,直到找到目标键或到达叶子节点。
-
插入操作
-
找到合适的叶子节点插入
-
如果节点未满,直接插入
-
如果节点已满,进行分裂:
-
将中间键提升到父节点
-
分裂剩余键到两个新节点
-
递归检查父节点是否需要分裂
-
-
删除操作
-
如果要删除的键在叶子节点,直接删除
-
如果在非叶子节点,用后继键替换并删除后继键
-
删除后如果节点键数少于最小值:
-
尝试从兄弟节点借一个键
-
如果兄弟节点也不足,与兄弟节点合并
-
7.B树的优缺点
优点:
-
保持数据有序
-
自动平衡
-
适合磁盘存储(减少I/O次数)
-
支持高效的范围查询
缺点:
-
非叶子节点也存储数据,可能导致节点容纳的键减少
-
范围查询效率不如B+树
九、B+树
B+树是B树的变种,在数据库系统中更为常用。它与B树的主要区别在于数据只存储在叶子节点,且叶子节点通过指针【双向指针】连接形成链表。

1.B+树的特性
一棵m阶的B+树具有以下性质:
-
每个节点最多有m个子节点
-
除根节点外,每个非叶子节点至少有⌈m/2⌉个子节点
-
根节点至少有2个子节点(除非它是叶子节点)
-
所有叶子节点都位于同一层
-
非叶子节点只存储键,不存储数据
-
叶子节点存储所有键和数据,并通过指针连接形成链表
2.B+树的操作
-
查找操作
-
单值查找:类似B树,但只在叶子节点找到数据
-
范围查找:在叶子节点找到起始键后,沿链表遍历
-
-
插入操作
类似B树,但分裂时:
-
非叶子节点分裂时中间键会复制到父节点
-
叶子节点分裂时中间键会出现在右节点中
-
删除操作
类似B树,但需要考虑叶子节点的链表维护
-
B+树的优缺点
优点:
-
更高的扇出(非叶子节点只存键,可容纳更多子节点)
-
更稳定的查询性能(所有查询都要到叶子节点)
-
更高效的范围查询(叶子节点链表)
-
更适合磁盘存储系统
缺点:
-
非叶子节点不存储数据,可能需要更多次查找才能访问数据
-
实现比B树稍复杂
十、B树和B+树的区别是什么呢?
B树和B+树的主要区别在于:
-
B树的非叶子节点和叶子节点都存放数据,而B+树的所有数据只出现在叶子节点,这使得B+树在查询时效率更稳定。
-
B+树在进行范围查询时效率更高,因为所有数据都在叶子节点,并且叶子节点之间形成了双向链表。
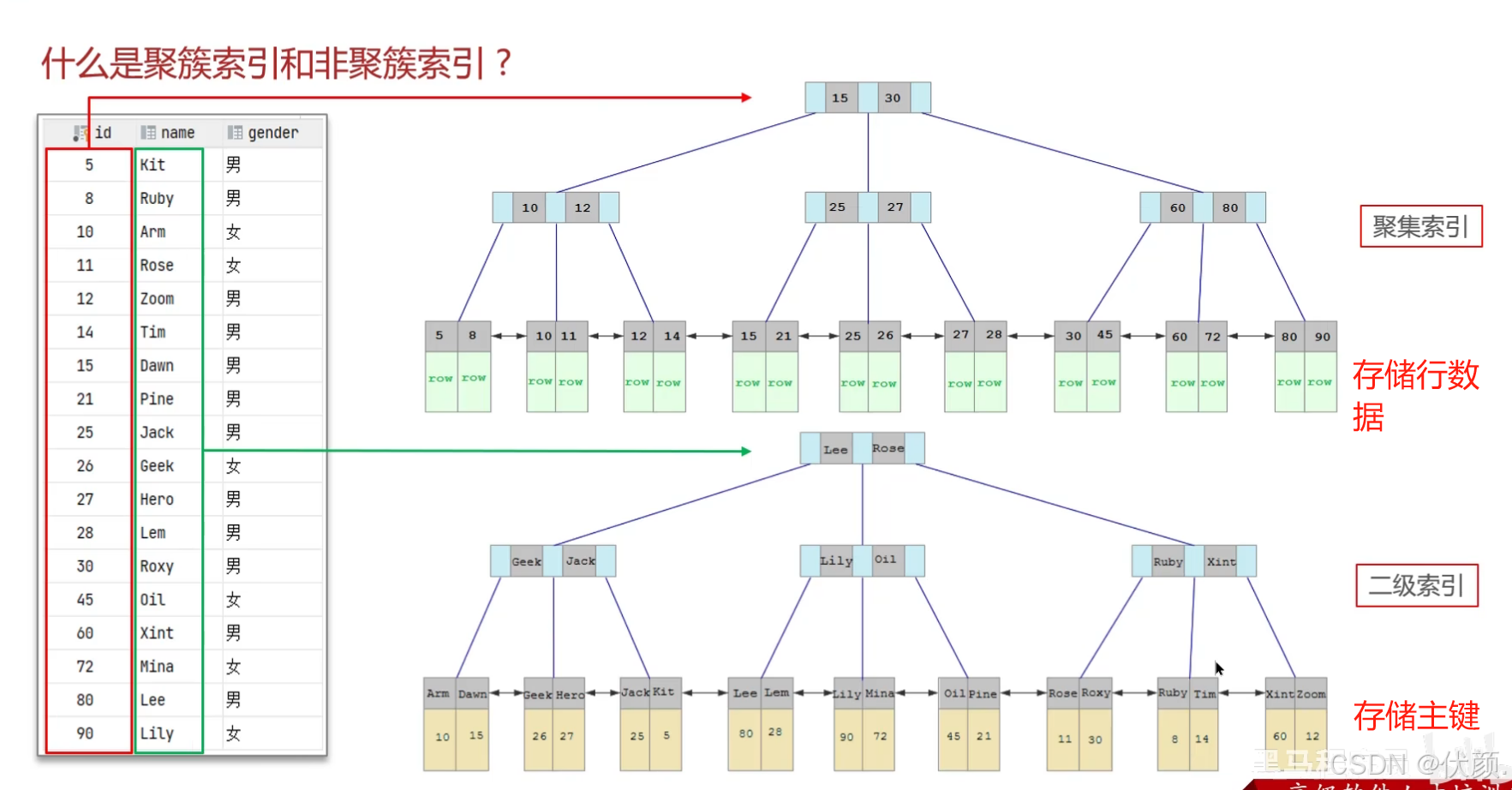
十一、什么是聚簇索引什么是非聚簇索引?
-
聚簇索引:必须有。是指数据与索引放在一起,B+树的叶子节点保存了整行数据,通常只有一个聚簇索引,一般是由主键构成。
-
非聚簇索引(二级索引):是数据与索引分开存储,B+树的叶子节点保存的是主键值,可以有多个非聚簇索引,通常我们自定义的索引都是非聚簇索引。
聚集索引选取规则:
-
如果存在主键,主键索引就是聚集索引。
-
如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
-
如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引。
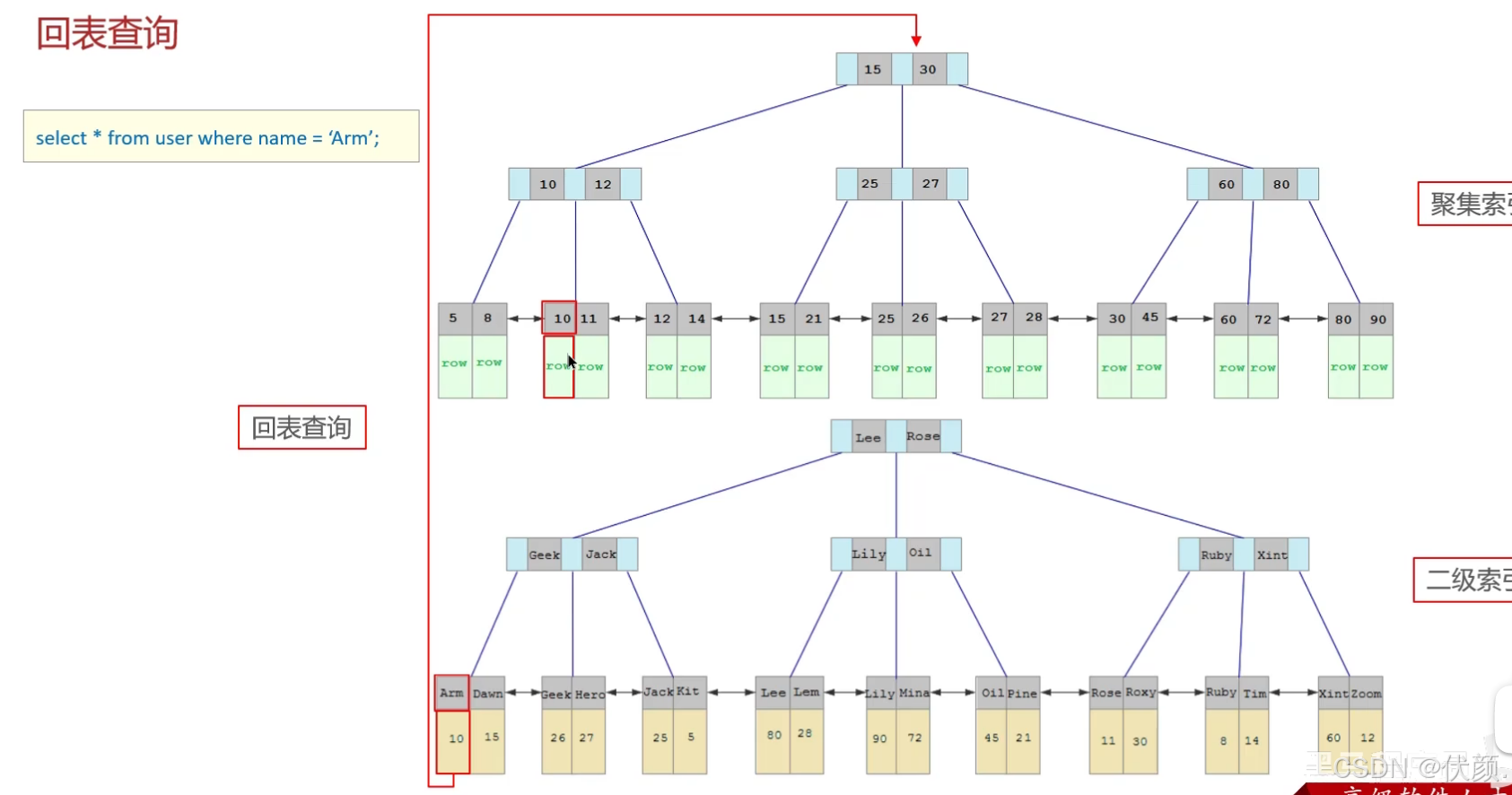
十二、知道什么是回表查询吗?
-
回表查询是指通过二级索引找到对应的主键值
-
然后再通过主键值查询聚簇索引中对应的整行数据的过程
十三、知道什么叫覆盖索引吗?
