DeepSeek-V3 解析第二篇:DeepSeekMoE
这篇文章是我们 DeepSeek-V3 系列的第二篇,聚焦于 DeepSeek 模型 [1, 2, 3] 的一个关键架构突破:DeepSeekMoE。
📚 本文也是我们【LLM 架构演化系列】的第二篇,聚焦 DeepSeek-V3 的 MoE 架构创新。如果你正研究大模型性能优化或架构设计,欢迎参考本系列其他内容,我们也整理了多份内部实验图与流程笔记,读者留言即可交流获取。

Vegapunk №02——One Piece 角色,由 ChatGPT 生成插画
在本文里,我们会聊聊什么是 Mixture-of-Experts(MoE)、它为什么在 LLM 里越来越火,以及它带来的挑战。我们还会看看专家专精和知识共享之间的平衡,以及 DeepSeekMoE 如何优化这笔买卖。
最妙的是:为了让概念更直观,我们会用「餐厅」的比喻,把 MoE 的每个元素都对应到厨房里的厨师角色上来讲。
如果你想看 DeepSeek 系列其他文章,戳这里:
• Part 1:Multi-head Latent Attention
本文目录:
• 背景:介绍 MoE 的运作方式、优势与挑战,并聊聊专家专精与知识共享的取舍。
• DeepSeekMoE 架构:细说细粒度专家分段与共享专家隔离。
• 评测:通过一系列实验展示 DeepSeekMoE 的表现。
• 总结。
• 参考文献。
背景
LLM 里的 MoE(Mixture-of-Experts)
在 LLM 语境下,MoE 通常是把 Transformer 里的 FFN 层换成 MoE 层,下图示意:
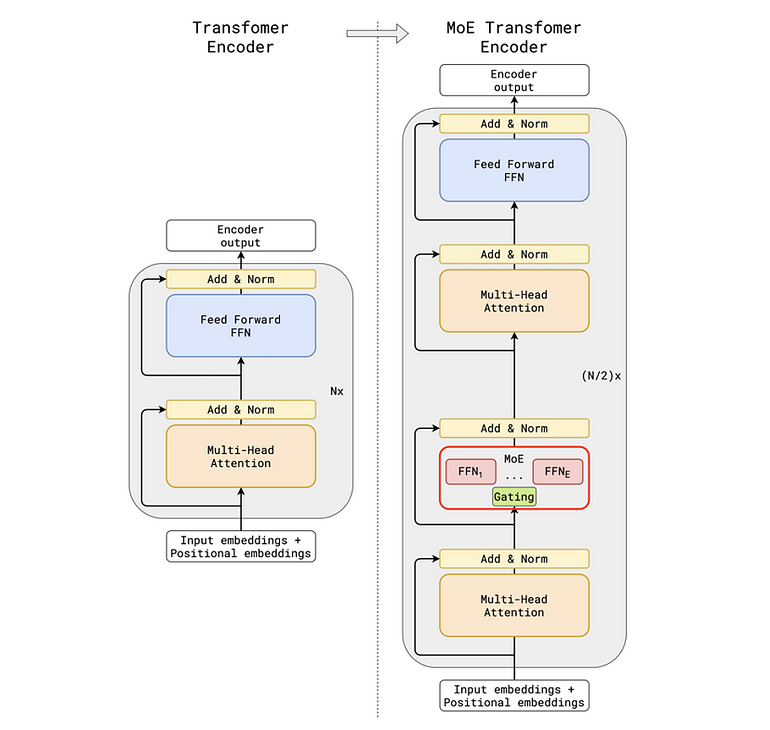
图 1. MoE 层示意,图片摘自 GShard 论文 。
