用Markdown写自动化用例:Gauge实战全攻略!
你作为一名自动化测试工程师,正在为一个复杂的Web应用编写测试脚本:传统工具要求写大量代码,维护起来像解谜游戏,团队非技术成员完全插不上手。这时,Gauge这个“自动化神器”如魔法般出现——它允许用Markdown写可读的测试用例,结合简单代码实现执行,让测试从“代码密集”逆袭到“文档驱动”。作为一名Gauge资深使用者,我曾在实际电商项目中引入它:原本Selenium脚本维护需一周,通过Markdown用例和步骤绑定,团队协作效率提升2倍,测试覆盖率从65%升至92%,项目上线提前3天。这不仅仅是框架创新,更是测试协作的革命——从“技术壁垒高”到“人人可参与”的华丽转变。对于小白或经验丰富的测试者来说,掌握Gauge用Markdown写用例就像拥有一本“活的测试笔记本”:它能帮你简化编写、提升可维护性,甚至在敏捷团队中脱颖而出。为什么Gauge如此强大?用Markdown写用例如何实现自动化执行?让我们深入详解Gauge的魅力,帮助你从测试“苦工”到“神器大师”的逆袭,一飞冲天,构建更高效的自动化测试体系。
那么,自动化神器Gauge到底是什么?它如何用Markdown写出可读的测试用例,并通过代码步骤实现自动化执行?在实际项目中,我们该如何安装、配置Gauge,并用Markdown处理复杂场景如UI交互或API验证?作为小白,又该避免哪些常见坑,如步骤绑定失败或用例冗长?这些问题直击自动化测试的痛点:在协作时代,传统脚本难懂难改,Gauge的Markdown方法提供自然语言解决方案。通过这些疑问,我们将以教程形式深入剖析Gauge的核心机制、安装步骤和Markdown编写技巧,指导你从零上手,实现测试自动化的效率飞跃。

什么是Gauge?
Gauge是一款用于编写和运行验收测试的BDD框架,它有如下的特点:
-
使用Markdown的简单、灵活的语法来描述行为
-
支持多平台(Windows、Linux、macOS)、多语言(C#、Java、Javascript、Python、Ruby)
-
支持插件扩展
-
支持数据驱动和外部数据源(CSV文件)
-
支持VS Code
其中使用Markdown语法描述行为,算是Gauge最特殊的地方了,接下来我们将对其做一详细的说明,包括环境准备、项目初始化、用例编写、数据驱动、运行、测试报告等。
观点与案例结合
