快速上手知识图谱开源库pykeen教程指南(一)
文章目录
- 1 AmpliGraph 和 PyKEEN 对比介绍
- 2 直接上案例
- 2.1 数据载入:TriplesFactory
- 2.2 模型训练
- 2.2.1 训练信息
- 2.2.2 TransE模型可以降维实体、关系的关系
- 2.3 模型保存与加载、评估
- 2.3.1 保存与模型加载
- 2.3.2 评估
- 2.4 模型预测
- 2.4.1 链接预测或关系预测 - predict_target
- 2.4.2 新三元组可能性预测 - predict_triples
- 2.4.3 全三元组可能性预测 - predict_all
- 2.4.4 其他预测
1 AmpliGraph 和 PyKEEN 对比介绍
AmpliGraph 和 PyKEEN 是知识图谱嵌入(Knowledge Graph Embedding, KGE)领域的两大主流开源框架,均专注于将知识图谱中的实体和关系映射到低维向量空间,以支持链接预测、知识补全等任务。
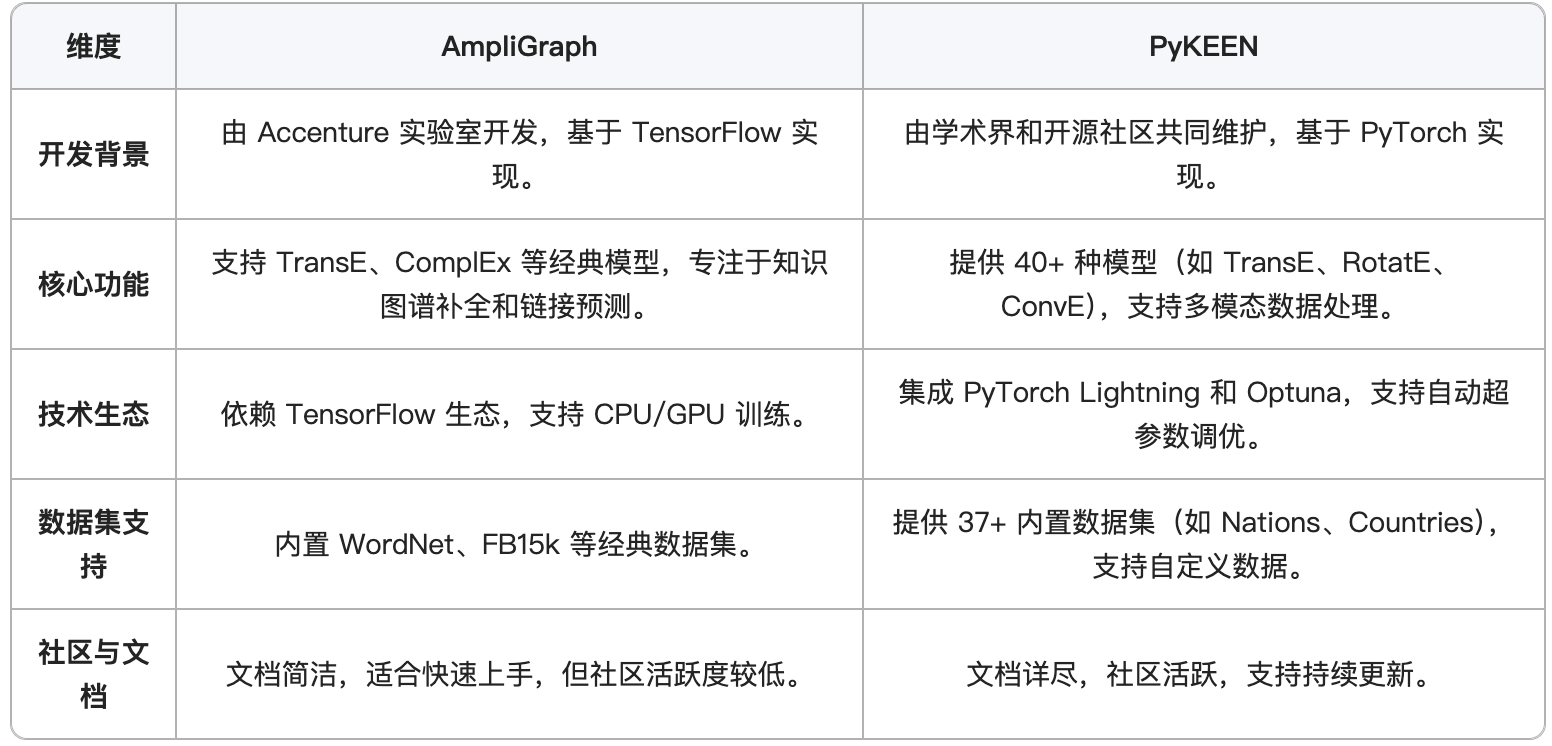
笔者学了一天pykeen个人感觉:
- 更新频率来说,pykeen 比ampligraph频繁一些,维护者更新比较频繁
- 文档问题,代码比较丰富,但是example给的非常简单,不利于入门学习;而且很多函数更新太快,文档里面的代码都不可以使用,处于比较不稳定的状态,需要自己看源码探索!!! 比较费劲啊!!! 好像也没人用啊??