-
覆盖索引是指在SELECT查询中,返回的列全部能在索引中找到,避免了回表查询,提高了性能。
-
使用覆盖索引可以减少对主键索引的查询次数,提高查询效率。
覆盖索引是指查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到
使用id查询,直接走聚集索引查询,一次索引扫描,直接返回数据,性能高。
如果返回的列中没有创建索引,有可能会触发回表查询,尽量避免使用select*

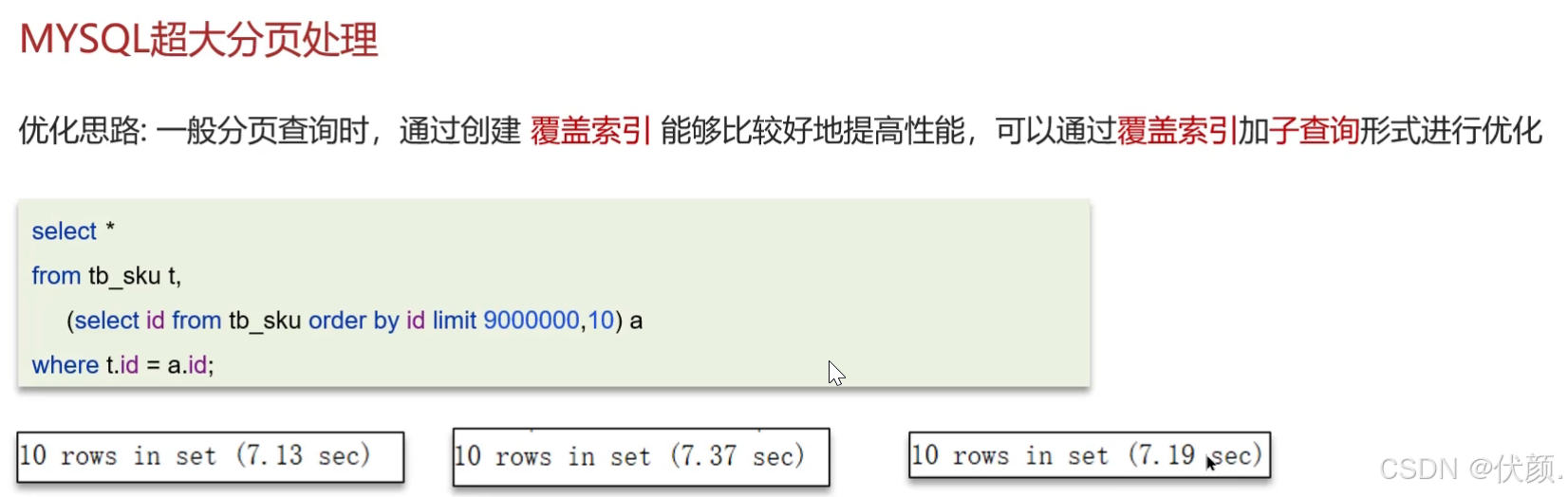
十四、mysql超大分页怎么处理?
可以用覆盖索引处理
-
问题:在数据量比较大时,limit分页查询,需要对数据进行排序,效率低
-
解决方案:覆盖索引+子查询
超大分页通常发生在数据量大的情况下,使用
LIMIT分页查询且需要排序时效率较低。可以通过覆盖索引和子查询来解决。首先查询数据的ID字段进行分页,然后根据ID列表用子查询来过滤只查询这些ID的数据,因为查询ID时使用的是覆盖索引,所以效率可以提升。

十五、索引创建原则有哪些?
-
针对于数据量较大,且查询比较频繁的表建立索引。单表超过10万数据(增加用户体验)
-
针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
-
尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。【值不同】
-
如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。
-
尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高査询效率。
-
要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
-
如果索引列不能存储NUL值,请在创建表时使用NOTNUL约束它,当优化器知道每列是否包含NUL值时,它可以更好地确定哪个索引最有效地用于查询。
数据量较大,且查询比较频繁的表【重要】
常作为查询条件、排序、分组的字段【重要】
字段内容区分度高
内容较长,使用前缀索引
尽量联合索引【重要】
要控制索引的数量【重要】
如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它
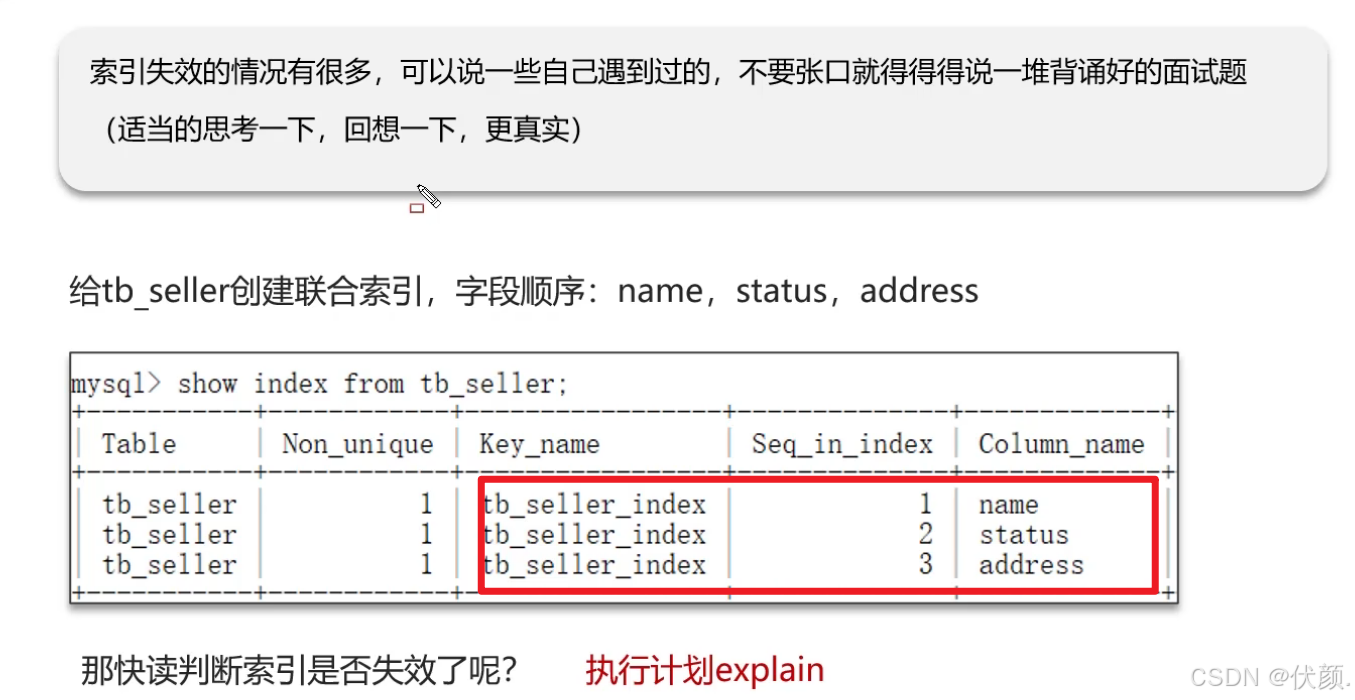
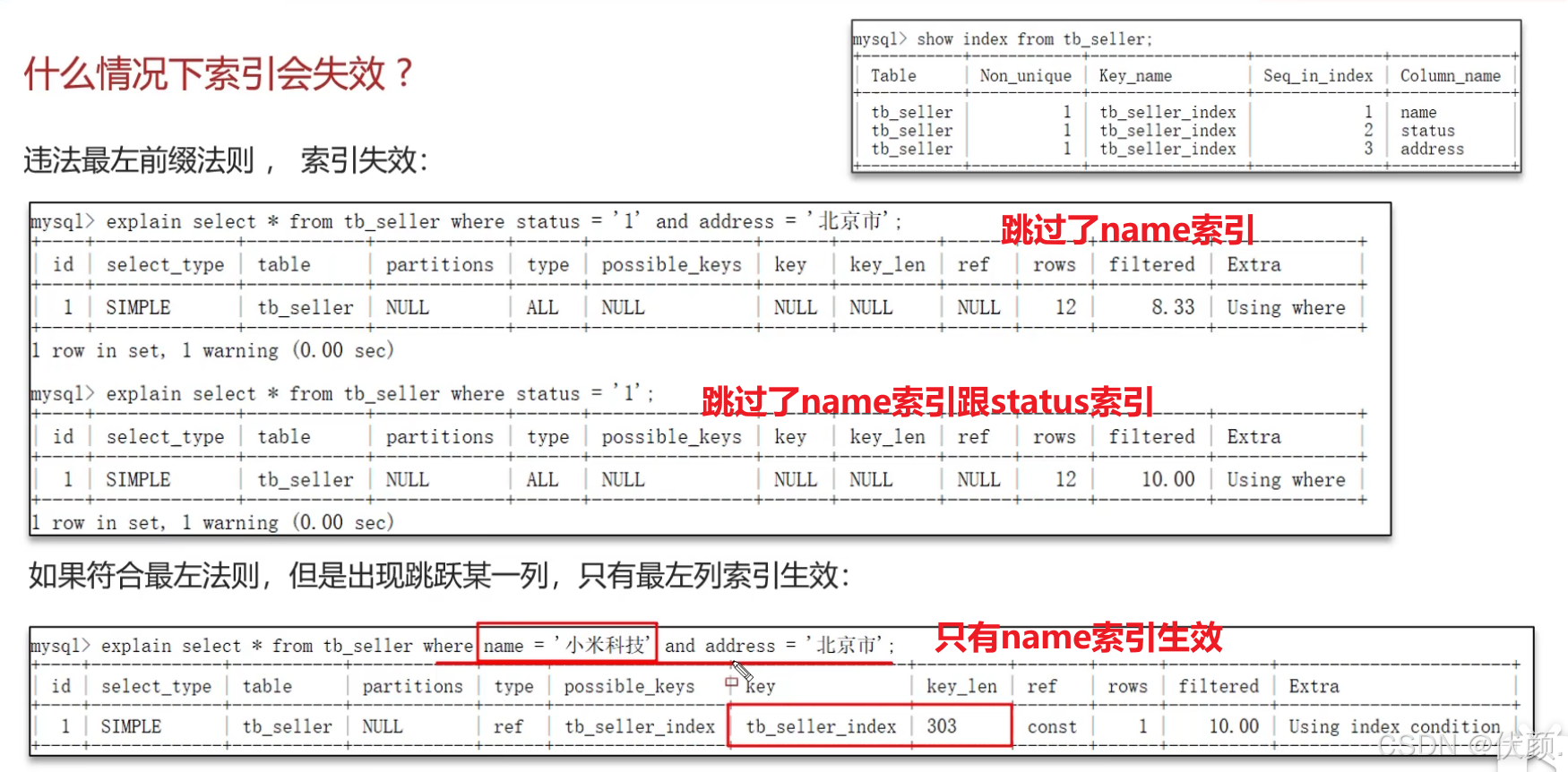
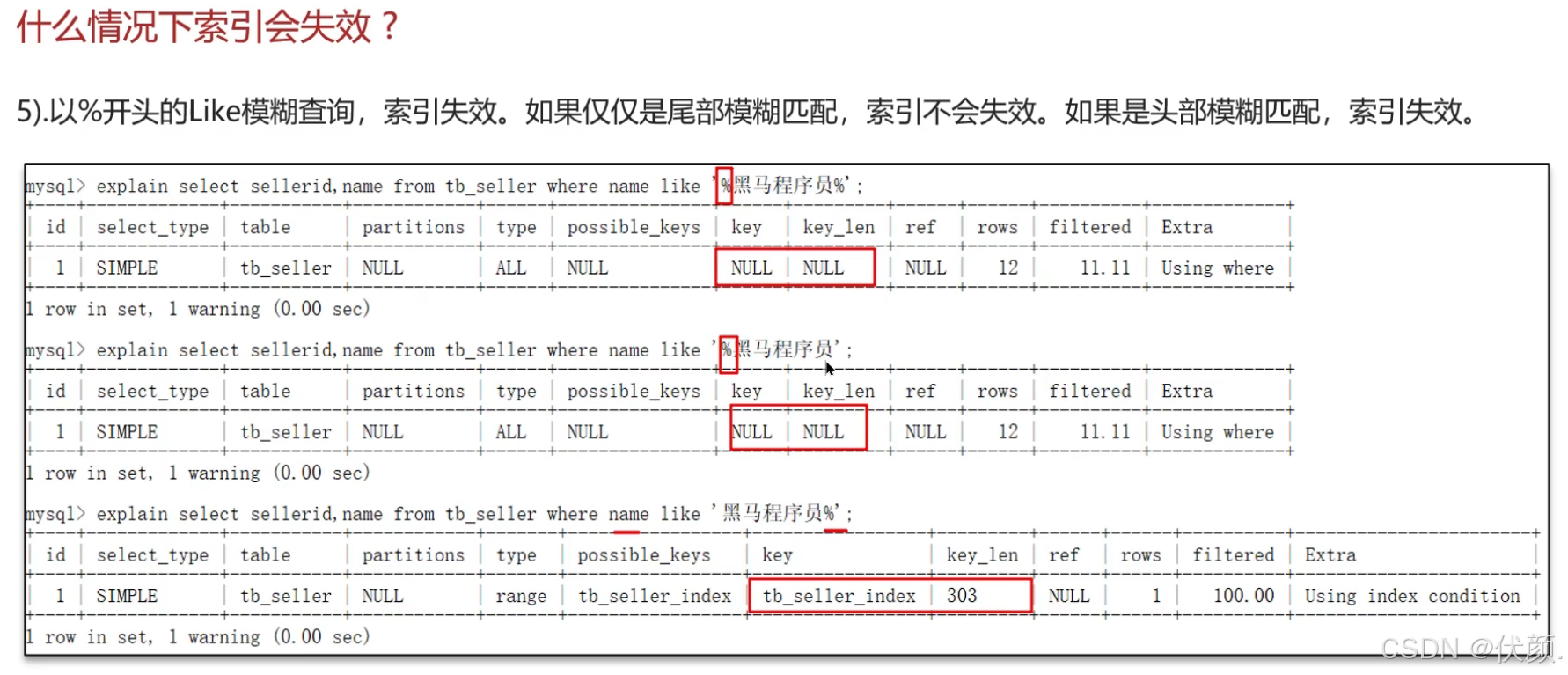
十六、什么情况下索引会失效?
