open webui源码分析13-模型管理
在open webui中使用的模型来源很多,可以直连第三方大模型,可以连接ollama使用本地化模型,可以使用本地定制的模型(比如挂接了知识库的模型),可以是本地管道,还可以是流水线,各种模型特征不一,数据结构也有差距,代码中经常要根据模型中的属性执行不同的逻辑,属实让人头疼,本文对open webui中的模型管理进行透彻的分析。
1.持久化存储分析
1.1外部公用大模型
1.1.1获取可用模型列表
在open webui增加外部公用大模型时,在输入大模型的URL和API_KEY之后,先调用第三方大模型的modles接口获取可用大模型(以deepseek为例就是https://api.deepseek.com/models),返回数据如下:
{
"object": "list",
"data": [
{
"id": "deepseek-chat",
"object": "model",
"owned_by": "deepseek"
},
{
"id": "deepseek-reasoner",
"object": "model",
"owned_by": "deepseek"
}
]
}
1.1.2更新open webui系统内大模型数据
更新大模型数据入口地址为:http://{ip:port}/api/v1/users/user/settings/update,请求数据如下:
{
"ui": {
"directConnections": {
"OPENAI_API_BASE_URLS": [
"https://api.deepseek.com"
],
"OPENAI_API_KEYS": [
"sk-46afcc3ac8f341e680344a6942209532"
],
"OPENAI_API_CONFIGS": {
"0": {
"enable": true,
"tags": [],
"prefix_id": "",
"model_ids": [],
"connection_type": "external"
}
}
}}
使用第三方大模型数据更新本地相关数据入口方法为update_user_settings_by_session_user,代码如下:
@router.post("/user/settings/update", response_model=UserSettings)
async def update_user_settings_by_session_user(
request: Request, form_data: UserSettings, user=Depends(get_verified_user)
):
updated_user_settings = form_data.model_dump()
if (#权限检查
user.role != "admin"
and "toolServers" in updated_user_settings.get("ui").keys()
and not has_permission(
user.id,
"features.direct_tool_servers",
request.app.state.config.USER_PERMISSIONS,
)
):
# If the user is not an admin and does not have permission to use tool servers, remove the key
updated_user_settings["ui"].pop("toolServers", None)#用整个更新请求表单数据更新user表的settings字段
user = Users.update_user_settings_by_id(user.id, updated_user_settings)
if user:
return user.settings
else:
raise HTTPException(
status_code=status.HTTP_400_BAD_REQUEST,
detail=ERROR_MESSAGES.USER_NOT_FOUND,
1.1.3结论
公有第三方大模型数据存储在 user表的settings字段中。
1.2.内部定制大模型
内部定制模型是指基于ollama内的基础大模型进行特性定制的模型,比如追加知识库,在open webui源码分析9-知识库-CSDN博客中已经讲过,这类大模型信息保存在model表中,具体结构如下图:
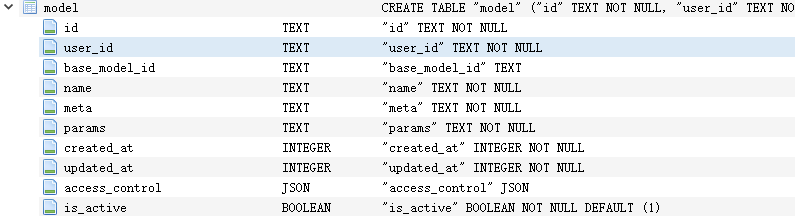
1.3管道
管道作为一种大模型,其信息存储在function表中,具体结构如下图所示:
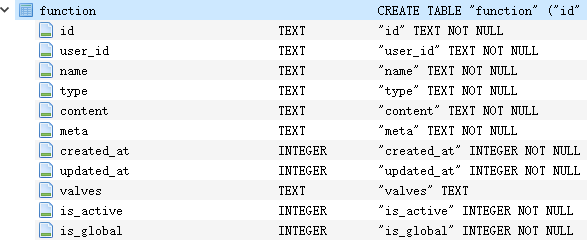
1.4.ollama内大模型
在ollama运行的大模型,其数据并不在open webui后端持久化存储。在open webui运行过程中会请求获取数据。如何获取,后面再分析。
1.5流水线
流水线运行在Pipelines服务中,其数据也不在open webui内持久化存储。在open webui运行过程中会请求获取数据。如何获取,后面再分析。
2.大模型数据加载分析
2.1整体流程
大模型数据加载流程如下图所示:
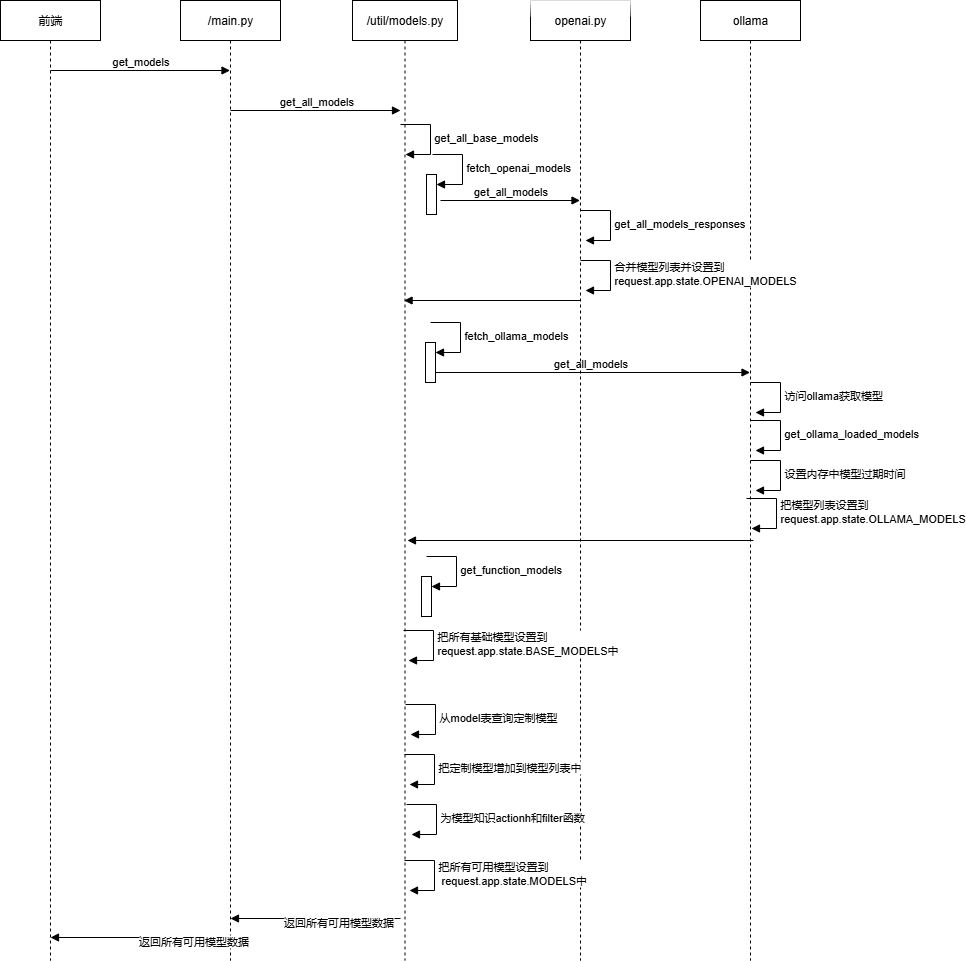
2.2 入口方法
open webui启动过程中并不加载模型数据,前端启动后会从后台请求模型数据。入口为http://{ip:port}/api/models,对应方法为main.py的get_models方法,下面对该方法的代码进行详细分析。
本方法流程如下:
1) 调用get_all_models获取所有的模型,包括ollama模型,openai模型(比如pipeline)和管道函数
2)遍历模型列表
2.1)剔除过滤器类型的pipeline
2.2)为模型设置标签
3)对所有模型按照优先级重排序
4)剔除用户无权访问的模型
@app.get("/api/models")
async def get_models(
request: Request, refresh: bool = False, user=Depends(get_verified_user)