- 内置的模型很多,不过呢,很多功能只能用特定的几款模型,有点学术派
pykeen的教程:
- github地址:https://github.com/pykeen/pykeen
- 官方文档地址:https://pykeen.readthedocs.io/en/latest/index.html
安装:
pip install pykeen
关于AmpliGraph 的一些学习文档:
- http://www.uml.org.cn/ai/202310264.asp
- https://blog.csdn.net/weixin_44458771/article/details/125671237
- https://juejin.cn/post/7030048656216555556
2 直接上案例
triples = [# 消费者与会员权益关联("Consumer_ZhangWei", "uses_privilege", "Gold_Member_Discount"),("Consumer_LiNa", "uses_privilege", "Platinum_Free_Shipping"),("Consumer_WangQiang", "uses_privilege", "Silver_Coupon_100"),("Consumer_ChenXin", "uses_privilege", "Diamond_Exclusive_Gift"),# 消费者在门店购买商品(结合权益)("Consumer_ZhangWei", "purchased_at", "Store_Beijing_Chaoyang"),("Store_Beijing_Chaoyang", "sells_with_privilege", "Gold_Member_Discount"),("Consumer_ZhangWei", "buys", "Smartphone_X"),("Consumer_LiNa", "purchased_at", "Store_Shanghai_Pudong"),("Store_Shanghai_Pudong", "sells_with_privilege", "Platinum_Free_Shipping"),("Consumer_LiNa", "buys", "Laptop_Pro15"),("Consumer_WangQiang", "purchased_at", "Store_Guangzhou_Tianhe"),("Store_Guangzhou_Tianhe", "sells_with_privilege", "Silver_Coupon_100"),("Consumer_WangQiang", "buys", "Wireless_Earbuds"),("Consumer_ChenXin", "purchased_at", "Store_Beijing_Chaoyang"),("Store_Beijing_Chaoyang", "sells_with_privilege", "Diamond_Exclusive_Gift"),("Consumer_ChenXin", "buys", "4K_Monitor_27inch"),# 补充关系链("Smartphone_X", "category", "Electronics"),("Laptop_Pro15", "price_range", "High_End"),("Wireless_Earbuds", "brand", "SoundMaster"),("4K_Monitor_27inch", "stock_status", "In_Stock")
]import numpy as np
from pykeen.triples import TriplesFactory# 将三元组转换为PyKEEN可处理的格式
triples = np.array(triples)
