【学习心得】Xtuner模型qlora微调时错误记录
问题一:使用Xtuner进行模型qlora模型微调的时候,报错No module named 'triton.ops'
The above exception was the direct cause of the following exception:Traceback (most recent call last):File "/output/xtuner/xtuner/tools/train.py", line 392, in <module>main()File "/output/xtuner/xtuner/tools/train.py", line 381, in mainrunner = Runner.from_cfg(cfg)File "/usr/local/envs/xtuner/lib/python3.10/site-packages/mmengine/runner/runner.py", line 462, in from_cfgrunner = cls(File "/usr/local/envs/xtuner/lib/python3.10/site-packages/mmengine/runner/runner.py", line 429, in __init__self.model = self.build_model(model)File "/usr/local/envs/xtuner/lib/python3.10/site-packages/mmengine/runner/runner.py", line 836, in build_modelmodel = MODELS.build(model)File "/usr/local/envs/xtuner/lib/python3.10/site-packages/mmengine/registry/registry.py", line 570, in buildreturn self.build_func(cfg, *args, **kwargs, registry=self)File "/usr/local/envs/xtuner/lib/python3.10/site-packages/mmengine/registry/build_functions.py", line 234, in build_model_from_cfgreturn build_from_cfg(cfg, registry, default_args)File "/usr/local/envs/xtuner/lib/python3.10/site-packages/mmengine/registry/build_functions.py", line 123, in build_from_cfgobj = obj_cls(**args) # type: ignoreFile "/output/xtuner/xtuner/model/sft.py", line 97, in __init__self.llm = self.build_llm_from_cfg(File "/output/xtuner/xtuner/model/sft.py", line 143, in build_llm_from_cfgllm = self._build_from_cfg_or_module(llm)File "/output/xtuner/xtuner/model/sft.py", line 296, in _build_from_cfg_or_modulereturn BUILDER.build(cfg_or_mod)File "/usr/local/envs/xtuner/lib/python3.10/site-packages/mmengine/registry/registry.py", line 570, in buildreturn self.build_func(cfg, *args, **kwargs, registry=self)File "/usr/local/envs/xtuner/lib/python3.10/site-packages/mmengine/registry/build_functions.py", line 123, in build_from_cfgobj = obj_cls(**args) # type: ignoreFile "/usr/local/envs/xtuner/lib/python3.10/site-packages/transformers/models/auto/auto_factory.py", line 564, in from_pretrainedreturn model_class.from_pretrained(File "/usr/local/envs/xtuner/lib/python3.10/site-packages/transformers/modeling_utils.py", line 3620, in from_pretrainedhf_quantizer.validate_environment(File "/usr/local/envs/xtuner/lib/python3.10/site-packages/transformers/quantizers/quantizer_bnb_8bit.py", line 77, in validate_environmentfrom ..integrations import validate_bnb_backend_availabilityFile "<frozen importlib._bootstrap>", line 1075, in _handle_fromlistFile "/usr/local/envs/xtuner/lib/python3.10/site-packages/transformers/utils/import_utils.py", line 1805, in __getattr__module = self._get_module(self._class_to_module[name])File "/usr/local/envs/xtuner/lib/python3.10/site-packages/transformers/utils/import_utils.py", line 1819, in _get_moduleraise RuntimeError(
RuntimeError: Failed to import transformers.integrations.bitsandbytes because of the following error (look up to see its traceback):
No module named 'triton.ops'根据回溯来分析错误原因:
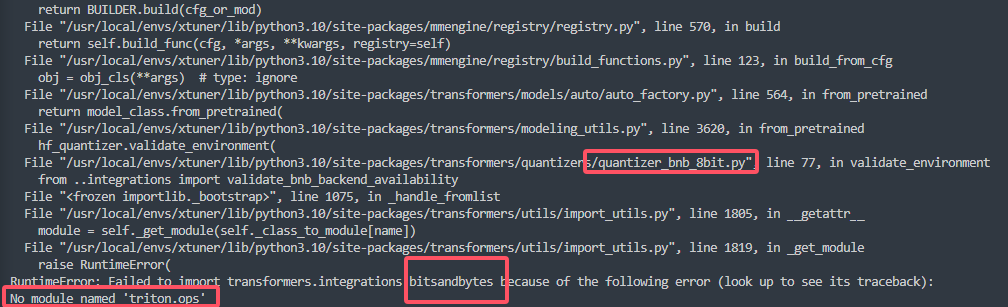
这是在尝试使用 BitsAndBytes(8-bit 量化) 加载模型时发生的,我们查看一下 bitsandbytes 库是否正确安装。
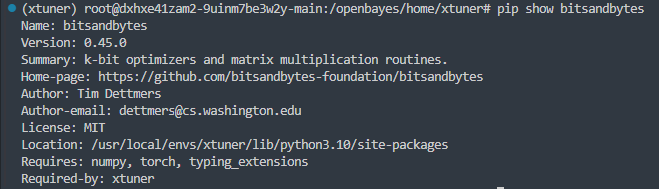
