ES6手录01-let与const
:::info
推荐的学习文档:https://es6.ruanyifeng.com/
:::
:::info
推荐的学习文档:https://developer.mozilla.org/zh-CN/docs/Web/JavaScript
:::
一、ES6基础认知
(一)ES6简介
ES6,全称ECMAScript 6.0,作为JavaScript语言的下一代标准,于2015年6月正式发布。其核心目标是让JavaScript能够胜任复杂大型应用程序的开发工作,跻身企业级开发语言行列。
从与JavaScript的关系来看,ES6是JavaScript的规格标准,而JavaScript则是ES6的一种实现。打个比方,就如同“汽车设计标准”与“具体品牌汽车”的关系,ES6规定了语言应具备的特性和规则,JavaScript按照这些规则进行具体实现。
(二)ES6与ES5的关系
- 版本演进:ES6是ES5.1版的下一代标准,是在ES5基础上的一次重大升级。
- 兼容性:ES6完全兼容ES5,这意味着之前用ES5编写的代码在支持ES6的环境中依然可以正常运行,同时ES6新增了大量实用的语法特性,如箭头函数、类、模块等。
- 开发背景:JavaScript最初开发十分仓促,仅用10天就完成了初步设计,存在诸多设计缺陷和功能不足。随着前端技术的快速发展,JavaScript需要承担更复杂的开发任务,ES6应运而生,对JavaScript进行了大量补充和完善,以满足企业级开发需求。
- 现状:目前前端技术已进入稳定期,ES6之后的版本主要是进行小规模更新,逐步完善语言功能,不再有像ES6这样颠覆性的变化。
(三)ES6的发布历史
- 初始版本:2015年6月发布《ECMAScript 2015标准》,这是ES6的正式版本,标志着JavaScript进入了一个新的发展阶段。
- 后续版本
- 2016年6月发布ES2016(可视为ES6.1版),该版本仅新增了数组includes方法和指数运算符(**)两个特性。
- 2017年6月发布ES2017,新增了异步函数(async/await)、Object.values()、Object.entries()等特性。
- 此后,ECMAScript每年都会发布一个新版本,版本号以发布年份命名,如ES2018、ES2019等。
- 命名规则:ES6原本特指2015年发布的ECMAScript 2015标准,但随着后续版本的不断发布,ES6逐渐成为一个历史名词,现在泛指ES5.1版后的所有ECMAScript新标准。
- 版本差异:除了ES2016仅新增少量特性外,后续版本也都是在ES6基础上进行的增量更新,每个版本新增的特性数量相对较少,主要是对语言功能的进一步优化和补充。
(四)ES6的目标
- 解决痛点:弥补JavaScript语言设计初期的不足,比如修复var声明变量的缺陷、完善作用域机制等,让语言更加严谨和规范。
- 企业级开发:增强语言的严谨性,提供更强大的功能支持,如类、模块、模块化加载等,使JavaScript能够支持大型应用开发,满足企业级项目的需求。
- 标准化:建立统一的语言规范,避免不同浏览器厂商对JavaScript实现的差异,减少开发过程中的兼容性问题,提高开发效率。
- 未来发展:与TypeScript等新语言形成互补关系。TypeScript是基于JavaScript的超集,增加了静态类型检查等特性,而ES6的发展为TypeScript提供了更好的基础,两者相互促进,共同推动前端开发技术的进步。
(五)Babel转码器
- 作用:由于部分旧版本浏览器对ES6的支持不够完善,Babel转码器可以将ES6代码转换为ES5代码,从而使ES6代码能够在老版本的浏览器中正常执行。这意味着开发者可以使用ES6的新特性进行代码编写,而不必担心现有浏览器是否支持。
- 工作原理
- 配置文件:通过.babelrc配置文件设置转码规则,该文件通常位于项目根目录下。在配置文件中,可以指定需要使用的插件和预设(presets)。
