Lora原理介绍并用Macbook air超快实现本地微调小模型
note:我认为“干中学”是AI时代最高效的掌握技能的方式,本篇文章将基于一个简单的微调示例,解释微调的相关概念以及相关工具的使用。本次实践完全参照下面这篇文章,感谢大佬让我这个大模型小白能快速试验微调
https://juejin.cn/post/7426343844595335168
微调基础概念
什么是微调?
微调是基于一个已经训练好的神经网络模型,通过对其参数进行细微调整,使其更好地适应特定的任务或数据。通过在新的小规模数据集上继续训练模型的部分或全部层,模型能够在保留原有知识的基础上,针对新任务进行优化,从而提升在特定领域的表现。
微调的划分
以下内容参考自大模型为什么需要微调?有哪些微调方式?#大模型 #微调_哔哩哔哩_bilibili
1. 按照微调参数规模划分
-
FPFT(Full Parameter Fine-Tuning)全参数微调:用预沉练模型作为初始化权重,在特定数据集上继续训练,全部参数都更新的方法
-
PEFT(Parameter Efficient Fine-Tuning)参数高效微调:用更少的计算资源完成模型参数的更新,包括只更新一部分参数,或者通过对参数进行某种结构化约束,例如稀疏化或低秩近似来降低微调的模型参数量
- 我们熟知的就有 Adapter、Lora、Qlora、P-turning等
2. 按照训练流程划分
按照大模型训练阶段进行微调,或者根据大模型微调的目标来区分,从提示微调 Prompt Tuning、
有监督微调SFT、RLHF 人类反馈强化学习的方式来划分。

其中ICL (In-Context learning)上下文学习:区别于普通微调 Fine-Tuning,不对LLMs执行任何
的微调,直接将模型的输入输出拼接起来作为一个 prompt。这也是当前 AI 应用很常见的一种方法。
3. 按照训练的方式划分
-
预训练Pre-Training:LLMs 预训练过程是无监督的(或者叫自监督的更合适),但微调过程往往是有监督的。当进行有监督微调时,模型权重会根据与真实标签的差异进行调整。
-
Supervised fine-tuningSFT:有监督微调使用有标签的数据(Label Data )来调整已经预训练的LLMS,使其更适应某一特定场景任务。
- 而我们熟悉的 Instruction Turning 其实是 SFT 的一种特殊形式。指令微调旨在增强模型理解并执行不同指令的能力。通过指令-输出对的训练,使模型能够更好地遵循人类指令,提高其在多个任务上的泛化能力。下面是其数据形式。
[{"instruction": "用简单的语言解释量子力学。","input": "",//可省略"output": "量子力学是研究微小粒子行为的科学..."},{"instruction": "将以下句子翻译成法语。","input": "你好,今天天气不错。","output": "Bonjour, il fait beau aujourd'hui."}
]
LoRA原理
由于下面的案例主要是基于 Lora 实现的,下面我将简单介绍一下 Lora 的基本原理
背景
在大模型(如 GPT、BERT 等)应用中,微调面临以下主要挑战:
- 计算资源消耗大:大模型参数量巨大,微调时需要大量的计算资源和存储空间。
- 模型性能风险:直接微调全部参数,可能会破坏预训练模型原有的泛化能力和性能。
- 存储与部署压力:每个微调版本都需存储一份完整模型,导致存储和多场景部署成本极高。
- 推理延迟增加:部分微调方法会显著增加推理时的计算量,影响模型的实时响应能力。
LoRA 的提出正是为了解决上述问题。
它通过引入低秩矩阵的方式,仅对模型中的部分参数进行高效、低成本的微调,极大减少了计算和存储开销,同时保持了模型的原始性能和推理效率。这使得大模型的微调和多场景部署变得更加高效和灵活。
预备知识——低秩矩阵分解
ps:下面内容来源于B站课程-唐国梁Tommy
