基于MCP协议实现一个智能审核流程
背景
昨天下午,同事发来一个需求,大概的意思就是想把一些简单又重复性很高的工作,单拎出来,看看能不能试着用人工智能的方式来给运营人员减减负。
大概看了一下这些需求,基本包括以下几个要点
- 审查材料附件里的关键信息和在用户提交的基本信息是否一致,比如姓名,证件号等等
- 审查指定一些PDF材料是否能正常打开,有的用户上传的材料没等上传结束就退出系统,会导致文件完整性异常
- 审查照片是否清晰,背景图片是否是纯色
- …诸如此类
我简单总结了一下,然后觉得这完全契合MCP Server的处理流程啊!
首先,整个的工作,只是鉴定材料和信息是否合规,并不涉及专业领域,所以可行性大大提高。
其次,这些工作的核心,主要还是一个比对的工作,就类似一个材料审查员,看看写的材料到底对不对,有没有丢项漏项之类。
基于此,我今天花了点时间,封装了几个MCP Server Tool,然后用Cline测试了一下,效果非常好!
接下来,咱们简单聊一下这个处理的流程
编写MCP Server
这里,还是在我上篇那个项目案例(https://juejin.cn/post/7497074247777845287)下的扩充。
这里,我先准备2个Tool,分别是识别PDF文档和鉴定PDF文档是否是扫描件。
鉴定PDF工具
鉴定的思路有很多,我这里提供一个思路,然后给出部分代码,完整的代码大家可以GPT一下就好。
- 首先,待鉴定的PDF文件,可能是本地文件,也可能是网络文件,这里先将文件统一缓存到本地
- 判定文件是否可读,如果不可读,则返回鉴定结果
- 可读的文件获取一下文档页数,如果页数较少,则整个文档都检查一遍,反之检查少部分页面(平衡一下处理性能)
- 如果检查到有文本,那说明不是扫描件,反之则是
- 最后,看情况清理掉临时的处理文件
注意,我这里判定是不是扫描件的方式相对简单,实际要根据具体业务场景做调整
看下代码
[McpServerTool(Name = "IsScanner"), Description("鉴定文档是不是扫描件")]public dynamic IsScanner([FromServices] IResponseHelper _resp,[Description("文档路径,可能是本地路径也可能是网络路径")] string pdfpath){Guangdong.Assistant.Logger.Warning("鉴定文档插件正确执行");if (new PdfScannerChecker().IsScannedPdf(pdfpath)){return _resp.error("该文件是扫描件");}return _resp.success("ok");}
