论文学习30:LViT: Language Meets Vision Transformerin Medical Image Segmentation
代码来源
https://github.com/HUANGLIZI/LViT
模块作用
深度学习已广泛应用于医学图像分割等领域。然而,由于数据标注成本过高,获取充足的高质量标注数据成为限制现有医学图像分割模型性能的关键。为了缓解这一限制,本文提出了一种新的文本增强医学图像分割模型 LViT(Language Meets Vision Transformer)。在这个 LViT 模型中,引入了医学文本标注来弥补图像数据的质量缺陷。此外,文本信息可以指导在半监督学习中生成更高质量的伪标签。文中还提出了一种指数伪标签迭代机制 (EPI),以帮助像素级注意力模块 (PLAM) 在半监督 LViT 环境中保留局部图像特征。
模块结构
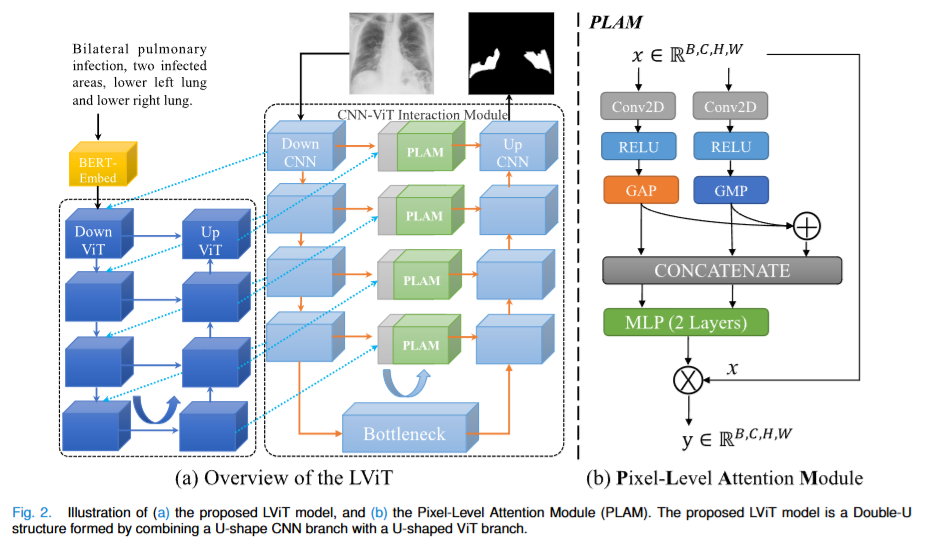
LViT 采用 双 U 形结构,结合 U 形 CNN 分支(提取局部特征)和 U 形 ViT 分支(融合全局及跨模态信息),克服纯 CNN 全局上下文不足和纯 Transformer 计算成本高、忽略局部细节的局限。文本通过简单的嵌入层(BERT-Embed)处理,而非使用完整文本编码器,减少参数量。
模块代码
class LViT(nn.Module):def __init__(self, config, n_channels=3, n_classes=1, img_size=224, vis=False):super().__init__()self.vis = visself.n_channels = n_channelsself.n_classes = n_classesin_channels = config.base_channelself.inc = ConvBatchNorm(n_channels, in_channels)self.downVit = VisionTransformer(config, vis, img_size=224, channel_num=64, patch_size=16, embed_dim=64)self.downVit1 = VisionTransformer(config, vis, img_size=112, channel_num=128, patch_size=8, embed_dim=128)self.downVit2 = VisionTransformer(config, vis, img_size=56, channel_num=256, patch_size=4, embed_dim=256)self.downVit3 = VisionTransformer(config, vis, img_size=28, channel_num=512, patch_size=2, embed_dim=512)self.upVit = VisionTransformer(config, vis, img_size=224, channel_num=64, patch_size=16, embed_dim=64)self.upVit1 = VisionTransformer(config, vis, img_size=112, channel_num=128, patch_size=8, embed_dim=128)self.upVit2 = VisionTransformer(config, vis, img_size=56, channel_num=256, patch_size=4, embed_dim=256)self.upVit3 = VisionTransformer(config, vis, img_size=28, channel_num=512, patch_size=2, embed_dim=512)self.down1 = DownBlock(in_channels, in_channels * 2, nb_Conv=2)self.down2 = DownBlock(in_channels * 2, in_channels * 4, nb_Conv=2)self.down3 = DownBlock(in_channels * 4, in_channels * 8, nb_Conv=2)self.down4 = DownBlock(in_channels * 8, in_channels * 8, nb_Conv=2)self.up4 = UpblockAttention(in_channels * 16, in_channels * 4, nb_Conv=2)self.up3 = UpblockAttention(in_channels * 8, in_channels * 2, nb_Conv=2)self.up2 = UpblockAttention(in_channels * 4, in_channels, nb_Conv=2)self.up1 = UpblockAttention(in_channels * 2, in_channels, nb_Conv=2)self.outc = nn.Conv2d(in_channels, n_classes, kernel_size=(1, 1), stride=(1, 1))self.last_activation = nn.Sigmoid() # if using BCELossself.multi_activation = nn.Softmax()self.reconstruct1 = Reconstruct(in_channels=64, out_channels=64, kernel_size=1, scale_factor=(16, 16))self.reconstruct2 = Reconstruct(in_channels=128, out_channels=128, kernel_size=1, scale_factor=(8, 8))self.reconstruct3 = Reconstruct(in_channels=256, out_channels=256, kernel_size=1, scale_factor=(4, 4))self.reconstruct4 = Reconstruct(in_channels=512, out_channels=512, kernel_size=1, scale_factor=(2, 2))self.pix_module1 = PixLevelModule(64)self.pix_module2 = PixLevelModule(128)self.pix_module3 = PixLevelModule(256)self.pix_module4 = PixLevelModule(512)self.text_module4 = nn.Conv1d(in_channels=768, out_channels=512, kernel_size=3, padding=1)self.text_module3 = nn.Conv1d(in_channels=512, out_channels=256, kernel_size=3, padding=1)self.text_module2 = nn.Conv1d(in_channels=256, out_channels=128, kernel_size=3, padding=1)self.text_module1 = nn.Conv1d(in_channels=128, out_channels=64, kernel_size=3, padding=1)def forward(self, x, text):x = x.float() # x [4,3,224,224]x1 = self.inc(x) # x1 [4, 64, 224, 224]text4 = self.text_module4(text.transpose(1, 2)).transpose(1, 2) text3 = self.text_module3(text4.transpose(1, 2)).transpose(1, 2)text2 = self.text_module2(text3.transpose(1, 2)).transpose(1, 2)text1 = self.text_module1(text2.transpose(1, 2)).transpose(1, 2)y1 = self.downVit(x1, x1, text1)x2 = self.down1(x1)y2 = self.downVit1(x2, y1, text2)x3 = self.down2(x2)y3 = self.downVit2(x3, y2, text3)x4 = self.down3(x3)y4 = self.downVit3(x4, y3, text4)x5 = self.down4(x4)y4 = self.upVit3(y4, y4, text4, True)y3 = self.upVit2(y3, y4, text3, True)y2 = self.upVit1(y2, y3, text2, True)y1 = self.upVit(y1, y2, text1, True)x1 = self.reconstruct1(y1) + x1x2 = self.reconstruct2(y2) + x2x3 = self.reconstruct3(y3) + x3x4 = self.reconstruct4(y4) + x4x = self.up4(x5, x4)x = self.up3(x, x3)x = self.up2(x, x2)x = self.up1(x, x1)if self.n_classes == 1:logits = self.last_activation(self.outc(x))else:logits = self.outc(x) # if not using BCEWithLogitsLoss or class>1return logits总结
本文提出了一种新的视觉语言医学图像分割模型LViT,该模型利用医学文本标注来弥补图像数据的质量缺陷,并在半监督学习中指导生成更高质量的伪标签。为了评估LViT的性能,研究人员构建了多模态医学分割数据集(图像+文本),实验结果表明,这个模型在全监督和半监督环境下均具有卓越的分割性能。此外,研究人员还提供了一个关于早期食管癌诊疗的示例应用,以展示文本标注如何在实际场景中发挥作用。目前,这个模型是一个二维分割模型。在未来的工作中,研究人员将把模型扩展到三维,并在更多医学数据上进行实验,以进一步验证其通用性。此外,在当前版本的LViT 模型中,需要在推理阶段提供文本输入。因此,未来的工作可以是根据提供的图像信息自动生成文本注释。由于文本注释是结构化的,可以在 LViT 的未来版本中将文本注释生成问题转化为分类问题。这能够支持有或无文本输入的推理,从而增强模型的可用性。