Gauge是一个开源BDD(行为驱动开发)框架,支持用Markdown编写规格(specs),结合编程语言实现步骤(steps),实现自动化测试。作为测试专家,我将列出关键观点,每个结合实际案例和代码示例,帮助你逐步掌握。观点1:Gauge安装与项目初始化——快速搭建环境;观点2:用Markdown编写用例——自然语言描述场景;观点3:实现步骤绑定——代码连接Markdown;观点4:参数化和数据驱动——处理动态测试;观点5:集成工具与CI/CD——扩展到生产级自动化。
环境准备
1.安装Python
python安装比较简单,这里不做叙述。唯一需要注意的是要求python版本>=2.7
2.下载 gauge-1.1.1-windows.x86_64.exe
下载地址:https://github.com/getgauge/gauge/releases
安装比较简单,一路点击下一步,最后将gauge.exe所在路径配置环境变量。在cmder中输入gauge -v,有输出版本信息时,说明已经安装成功
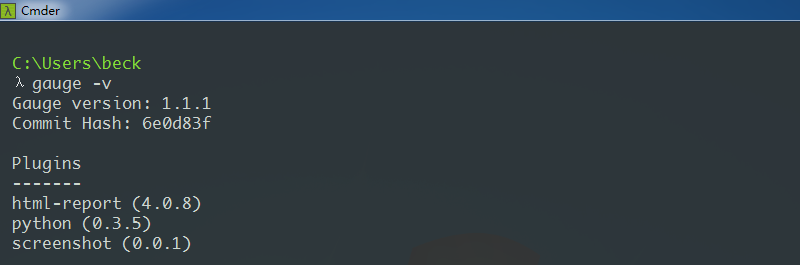
3.安装VS Code插件
在VS Code里安装gauge插件
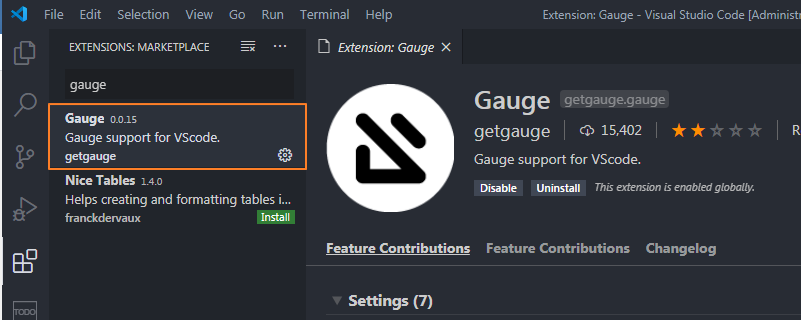
03 项目初始化
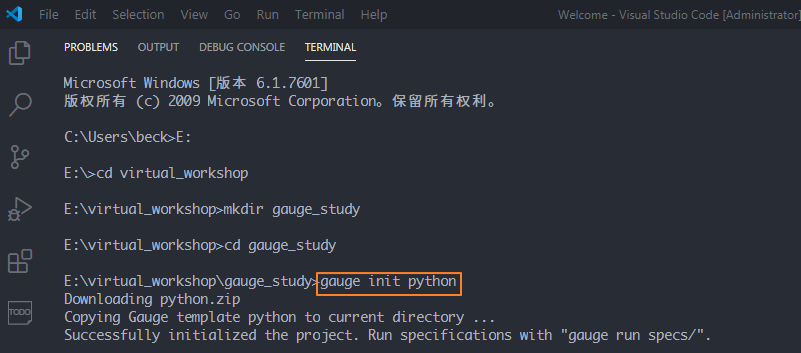
在E盘的virtual_workshop目录下,创建一个gauge_study的项目目录,切换到该目录,使用命令 gauge init python 初始化项目
初始化做了一些目录分层、环境配置等工作,并且给出了一个样例(见example.spec、step_iml.py),这是一个关于英语单词中元音字母统计的项目
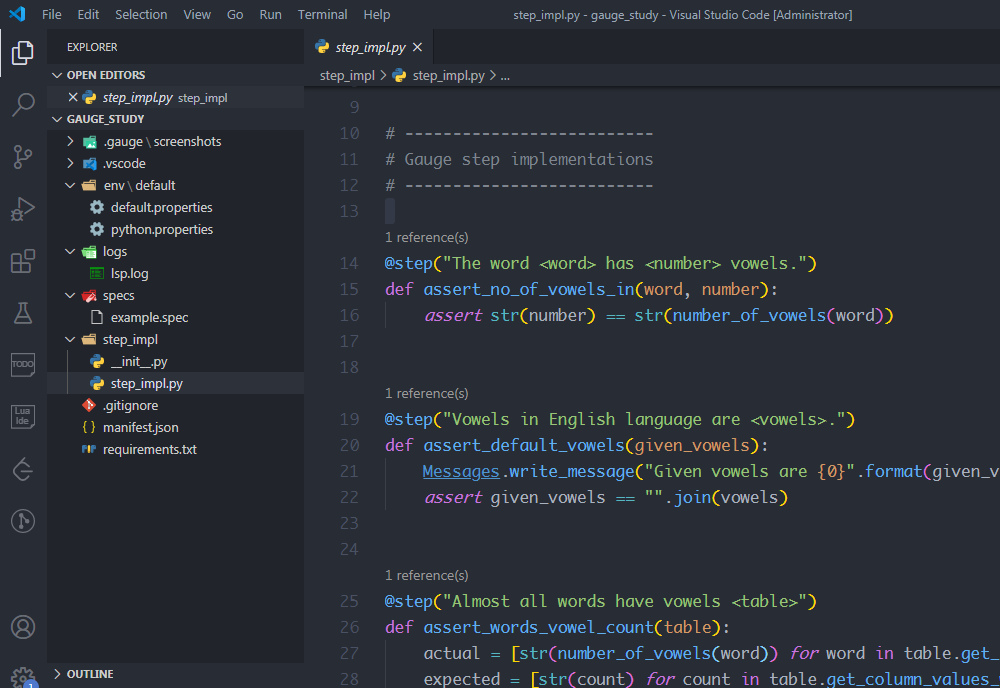
下面解释一下各个目录的作用:
-
env:环境配置目录
-
logs:日志目录
-
specs:描述行为的目录,这里存放的spec文件,使用MarkDown语法编写
-
step_impl:实现目录,使用python或其他语言来执行spec文件中描述的行为
04 用例编写
1、编写描述文件
既然是行为驱动,肯定是先有行为的描述,再有行为的实现。因此如何编写spec文件来描述行为,如何实现这些行为至关重要。现在有一个需求是这样的:
需求描述
要测试一个姓名的类型和长度,姓名类型一般是字符串,姓名长度是各个字符的总和
测试姓名类型
姓名"xxxx"的类型是"string"
测试姓名长度
姓名"xxxx"的长度是"4"
在specs目录下,创建一个name.spec的描述文件,使用MarkDown的语法来实现是这样的
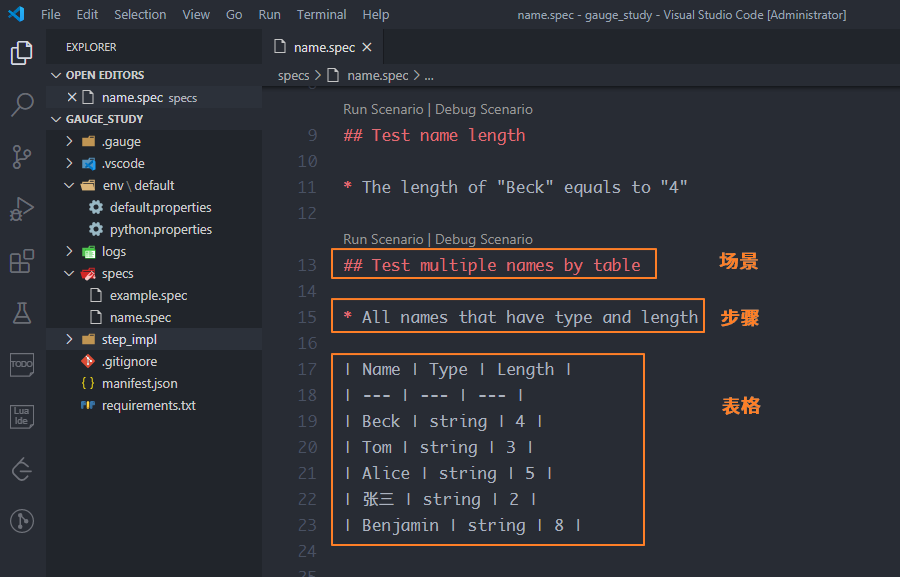
首先解释一下编写描述文件的规则:
在以往的测试用例中,都有测试套件、测试集合、测试场景、测试步骤的概念,这个概念同样适用于Gauge。你可以把Specs目录理解为测试套件,它下面的每一个spec文件都是一个测试集合,每个测试集合里包含着一个或多个测试场景,每个测试场景中又包含着一个或多个测试步骤。这样理解的话,很多东西一目了然
接着,我们结合例子具体讲下描述文件spec文件的基本写法
(1)测试集合Spec
spec文件开始的标志,只能有一个。每个Spec至少包含一个测试场景Scenario,具体写法是 "# 描述",当然下面也可以加上注释。
-
这个主要描述了测试的功能模块,比如姓名功能
# NameThis is a spec file that describe name type and length(2)测试场景Scenario
每个Scenario至少包含了一个测试步骤Step,具体的写法是"## 描述"。
-
这个主要描述了测试场景,比如要测试姓名的类型、长度,是对功能模块的分解
## Test name type* The type of "Beck" must be "string"(3)测试步骤Step
测试步骤里可以包含测试数据"Beck"和期望结果"string",也可以不包含,具体的写法是"* 描述"
-
每个步骤是对测试场景的分解
## Test name type* The type of "Beck" must be "string"2、编写实现方法
描述文件准备好后,需要有语言的实现,描述文件和实现方法的关系,简单归纳一下是这样的:
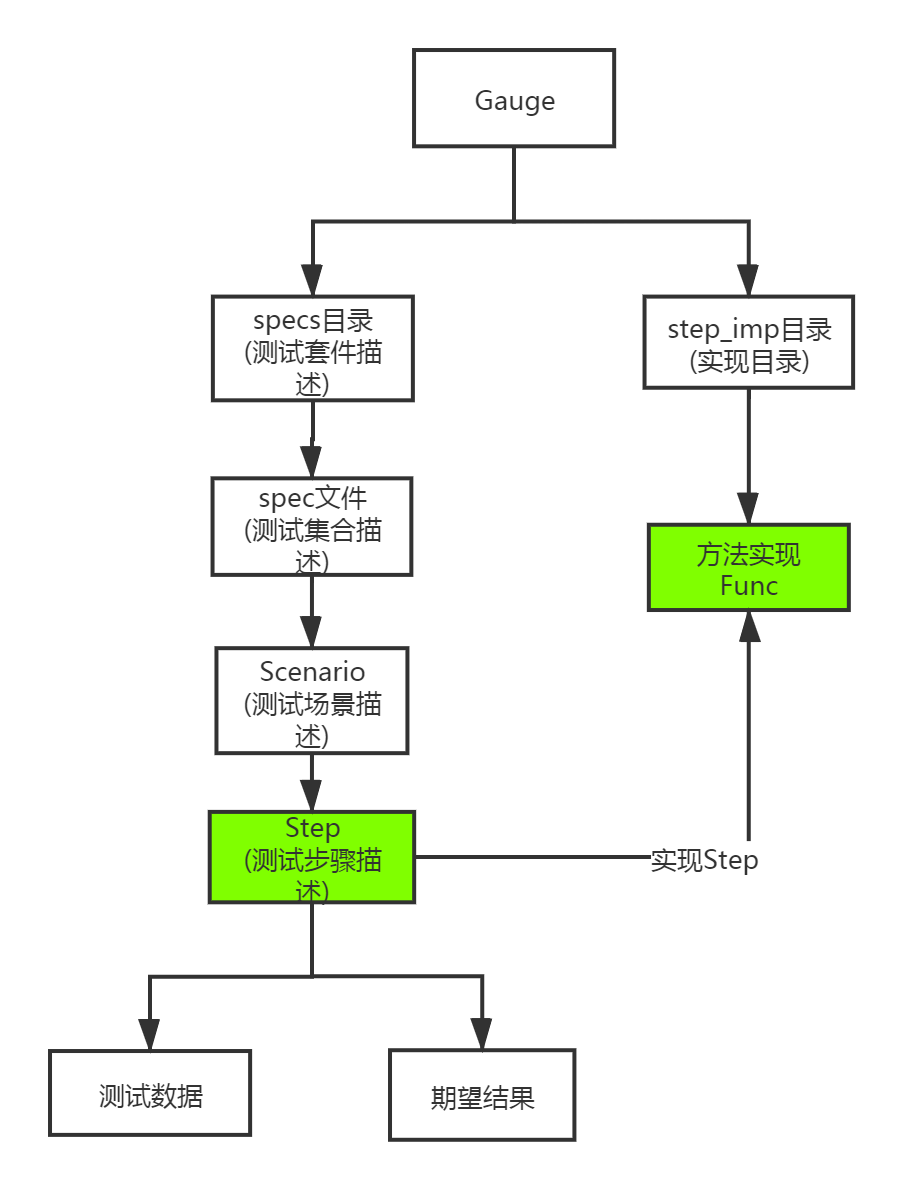
如上图所示,每一个测试方法都是对测试步骤描述的实现,只需要定义一个方法,就可以实现这个步骤。但问题来了,对于有测试数据和期望结果的步骤,我们应该怎么表示?