- 预设规则集:支持presets预设规则集,如env、react等。其中,env预设可以根据目标浏览器或运行环境自动确定需要转换的ES6特性,react预设则用于转换React相关的JSX语法。
- 必要性:在前端开发中,为了兼顾兼容性和开发效率,使用Babel转码器是十分必要的。它允许开发者提前使用ES6的新特性,提升开发体验和代码质量,同时确保代码能够在各种浏览器环境中正常运行。
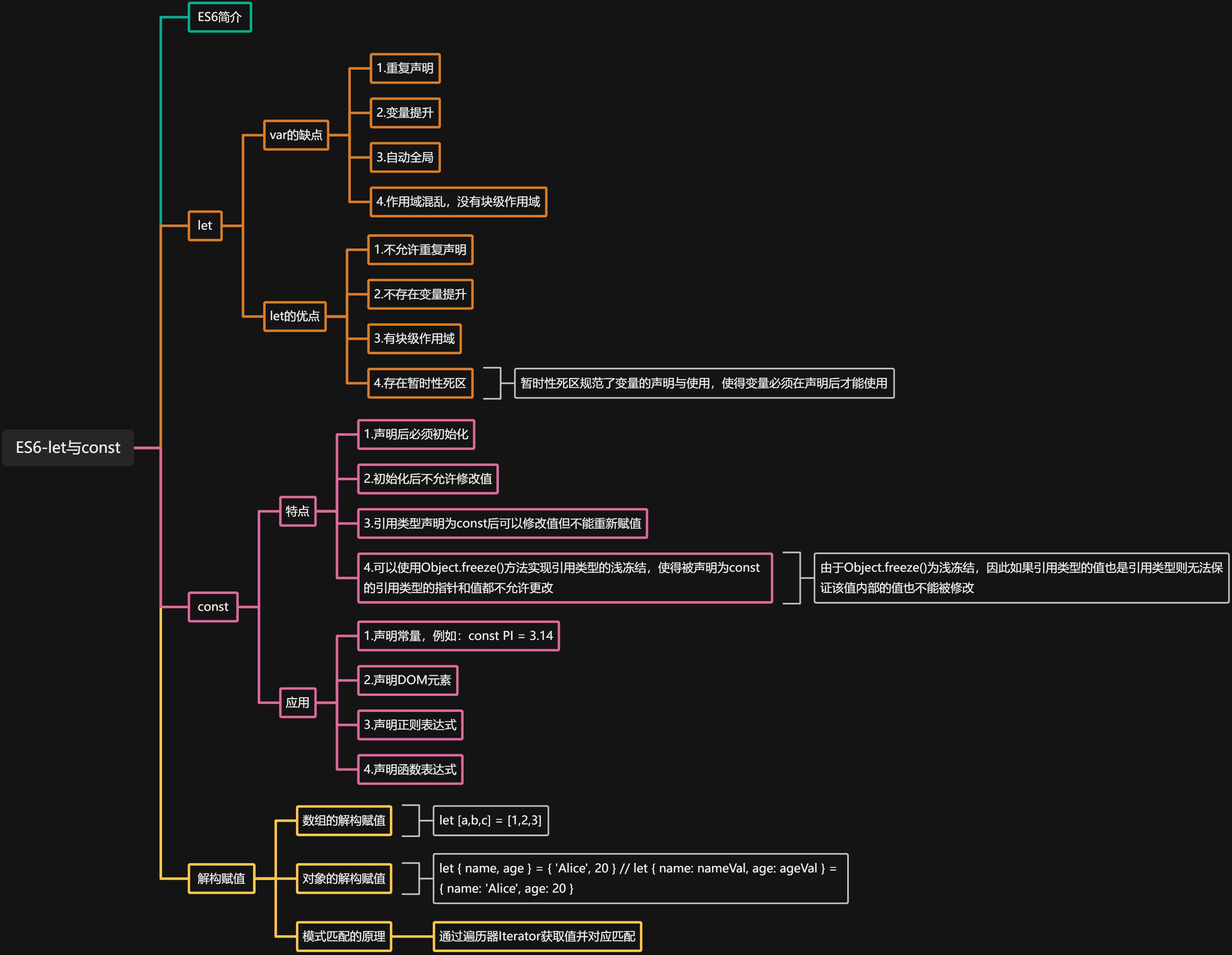
二、变量声明
(一)var的问题
- 重复声明:允许在同一个作用域内对同名变量进行重复声明,后声明的变量会覆盖前面声明的变量,这容易导致变量值被意外修改,增加代码的出错风险。例如:
var a = 10;
var a = 20;
console.log(a); // 输出20,前面的赋值被覆盖
- 变量提升:var声明的变量会被提升到作用域的顶部,即变量可以在声明之前被访问,此时变量的值为undefined,这种行为不符合常规的编程逻辑,容易造成代码逻辑混乱。例如:
console.log(b); // 输出undefined,变量b被提升
var b = 30;
- 自动全局:如果在函数内部或其他块级作用域内,使用var声明变量时遗漏了var关键字,该变量会自动成为全局变量,可能会污染全局命名空间,引发意外的错误。例如:
function fn() {c = 40; // 遗漏var,c成为全局变量
}
fn();
console.log(c); // 输出40
- 作用域混乱:var声明的变量只有函数作用域和全局作用域,没有块级作用域。在if语句、for循环等块级结构中使用var声明的变量,在块级结构外部依然可以访问,这可能会导致变量作用域混乱,影响代码的可读性和可维护性。例如:
if (true) {var d = 50;
}
console.log(d); // 输出50,d在if块外部可访问
(二)let声明
- 基本语法:使用let关键字声明变量,语法格式为
let 变量名 = 值;,其中值可以根据需要进行赋值,也可以先声明后赋值(但在声明前不能访问变量)。 - 特性
- 禁止重复声明:在同一个作用域内,不允许使用let重复声明同名变量,否则会抛出语法错误(SyntaxError)。这有效避免了var重复声明带来的变量值被意外覆盖的问题。例如:
let a = 10;
let a = 20; // 抛出SyntaxError: Identifier 'a' has already been declared
- **不存在变量提升**:let声明的变量不存在变量提升现象,变量只能在声明之后被访问。如果在let声明之前访问变量,会抛出引用错误(ReferenceError)。这种设计更符合正常的编程逻辑,减少了代码的潜在错误。例如:
console.log(b); // 抛出ReferenceError: Cannot access 'b' before initialization
let b = 20;
- **具有块级作用域**:let声明的变量具有块级作用域,即变量只在声明它的块级作用域(由大括号{}包裹的区域,如if语句、for循环、函数体等)内有效,在块级作用域外部无法访问该变量。这解决了var作用域混乱的问题,使变量的作用范围更加明确。例如:
if (true) {let c = 30;console.log(c); // 输出30,在if块内部可访问
}
console.log(c); // 抛出ReferenceError: c is not defined,在if块外部不可访问
- **存在暂时性死区(TDZ)**:在一个块级作用域内,如果存在let声明的变量,那么从块级作用域开始到变量声明语句之间的区域,被称为该变量的**暂时性死区**。**在暂时性死区内,即使外部有同名变量,也不能访问该变量,否则会抛出引用错误。暂时性死区的存在进一步规范了变量的使用,确保变量只能在声明之后被访问。**例如:
let d = 40;
if (true) {console.log(d); // 抛出ReferenceError: Cannot access 'd' before initialization,处于d的暂时性死区let d = 50;
}
- let在for循环中的应用:在for循环中使用let声明循环变量,每次循环都会创建一个新的变量绑定,使得每个循环迭代中的变量都是独立的。这解决了使用var声明循环变量时,循环结束后所有回调函数都访问同一个变量的问题。例如:
// 使用var声明循环变量
for (var i = 0; i < 5; i++) {setTimeout(function() {console.log(i); // 输出5个5,因为所有回调函数访问的是同一个i}, 100);
}// 使用let声明循环变量
for (let j = 0; j < 5; j++) {setTimeout(function() {console.log(j); // 输出0、1、2、3、4,每个回调函数访问的是对应迭代的j}, 100);
}
- 开发建议:在现代JavaScript开发中,推荐使用let替代var声明变量。无论是在Vue、React等前端框架开发中,还是在公司的实际项目开发中,let都已成为主流的变量声明方式。使用let可以实现更严格的变量作用域控制,避免变量提升带来的问题,防止意外重复声明,同时更好地支持块级作用域,提高代码的质量和可维护性。
(三)const声明
- 基本语法:使用const关键字声明常量,语法格式为
const 常量名 = 值;。与let不同的是,const声明的常量必须在声明时立即初始化,不能先声明后赋值,否则会抛出语法错误。例如:
const PI = 3.14159; // 正确,声明时初始化
const MAX; // 抛出SyntaxError: Missing initializer in const declaration,未初始化
- 特性
- 必须初始化:这是const与let的重要区别之一,const声明的常量在声明时必须赋予初始值,确保常量从一开始就有确定的值。
- 不能重新赋值:常量一旦声明并初始化,其值就不能被重新修改,尝试给const声明的常量重新赋值会抛出类型错误(TypeError)。例如:
const COLOR = 'red';
COLOR = 'blue'; // 抛出TypeError: Assignment to constant variable
- **其他特性与let相同**:const声明的常量同样具有块级作用域,不存在变量提升,并且存在暂时性死区。例如:
// 块级作用域
if (true) {const NUM = 100;console.log(NUM); // 输出100
}
console.log(NUM); // 抛出ReferenceError: NUM is not defined// 暂时性死区
const NAME = 'Alice';
if (true) {console.log(NAME); // 抛出ReferenceError: Cannot access 'NAME' before initializationconst NAME = 'Bob';
}
- 适用场景
- 声明常量:用于声明程序运行过程中值不会发生改变的常量,如数学常数(PI)、配置参数(API地址、默认端口号等)。例如:
const API_BASE_URL = 'https://api.example.com';
const DEFAULT_PORT = 8080;
- **DOM元素引用**:在DOM操作中,获取的元素对象通常不需要被重新赋值,使用const声明可以确保元素引用的稳定性。例如:
const box = document.getElementById('box');
box.style.color = 'red'; // 允许修改元素的属性,因为const限制的是引用不变,而非内容不变
- **正则表达式**:定义好的正则模式通常是固定不变的,使用const声明正则表达式可以避免其被意外修改。例如:
const EMAIL_REGEX = /^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$/;
- **函数表达式**:当使用函数表达式定义函数,且函数不需要被重新赋值时,使用const声明可以提高代码的可读性和稳定性。例如:
const add = function(a, b) {return a + b;
};
- const声明对象或数组时的注意事项
- 指针与内容区别:const声明的对象或数组,其限制的是变量存储的指针(即对象或数组在内存中的地址)不可变,而不是对象或数组内部的属性或元素不可变。也就是说,**不能将const声明的对象或数组重新赋值为一个新的对象或数组,但可以修改对象的属性值或数组的元素。**例如:
// 声明对象
const person = { name: 'Tom', age: 20 };
person.age = 21; // 允许,修改对象的属性值
console.log(person); // 输出{ name: 'Tom', age: 21 }
person = { name: 'Jerry', age: 18 }; // 抛出TypeError: Assignment to constant variable,重新赋值对象// 声明数组
const arr = [1, 2, 3];
arr.push(4); // 允许,修改数组的元素
console.log(arr); // 输出[1, 2, 3, 4]
arr = [5, 6, 7]; // 抛出TypeError: Assignment to constant variable,重新赋值数组
- **最佳实践**:对于不打算重新赋值的引用类型(对象、数组等),都建议使用const声明,以明确变量的不可重新赋值特性。**如果需要确保对象内部的属性也不可修改,可以结合Object.freeze()方法。**Object.freeze()方法可以冻结一个对象,使其属性不能被添加、删除或修改(**浅冻结,即如果对象的属性值也是引用类型,该引用类型的内部属性仍可修改**)。例如:
const frozenObj = Object.freeze({ name: 'Alice', age: 25 });
frozenObj.age = 26; // 严格模式下抛出TypeError,非严格模式下修改无效
console.log(frozenObj.age); // 输出25// 浅冻结示例
const obj = { info: { score: 90 } };
Object.freeze(obj);
obj.info.score = 95; // 允许修改,因为obj.info是引用类型,仅冻结了obj的直接属性
console.log(obj.info.score); // 输出95
三、变量的解构赋值
(一)基本概念与语法
变量的解构赋值是ES6中引入的一种便捷的变量赋值方式,它允许按照一定的模式,从数组或对象中提取值,然后将提取的值赋给对应的变量。其基本语法根据解构的目标不同分为数组解构赋值和对象解构赋值。
- 数组解构赋值:基本语法为
let [变量1, 变量2, ..., 变量n] = 数组;,通过数组的索引顺序来匹配变量和数组中的元素,实现变量赋值。例如:
let [a, b, c] = [1, 2, 3];
console.log(a); // 输出1
console.log(b); // 输出2
console.log(c); // 输出3
- 对象解构赋值:基本语法为
