Ceph 原理与集群配置
一、Ceph 工作原理
1.1.为什么学习 Ceph?
在学习了 NFS 存储之后,我们仍然需要学习 Ceph 存储。这主要是因为不同的存储系统适用于不同的场景,NFS 虽然有其适用之处,但也存在一定的局限性。而 Ceph 能够满足现代分布式、大规模、高可靠存储架构的要求。
NFS 主要适用于简单文件共享的轻量场景,它就像是一个小型的共享仓库,适合几个人或者小团队之间简单地共享一些文件。但当我们面临大规模的数据存储、需要高度可靠的数据保护以及分布式的存储架构时,NFS 就显得力不从心了。
Ceph 则解决了大规模、高可靠、分布式存储的复杂需求。在现代数据密集型业务中,如云计算、大数据、AI 等领域,数据量巨大且对存储的可靠性和扩展性要求极高。学习 Ceph 可以让我们掌握应对这些复杂场景的核心技术,弥补 NFS 在扩展性、功能丰富度、可靠性上的不足,使我们能够适应技术发展的趋势。
1.2.什么是 Ceph⭐
Ceph 是实现优性能、可靠性、可扩展性的存储系统,具有 “统一的” 和 “分布式” 两大特性:
-
“统一的”:Ceph 一套存储系统可同时提供对象存储、块存储、文件系统存储三种功能。
-
“分布式”:Ceph 是无中心结构,无中心结构就是 Ceph 集群,无论访问集群中的哪一个节点,都能访问整个 Ceph 结构,理论上具备无限可扩展性。
1.3.Ceph 系统层次⭐
自下而上,四个层次
-
RADOS:基础存储系统(可靠的、自动化的、分布式的对象存储)
-
Cluster map:它是记录全局系统状态的数据结构,由以下两个部分组成:
-
OSD:数量众多,是数据存储和维护的核心。本质上,它是安装了操作系统和文件系统的计算机,每个 OSD 拥有自己的 OSD deamon,用于完成 OSD 的逻辑功能。同时,它还会与 Monitor 以及其他 OSD 进行通信,以完成数据的存储和维护。可以把 OSD 想象成一个个具体的小仓库,负责实际存放货物(数据)。
-
Monitor:主要负责状态检测和维护。它就像仓库的管理员,时刻关注着各个小仓库(OSD)的状态,确保整个仓库网络的正常运行。
-
-
-
LIBRADOS:基础库,为上层应用提供了访问 RADOS 的接口。可以把它看作是连接上层应用和底层存储系统的桥梁。
-
RADOS GW、RBD、Ceph FS:高层应用接口,分别对应对象存储、块存储和文件系统存储的接口。不同的应用可以通过这些接口来使用 Ceph 提供的不同存储功能。
-
应用层:使用 Ceph 存储服务的各种应用程序。
1.4.寻址流程⭐
Ceph 通过三次映射实现了从文件到底层存储设备的高效、可靠寻址,具体如下:
-
File(文件)→ Object(对象)映射:将用户操作的文件切分成固定大小(由 RADOS 限定,如 2MB 或 4MB)的对象。这样做有两个好处:一是让大小不限的文件变为易于 RADOS 管理的统一尺寸对象,就像把不同大小的货物打包成统一规格的箱子;二是将对单一文件的串行处理转换为对多个对象的并行处理,提升了效率。
-
Object(对象)→ PG(归置组)映射:通过哈希算法将对象映射到 PG。一个对象只能映射到一个 PG,而一个 PG 可管理多个对象(如数千个甚至更多),实现对对象存储的逻辑组织。可以把 PG 看作是一个个货架,对象就像放在货架上的商品。