tf = TriplesFactory.from_labeled_triples(triples=triples,create_inverse_triples=False # 是否生成反向三元组(如用于对称关系)
)# 划分训练集与测试集(比例80%训练,20%测试)
training, testing = tf.split(ratios = 0.9)import os
import numpy as np
import pykeen
from pykeen.pipeline import pipeline
from pykeen.triples import TriplesFactory# 训练
results = pipeline(training=training,testing=testing,model="RotatE",training_kwargs=dict(num_epochs=100),random_seed=1235,device="cpu",
)# 模型保存
results.save_to_directory("Consumer_results")# 预测
from pykeen import predict
user = "Consumer_ChenXin"
relation = 'purchased_at'if user in tf.entity_id_to_label.values():if relation in tf.relation_id_to_label.values():# 确保在tf的实体名单之中res = predict.predict_target(model=results.model, head=user,\relation=relation, triples_factory=tf).dfelse:print(f'{relation} not in relation.')
else:print(f'{user} not in entity.')res
以上的数据集是笔者自己让deepseek模拟的,prompt为:
需要模拟一个知识图谱使用的三元组数据集,数据集为零售行业,
数据集的本体包括:
- 商品
- 门店
- 消费者
- 会员权益
关系大致为:
- 不同消费者在不同门店、使用不同会员权益购买不同的商品给出模拟的三元组数据集,商品、门店、消费者、会员权益需要给出具体的名称
并且根据此给pykeen进行预测
最终给出最终实现的python的代码,代码需要逐行给出注释
因为如果模拟的数据三元组数量较少,就会出现以下报错:
`ValueError: Could not find a coverage of all entities and relation with only 5 triples.`
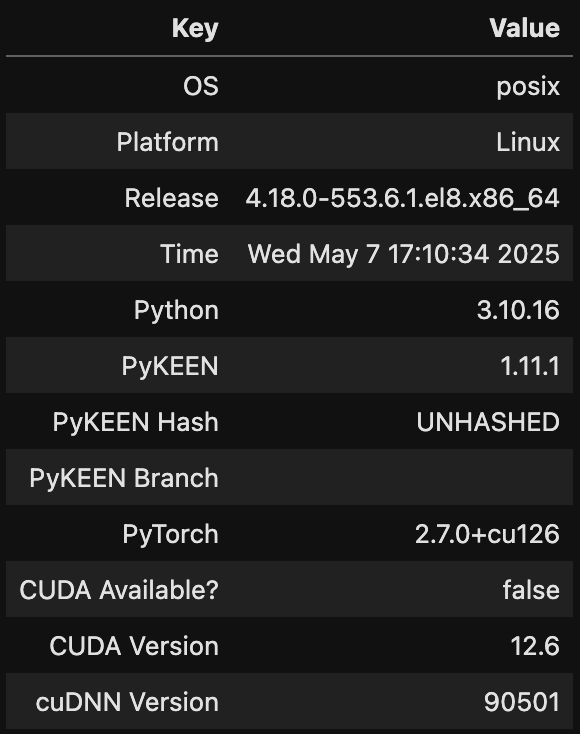
笔者运行Pykeen的环境为:
pykeen.env()
2.1 数据载入:TriplesFactory
从上述案例可以看到数据载入需要转变为TriplesFactory格式,这一格式是pykeen自带的特殊的格式
from pykeen.triples import TriplesFactory
# 定义原始三元组
triples = [("Alice", "buys", "Product_A"),("Bob", "buys", "Product_B"),
]
# 将三元组转换为PyKEEN可处理的格式
tf = TriplesFactory.from_labeled_triples(triples=triples,create_inverse_triples=False # 是否生成反向三元组(如用于对称关系)
)
那么triples、triples_factory有啥差别呢:
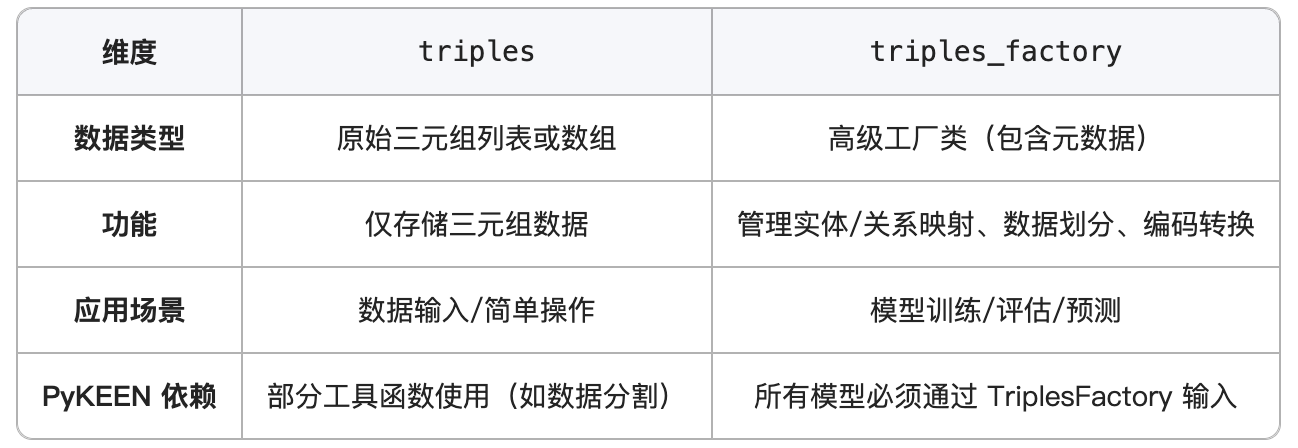
其中triples_factory有什么重要属性呢?