let { 属性名1: 变量1, 属性名2: 变量2, ..., 属性名n: 变量n } = 对象;,如果变量名与对象的属性名相同,可以简化为let { 属性名1, 属性名2, ..., 属性名n } = 对象;,通过属性名来匹配变量和对象中的属性值,实现变量赋值。例如:
// 完整语法
let { name: userName, age: userAge } = { name: 'Tom', age: 20 };
console.log(userName); // 输出'Tom'
console.log(userAge); // 输出20// 简化语法(变量名与属性名相同)
let { name, age } = { name: 'Jerry', age: 18 };
console.log(name); // 输出'Jerry'
console.log(age); // 输出18
(二)模式匹配原理
解构赋值的本质是“模式匹配”,即只要等号两边的模式结构相同,左边的变量就会被自动赋予右边对应位置或对应属性的值。这种赋值机制打破了传统“逐个赋值”的繁琐,让多变量赋值更简洁。
模式匹配的核心逻辑:“结构对等,位置/属性对应”
解构赋值的本质是“模式与值的匹配”,可以类比为“钥匙与锁的对应”:
- 左侧的“模式”(如
[a, b]或{name, age})是“锁”,定义了“要提取哪些位置/属性的值”; - 右侧的“数据”(如
[1, 2]或{name: "Alice", age: 25})是“钥匙”,提供了“可供提取的值”; - 匹配规则:锁的结构必须与钥匙的结构“对等”——数组模式对应数组/可遍历数据,对象模式对应对象,嵌套结构需层层对齐,否则匹配失败(未匹配的变量值为
undefined)。
数组解构的模式匹配:按“索引位置”匹配
数组是“有序数据集合”,因此数组解构的模式匹配严格按“索引位置”对齐——左侧数组模式中第n个位置的变量,自动匹配右侧数组第n个索引的值。
基础匹配:一维数组的位置对应
**原理:**左侧模式为“数组结构”(用[]包裹变量),右侧数据需是“可遍历对象”(数组、Set、字符串等,需具备Iterator接口);变量的“位置索引”与右侧数据的“索引”完全对应,不管变量名是什么。
示例:
// 模式:[a, b, c](3个变量,对应索引0、1、2)
// 数据:[10, 20, 30](3个值,索引0=10、1=20、2=30)
let [a, b, c] = [10, 20, 30];
匹配过程:
- 左侧模式
[a, b, c]解析为“需要提取索引0、1、2的值”; - 右侧数组
[10, 20, 30]按索引顺序提供值; - 按位置赋值:
a = 数组[0](10)、b = 数组[1](20)、c = 数组[2](30); - 最终结果:
a=10、b=20、c=30。
特殊场景:“跳过位置”与“不完全匹配”
模式匹配允许“跳过不需要的位置”(用空逗号占位),或“数据长度大于模式长度”(多余值被忽略),核心仍是“按位置对应”:
// 1. 跳过索引1的值(用逗号占位)
let [x, , y] = [1, 2, 3];
// 匹配:x=索引0(1),跳过索引1,y=索引2(3)→ x=1、y=3// 2. 数据长度大于模式长度(多余值忽略)
let [m, n] = [4, 5, 6, 7];
// 匹配:m=索引0(4),n=索引1(5),索引2、3的值被忽略→ m=4、n=5// 3. 模式长度大于数据长度(未匹配变量为undefined)
let [p, q, r] = [8];
// 匹配:p=索引0(8),q=索引1(无值),r=索引2(无值)→ q=undefined、r=undefined
进阶匹配:嵌套数组的“多层位置对应”
若数组是“嵌套结构”(数组内部包含子数组),则模式也需用“嵌套数组”对齐,每层结构都按索引位置匹配,即“外层对外层,内层对内层”。