-
PG(归置组)→ OSD(对象存储设备)映射:利用 CRUSH 算法,将 PG 以多副本(通常为 3 副本)形式映射到不同的 OSD 上。这样每个 PG 的数据会分布到多个 OSD 存储,实现数据冗余备份、高可用及负载均衡,确保系统的可靠性和稳定性。就像把货架上的商品复制多份,分别存放在不同的小仓库中,即使某个小仓库出现问题,也不会影响商品的正常使用。
1.5.数据写入流程
Ceph 数据写入流程基于三次映射(File → Object → PG → OSD),具体如下:
-
File 切片为 Object:用户写入的文件先被切分为固定大小的 Object(如 4MB),这是 Ceph 存储的最小单元,便于管理和并行操作。
-
确定存储位置:通过哈希 HASH 算法将 Object 映射到 PG(归置组),再利用 CRUSH 算法根据集群拓扑(如机架、机房等)将 PG 映射到多个 OSD(通常为 3 个,形成三副本)。这样可以确保数据的安全性和可靠性。
-
客户端与 OSD 通信
-
客户端通过 CRUSH 算法知道目标 OSD(包含主 OSD 和从 OSD),将数据发送给主 OSD。
-
主 OSD 接收数据后,会将数据同步到从 OSD。
-
当所有从 OSD 成功接收数据并向主 OSD 确认后,主 OSD 才将数据持久化写入本地,并向客户端返回写入成功的确认。
-
1.6.集群维护
-
在 Ceph 集群维护中,Monitor 负责汇总集群状态并形成 cluster map,随后将其扩散至所有 OSD 和 Client。OSD 利用 cluster map 进行数据维护,Client 借助 cluster map 实现数据寻址。
-
需注意的是,Monitor 不会主动轮询 OSD 状态,而是由 OSD 主动向 Monitor 上报自身状态(如新增 OSD 加入集群,或检测到自身 / 其他 OSD 异常时)。
-
Monitor 收到上报信息后更新 cluster map 并再次扩散,确保集群内各组件掌握最新的集群状态,保障 Ceph 集群的正常运行与数据处理。
-
简言之,通过 “OSD 主动上报状态 → Monitor 汇总更新 cluster map → 扩散至全体 OSD 和 Client” 的流程,实现集群状态的同步与维护,支撑 OSD 和 Client 的数据操作。
1.7.新增 OSD
新增 OSD:
-
首先与 monitor 通信,monitor 将其加入 cluster map,设置状态 up 或者 out,将最终版的 cluster map 发给 OSD。
-
(新增 OSD 就像是在仓库网络中添加一个新的小仓库,需要先告知管理员(Monitor),管理员将其信息记录到仓库地图(cluster map)中,并设置其状态,然后将更新后的地图发给其他小仓库(OSD))
恢复 OSD:
-
Ceph 的自动化故障恢复指当 OSD 故障时,系统自动检测并通过 CRUSH 算法将故障节点上的数据副本重新分布到其他正常 OSD 上以维持副本数,故障节点修复后自动纳入集群并重新平衡数据,全程无需人工干预。
-
