强化学习之基于无模型的算法之基于值函数的深度强化学习算法
3、基于值函数的深度强化学习算法
1)深度Q网络(DQN)
核心思想
- 经验回放(Experience Replay):将智能体的交互经验(状态、动作、奖励、下一状态)存储在回放缓冲区中,训练时随机采样以打破数据相关性,提高样本利用率和模型稳定性。
- 目标网络(Target Network):使用一个延迟更新的目标网络计算目标Q值,避免主网络频繁更新导致的目标值震荡,稳定训练过程。
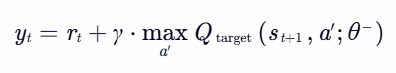
- rt:当前时间步 t 获得的即时奖励。
- γ:折扣因子(0≤γ≤1),用于平衡即时奖励与未来奖励的重要性。
- maxa′Qtarget(st+1,a′;θ−):目标网络(参数为 θ−)在下一状态 st+1 下所有可能动作 a′ 中Q值的最大值,表示未来收益的估计。
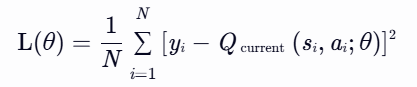
- N:批量大小(mini-batch size),即从经验回放缓冲区中随机采样的样本数量。
- yi:第 i 个样本的目标Q值,由目标网络计算。
- Qcurrent(si,ai;θ):当前网络(参数为 θ)对状态 si 和动作 ai 的Q值预测。
实现代码
#! /usr/bin/env pythonimport torch
import torch.nn as nn
import time
import random
import numpy as np
import gym
from PIL import Image
import matplotlib.pyplot as plt# DQN深度模型,用来估计Atari环境的Q函数
class DQN(nn.Module):def __init__(self, img_size, num_actions):super().__init__()# 输入图像的形状(c, h, w)self.img_size = img_sizeself.num_actions = num_actions# 对于Atari环境,输入为(4, 84, 84)self.featnet = nn.Sequential(nn.Conv2d(img_size[0], 32, kernel_size=8, stride=4),nn.ReLU(),nn.Conv2d(32, 64, kernel_size=4, stride=2),nn.ReLU(),nn.Conv2d(64, 64, kernel_size=3, stride=1),nn.ReLU())# 价值网络,根据特征输出每个动作的价值self.vnet = nn.Sequential(nn.Linear(self._feat_size(), 512),nn.ReLU(),nn.Linear(512, self.num_actions))def _feat_size(self):#在其管理的代码块内,不进行梯度计算with torch.no_grad():x = torch.randn(1, *self.img_size) #x是一个形状为(1, c, h, w)的随机张量,其中1表示批量大小为 1,c、h、w分别是图像的通道数、高度和宽度。x = self.featnet(x).view(1, -1) #view方法用于改变张量的形状,1表示第一维的大小为 1,-1表示让 PyTorch 根据张量的总元素数自动计算该维度的大小return x.size(1) #x.size(1)返回张量x第二维的大小def forward(self, x): bs = x.size(0)# 提取特征feat = self.featnet(x).view(bs, -1)# 获取所有可能动作的价值values = self.vnet(feat)return valuesdef act(self, x, epsilon=0.0):# ε-贪心算法if random.random() > epsilon:with torch.no_grad():values = self.forward(x)return values.argmax(-1).squeeze().item()else:return random.randint(0, self.num_actions-1)from collections import deque
class ExpReplayBuffer(object):def __init__(self, buffer_size):super().__init__()self.buffer = deque(maxlen=buffer_size)def push(self, state, action, reward, next_state, done):self.buffer.append((state, action, reward, next_state, done))def sample(self, bs): #zip(*...) 是一个解包和重新打包的操作。* 是解包运算符,它将 random.sample 返回的列表中的每个元组解包,然后 zip 函数将这些解包后的元素重新组合成新的元组state, action, reward, next_state, done = \zip(*random.sample(self.buffer, bs))return np.stack(state, 0), np.stack(action, 0), \np.stack(reward, 0), np.stack(next_state, 0), \np.stack(done, 0).astype(np.float32)def __len__(self):return len(self.buffer)class EnvWrapper(object):def __init__(self, env, num_frames):super().__init__()self.env_ = envself.num_frames = num_framesself.frame = deque(maxlen=num_frames)def _preprocess(self, img):# 预处理数据img = Image.fromarray(img) # 假设 img 是一个 NumPy 数组img = img.convert("L") # 转换为灰度图像img = img.resize((84, 84)) # 调整大小return np.array(img)/256.0 # 归一化到 [0, 1]def reset(self):obs = self.env_.reset() # 重置环境if isinstance(obs, tuple):obs = obs[0] # 提取元组中的第一个元素作为观察值self.frame = [] # 清空之前的帧for _ in range(self.num_frames):processed_frame = self._preprocess(obs) # 对观察值进行预处理self.frame.append(processed_frame)return np.stack(self.frame, axis=0) # 返回堆叠的帧def step(self, action):obs, reward, _, done, _ = self.env_.step(action)processed_frame = self._preprocess(obs)self.frame.pop(0) # 移除最早的帧self.frame.append(processed_frame) # 添加最新的帧return np.stack(self.frame, 0), np.sign(reward), done, {}@propertydef env(self):return self.env_def train(buffer, model, optimizer):# 对经验回放的数据进行采样state, action, reward, next_state, done = buffer.sample(BATCH_SIZE)state = torch.tensor(state, dtype=torch.float32) #.cudareward = torch.tensor(reward, dtype=torch.float32) #.cudaaction = torch.tensor(action, dtype=torch.long) #.cudanext_state = torch.tensor(next_state, dtype=torch.float32) #.cudadone = torch.tensor(done, dtype=torch.float32)# 下一步状态的预测with torch.no_grad():target, _ = model(next_state).max(dim=-1) #获取最后一个维度上的最大值和最大值索引target = reward + (1-done)*GAMMA*target# 当前状态的预测#model(state) 调用 DQN 类的 forward 方法对输入的状态进行前向传播,输出每个样本在所有可能动作上的价值predict = model(state).gather(1, action.unsqueeze(-1)).squeeze()#unsqueeze(-1) 方法在张量的最后一个维度上增加一个维度,将 action 的形状从 (batch_size,) 变为 (batch_size, 1)。