-
没有遵循最左匹配原则。
-
使用了模糊查询且
%号在前面。【只有尾部模糊可以命中索引】 -
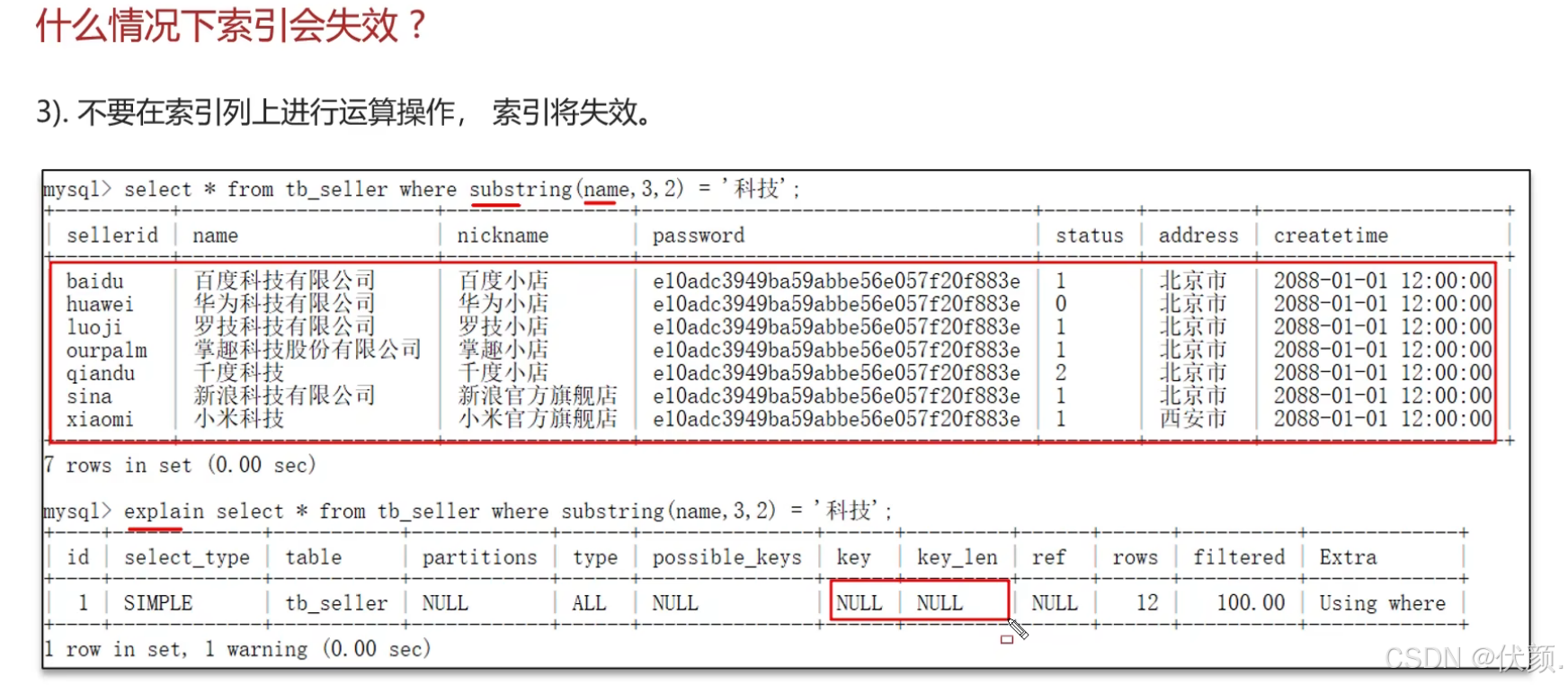
在索引字段上进行了运算或类型转换。
-
使用了复合索引但在中间使用了范围查询,导致右边的条件索引失效。
-
字符串不加单引号。【类型转换】



十七、sql优化的经验?
SQL优化可以从以下几个方面考虑:
-
表设计优化。建表时选择合适的字段类型。
-
创建表时,我们主要参考《阿里开发手册(嵩山版/终极版)》开发手册【java开发手册(黄山版)】,选择字段类型时结合字段内容,比如数值类型选择
TINYINT、INT、BIGINT等,字符串类型选择CHAR、VARCHAR或TEXT。
-
-
索引优化/使用索引,遵循创建索引的原则。
-
在使用索引时,我们遵循索引创建原则,确保索引字段是查询频繁的,使用复合索引覆盖SQL返回值,避免在索引字段上进行运算或类型转换,以及控制索引数量。
-
-
SQL语句优化。编写高效的SQL语句,比如避免使用
SELECT *,尽量使用UNION ALL代替UNION,以及在表关联时使用INNER JOIN。 -
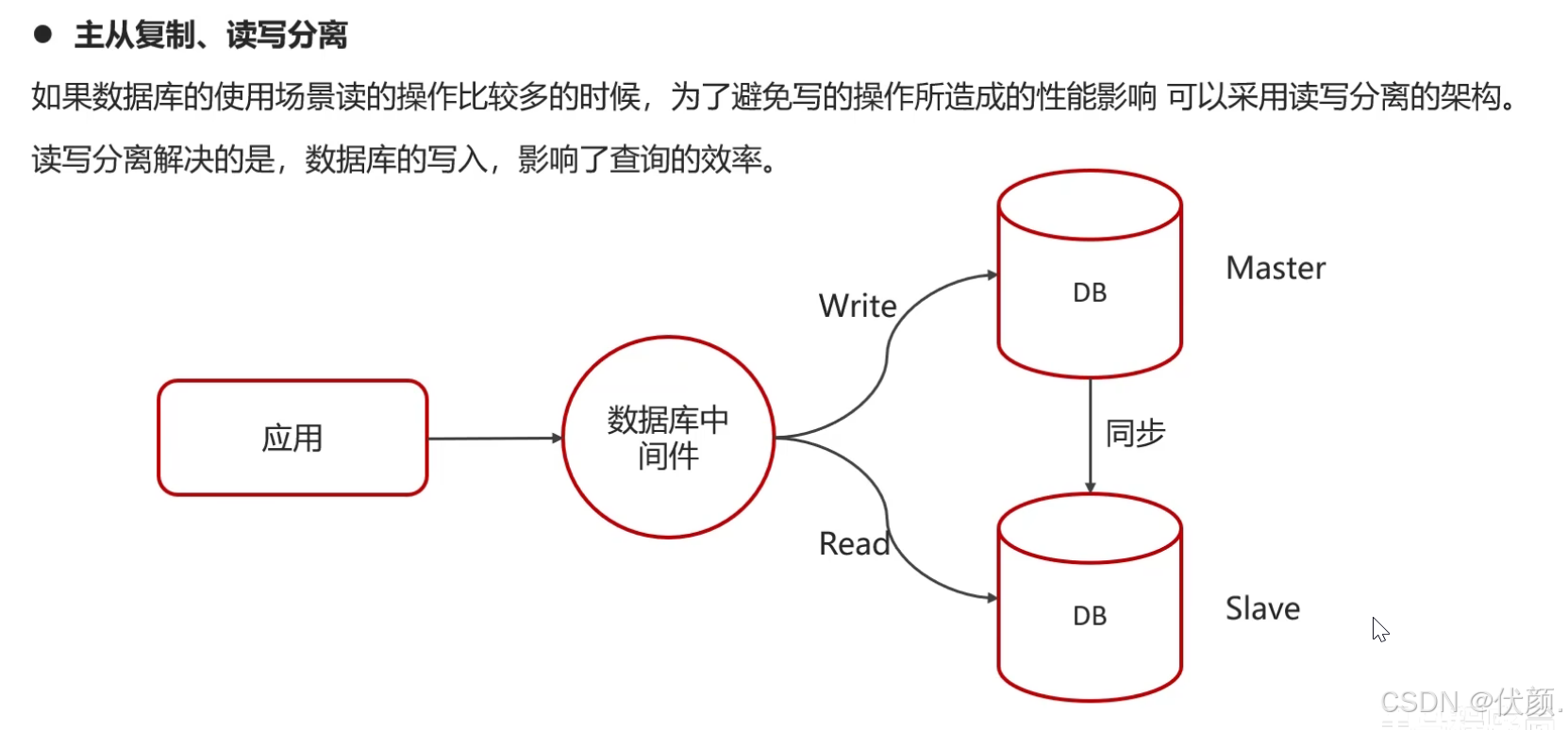
采用主从复制和读写分离提高性能。
-
在数据量大时考虑分库分表。

十八、你平时对SQL语句做了哪些优化呢?
-
我对SQL语句的优化包括指明字段名称而不是使用
SELECT *,避免造成索引失效的写法。 -
聚合查询时使用
UNION ALL代替UNION。 -
表关联时优先使用
INNER JOIN,以及下在必须使用LEFT JOIN或RIGHT JOIN时,确保小表作为驱动表。
十九、事务的特性是什么?可以详细说一下吗?
事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
事务的特性是ACID,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。例
-
即原子性(Atomicity):A向B转账500元,这个操作要么都成功,要么都失败,体现了原子性。
-
【事务是不可分割的最小操作单元,要么全部成功,要么全部失败。】
-
-
一致性(Consistency):转账过程中数据要保持一致,A扣除了500元,B必须增加500元。
-
【事务完成时,必须使所有的数据都保持一致状态。】
-
-
隔离性(Isolation):隔离性体现在A向B转账时,不受其他事务干扰。
-
【数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行】
-
-
持久性(Durability):持久性体现在事务提交后,数据要被持久化存储。
-
【事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。】
-
二十、并发事务带来哪些问题?
并发事务可能导致脏读、不可重复读和幻读。
-
脏读:一个事务读到另外一个事务还没有提交的数据。
-
不可重复读:一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读。【由于其他事务的修改】-update
-
幻读:一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在,好像出现了”幻影”。【其他事务插入的“幻行”】--insert delete
二十一、怎么解决并发事务的问题?MYSQL的默认隔离级别?