可能是版本不对,试着重装一下后还是报错,最后查找资料发现是torch2.6以上版本和bitstandbytes版本的冲突问题。
解决方案:安装低版本的pytorch==2.5.1我们进入xtuner的requirement文件里面修改一下torch版本
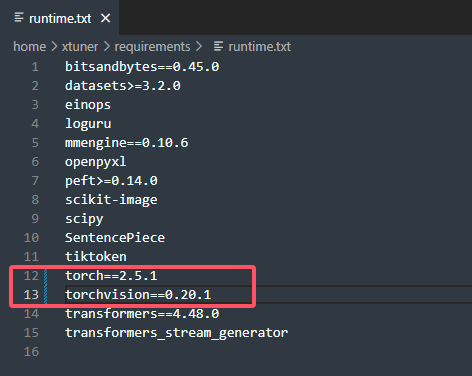
然后再执行一次xtuner安装就可以了
# 在xtuner源码目录中执行
pip install -e .问题二:使用Xtuner进行模型qlora模型微调的时候,报错KeyError: 'qwen'
Traceback (most recent call last):File "/usr/local/envs/xtuner/lib/python3.10/site-packages/transformers/models/auto/configuration_auto.py", line 1071, in from_pretrainedconfig_class = CONFIG_MAPPING[config_dict["model_type"]]File "/usr/local/envs/xtuner/lib/python3.10/site-packages/transformers/models/auto/configuration_auto.py", line 773, in __getitem__raise KeyError(key)
KeyError: 'qwen'During handling of the above exception, another exception occurred:Traceback (most recent call last):File "/output/xtuner/xtuner/tools/train.py", line 392, in <module>main()File "/output/xtuner/xtuner/tools/train.py", line 381, in mainrunner = Runner.from_cfg(cfg)File "/usr/local/envs/xtuner/lib/python3.10/site-packages/mmengine/runner/runner.py", line 462, in from_cfgrunner = cls(File "/usr/local/envs/xtuner/lib/python3.10/site-packages/mmengine/runner/runner.py", line 429, in __init__self.model = self.build_model(model)File "/usr/local/envs/xtuner/lib/python3.10/site-packages/mmengine/runner/runner.py", line 836, in build_modelmodel = MODELS.build(model)File "/usr/local/envs/xtuner/lib/python3.10/site-packages/mmengine/registry/registry.py", line 570, in buildreturn self.build_func(cfg, *args, **kwargs, registry=self)File "/usr/local/envs/xtuner/lib/python3.10/site-packages/mmengine/registry/build_functions.py", line 234, in build_model_from_cfgreturn build_from_cfg(cfg, registry, default_args)File "/usr/local/envs/xtuner/lib/python3.10/site-packages/mmengine/registry/build_functions.py", line 123, in build_from_cfgobj = obj_cls(**args) # type: ignoreFile "/output/xtuner/xtuner/model/sft.py", line 97, in __init__self.llm = self.build_llm_from_cfg(File "/output/xtuner/xtuner/model/sft.py", line 142, in build_llm_from_cfgllm = self._dispatch_lm_model_cfg(llm_cfg, max_position_embeddings)File "/output/xtuner/xtuner/model/sft.py", line 281, in _dispatch_lm_model_cfgllm_cfg = AutoConfig.from_pretrained(File "/usr/local/envs/xtuner/lib/python3.10/site-packages/transformers/models/auto/configuration_auto.py", line 1073, in from_pretrainedraise ValueError(
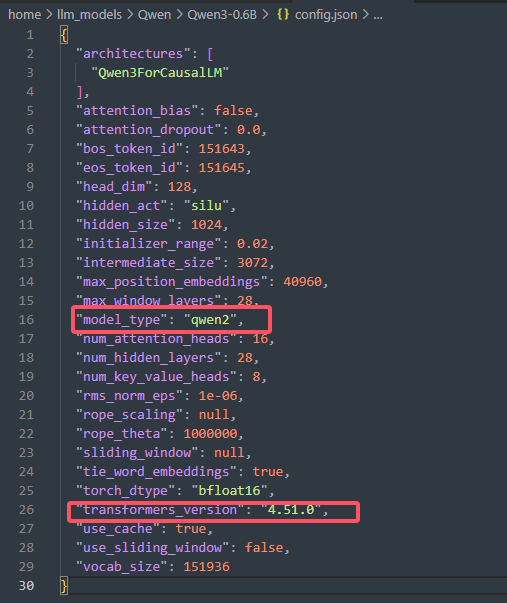
ValueError: The checkpoint you are trying to load has model type `qwen` but Transformers does not recognize this architecture. This could be because of an issue with the checkpoint, or because your version of Transformers is out of date.You can update Transformers with the command `pip install --upgrade transformers`. If this does not work, and the checkpoint is very new, then there may not be a release version that supports this model yet. In this case, you can get the most up-to-date code by installing Transformers from source with the command `pip install git+https://github.com/huggingface/transformers.git`原因分析:当前安装的Transformers 库不支持这个模型最新qwen3模型。
解决方案:qwen3的模型配置文件中说明了支持的transformers版本为4.51.0但是我要使用Xtuner微调,xtuner框架支持的transformers版本是4.48.0所以我不能安装最新的版本。于是可以修改配置文件中的model_type字段,改成qwen2