C++之基于正倒排索引的Boost搜索引擎项目介绍
1. 为什么我们要写项目
1.1 把理论知识转化为实际能力
计算机专业的课程(如编程语言、数据结构、算法、操作系统等)多以理论和抽象概念为主,而项目是 “用起来” 的过程。比如学了数据结构中的链表、树,只有在做通讯录管理系统、文件索引工具等项目时,才能真正理解它们在实际场景中的作用;学了多线程,在开发简单的并发程序(如聊天软件)时,才会明白锁机制、线程同步的实际意义。
1.2 培养解决复杂问题的思维
项目开发中总会遇到各种 “意料之外” 的问题:代码逻辑漏洞、性能瓶颈、兼容性问题等。解决这些问题的过程,能倒逼你学会拆解问题、查阅文档(如官方手册、技术博客)、调试代码(用 IDE 断点、日志分析),甚至借鉴开源项目的思路 —— 这些都是未来工作中不可或缺的 “实战思维”。
1.3 理解完整的开发流程
实际工作中的开发不是孤立写几行代码,而是从需求分析、设计架构、编码实现,到测试优化、版本管理的全流程。通过做项目,你会接触到 Git 等版本控制工具、单元测试方法,甚至团队协作(如分工开发、代码评审),提前适应工业界的开发模式。
1.4 构建个人竞争力
无论是求职还是深造,项目经验都是重要的 “证明”。简历上的项目能直观体现你的技术栈(如用 Python 做数据分析、用 Java 开发 Web 应用)和解决问题的能力,面试中也能通过讲解项目细节,展示自己的技术深度和思考过程,这比单纯的成绩更有说服力。
2. 什么是搜索引擎
我们平常在生活里面使用的Google,百度,360浏览器,搜狗搜索之类的就是搜索引擎。当然这是一种简单说法,复杂点来说搜索引擎是一种通过特定算法从互联网上抓取、索引并检索信息的工具,旨在帮助用户快速找到所需内容。其核心功能包括网页抓取(爬虫技术)、建立索引库、排序算法(如PageRank)以及用户交互界面。
3. 搜索引擎基本逻辑讲解
首先我们的手机或者电脑使用浏览器上传关键字http请求,接着服务器收到我们的请求后进行去标签并建立索引,然后通过以前在全网建立的索引来进行查找,接着把找到的内容经过排序拼接到一起,构建一个全新的网页并返回给用户。