解决方案:使用事务隔离。MySQL支持四种隔离级别:【可重复读】-- 默认
-
读未提交(READ UNCOMMITTED):解决不了所有问题。
-
读已提交(READ COMMITTED):能解决脏读,但不能解决不可重复读和幻读。
-
可重复读(REPEATABLE READ):能解决脏读和不可重复读,但不能解决幻读,这也是MySQL的默认隔离级别。
-
串行化(SERIALIZABLE):可以解决所有问题,但性能较低。
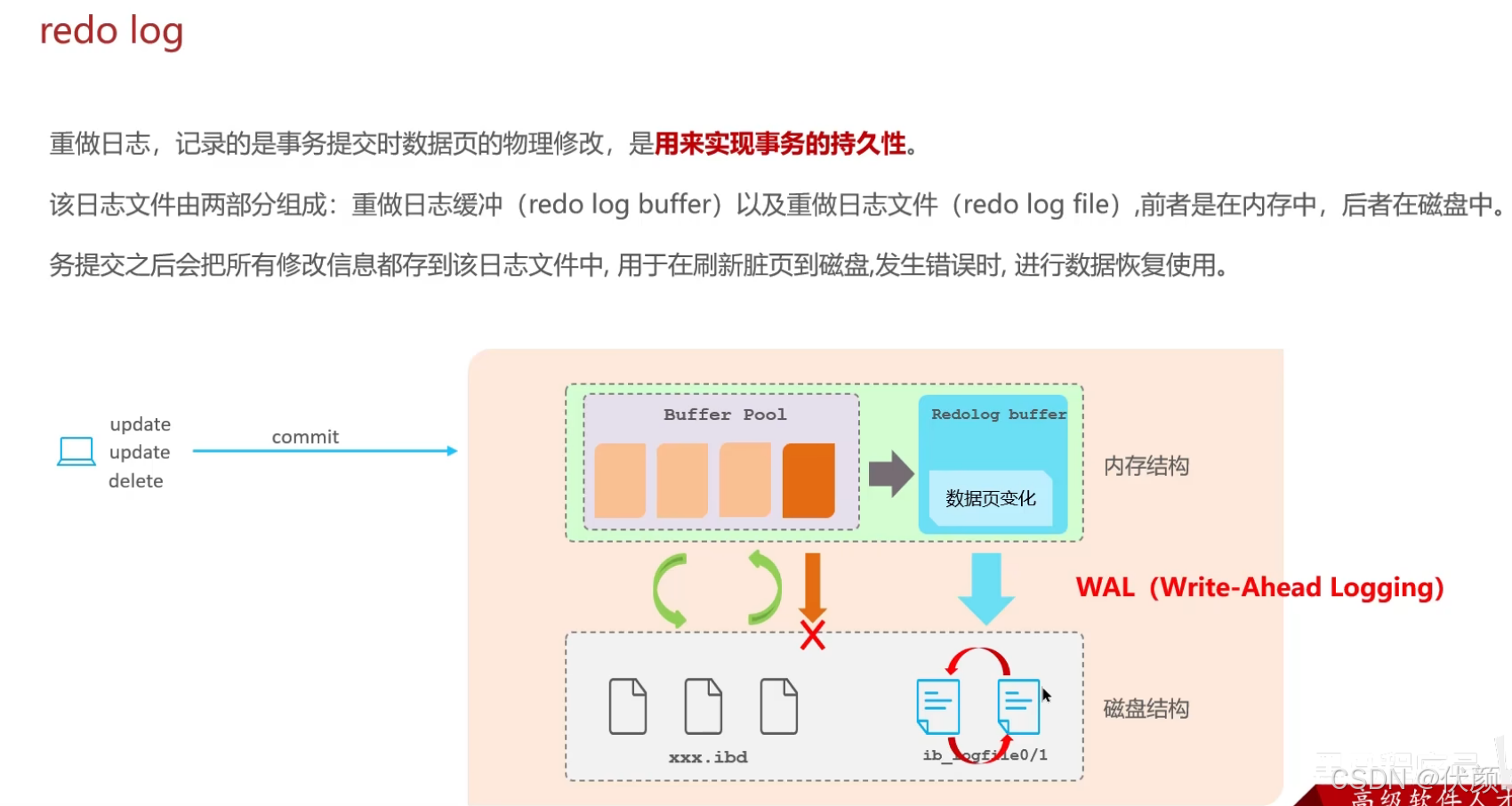
二十二、undo log和redo log的区别是什么?
-
redo log记录的是数据页的物理变化,用于服务宕机后的恢复,保证事务的持久性。 -
undo log记录的是逻辑日志,用于事务回滚时恢复原始数据【逆操作实现】,保证事务的原子性和一致性。

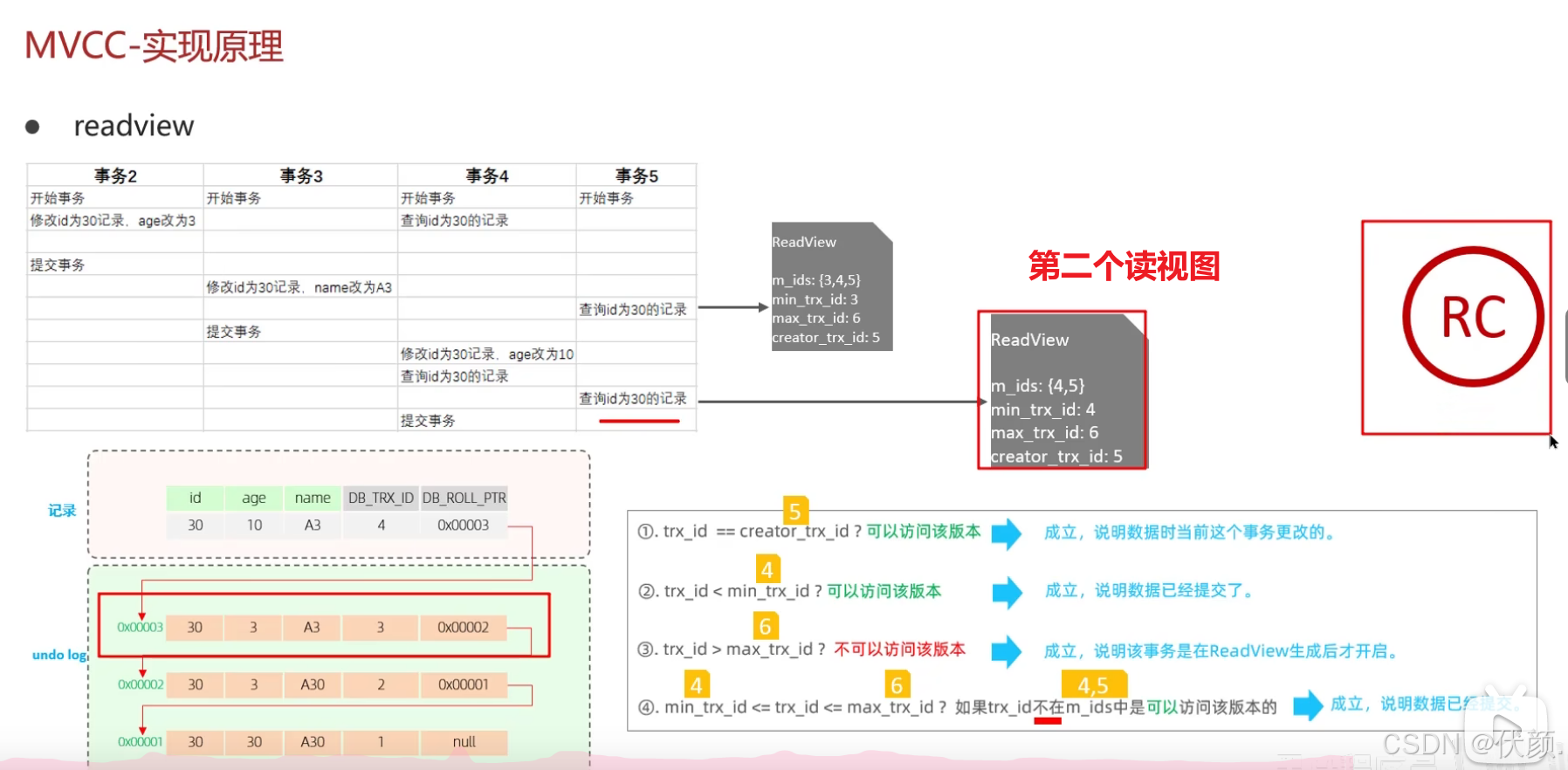
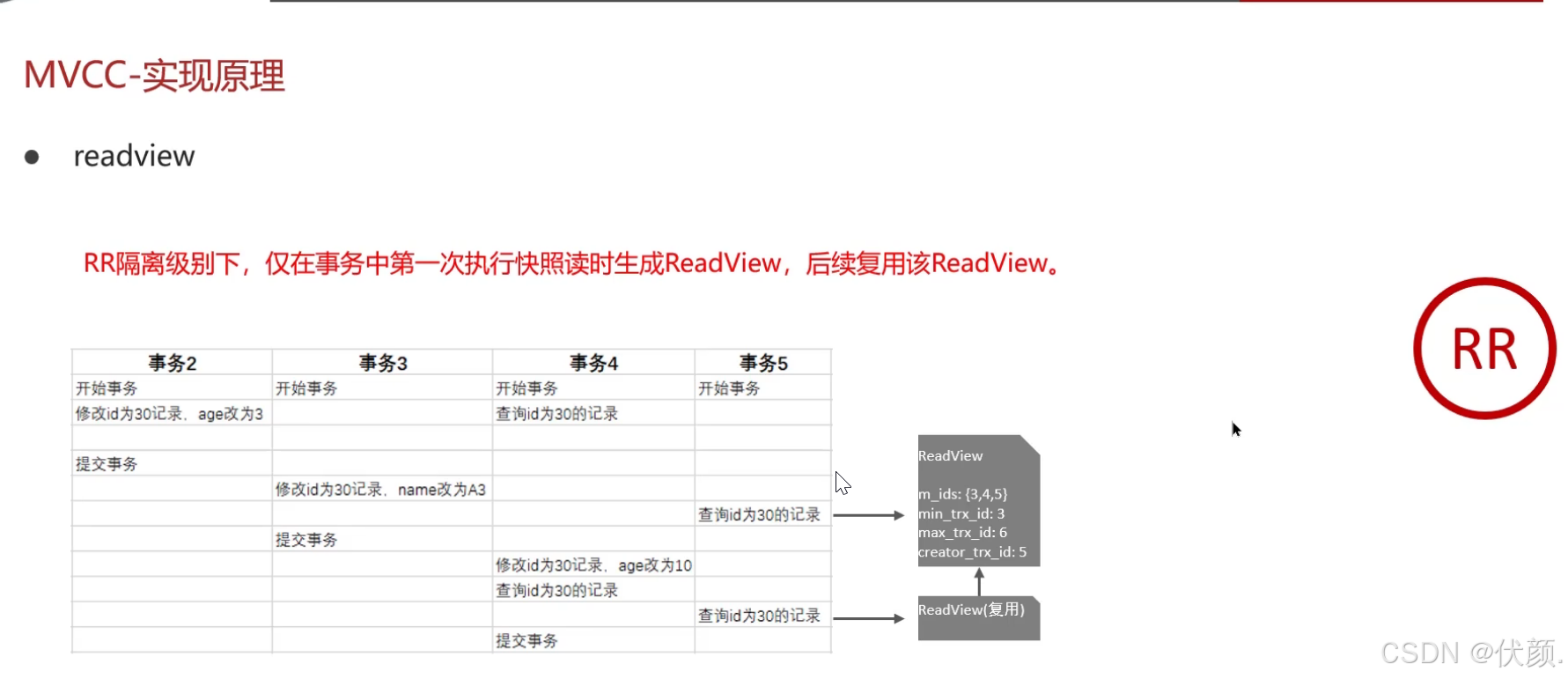
二十三、事务中的隔离性是如何保证的呢?(MVCC)
MVCC - multi-versioned concurrency control 多版本并发控制