这样做是为了满足 gather 方法的输入要求。#squeeze 方法用于移除张量中维度大小为 1 的维度。loss = (predict - target).pow(2).mean()# 损失函数的优化optimizer.zero_grad()loss.backward()optimizer.step()return loss.item()GAMMA = 0.99
EPSILON_MIN = 0.01
EPSILON_MAX = 1.00
NFRAMES = 4
BATCH_SIZE = 32
NSTEPS = 400000
NBUFFER = 10000
env = gym.make('PongDeterministic-v4', render_mode='human')
env = EnvWrapper(env, NFRAMES)state = env.reset()
buffer = ExpReplayBuffer(NBUFFER)
dqn = DQN((4, 84, 84), env.env.action_space.n)
# dqn.cuda()
optimizer = torch.optim.Adam(dqn.parameters(), 1e-4)all_rewards = []
all_losses = []
episode_reward = 0
all_steps1 = []
all_steps2 = []eps = lambda t: EPSILON_MIN + (EPSILON_MAX - EPSILON_MIN)*np.exp(-t/30000) #E指数衰减的方式,确保随着训练的进行,探索的比例逐渐减少time_start = time.time()
for nstep in range(NSTEPS):print(nstep)p = eps(nstep)state_t = torch.tensor(state, dtype=torch.float32).unsqueeze(0) #.cudaaction = dqn.act(state_t, p)next_state, reward, done, _ = env.step(action)buffer.push(state, action, reward, next_state, done)state = next_stateepisode_reward += rewardif done:state = env.reset()all_rewards.append(episode_reward)all_steps1.append(nstep)episode_reward = 0if len(buffer) >= 1000:loss = train(buffer, dqn, optimizer)all_losses.append(loss)all_steps2.append(nstep)time_end = time.time()
print("DQN cost time:" + str(time_end - time_start))# 绘制奖励图
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.plot(all_steps1, all_rewards)
plt.title('Episode Rewards')
plt.xlabel('Step')
plt.ylabel('Reward')# 绘制损失训练图
plt.subplot(1, 2, 2)
plt.plot(all_steps2, all_losses)
plt.title('Training Loss')
plt.xlabel('Step')
plt.ylabel('Loss')plt.tight_layout()
plt.show()2)双网络Q学习算法(Double DQN)
核心思想
Double DQN是对DQN的一种改进,旨在解决过估计的问题。在 DQN 的基础上,引入了两个 Q 网络,一个用于选择动作(在线网络),另一个用于评估动作的价值(目标网络)。在更新 Q 值时,使用在线网络选择动作,然后用目标网络来计算目标 Q 值,这样可以减少 Q 值的过估计问题,提高算法的稳定性和准确性。
公式:
计算Q值公式:
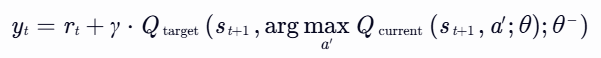
计算损失函数:
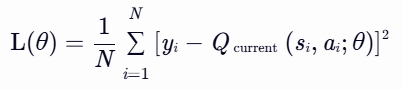
优点:有效减少了 Q 值的过估计,提高了算法的性能和稳定性;在一些复杂环境中表现优于传统的 DQN。
缺点:增加了模型的复杂度和计算量,因为需要维护两个 Q 网络;对超参数的调整仍然比较敏感。
实现代码
#! /usr/bin/env pythonimport torch
import torch.nn as nn
import time
import random
import numpy as np
import gym
from PIL import Image
import matplotlib.pyplot as plt# DQN深度模型,用来估计Atari环境的Q函数
class DQN(nn.Module):def __init__(self, img_size, num_actions):super().__init__()# 输入图像的形状(c, h, w)self.img_size = img_sizeself.num_actions = num_actions# 对于Atari环境,输入为(4, 84, 84)self.featnet = nn.Sequential(nn.Conv2d(img_size[0], 32, kernel_size=8, stride=4),nn.ReLU(),nn.Conv2d(32, 64, kernel_size=4, stride=2),nn.ReLU(),nn.Conv2d(64, 64, kernel_size=3, stride=1),nn.ReLU())# 值网络,根据特征输出每个动作的价值self.vnet = nn.Sequential(nn.Linear(self._feat_size(), 512),nn.ReLU(),nn.Linear(512, self.num_actions))def _feat_size(self):with torch.no_grad():x = torch.randn(1, *self.img_size)x = self.featnet(x).view(1, -1)return x.size(1)def forward(self, x): bs = x.size(0)# 提取特征feat = self.featnet(x).view(bs, -1)# 获取所有可能动作的价值values = self.vnet(feat)return valuesdef act(self, x, epsilon=0.0):# ε-贪心算法if random.random() > epsilon:with torch.no_grad():values = self.forward(x)return values.argmax(-1).squeeze().item()else:return random.randint(0, self.num_actions-1)from collections import deque