):
def get_filtered_models(models, user):
filtered_models = []
for model in models:
if model.get("arena"):
if has_access(
user.id,
type="read",
access_control=model.get("info", {})
.get("meta", {})
.get("access_control", {}),
):
filtered_models.append(model)
continuemodel_info = Models.get_model_by_id(model["id"])
if model_info:
if user.id == model_info.user_id or has_access(
user.id, type="read", access_control=model_info.access_control
):
filtered_models.append(model)return filtered_models
all_models = await get_all_models(request, refresh=refresh, user=user)
models = []
for model in all_models:
# 如果模型类型为流水线,并且流水线的类型为filter,则剔除不做处理
if "pipeline" in model and model["pipeline"].get("type", None) == "filter":
continuetry:
model_tags = [#从模型的info.meta.tags获取模型标签
tag.get("name")
for tag in model.get("info", {}).get("meta", {}).get("tags", [])
]#从模型tags获取模型标签
tags = [tag.get("name") for tag in model.get("tags", [])]tags = list(set(model_tags + tags))#计算两个标签的并集
model["tags"] = [{"name": tag} for tag in tags] #设置模型tags为并集的结果
except Exception as e:
log.debug(f"Error processing model tags: {e}")
model["tags"] = []
passmodels.append(model)
'''
以下对模型模型列表按照优先级排序,优先级保存在
request.app.state.config.MODEL_ORDER_LIST
'''
model_order_list = request.app.state.config.MODEL_ORDER_LIST
if model_order_list:
model_order_dict = {model_id: i for i, model_id in enumerate(model_order_list)}
# Sort models by order list priority, with fallback for those not in the list
models.sort(
key=lambda x: (model_order_dict.get(x["id"], float("inf")), x["name"])
)# 剔除用户无权访问的模型,仅返回用户有权限使用的所有模型
if user.role == "user" and not BYPASS_MODEL_ACCESS_CONTROL:
models = get_filtered_models(models, user)log.debug(
f"/api/models returned filtered models accessible to the user: {json.dumps([model['id'] for model in models])}"
)
return {"data": models}
下面对以上get_models方法和核心方法get_all_models进行分析,该方法位于utils目录的 models.py文件中,具体如下:
本方法流程如下:
1)首次调用时,调用get_all_base_models方法,并设置全局变量 request.app.state.BASE_MODELS,否则直接使用基础模型
2)把Arena模型增加到模型列表中
3)把定制模型增加到模型列表中
4)遍历模型列表,为模型设置actions和filters
5)把所有的模型数据保存在全局变量request.app.state.MODELS中
6)返回可用模型列表
async def get_all_models(request, refresh: bool = False, user: UserModel = None):
if (
request.app.state.MODELS
and request.app.state.BASE_MODELS
and (request.app.state.config.ENABLE_BASE_MODELS_CACHE and not refresh)
):
base_models = request.app.state.BASE_MODELS
else:
base_models = await get_all_base_models(request, user=user)
request.app.state.BASE_MODELS = base_models# 把基础模型拷贝到models
models = [model.copy() for model in base_models]# 如果没有可用模型直接返回
if len(models) == 0:
return []# 以下为Arena模型处理,暂不分析
if request.app.state.config.ENABLE_EVALUATION_ARENA_MODELS:
arena_models = []