PDF的处理代码我这里也给出来,实际上大家并不需要参照这个版本
/// <summary>
/// 判断一个PDF文件是否为扫描件。
/// </summary>
/// <param name="filePathOrUrl">PDF文件路径或URL。</param>
/// <param name="pageLimit">检查前几页。</param>
/// <returns>如果是扫描件返回true,否则返回false。</returns>
public bool IsScannedPdf(string filePathOrUrl, int pageLimit = 0)
{var fileResolution = GetLocalFile(filePathOrUrl);if (fileResolution == null){Magic.Guangdong.Assistant.Logger.Error("Failed to download or open the file.");return false;}string localFilePath = fileResolution.FilePath;bool isTempFile = fileResolution.IsTempFile;// 检查文件是否可读if (!FileIsReadable(localFilePath)){Magic.Guangdong.Assistant.Logger.Error($"The file {filePathOrUrl} cannot be opened."); if (isTempFile) File.Delete(localFilePath); // 清理失败时也尽量删掉无效文件return false;}try{using (var pdfDocument = PdfDocument.Open(localFilePath)){if (pageLimit == 0){int totalPages = pdfDocument.NumberOfPages;pageLimit = totalPages < 5 ? totalPages : 5;}foreach (var page in pdfDocument.GetPages().Take(pageLimit)){// 检查文本if (!string.IsNullOrWhiteSpace(page.Text)){continue; // 如果有文本,则跳过该页}// 检查图像var images = page.GetImages();if (images.Any()){// 简单地认为如果存在图像,则可能是扫描件return true;}}}}finally{// 