左边是一堆 N 层 Transformer,每层有一个 MHA 子层 + 一个 FFN 子层。右边是一堆 N/2 层 Transformer,隔一层就把 FFN 换成 MoE。所以说,MoE 层按配置间隔取代 FFN。
往 MoE 层里看,它有一个 Gating 操作,再跟多个 FFN——这些 FFN 结构跟普通 FFN 一样,被叫作「专家」。Gate 训练来决定给定输入该叫哪个专家上场。
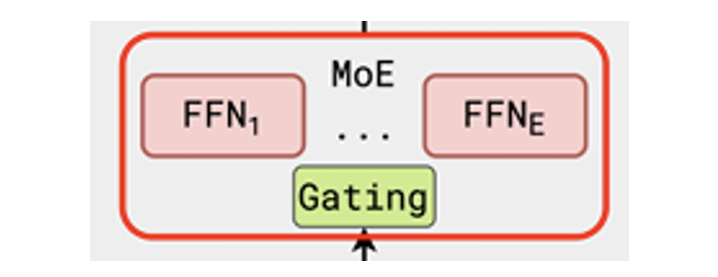
图 2. MoE 层:Gate + 多个 FFN 专家。图片来自 。
MoE 的通用公式(沿用 [4] 的公式编号):
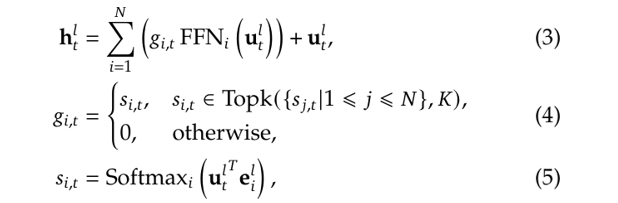
其中:
• u^l_t 和 h^l_t 分别是第 l 层、t 号 token 的输入/输出隐藏态。
• FFN_i 是第 i 个专家,总共 N 个。
• g_{i, t} 是 token t 对专家 i 的 gate 值,由 softmax 后 TopK 得到。
• e^l_i 是式 (5) 里的专家 i 的「质心」,把之前路由到该专家的所有输入 token 聚合得来。
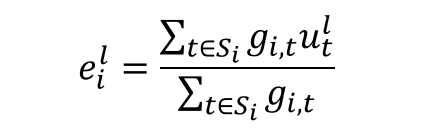
下面我们倒着过一遍 (5)→(3):
• 式 (5):u^l_t 跟 e^l_i 做内积,算 token 跟专家平均输入的相似度。直觉上,之前常服务于类似输入的专家更合适。一通 softmax 把分数弄成概率分布。N 个专家就出 N 个 s_{i, t}。
• 式 (4):对全部 s_{i, t} 做 TopK,得到稀疏的 g_{i, t}。
• 式 (3):用稀疏 g_{i, t} 选 K 个专家算输出。
也就是说,N 个里面只激活 K 个专家(通常 K 很小)。总参数暴涨,但每次前向只用到一小部分。
“总参数 236B,但每个 token 只激活 21B……”
那多搞 MoE、参数陡增到底图啥?