(这就像当某个小仓库出现问题时,系统会自动将里面的货物转移到其他小仓库,等这个小仓库修好后,再将货物重新分配回来)
负载均衡 OSD:
-
新 OSD 替换旧 OSD,复制换数据后,新 OSD 被置为 up 且 in 状态,旧 OSD 退出该 PG,cluster map 数据更新。
-
(这就像用一个新的小仓库替换旧的小仓库,将旧仓库里的货物复制到新仓库,然后让旧仓库退出相应的货架管理,同时更新仓库地图)
自动化故障探测:
-
OSD 走动监测状态,包括自身问题和其他 OSD 问题,自动上报 monitor,monitor 把有问题 OSD 状态设置为 down 且 in,如果不能自动恢复则设置为 down 且 out,如果能自动恢复则设置为 up 且 in。
-
(这就像每个小仓库都有一个自我检测装置,发现问题后会及时告知管理员,管理员根据情况对小仓库的状态进行调整)
二、配置 Ceph 集群
-
配置要求
-
硬件要求:RHEL 9 三台主机,每台主机需要 4G 内存,并添加两块 50G 硬盘。
-
系统设置:关闭防火墙、SELinux,以避免对 Ceph 集群的通信和运行造成干扰。
-
2.1.准备工作
配置 hosts 解析。
目的:是为了让各个主机能够通过主机名相互识别和通信,就像给每个小仓库都取了一个容易记住的名字,方便大家交流。
cat >> /etc/hosts << EOF
192.168.67.121 ceph-master
192.168.67.122 ceph-node1
192.168.67.123 ceph-node2
EOF时间同步,因为 Ceph 时间要求同步到 0.05s 之内,所以对时间要求很严格。
时间同步对于 Ceph 集群非常重要,因为各个组件之间的通信和数据处理需要基于统一的时间标准。如果时间不同步,可能会导致数据不一致、状态判断错误等问题。
yum install bash-completion vim tree psmisc wget tar net-tools lrzsz -y
yum install chrony -y
sed -i 's/^pool.*/pool ntp1.aliyun.com iburst/g' /etc/chrony.confsystemctl enable --now chronyd
systemctl restart chronyd
chronyc sources
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* 120.25.115.20 2 6 33 5 -1993ns[ -126us] +/- 17ms
2.2.cephadm 配置 Ceph
2.2.1.安装 docker-ce
安装 Docker-ce 是为了构建 Docker 软件仓库,用于下载 Docker。Docker 可以为 Ceph 组件提供一个隔离的运行环境,避免本地环境依赖问题。
cat >> /etc/yum.repos.d/docker.repo << EOF
[docker]
name=docker
baseurl=https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/rhel/9.3/x86_64/stable/