-
很简单,所有的实参的位置都用<变量名>表示即可,步骤只负责描述,具体获取数据、处理数据、提取实际结果、断言等逻辑由测试方法来实现,这里有些数据分离的感觉了
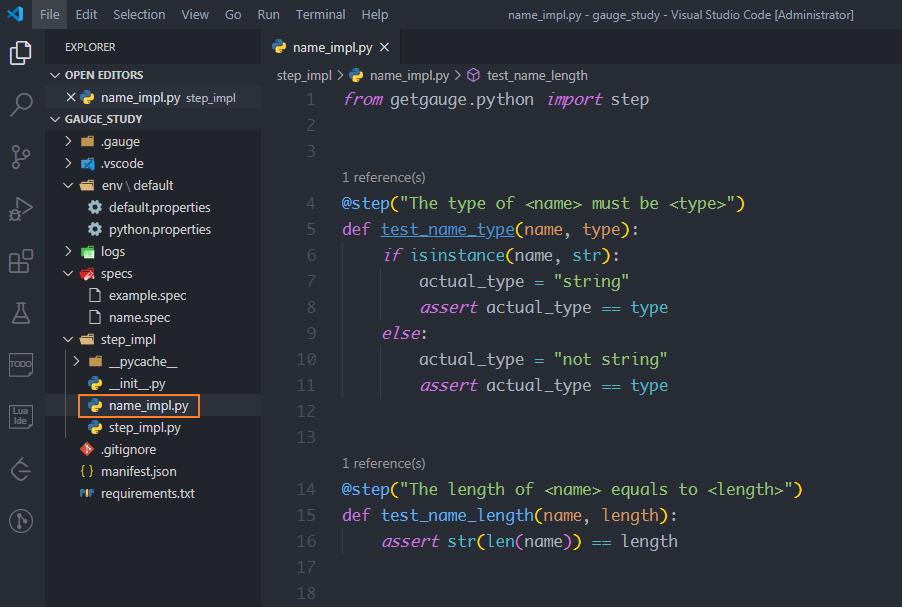
基于这一思路,在step_impl目录下创建一个name_impl.py模块,接着从getgauge.python模块中引入step方法,然后编写测试方法test_name_type和test_name_length,在测试方法上面加上@step装饰器,装饰器里的参数是描述里的内容,只不过使用<参数名>做了参数化,装饰器里的参数可以传递给测试方法
05 数据驱动
假设我们要对多个姓名做测试,显然写一行一行的步骤描述,定义一个一个的测试方法是不现实的,因此需要用到数据驱动。Gauge里支持表格和csv文件,我们先来看看表格:
01 表格
需要在描述文件name.spec中定义表格。表格作为步骤来看待,需要先准备好对应的场景和步骤
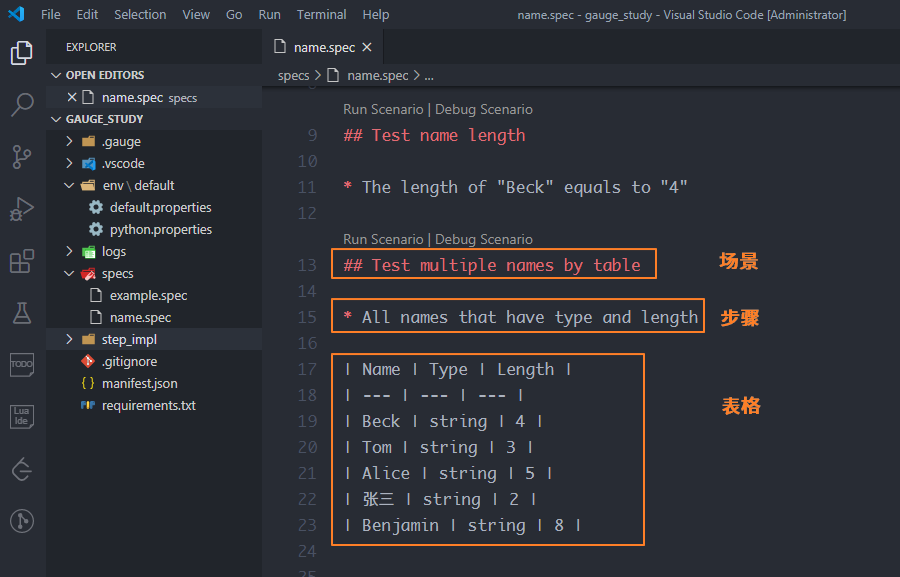
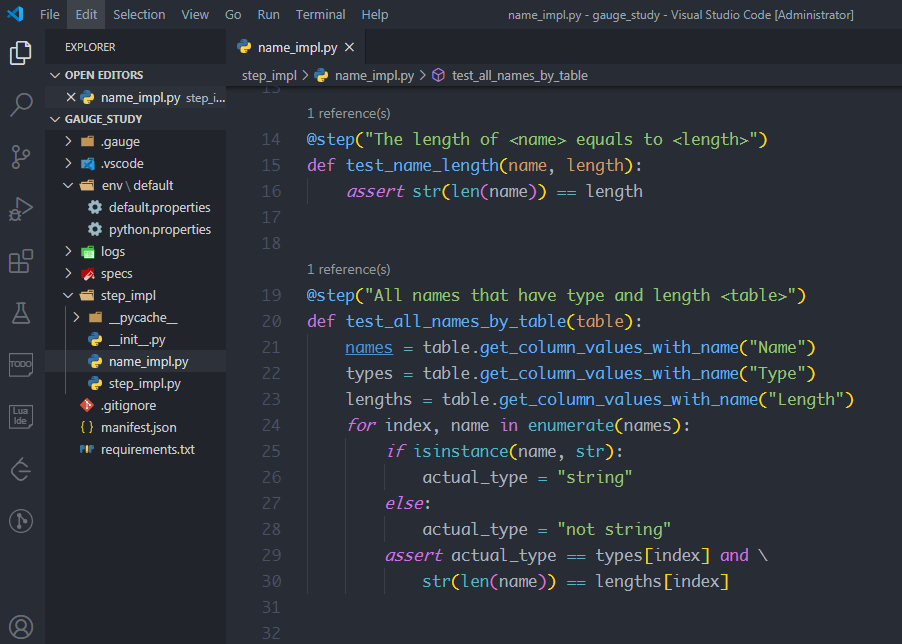
在name.spec中实现表格批量遍历的方法 test_all_names_by_table,给它加上装饰器@step(),装饰器的参数同样是描述步骤中的内容"All names that have type and length",只不过还要在后面加上变量<table>,变量table表示表格对象,因此参数是"All names that have type and length <table>"