# tf相关的属性,包括实体个数,关系数量,三元组个数
tf.num_entities, tf.num_relations, tf.num_triples
> (19, 8, 20)#tf中实体的词云
tf.entity_word_cloud()# 关系的词云
tf.relation_word_cloud()# 实体ID与Label
tf.entity_id_to_label.values()
> {0: '4K_Monitor_27inch',1: 'Consumer_ChenXin',2: 'Consumer_LiNa',3: 'Consumer_WangQiang',4: 'Consumer_ZhangWei',5: 'Diamond_Exclusive_Gift',6: 'Electronics',7: 'Gold_Member_Discount',8: 'High_End',9: 'In_Stock',10: 'Laptop_Pro15',11: 'Platinum_Free_Shipping',12: 'Silver_Coupon_100',13: 'Smartphone_X',14: 'SoundMaster',15: 'Store_Beijing_Chaoyang',16: 'Store_Guangzhou_Tianhe',17: 'Store_Shanghai_Pudong',18: 'Wireless_Earbuds'}# 关系的ID与Label
tf.relation_id_to_label
> {0: 'brand',1: 'buys',2: 'category',3: 'price_range',4: 'purchased_at',5: 'sells_with_privilege',6: 'stock_status',7: 'uses_privilege'}
2.2 模型训练
2.2.1 训练信息
一般来说最好使用以下三款模型:
TransE、ConvE、RotatE
以上三款可以后续比较顺利使用predict函数
results = pipeline(training=training,testing=testing,model="RotatE",training_kwargs=dict(num_epochs=100),random_seed=1235,device="cpu",
)# 模型一些具体信息
results.model# 训练集一些基本信息
results.training
# results.testing # 没有这个属性其中一些训练过程可以保存,包括loss的图:
import matplotlib.pyplot as plt
# 训练loss结果展示
results.plot_losses()
plt.show()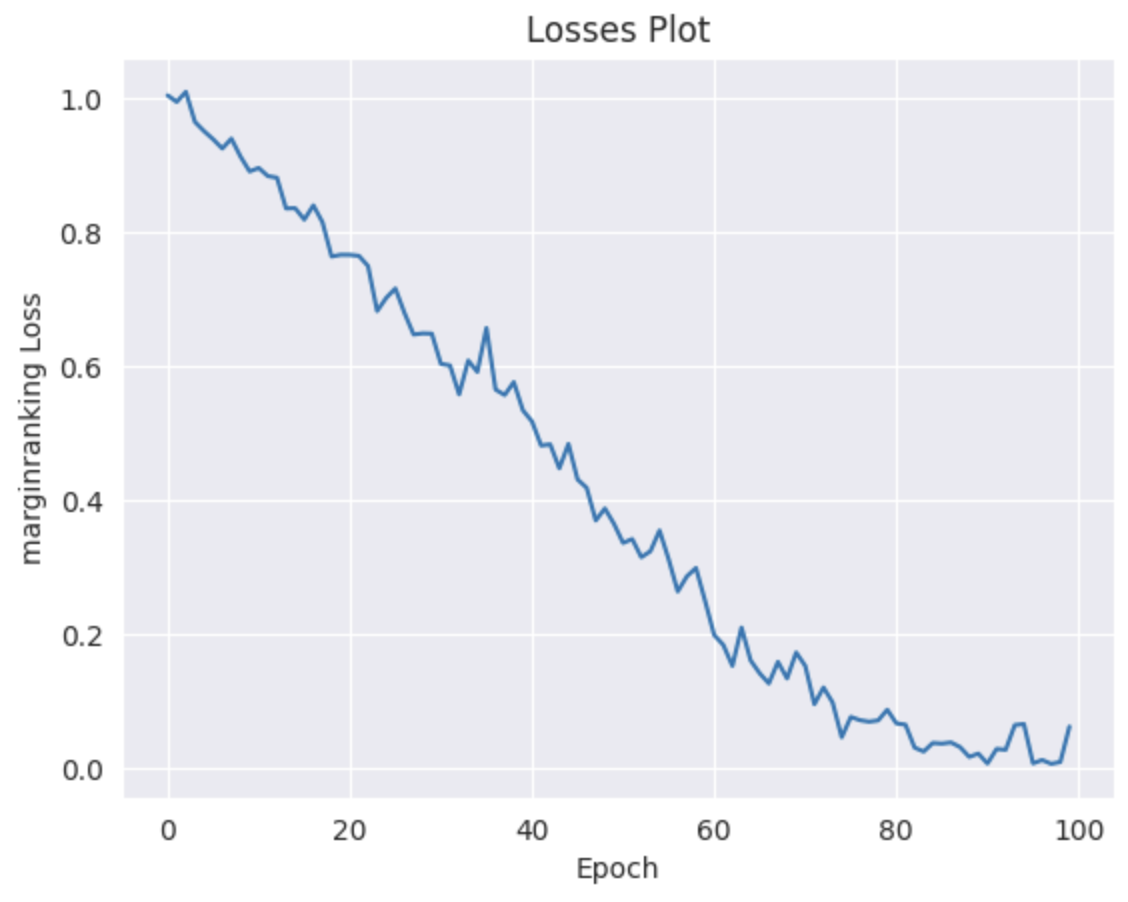
2.2.2 TransE模型可以降维实体、关系的关系
results_te = pipeline(training=training,testing=testing,model="TransE",model_kwargs=dict(embedding_dim=2),training_kwargs=dict(use_tqdm_batch=False),evaluation_kwargs=dict(use_tqdm=False),random_seed=1,device="cpu",
)
results_te.plot(er_kwargs=dict(plot_relations=True))笔者测试了TransE可以显示图,但是RotatE无法显示图
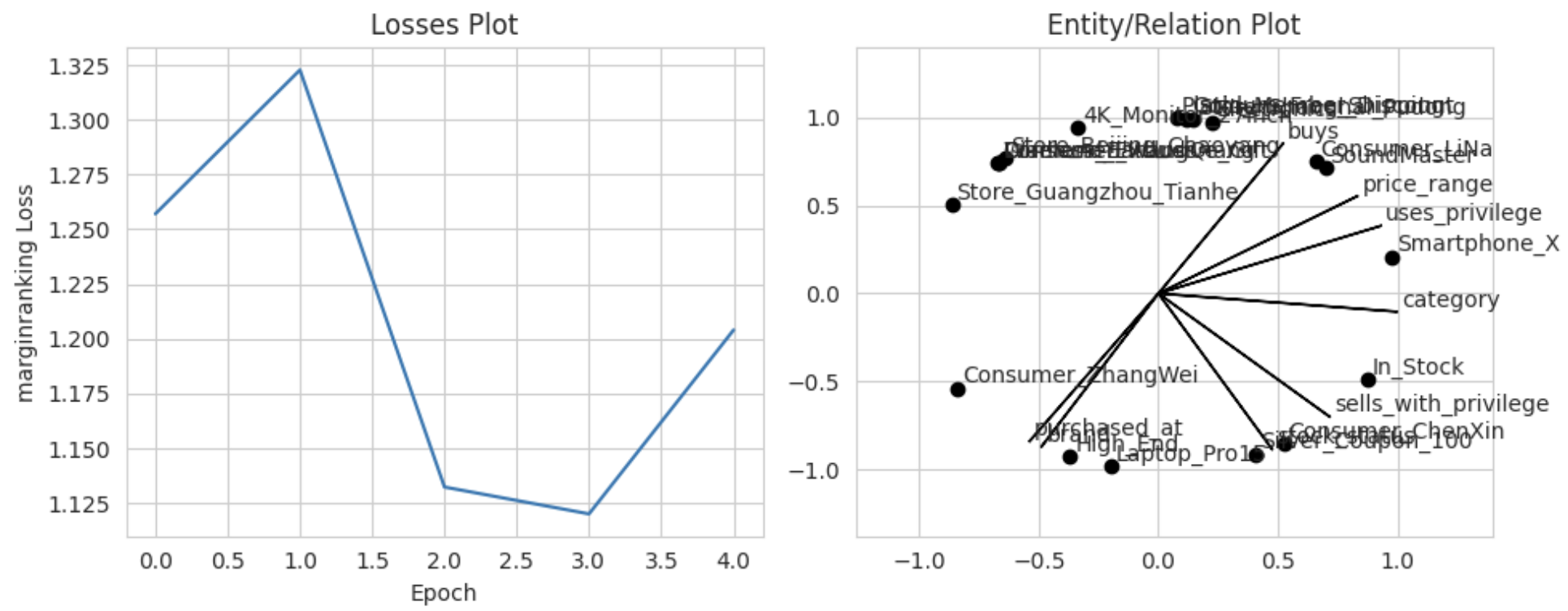
2.3 模型保存与加载、评估
2.3.1 保存与模型加载
有几种保存状态,第一种一股脑把所有东西都保存到文件里面:
# 模型保存
results.save_to_directory("Consumer_results")
这个文件夹里面有很多东西,