if len(request.app.state.config.EVALUATION_ARENA_MODELS) > 0:
arena_models = [
{
"id": model["id"],
"name": model["name"],
"info": {
"meta": model["meta"],
},
"object": "model",
"created": int(time.time()),
"owned_by": "arena",
"arena": True,
}
for model in request.app.state.config.EVALUATION_ARENA_MODELS
]
else:
# Add default arena model
arena_models = [
{
"id": DEFAULT_ARENA_MODEL["id"],
"name": DEFAULT_ARENA_MODEL["name"],
"info": {
"meta": DEFAULT_ARENA_MODEL["meta"],
},
"object": "model",
"created": int(time.time()),
"owned_by": "arena",
"arena": True,
}
]
models = models + arena_modelsglobal_action_ids = [#从function表查询全局action类型的function
function.id for function in Functions.get_global_action_functions()
]
enabled_action_ids = [#保留状态为激活的action类型的function
function.id
for function in Functions.get_functions_by_type("action", active_only=True)
]global_filter_ids = [#从function查询全局filter类型的function
function.id for function in Functions.get_global_filter_functions()
]
enabled_filter_ids = [#保留状态为激活的过滤器function
function.id
for function in Functions.get_functions_by_type("filter", active_only=True)
]#以下为定制模型处理,包括挂接知识库的模型
custom_models = Models.get_all_models()#从model表查询所有定制模型
for custom_model in custom_models:#如果定制模型的基础模型id为空
if custom_model.base_model_id is None:
for model in models:'''
如果基础模型id与定制模型id相等,或者基础模型是ollama模型并且二者id匹配,
如果定制模型是激活状态,则用定制模型的名字、action_ids和 filter_ids设置基 础模型,否则从基础模型中剔除
'''
if custom_model.id == model["id"] or (
model.get("owned_by") == "ollama"
and custom_model.id
== model["id"].split(":")[
0
] # Ollama may return model ids in different formats (e.g., 'llama3' vs. 'llama3:7b')
):
if custom_model.is_active:
model["name"] = custom_model.name
model["info"] = custom_model.model_dump()# Set action_ids and filter_ids
action_ids = []
filter_ids = []if "info" in model and "meta" in model["info"]:
action_ids.extend(
model["info"]["meta"].get("actionIds", [])
)
filter_ids.extend(
model["info"]["meta"].get("filterIds", [])
)model["action_ids"] = action_ids
model["filter_ids"] = filter_ids
else: #从models中剔除未激活的模型
models.remove(model)elif custom_model.is_active and (
custom_model.id not in [model["id"] for model in models]
):#如果定制模型为激活状态,并且该模型的id在基础模型中找不到
owned_by = "openai"
pipe = Noneaction_ids = []
filter_ids = []for model in models:#遍历模型,找到与定制模型 base_model_id匹配的模型
if (
custom_model.base_model_id == model["id"]
or custom_model.base_model_id == model["id"].split(":")[0]
):
owned_by = model.get("owned_by", "unknown owner")
if "pipe" in model:
pipe = model["pipe"]
break#从定制模型的meta中提取actionIds和filterIds,并分别追加到action_ids和 filter_ids
if custom_model.meta:
meta = custom_model.meta.model_dump()if "actionIds" in meta:
action_ids.extend(meta["actionIds"])if "filterIds" in meta:
filter_ids.extend(meta["filterIds"])models.append(
{#把定制模型增加到models列表中
"id": f"{custom_model.id}",
"name": custom_model.name,
"object": "model",
"created": custom_model.created_at,
"owned_by": owned_by,
"info": custom_model.model_dump(),
"preset": True,
**({"pipe": pipe} if pipe is not None else {}),
"action_ids": action_ids,
"filter_ids": filter_ids,
}
)# Process action_ids to get the actions
def get_action_items_from_module(function, module):
actions = []
if hasattr(module, "actions"):
actions = module.actions
return [
{
"id": f"{function.id}.{action['id']}",
"name": action.get("name", f"{function.name} ({action['id']})"),
"description": function.meta.description,
"icon": action.get(
"icon_url",
function.meta.manifest.get("icon_url", None)
or getattr(module, "icon_url", None)
or getattr(module, "icon", None),
),
}
for action in actions
]
else:
return [
{
"id": function.id,
"name": function.name,
"description": function.meta.description,
"icon": function.meta.manifest.get("icon_url", None)
or getattr(module, "icon_url", None)
or getattr(module, "icon", None),
}
]# Process filter_ids to get the filters
def get_filter_items_from_module(function, module):
return [
{
"id": function.id,
"name": function.name,
"description": function.meta.description,
"icon": function.meta.manifest.get("icon_url", None)
or getattr(module, "icon_url", None)
or getattr(module, "icon", None),
}
]def get_function_module_by_id(function_id):
function_module, _, _ = get_function_module_from_cache(request, function_id)
return function_modulefor model in models:#遍历模型列表,为模型设置actions和filters
action_ids = [#从模型自带的action与全局action中抽取出被启用的
action_id
for action_id in list(set(model.pop("action_ids", []) + global_action_ids))
if action_id in enabled_action_ids
]
filter_ids = [#从模型自带的filter与全局action中抽取出被启用的
filter_id
for filter_id in list(set(model.pop("filter_ids", []) + global_filter_ids))
if filter_id in enabled_filter_ids
]model["actions"] = []
#把action_ids中的所有action的模块信息{action_function, function_module}增加到模型的actions列表中
for action_id in action_ids:
action_function = Functions.get_function_by_id(action_id)
if action_function is None:
raise Exception(f"Action not found: {action_id}")function_module = get_function_module_by_id(action_id)
model["actions"].extend(
get_action_items_from_module(action_function, function_module)
)model["filters"] = []
#把action_ids中的所有action的模块信息{filter_function, filter_module}增加到模型的filters列表中
for filter_id in filter_ids:
filter_function = Functions.get_function_by_id(filter_id)
if filter_function is None:
raise Exception(f"Filter not found: {filter_id}")function_module = get_function_module_by_id(filter_id)
if getattr(function_module, "toggle", None):
