【视觉基础模型-SAM系列-1】Segment Anything
论文链接:Segment Anything
代码链接:GitHub - facebookresearch/segment-anything: The repository provides code for running inference with the SegmentAnything Model (SAM), links for downloading the trained model checkpoints, and example notebooks that show how to use the model.
作者:Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, Christoph Feichtenhofer
发表单位:Meta AI Research, FAIR
会议/期刊:ICCV 2023
目录
一、研究背景
二、整体框架
三、核心方法
3.1 模型结构
3.2 训练细节
3.3 数据集的获取
四、实验结果
一、研究背景
自然语言处理(NLP)领域的基础模型(如GPT、BERT)通过海量文本训练和prompt方式,展现出强大的零样本、少样本泛化能力。相比之下,计算机视觉领域中的基础模型发展相对滞后,尤其在图像分割任务中,尚缺乏类似“预训练+提示”的通用方法。
在本文中,作者首先讨论了如何构建一个通用的图像分割基础模型?答案如下:
-
一种能支持zero-shot泛化的任务形式 (task) —— Promptable Segmentation
-
一个结构设计合理、性能高效的模型 (model) —— Segment Anything Model (SAM)
-
一个大规模、高质量的训练数据集 (data) —— Segment Anything Data Engine
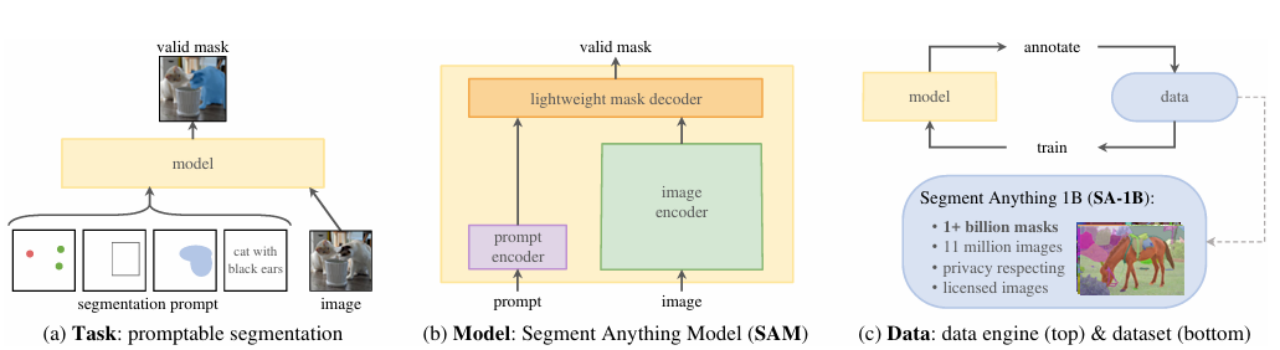
SAM的三大核心基础,任务、模型和数据
二、整体框架
Segment Anything 项目由三个核心组成部分构成:
任务:Promptable Segmentation(可提示分割)
-
用户输入提示(如点、框、掩码或文本)→ 模型输出有效的分割掩码。
-
可以处理多义性提示(如一处点可能表示“衬衫”也可能表示“人”)。
模型:Segment Anything Model (SAM)
-
包括一个图像编码器、提示编码器和轻量的掩码解码器。
-
可实时响应用户交互,处理点、框、掩码甚至自由文本提示。
数据引擎:Segment Anything Data Engine(笔者认为这个部分其实是最重要的)
-
三阶段标注机制(人工辅助 → 半自动 → 全自动)构建了 SA-1B 数据集,包含11M张图像和超过11亿个掩码
-
SAM本身用于辅助和自动化生成掩码,从而持续提升自身能力,实现数据和模型的共进化。
三、核心方法
3.1 模型结构
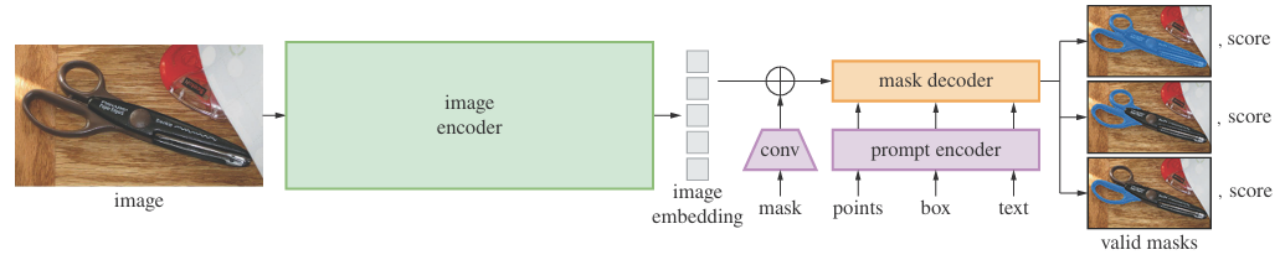
模型框架,图像编码器 + 提示编码器 + 掩码解码器
目的:一次图像编码,多次提示交互,支持实时响应,得到的 image embedding 是后续掩码预测的基础,尺寸为 [H/16, W/16, D]。
A. 图像编码器:使用 ViT(B/L/H)作为骨干网络,初始化方式为 MAE预训练,并在训练过程中扩大了原始分辨率(分辨率增强、适应长图、打补丁);
B. 提示编码器:接收稀疏提示和稠密提示,前者如点、框和文本,通过坐标位置编码+类型编码,文本则采用预训练的 CLIP 文本编码器(实际这个版本没有公开),后者指已有掩码(如人工编辑的粗mask),采用卷积编码器,提取稠密特征后逐元素加到 image embedding ;