如果是临时文件,处理完成后删除if (isTempFile && File.Exists(localFilePath)){try{File.Delete(localFilePath);Magic.Guangdong.Assistant.Logger.Warning($"Temporary file {localFilePath} has been deleted.");}catch (Exception ex){Magic.Guangdong.Assistant.Logger.Error($"Failed to delete temporary file: {ex.Message}");}}}return false; // 如果没有找到任何图像且所有检查的页面都没有文本,则认为不是扫描件
}
识别PDF内容
这里有的模型已经具备识别PDF文档的功能,当然我们也可以用一些开放平台提供的能力,这点就根据实际情况采取合适的方案就好。
我这里是使用的百度云的API做的PDF识别。
识别代码,就不再列举,看下工具代码
[McpServerTool(Name = "DetectApplyForm"), Description("识别申报表内容")]
public async Task<dynamic> DetectApplyForm([FromServices] IBaiduOcrHelper _baiduOcrHelper,[FromServices] IResponseHelper _resp,[Description("申报表PDF路径")] string pdfpath)
{Guangdong.Assistant.Logger.Warning("文档识别插件正确执行");return _resp.success(await _baiduOcrHelper.DocumentRecognition(pdfpath));}
验证
Inspector
有这两个Tool,就可以做验证工作了,先用Inspector看看工具的运行是否正常。
这里我们输入路径参数,看到MCP Server正确执行,Client上返回了期望的结果。
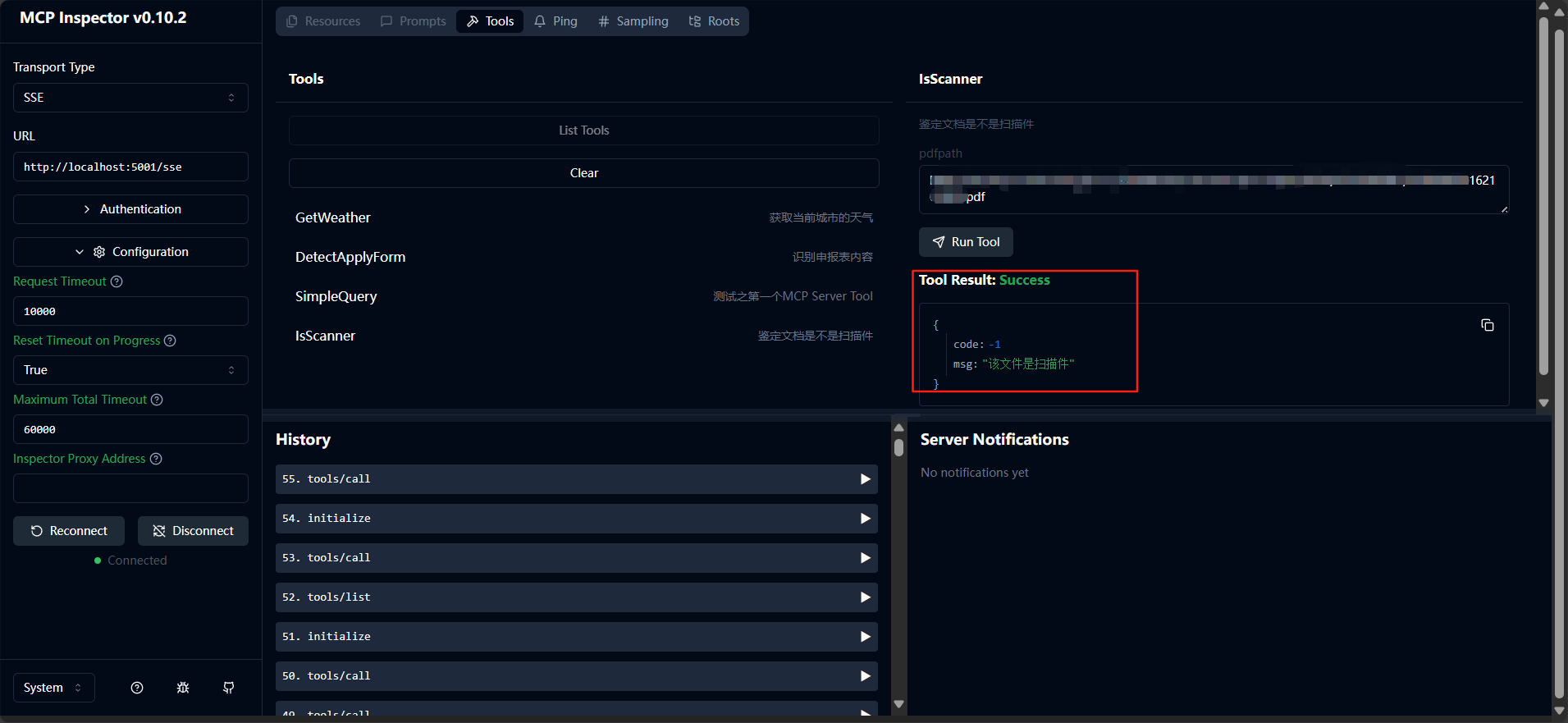
再看看PDF文档识别的效果
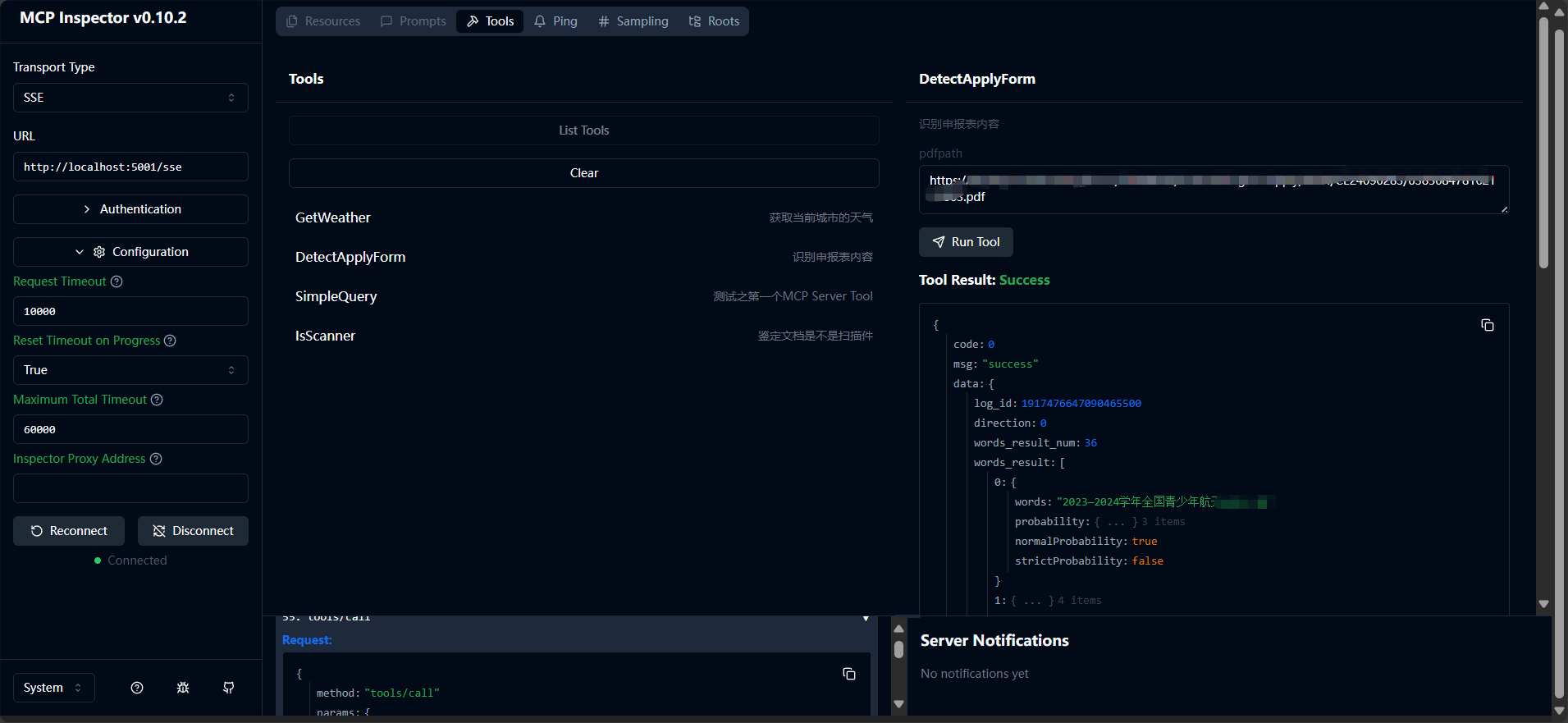
可以看到,两个插件都正常执行。
到这里,我们就可以继续完善我们的Server Tool,然后在业务系统的Client端,调用MCP Server的能力来完成自动审核的任务了。
Cline
上篇我提到的SK框架就可以胜任这个工作,但这里我想介绍一下另外一个更适合我们开发者的MCP Client,Cline!