低秩矩阵分解是一种将高维矩阵近似为两个低维矩阵乘积的技术,常用于数据降维、压缩、推荐系统等领域。
步骤1:理解目标
我们有一个高维矩阵 Δ W \Delta W ΔW ,希望将其近似为两个低维矩阵 A A A和 B B B的乘积,即 Δ W ≈ B A \Delta W \approx BA ΔW≈BA。
步骤2:设定矩阵维度
假设 Δ W \Delta W ΔW是一个 d × d d \times d d×d的矩阵。我们选择一个较小的整数 r r r,使得 r ≪ d r \ll d r≪d 。矩阵 A A A 的维度将是 d × r d \times r d×r ,矩阵 B B B 的维度将是 r × d r \times d r×d 。
步骤3:矩阵初始化
- 初始化矩阵 A A A 和 B B B 。可以使用随机初始化、正态分布初始化等方法。例如:
- A ∼ N ( 0 , σ 2 ) A \sim \mathcal{N}(0, \sigma^2) A∼N(0,σ2) ,表示矩阵 A A A 的每个元素都是从均值为0、方差为 σ 2 \sigma^2 σ2 的正态分布中随机抽取的。
- B B B 初始化为零矩阵,即 B = 0 B = 0 B=0 。
步骤4:矩阵乘积
- 通过矩阵乘积 B A BA BA ,可以得到一个近似的 d × d d \times d d×d 矩阵:
W ′ = B A W' = BA W′=BA
其中 W ′ ≈ Δ W W' \approx \Delta W W′≈ΔW 。
步骤5:优化和训练
- 在训练过程中,通过优化算法(如梯度下降),不断调整矩阵 A A A 和 B B B 的值,使得 W ′ W' W′ 更加接近于 Δ W \Delta W ΔW 。
- 损失函数通常是衡量 Δ W \Delta W ΔW 与 W ′ W' W′ 之间差距的一个函数,例如均方误差:
L = ∥ Δ W − B A ∥ F 2 L = \| \Delta W - BA \|_F^2 L=∥ΔW−BA∥F2
步骤6:更新规则
-
通过优化算法计算损失函数关于 A A A 和 B B B 的梯度,并更新 A A A 和 B B B 的值。例如,使用梯度下降法更新规则如下:
A ← A − η ∂ L ∂ A A \leftarrow A - \eta \frac{\partial L}{\partial A} A←A−η∂A∂L
B ← B − η ∂ L ∂ B B \leftarrow B - \eta \frac{\partial L}{\partial B} B←B−η∂B∂L
其中 η \eta η 是学习率。
LoRA详解
LoRA原理
所以LoRA假设模型参数更新矩阵(ΔW)具有低秩特性,即可以用两个更小的矩阵(A和B)的乘积来近似:
Δ W ≈ B A \Delta W \approx BA ΔW≈BA
其中,A是维度为 d × r d \times r d×r的降维矩阵,B是维度为 r × d r \times d r×d 的升维矩阵,r(秩)远小于原始维度d(例如r=8)。这使得可训练参数量从 d 2 d^2 d2减少到 2 r d 2rd 2rd,显著降低计算需求
在整个过程中,原始模型权重(W)在微调过程中完全冻结,仅训练低秩矩阵A和B。
输出叠加:模型的实际输出为原始权重与低秩调整项的结合:
h = W x + α ⋅ ( B ⋅ A x ) h = Wx + α · (B·Ax) h=Wx+α⋅(B⋅Ax)
其中,α为缩放因子,用于控制低秩调整对输出的影响幅度

其中A 是一个随机初始化的矩阵,服从正态分布;B 初始化为零矩阵。
为什么要用这种初始化方式?
(1)如果B和A全部初始化为零矩阵,缺点是很容易导致梯度消失;(2)如果B和A全部正态分布初始化,那么在模型训练开始时,就会容易得到一个过大的偏移值 Δ W \Delta W ΔW,从而引起太多噪声,导致难以收敛
选择哪些权重矩阵进行适配?