C. mask解码器:完成2个阶段过程,Prompt token和image embedding双向cross-attention(Prompt→Image,Image→Prompt )、对 decoder 输出的 token用 MLP 映射为掩码权重向量得到scores(也就foreground probability),结合 image embedding 输出最终的二维掩码。
对于提示信息,分类讨论:
-
点和框:通过 坐标位置编码(positional encoding)+ 类型嵌入(learned type embedding)。
-
文本:使用预训练的 CLIP 文本编码器,将 free-form phrase 编码为 [D] 维度向量。
-
多点或框被序列化为 token 序列。
-
已有掩码:采用卷积编码器,提取稠密特征后逐元素加到 image embedding 上。
3.2 训练细节
多义性处理:
支持多掩码输出,应对多义提示(如一处点同时可能表示“人”或“衣服”)
模型输出 三个候选掩码,每个都有一个置信度(predicted IoU)分数。
训练阶段:采用 minimum loss 机制,仅回传与 GT 最接近的一个掩码(min loss over outputs)。
推理阶段:默认返回置信度最高的掩码,也可使用“oracle”方式选最接近 GT 的那个。
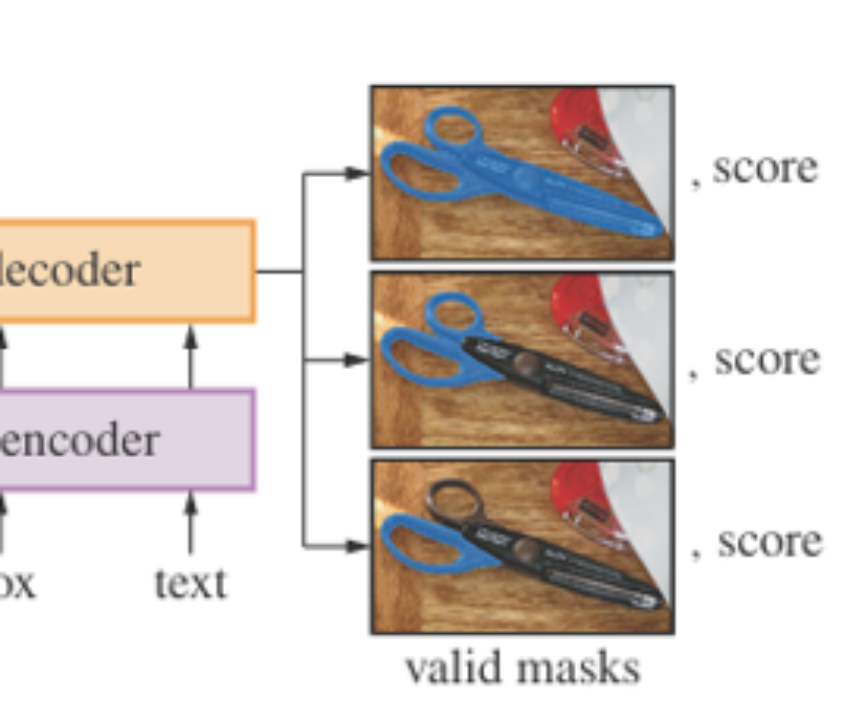
多义性处理示意图
训练方法:
对每个训练样本,模拟多轮提示输入,包括点、框、掩码等。每轮提示由 1–11 个 prompt 组成,模拟互动式标注行为。
Focal Loss:应对前景背景不平衡。Dice Loss:提升掩码边界精度。组合后联合优化。
3.3 数据集的获取
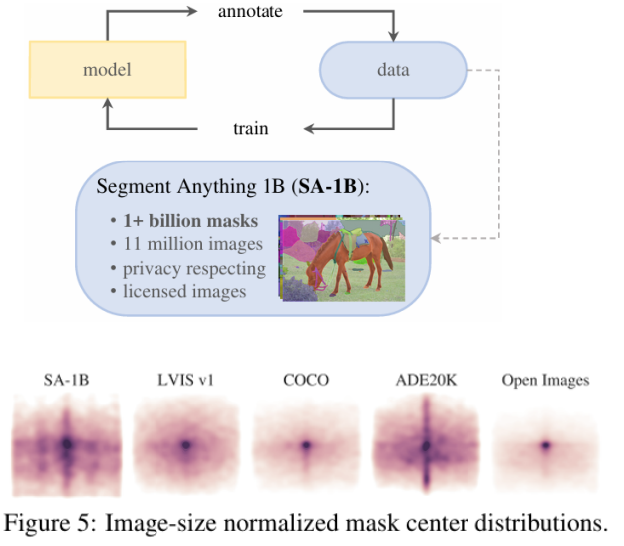
添加图片注释,不超过 140 字(可选)
图像分割数据集不像图像分类、图文对齐任务有 web-scale 数据(如 ImageNet、LAION),语义分割数据非常稀缺,手工标注代价高昂,尺度无法扩展。
第一阶段:人工辅助(Assisted-Manual)
人工点击 + SAM 响应 → 快速生成高质量掩码
专业标注员使用带有 SAM 的浏览器工具,在图像上点击 前景 / 背景点,模型预测 mask;结果可使用“画笔/橡皮”工具细化(类似 Photoshop);无需语义分类,仅关注掩码质量(label free,面向 segmentation 而非 detection);引导标注员优先标注显著物体,每个掩码最多允许 30 秒;每隔一段时间 SAM 重新训练更新,形成迭代闭环。
成果:
-
约 12 万张图像,430 万个掩码;
-
掩码平均耗时从 34 秒 → 14 秒(比 COCO 快 6.5 倍);
-
平均每图从 20 个掩码提升至 44 个。
第二阶段:半自动(Semi-Automatic)
模型预填 → 人工补充 → 多样性扩展
SAM 自动预测部分显著目标(如通过 bounding box 检测器辅助);标注员只需补充 未被检测出的边角类目标;这样可覆盖更多“小目标、低对比、背景化”类别,提升 mask 多样性;使用“generic object” 检测器,泛化性强;同样支持迭代训练更新模型。
成果:
-
18 万张图像,590 万新增掩码;
-
总计 10.2M 掩码;
-
单掩码耗时上升回 34 秒(因剩余目标更难标注);
-
每图掩码数升至 72(含自动掩码)。
第三阶段:全自动(Fully-Automatic)
使用迭代训练后的 SAM 大模型,在无人工参与下全自动生成掩码。
