〔从零搭建〕数据中枢平台部署指南
🔥🔥 AllData大数据产品是可定义数据中台,以数据平台为底座,以数据中台为桥梁,以机器学习平台为中层框架,以大模型应用为上游产品,提供全链路数字化解决方案。
✨杭州奥零数据科技官网:http://www.aolingdata.com
✨Github项目:https://github.com/alldatacenter/alldata
✨Gitee项目:https://gitee.com/alldatacenter/alldata
✨AllData官方手册:https://www.yuque.com/aolingdata/product
✨AllData正式环境:http://43.138.156.44:5173/ui_moat
摘要:数据中枢平台基于开源项目DataCap建设,是一款用于数据转换、集成和可视化的集成软件。文章内容主要为以下四部分:
一、在线演示环境
二、功能简介
三、源码编译部署安装
四、访问数据中枢平台页面
💡Tips:关注「公众号」大数据商业驱动引擎

🔹AllData数据中台线上正式环境:http://43.138.156.44:5173/ui_moat/
请联系市场总监获取账号密码


一、数据中枢平台基于开源项目DataCap建设
AllData数据中台商业版中的数据中枢平台(DataCap)功能,是一款用于数据转换、集成和可视化的集成软件。
支持多种数据源、文件类型、大数据相关数据库、关系型数据库、NoSQL 数据库等。通过该软件可以实现对多数据源的管理,以及对数据源下的数据进行各种操作转换。
1、将所有数据源的查询语言统一为 SQL,无论是关系型数据库、NoSQL、文件系统还是其他中间件,都可以使用 SQL 进行操作。
2、持超过 40+ 数据源,包括 ClickHouse、MySQL、PostgreSQL、MongoDB、Redis、Elasticsearch、Kafka 等主流数据库和中间件。
3、通过 JDBC、Native、HTTP 等多种协议连接到不同的数据源,提供了更大的灵活性和兼容性。
4、插件化系统设计,支持在线安装、卸载、更新和热部署,方便系统的扩展和维护。
5、支持数据转换和集成,可以将不同数据源的数据转换为统一的格式,并进行数据集成,实现数据的统一化管理和分析,方便用户进行数据迁移和整合。
🔹DataCap开源项目:https://github.com/devlive-community/datacap
二、离线开发平台功能特点:
- 数据转换
- 数据查询
- 数据集成
- 数据可视化
- 插件扩展系统

💡部署步骤:

一、环境准备 --构建高可用基础设施
1.1 操作系统要求:
- 推荐系统: CentOS 7.9/Ubuntu 20.04 LTS,需配置静态IP及SSH免密登录。
- Java环境: JDK11(必须配置JAVA_HOME,例如exportJAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64)。
- 数据库: MySQL 8.0(需初始化数据库并执行install/datacap_mysql.sql脚本,包含表结构及初始数据)。
- 构建工具: Maven 3.8.6(配置阿里云镜像加速依赖下载)、Git 2.30+。
- 前端依赖: Node.js 16.x(用于前端模块编译)。
1.2 服务资源规划:
-
测试环境: 4核8G内存 + 100GB磁盘空间。
-
生产环境: 16核32G内存 + 500GB NVMe SSD(支持40+数据源并发连接)。
-
网络要求: 开放端口8080(Web服务)、9090(API服务)、3306(MySQL)、6379(Redis,可选)。
二、源码编译部署获取安装包dat

三、分支选择建议
3.1 开发环境:
使用dev分支获取最新功能。
3.2 生产环境:
选择release/v2.x.x标签版本(如v2.5.0),避免未经验证的代码。
四、编译构建 --后端服务构建
4.1 后端服务构建:
进入项目目录后,使用Maven安装项目依赖:

4.2 关键输出:
-
datacap-server/target/datacap-server-2.5.0.jar(主服务JAR包)。
-
datacap-plugins/target/plugins.zip(插件市场依赖包)。
4.3 前端模块编译:

4.4 插件系统热部署:
解压plugins.zip至/opt/datacap/plugins目录,支持动态加载JDBC驱动、转换器等扩展。
五、部署与运行配置 --生成级服务托管
5.1 Syste服务托管(推荐)
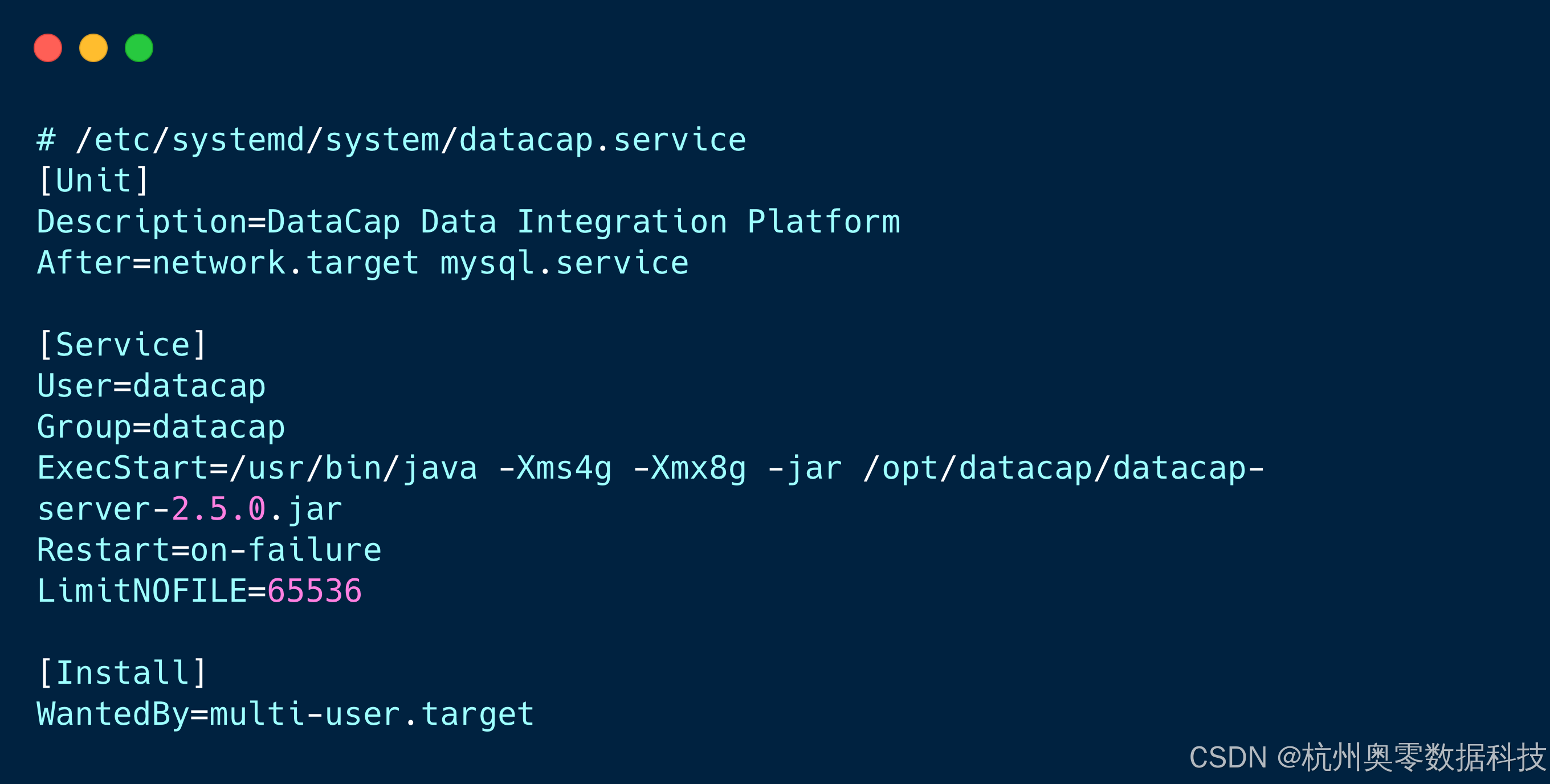
💡启动命令:

5.2 核心配置文件
数据库连接:config/application-prod.yml

插件路径:config/plugin.yml

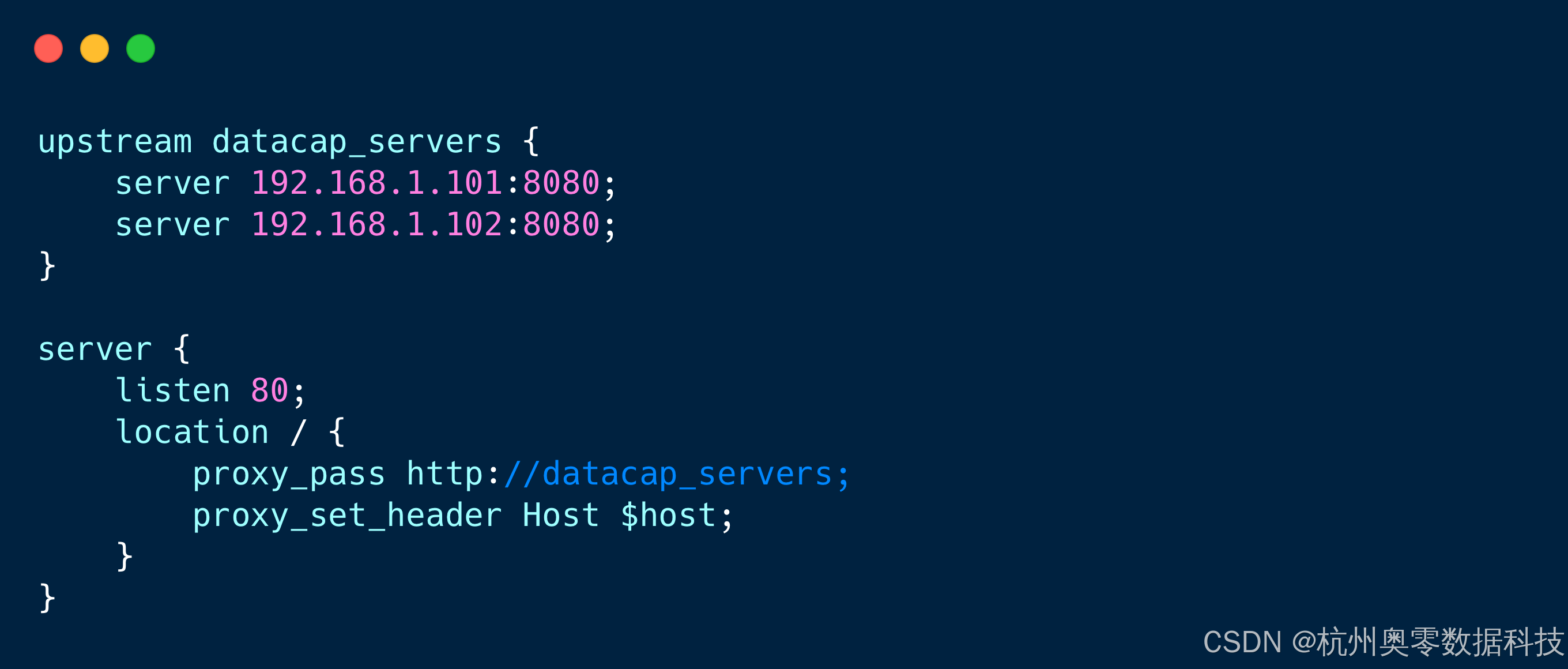
5.3 高可用部署
集群模式:通过Nginx负载均衡(配置示例):
六、可选配置 --性能优化与功能扩展
6.1 数据源插件扩展
-
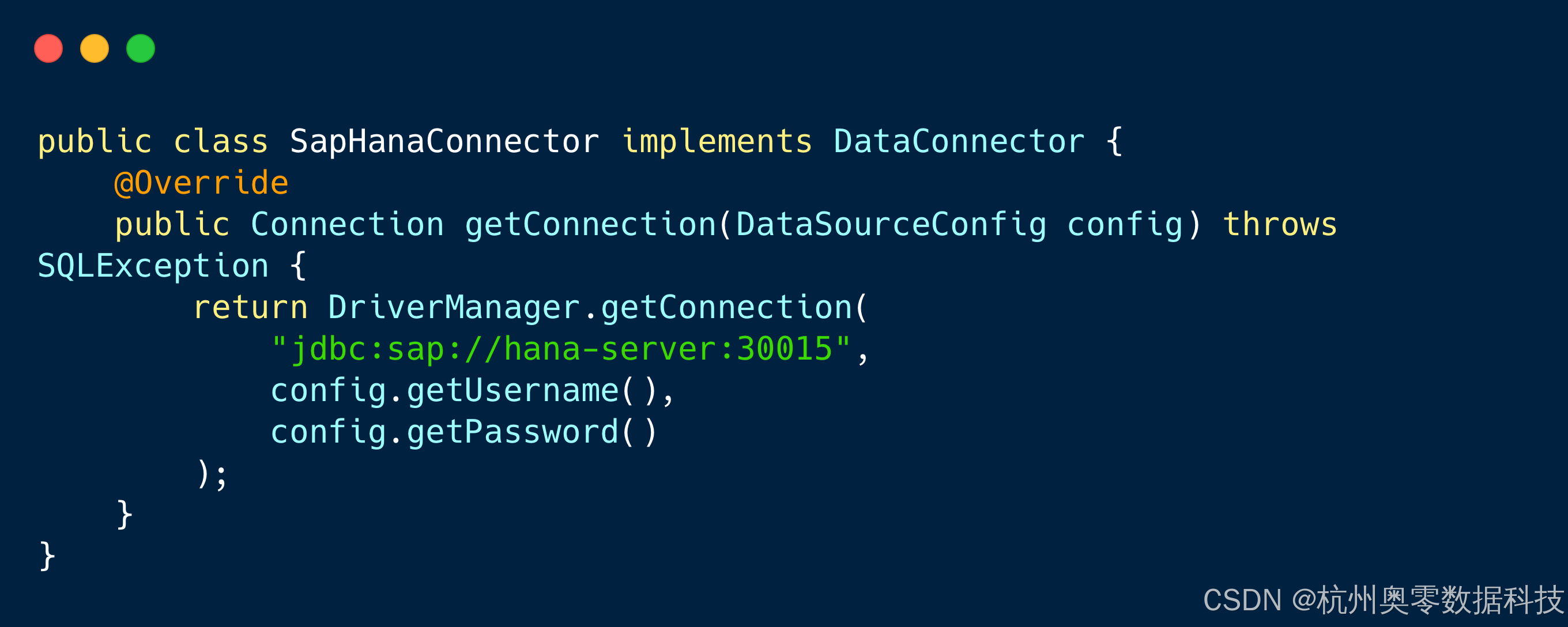
自定义Connector:实现com.datacap.plugin.connector.DataConnector接口,打包为JAR后放入插件目录。
-
示例:添加SAP HANA支持:
6.2 性能调优参数
JVM优化:

线程池配置:application-prod.yml

6.3 安全加固措施
API鉴权:启用JWT令牌验证(修改security.yml):

审计日志:配置logback-spring.xml记录敏感操作:

七、验证与监控
7.1 健康检查接口

7.2 关键指标监控
🔹Prometheus配置:启用/actuator/prometheus端点,监控指标包括:
- datacap_task_queue_size(任务积压数)
- datacap_connector_latency_seconds(数据源响应时间)
7.3 日志分析
🔹使用ELK栈集中管理日志,关键字段包括:
- taskId(任务唯一标识)
- dataSourceType(数据源类型)
- errorStack(异常堆栈)
八、典型问题处理
8.1 插件加载失败
🔹现象:日志出现PluginLoadException: Class not found。
🔹解决:检查插件JAR是否包含META-INF/services/com.datacap.plugin.spi.ServiceLoader文件。
8.2 MySQL连接池耗尽
🔹现象:Too many connections错误
🔹解决:调整max-active参数(默认20)并优化SQL查询:
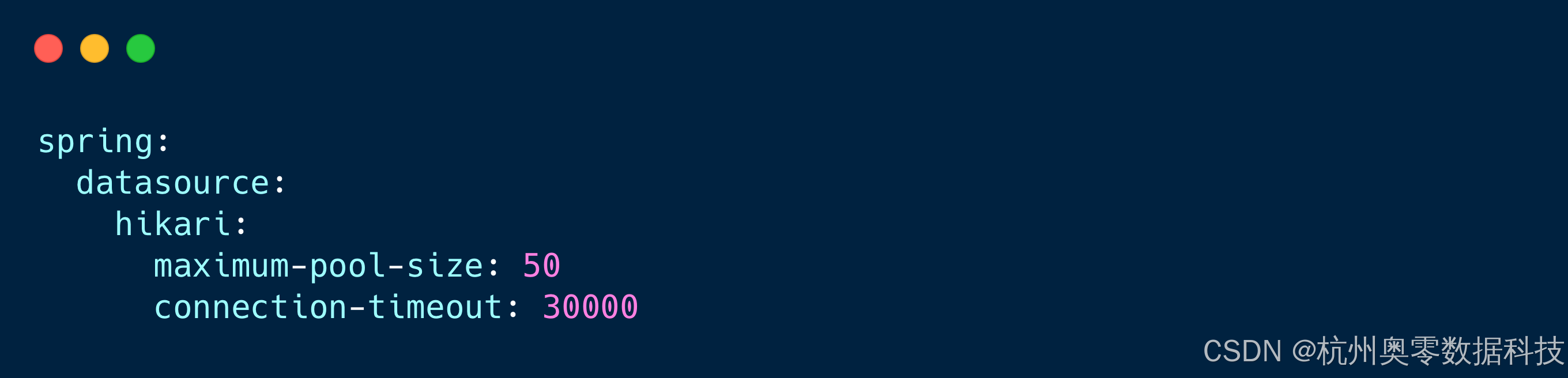
8.3 跨域问题(前端集成)
🔹现象:浏览器控制台报CORS policy错误。
🔹解决:在application-prod.yml中配置:


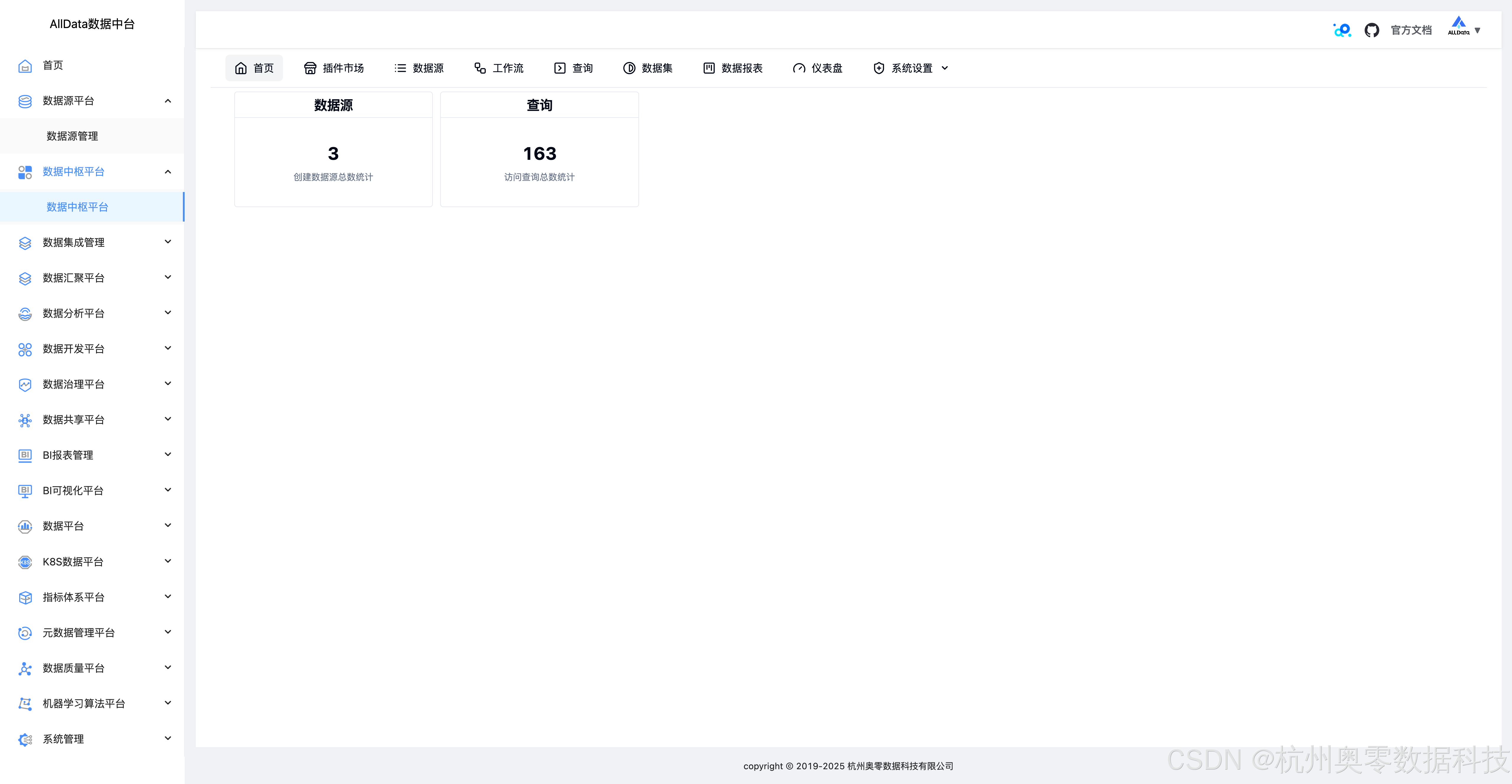
1、数据中枢平台首页
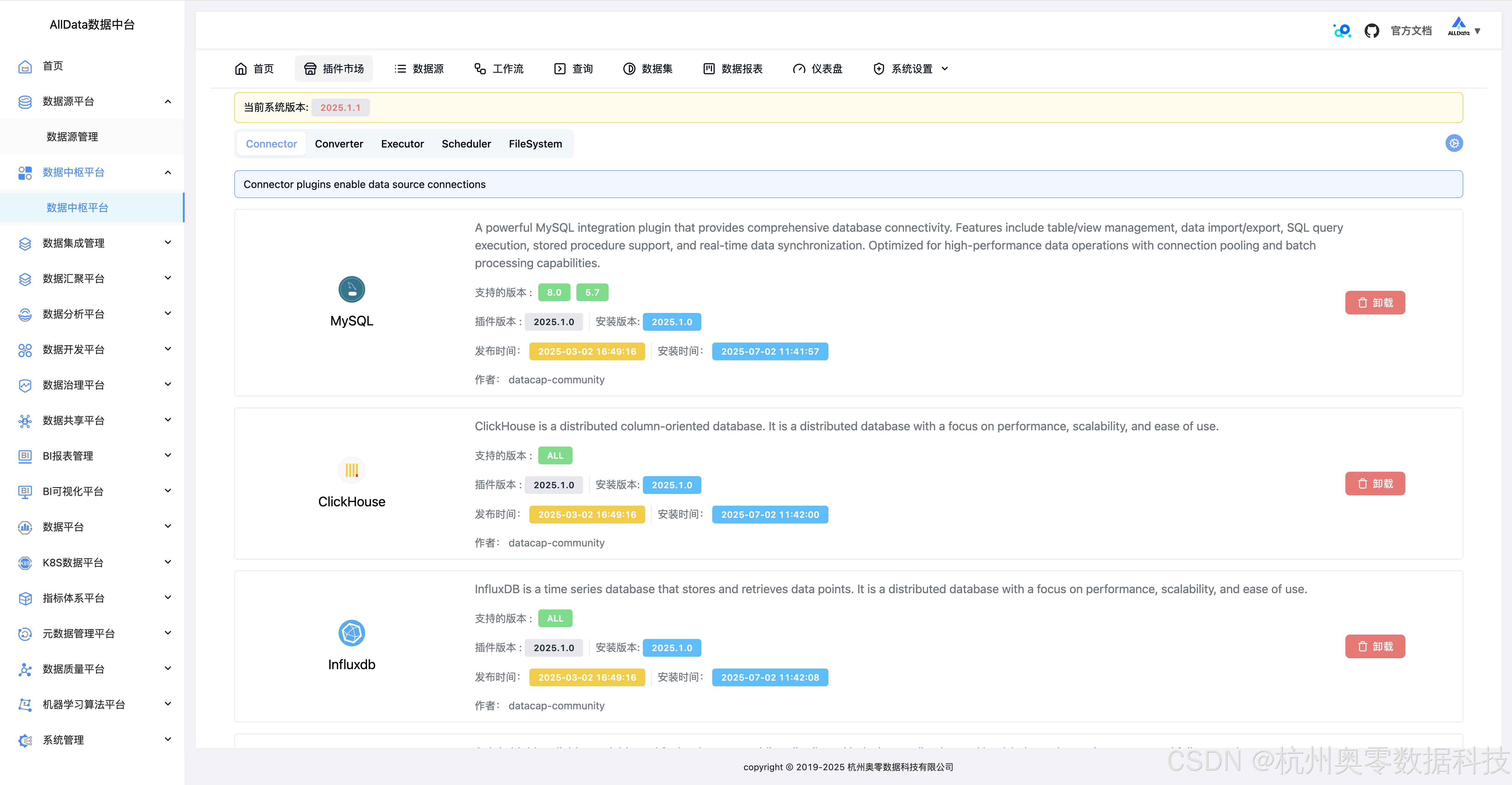
2、插件市场-Connecttor
插件市场提供丰富插件,支持功能扩展与定制,满足企业多样化数据需求。
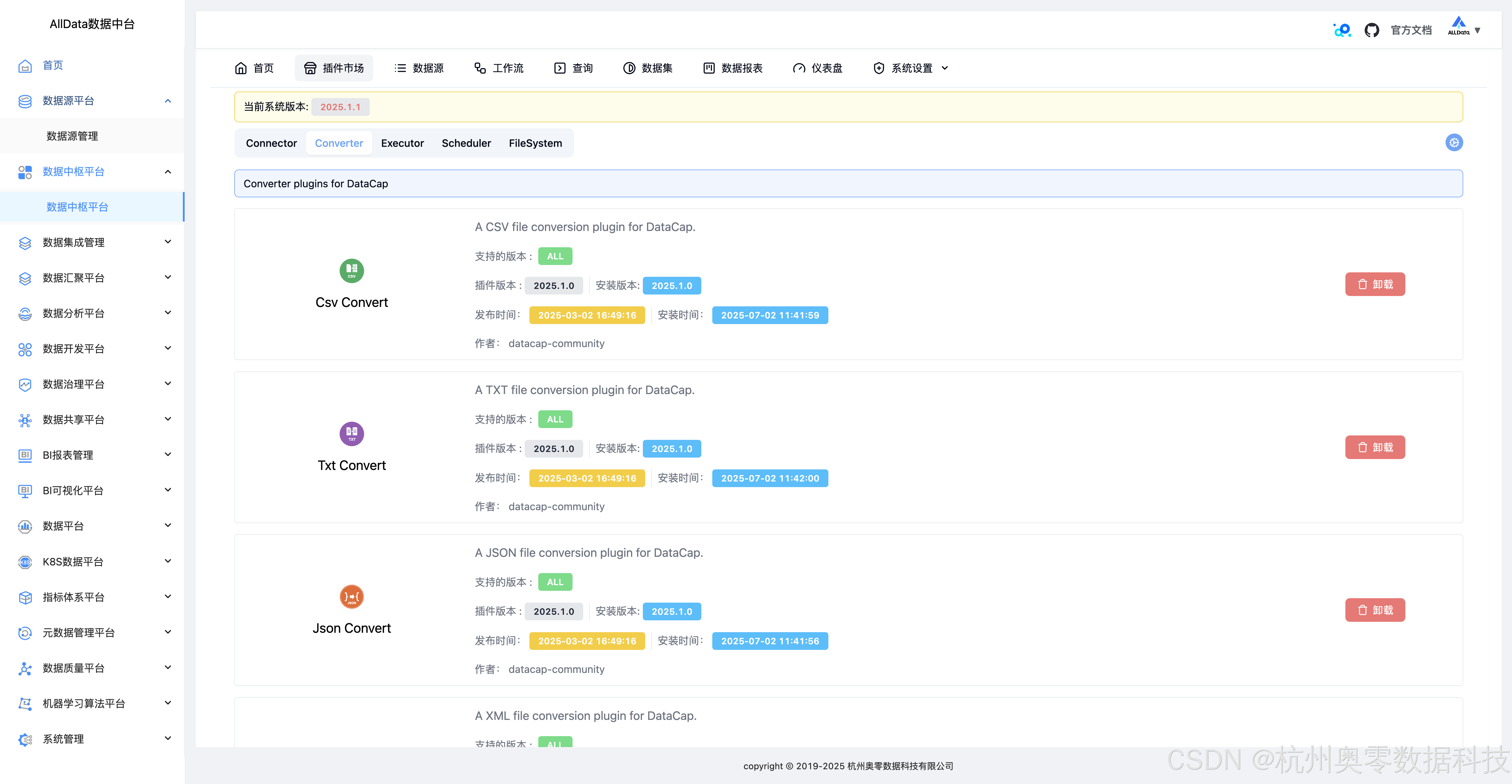
3、插件市场-Converter
4、插件市场-Executor
5、插件市场-Scheduler
6、插件市场-FileSystem
7、数据源
支持多类型数据库及文件存储的高效集成与统一管理。
8、数据源-创建数据源
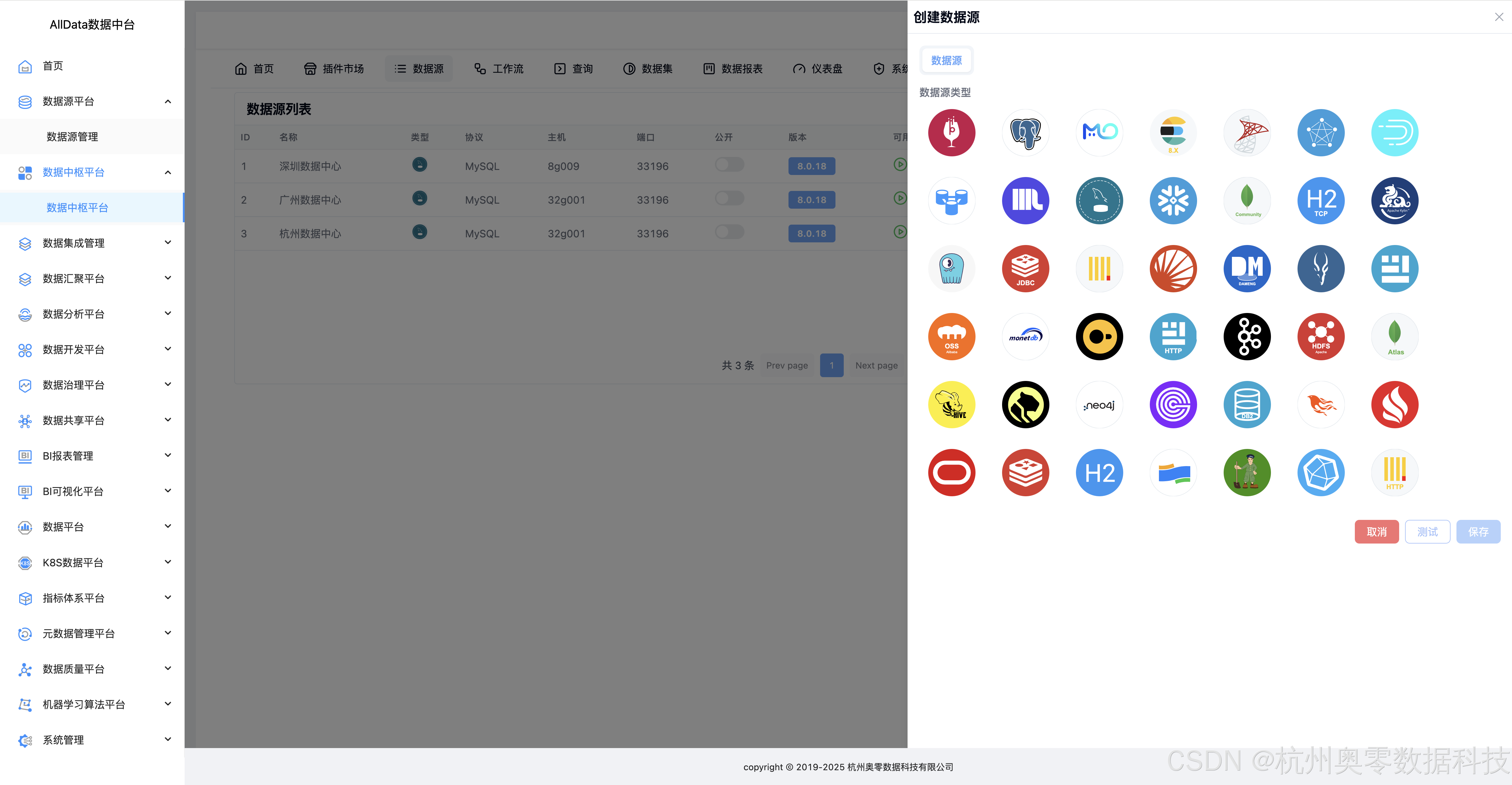
9、修改数据源