class ExpReplayBuffer(object):def __init__(self, buffer_size):super().__init__()self.buffer = deque(maxlen=buffer_size)def push(self, state, action, reward, next_state, done):self.buffer.append((state, action, reward, next_state, done))def sample(self, bs):state, action, reward, next_state, done = \zip(*random.sample(self.buffer, bs))return np.stack(state, 0), np.stack(action, 0), \np.stack(reward, 0), np.stack(next_state, 0), \np.stack(done, 0).astype(np.float32)def __len__(self):return len(self.buffer)class EnvWrapper(object):def __init__(self, env, num_frames):super().__init__()self.env_ = envself.num_frames = num_framesself.frame = deque(maxlen=num_frames)def _preprocess(self, img):# 预处理数据img = Image.fromarray(img)img = img.convert("L")img = img.resize((84, 84))return np.array(img)/256.0def reset(self):obs = self.env_.reset() # 重置环境if isinstance(obs, tuple):obs = obs[0] # 提取元组中的第一个元素作为观察值self.frame = [] # 清空之前的帧for _ in range(self.num_frames):processed_frame = self._preprocess(obs) # 对观察值进行预处理self.frame.append(processed_frame)return np.stack(self.frame, axis=0) # 返回堆叠的帧def step(self, action):obs, reward, _, done, _ = self.env_.step(action)processed_frame = self._preprocess(obs)self.frame.pop(0) # 移除最早的帧self.frame.append(processed_frame) # 添加最新的帧return np.stack(self.frame, 0), np.sign(reward), done, {}@propertydef env(self):return self.env_def train(buffer, model1, model2, optimizer):# 对经验回放的数据进行采样state, action, reward, next_state, done = buffer.sample(BATCH_SIZE)state = torch.tensor(state, dtype=torch.float32)reward = torch.tensor(reward, dtype=torch.float32)action = torch.tensor(action, dtype=torch.long)next_state = torch.tensor(next_state, dtype=torch.float32)done = torch.tensor(done, dtype=torch.float32)with torch.no_grad():# 用Q1计算最大价值的动作next_action = model1(next_state).argmax(-1) #获取最后一个维度上的最大值索引# 用Q2计算对应的最大价值target = model2(next_state)\.gather(1, next_action.unsqueeze(-1)).squeeze() #.squeeze():移除多余的维度,使 target 成为一个一维张量。target = reward + (1-done)*GAMMA*target# 当前状态的预测predict = model1(state).gather(1, action.unsqueeze(-1)).squeeze()loss = (predict - target).pow(2).mean()# 损失函数的优化optimizer.zero_grad() #确保梯度从零开始计算。loss.backward() #计算当前批次数据的梯度。optimizer.step() #使用计算出的梯度更新模型参数,pytorch框架自带,PyTorch 会自动根据优化器的类型(如 SGD、Adam 等)和配置的参数(如学习率)来更新模型参数return loss.item() #提供当前批次的损失值,用于监控和评估模型性能GAMMA = 0.99
EPSILON_MIN = 0.01
EPSILON_MAX = 1.00
NFRAMES = 4
BATCH_SIZE = 32
NSTEPS = 400000
NBUFFER = 10000
env = gym.make('PongDeterministic-v4')
env = EnvWrapper(env, NFRAMES)state = env.reset()
buffer = ExpReplayBuffer(NBUFFER)
# 构造两个相同的神经网络
dqn1 = DQN((4, 84, 84), env.env.action_space.n)
dqn2 = DQN((4, 84, 84), env.env.action_space.n)
dqn2.load_state_dict(dqn1.state_dict())
# dqn1.cuda()
# dqn2.cuda()
optimizer = torch.optim.Adam(dqn1.parameters(), 1e-4)all_rewards = []
all_losses = []
episode_reward = 0
all_steps1 = []
all_steps2 = []eps = lambda t: EPSILON_MIN + (EPSILON_MAX - EPSILON_MIN)*np.exp(-t/30000)time_start = time.time()
for nstep in range(NSTEPS):print(nstep)p = eps(nstep)state_t = torch.tensor(state, dtype=torch.float32).unsqueeze(0)action = dqn1.act(state_t, p)next_state, reward, done, _ = env.step(action)buffer.push(state, action, reward, next_state, done)state = next_stateepisode_reward += rewardif done:state = env.reset()all_rewards.append(episode_reward)episode_reward = 0all_steps1.append(nstep)if len(buffer) >= 1000:loss = train(buffer, dqn1, dqn2, optimizer)all_losses.append(loss)all_steps2.append(nstep)# 更新Q2参数if (nstep + 1) % 100 == 0:dqn2.load_state_dict(dqn1.state_dict())time_end = time.time()
print("double DQN cost time:" + str(time_end - time_start))# 绘制奖励图
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.plot(all_steps1, all_rewards)
plt.title('Episode Rewards')
plt.xlabel('Step')