model["filters"].extend(
get_filter_items_from_module(filter_function, function_module)
)log.debug(f"get_all_models() returned {len(models)} models")
#把所有的模型数据赋值给全局变量request.app.state.MODELS
request.app.state.MODELS = {model["id"]: model for model in models}
return models #返回所有的模型
def check_model_access(user, model):
if model.get("arena"):
if not has_access(
user.id,
type="read",
access_control=model.get("info", {})
.get("meta", {})
.get("access_control", {}),
):
raise Exception("Model not found")
else:
model_info = Models.get_model_by_id(model.get("id"))
if not model_info:
raise Exception("Model not found")
elif not (
user.id == model_info.user_id
or has_access(
user.id, type="read", access_control=model_info.access_control
)
):
raise Exception("Model not found")
get_all_base_models方法用户获取所有的基础模型,包括ollama内的模型,pipeline和管道。
该方法三个异步任务,分别从Pipelines服务和ollama服务中获取模型列表,然后再从本地获取管道类型的函数列表,汇总后返回。
async def get_all_base_models(request: Request, user: UserModel = None):
openai_task = (#从Pipelines服务获取模型
fetch_openai_models(request, user)
if request.app.state.config.ENABLE_OPENAI_API
else asyncio.sleep(0, result=[])
)
ollama_task = (#从ollama获取模型
fetch_ollama_models(request, user)
if request.app.state.config.ENABLE_OLLAMA_API
else asyncio.sleep(0, result=[])
)
function_task = get_function_models(request) #获取本地管道类型函数列表#异步执行三个任务
openai_models, ollama_models, function_models = await asyncio.gather(
openai_task, ollama_task, function_task
)return function_models + openai_models + ollama_models
2.3从Pipelines拉取数据
fetch_openai_models负责从Pipelines服务获取模型,调用openai模块的get_all_models,具体代码如下:
async def fetch_openai_models(request: Request, user: UserModel = None):
openai_response = await openai.get_all_models(request, user=user)
return openai_response["data"]
下面对openai模块get_all_models进行分析,具体代码如下:
@cached(ttl=MODELS_CACHE_TTL)
async def get_all_models(request: Request, user: UserModel) -> dict[str, list]:
log.info("get_all_models()")'''
在open webui源码分析12-Pipeline-CSDN博客中,增加连接时设置了
ENABLE_OPENAI_API
'''
if not request.app.state.config.ENABLE_OPENAI_API:
return {"data": []}responses = await get_all_models_responses(request, user=user)
def extract_data(response):
if response and "data" in response:
return response["data"]
if isinstance(response, list):
return response
return None#该方法是内嵌方法,把从所有open ai服务获取的模型合并成一个列表
def merge_models_lists(model_lists):
log.debug(f"merge_models_lists {model_lists}")
merged_list = []for idx, models in enumerate(model_lists):
if models is not None and "error" not in models:merged_list.extend(
[
{#存在同名kv时,后面的覆盖前面的
**model,
"name": model.get("name", model["id"]),
"owned_by": "openai",
"openai": model,#新增加的
"connection_type": model.get("connection_type", "external"),