如果单独模型保存与加载,参考下面需要通过load_state_dict,这个在example没有,是笔者到源码里面挖出来。下述代码是可以成功执行的:
# 来自:https://github.com/pykeen/pykeen/blob/42bfa99a17ee489d0d54dc6332d5cc71fc0ded08/docs/source/tutorial/troubleshooting.rst#L47import torch
# 保存
torch.save(results.model.state_dict(), "test.pt")# 加载模型
from pykeen.models import RotatE
model = RotatE(triples_factory=tf)
state_dict = torch.load("test.pt")
model.load_state_dict(state_dict)
2.3.2 评估
评估指标反映了知识图谱嵌入模型的性能
衡量模型在链接预测任务中的表现(例如预测缺失的头实体、关系或尾实体)
优先关注 Filtered Hits@10 和 MRR,这两个指标综合反映了模型的精度和泛化能力
模型的评估指标有非常多:
results.metric_results.to_df()
pykeen一下给了非常多的指标,报错:
{'adjusted_arithmetic_mean_rank','adjusted_arithmetic_mean_rank_index','adjusted_geometric_mean_rank_index','adjusted_hits_at_k','adjusted_inverse_harmonic_mean_rank','arithmetic_mean_rank','count','geometric_mean_rank','harmonic_mean_rank','hits_at_1','hits_at_10','hits_at_3','hits_at_5','inverse_arithmetic_mean_rank','inverse_geometric_mean_rank','inverse_harmonic_mean_rank','inverse_median_rank','median_absolute_deviation','median_rank','standard_deviation','variance','z_arithmetic_mean_rank','z_geometric_mean_rank','z_hits_at_k','z_inverse_harmonic_mean_rank'}
其中解读几个
Mean Rank (MR)
正确实体在预测结果中的平均排名。
- 计算方式:对所有测试三元组,计算正确实体在预测列表中的排名(从1开始计数),取平均值。
- 解读:值越小越好,但容易受长尾效应影响(例如某个正确实体排名极低会显著拉高均值)。
- Adjusted Mean Rank (AMR):
- 对 Mean Rank 的修正版本,避免因数据集规模差异导致结果不可比
- 计算方式:将原始排名除以实体总数,再取平均。
- 解读:标准化后的指标,值越小越好,常用于跨数据集对比。
Mean Reciprocal Rank (MRR)
正确实体排名的倒数均值,衡量模型快速定位正确实体的能力。
- 计算方式:对每个三元组的正确实体排名取倒数(如排名第2则得分为1/2),再取所有得分的平均值。
- 解读:值越接近1越好,常用于推荐系统和问答场景。
Hits@k
- 含义:正确实体出现在预测结果前k位的比例。
- 常见变种:
- Hits@1:正确实体排名第1的比例(最高精度)。
- Hits@3:正确实体在前3名中的比例。
- Hits@10:正确实体在前10名中的比例(最宽松的评估)。
- 解读:值越大越好,反映模型在不同精度需求下的稳定性。adjusted_hits_at_k,越接近1越好!