plt.ylabel('Reward')# 绘制损失训练图
plt.subplot(1, 2, 2)
plt.plot(all_steps2, all_losses)
plt.title('Training Loss')
plt.xlabel('Step')
plt.ylabel('Loss')plt.tight_layout()
plt.show()3)优先经验回放(Prioritized Experience Replay)
核心思想
- 优先级计算:基于TD误差的绝对值或排名分配优先级。
- 采样策略:采用比例优先级或排名优先级,结合重要性采样(Importance Sampling)纠正偏差。
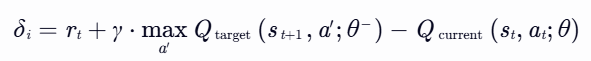
- rt:当前时间步的即时奖励。
- γ:折扣因子(0≤γ≤1),平衡即时与未来收益。
- Qtarget(st+1,a′;θ−):目标网络对下一状态 st+1 和动作 a′ 的Q值预测。
- Qcurrent(st,at;θ):当前网络对当前状态 st 和动作 at 的Q值预测。
- ϵ:极小正数(如 10−6),避免优先级为0。
- 特点:直接关联TD-error,但受噪声影响较大(异常值可能主导优先级)。
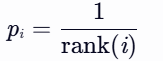
- rank(i):样本按 ∣δi∣ 排序后的序号(如TD-error最大的样本排名为1)。
- 特点:对异常值不敏感,鲁棒性更强,但需额外排序操作。
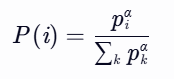
- α:控制优先回放强度的超参数(α≥0):
- α=0:退化为均匀采样;
- α=1:完全按优先级采样。
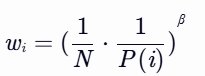
- N:经验回放池容量。
- β:控制偏差补偿强度的超参数(通常从0逐渐增至1):
- 训练初期:β=0.4(弱补偿);
- 训练后期:β=1.0(强补偿)。
- 归一化:为稳定训练,需将权重归一化:
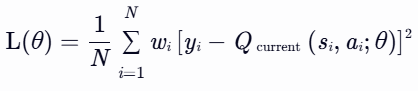
- yi:目标Q值(如Double DQN公式计算)。
- 作用:通过权重 wi 平衡高优先级样本的过度学习
实现代码
#! /usr/bin/env pythonimport torch
import torch.nn as nn
import torch.nn.functional as F
import random
import numpy as np
import gym
from PIL import Image# DQN深度模型,用来估计Atari环境的Q函数
class DQN(nn.Module):def __init__(self, img_size, num_actions):super().__init__()# 输入图像的形状(c, h, w)self.img_size = img_sizeself.num_actions = num_actions# 对于Atari环境,输入为(4, 84, 84)self.featnet = nn.Sequential(nn.Conv2d(img_size[0], 32, kernel_size=8, stride=4),nn.ReLU(),nn.Conv2d(32, 64, kernel_size=4, stride=2),nn.ReLU(),nn.Conv2d(64, 64, kernel_size=3, stride=1),nn.ReLU())# 值网络,根据特征输出每个动作的价值self.vnet = nn.Sequential(nn.Linear(self._feat_size(), 512),nn.ReLU(),nn.Linear(512, self.num_actions))def _feat_size(self):with torch.no_grad():x = torch.randn(1, *self.img_size)x = self.featnet(x).view(1, -1)return x.size(1)def forward(self, x): bs = x.size(0)# 提取特征feat = self.featnet(x).view(bs, -1)# 获取所有可能动作的价值values = self.vnet(feat)return valuesdef act(self, x, epsilon=0.0):# ε-贪心算法if random.random() > epsilon:with torch.no_grad():values = self.forward(x)return values.argmax(-1).squeeze().item()else:return random.randint(0, self.num_actions-1)from collections import deque
from heapq import heappush, heappushpop, heapify, nlargest
from operator import itemgetterclass Sample(tuple):def __lt__(self, x):return self[0] < x[0] #如果当前实例的第一个元素小于 x 的第一个元素,则返回 True;否则,返回 Falseclass PrioritizedExpReplayBuffer(object):def __init__(self, buffer_size, alpha):super().__init__()self.alpha = alphaself.buffer_size = buffer_sizeself.buffer = []def heapify(self):heapify(self.buffer)def push(self, state, action, reward, next_state, done):# 设置样本的初始时序误差,如果缓冲区为空,则设置初始时序误差为 1.0;否则,获取当前缓冲区中最大的时序误差作为新样本的初始时序误差。td = 1.0 if not self.buffer else \nlargest(1, self.buffer, key=itemgetter(0))[0][0]# 向优先队列插入样本if len(self.buffer) < self.buffer_size:heappush(self.buffer, \Sample((td, state, action, reward, next_state, done)))else:heappushpop(self.buffer, \Sample((td, state, action, reward, next_state, done)))# 设置样本的时序误差,更新存储在 self.buffer 中某些样本的TD(Temporal Difference,时间差分)值def set_td_value(self, index, value):for idx_s, idx_t in enumerate(index): #遍历index列表,同时获取每个元素的索引(idx_s)和值(idx_t)。这里idx_t表示self.buffer中需要更新的样本的索引,而idx_s则是对应的新TD值在value列表中的位置。self.buffer[idx_t] = Sample((value[idx_s], *self.buffer[idx_t][1:])) #更新self.buffer中指定索引(idx_t)处的样本。def sample(self, bs, beta=1.0):# 计算权重并且归一化with torch.no_grad():weights = torch.tensor([val[0] for val in self.buffer])weights = weights.abs().pow(self.alpha)weights = weights/weights.sum()prob = weights.cpu().numpy()weights = (len(weights)*weights).pow(-beta)weights = weights/weights.max()weights = weights.cpu().numpy()index = random.choices(range(len(weights)), weights=prob, k=bs)#k=bs: 指定从 range(len(weights)) 中随机抽取 bs 个元素。