-
事务的隔离性通过
锁和多版本并发控制(MVCC)来保证。 -
锁:排他锁(如一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的其他锁)
-
MySQL中的多版本并发控制(MCVV)。指维护一个数据的多个版本,使得读写操作没有冲突。
-
底层实现包括
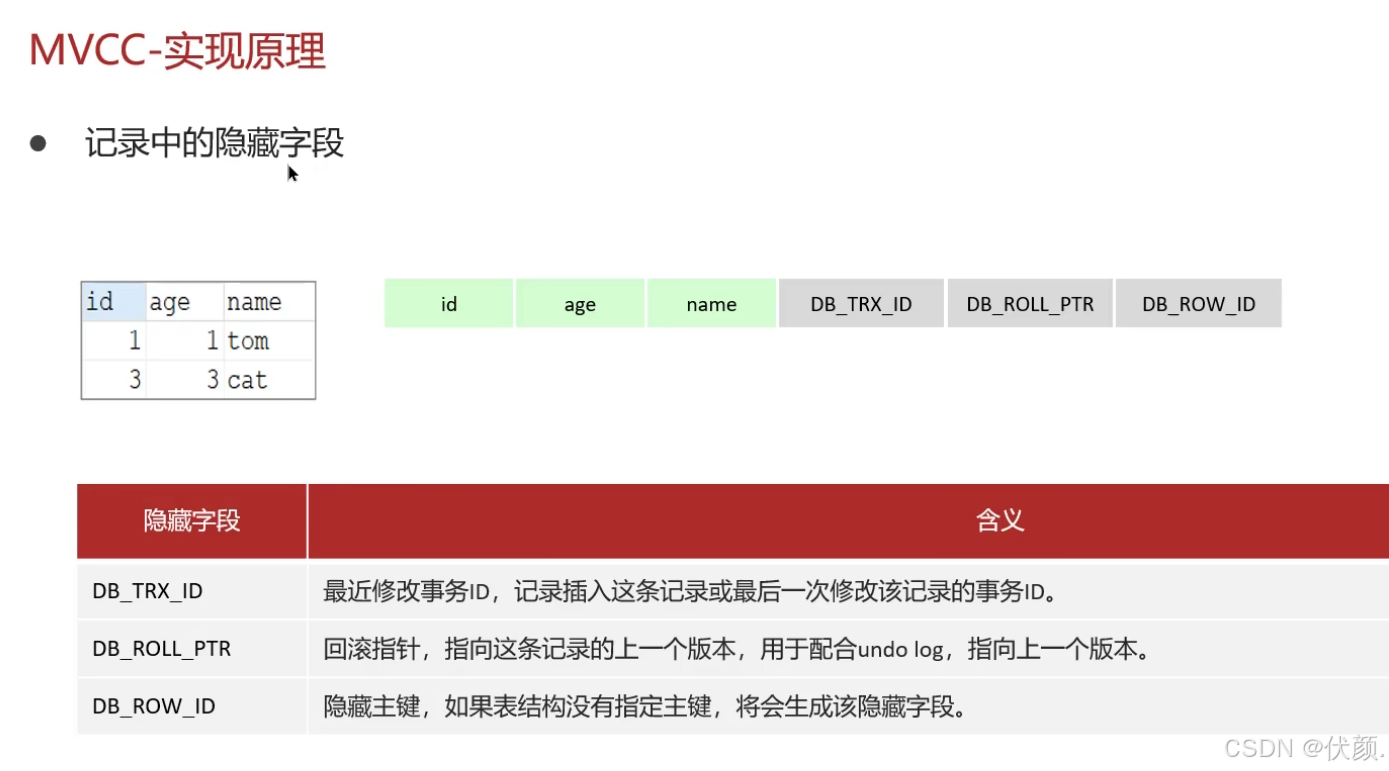
隐藏字段、undo log和read view。 -
隐藏字段包括
-
trx_id(事务id):记录每一次操作的事务id,是自增的 -
roll_pointer(回滚指针):指向上一个版本的事务版本记录地址 -
row_id:隐藏主键,如果表结构没有指定主键,将会生成该隐藏字段
-
-
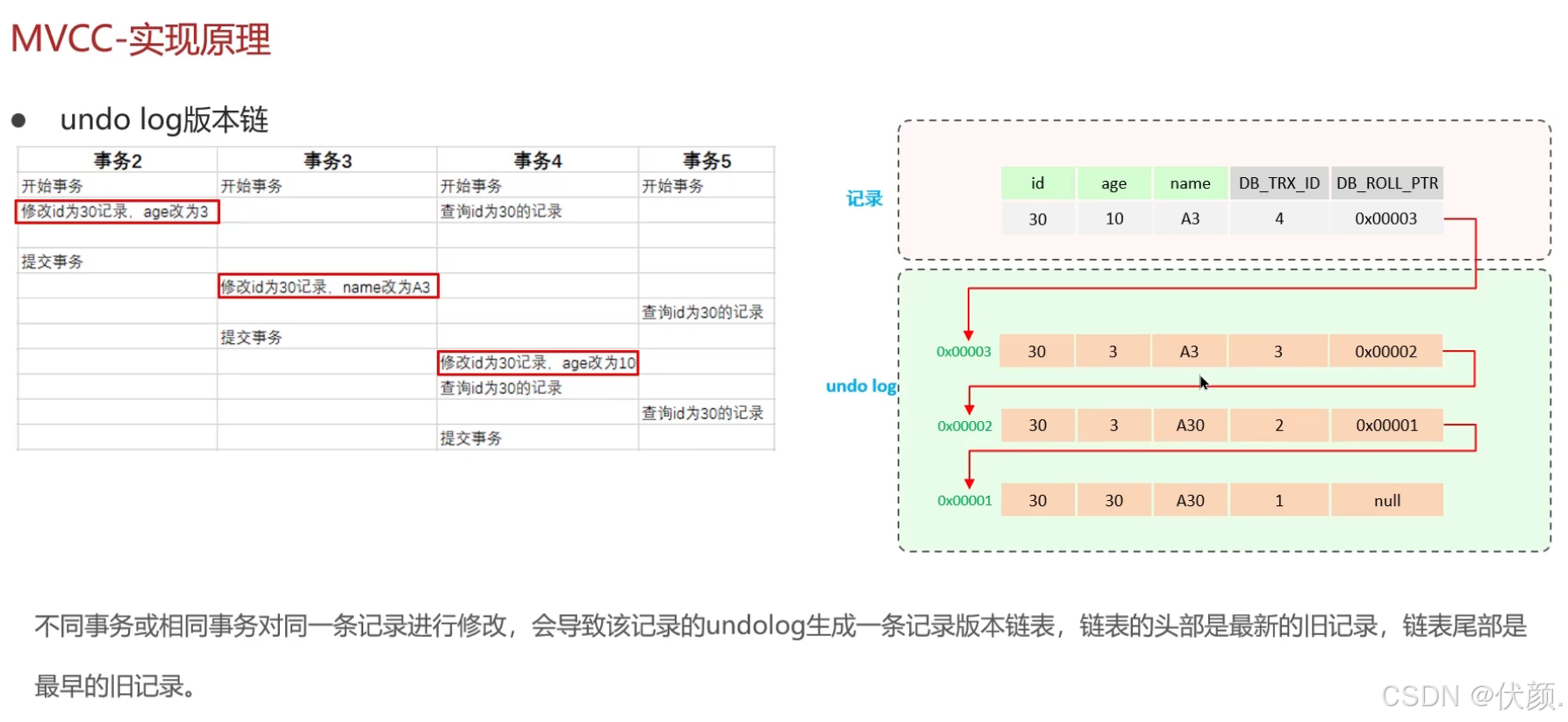
undo log记录了不同版本的数据,通过roll_pointer形成版本链。-
① 回滚日志,存储老版本数据 ② 版本链:多个事务并行操作某一行记录,记录不同事务修改数据的版本,通过roll pointer指针形成一个链表
-
-
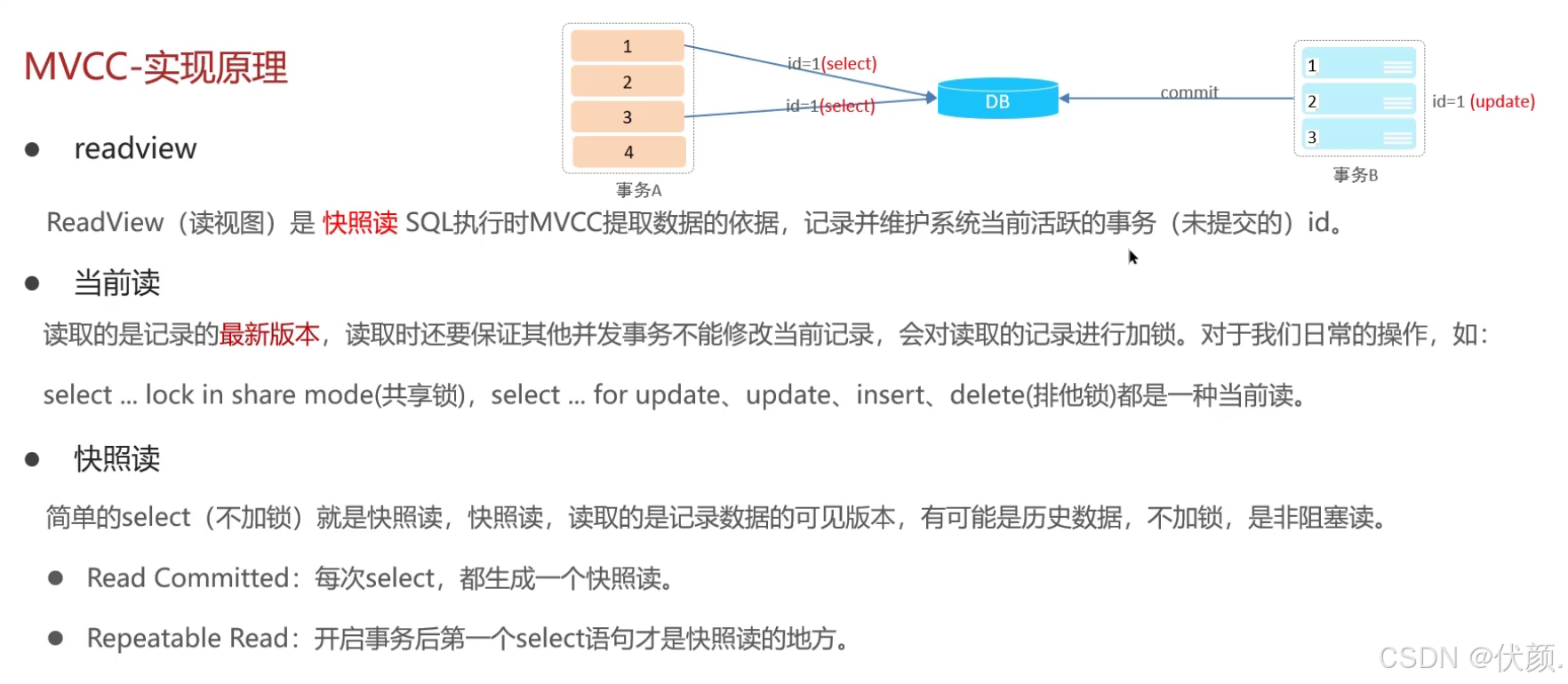