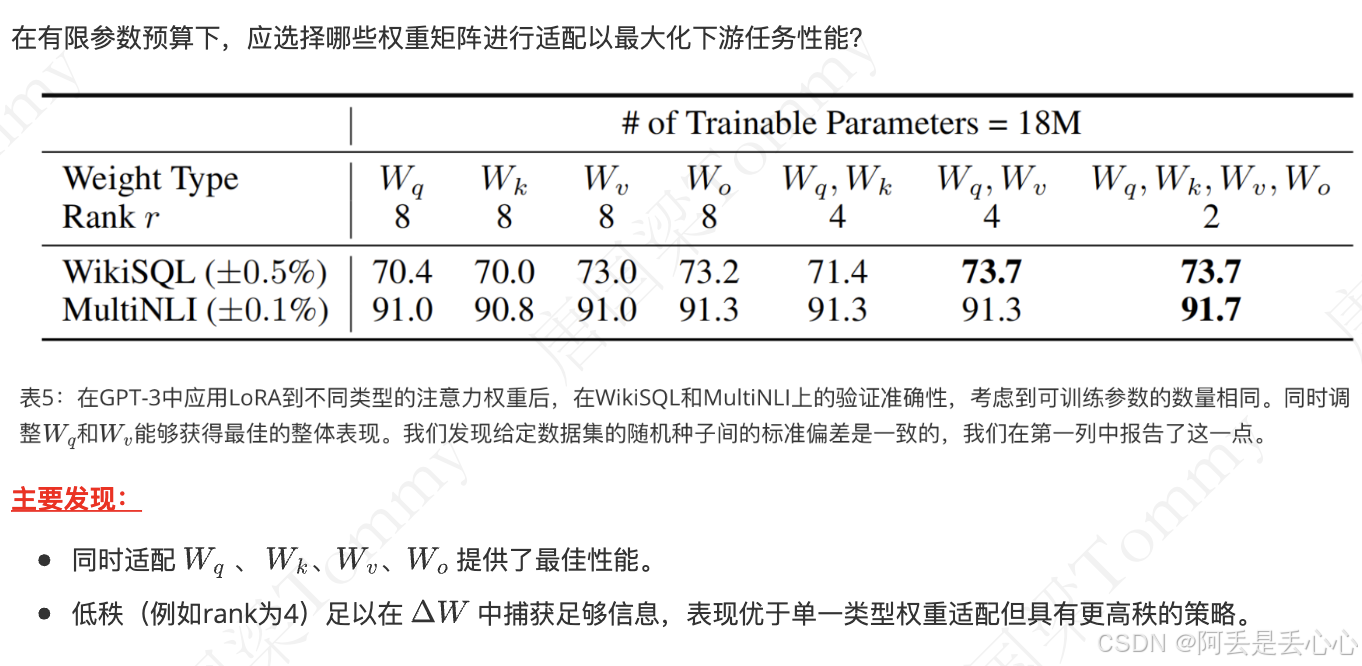
与其他微调方法对比
(1)与全量微调(Full Finetuning)的差异
- 全量微调:反向传播需计算所有参数的梯度(包括 WV),计算图和显存占用与模型规模成
正比。 - LORA:仅计算低秩矩阵的梯度,但需保留完整的计算图路径(因 W 冻结但参与前向传播),因此反向传播的计算复杂度略高于仅训练部分参数的方法(如Adapter)。
(2) 与参数高效微调(PEFT)方法的对比
- Adapter:插入小型网络模块,反向传播需计算模块内所有参数的梯度,但模块参数量通常大于LORA。
- Prefix-Tuning:仅优化前缀嵌入的梯度,不涉及权重矩阵的分解,但任务泛化性较差14。
举个简单例子





Macbook 简单微调实践
本次实践用的是MLX,MLX是由苹果的机器学习研究团队推出的用于机器学习的阵列框架,该开源框架专为 Apple Silicon 芯片而设计优化。该库允许在新的 Apple Silicon(M 系列)芯片上对 LLM 进行微调。此外,MLX 还支持使用 LoRA 、QLoRA等方法对 LLM 进行微调。
下载模型
下载一个小模型, 我的电脑是 M3 air 24G内存, 微调1.5B的小模型够了, 就选Qwen/Qwen2.5-1.5B
#安装依赖
uv pip install -U huggingface_hub
#设置环境变量
export HF_ENDPOINT=https://hf-mirror.com
#下载模型,保存至qwen2.5-0.5B目录
huggingface-cli download --max-workers 4 --resume-download Qwen/Qwen2.5-1.5B --local-dir Qwen2.5-1.5B
逐行代码解释
- 使用 uv 工具升级(或安装)huggingface_hub 这个 Python 库。
- 设置环境变量 HF_ENDPOINT,指定 Hugging Face 镜像站点为 https://hf-mirror.com。 这样做可以加速模型下载,尤其是在中国大陆访问 Hugging Face 官方站点较慢时。 该环境变量会被 huggingface_hub 及
huggingface-cli 工具自动识别和使用。- 使用 huggingface-cli 工具下载 Hugging Face 上的 Qwen2.5-1.5B 模型到本地目录。 huggingface-cli download:调用 huggingface 的命令行工具进行模型下载。