用它,我们可以最大限度的在真正开始开发自己的业务Client前,模拟出整个AI自动处理的流程。
安装配置
关于Cline的安装配置,我这里不过多解释,大家参照官方文档配置即可,没什么比官网更合适的入门文档了。
https://cline.bot/
配置模型
在Cline中配置一个有Function Call能力的模型,我这里使用的是Qwen系列,说起来,Qwen最近新发布的Qwen3开源模型已经原生支持MCP了,相当炸裂。
配置界面如下👇

连接MCP Server
打开Clien的配置文件,或者进入他的配置窗口,配置上我们本地的MCPServer
{"mcpServers": {"firecrawl-mcp": {"timeout": 60,"command": "cmd","args": ["/c","set FIRECRAWL_API_KEY=**不告诉你** && npx -y firecrawl-mcp"],"transportType": "stdio"},//👇这个"LocalMCP": {"url": "http://localhost:5001/sse","disabled": false,"autoApprove": []}}
}
模拟审核流程
配置工作完成以后,我们就可以在Cline上先模拟一下AI的整个审核流程了
来看下处理的截图(敏感信息已遮挡)
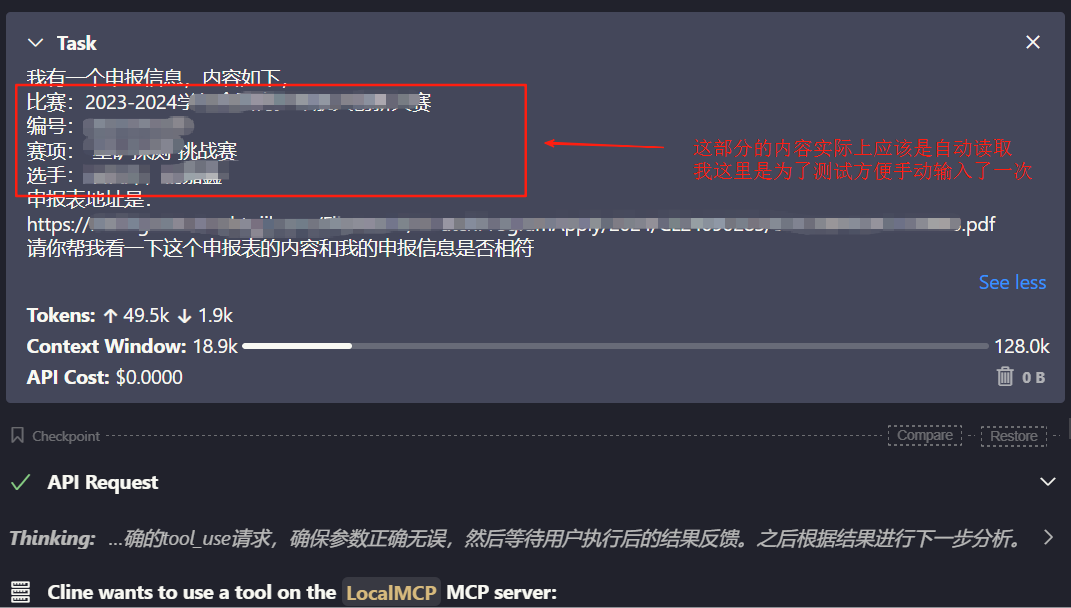
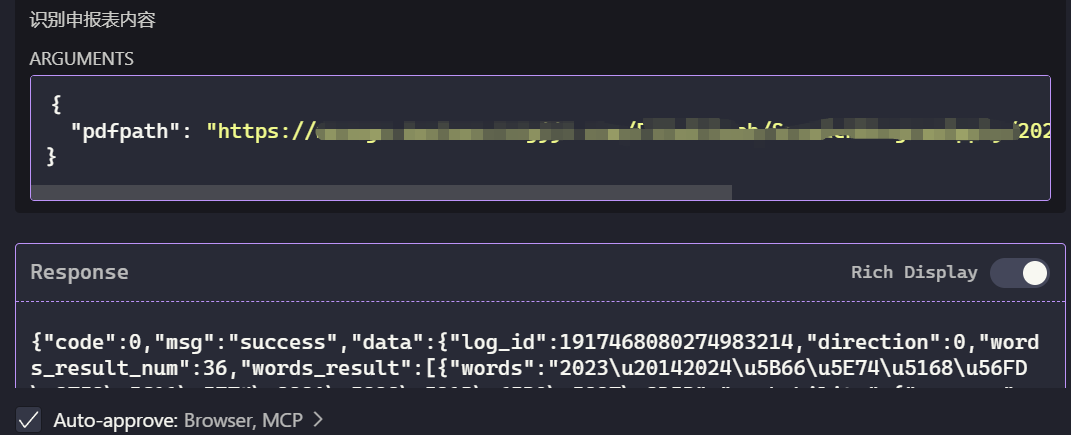


这样,我们就能在编写完Server之后,先利用Clien做一下整体的集成测试,发现效果和我们预期的效果相差无几时,就可以真正上手去编写业务代码了。
好了,基本就是这样了,赶在五一之前再发一篇,假期快乐。