MoE 的好处与挑战
MoE 的妙处跟很多现实系统一个路数,用比喻很好懂。
想象开一家中餐+意大利餐的饭店,招厨子有俩方案:
• 方案1:找一个中意都精通的大厨,单刷所有菜——对应普通 Transformer,一个 FFN 顶所有 token。
• 方案2:请一批专攻中餐或意餐的厨子,再配一个主厨指派订单——对应 MoE:每个厨子是专家,主厨是 Gate。
显然方案2更好招人,菜也更地道;方案1想找通天大厨难如登天。
回到 LLM,MoE 背后的动力有「尺度假设」:模型越大越容易蹦出涌现能力。GPT 从 117M 升到 175B 就是例子。但不是谁都烧得起巨额算力。MoE 折中:整体模型规模上去,算力/显存成本靠「稀疏激活」压下来。
[4] 里演示:2B 模型只激活 0.3B,16B 激活 2.8B,145B 激活 22.2B,激活比例约 1/7,训练推理都省。
但设计都有坑。MoE 很吃 Gate,路由不准就「专家塌缩」——部分专家被用爆,其他吃灰;负载失衡、稳定性差,全来。
所以负载均衡是 MoE 的热门议题。DeepSeekMoE 也有招,这篇先讲核心创新,负载均衡(比如无辅助损的均衡 [8])下回说。
💡 MoE 在工业部署中涉及多个设计抉择,如专家分配策略、负载均衡方法、通用 vs 专精结构取舍等,我们在实际工程里踩过不少坑。如你在工程实现过程中有类似困惑,欢迎一起探讨,我们将持续整理 DeepSeekMoE 的复现与对比实践细节。
知识专精 vs. 知识共享
招厨子时,也在权衡全能 vs. 专精:方案1 偏全能但深度有限,方案2 偏专精。MoE 里同样:每个专家只见部分 token,自然应各有侧重,同时共享参数让知识有交集。但度不好量化。
过度专精 → 不稳、路由错位掉性能、容量浪费。
过度雷同 → 多出来的参数没产出,浪费算力。
接下来看看 DeepSeekMoE 怎么调这个平衡。
DeepSeekMoE 架构
DeepSeekMoE 用两招调专精/共享:细粒度专家分段 + 共享专家隔离。
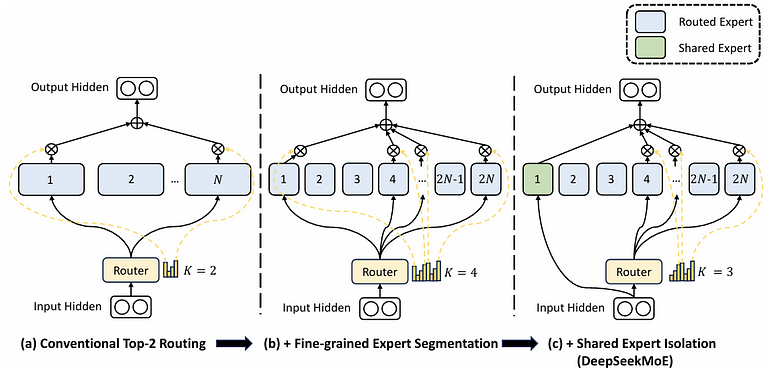
图 3. DeepSeekMoE 示意。
细粒度专家分段
为了鼓励专精,DeepSeekMoE 把专家细分。直觉:一个 token 激活更多专家,知识被拆分分配给多个专家的概率大。
餐厅比喻:原本一个厨子包全部中餐、另一个包全部意餐;细分后,多位厨子各负责中餐里的炒、蒸、煮,或意餐里的面、酱、烤,如下图。
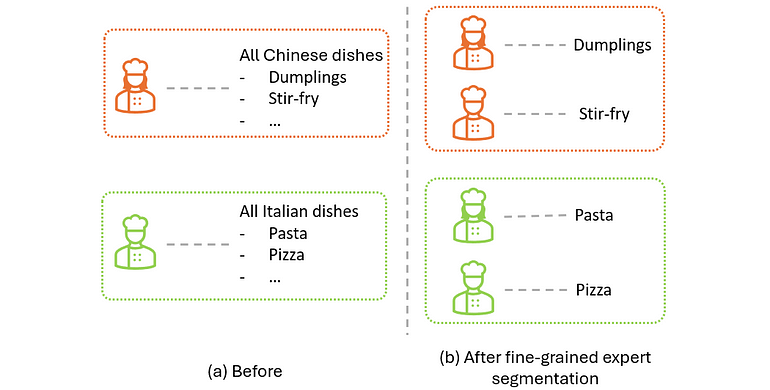