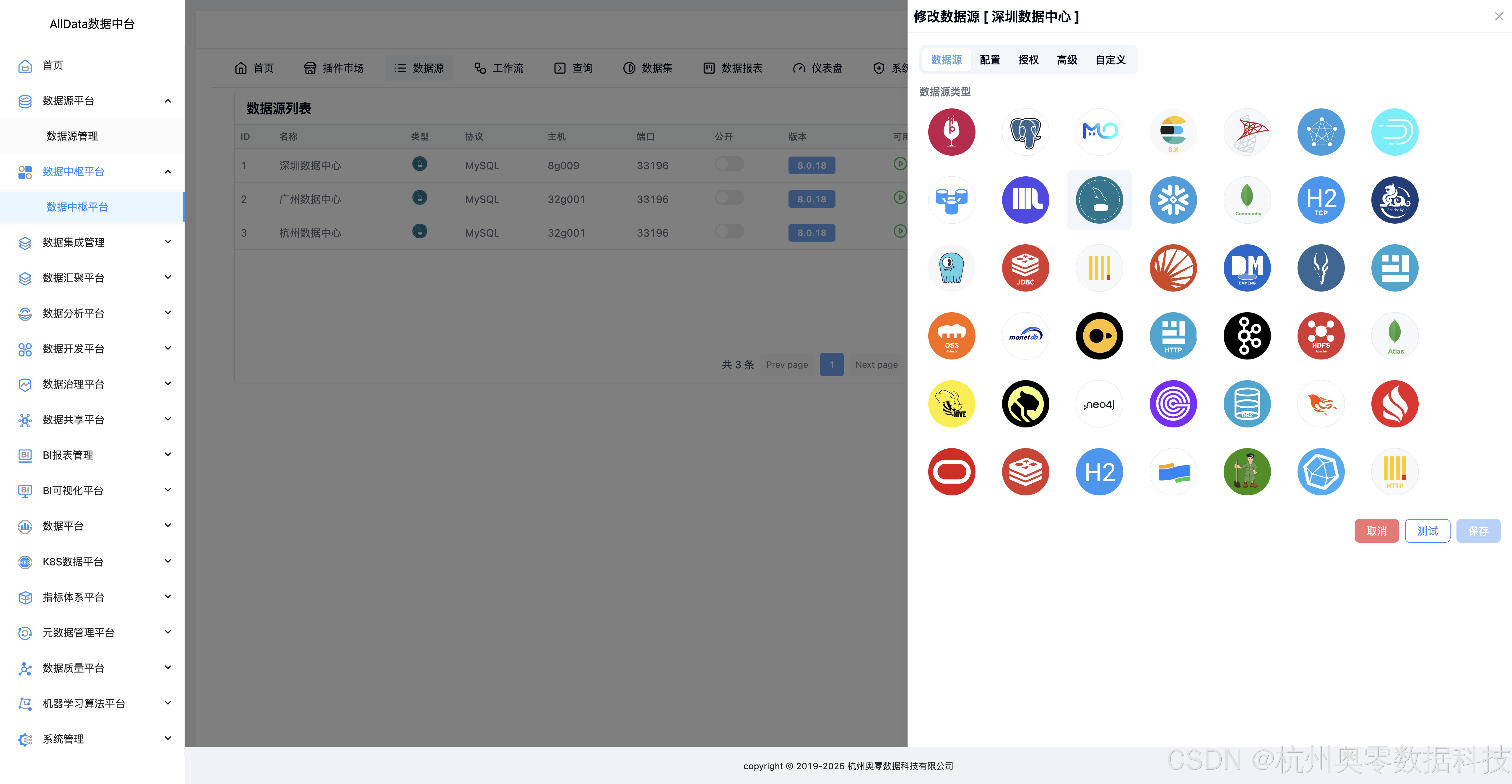
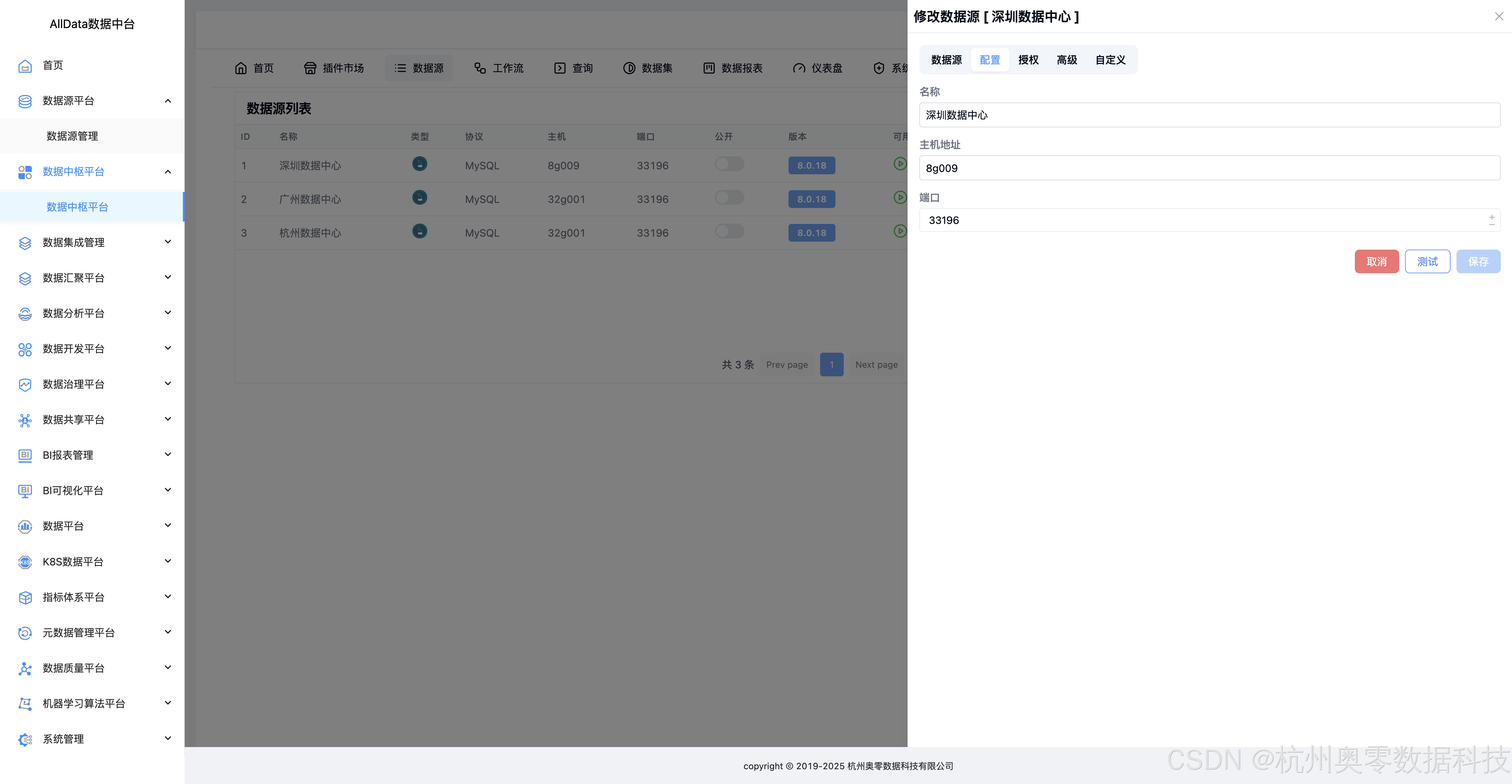
10、修改数据源-配置
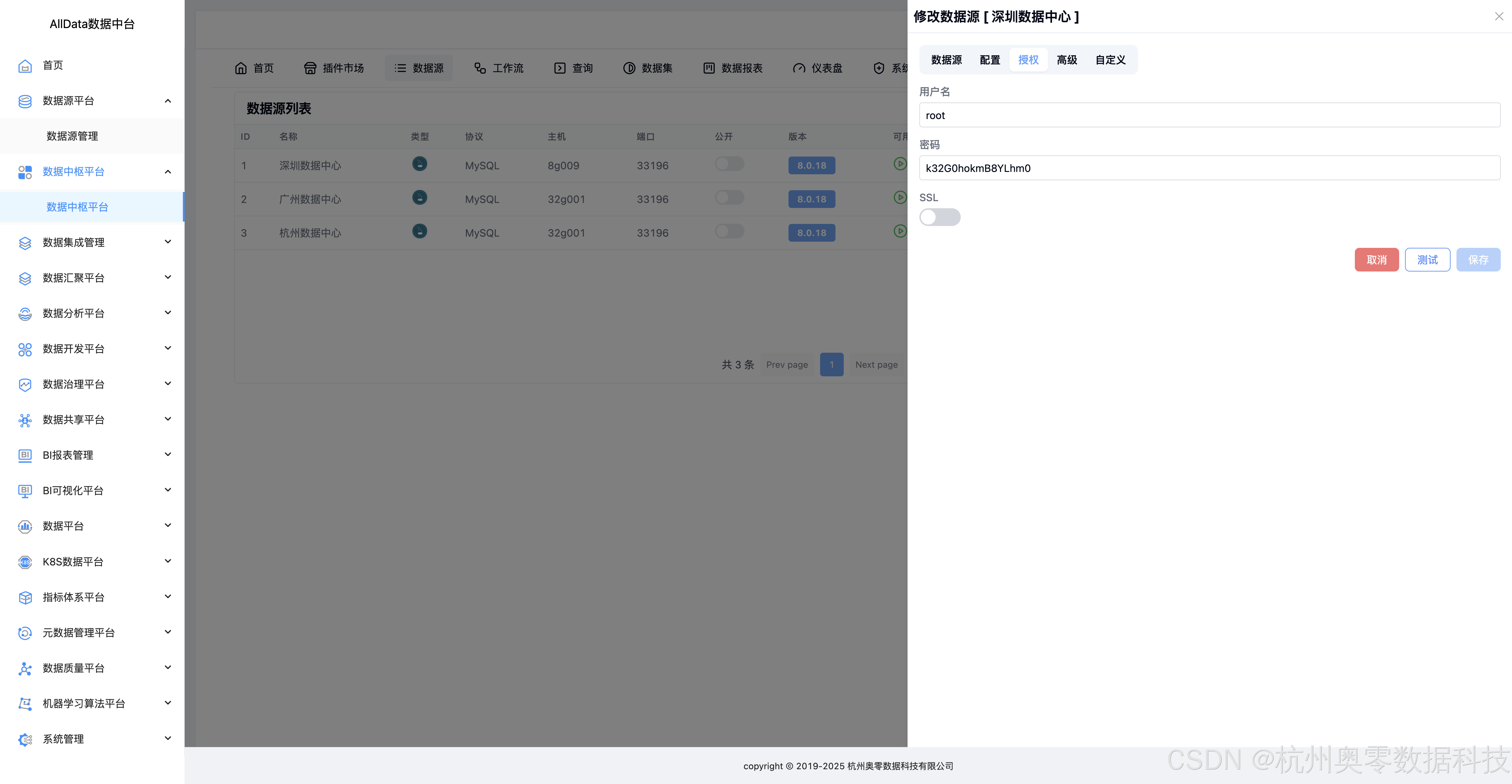
11、修改数据源-授权
12、修改数据源-高级
13、修改数据源-自定义
14、工作流
支持可视化编排,实现数据任务的自动化调度与灵活执行
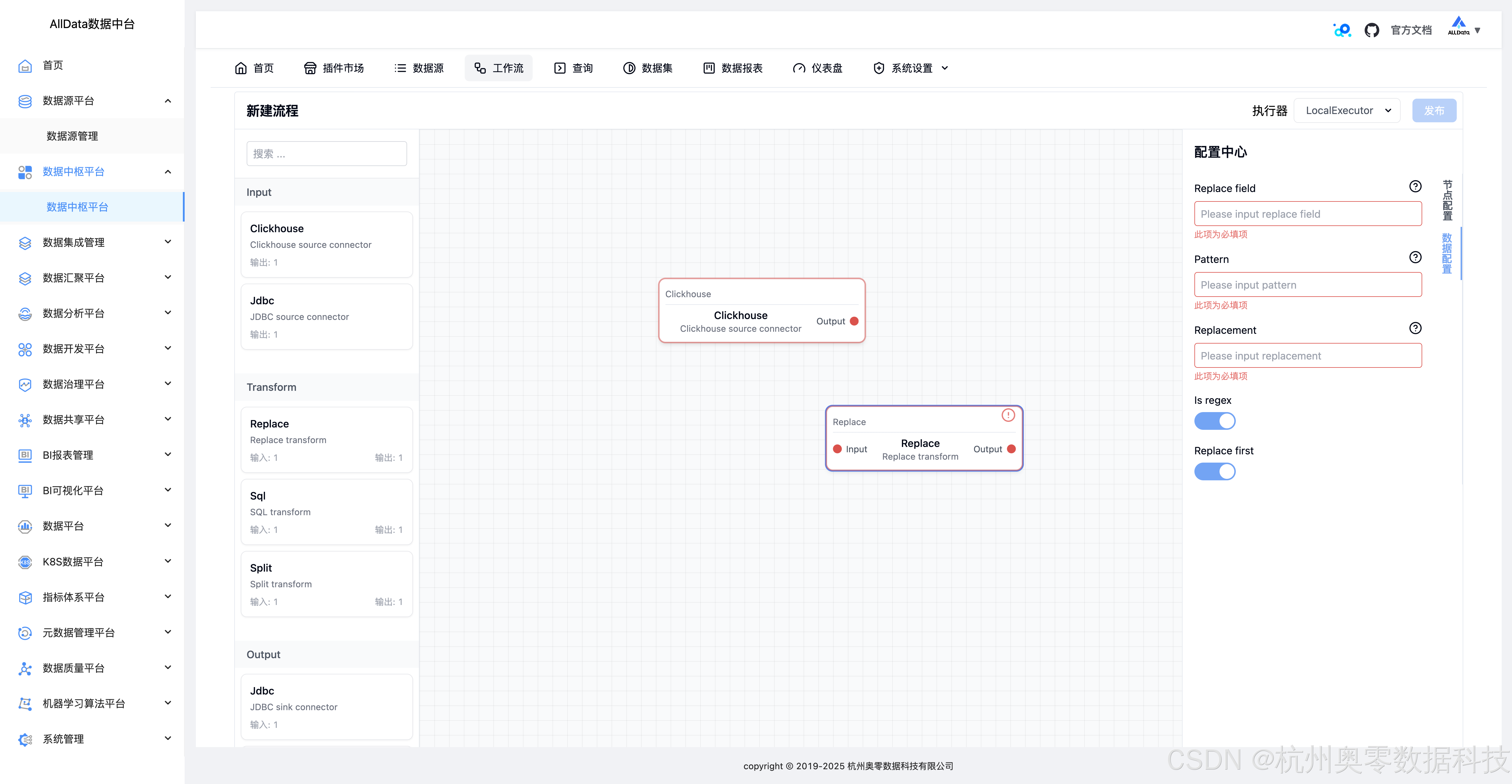
15、新建流程-节点配置
16、新建流程-数据配置
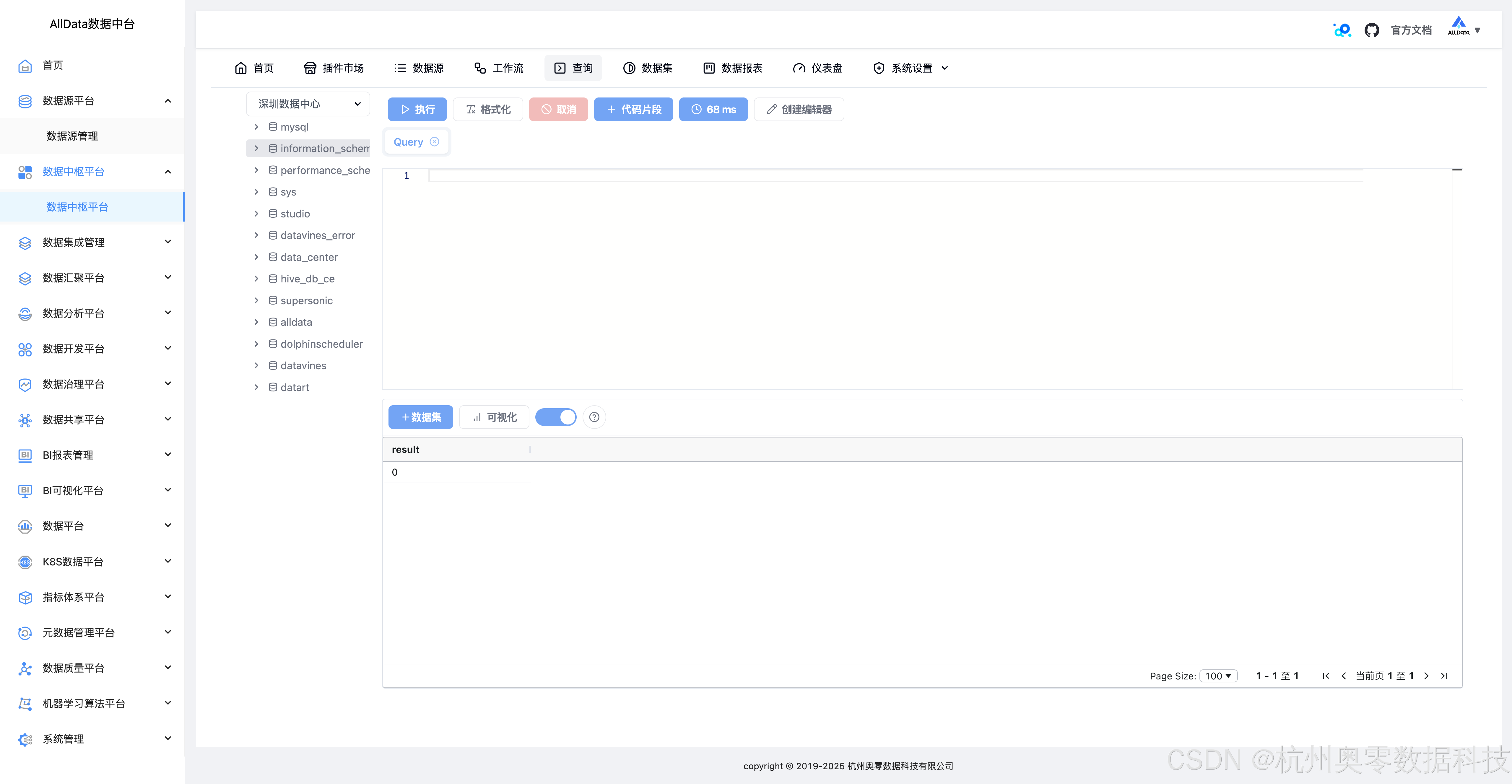
17、查询