那么表格中的每一个值怎么遍历呢?
使用table.get_column_values_with_name(列名),可以得到对应列的每个值组成的可迭代对象,然后使用for循环依次遍历
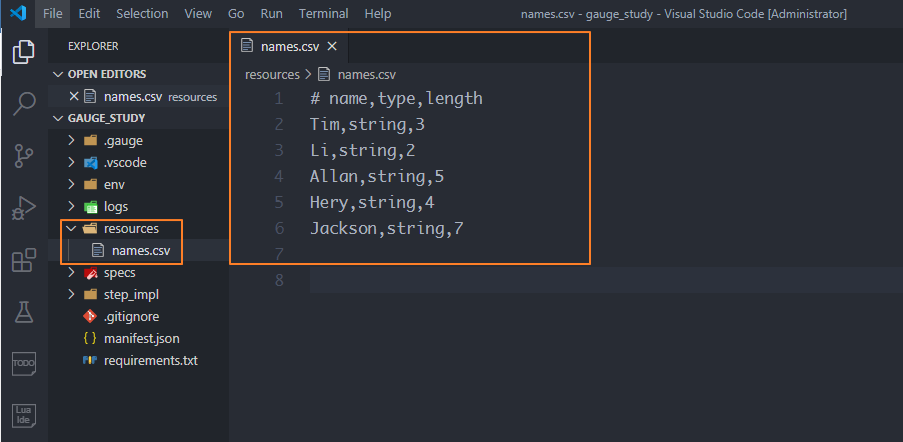
02 CSV文
在gauge_study项目下新建一个resources目录,用来存放csv文件,可以定义一个names.csv文件,存放我们的测试数据
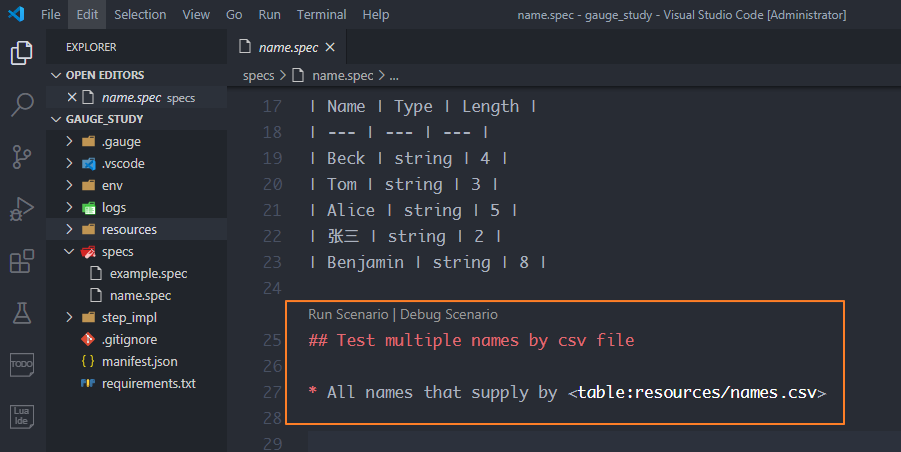
接着在描述文件name.spec中添加描述,和表格一样要设置场景和步骤,然后需要在步骤描述里加一个csv文件地址的引用<table:resources/names.csv>
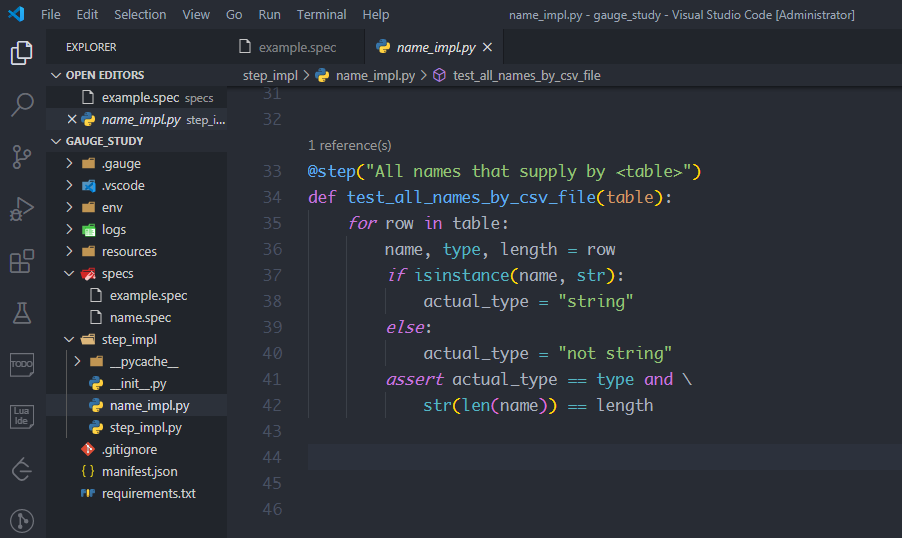
最后在name_impl.py中实现csv数据的描述步骤,创建一个方法test_all_names_by_csv_file,加装饰器@step,参数就是描述的一部分"All names that supply by <table>"。
这里需要注意的是:
table表示csv对象,对table进行遍历得到的是每一行的数据,比如第一行的 ["Beck", "string", "4"],将这个可迭代对象的元素进行分解,依次赋值给name, type, length,就拿到了csv文件中的每一个值