gpgcheck=0
EOF安装 Docker-ce。
yum install docker-ce -y配置 Docker 加速器。
cat >> /etc/docker/daemon.json << EOF
{"registry-mirrors": ["https://docker.m.daocloud.io","https://hub-mirror.c.163.com","https://mirror.baidubce.com","https://docker.nju.edu.cn","https://register.liberx.info","https://mirror.ccs.tencentyun.com","https://2i1r7dqv.mirror.aliyuncs.com"]
}
EOF
2.2.2.安装 cephadm
准备 ceph 的 yum 源,以便后续安装 cephadm。
cat >> /etc/yum.repos.d/ceph.repo << EOF
[ceph]
name=ceph x86_64
baseurl=https://mirrors.aliyun.com/ceph/rpm-squid/el9/x86_64
enabled=1
gpgcheck=0
[ceph-noarch]
name=ceph noarch
baseurl=https://mirrors.aliyun.com/ceph/rpm-squid/el9/noarch
enabled=1
gpgcheck=0
[ceph-source]
name=ceph SRPMS
baseurl=https://mirrors.aliyun.com/ceph/rpm-squid/el9/SRPMS
enabled=1
gpgcheck=0
EOF安装 Python3,因为 cephadm 依赖 Python3。
yum install python3 -y在 ceph-master 主机上安装 cephadm(其他两台主机不需要安装)。
cephadm 是 Ceph 官方提供的集群管理工具,支持自动化部署、扩容、监控,仅需在管理节点(如 ceph-master)安装。
yum install cephadm -y
2.2.3.初始化 ceph 集群
在 ceph-master 主机上初始化 ceph 集群。
cephadm --docker bootstrap \
--mon-ip 192.168.67.121 \
--initial-dashboard-user admin \
--initial-dashboard-password redhat \
--dashboard-password-noupdate \
--allow-fqdn-hostname-
--docker:使用 Docker 运行 Ceph 组件(mon、mgr 等),避免本地环境依赖问题。
-
--mon-ip:指定第一个 Monitor 节点的 IP(集群核心组件,负责维护集群状态)。Monitor 就像仓库的管理员,需要有一个固定的地址来进行管理和通信。
-