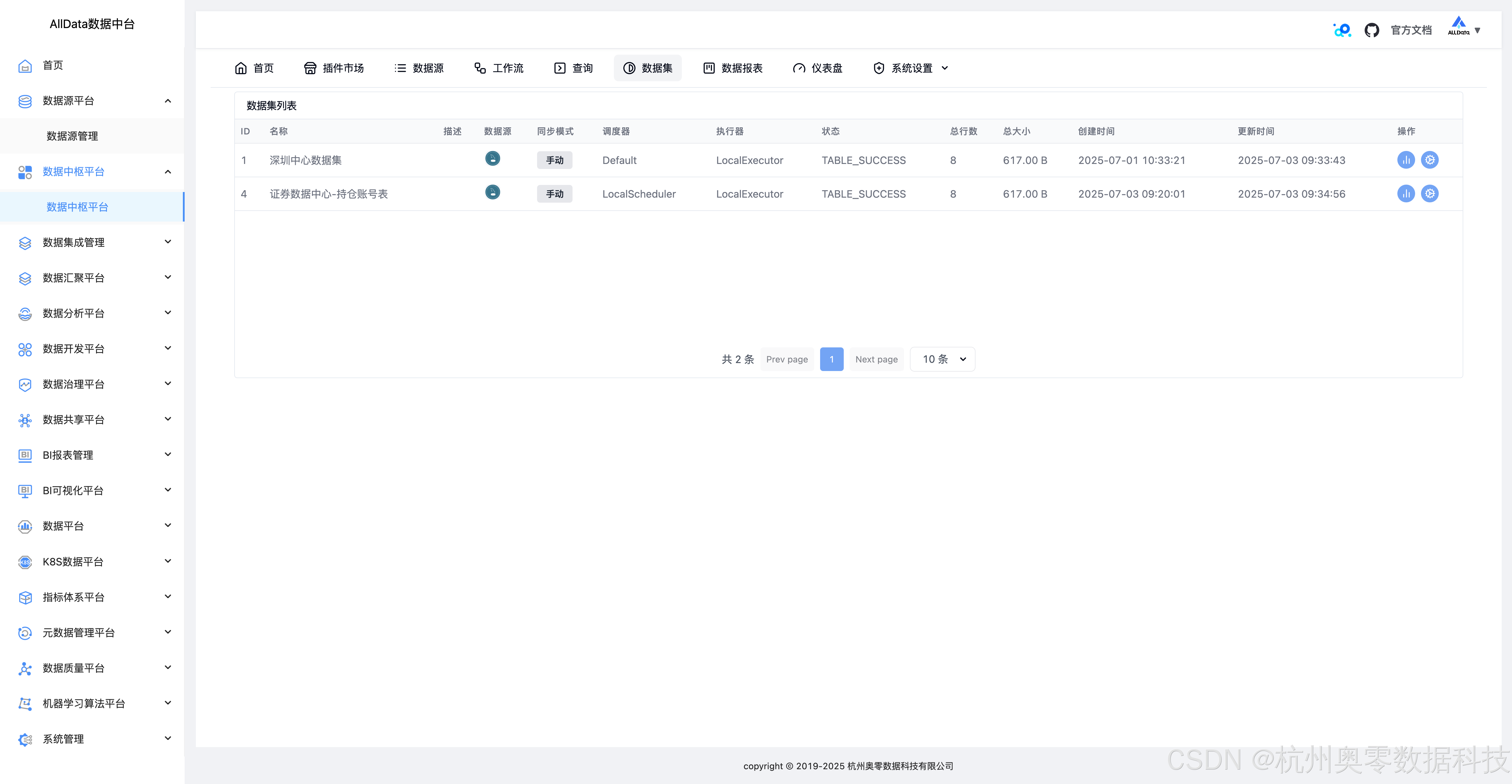
18、数据集
支持多源数据集成与统一管理。
19、即席查询
支持灵活检索分析,秒级响应复杂查询。
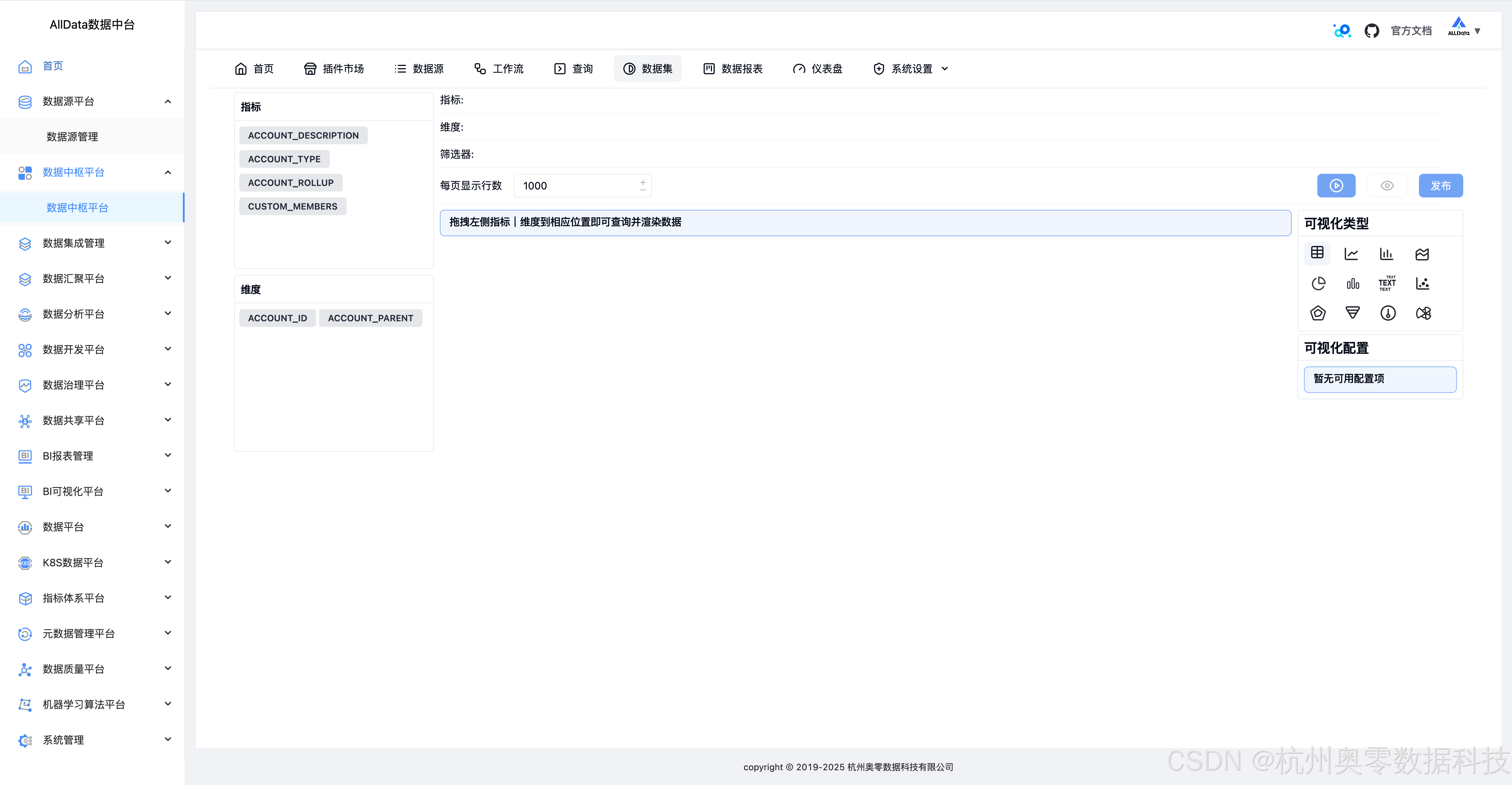
20、即席查询-配置
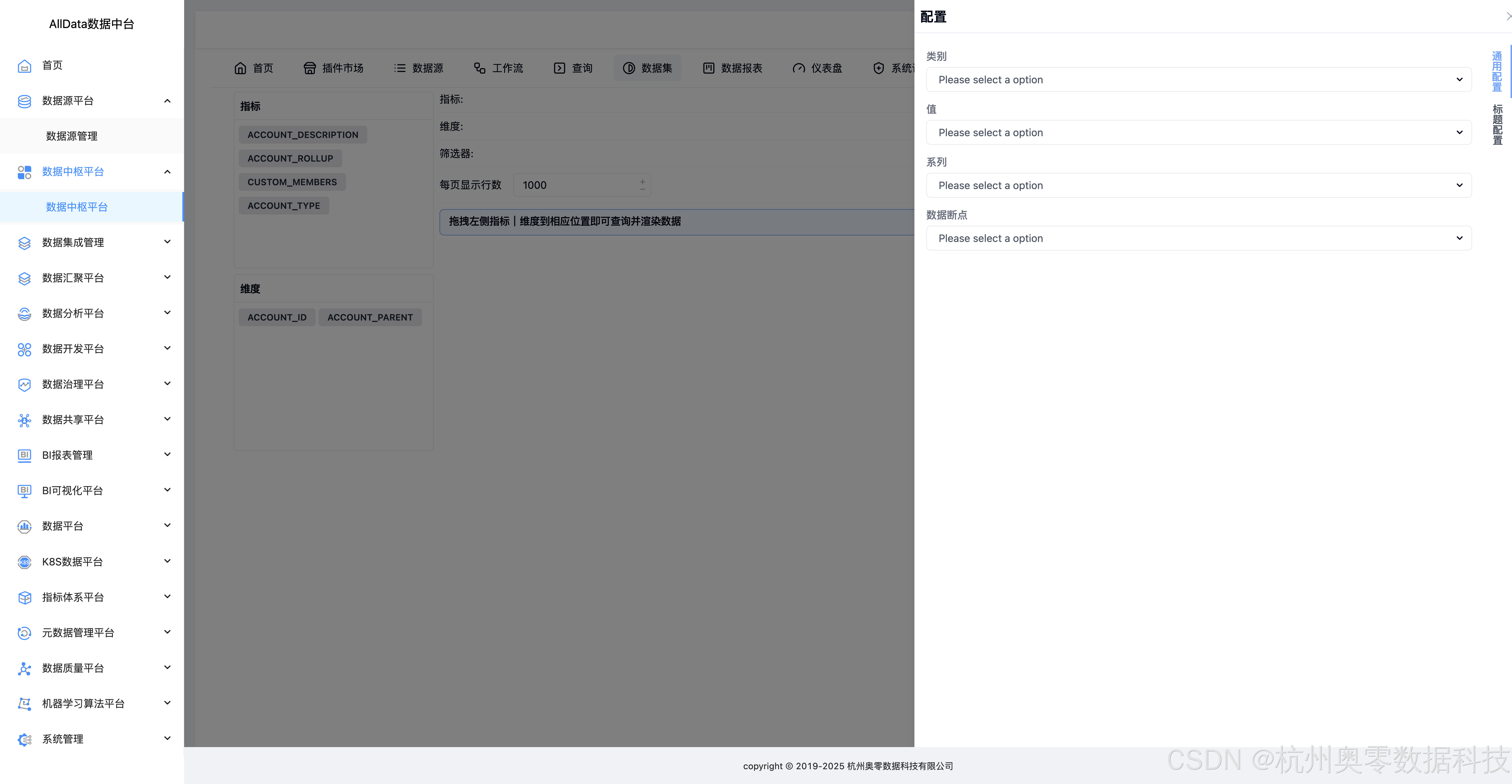
21、数据集-查看详情
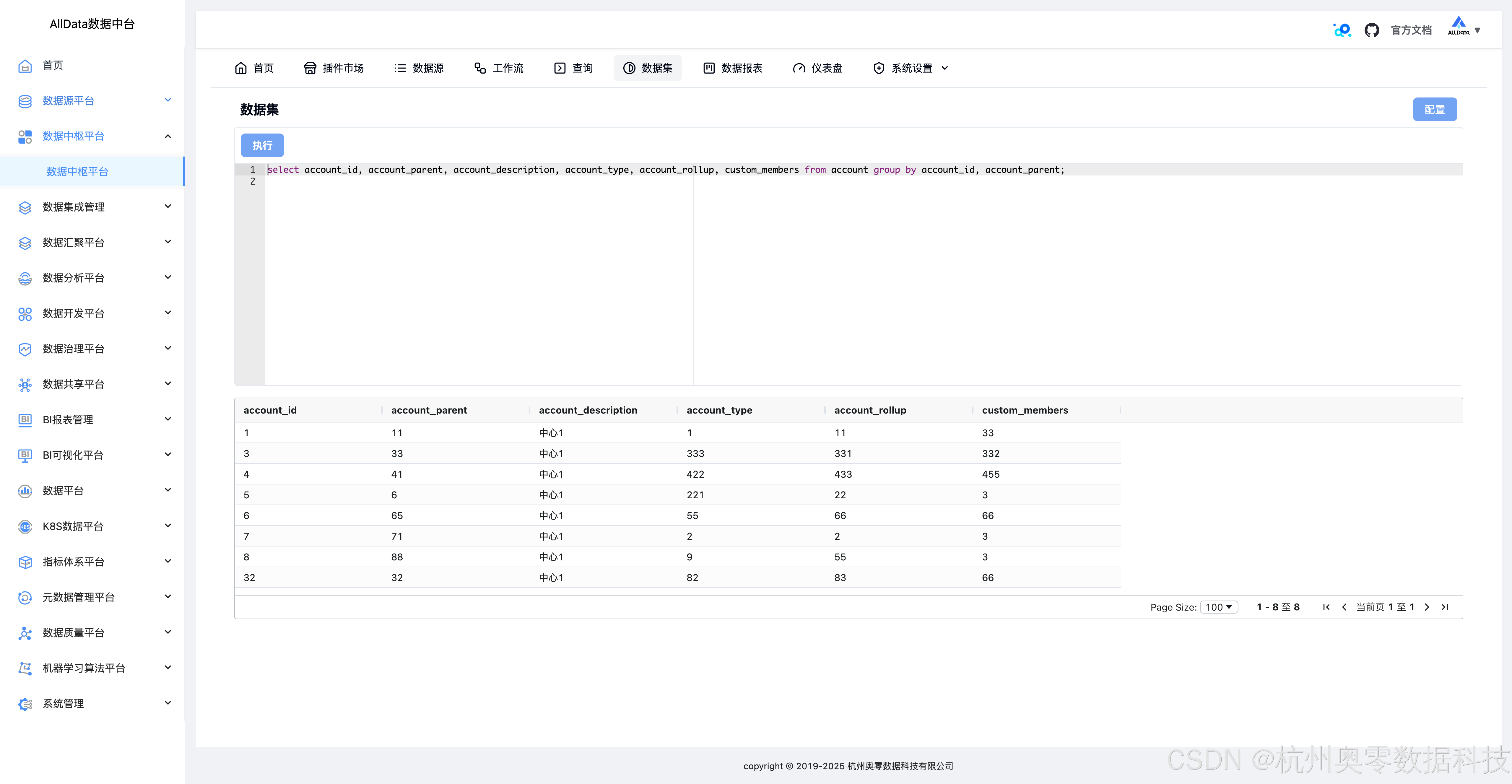
22、数据集
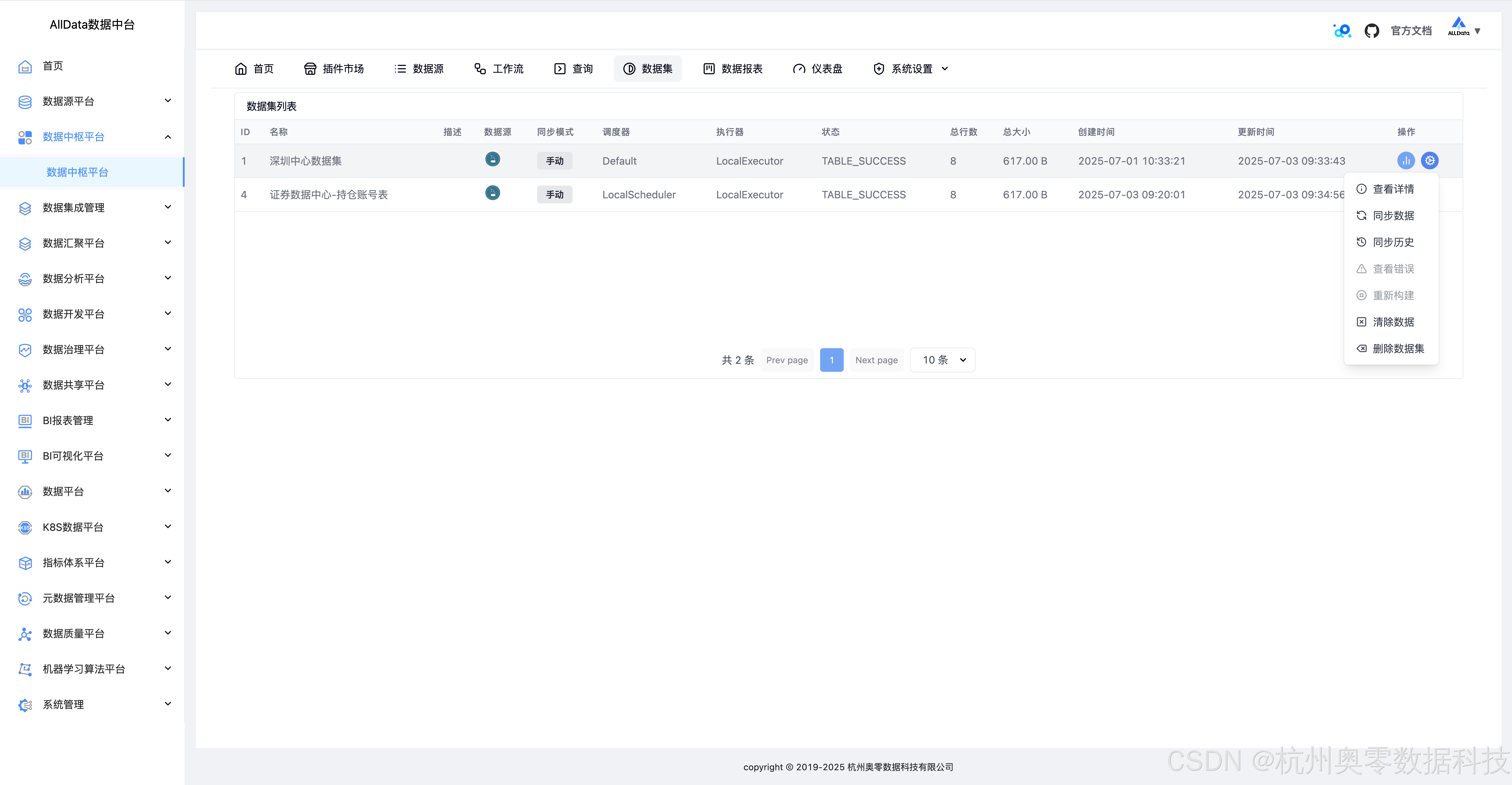
23、同步数据
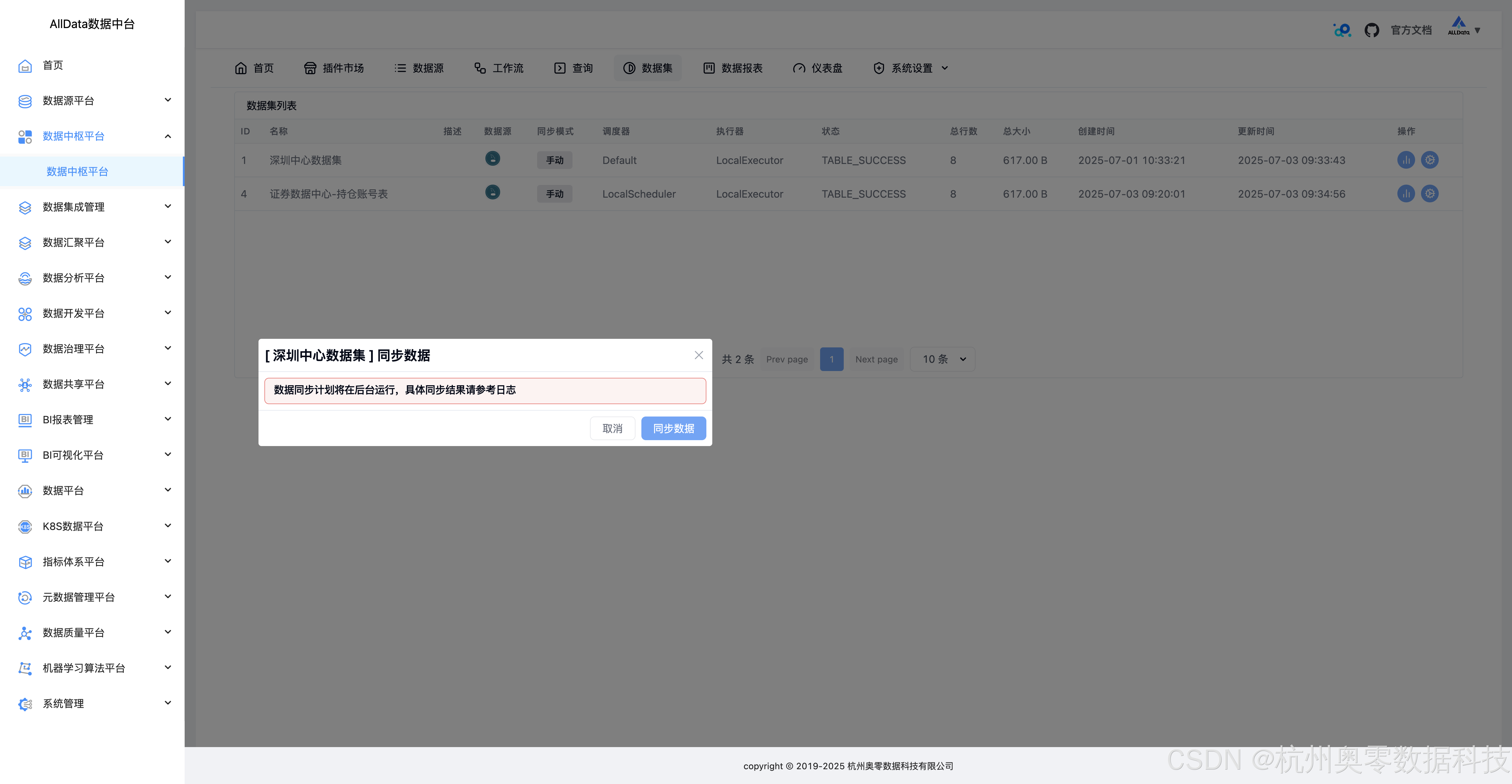
24、历史同步
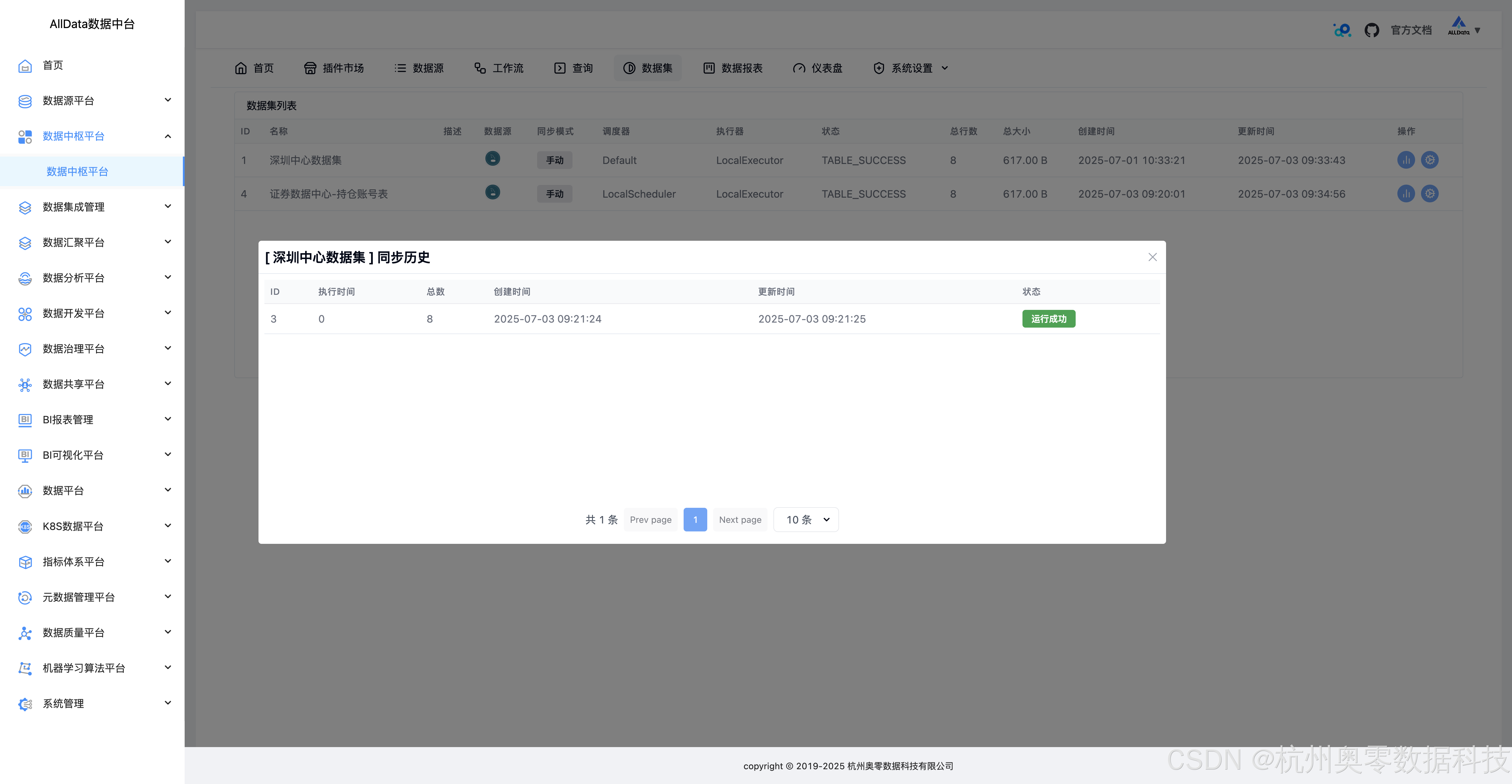