–max-workers 4:设置最多使用 4 个线程并发下载,加快速度。
–resume-download:如果下载中断,可以断点续传,避免重复下载已完成的部分。 Qwen/Qwen2.5-1.5B:指定要下载的模型仓库名称(组织/模型名)。
–local-dir Qwen2.5-1.5B:将模型文件保存到本地的 Qwen2.5-1.5B 目录下。
安装依赖与mlx
pip install mlx-lm
pip install transformers
pip install torch
pip install numpy
git clone --depth 1 https://github.com/ml-explore/mlx-examples
可以看到 mlx_example下面的目录结构
准备数据集
MLX支持三种格式的数据集
- Completion
{ “prompt”: “What is the capital of France?”, “completion”: “Paris.” }
- chat
{ “messages”: [
{
“role”: “system”,
“content”: “You are a helpful assistant.”
},
{
“role”: “user”,
“content”: “Hello.”
},
{
“role”: “assistant”,
“content”: “How can I assistant you today.”
} ] }
- text
{ “text”: “This is an example for the model.” }
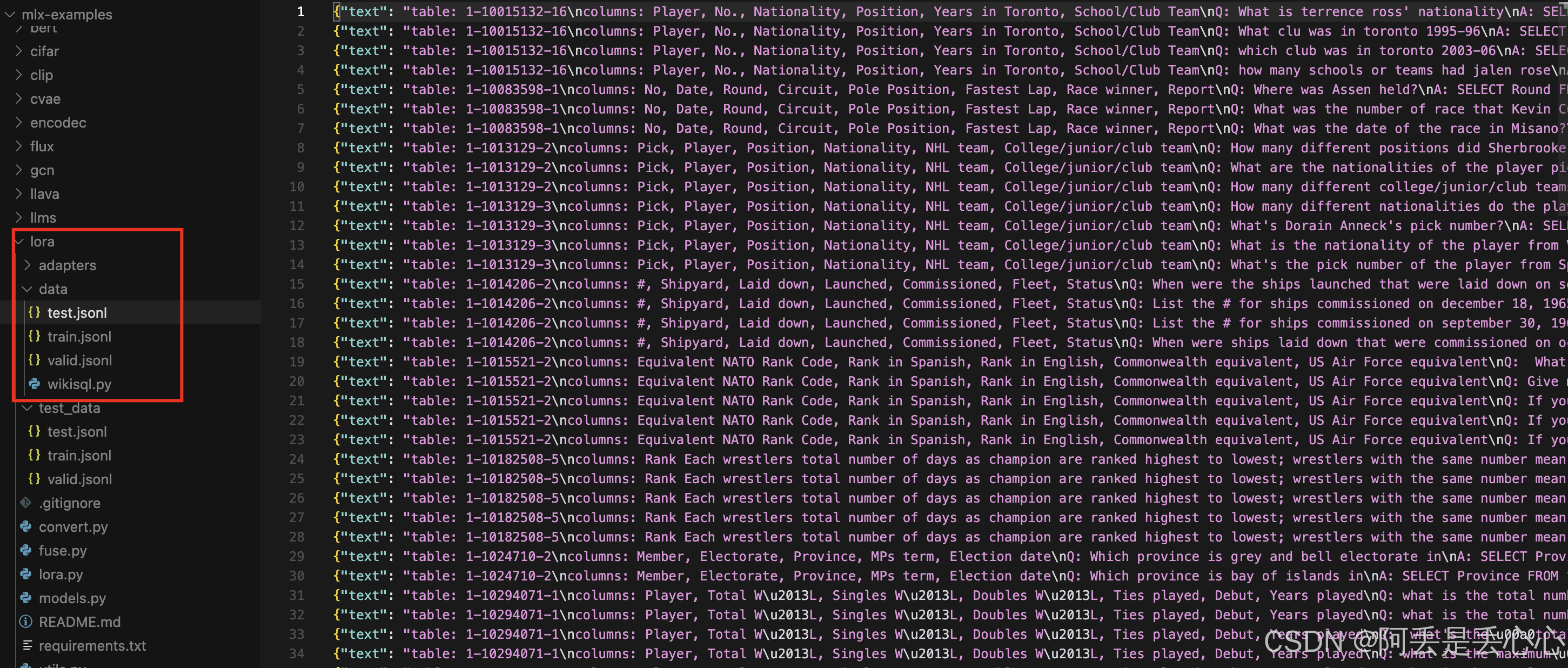
在 lora 下面自带一个数据集 就是最后一种 text 格式,看起来是实现text2sql 任务
我们可以按照第一种Completion方式准确数据
新建 test_data 数据集,输入相应文本
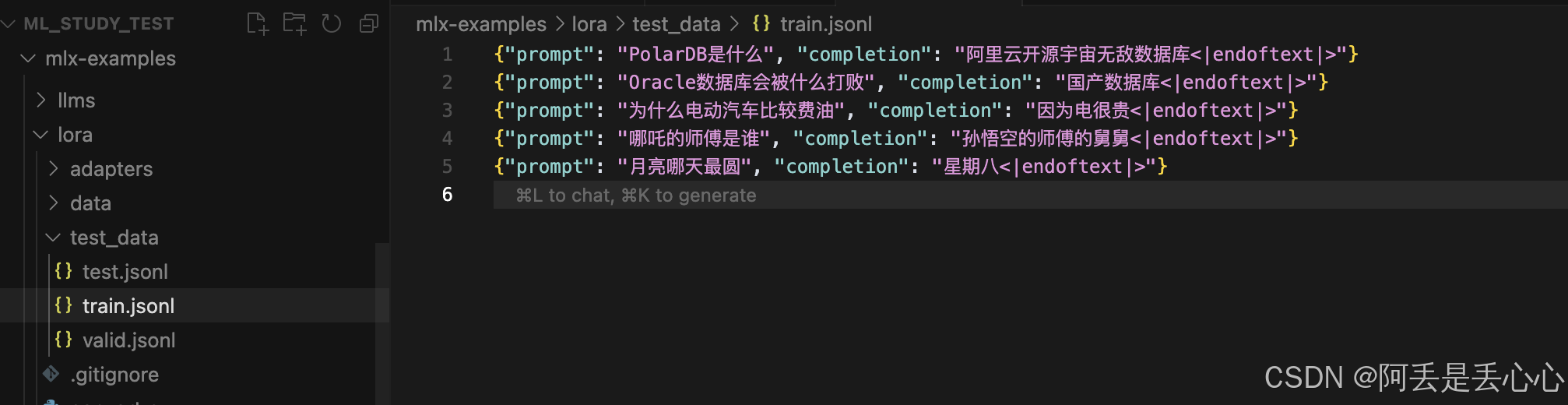
准备数据集
vi test_data/train.jsonl {"prompt": "PolarDB是什么<|endoftext|>", "completion": "阿里云开源宇宙无敌数据库<|endoftext|>"}
{"prompt": "Oracle数据库会被什么打败<|endoftext|>", "completion": "国产数据库<|endoftext|>"}
{"prompt": "为什么电动汽车比较费油<|endoftext|>", "completion": "因为电很贵<|endoftext|>"}