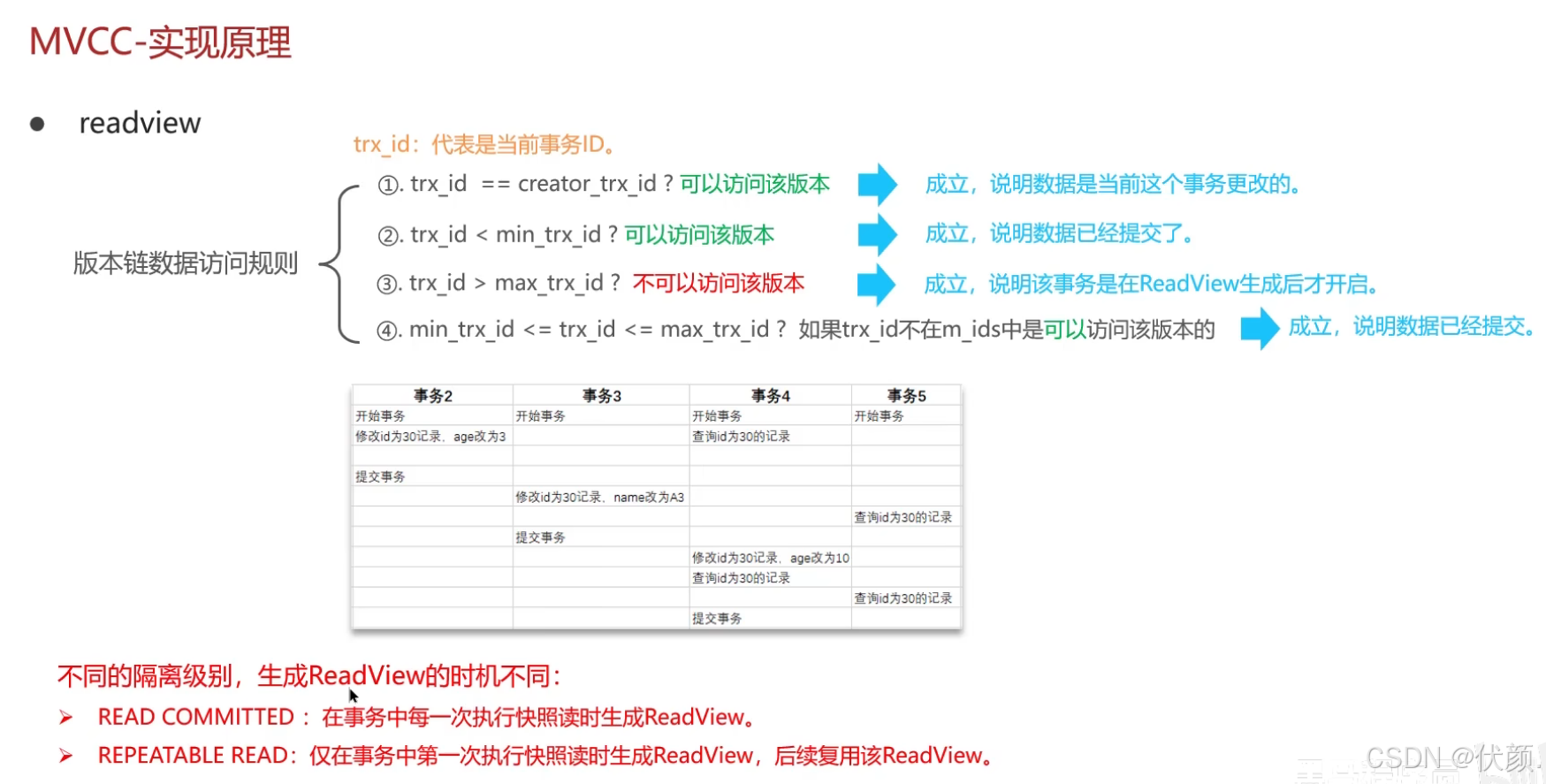
read view定义了不同隔离级别下的快照读,决定了事务访问哪个版本的数据。-
根据readView的匹配规则和当前的一些事务id判断该访问那个版本的数据
-
不同的隔离级别快照读是不一样的,最终的访问的结果不一样
-
RC:每一次执行快照读时生成ReadView
-
RR:仅在事务中第一次执行快照读时生成ReadView,后续复用
-
-
-



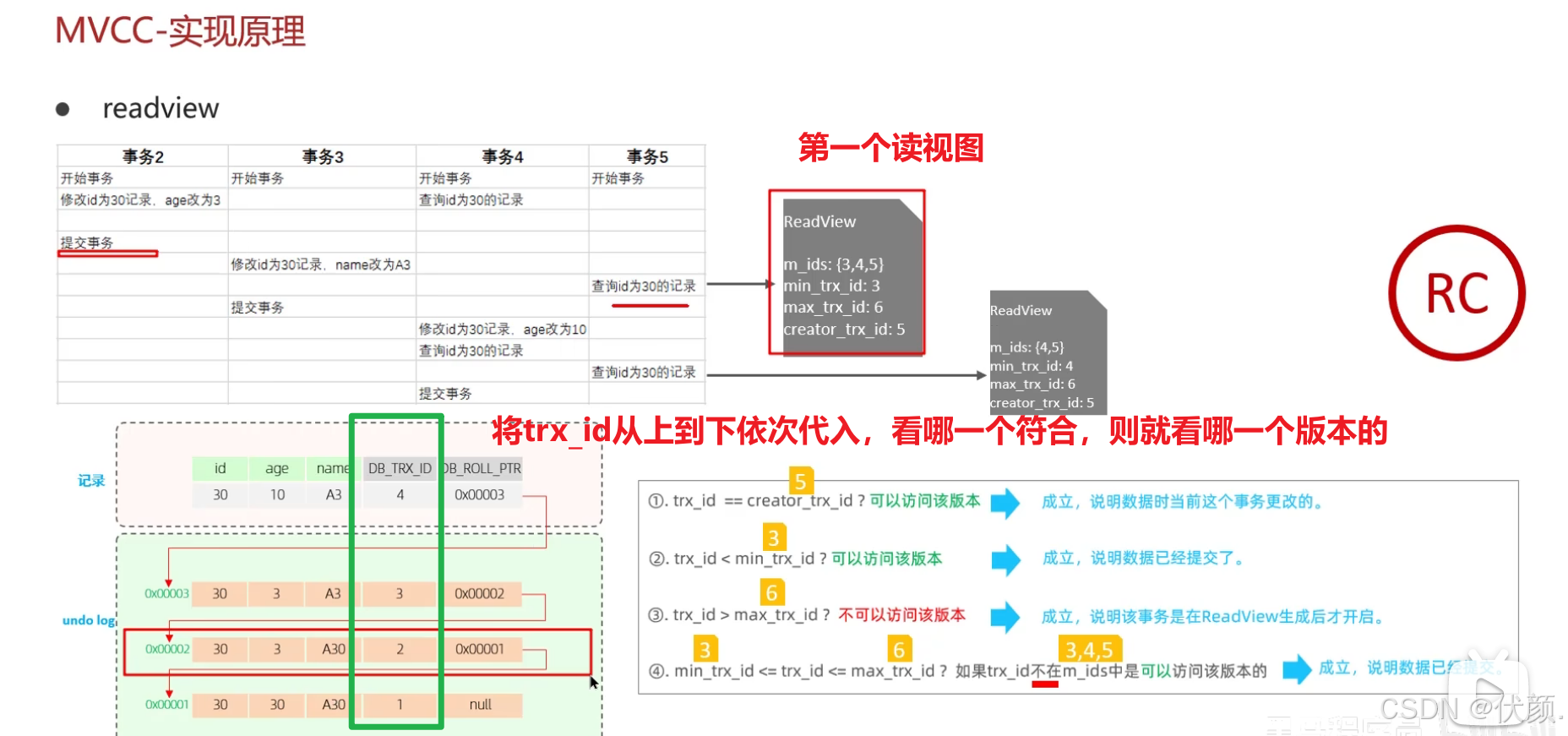
RC隔离级别:读已提交的
第一个视图,读取2版本
第二个视图,读取3版本
二十四、mysql主从同步原理?
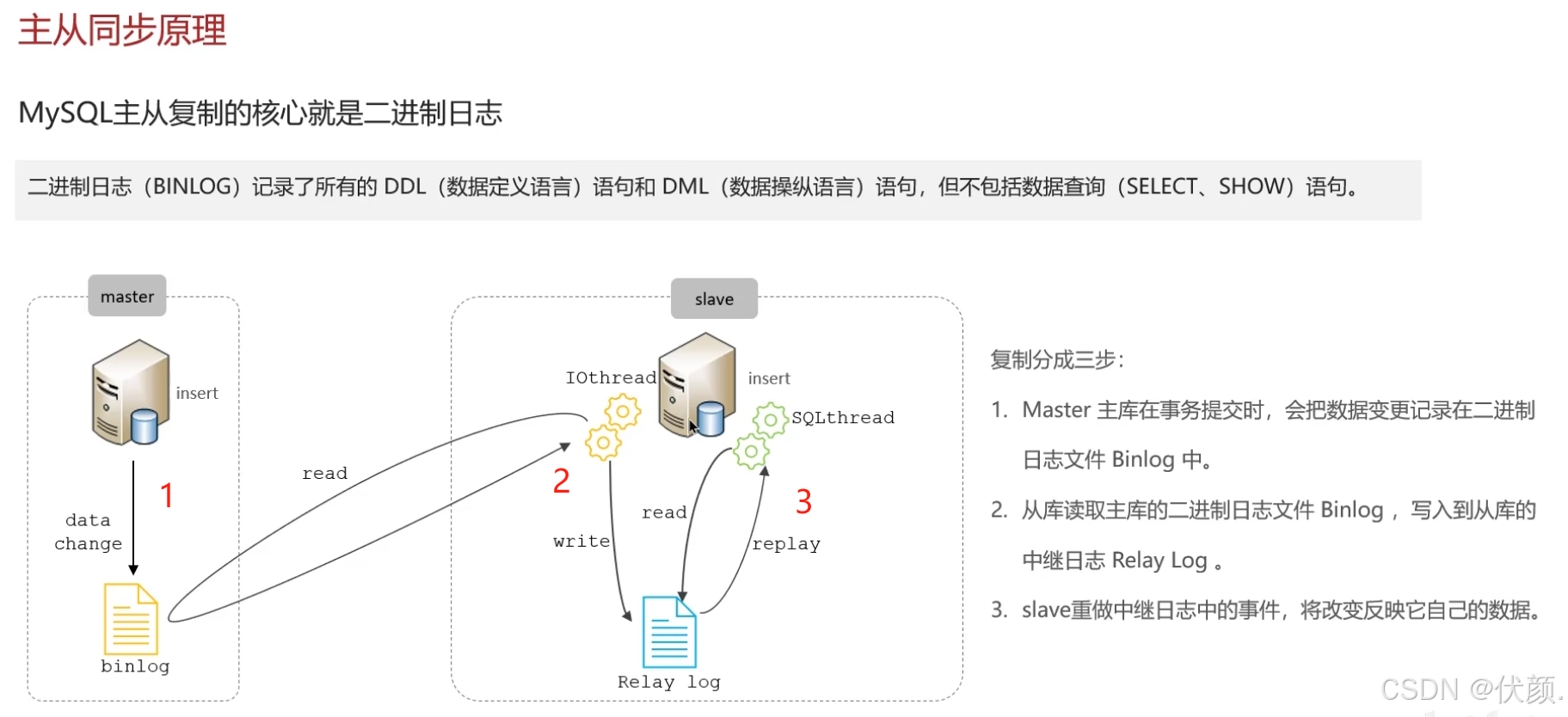
MySQL主从复制的核心是二进制日志(Binlog)。步骤如下:
-
主库在事务提交时记录数据变更到Binlog。
-
从库读取主库的Binlog并写入中继日志(Relay Log)。
-
从库重做中继日志中的事件,反映到自己的数据中。
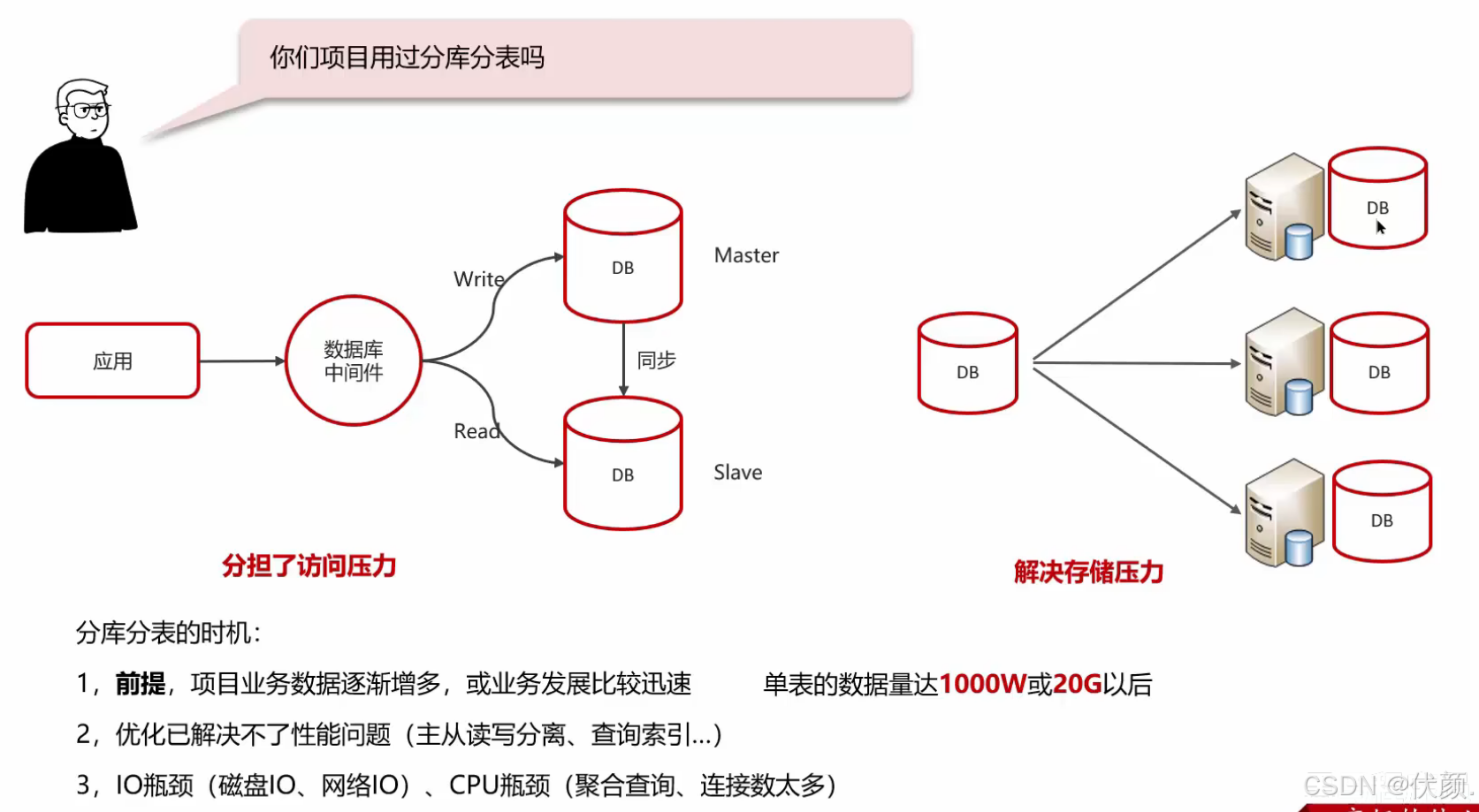
二十五、你们项目用过MySQL的分库分表吗?