25、数据报表
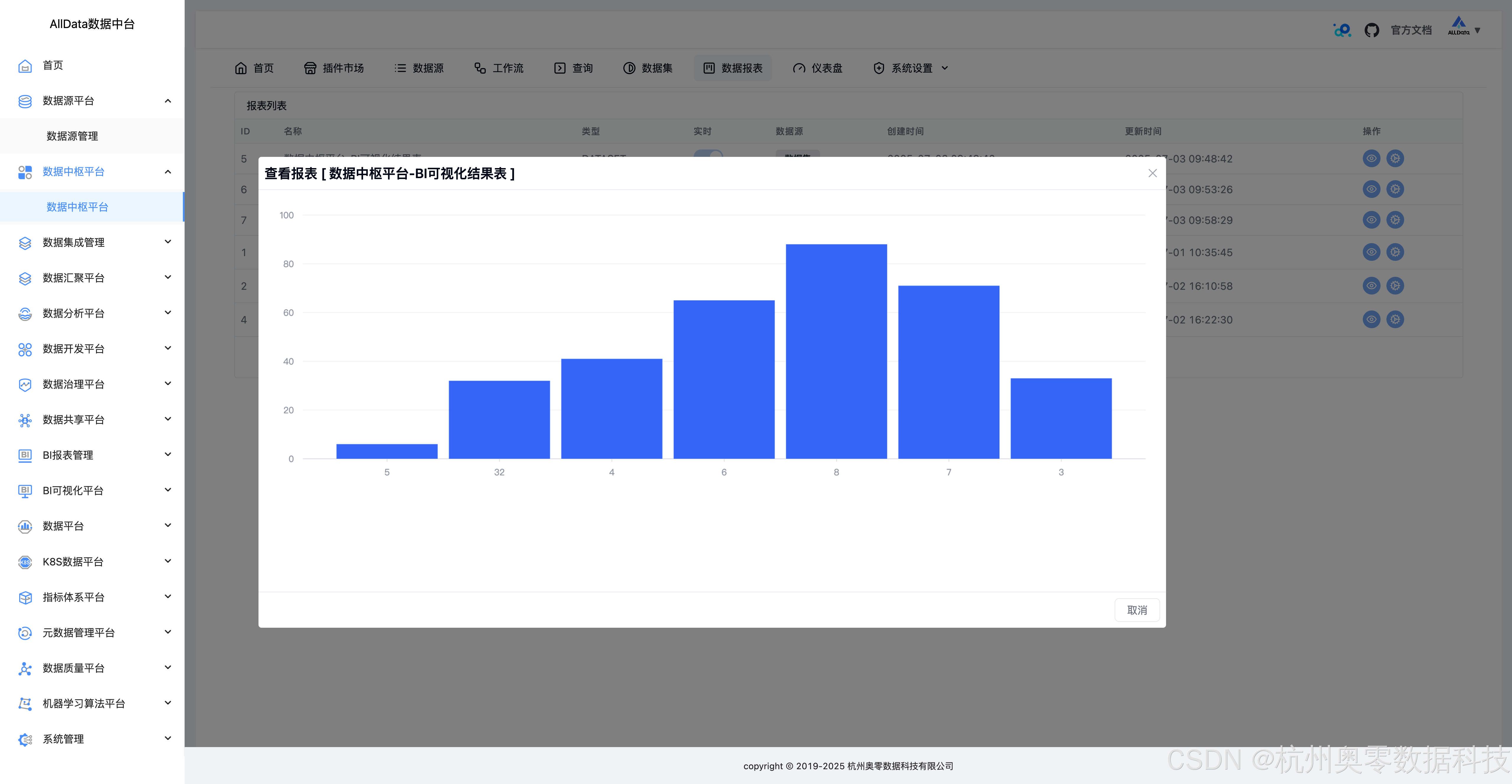
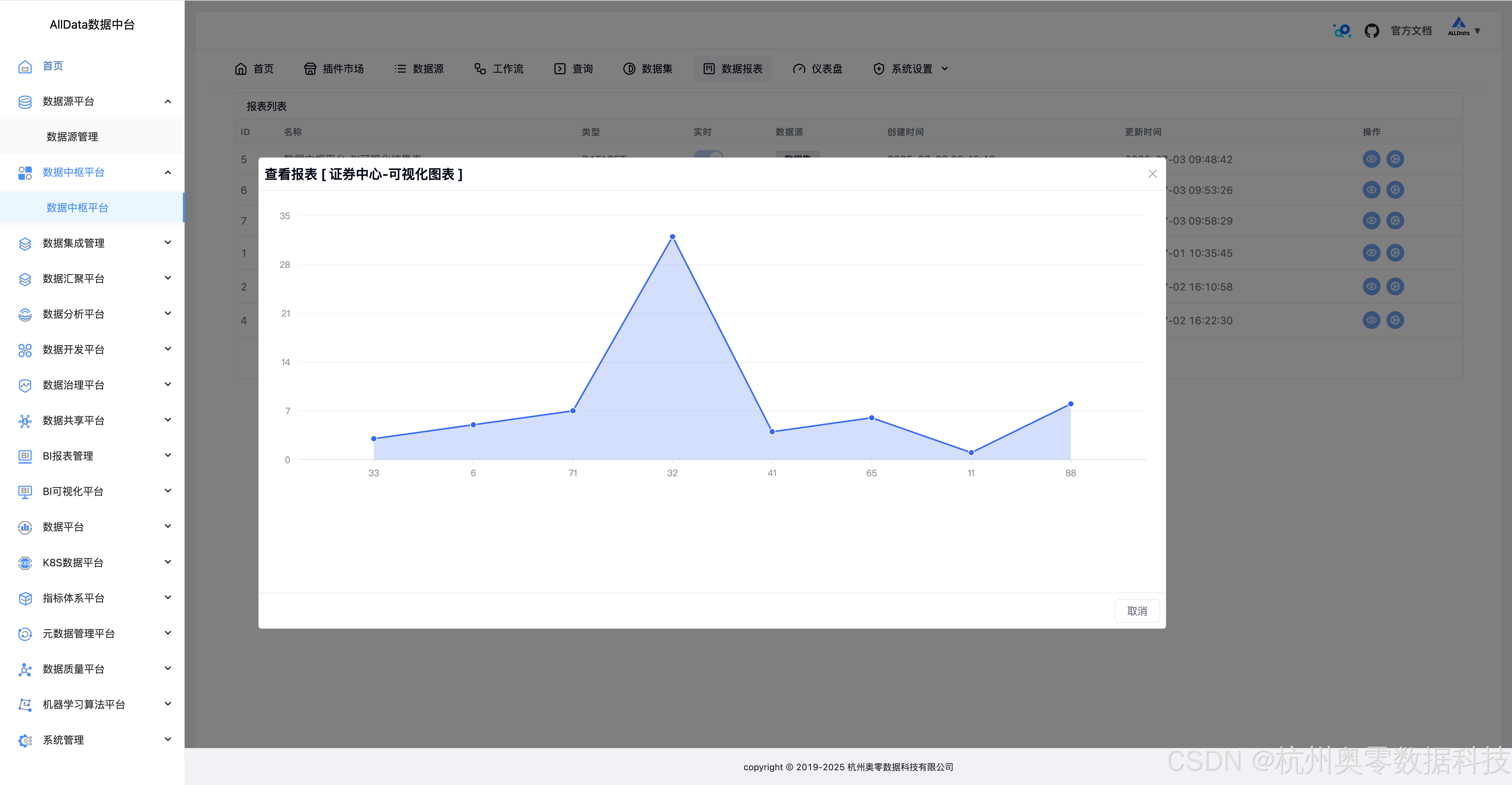
26、查看报表-BI可视化结果表
27、查看报表-可视化图表
28、查看报表
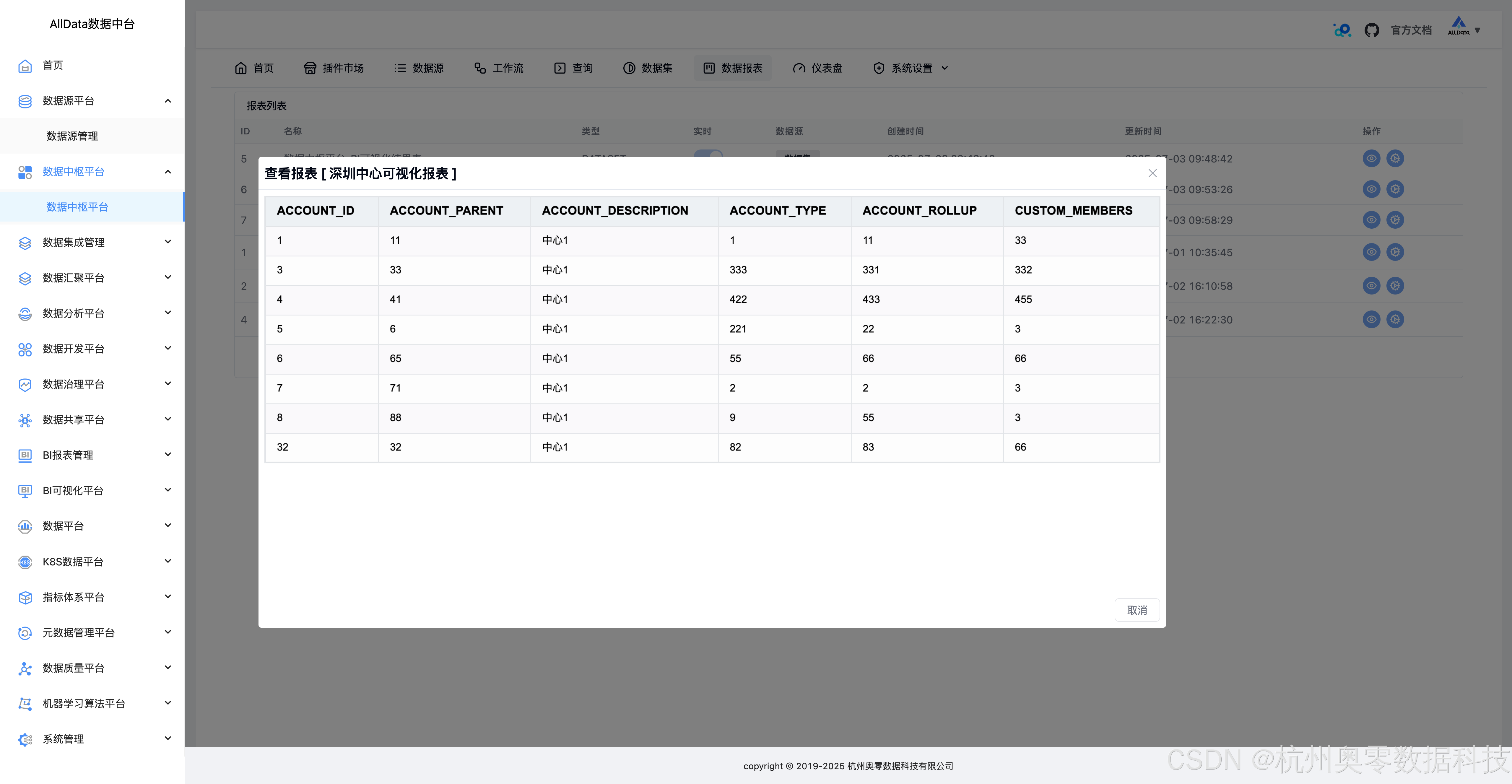
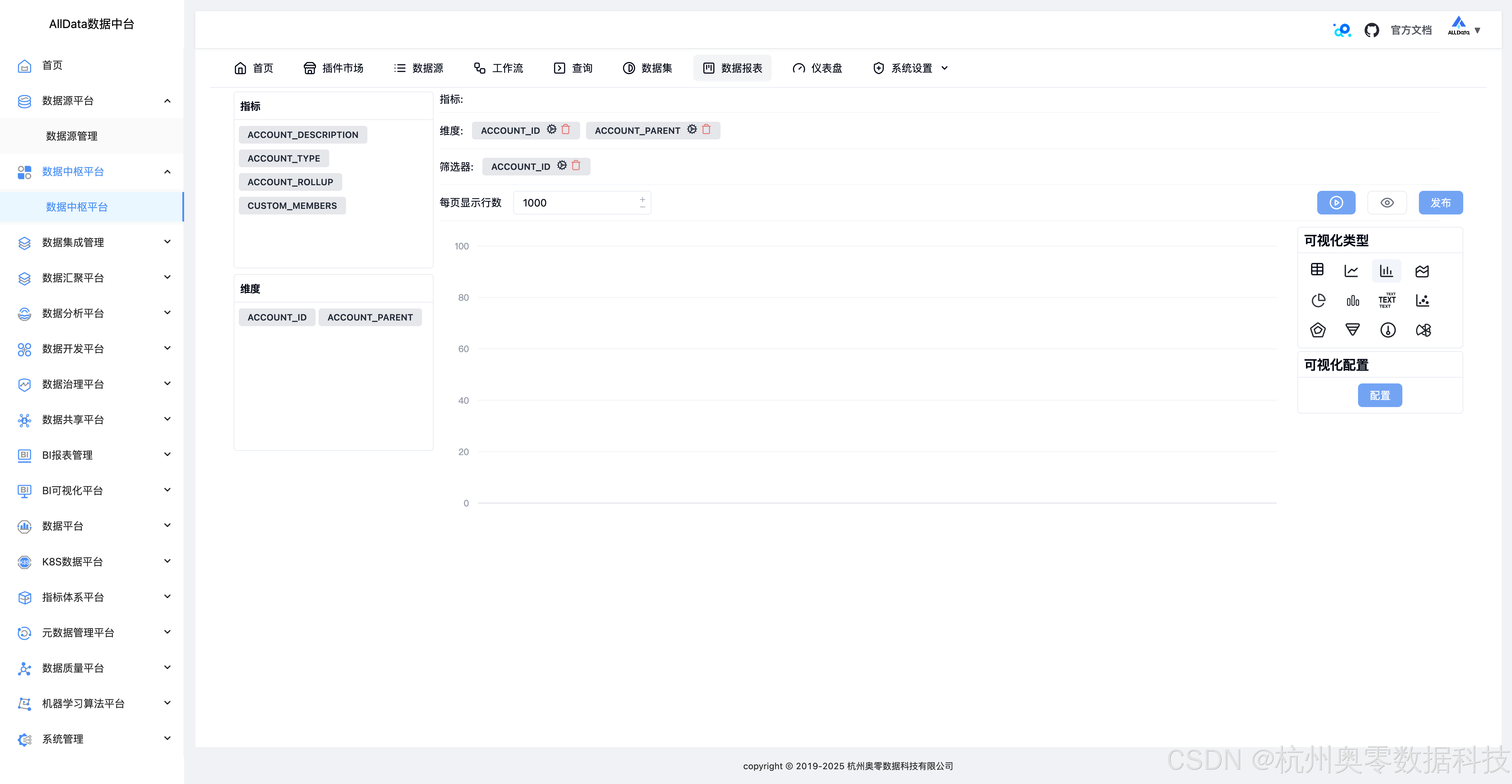
29、修改报表
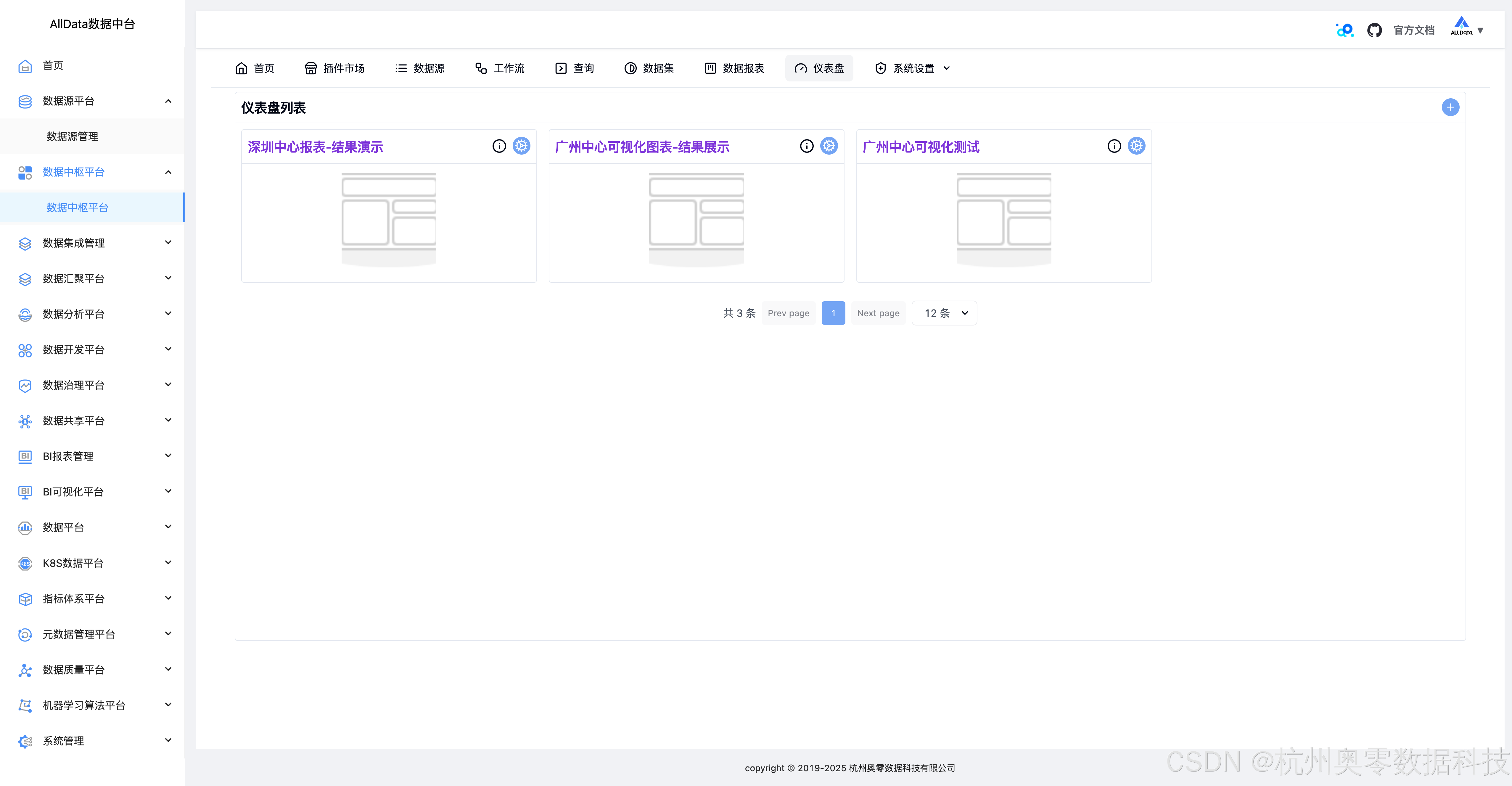
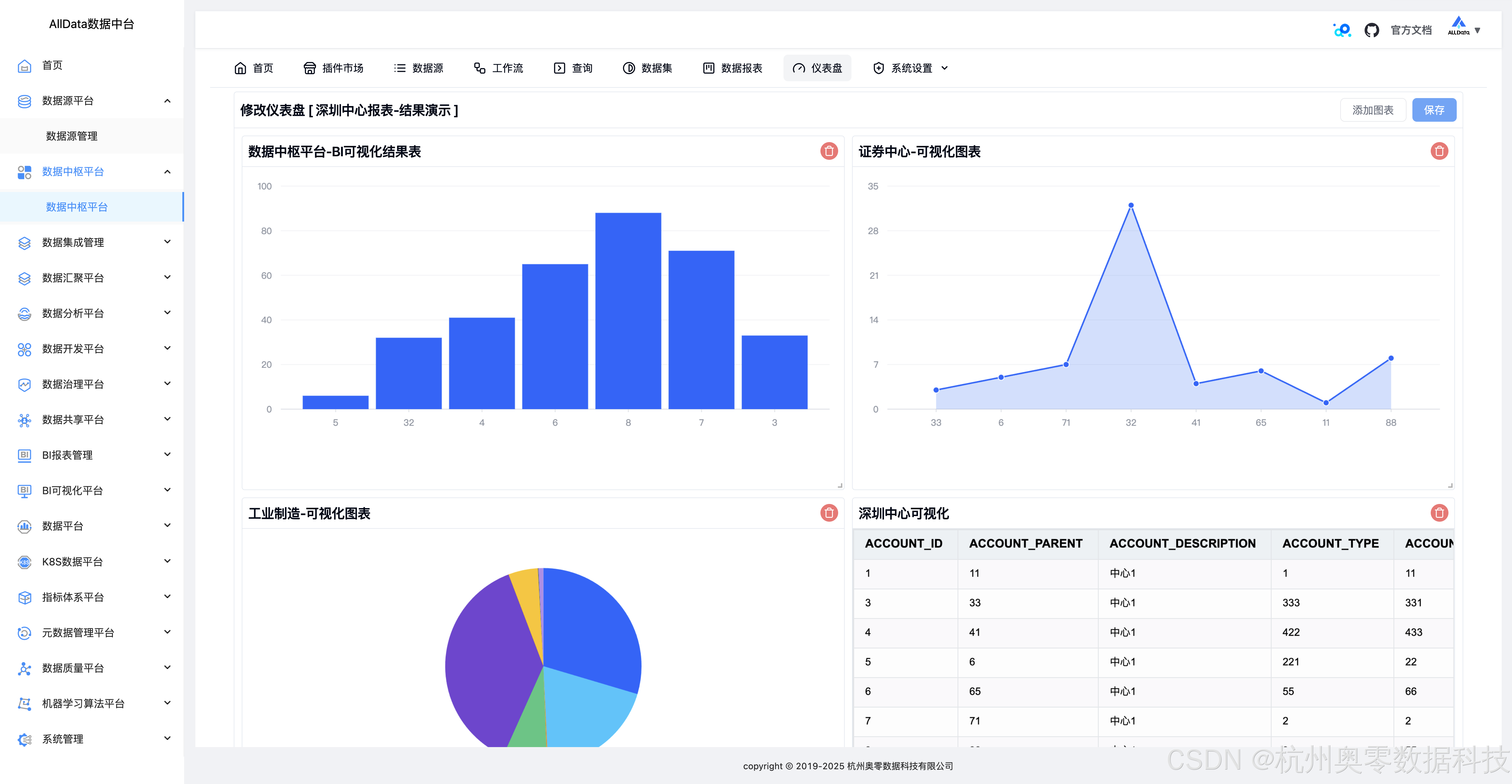
30、仪表盘