# 根据index返回训练样本_, state, action, reward, next_state, done = \zip(*[self.buffer[i] for i in index]) #使用 zip 将这些子列表“按列”组合在一起weights = [weights[i] for i in index]return np.stack(weights, 0).astype(np.float32), index, \np.stack(state, 0), np.stack(action, 0), \np.stack(reward, 0), np.stack(next_state, 0), \np.stack(done, 0).astype(np.float32)def __len__(self):return len(self.buffer)class EnvWrapper(object):def __init__(self, env, num_frames):super().__init__()self.env_ = envself.num_frames = num_framesself.frame = deque(maxlen=num_frames)def _preprocess(self, img):# 预处理数据img = Image.fromarray(img)img = img.convert("L")img = img.resize((84, 84))return np.array(img)/256.0def reset(self):obs = self.env_.reset() # 重置环境if isinstance(obs, tuple):obs = obs[0] # 提取元组中的第一个元素作为观察值self.frame = [] # 清空之前的帧for _ in range(self.num_frames):processed_frame = self._preprocess(obs) # 对观察值进行预处理self.frame.append(processed_frame)return np.stack(self.frame, axis=0) # 返回堆叠的帧def step(self, action):obs, reward, _, done, _ = self.env_.step(action)# self.frame.append(self._preprocess(obs))processed_frame = self._preprocess(obs)self.frame.pop(0) # 移除最早的帧self.frame.append(processed_frame) # 添加最新的帧return np.stack(self.frame, 0), np.sign(reward), done, {}@propertydef env(self):return self.env_def train(buffer, model1, model2, optimizer):# 对经验回放的数据进行采样weights, index, state, action, reward, next_state, done = buffer.sample(BATCH_SIZE, BETA)state = torch.tensor(state, dtype=torch.float32)reward = torch.tensor(reward, dtype=torch.float32)action = torch.tensor(action, dtype=torch.long)next_state = torch.tensor(next_state, dtype=torch.float32)done = torch.tensor(done, dtype=torch.float32)weights = torch.tensor(weights, dtype=torch.float32)# 下一步状态的预测with torch.no_grad():# 用Q1计算最大价值的动作next_action = model1(next_state).argmax(-1)# 用Q2计算对应的最大价值target = model2(next_state)\.gather(1, next_action.unsqueeze(-1)).squeeze()target = reward + (1-done)*GAMMA*target# 当前状态的预测predict = model1(state).gather(1, action.unsqueeze(-1)).squeeze()# 计算时序差分误差with torch.no_grad():td = (predict - target).squeeze().abs().cpu().numpy() + 1e-6#调整误差buffer.set_td_value(index, td)loss = (weights*(predict - target).pow(2)).mean()# 损失函数的优化optimizer.zero_grad()loss.backward()optimizer.step()return loss.item()GAMMA = 0.99
EPSILON_MIN = 0.01
EPSILON_MAX = 1.00
NFRAMES = 4
BATCH_SIZE = 32
NSTEPS = 4000000
NBUFFER = 20000
ALPHA = 0.4
BETA = 0.6
env = gym.make('PongDeterministic-v4')
env = EnvWrapper(env, NFRAMES)state = env.reset()
buffer = PrioritizedExpReplayBuffer(NBUFFER, ALPHA)
# 构造两个相同的神经网络
dqn1 = DQN((4, 84, 84), env.env.action_space.n)
dqn2 = DQN((4, 84, 84), env.env.action_space.n)
dqn2.load_state_dict(dqn1.state_dict())
# dqn1.cuda()
# dqn2.cuda()
optimizer = torch.optim.Adam(dqn1.parameters(), 1e-4)all_rewards = []
all_losses = []
episode_reward = 0eps = lambda t: EPSILON_MIN + (EPSILON_MAX - EPSILON_MIN)*np.exp(-t/30000)for nstep in range(NSTEPS):p = eps(nstep)state_t = torch.tensor(state, dtype=torch.float32).unsqueeze(0)action = dqn1.act(state_t, p)next_state, reward, done, _ = env.step(action)buffer.push(state, action, reward, next_state, done)state = next_stateepisode_reward += rewardif done:state = env.reset()all_rewards.append(episode_reward)episode_reward = 0if len(buffer) >= 10000:loss = train(buffer, dqn1, dqn2, optimizer)# 更新Q2参数if (nstep + 1) % 1000 == 0:dqn2.load_state_dict(dqn1.state_dict())# 重建二叉堆if (nstep + 1) % 100000 == 0:buffer.heapify()4)竞争DQN算法(Dueling DQN)
核心思想
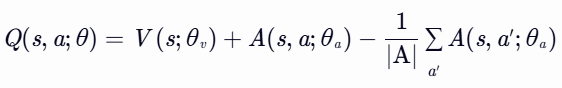
- V(s;θv):状态价值函数,评估状态 s 的整体好坏(与动作无关)。
- A(s,a;θa):优势函数,评估动作 a 相对于状态 s 下其他动作的相对优势。
- ∣A∣1∑a′A(s,a′;θa):优势函数的均值,用于唯一化分解(消除冗余,确保 V(s) 和 A(s,a) 可被唯一确定)。