**原理:**嵌套数组的模式匹配是“递归过程”:先匹配外层数组的位置,若某位置的值仍是数组,则进一步匹配该位置的内层模式与内层数组。
示例与拆解:
// 模式:[a, [b, [c]]](外层1个变量,内层1个变量,最内层1个变量)
// 数据:[1, [2, [3, 4]]](外层数组,内层数组,最内层数组)
let [a, [b, [c]]] = [1, [2, [3, 4]]];
匹配过程(从外到内):
- 外层匹配:左侧外层模式
[a, [b, [c]]]对应右侧外层数组[1, [2, [3, 4]]]a对应外层索引0的值 →a=1;- 外层索引1的值是子数组
[2, [3, 4]],需与左侧内层模式[b, [c]]进一步匹配;
- 中层匹配:左侧中层模式
[b, [c]]对应子数组[2, [3, 4]]b对应中层索引0的值 →b=2;- 中层索引1的值是子数组
[3, 4],需与左侧最内层模式[c]匹配;
- 内层匹配:左侧最内层模式
[c]对应子数组[3, 4]c对应内层索引0的值 →c=3(子数组索引1的值4被忽略);
- 最终结果:
a=1、b=2、c=3。
对象解构的模式匹配:按“属性名”匹配
对象是“键值对集合”,因此对象解构的模式匹配不依赖位置,只按“属性名”对齐——左侧对象模式中的“属性名”,必须与右侧对象的“属性名”完全一致,才能提取对应的值。
基础匹配:单层对象的“属性名对应”
**原理:**左侧模式为“对象结构”(用{}包裹属性名),右侧数据需是“对象”(普通对象、数组对象等,需有对应属性);变量的“属性名”与右侧对象的“属性名”匹配,变量值为对应属性的value。
关键细节:若左侧属性名与希望的变量名一致,可简化为{属性名};若需自定义变量名,需用{属性名: 变量名}的格式。
示例与拆解:
// 数据:普通对象,属性名name、age、gender
const user = { name: "Bob", age: 30, gender: "male" };// 1. 简化写法:属性名=变量名
let { name, age } = user;
// 匹配:找右侧对象中属性名=name、age的值 → name="Bob"、age=30// 2. 自定义变量名:属性名≠变量名
let { gender: userGender } = user;
// 匹配:找右侧属性名=gender的值,赋值给变量userGender → userGender="male"
匹配过程(以简化写法为例):
- 左侧模式
{name, age}解析为“需要提取属性名=name和age的值”; - 右侧对象
user遍历自身属性,找到name和age; - 按属性名赋值:
name = user.name(“Bob”)、age = user.age(30); - 未匹配的属性(如
gender)被忽略,未找到的属性(如address)对应变量值为undefined。
进阶匹配:嵌套对象的“多层属性名对应”
若对象是“嵌套结构”(属性值仍是对象),则模式也需用“嵌套对象”对齐,每层结构都按属性名匹配,即“外层属性对外层属性,内层属性对内层属性”。
**原理:**嵌套对象的模式匹配也是“递归过程”:先匹配外层对象的属性,若某属性的值仍是对象,则进一步匹配该属性的内层模式与内层对象。
示例与拆解:
// 数据:嵌套对象,user有属性name,address有属性city、street
const user = {name: "Charlie",address: {city: "Beijing",street: "Main Road"}
};// 模式:{name, address: {city}}(外层属性name,内层属性city)
let { name, address: { city } } = user;
匹配过程(从外到内):
- 外层匹配:左侧外层模式
{name, address: {city}}对应右侧对象username对应外层属性名name→name="Charlie";- 外层属性