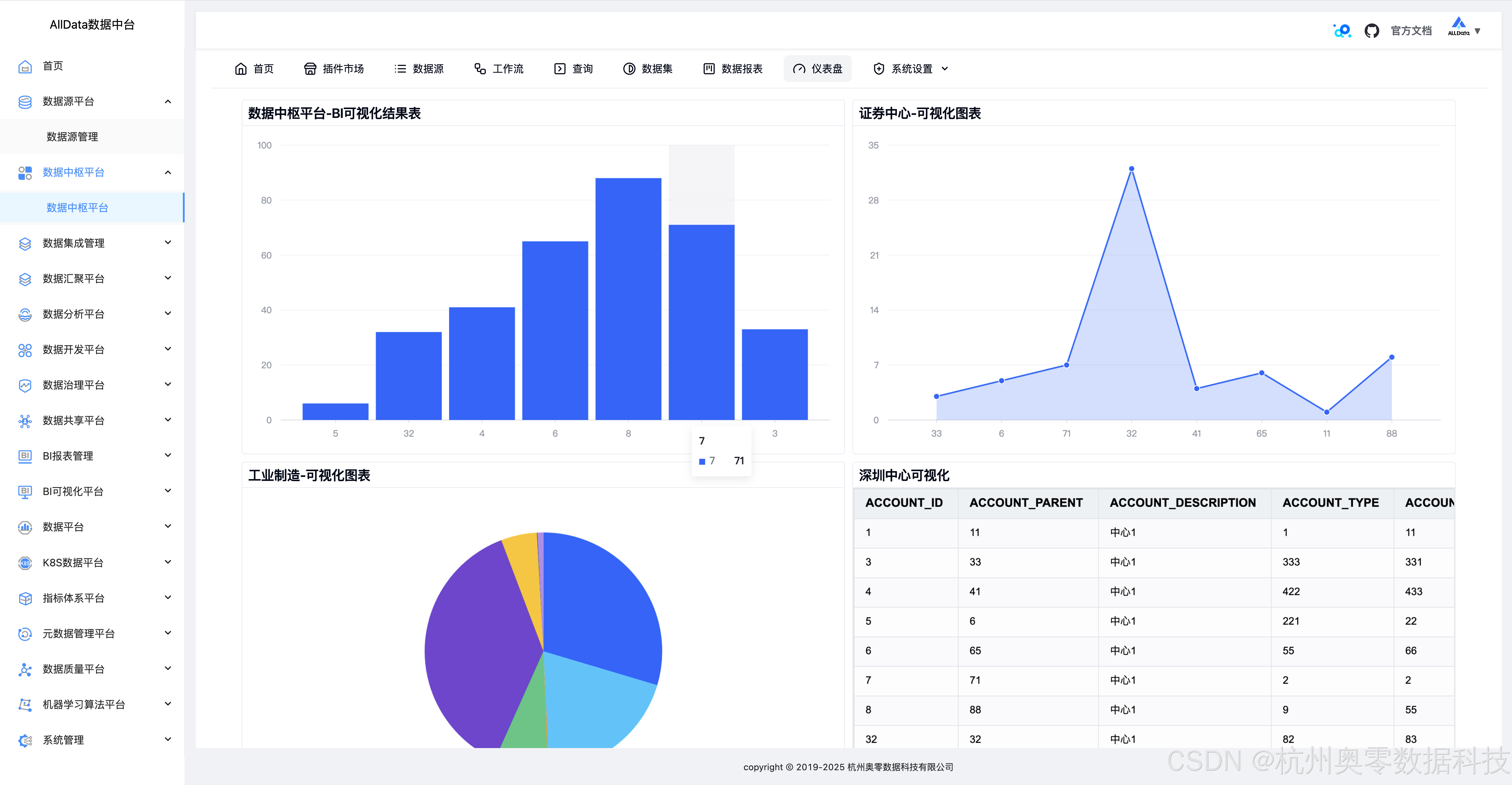
31、点击查看结果演示
32、修改仪表盘
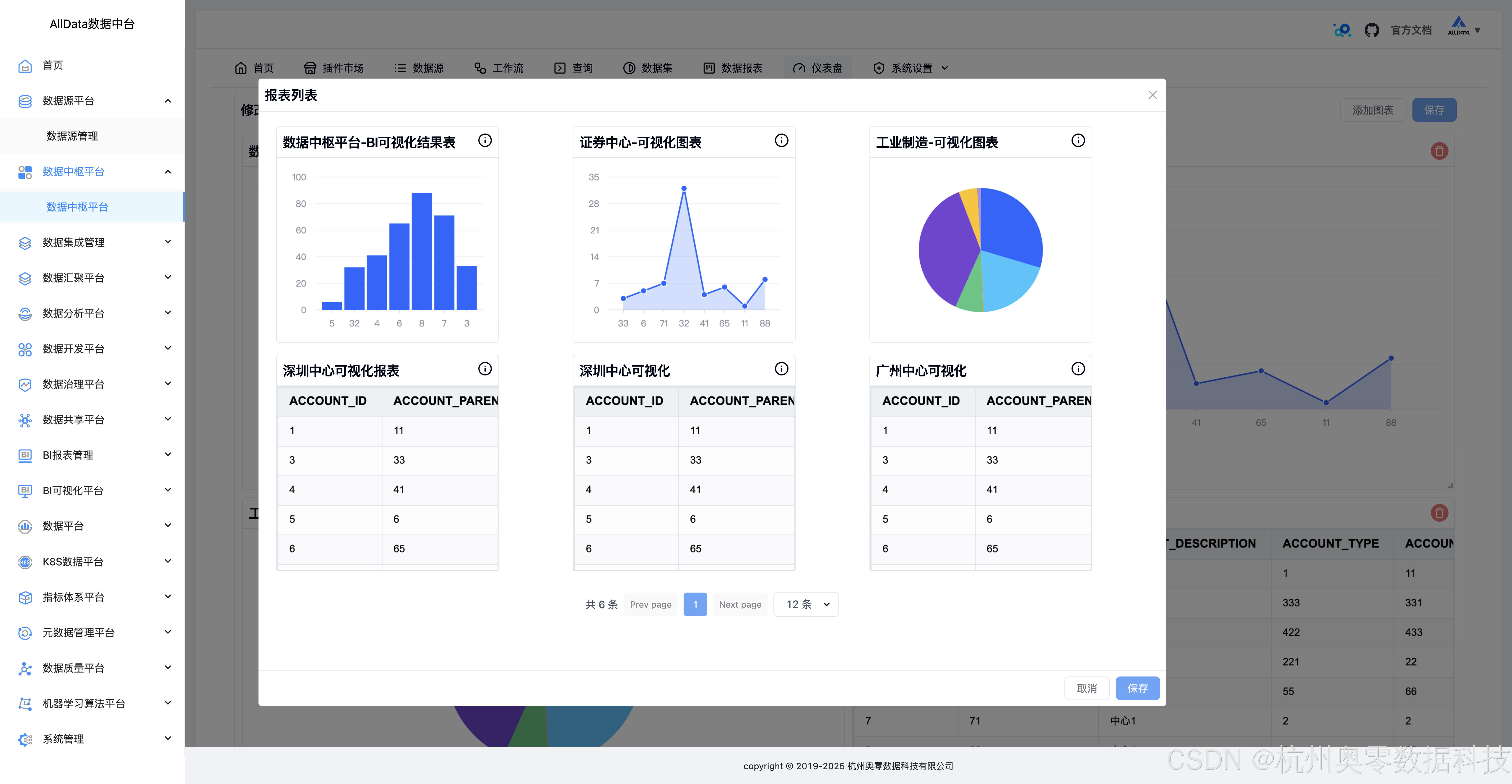
33、添加图表-报表列表
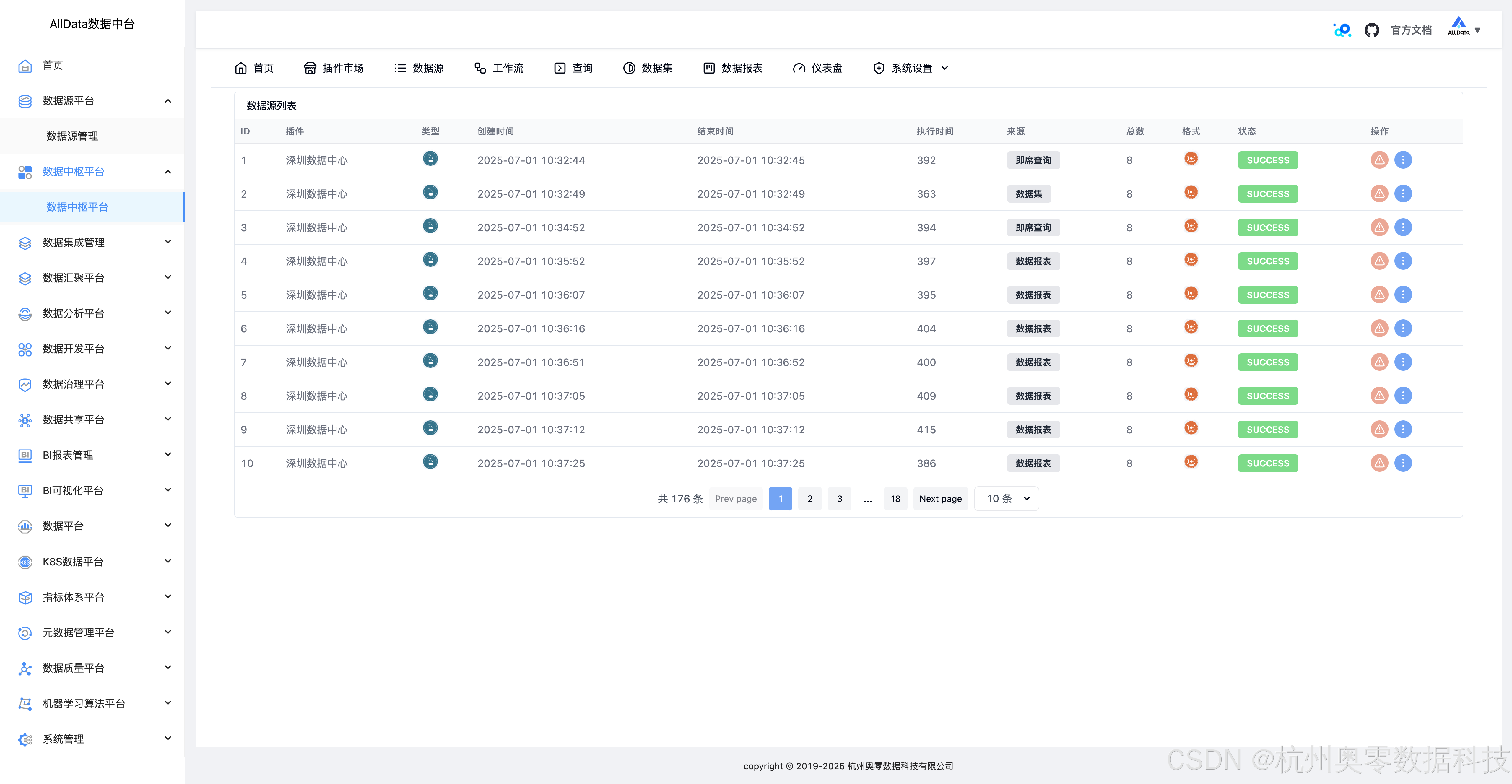
34、系统设置-历史查询
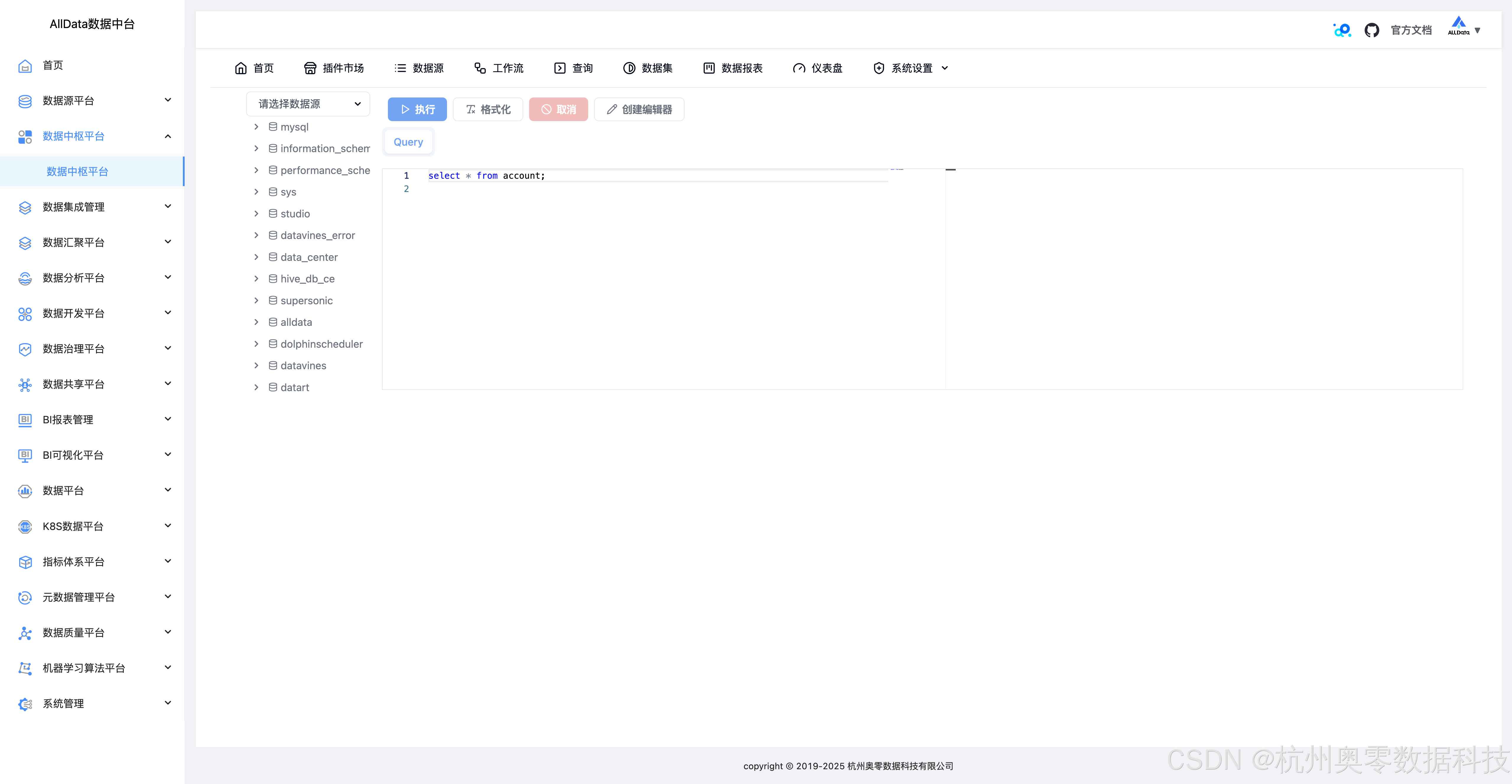
35、系统设置-历史查询-引用记录
36、系统设置-历史查询-显示SQL
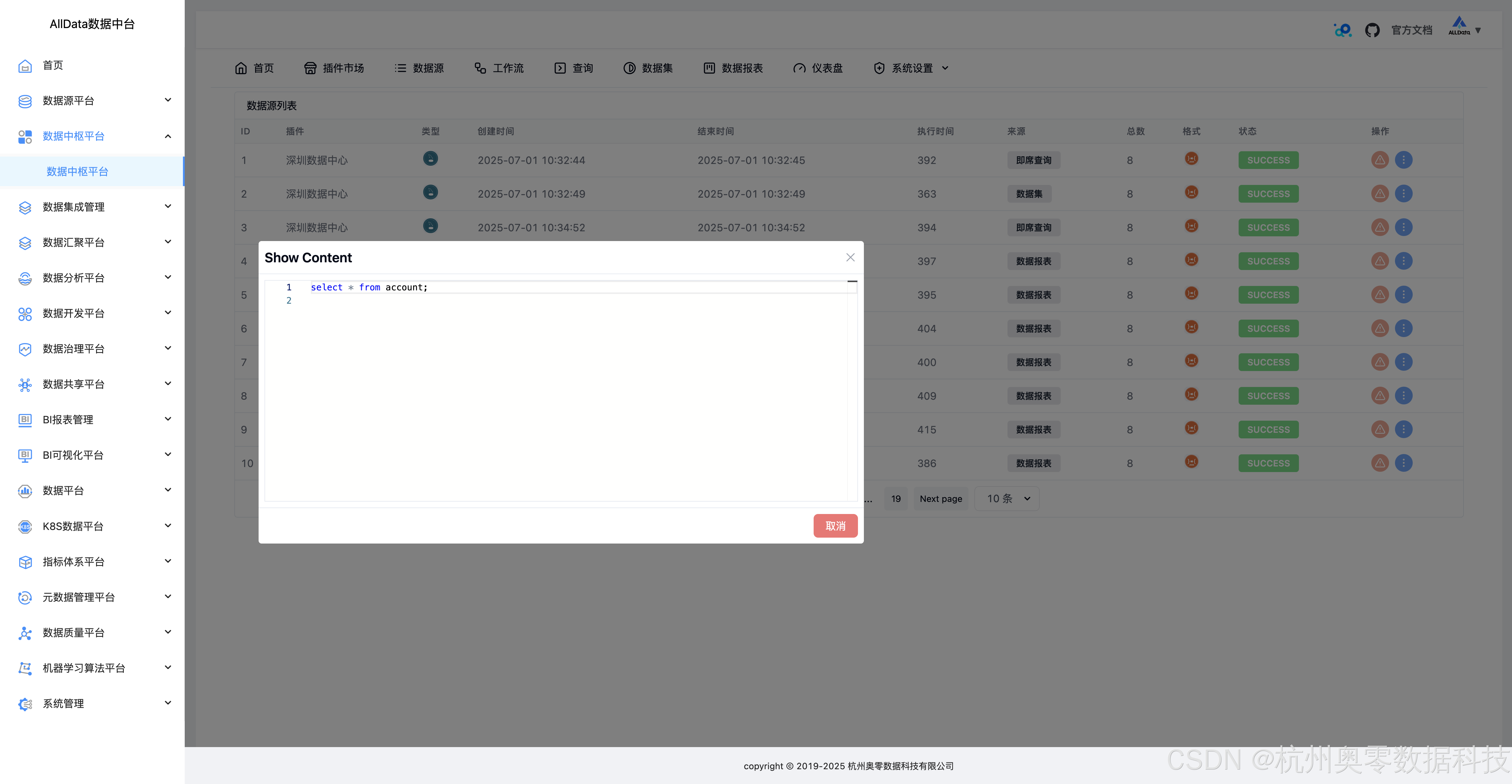
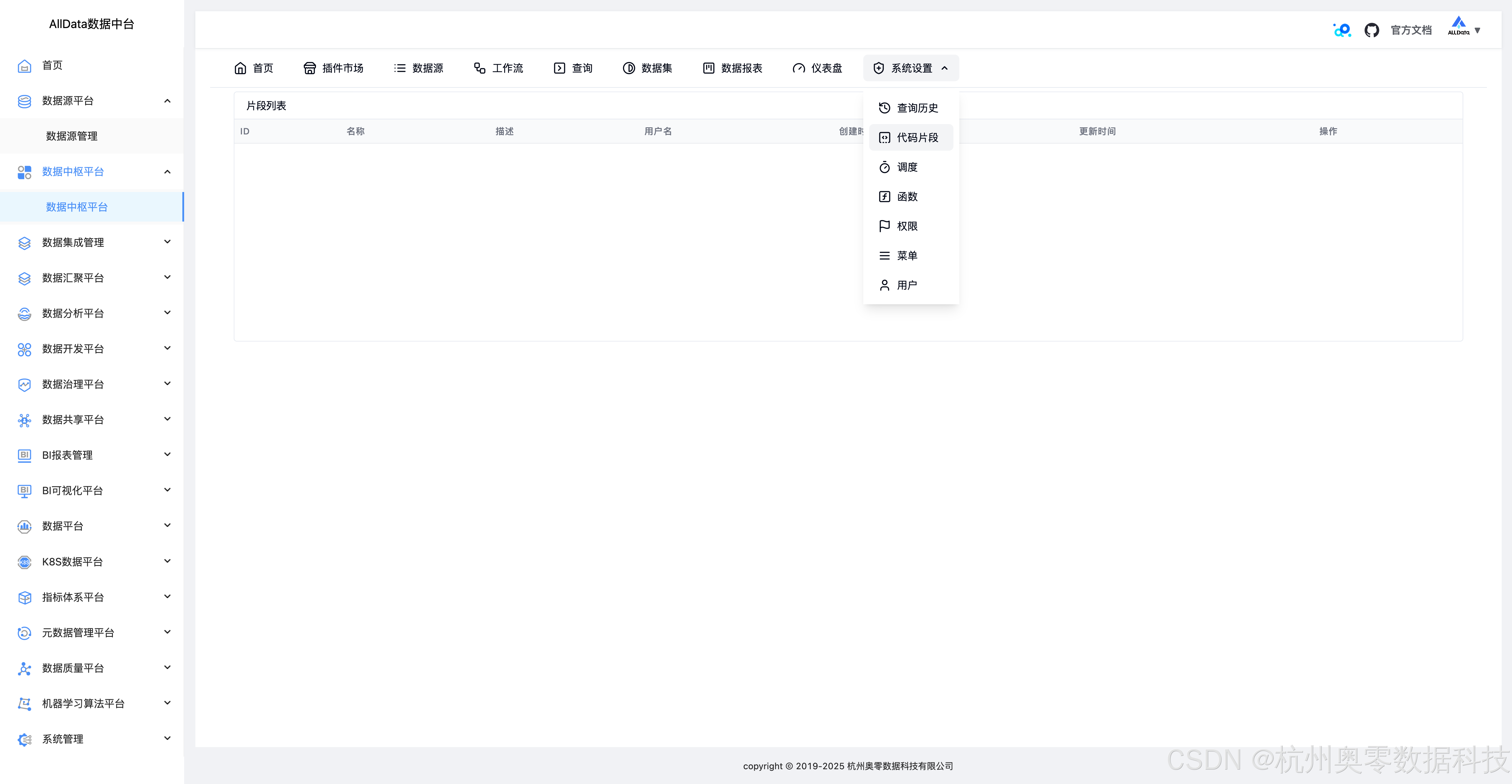
37、系统设置-代码片段