"urlIdx": idx,
}
for model in models
if (model.get("id") or model.get("name"))
and (
"api.openai.com"
not in request.app.state.config.OPENAI_API_BASE_URLS[idx]
or not any(
name in model["id"]
for name in [
"babbage",
"dall-e",
"davinci",
"embedding",
"tts",
"whisper",
]
)
)
]
)return merged_list
#调用merge_models_lists对所有来源的模型进行合并
models = {"data": merge_models_lists(map(extract_data, responses))}
log.debug(f"models: {models}")'''
此时models数据如下:
{
"data": [
{
"id": "example_pipeline_scaffold",
"name": "Pipeline Example",
"object": "model",
"created": 1756518781,
"owned_by": "openai",
"pipeline": {
"type": "pipe",
"valves": false
},
"connection_type": "external",
"openai": {
"id": "example_pipeline_scaffold",
"name": "Pipeline Example",
"object": "model",
"created": 1756518781,
"owned_by": "openai",
"pipeline": {
"type": "pipe",
"valves": false
},
"connection_type": "external"
},
"urlIdx": 0
}
]
}重要:针对本类型的模型connection_type为external,owned_by是openai
'''
#把models设置到request.app.state.OPENAI_MODELS中
request.app.state.OPENAI_MODELS = {model["id"]: model for model in models["data"]}
return models
下面对关键方法get_all_modles_responses方法进行分析,具体代码如下:
async def get_all_models_responses(request: Request, user: UserModel) -> list:
if not request.app.state.config.ENABLE_OPENAI_API:
return []#处理API_URL和API_KEY长度不匹配参见open webui源码分析12-Pipeline-CSDN博客
num_urls = len(request.app.state.config.OPENAI_API_BASE_URLS)
num_keys = len(request.app.state.config.OPENAI_API_KEYS)if num_keys != num_urls:
# if there are more keys than urls, remove the extra keys
if num_keys > num_urls:
new_keys = request.app.state.config.OPENAI_API_KEYS[:num_urls]
request.app.state.config.OPENAI_API_KEYS = new_keys
# if there are more urls than keys, add empty keys
else:
request.app.state.config.OPENAI_API_KEYS += [""] * (num_urls - num_keys)
request_tasks = []
'''
遍历所有的连接,请求模型列表。
结合以下数据看代码更容易,这些数据存储在 request.app.state.config中。
________________________________________________________________
{
"OPENAI_API_BASE_URLS": [
"http://localhost:9099" #运行的Pipelines服务地址
],
"OPENAI_API_KEYS": [
"0p3n-w3bu!" #Pipelines服务访问密钥
],
"OPENAI_API_CONFIGS": { #配置信息
"0": {
"enable": true,
"tags": [],
"prefix_id": "",
"model_ids": [], #指定一个连接中模型的子集,为空是相当于全部模型
"connection_type": "external"
}
}
}————————————————————————————————————
'''
for idx, url in enumerate(request.app.state.config.OPENAI_API_BASE_URLS):
if (str(idx) not in request.app.state.config.OPENAI_API_CONFIGS) and (
url not in request.app.state.config.OPENAI_API_CONFIGS # Legacy support
):#不须关注
request_tasks.append(
send_get_request(
f"{url}/models",
request.app.state.config.OPENAI_API_KEYS[idx],
user=user,
)
)
else:#python语法糖,如果在OPENAI_API_CONFIGS没有idx,则使用'url',否则为空