--initial-dashboard-user/password:设置 Web 管理界面(Ceph Dashboard)的初始登录凭证,方便我们通过 Web 界面来管理和监控 Ceph 集群。
-
--dashboard-password-noupdate:禁止 Dashboard 自动更新密码(生产环境可选)。
-
--allow-fqdn-hostname:允许使用主机名(非 IP)进行节点识别,兼容后续可能的 DNS 配置。
2.2.4.扩展 ceph 集群
集群扩容,拷贝公钥到 node 节点。
将 ceph-master 的 SSH 公钥(ceph.pub 由 cephadm 自动生成)添加到 node 节点,实现无密码登录,便于后续远程管理和部署 OSD 等组件。这就像给管理员一把万能钥匙,可以直接打开各个小仓库的门。
ssh-copy-id -f -i /etc/ceph/ceph.pub ceph-node1
ssh-copy-id -f -i /etc/ceph/ceph.pub ceph-node2添加节点集群。
cephadm shell ceph orch host add ceph-node1
cephadm shell ceph orch host add ceph-node2-
cephadm shell:进入 cephadm 命令行环境,获取集群管理权限。
-
ceph orch host add:将节点(ceph-node1/2)加入集群,以便后续分配 OSD、mon 等组件。这就像把新的小仓库加入到仓库网络中。
2.2.5.配置 ceph 集群
安装 ceph-common 的核心价值在于:
-
提供访问 Ceph 集群的必要工具(如 ceph、rbd 等命令)。
-
支持应用程序与 Ceph 集成(通过客户端库)。让其他应用程序能够方便地使用 Ceph 提供的存储服务。
-
简化集群配置与管理(自动加载配置文件、认证信息)。减少我们手动配置的工作量。
如果仅作为存储客户端(如挂载 CephFS 或使用 RBD 卷),ceph-common 是必需的;若作为集群管理员,则更依赖此包提供的完整工具链。
# 配置 epel 源
yum install -y https://mirrors.aliyun.com/epel/epel-release-latest-9.noarch.rpm
# 安装 ceph-common
yum install ceph-common -y添加 osd 磁盘设备。
为每个节点的两块硬盘(/dev/sdb、/dev/sdc)创建 OSD 服务,OSD 是 Ceph 的核心存储单元,负责实际数据的存储和管理。添加 OSD 就像在各个小仓库中增加更多的存储空间,以满足不断增长的数据存储需求。
ceph orch daemon add osd ceph-master:/dev/sdb
ceph orch daemon add osd ceph-master:/dev/sdc
ceph orch daemon add osd ceph-node1:/dev/sdb
ceph orch daemon add osd ceph-node1:/dev/sdc
ceph orch daemon add osd ceph-node2:/dev/sdb