{"prompt": "哪吒的师傅是谁<|endoftext|>", "completion": "孙悟空的师傅的舅舅<|endoftext|>"}
{"prompt": "月亮哪天最圆<|endoftext|>", "completion": "星期八<|endoftext|>"} vi test_data/valid.jsonl {"prompt": "PolarDB是什么<|endoftext|>", "completion": "阿里云开源宇宙无敌数据库<|endoftext|>"}
{"prompt": "Oracle数据库会被什么打败<|endoftext|>", "completion": "国产数据库<|endoftext|>"}
{"prompt": "为什么电动汽车比较费油<|endoftext|>", "completion": "因为电很贵<|endoftext|>"} vi test_data/test.jsonl {"prompt": "哪吒的师傅是谁<|endoftext|>", "completion": "孙悟空的师傅的舅舅<|endoftext|>"}
{"prompt": "月亮哪天最圆<|endoftext|>", "completion": "星期八<|endoftext|>"} 微调模型
mlx_lm.lora --model ~/Documents/PythonProject/ml_study_test/Qwen2.5-1.5B --train --data ./test_data --learning-rate 1.0e-4 --val-batches -1 --batch-size 2
代码解释
–mlx_lm.lora
这是一个命令行工具(或 Python 脚本),用于对大模型进行 LoRA(低秩适配)微调。
–model ~/Documents/PythonProject/ml_study_test/Qwen2.5-1.5B
指定要微调的基础模型的路径,这里是本地的 Qwen2.5-1.5B 模型目录。
–train
表示执行训练(微调)操作。
–data ./test_data
指定训练数据所在的目录,这里是当前目录下的 test_data 文件夹。里面应包含用于微调的数据集。
–learning-rate 1.0e-4
设置训练时的学习率为 0.0001。学习率决定了模型参数每次更新的步长,是训练中非常重要的超参数。
–val-batches -1
指定验证集的 batch 数量为 -1,通常表示“使用全部验证数据”进行评估。
–batch-size 2