图 4. (a) 细分前 vs. (b) 细分后,餐厅示意。作者自绘。
图 3 里 (a) 每 token 路由到 N 个专家里的 2 个;(b) 把专家数量翻 m 倍到 2N,每个专家宽度缩 1/m,每 token 路由 4 个专家,计算量持平。
作者虽没给理论证明,但实验验证了,评测部分见。
共享专家隔离
第二招:隔离出「共享专家」减少冗余。直觉:留几位专家学通用知识,剩下专家更专注专精。
餐厅比喻:再把厨师分两组——上半是通用技法(刀工、火候、基本调味),下半各自研究招牌菜,如下图。
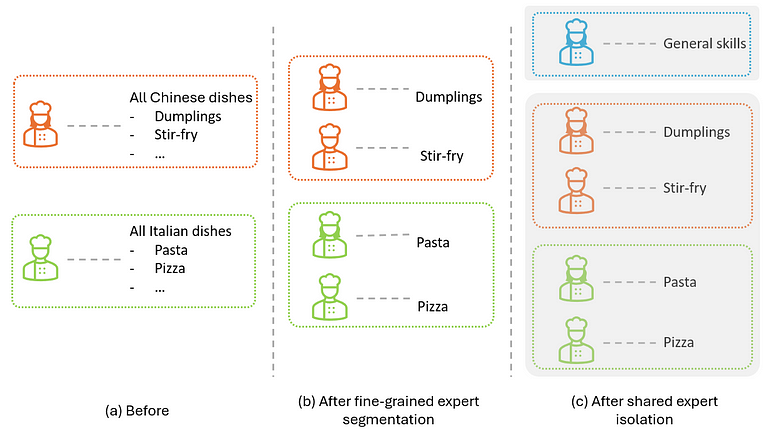
图 5. 在图 4 基础上加共享专家隔离示意。作者自绘。
图 3 © 里,一个专家标绿,作为共享专家:所有 token 都直接进它,不过路由器;同时把专精专家激活数从 4 减到 3,总激活数跟图 3 (b) 持平。
合起来,如下图右侧把 DeepSeekMoE 公式化,并跟通用 MoE 对比。
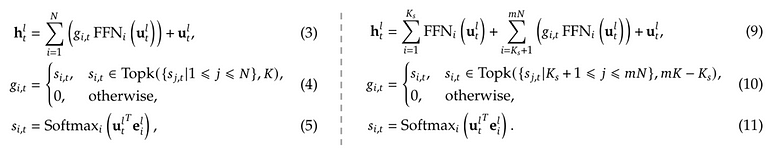
图 6. 左:通用 MoE;右:DeepSeekMoE。作者按 [4] 公式绘制。
其中:
• 式 (11) 同旧式 (5);
• 式 (10) 类似 (4),但在 (mN – K_s) 个专家里 TopK 选 (mK – K_s) 个,K_s 是共享专家数;
• 式 (9) 把 (3) 的第一项拆成共享专家 + 路由专家两项。
虽然无严格理论证明,但下节评测表明,共享专家提升表现并减冗余。
评测
上文两招听着靠谱,但到底多大用?问三点:
• DeepSeekMoE 结果到底更好吗?
• 细粒度专家分段到底多大程度促专精?
• 共享专家隔离能多大程度降冗余?
作者设计了一系列实验。
DeepSeekMoE 结果更好吗?
先看整体性能:训练一批总参/激活参近似的模型,多任务评估,主结果如下,最佳指标加粗。
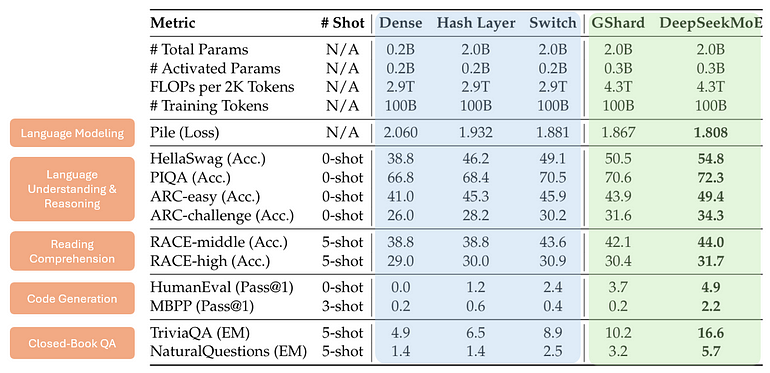
图 7. 整体表现。作者依据 [4] 表 1 绘制。
要点:
• 蓝列:普通 Transformer(Dense) vs. Hash Layer [6] / Switch Transformer [7] 两种 MoE,同激活参下,MoE 明显强。
• 绿列:DeepSeekMoE vs. GShard [5],同激活参下,DeepSeekMoE 更强。
但整体好 ≠ 专精/共享平衡好,所以继续测。
细粒度分段真促专精吗?