2.4 模型预测
在文档中Predict 有比较详细的介绍
pykeen.predict.predict_triples()可用于计算给定三元组集的分数。pykeen.predict.predict_target()可用于对给定预测目标的选择进行评分,即根据另外两个实体计算头部实体、关系或尾部实体的分数。pykeen.predict.predict_all()可以用来计算所有可能三元组的得分。从科学角度来看,pykeen.predict.predict_all()在可以通过实验测试和验证预测的场景中,这是最有趣的。
每个模型的实现方式是:分数越高(或分数越小),三元组为真的可能性就越大。
2.4.1 链接预测或关系预测 - predict_target
最适用的模式
from pykeen import predict
user = "Consumer_ChenXin"
relation = 'purchased_at'if user in tf.entity_id_to_label.values():if relation in tf.relation_id_to_label.values():# 确保在tf的实体名单之中res = predict.predict_target(model=results.model, head=user,\relation=relation, triples_factory=tf).dfelse:print(f'{relation} not in relation.')
else:print(f'{user} not in entity.')res
设置预测实体与关系,然后根据模型给出最可能的三元组,具体返回:
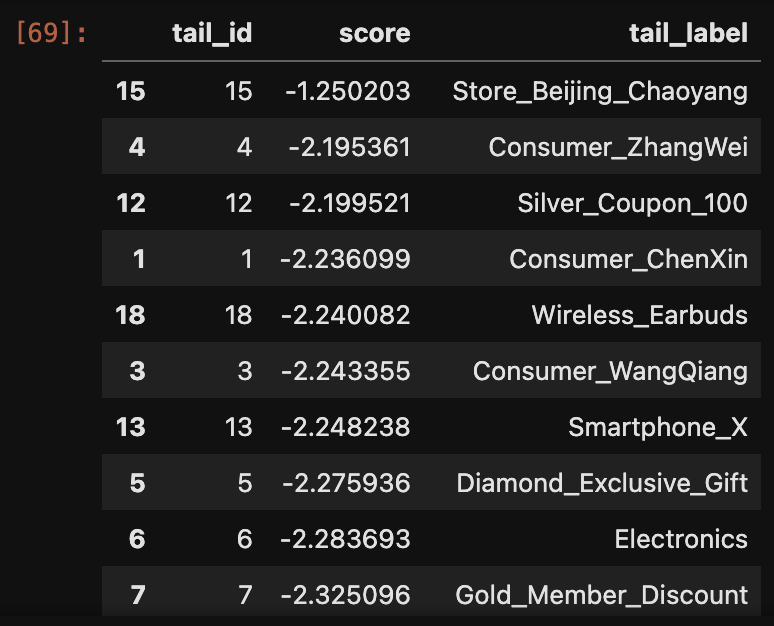
可以看到用户Consumer_ChenXin最可能去purchased_at购买的是Store_Beijing_Chaoyang,是符合要求 的
2.4.2 新三元组可能性预测 - predict_triples
最复杂、最不准、很难解读的一个预测函数了。
一个模型的三元组的得分不能与另一个模型的三元组的得分进行比较
from pykeen import predict
predict.predict_triples(model=results.model, triples_factory=tf).process(factory=tf).df.sort_values(by=['score','head_label'], ascending=False)
# 与上述结果相同triples 、 triples_factory功效相同
from pykeen import predict
predict.predict_triples(model=results.model, triples=tf).process(factory=tf).df.sort_values(by=['score','head_label'], ascending=False)
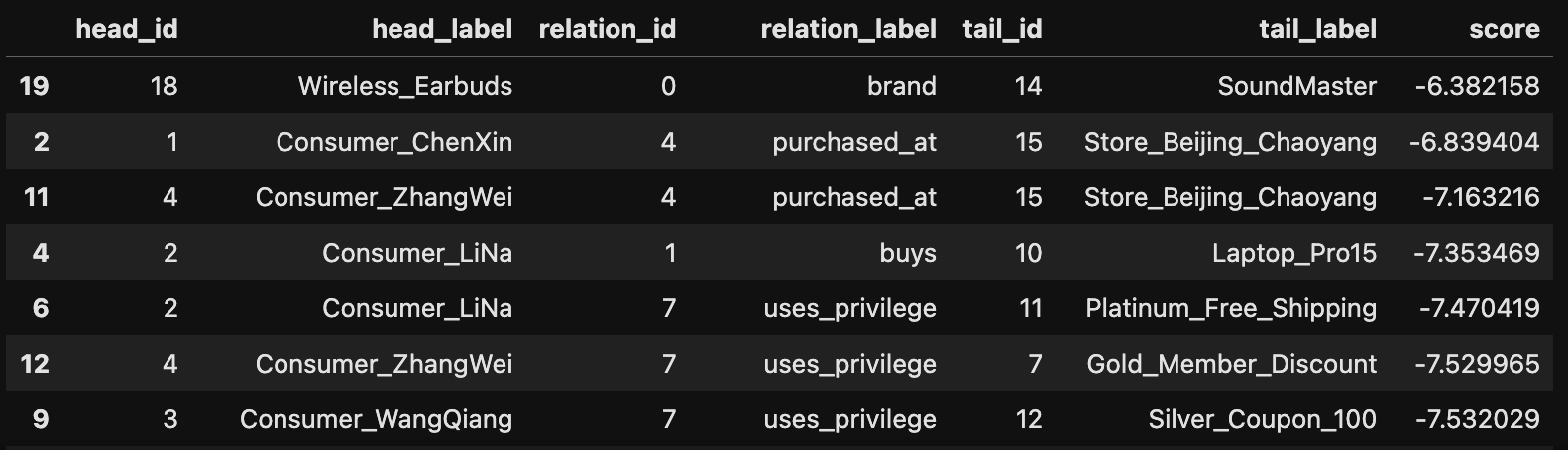
这个是用本篇的原始的数据进行预测:
pre_data = np.array([# 消费者与会员权益关联("Consumer_ZhangWei", "uses_privilege", "Gold_Member_Discount"),("Consumer_ZhangWei", "uses_privilege", "Platinum_Free_Shipping"), # 错误("Consumer_ZhangWei", "uses_privilege", "D"),# 大错特错,实体根据没有("Consumer_LiNa", "uses_privilege", "Platinum_Free_Shipping"),("Consumer_WangQiang", "uses_privilege", "Silver_Coupon_100"),("Consumer_ChenXin", "uses_privilege", "Diamond_Exclusive_Gift"),
])
pre_data_f = TriplesFactory.from_labeled_triples(triples=pre_data,create_inverse_triples=False # 是否生成反向三元组(如用于对称关系)
)predict.predict_triples(model=results.model, triples=pre_data_f).process(factory=pre_data_f).df然后我单独截取一部分三元组并进行预测,可以得到:
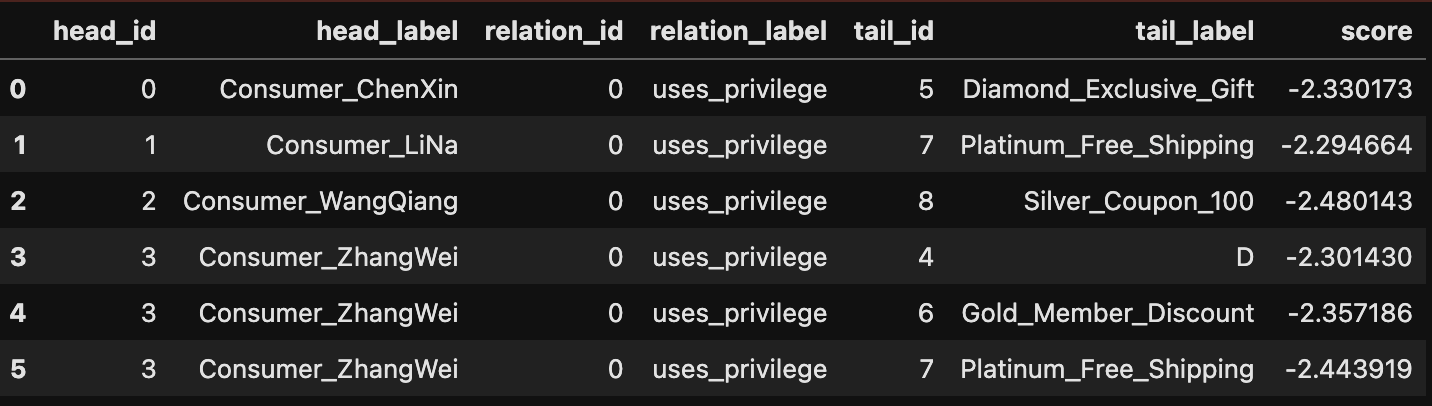
可以看到:
- 同一个三元组与之前的score不同
- 三元组出现未知的实体也会给出预测
- 笔者构造了一些错误的三元组,但是此时model预测失效一般,不准
- 其中,
factory=pre_data_f这个过程只不过是在给id添加label,所以factory=pre_data_f与设置factory=tf会是两个结果 - 大概可以推断,预测的本质是基于ID进行预测,所以笔者以上的操作手法应该是不对的
当然,笔者还没探索完,感觉使用predict_triples的姿势不对
以下有一些会报错的用法:
pre_data = np.array([
("Consumer_ZhangWei", "uses_privilege", "Gold_Member_Discount"),("Consumer_ZhangWei", "uses_privilege", "Platinum_Free_Shipping"),("Consumer_LiNa", "uses_privilege", "Platinum_Free_Shipping"),("Consumer_WangQiang", "uses_privilege", "Silver_Coupon_100"),("Consumer_ChenXin", "uses_privilege", "Diamond_Exclusive_Gift")
])
pre_data_f = TriplesFactory.from_labeled_triples(triples=pre_data,create_inverse_triples=False # 是否生成反向三元组(如用于对称关系)
)predict.predict_triples(model=results.model, triples_factory=pre_data_f).process(factory=tf).df
# .process(factory=tf) 就是根据ID把label翻译出来
会报错:
ValueError: If triples are not ID-based, a triples factory must be provided and label-based.