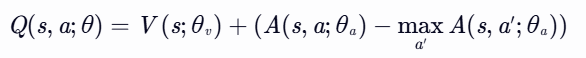
- 均值形式:更稳定,避免优势函数取值过大导致数值问题。
- 最大值形式:可能增强最优动作的突出性,但训练更敏感。
实现代码
#! /usr/bin/env pythonimport torch
import torch.nn as nn
import torch.nn.functional as F
import random
import numpy as np
import gym
from PIL import Image# Duel DQN深度模型,用来估计Atari环境的Q函数
class DDQN(nn.Module):def __init__(self, img_size, num_actions):super().__init__()# 输入图像的形状(c, h, w)self.img_size = img_sizeself.num_actions = num_actions# 对于Atari环境,输入为(4, 84, 84)self.featnet = nn.Sequential(nn.Conv2d(img_size[0], 32, kernel_size=8, stride=4),nn.ReLU(),nn.Conv2d(32, 64, kernel_size=4, stride=2),nn.ReLU(),nn.Conv2d(64, 64, kernel_size=3, stride=1),nn.ReLU())# 优势函数网络,根据特征输出每个动作的价值self.adv_net = nn.Sequential(nn.Linear(self._feat_size(), 512),nn.ReLU(),nn.Linear(512, self.num_actions))# 价值函数网络,根据特征输出当前的状态的价值self.val_net = nn.Sequential(nn.Linear(self._feat_size(), 512),nn.ReLU(),nn.Linear(512, 1))def _feat_size(self):with torch.no_grad():x = torch.randn(1, *self.img_size)x = self.featnet(x).view(1, -1)return x.size(1)def forward(self, x): bs = x.size(0)# 提取特征feat = self.featnet(x).view(bs, -1)# 获取所有可能动作的价值values = self.val_net(feat) + self.adv_net(feat) - \self.adv_net(feat).mean(-1, keepdim=True)return valuesdef act(self, x, epsilon=0.0):# ε-贪心算法if random.random() > epsilon:with torch.no_grad():values = self.forward(x)return values.argmax(-1).squeeze().item()else:return random.randint(0, self.num_actions-1)from collections import deque
class ExpReplayBuffer(object):def __init__(self, buffer_size):super().__init__()self.buffer = deque(maxlen=buffer_size)def push(self, state, action, reward, next_state, done):self.buffer.append((state, action, reward, next_state, done))def sample(self, bs):state, action, reward, next_state, done = \zip(*random.sample(self.buffer, bs))return np.stack(state, 0), np.stack(action, 0), \np.stack(reward, 0), np.stack(next_state, 0), \np.stack(done, 0).astype(np.float32)def __len__(self):return len(self.buffer)class EnvWrapper(object):def __init__(self, env, num_frames):super().__init__()self.env_ = envself.num_frames = num_framesself.frame = deque(maxlen=num_frames)def _preprocess(self, img):# 预处理数据img = Image.fromarray(img)img = img.convert("L")img = img.resize((84, 84))return np.array(img)/256.0def reset(self):obs = self.env_.reset() # 重置环境if isinstance(obs, tuple):obs = obs[0] # 提取元组中的第一个元素作为观察值self.frame = [] # 清空之前的帧for _ in range(self.num_frames):processed_frame = self._preprocess(obs) # 对观察值进行预处理self.frame.append(processed_frame)return np.stack(self.frame, axis=0) # 返回堆叠的帧def step(self, action):obs, reward, _, done, _ = self.env_.step(action)processed_frame = self._preprocess(obs)self.frame.pop(0) # 移除最早的帧self.frame.append(processed_frame) # 添加最新的帧return np.stack(self.frame, 0), np.sign(reward), done, {}@propertydef env(self):return self.env_def train(buffer, model1, model2, optimizer):# 对经验回放的数据进行采样state, action, reward, next_state, done = buffer.sample(BATCH_SIZE)state = torch.tensor(state, dtype=torch.float32) #.cuda()reward = torch.tensor(reward, dtype=torch.float32) #.cuda()action = torch.tensor(action, dtype=torch.long) #.cuda()next_state = torch.tensor(next_state, dtype=torch.float32) #.cuda()done = torch.tensor(done, dtype=torch.float32) #.cuda()# 下一步状态的预测,直接使用Q2的结果with torch.no_grad():target, _ = model2(next_state).max(-1)target = reward + (1-done)*GAMMA*target# 当前状态的预测predict = model1(state).gather(1, action.unsqueeze(-1)).squeeze()loss = (predict - target).pow(2).mean()# 损失函数的优化optimizer.zero_grad()loss.backward()optimizer.step()return loss.item()GAMMA = 0.99
EPSILON_MIN = 0.01
EPSILON_MAX = 1.00
NFRAMES = 4
BATCH_SIZE = 32
NSTEPS = 4000000
NBUFFER = 100000
env = gym.make('PongDeterministic-v4')
env = EnvWrapper(env, NFRAMES)state = env.reset()