ceph orch daemon add osd ceph-node2:/dev/sdc设置管理节点。
标记 ceph-master 为管理节点(_admin 是 cephadm 的特殊标签),允许该节点执行集群管理操作(如修改配置、添加组件)。这就像指定一个仓库管理员,负责整个仓库网络的管理和协调工作。
ceph orch host label add ceph-master _admin将 mon 和 mgr 组件部署到所有节点中(高可用性)。
ceph orch apply mon "ceph-master ceph-node1 ceph-node2"
ceph orch apply mgr --placement "ceph-master ceph-node1 ceph-node2"-
部署 Monitor 组件:在三个节点上部署 Monitor 组件,通过 Paxos 算法实现选举和状态同步(奇数个节点避免脑裂,确保高可用性)。Monitor 负责维护集群的状态信息,多个 Monitor 节点可以保证在某个节点出现故障时,集群仍然能够正常运行。
-
部署 Manager 组件:在三个节点上部署 Manager 组件(Active-Standby 模式),负责集群监控、仪表盘管理、自动化策略执行,提升运维效率。Manager 就像一个智能的监控系统,实时监控集群的运行状态,并根据预设的策略进行自动化管理。
2.3.验证 ceph 集群状态
查看 ceph 健康状态。
[root@ceph-master ~]# ceph -scluster:id: 8bb910d6-2b1b-11f0-8725-000c292a6edehealth: HEALTH_OK # 健康状态 OKservices:mon: 3 daemons, quorum ceph-master,ceph-node2,ceph-node1 (age 3m) # 三个 monmgr: ceph-master.nobasm(active, since 7m), standbys: ceph-node2.femkkp, ceph-node1.rvdoat # 三个 mgrosd: 6 osds: 6 up (since 93s), 6 in (since 112s) # 六个 osddata:pools: 1 pools, 1 pgsobjects: 2 objects, 577 KiBusage: 161 MiB used, 300 GiB / 300 GiB avail # osd 一共 300 GiBpgs: 1 active+clean验证 ceph Web 页面(https://ip:8443)。
输入用户名和密码登录,显示如下界面即可。这可以让我们通过 Web 界面直观地管理和监控 Ceph 集群。
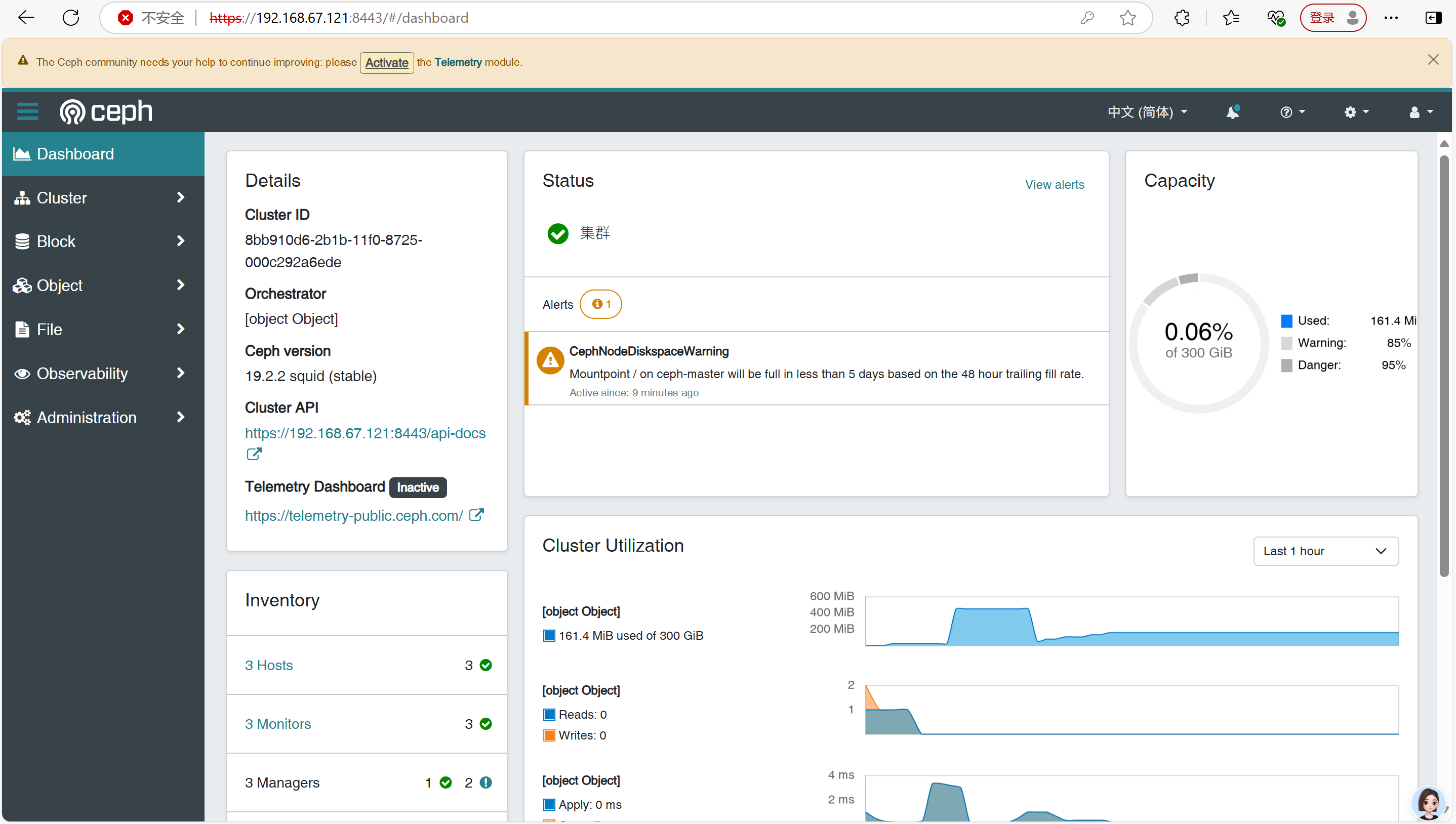
集成了 prometheus 并对接 grafna,(https://ip:3000)。
通过集成 prometheus 和 grafna,我们可以对 Ceph 集群进行更详细的监控和数据分析,及时发现和解决潜在的问题。
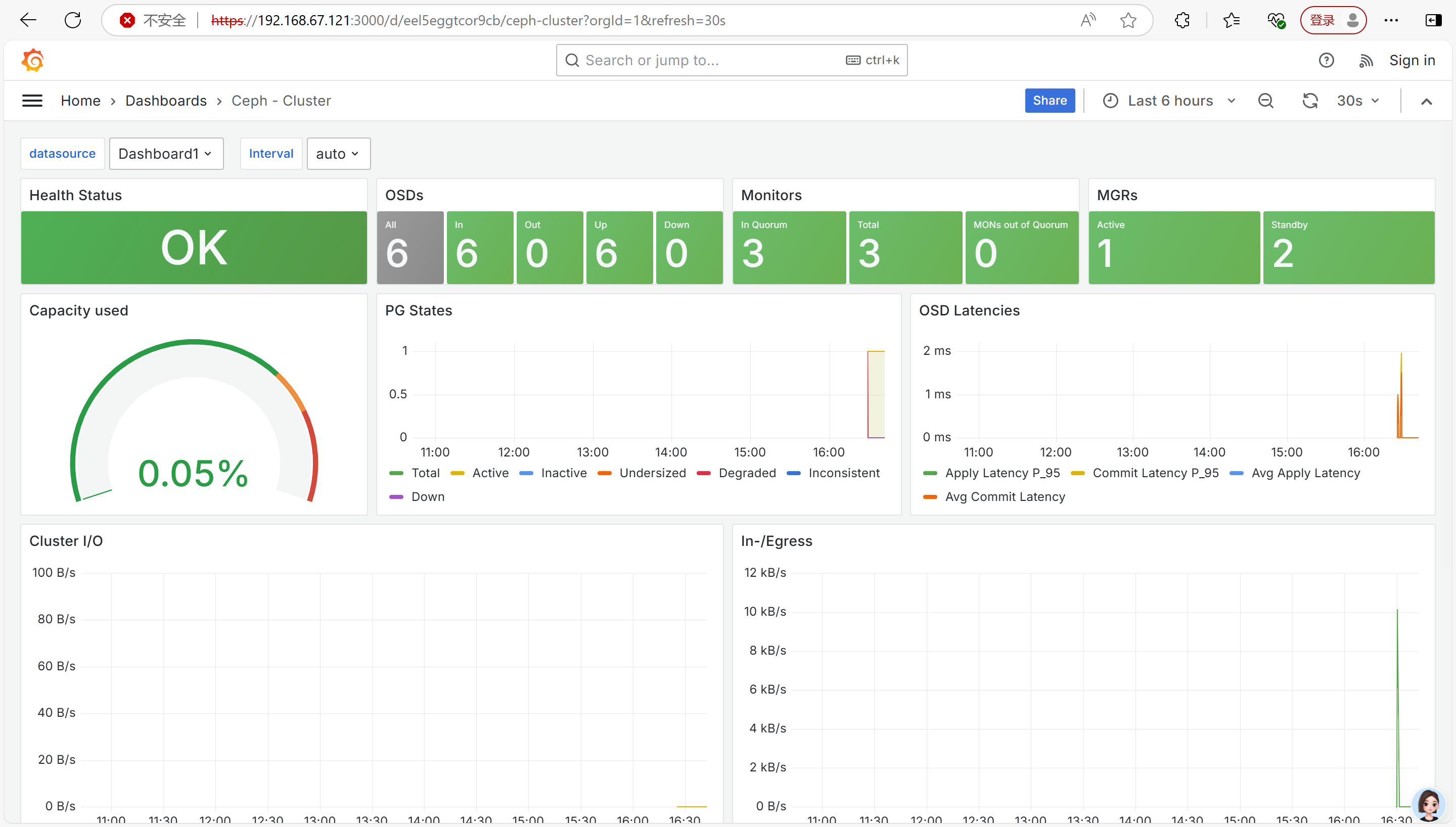
集群配置完毕。