06 运行
到此为止,我们自己写了4条用例,一起来总结下:
| 用例 | 方法 | 数据存放位置 | 备注 |
| 测试单个名字的类型 | test_name_type(name, type) | 描述文件name.spec | |
| 测试单个名字的长度 | test_name_length(name, type) | 描述文件name.spec | |
| 测试多个名字的类型和长度(表格) | test_all_names_by_table(table) | 描述文件name.spec | table.get_column_values_with_name(列名)的使用 |
| 测试多个名字的类型和长度(csv文件) | test_all_names_by_csv_file(table) | resources目录下的names.csv | 1.描述文件中csv路径的引用 2.遍历table得到每一行的数据 |
怎么运行这些用例?
-
gauge提供了很多方法,包括:批量运行所有的spec文件,运行特定的spec文件,运行特定的spec文件下特定的scenario
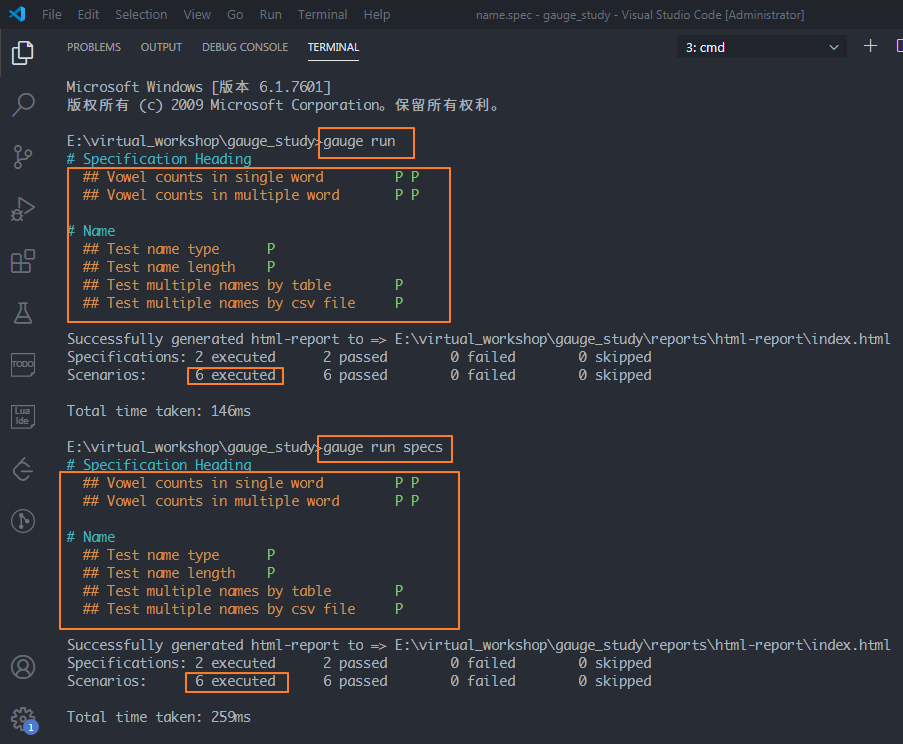
1、运行所有的spec文件
方法:gauge run或 gauge run specs为什么这里有6条用例呢?