直接量化专精难,于是作者反向操作:禁用最常被路由的专家看看掉多少分。更加专精 → 更难被替换 → 性能掉得多。
实验:禁用部分顶流专家,比 DeepSeekMoE 和基线 GShard x 1.5(两者禁用前 Pile loss 相近)。
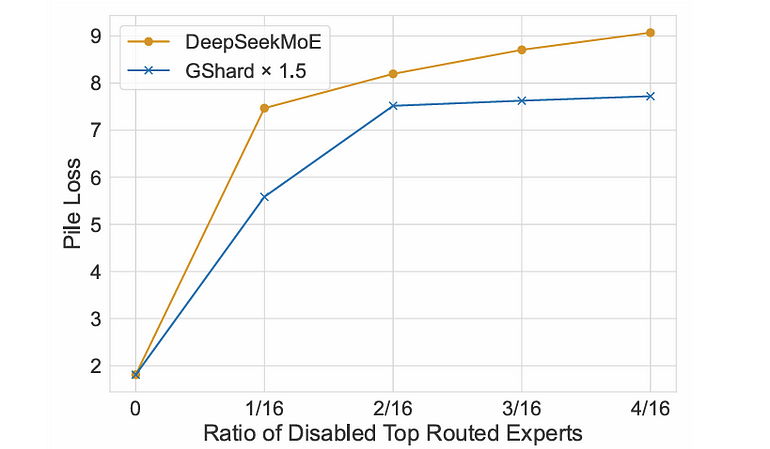
图 8. 禁用顶流专家后的 Pile loss。图片来自 [4]。
禁用比例越高,DeepSeekMoE 的 loss 一直更高,说明其专家更专精、替换性更差。
共享专家隔离真降冗余吗?
同理,作者把共享专家关掉,再多开一个路由专家,看看能否顶上。结果 Pile loss 从 1.808 飙到 2.414,说明共享专家掌握的知识独特,路由专家顶不上——冗余更少,专精更高。
总结
本文用餐厅比喻讲了 DeepSeekMoE——DeepSeek-V2 / V3 用到的关键架构创新。
我们先介绍了 MoE 的工作原理、优缺点和专精 vs. 共享的取舍,然后说明了 DeepSeekMoE 的两大招:细粒度专家分段、共享专家隔离,并在评测里看它们带来的提升。
核心 takeaway:DeepSeekMoE 通过促进专家专精,在与通用 MoE 近似的计算成本下提升了效果,算力利用更高效。
📘 这只是 DeepSeekMoE 架构探索的开篇。未也有时间我们还将深入分析其负载均衡机制,并对比主流 MoE 实现。如果你想系统理解 MoE 架构的工程化落地,可留言「MoE实践」获取我们内部使用的调优策略图和模型结构对比表。
参考文献
[1] DeepSeek
[2] DeepSeek-V3 技术报告
[3] DeepSeek-V2:一种强大、经济且高效的专家混合语言模型
[4] DeepSeekMoE:迈向专家混合语言模型的终极专家特化
[5] GShard:通过条件计算与自动分片扩展巨型模型
[6] Hash Layers:用于大型稀疏模型的哈希层
[7] Switch Transformers:通过简单高效的稀疏性扩展到万亿参数模型
[8] 无辅助损失的专家混合负载均衡策略