address的值是子对象{city: "Beijing", street: "Main Road"},需与左侧内层模式{city}匹配;
- 内层匹配:左侧内层模式
{city}对应子对象addresscity对应内层属性名city→city="Beijing"(子对象属性street被忽略);
- 最终结果:
name="Charlie"、city="Beijing"(注意:address不是变量,只是内层模式的“载体”,若需address变量,需单独声明:{address, address: {city}})。
模式匹配的通用规则与特殊场景
“可遍历对象”的数组模式匹配
数组模式的匹配不局限于“数组”,只要右侧数据是“可遍历对象”(具备Iterator接口,如Set、字符串、arguments等),都能按“索引位置”匹配。
本质原因:数组解构的底层是通过“遍历器(Iterator)”依次获取值,而非直接读取数组索引。
示例:
// 1. Set(可遍历,按遍历顺序匹配)
let [x, y] = new Set([1, 2, 3]);
// 匹配:Set遍历顺序为1、2、3 → x=1、y=2// 2. 字符串(可遍历,按字符顺序匹配)
let [a, b, c] = "hello";
// 匹配:字符串遍历顺序为'h'、'e'、'l' → a='h'、b='e'、c='l'// 3. arguments(类数组,可遍历,按索引匹配)
function fn() {let [first, second] = arguments; console.log(first, second); // 10, 20
}
fn(10, 20, 30);
模式匹配与默认值结合
若右侧数据中“无对应的值”(如模式长度大于数据长度、对象无对应属性),可给左侧模式的变量设置“默认值”,匹配失败时自动使用默认值。
默认值生效条件:右侧对应位置/属性的值为undefined(null、0、false等“假值”不会触发默认值)。
示例:
// 1. 数组模式默认值
let [a = 0, b = 1] = [2];
// 匹配:a=2(有值),b=undefined(无值)→ 触发默认值b=1// 2. 对象模式默认值
let { name = "匿名", age = 18 } = { name: "Dave" };
// 匹配:name="Dave"(有值),age=undefined(无属性)→ 触发默认值age=18// 3. 嵌套模式默认值
let [x, [y = 5]] = [3];
// 匹配:x=3,y=undefined(内层无值)→ 触发默认值y=5
“模式不匹配”的失败情况
若左侧模式与右侧数据的“结构类型不兼容”,则匹配失败,所有变量值为undefined(本质是“无法通过遍历器或属性访问提取值”)。
示例:
// 错误1:数组模式对应非可遍历对象(如普通对象)
let [a, b] = { x: 1, y: 2 };
// 匹配失败:普通对象无Iterator接口,无法遍历 → a=undefined、b=undefined// 错误2:对象模式对应非对象(如数字)
let { name } = 123;
// 匹配失败:数字不是对象,无属性 → name=undefined
模式匹配的本质总结
解构赋值的模式匹配,本质是ES6对“数据提取逻辑”的语法糖,其底层实现可概括为:
- 数组模式:通过“遍历器(Iterator)”依次读取右侧可遍历对象的值,按“位置索引”赋值给左侧变量;
- 对象模式:通过“属性访问(
obj[key])”读取右侧对象的属性值,按“属性名”赋值给左侧变量; - 嵌套模式:递归执行上述过程,层层匹配内层结构。
理解这一原理后,无论面对简单还是复杂的解构场景(如函数参数解构、JSON数据解析),都能清晰判断变量的赋值结果,避免因“结构不对齐”导致的错误。