如果画成图的话差不多就是这样:
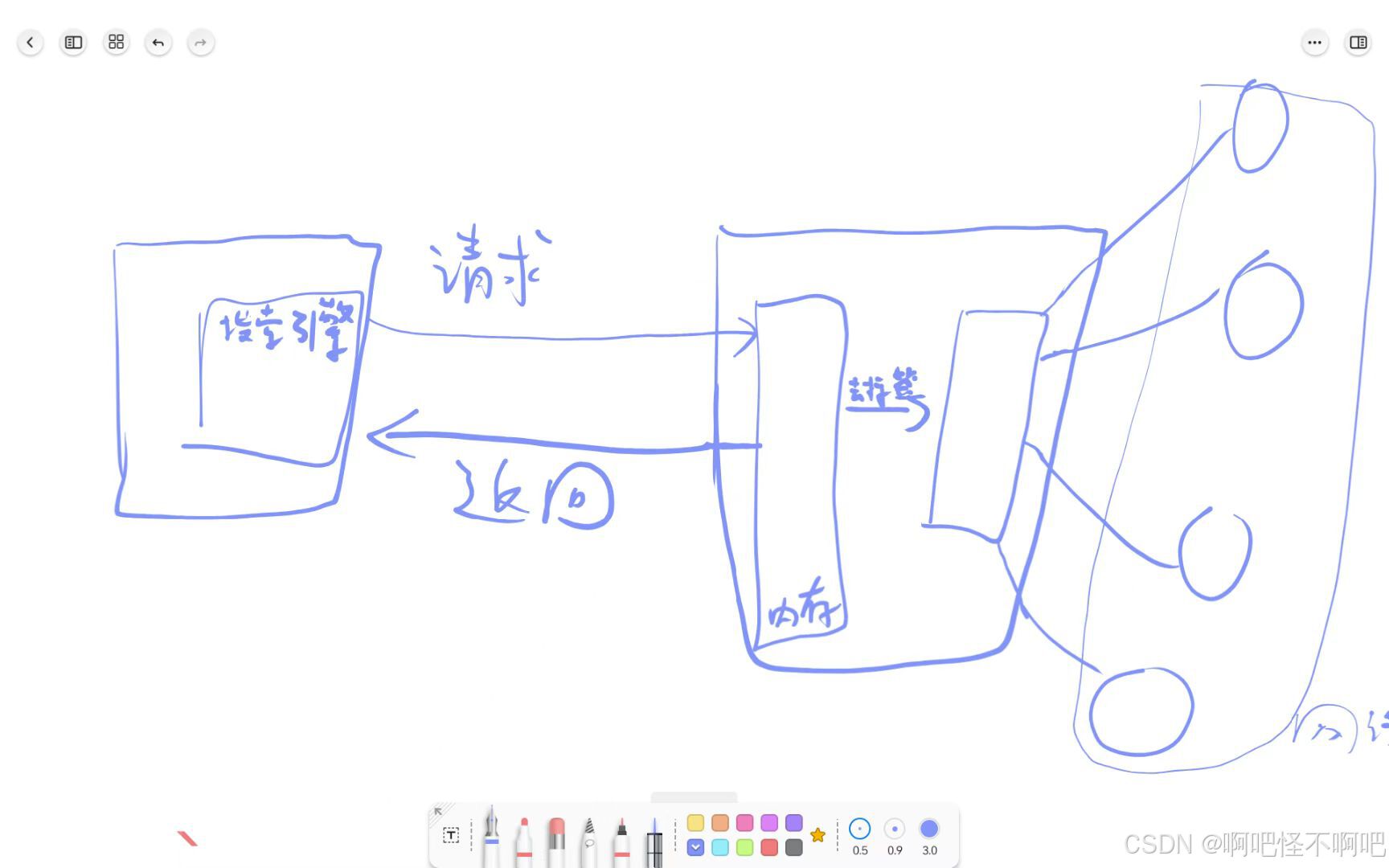
同时我们还会使用到正排索引与倒排索引,这两个互相配合共同帮助服务器高效定位并返回用户需要的内容。
4 正排索引
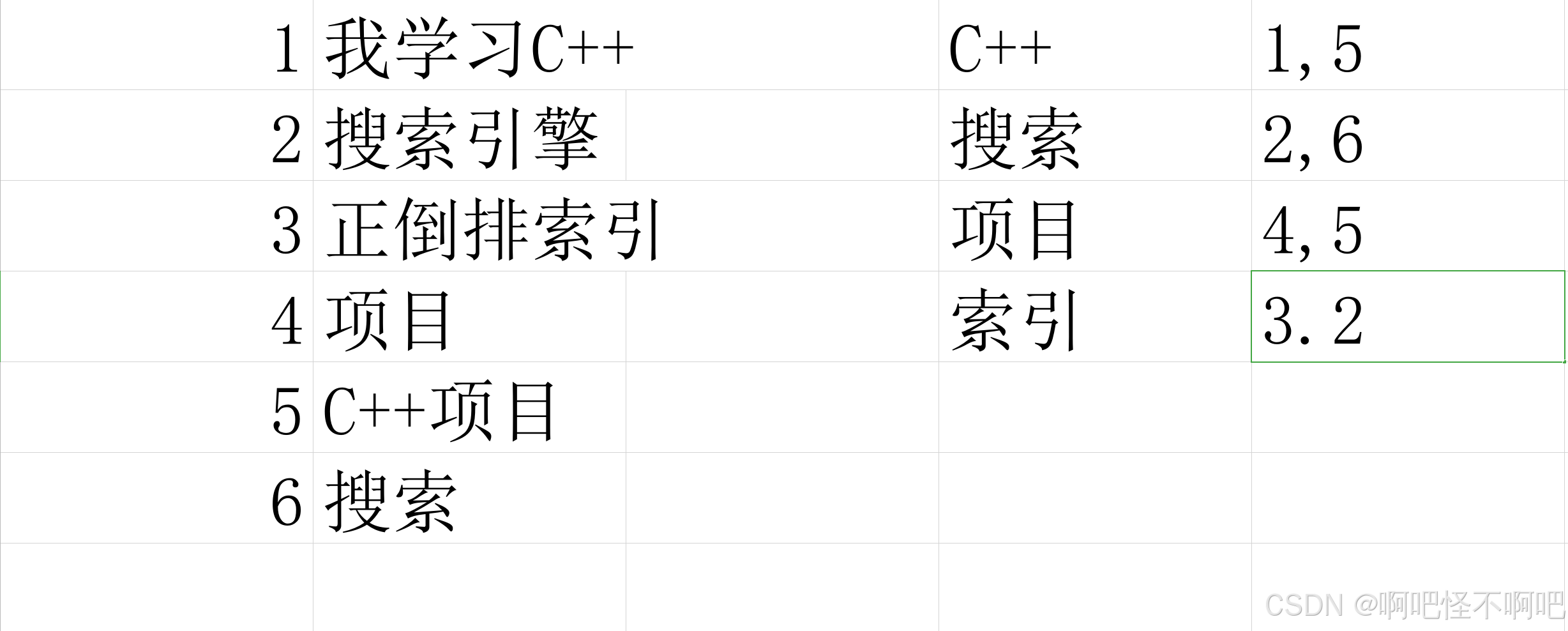
正排索引(Forward Index)是一种以文档为中心的数据结构,存储每个文档及其包含的单词列表。与倒排索引(通过单词查找文档)相反,正排索引通过文档ID直接获取文档内容及其词项信息。
通常以键值对形式存储:
- 键:文档ID(如整数或字符串标识符)。
- 值:文档的元数据(如标题、URL)及词项列表(可能包含词频、位置等)。
就是类似于下图的方式我通过3就可以访问到“ 搜索引擎 ”

4.1 正排索引的优缺点
优点:
- 文档内容获取高效,适合需要高频访问原始数据的场景。
- 结构简单,易于实现和维护。
缺点:
- 无法直接支持关键词到文档的映射,需依赖倒排索引完成搜索。
- 存储开销较大,尤其对长文本或海量文档集。
5. 倒排索引
倒排索引(Inverted Index)是一种数据库索引结构,用于快速查找包含特定单词或内容的文档。与传统的正排索引(按文档顺序存储内容)不同,倒排索引以单词或词项为键,记录其出现在哪些文档中。这种结构广泛应用于搜索引擎、全文检索等场景。
倒排索引的组成方式:
- 词项词典(Term Dictionary):存储所有唯一的单词或词项,通常按字典序排列。
- 倒排列表(Posting List):每个词项对应一个列表,记录包含该词项的文档ID及其出现位置(如词频、偏移量等)。
做成图片的话右边那个就是倒排索引,通过关键字来找到是那个文档或者说是那个key。
6.正倒排索引协作
一、角色分工:倒排索引 “找文档”,正排索引 “读内容”
- 倒排索引:以关键词为核心,存储 “关键词 → 文档 ID 列表” 的映射。