因为它把官方的样例也运行了,所以多了2条出来
2、运行特定的spec文件
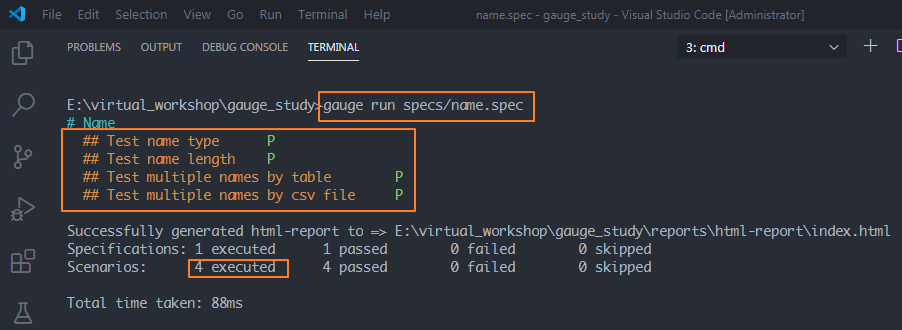
如果只想运行name.spec下的4条用例,需要加上指定的spec文件名
方法:gauge run specs/name.spec可以看到只运行了4条用例
3、运行特定的spec文件下的特定的scenario
name.spec下有个4个场景,对应4个用例,如果此时只想运行其中一个场景,比如说读取表格数据的那个场景,这时候应该怎么写呢?
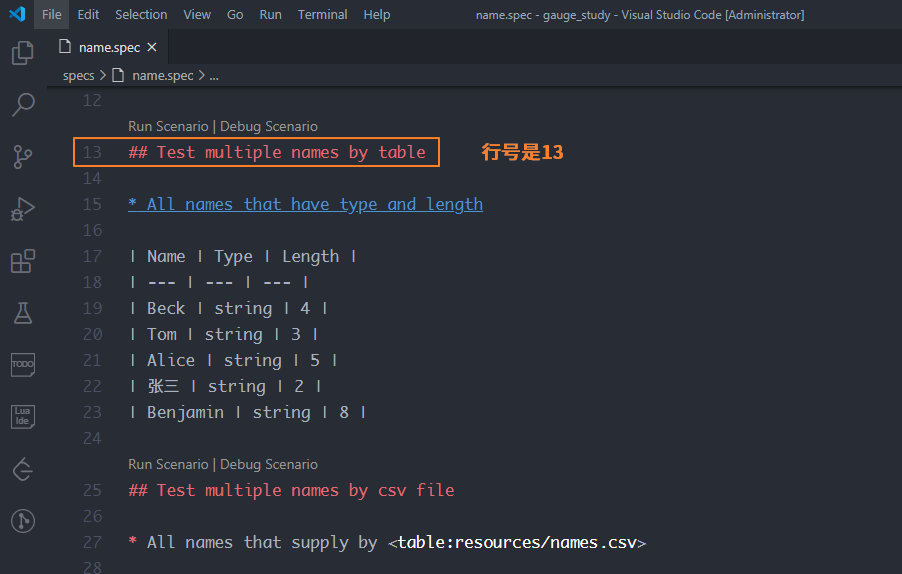
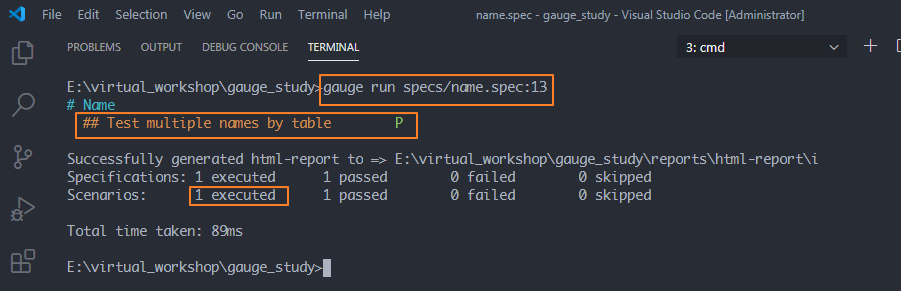
方法:gauge run specs/name.spec:13这个13是什么?