我们采用微服务架构,每个微服务对应一个数据库,是根据业务进行拆分的,这个其实就是垂直拆分。
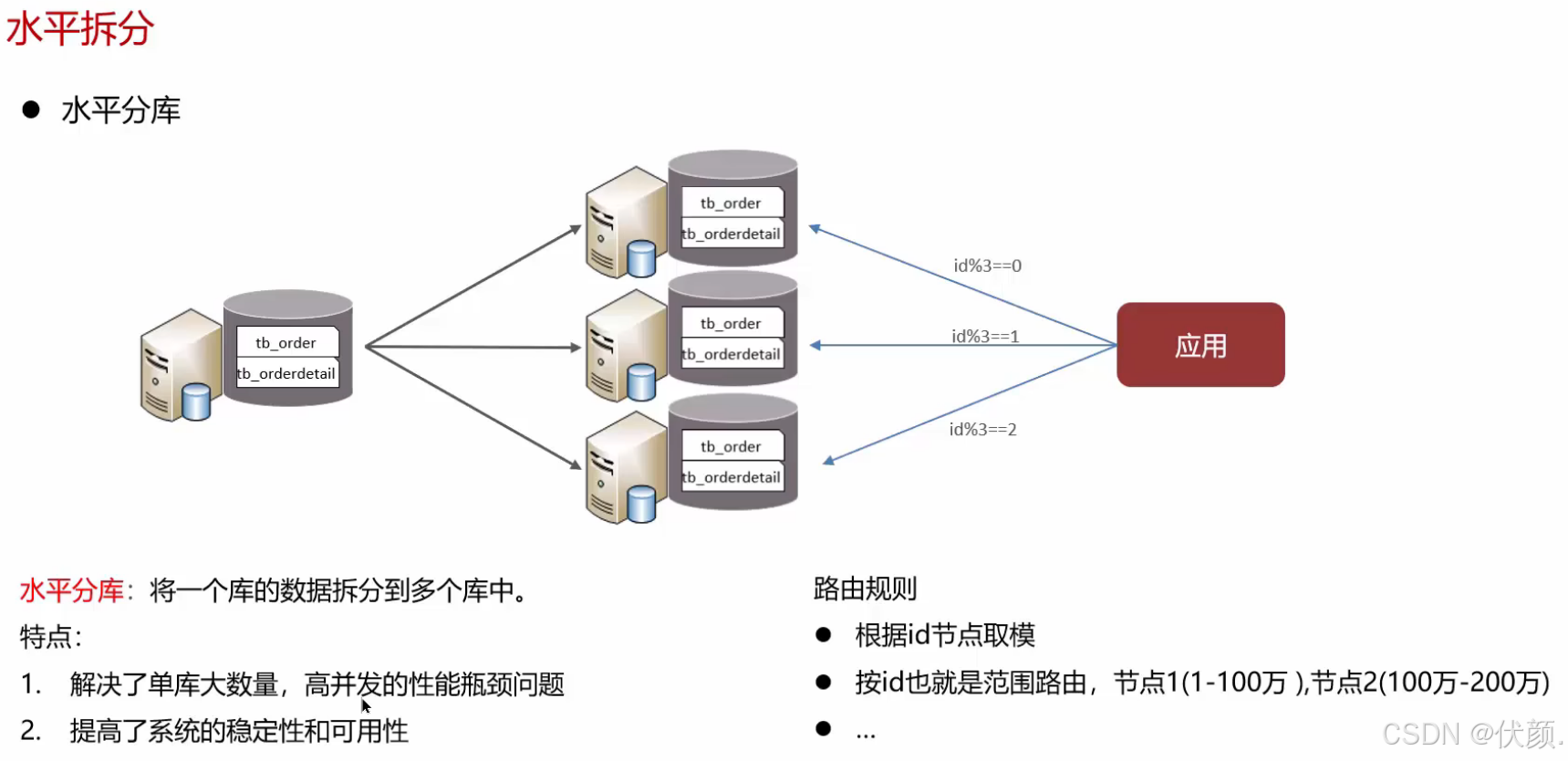
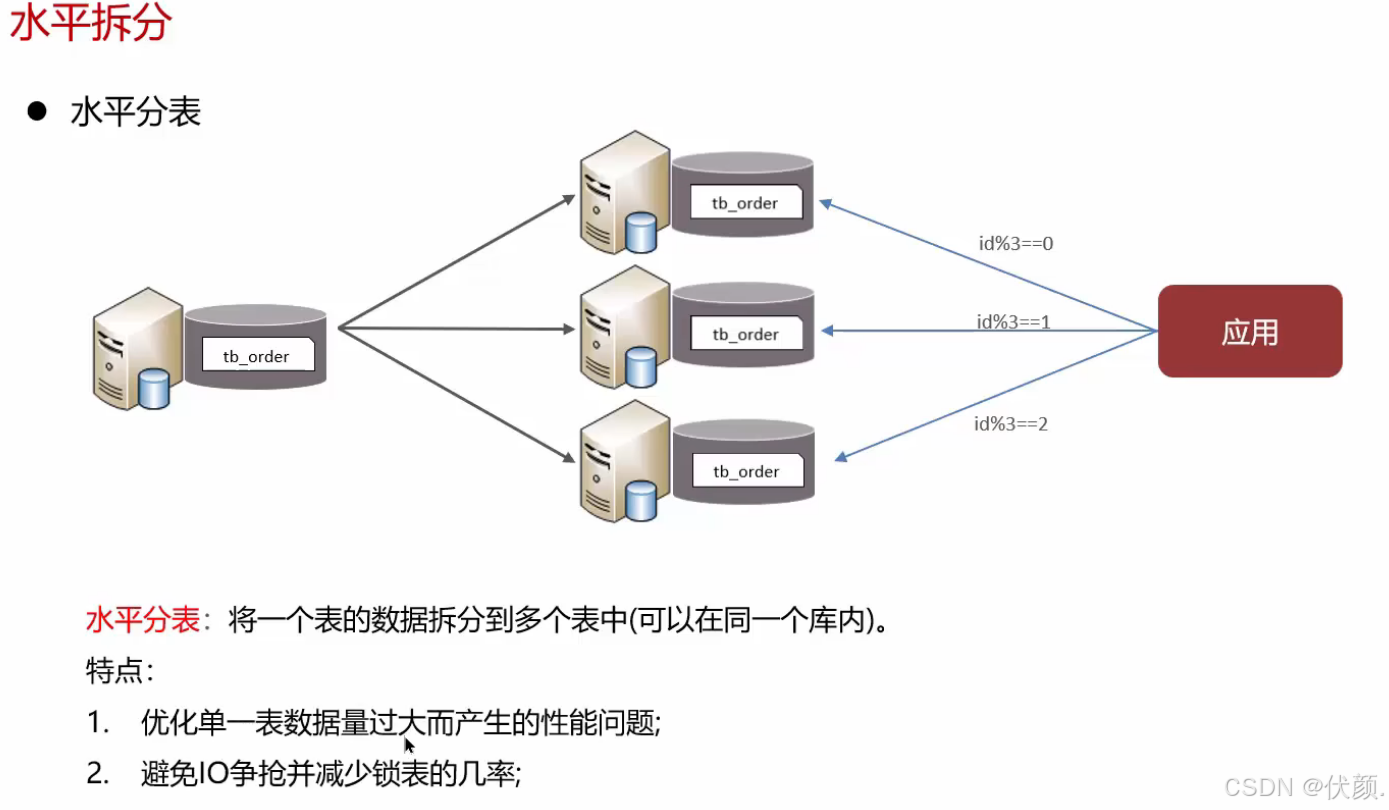
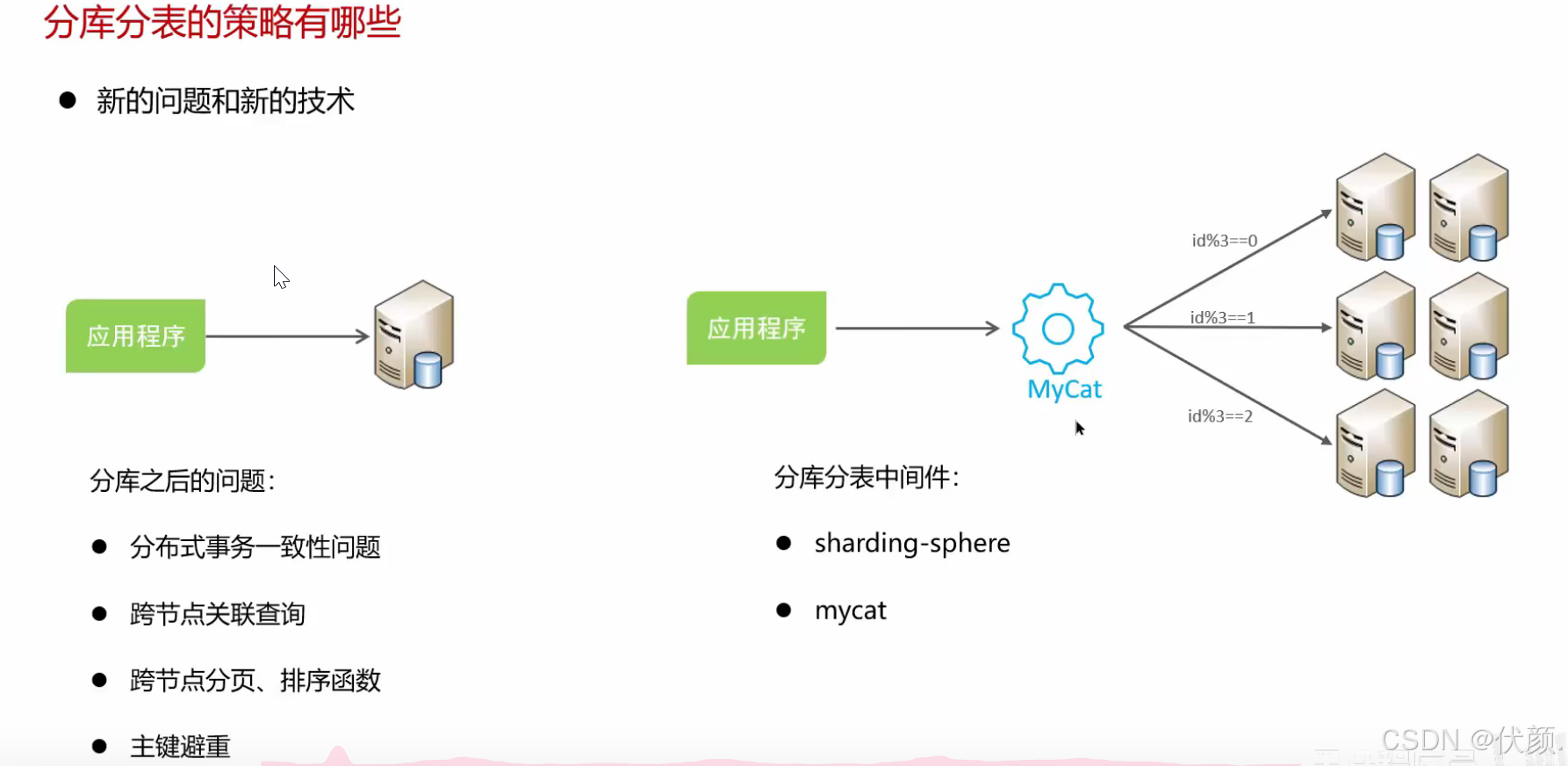
使用过。当时业务发展迅速,某个表数据量超过1000万,单库优化后性能仍然很慢,因此采用了水平分库。我们首先部署了3台服务器和3个数据库,使用mycat进行数据分片。旧数据也按照ID取模规则迁移到了各个数据库中,这样各个数据库可以分摊存储和读取压力,解决了性能问题。
-
业务介绍
-