buffer = ExpReplayBuffer(NBUFFER)
dqn1 = DDQN((4, 84, 84), env.env.action_space.n)
dqn2 = DDQN((4, 84, 84), env.env.action_space.n)
dqn2.load_state_dict(dqn1.state_dict())
optimizer = torch.optim.Adam(dqn1.parameters(), 1e-4)all_rewards = []
all_losses = []
episode_reward = 0eps = lambda t: EPSILON_MIN + (EPSILON_MAX - EPSILON_MIN)*np.exp(-t/30000)for nstep in range(NSTEPS):p = eps(nstep)state_t = torch.tensor(state, dtype=torch.float32).unsqueeze(0) #.cuda()action = dqn1.act(state_t, p)next_state, reward, done, _ = env.step(action)buffer.push(state, action, reward, next_state, done)state = next_stateepisode_reward += rewardif done:state = env.reset()all_rewards.append(episode_reward)episode_reward = 0if len(buffer) >= 10000:loss = train(buffer, dqn1, dqn2, optimizer)# 更新Q2参数if (nstep + 1) % 1000 == 0:dqn2.load_state_dict(dqn1.state_dict())5)分布形式的DQN算法(Distribution DQN)
核心思想
传统的 DQN 估计的是 Q 值的期望,而 Distribution DQN 则直接对 Q 值的概率分布进行建模。它将 Q 值表示为一个离散的概率分布,通过学习这个分布来估计不同奖励水平的概率。这样可以更全面地描述智能体对未来奖励的不确定性,从而做出更稳健的决策。
公式:
C51算法是分布形式的DQN算法的典型代表,其核心思想是将动作价值函数建模为离散分布而非单一期望值,从而更精确地刻画未来回报的不确定性。在 C51 中,将 Q 值的范围离散化为 N 个原子(atoms),每个原子代表一个可能的 Q 值,同时为每个原子分配一个概率,这些概率构成了 Q 值的概率分布。设 (V_min) 和 (V_max) 分别是 Q 值的最小和最大值,将区间 (V_min, V_max]) 均匀划分为 N 个原子,第 i 个原子的值为:
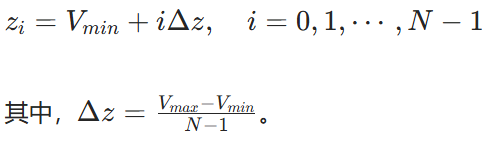

目标分布的计算
在 C51 中,需要计算目标分布。假设当前的样本为 (s, a, r, s'),其中 s 是当前状态,a 是采取的动作,r 是获得的奖励,s' 是下一个状态。
1. 选择下一个状态的最优动作
首先,根据当前网络估计的 Q 值分布,选择下一个状态s'的最优动作 a'。Q 值的期望可以通过分布的加权和来计算:
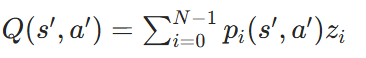
最优动作 a' 为:
![]()
2. 计算目标分布的支持点
根据贝尔曼方程,目标分布的支持点为:
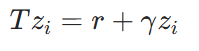
其中,γ是折扣因子。

损失函数
C51 算法使用交叉熵损失函数来最小化预测分布和目标分布之间的差异。对于样本 (s, a, r, s'),损失函数为:
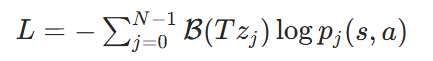
在实际训练中,会从经验回放缓冲区中随机抽取一批样本,计算这批样本的平均损失,然后使用梯度下降法更新网络参数。
优点:能够更好地处理奖励的不确定性,在一些具有随机奖励的环境中表现出色;提供了更丰富的信息,有助于智能体理解环境的动态性。
缺点:计算复杂度较高,因为需要处理概率分布而不是简单的数值;对数据量的要求较大,需要更多的样本才能准确估计 Q 值分布。
实现代码
#! /usr/bin/env pythonimport torch
import torch.nn as nn
import torch.nn.functional as F
import random
import numpy as np
import gym
from PIL import Imageclass CDQN(nn.Module):def __init__(self, img_size, num_actions, vmin, vmax, num_cats):super().__init__()# 输入图像的形状(c, h, w)self.img_size = img_sizeself.num_actions = num_actionsself.num_cats = num_cats #在vmin到vmax的价值函数的范围内划分的中间点的数目self.vmax = vmax #模型能够表示的最大价值函数的值self.vmin = vmin #模型能够表示的最小价值函数的值# 计算从vmin到vmax之间的一系列离散的价值self.register_buffer( #将离散值与pytorch模型绑定,命名为vrange"vrange",torch.linspace(self.vmin, self.vmax, num_cats).view(1, 1, -1) #计算离散的值) #在 self.vmin 和 self.vmax 之间均匀生成 num_cats 个点# 计算两个价值的差值self.register_buffer("dv",torch.tensor((vmax-vmin)/(num_cats-1)))# 对于Atari环境,输入为(4, 84, 84)self.featnet = nn.Sequential(nn.Conv2d(img_size[0], 32, kernel_size=8, stride=4),nn.ReLU(),nn.Conv2d(32, 64, kernel_size=4, stride=2),nn.ReLU(),nn.Conv2d(64, 64, kernel_size=3, stride=1),nn.ReLU())self.category_net = nn.Sequential(nn.Linear(self._feat_size(), 512),nn.ReLU(),nn.Linear(512, self.num_actions*self.num_cats),)def _feat_size(self):with torch.no_grad():x = torch.randn(1, *self.img_size)x = self.featnet(x).view(1, -1)return x.size(1)def forward(self, x): bs = x.size(0)# 提取特征feat = self.featnet(x).view(bs, -1)# 获取所有可能动作的价值概率分布logits = self.category_net(feat)\.view(-1, self.num_actions, self.num_cats)return logitsdef qval(self, x):probs = self.forward(x).softmax(-1)return (probs*self.vrange).sum(-1)def act(self, x, epsilon=0.0):# ε-贪心算法if random.random() > epsilon:with torch.no_grad():qval = self.qval(x)return qval.argmax(-1).squeeze().item()else:return random.randint(0, self.num_actions-1)from collections import deque