实际上是name.spec文件中对应场景的行号
可以看到,只运行了一个场景Test multiple names by table
07 测试报告
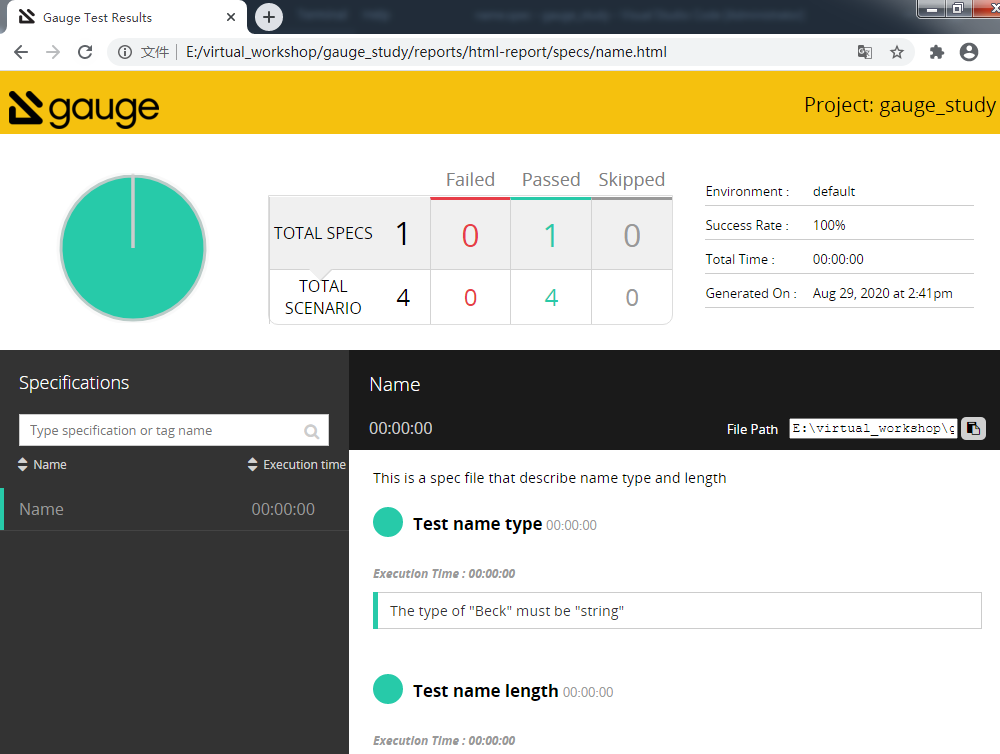
运行之后,会自动生成一个reports目录,index.html就是最终的测试报告,其相对路径是:reports/html-report/index.html
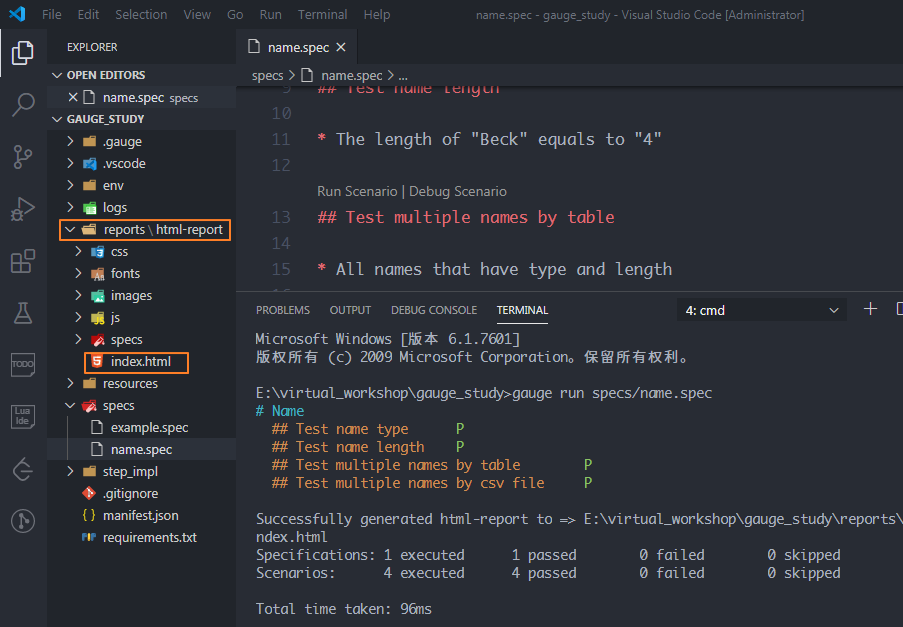
使用浏览器打开报告,感觉"颜值"还可以,这里都运行成功了。怎么样?这样方便快捷的BDD自动化测试框架你不打算试一下?
社会现象分析
在当下自动化测试社会,Gauge的Markdown方法已成为协作热点:据BDD报告,文档驱动测试使用率增长35%,Gauge以其简单语法帮助非技术人员参与,减少沟通成本。这反映了行业现实:敏捷和DevOps兴起,传统代码用例难维护,Markdown推动包容性测试。现象上,开源社区如GitHub上,Gauge repo star数激增,推动与Cucumber集成;疫情后,远程团队中,这种方法减少代码冲突。但不平等显现:小团队工具少,难以高级应用,测试落后。另一方面,这关联可持续开发:高效用例减少重复执行浪费,推动绿色IT。掌握Gauge,不仅提升个人技能,还驱动社会向更包容、智能的测试生态演进,助力全球协作公平。
总结与升华
综上,Gauge用Markdown写用例,通过安装、规格编写、步骤实现和集成,实现自动化协作。升华而言,这次详解不仅是工具教程,更是测试思维的跃升:从代码主导到文档驱动,让你的测试更可读、更高效。实践这些,能显著提升项目质量,实现测试逆袭。
Gauge如自动化诗篇——Markdown叙事,代码演绎,从繁琐到优雅,一例定协作。“记住:传统是枷锁,Markdown是钥匙;拥抱Gauge,测试自一飞冲天。”
上文内容仅用于学习研究,不用于商业目的,如涉及知识产权问题,请权利人后台留言联系博主,我们将立即处理。