规则网格点提示(32×32):均匀在图像中采样前景点,作为 prompt;每点输出多掩码(三重掩码):解决目标层级问题(如“车头-车-车队”);置信度评分(IoU 预测):为每个掩码预测 mask-quality;稳定性筛选(稳定掩码):将 mask map 以两个阈值(0.5±δ)二值化;若两个结果相似,视为稳定;冗余清理(Non-Maximum Suppression):去除重复掩码;补图机制:对小目标,使用 缩放图像局部区域补充掩码,提升分辨率捕捉能力。
成果:
-
对全部 1100 万图像执行自动生成;
-
最终生成 11 亿(1.1B)个掩码;
-
99.1% 掩码为自动生成,成为当时世界最大分割数据集。
数据评价:
-
对 500 张图像中的 5 万个自动掩码进行人工修正;
-
评估 IoU:94% 掩码与人工修正版本 IoU > 90%;
-
高于大多数公开数据集的标注一致性(COCO、ADE20K 在 85–91% 左右);
-
在后续实验中证明:用自动掩码训练模型的性能 ≈ 用全数据训练。
数据多样性:
-
图像来源:来自摄影师平台,非网络抓取,保证版权与隐私;
-
覆盖广泛国家:共 175 个国家,top3 分别来自不同洲;
-
收入与地区分布:中等收入国家代表性强,但非洲仍相对欠缺;
-
内容类型:含物体、人、动物、纹理、交通、自然场景等多种类型;
-
图像清晰度:平均分辨率 3300×4950,远高于 COCO。
四、实验结果

经典的模型,指标不用说,展示一些可视化的结果吧
五、后续的内容
【视觉基础模型-SAM系列-3】Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks-CSDN博客文章浏览阅读4次。ICCV 2023【视觉基础模型-SAM系列-1】Segment Anything-CSDN博客自然语言处理(NLP)领域的基础模型(如GPT、BERT)通过海量文本训练和prompt方式,展现出强大的零样本、少样本泛化能力。相比之下,计算机视觉领域中的基础模型发展相对滞后,尤其在图像分割任务中,尚缺乏类似“预训练+提示”的通用方法。【视觉基础模型-SAM系列-2】SAM2: Segment Anything in Images and Videos-CSDN博客。https://blog.csdn.net/cjy_colorful0806/article/details/147774458?fromshare=blogdetail&sharetype=blogdetail&sharerId=147774458&sharerefer=PC&sharesource=cjy_colorful0806&sharefrom=from_link
【视觉基础模型-SAM系列-2】SAM2: Segment Anything in Images and Videos-CSDN博客SAM2不输出全图所有 instance(如 Mask R-CNN 那样),但可以通过点击/框选择“某个目标”,只分割这个实例,并跨帧追踪。给出舌头的掩码,其中绿点是正面,红点是负面提示;自动传播到后续帧(即只跟踪这一实例);支持点击纠正(如错过了某一帧的舌头)。SAM2 用的是一种transformer + memory bank 的记忆机制:每帧提取 image feature;用户点击提示指明要追踪哪个目标;模型构建一个“object token”(即目标语义表示);https://blog.csdn.net/cjy_colorful0806/article/details/147771188?fromshare=blogdetail&sharetype=blogdetail&sharerId=147771188&sharerefer=PC&sharesource=cjy_colorful0806&sharefrom=from_link