api_config = request.app.state.config.OPENAI_API_CONFIGS.get(
str(idx),
request.app.state.config.OPENAI_API_CONFIGS.get(
url, {}
), # Legacy support
)enable = api_config.get("enable", True)
model_ids = api_config.get("model_ids", [])if enable: #针对被启用的配置
'''
如果model_ids为空创建一个异步任务,向指定的服务,比如Pipelines请求模型
列表。如果model_ids为空,则直接调用服务的对应接口。否则直接组织
model_list
'''
if len(model_ids) == 0:
request_tasks.append(
send_get_request(
f"{url}/models",
request.app.state.config.OPENAI_API_KEYS[idx],
user=user,
)
)
else:
model_list = {
"object": "list",
"data": [
{
"id": model_id,
"name": model_id,
"owned_by": "openai",
"openai": {"id": model_id},
"urlIdx": idx,
}
for model_id in model_ids
],
}request_tasks.append(#生成一个future,直接返回model_list
asyncio.ensure_future(asyncio.sleep(0, model_list))
)
else:#如果没有被启用,则创建一个什么都不做的future,增加到 request_tasks中
request_tasks.append(asyncio.ensure_future(asyncio.sleep(0, None)))responses = await asyncio.gather(*request_tasks)#异步执行所有任务
'''
调用Pipelines返回的数据如下,对照理解下面代码。
{
"data": [
{
"id": "example_pipeline_scaffold",
"name": "Pipeline Example",
"object": "model",
"created": 1756459482,
"owned_by": "openai",
"pipeline": {
"type": "pipe",
"valves": false
}
}
],
"object": "list",
"pipelines": true
}'''
for idx, response in enumerate(responses):
if response:
url = request.app.state.config.OPENAI_API_BASE_URLS[idx]
api_config = request.app.state.config.OPENAI_API_CONFIGS.get(
str(idx),
request.app.state.config.OPENAI_API_CONFIGS.get(
url, {}
), # Legacy support
)connection_type = api_config.get("connection_type", "external")
prefix_id = api_config.get("prefix_id", None)
tags = api_config.get("tags", [])for model in (
response if isinstance(response, list) else response.get("data", [])
):
if prefix_id:#如果配置中有prefix_id则在模型id前拼接prefix_id
model["id"] = f"{prefix_id}.{model['id']}"if tags: #如果配置中的tags不为空,则设置modes的标签
model["tags"] = tagsif connection_type:#设置模型的连接类型
model["connection_type"] = connection_typelog.debug(f"get_all_models:responses() {responses}")
'''
返回的responses数据如下:
{
"data": [
{
"id": "example_pipeline_scaffold",
"name": "Pipeline Example",
"object": "model",
"created": 1756518781,
"owned_by": "openai",
"pipeline": {
"type": "pipe",
"valves": false
},
"connection_type": "external"
}
],
"object": "list",
"pipelines": true
}'''
return responses
完成Pipelines数据拉取后,一方面在request.app.state.OPENAI_MODELS设置了所有的模型(形式为{model_id:model,……}),另一方面返回所有数据给上层。
2.4从ollama拉取数据
fetch_ollama_models从ollama请求可用模型列表,具体代码如下:
该方法很简单,主要逻辑看ollama.get_all_models
async def fetch_ollama_models(request: Request, user: UserModel = None):
raw_ollama_models = await ollama.get_all_models(request, user=user)
return [
{
"id": model["model"],
"name": model["name"],
"object": "model",