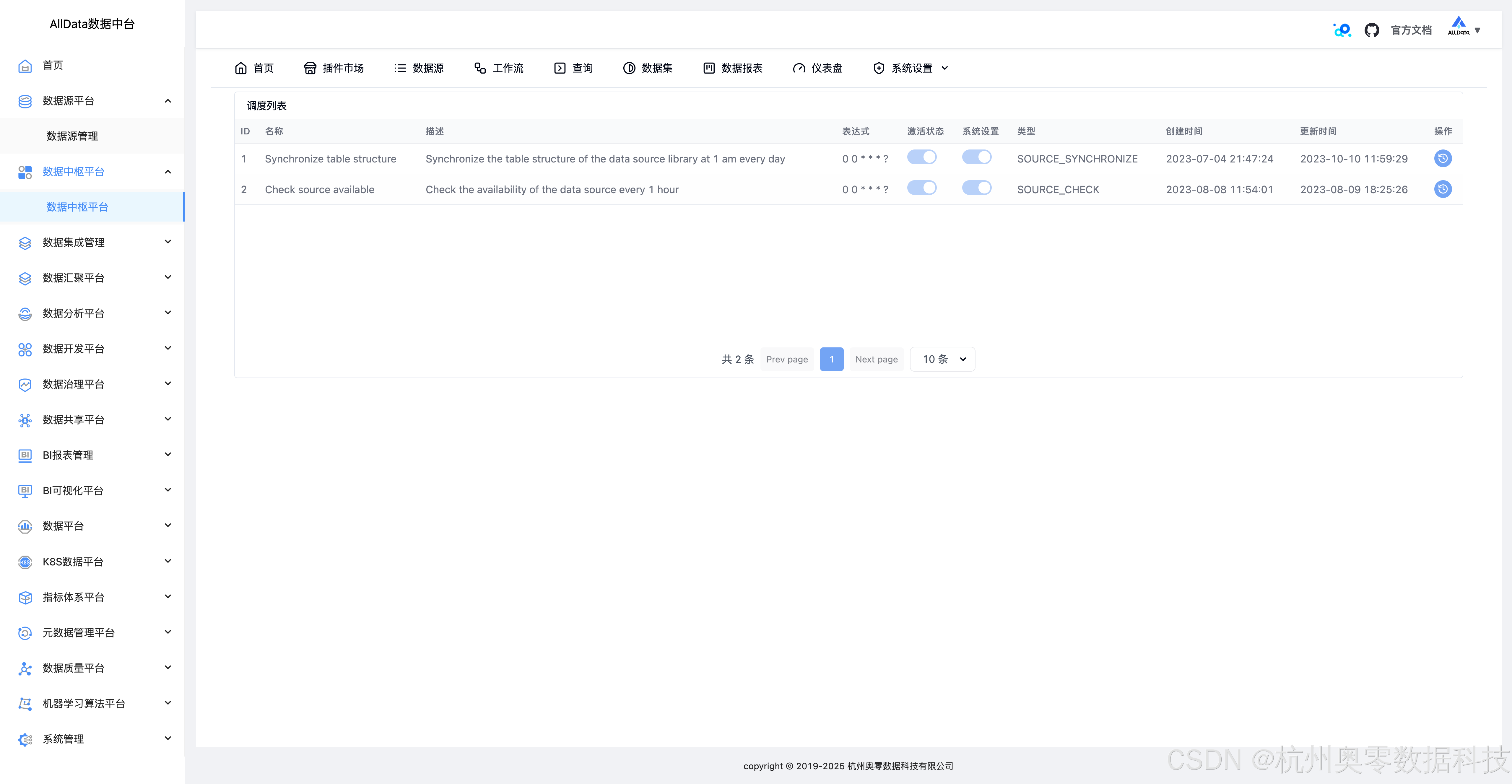
38、系统设置-调度
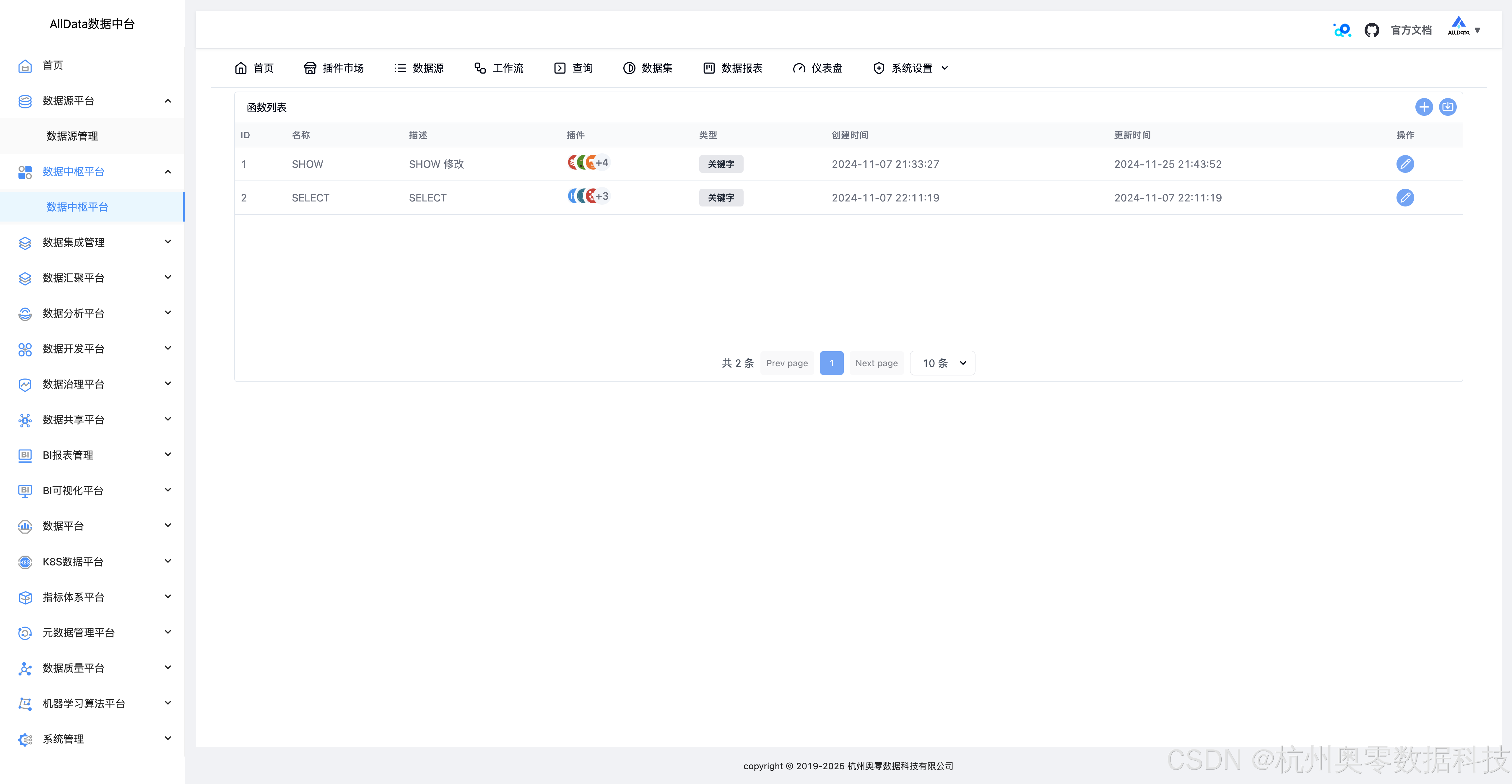
39、系统设置-函数
40、修改函数
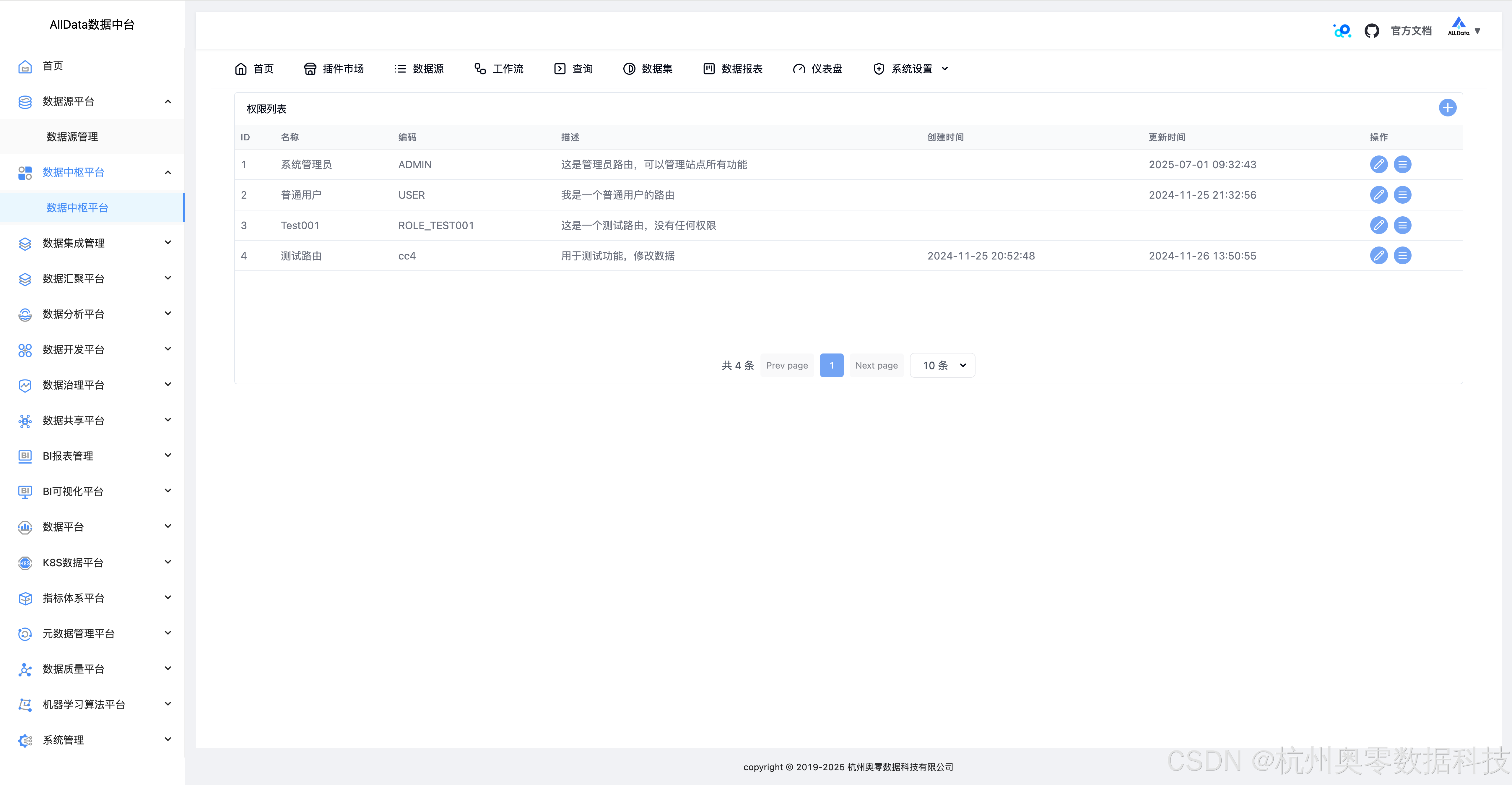
41、系统设置-权限
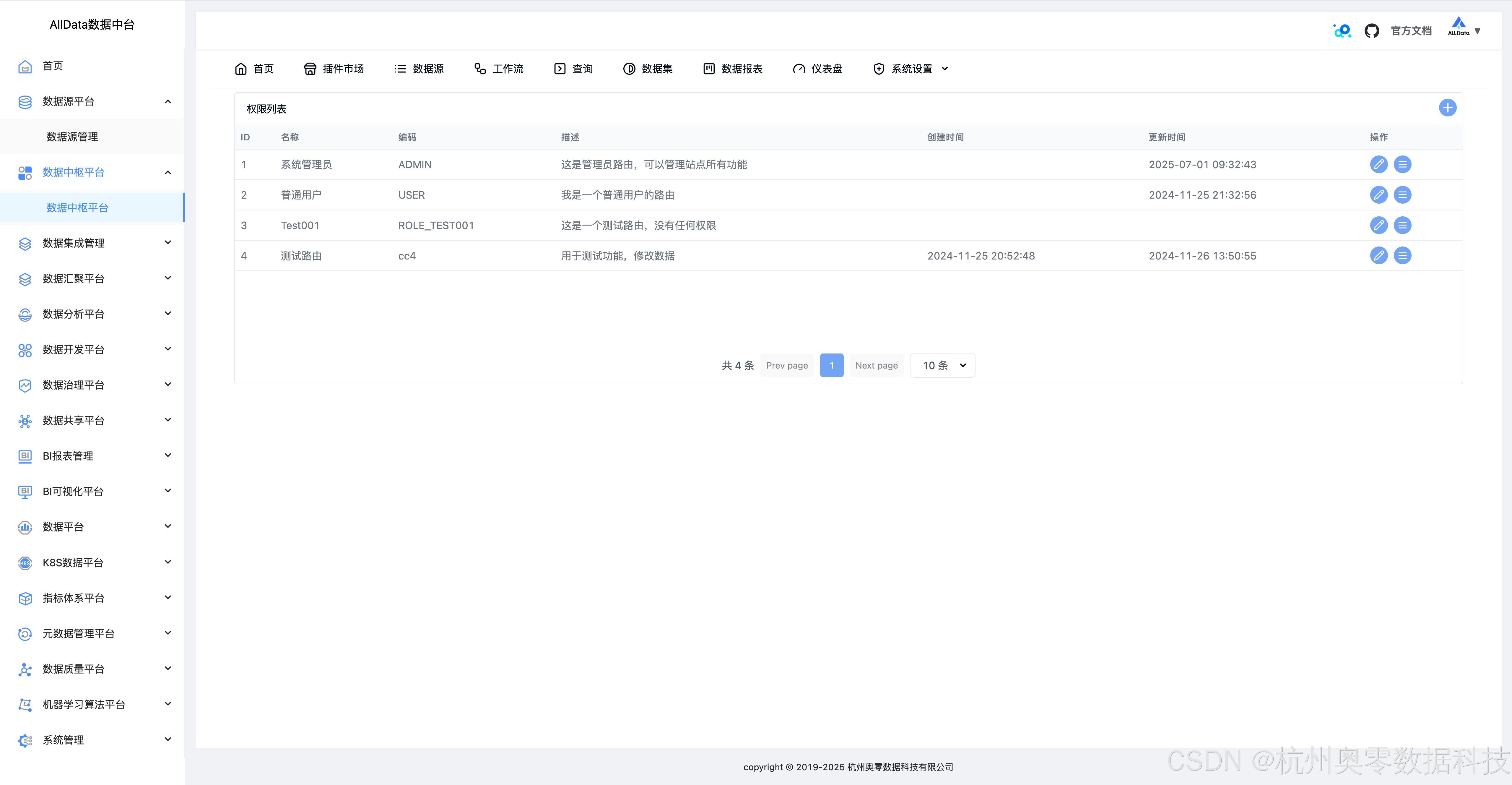
42、创建路由
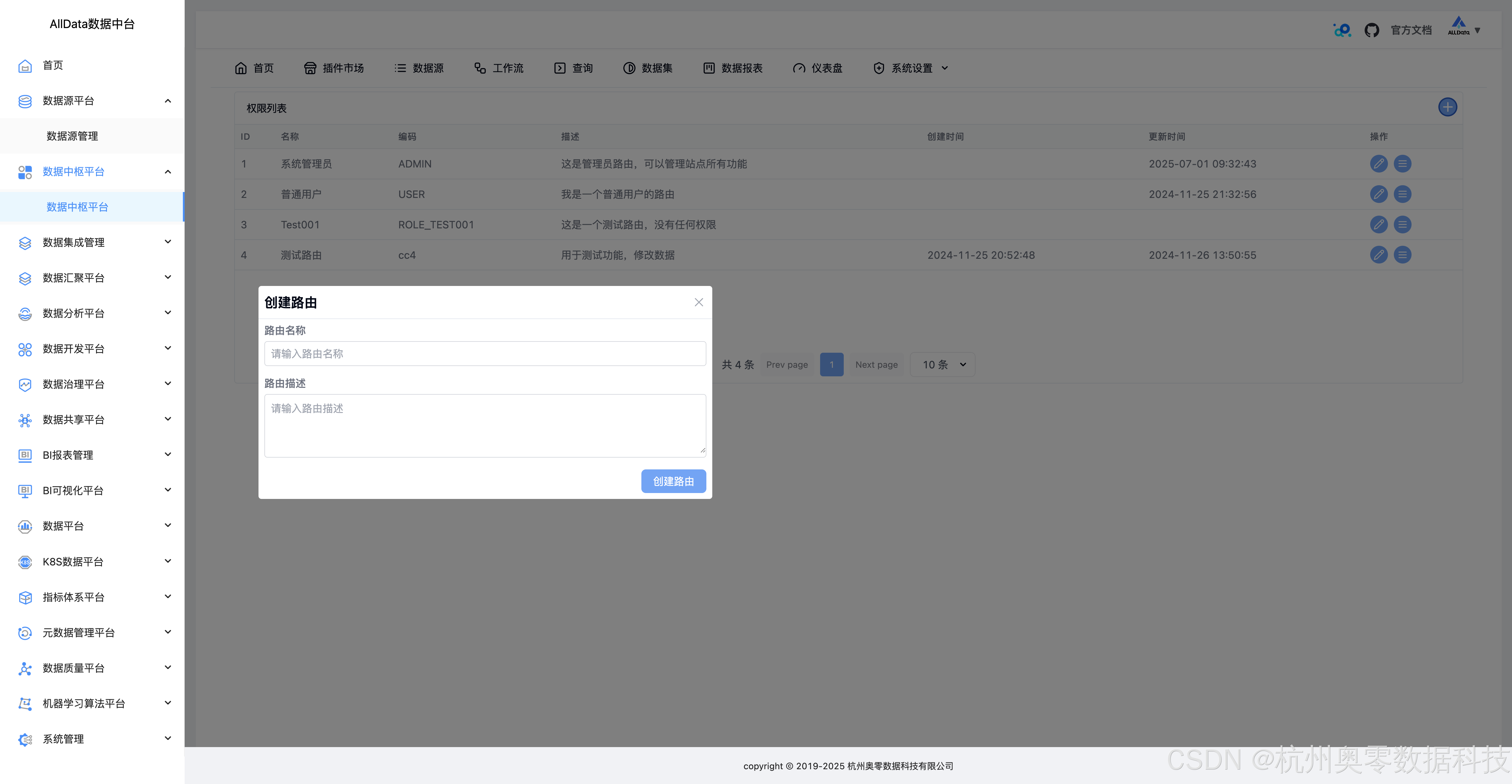
43、分配菜单
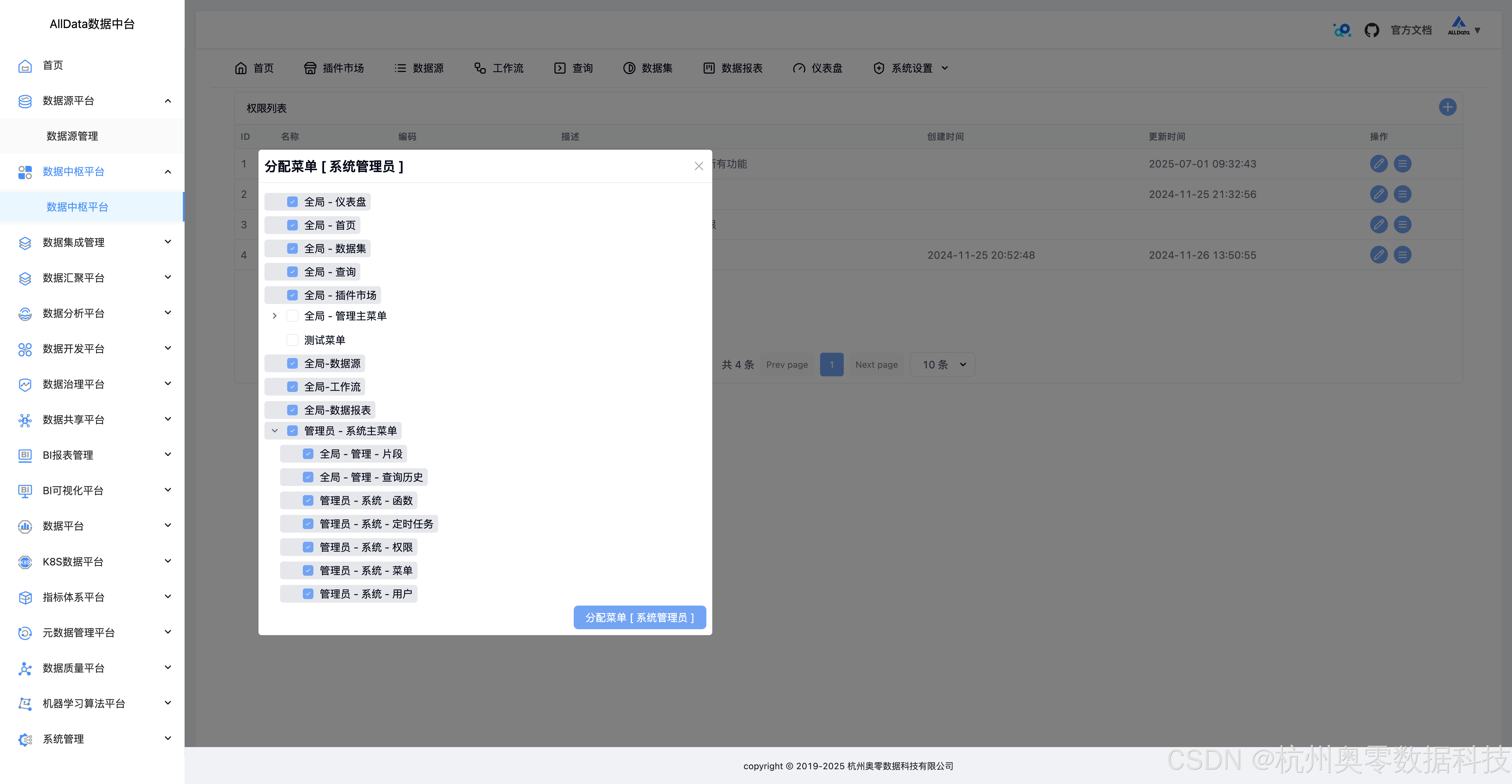
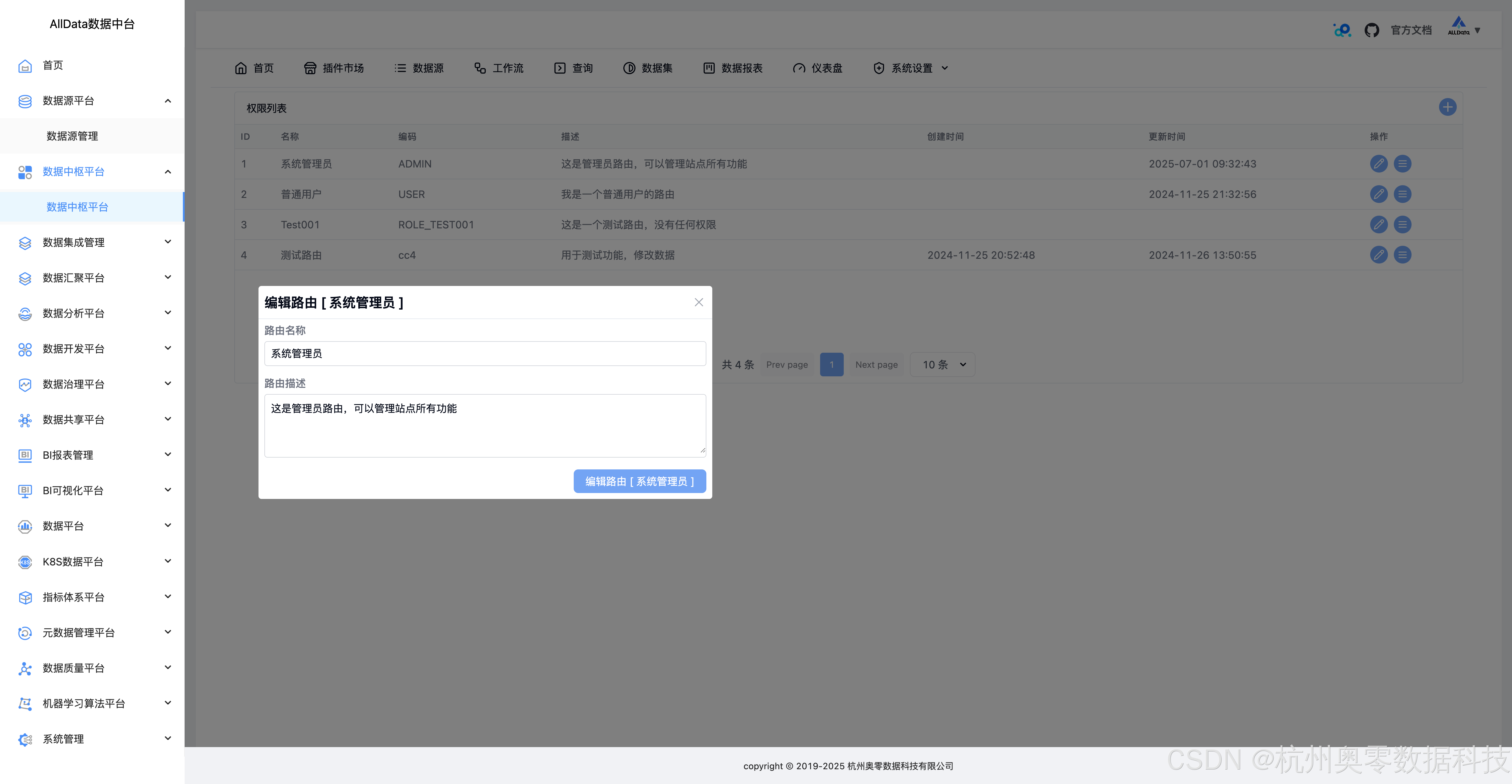
44、编辑路由