根据自己简历上的项目,想一个数据量较大业务(请求数多或业务累积大
-
达到了什么样的量级(单表1000万或超过20G)
-
具体拆分策略
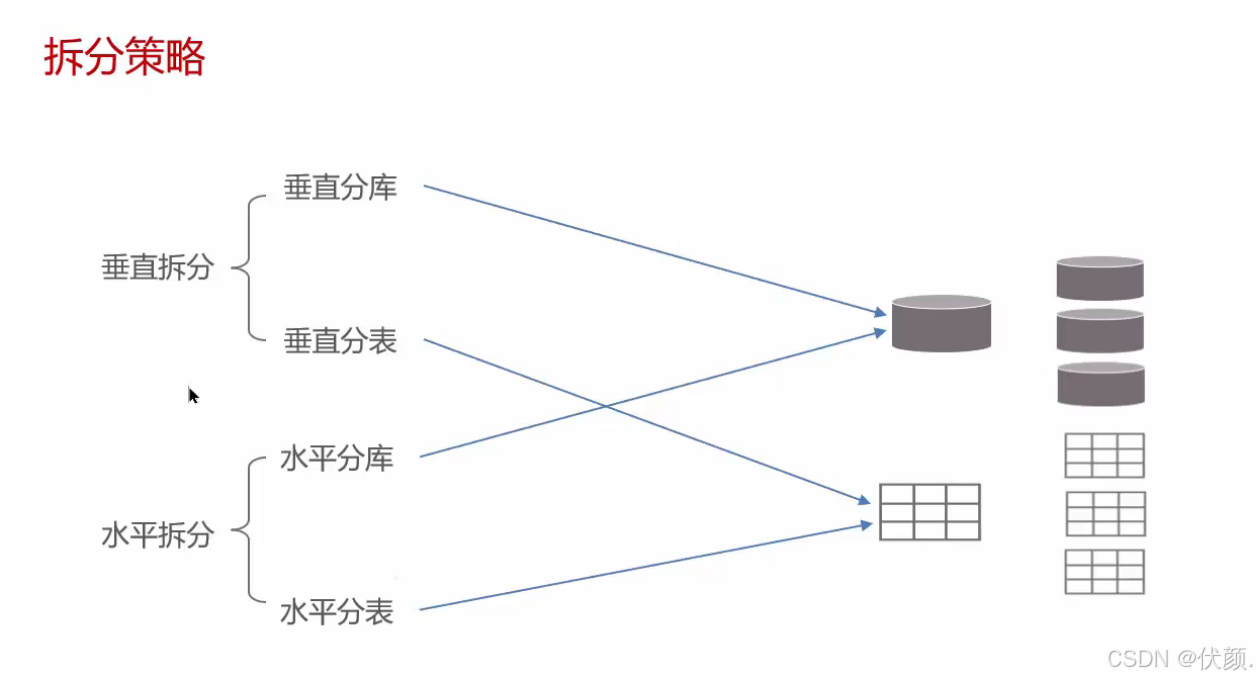
-
水平分库,将一个库的数据拆分到多个库中,解决海量数据存储和高并发的问题 -----
-
水平分表,解决单表存储和性能的问题 -----shaeding-sphere,mycat
-
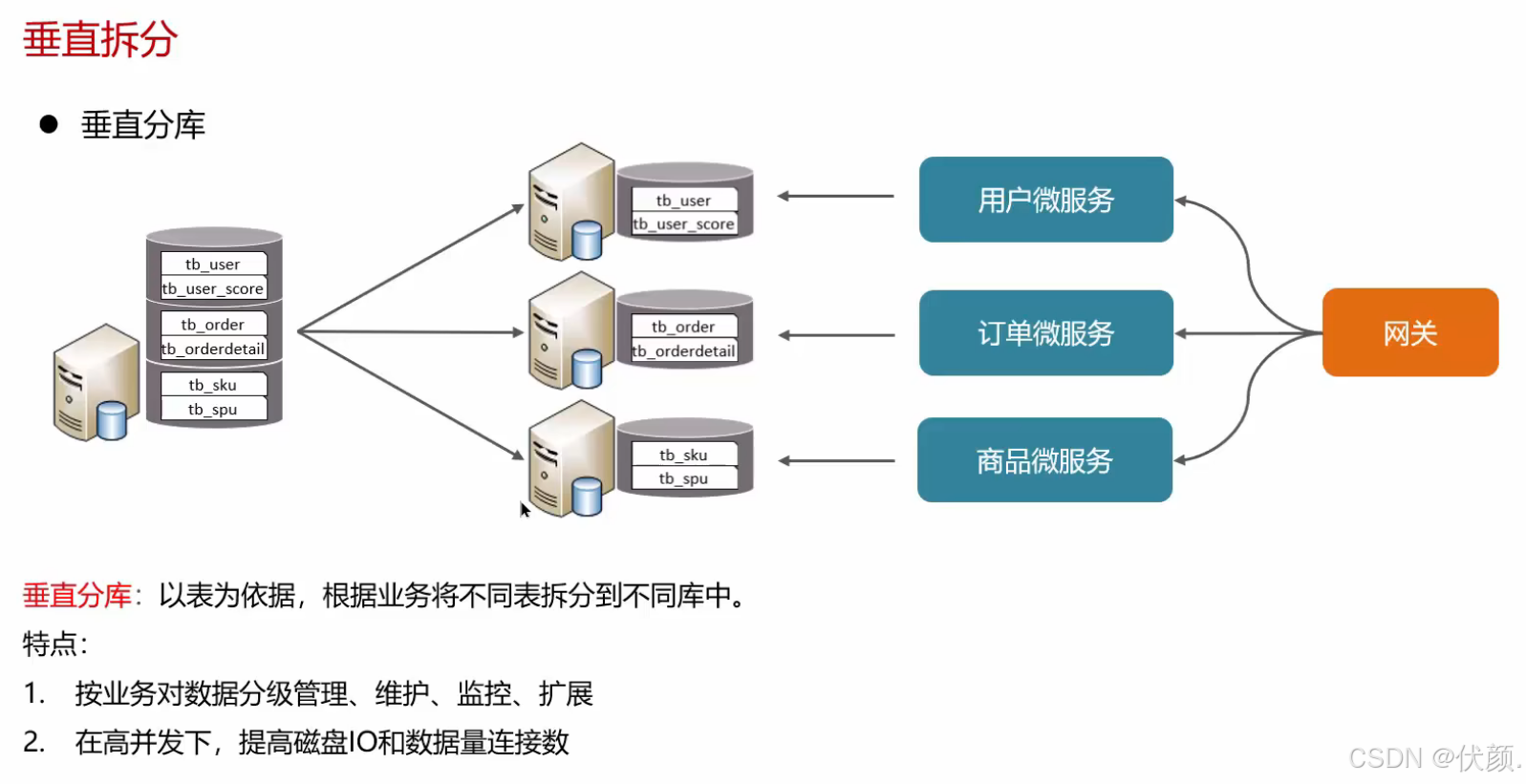
垂直分库,根据业务进行拆分,高并发下提高磁盘I0和网络连接数
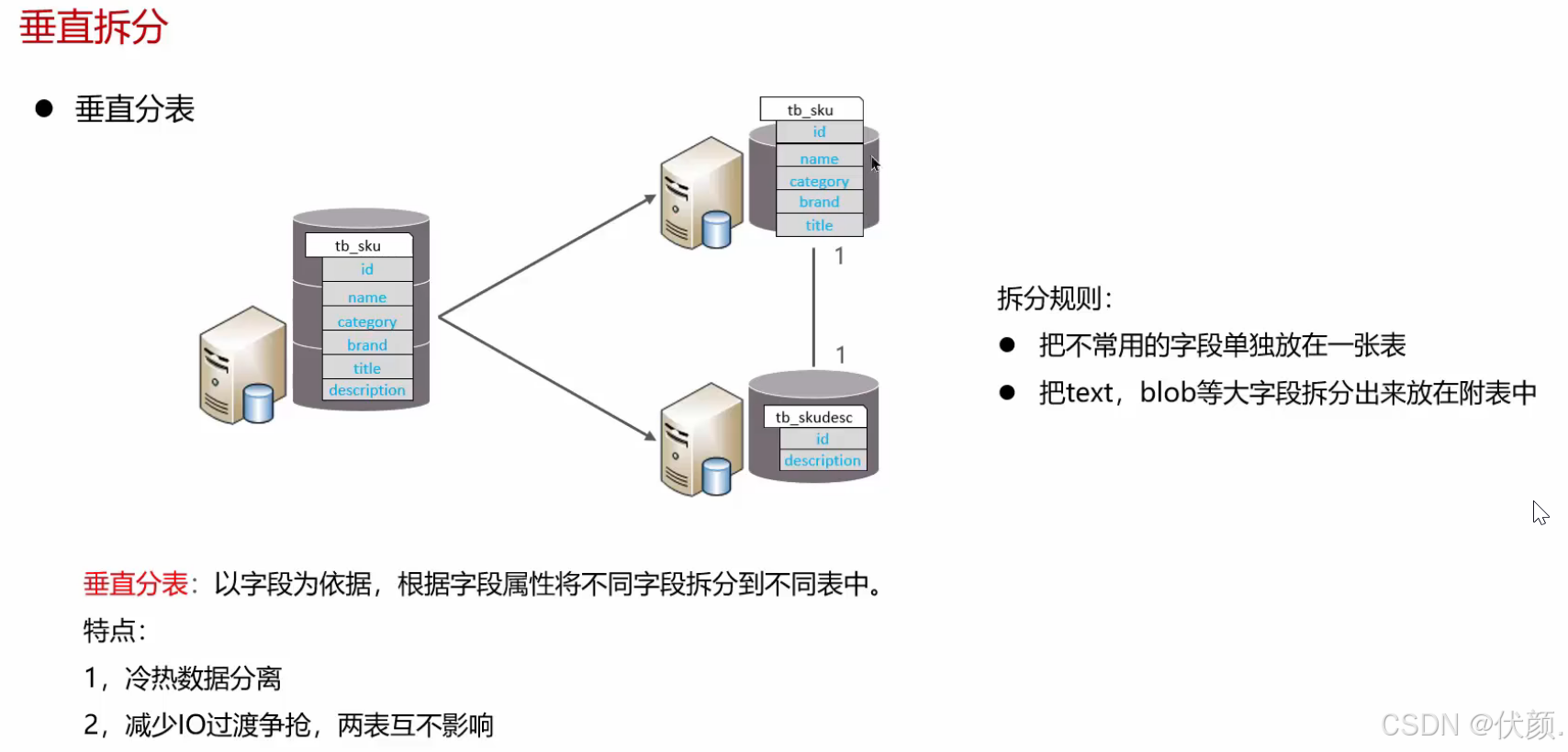
-
垂直分表,冷热数据分离,多表互不影响