作用是快速筛选匹配关键词的文档集合。例如用户搜索 “人工智能”,倒排索引会直接返回所有包含该词的文档 ID(如 Doc1、Doc2、Doc3…),避免遍历全网文档,大幅提升检索效率。 - 正排索引:以文档 ID 为核心,存储 “文档 ID → 原始内容(标题、正文、作者等)” 的映射。
作用是根据文档 ID 获取具体内容。例如倒排索引返回 Doc1 的 ID 后,正排索引会调取该文档的标题、摘要等信息,用于最终生成搜索结果页面。
二、协作流程:从用户搜索到结果展示的完整闭环
- 用户发起查询:在浏览器输入关键词(如 “5G 技术”),发送 HTTP 请求到搜索引擎服务器。
- 倒排索引筛选文档 ID:服务器先对关键词分词(如 “5G”“技术”),然后在倒排索引中查找所有包含这些词的文档 ID(如 Doc101、Doc205)。
- 正排索引提取文档内容:根据倒排索引返回的 ID,从正排索引中获取这些文档的标题、摘要、发布时间等元数据。
- 结果排序与返回:结合排序算法(如 TF-IDF、BM25)对文档相关性打分,将最终结果拼接成网页,通过 HTTP 响应返回给浏览器。
三、协作的必要性:解决 “效率” 与 “内容” 的双重需求
- 没有倒排索引:服务器需遍历所有文档(如全网数十亿网页)查找关键词,速度极慢,无法满足实时搜索需求。
- 没有正排索引:倒排索引仅能返回文档 ID,无法获取具体内容,用户看不到任何有意义的搜索结果。
四、类比理解:如同 “书籍目录 + 正文” 的配合
- 倒排索引 ≈ 书籍的目录:通过关键词(章节标题)快速定位页码(文档 ID)。
- 正排索引 ≈ 书籍的正文:通过页码(文档 ID)查看具体内容(章节文字)。
两者缺一不可 —— 目录帮你快速找到目标章节,正文让你阅读具体内容。
简言之,倒排索引负责 “快速筛选文档”,正排索引负责 “补充文档细节”,二者协作构成搜索引擎高效检索的核心机制。
正倒排索引是在内存里面的,搜索引擎是先所以爬虫获取数据,然后在通过正倒排索引来建立索引的。
PS:搜索引擎的爬虫和正倒排索引是一直在后台运行的,不管我们此时有没有使用搜索引擎。
我们在接下来的项目实现中不会使用爬虫,而是通过boost里面下载数据的方式来实现。