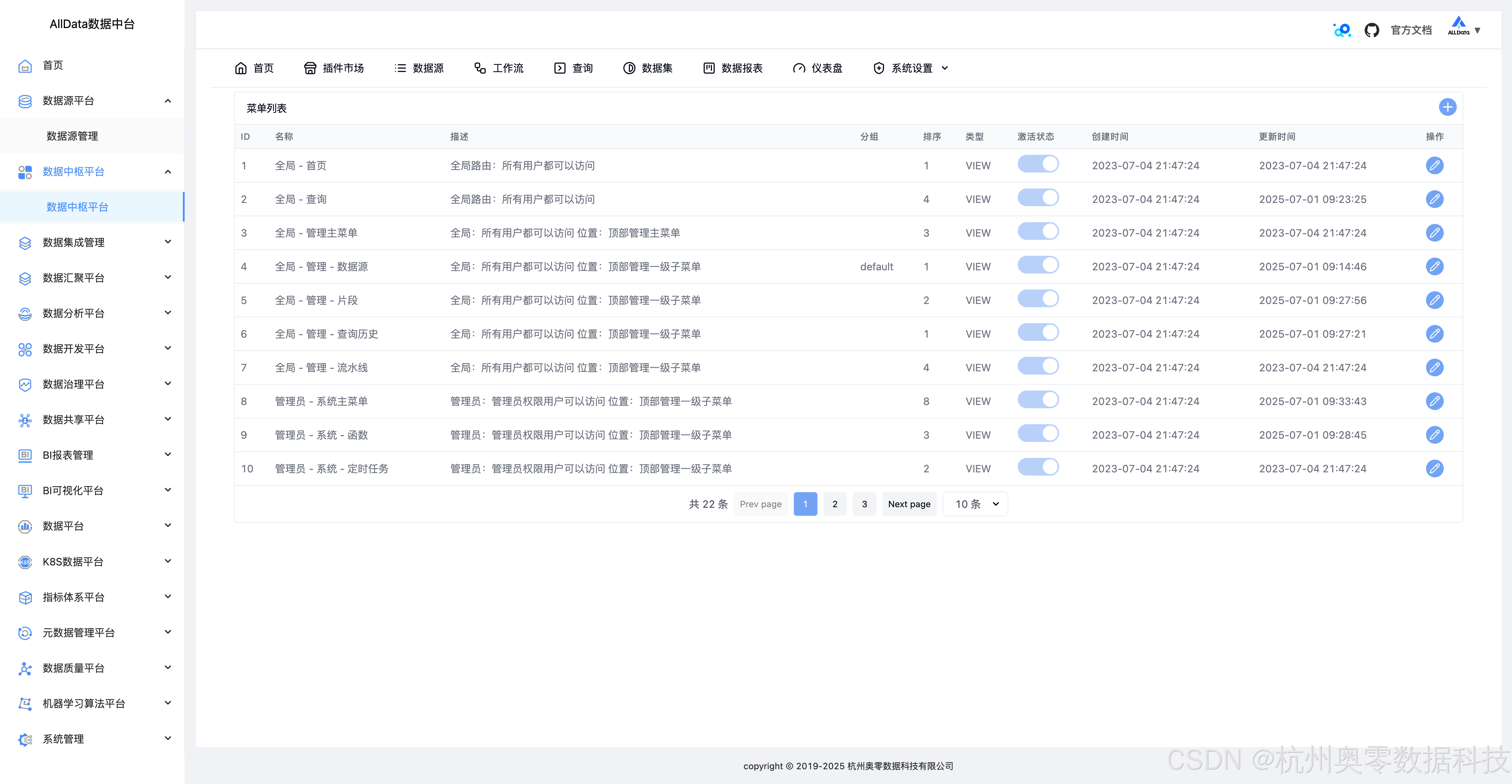
45、系统设置-菜单
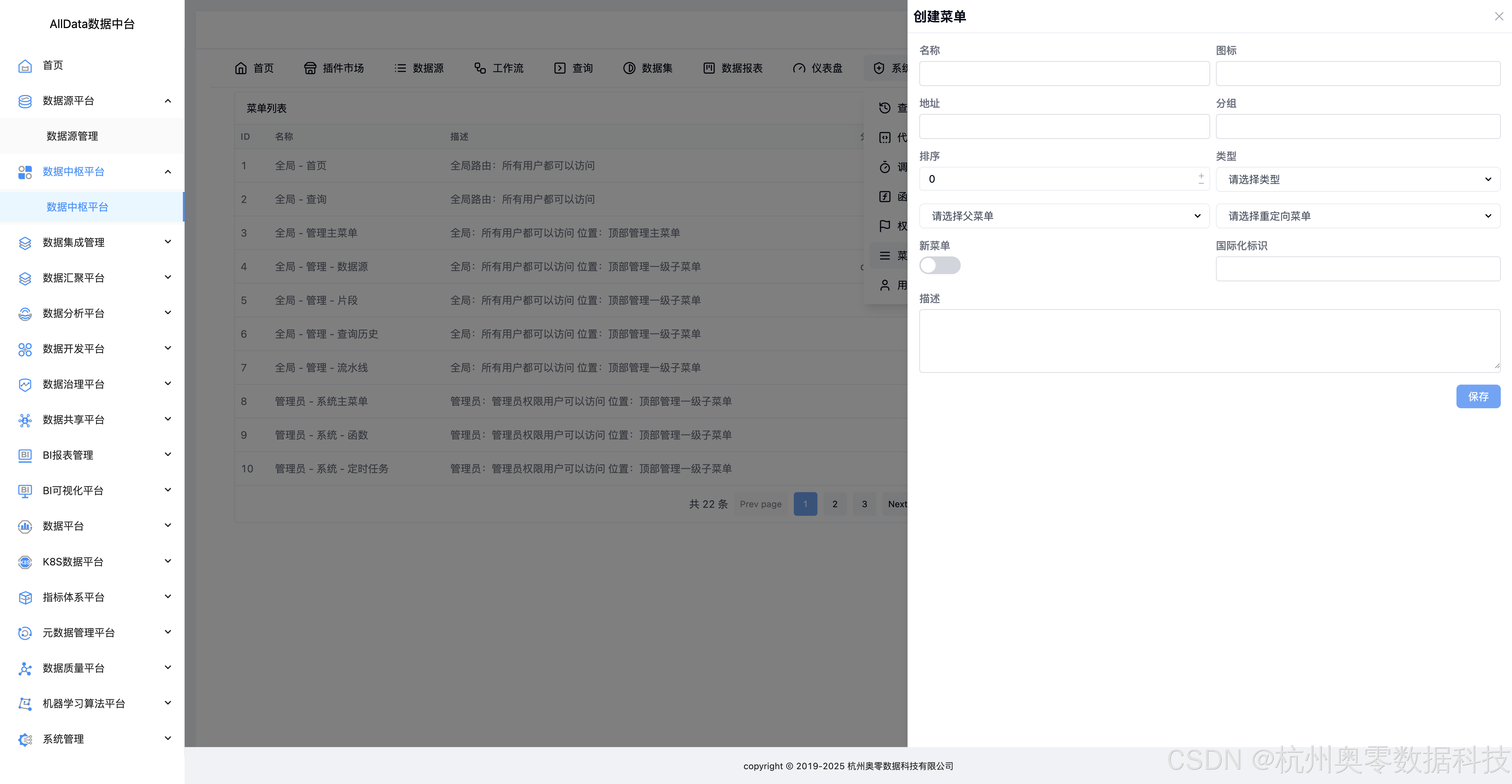
46、创建菜单
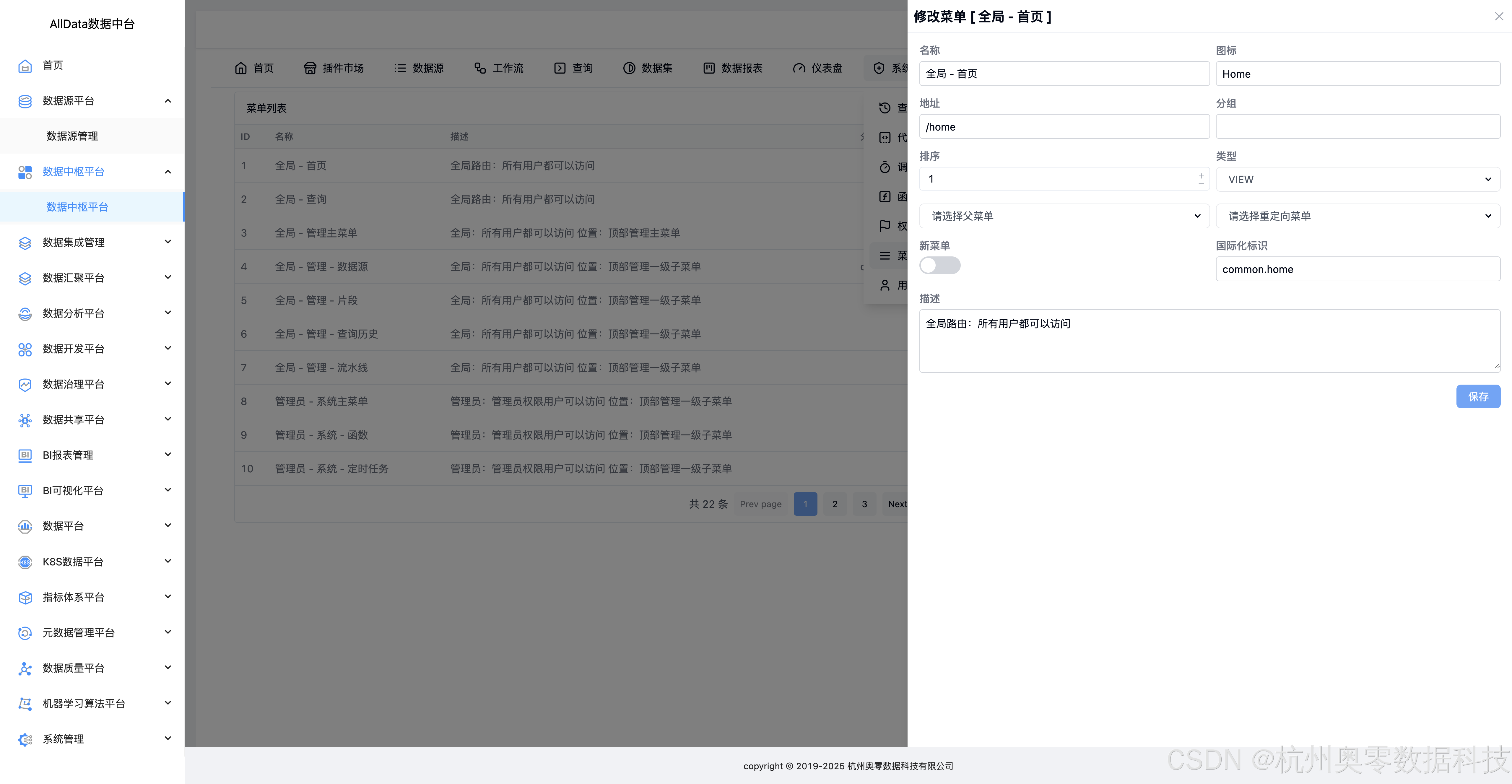
47、修改菜单
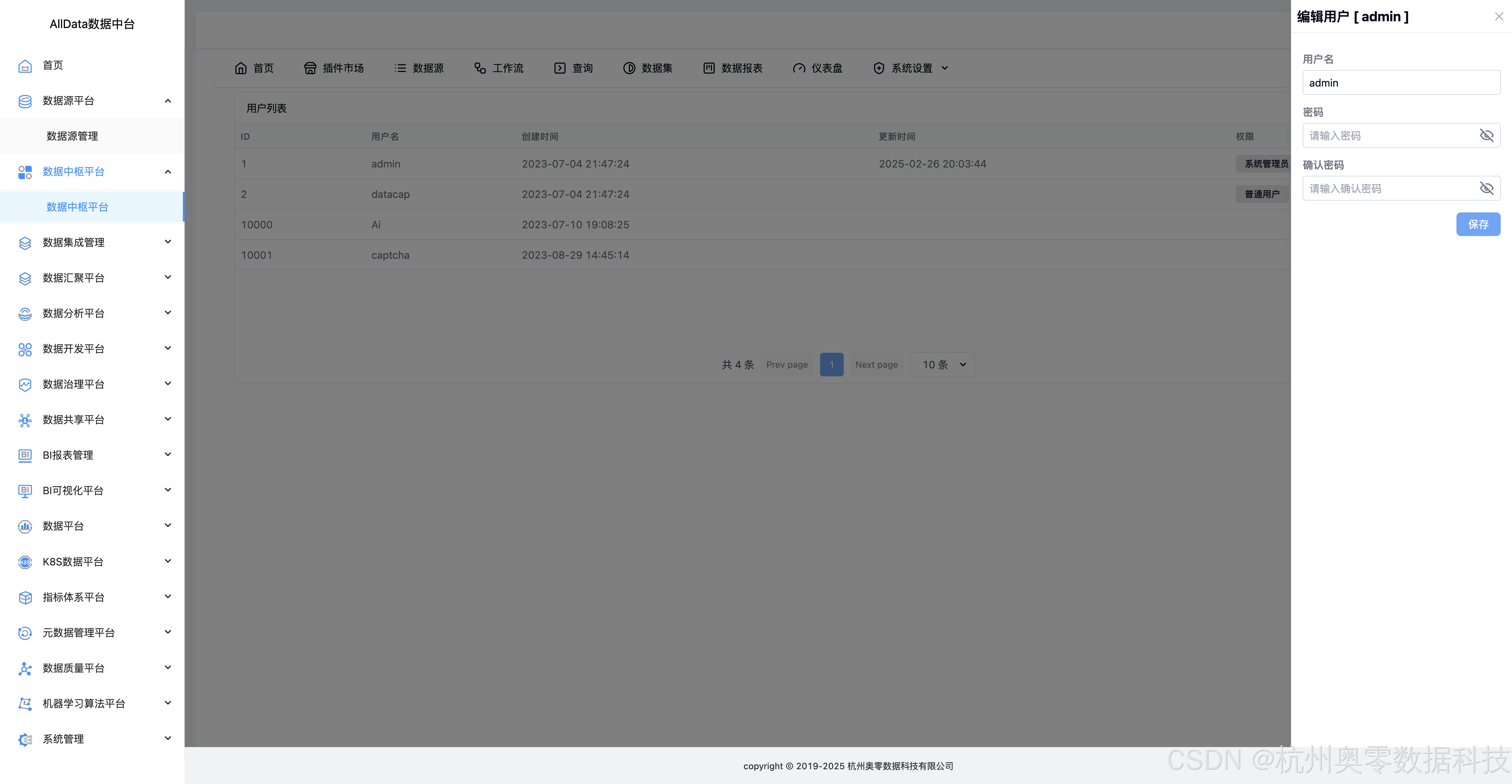
48、系统设置-用户
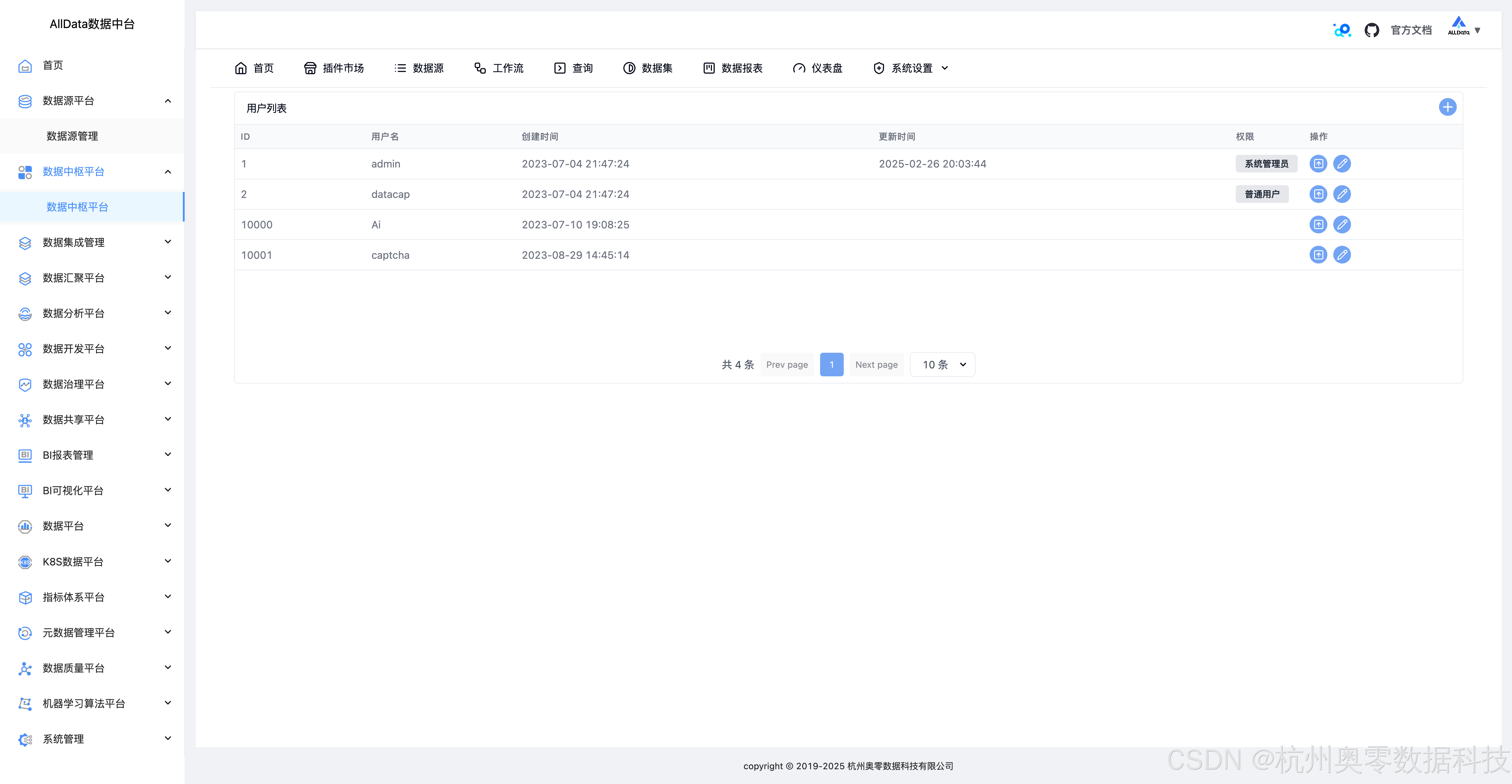
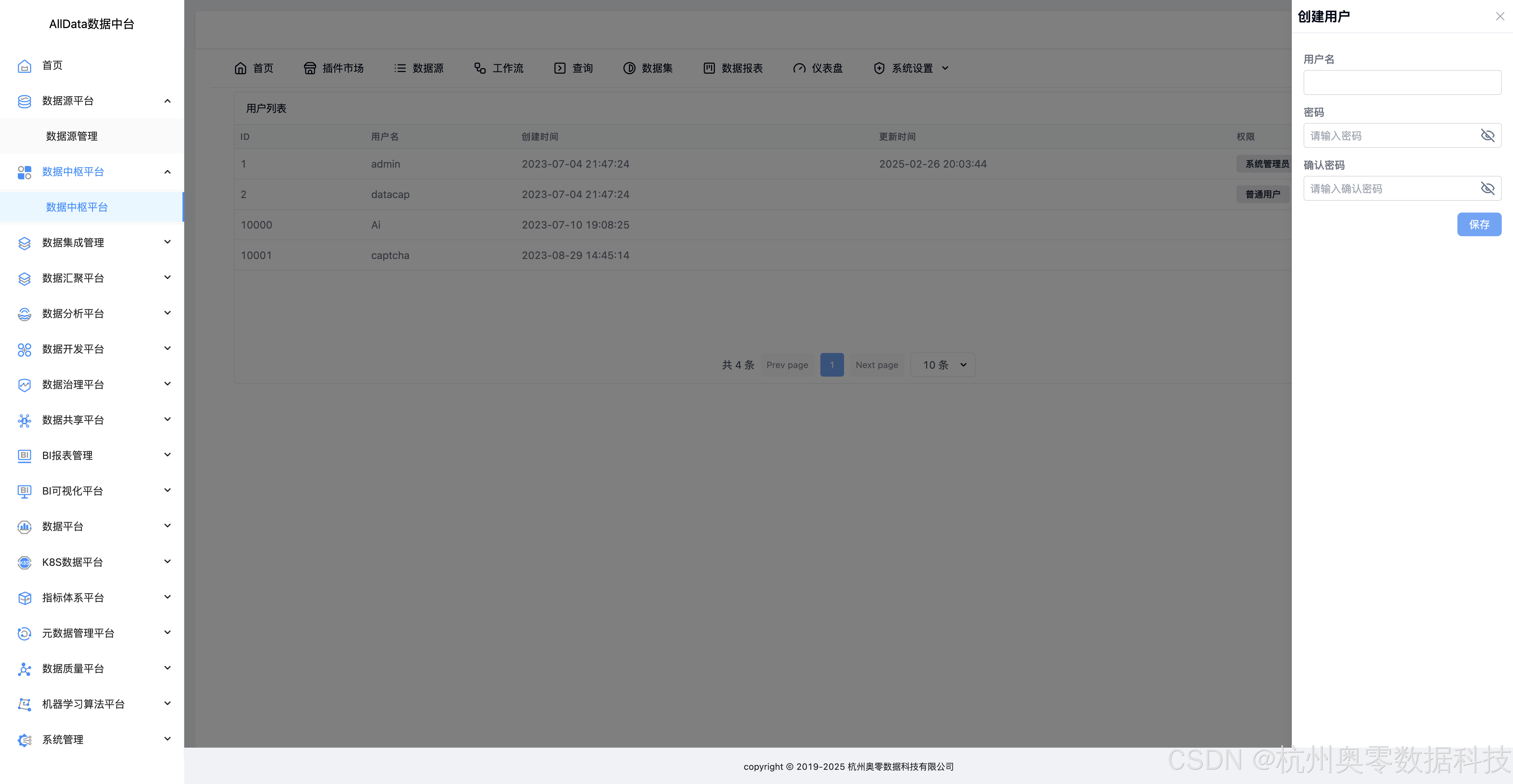
49、创建用户
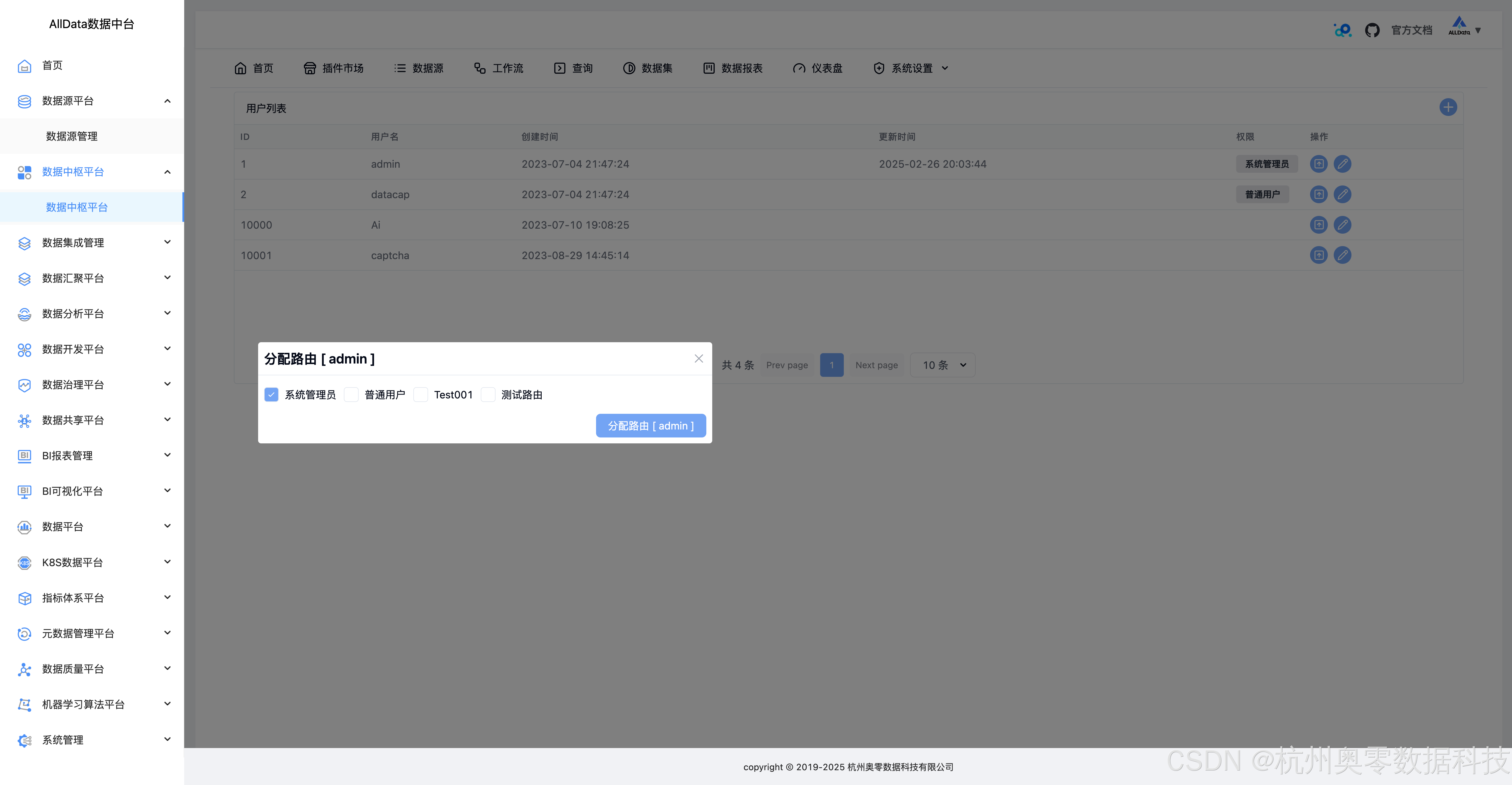
50、分配路由
51、编辑用户