class ExpReplayBuffer(object):def __init__(self, buffer_size):super().__init__()self.buffer = deque(maxlen=buffer_size)def push(self, state, action, reward, next_state, done):self.buffer.append((state, action, reward, next_state, done))def sample(self, bs):state, action, reward, next_state, done = \zip(*random.sample(self.buffer, bs))return np.stack(state, 0), np.stack(action, 0), \np.stack(reward, 0), np.stack(next_state, 0), \np.stack(done, 0).astype(np.float32)def __len__(self):return len(self.buffer)class EnvWrapper(object):def __init__(self, env, num_frames):super().__init__()self.env_ = envself.num_frames = num_framesself.frame = deque(maxlen=num_frames)def _preprocess(self, img):# 预处理数据img = Image.fromarray(img)img = img.convert("L")img = img.resize((84, 84))return np.array(img)/256.0def reset(self):obs = self.env_.reset() # 重置环境if isinstance(obs, tuple):obs = obs[0] # 提取元组中的第一个元素作为观察值self.frame = [] # 清空之前的帧for _ in range(self.num_frames):processed_frame = self._preprocess(obs) # 对观察值进行预处理self.frame.append(processed_frame)return np.stack(self.frame, axis=0) # 返回堆叠的帧def step(self, action):obs, reward, _, done, _ = self.env_.step(action)processed_frame = self._preprocess(obs)self.frame.pop(0) # 移除最早的帧self.frame.append(processed_frame) # 添加最新的帧return np.stack(self.frame, 0), np.sign(reward), done, {}@propertydef env(self):return self.env_def train(buffer, model, optimizer):# 对经验回放的数据进行采样state, action, reward, next_state, done = buffer.sample(BATCH_SIZE)state = torch.tensor(state, dtype=torch.float32)reward = torch.tensor(reward, dtype=torch.float32)action = torch.tensor(action, dtype=torch.long)next_state = torch.tensor(next_state, dtype=torch.float32)done = torch.tensor(done, dtype=torch.float32)idx = torch.arange(BATCH_SIZE)# 下一步状态的预测with torch.no_grad():prob = model(next_state).softmax(-1) #.softmax(-1) 将 logits 转换为概率分布。value_dist = prob*model.vrange #得到Q值的分布概率next_action = value_dist.sum(-1).argmax(-1) #选择最优动作prob = prob[idx, next_action[idx], :] #选出在最优动作下的Q 值分布概率# 计算下一步奖励的映射value = reward.unsqueeze(-1) + \(1-done).unsqueeze(-1)*GAMMA*model.vrange.squeeze(0)value = (value.clamp(VMIN, VMAX) - VMIN)/DVlf, uf = value.floor(), value.ceil() #floor() 和 ceil():分别取 value 的下界和上界整数索引ll, ul = lf.long(), uf.long()target = torch.zeros_like(value)#scatter_add_:PyTorch 的张量操作,用于将值按索引累加到目标张量中,投影操作target.scatter_add_(1, ll, prob*(uf-value))target.scatter_add_(1, ul, prob*(value-lf))# 当前状态的预测predict = model(state)[idx, action[idx], :]loss = -(target*predict.log_softmax(-1)).mean()# 损失函数的优化optimizer.zero_grad()loss.backward()optimizer.step()return loss.item()GAMMA = 0.99
EPSILON_MIN = 0.01
EPSILON_MAX = 1.00
NFRAMES = 4
BATCH_SIZE = 32
NSTEPS = 4000000
NBUFFER = 100000
VMIN = -10
VMAX = 10
NCATS = 51
DV = (VMAX - VMIN)/(NCATS - 1)
env = gym.make('PongDeterministic-v4')
env = EnvWrapper(env, NFRAMES)state = env.reset()
buffer = ExpReplayBuffer(NBUFFER)
dqn = CDQN((4, 84, 84), env.env.action_space.n, VMIN, VMAX, NCATS)
# dqn.cuda()
optimizer = torch.optim.Adam(dqn.parameters(), 1e-4)all_rewards = []
all_losses = []
episode_reward = 0eps = lambda t: EPSILON_MIN + (EPSILON_MAX - EPSILON_MIN)*np.exp(-t/30000)for nstep in range(NSTEPS):p = eps(nstep)state_t = torch.tensor(state, dtype=torch.float32).unsqueeze(0)action = dqn.act(state_t, p)next_state, reward, done, _ = env.step(action)buffer.push(state, action, reward, next_state, done)state = next_stateepisode_reward += rewardif done:state = env.reset()all_rewards.append(episode_reward)episode_reward = 0if len(buffer) >= 10000:loss = train(buffer, dqn, optimizer)6)彩虹算法(Rainbow)
核心思想
将多种改进技术结合在一起,包括 Double DQN、Prioritized Experience Replay、Dueling DQN、Distribution DQN 等。通过综合这些技术的优点,彩虹算法能够更有效地学习值函数,提高算法的性能和稳定性。
优点:在各种环境中都表现出了良好的性能,能够快速收敛到较优的策略;结合了多种技术,充分利用了各自的优势,对不同类型的任务都有较好的适应性。
缺点:由于结合了多种技术,模型复杂度较高,训练和调优相对困难;需要更多的计算资源和时间来运行。