设置每个训练 batch 的样本数为 2。batch size 越大,显存/内存消耗越多,但训练更稳定。
效果测试
mlx_lm.generate --model ~/Documents/PythonProject/ml_study_test/Qwen2.5-1.5B --adapter-path adapters --temp 0.0001 -m 30 --extra-eos-token assistant --prompt "PolarDB是什么?"
@bogon lora % mlx_lm.generate --model ~/Documents/PythonProject/ml_study_test/Qwen2.5-1.5B --adapter-path adapters --temp 0.0001 -m 30 --extra-eos-token assistant --prompt "PolarDB是什么?"
==========
阿里云开源宇宙无敌数据库
==========
Prompt: 24 tokens, 182.174 tokens-per-sec
Generation: 7 tokens, 32.178 tokens-per-sec
Peak memory: 3.134 GB
可以发现效果还不错
最后可以把微调后的参数和模型融合, 生成本地微调后的模型
mlx_lm.fuse --model ~/Documents/PythonProject/ml_study_test/Qwen2.5-1.5B --adapter-path adapters --save-path ~/Documents/PythonProject/ml_study_test/Qwen2.5-1.5B-test
最后还可以使用融合后的模型测试
@anonymous ml_study_test % mlx_lm.generate --model ~/Documents/PythonProject/ml_study_test/Qwen2.5-1.5B-test --prompt "哪吒的师傅是谁?"
==========
孙悟空的师傅的舅舅
==========
Prompt: 25 tokens, 208.395 tokens-per-sec
Generation: 6 tokens, 33.323 tokens-per-sec
Peak memory: 3.126 GB
自此基于 mlx 的简单微调就成功了 但是肯定在这个过程中还是会对其中各个步骤的细节有疑惑,比如说lora微调代码原理、adapters是干什么的等等 这些问题就在之后的文章里解释吧~