2.4.3 全三元组可能性预测 - predict_all
此操作的开销可能过高,并且模型可能会对训练过程中从未见过的实体/关系组合产生额外的、校准不良的得分。
predict.predict_all(model=results.model,k=100,target = 'tail').process(factory=tf).df.sort_values(by=['tail_label','relation_label'], ascending=False)predict.predict_all(model=results.model).process(factory=tf).df.sort_values(by=['tail_label','relation_label'], ascending=False)可以看到这个预测模式非常消耗计算量,相当于把实体-关系,所有的都排列组合,计算可能性,可以看到这里的组合非常多
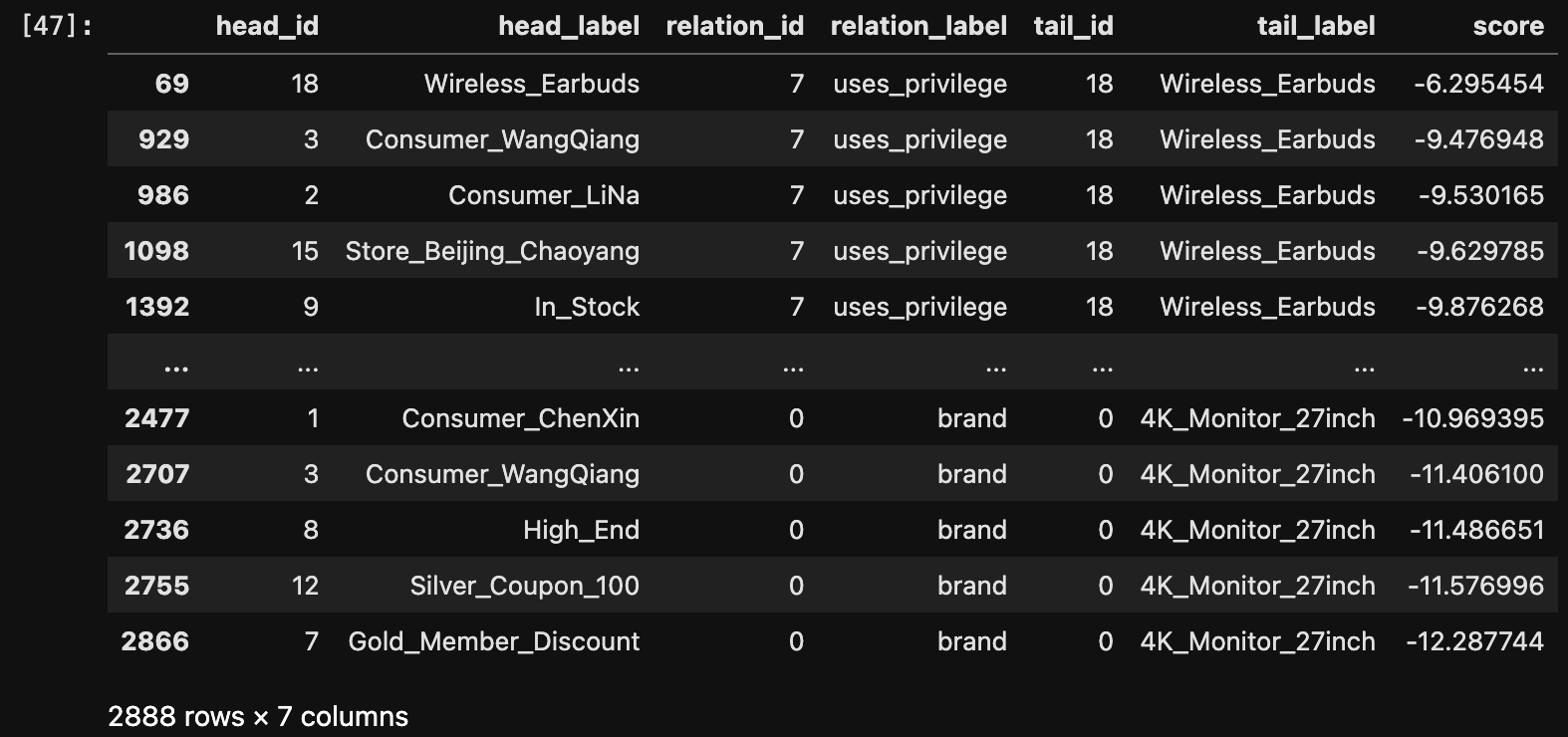
其中参数:
- k,显示前topk行
2.4.4 其他预测
文档中Predict 还有很多其他预测函数:
model.get_all_prediction_df
model.get_prediction_df
model.get_head_prediction_df
model.get_relation_prediction_df
model.get_tail_prediction_df
会出现报错:
'TransE' object has no attribute 'get_prediction_df'
RotatE object has no attribute 'get_prediction_df'
也是不确定哪些才可以使用了