"created": int(time.time()),
"owned_by": "ollama",
"ollama": model,
"connection_type": model.get("connection_type", "local"),
"tags": model.get("tags", []),
}
for model in raw_ollama_models["models"]
]
下面对ollama模块的get_all_modles方法进行分析:
@cached(ttl=MODELS_CACHE_TTL)
async def get_all_models(request: Request, user: UserModel = None):
log.info("get_all_models()")
if request.app.state.config.ENABLE_OLLAMA_API:
request_tasks = []'''
遍历所有的连接,请求模型列表。
结合以下数据看代码更容易,这些数据存储在 request.app.state.config中。
________________________________________________________________
{
"OLLAMA_BASE_URLS": [
"http://localhost:11434" #运行的ollama服务地址
],
"OLLAMA_API_CONFIGS": { #配置信息
"0": {
"enable": true,
"tags": [],
"prefix_id": "",
"model_ids": [], #指定一个ollama模型的子集,为空是相当于全部模型
"connection_type": "external"
}
}
}————————————————————————————————————
'''
for idx, url in enumerate(request.app.state.config.OLLAMA_BASE_URLS):
if (str(idx) not in request.app.state.config.OLLAMA_API_CONFIGS) and (
url not in request.app.state.config.OLLAMA_API_CONFIGS # Legacy support
):#关注这个分支。创建一个异步任务从ollama获取可用模型
request_tasks.append(send_get_request(f"{url}/api/tags", user=user))
else:
api_config = request.app.state.config.OLLAMA_API_CONFIGS.get(
str(idx),
request.app.state.config.OLLAMA_API_CONFIGS.get(
url, {}
), # Legacy support
)enable = api_config.get("enable", True)
key = api_config.get("key", None)if enable:
request_tasks.append(
send_get_request(f"{url}/api/tags", key, user=user)
)
else:
request_tasks.append(asyncio.ensure_future(asyncio.sleep(0, None)))responses = await asyncio.gather(*request_tasks)#运行异步任务并收集应答
for idx, response in enumerate(responses):#对照下面调用ollama返回的数据
if response:
url = request.app.state.config.OLLAMA_BASE_URLS[idx]
api_config = request.app.state.config.OLLAMA_API_CONFIGS.get(
str(idx),
request.app.state.config.OLLAMA_API_CONFIGS.get(
url, {}
), # Legacy support
)connection_type = api_config.get("connection_type", "local")
prefix_id = api_config.get("prefix_id", None)
tags = api_config.get("tags", [])
model_ids = api_config.get("model_ids", [])#如果在ollama配置中设置了模型列表,则剔除modle_ids列表之外的模型
if len(model_ids) != 0 and "models" in response:
response["models"] = list(
filter(
lambda model: model["model"] in model_ids,
response["models"],
)
)for model in response.get("models", []):
if prefix_id:#设置前缀
model["model"] = f"{prefix_id}.{model['model']}"if tags:#设置标签
model["tags"] = tagsif connection_type:#设置连接类型为local
model["connection_type"] = connection_type#调用merge_ollama_models_lists把多个ollama服务器获取的模型列表合并
models = {
"models": merge_ollama_models_lists(
map(
lambda response: response.get("models", []) if response else None,
responses,
)
)
}try:
'''
查询ollama已经加载的模型列表,此处调用的get_ollama_loaded_models方法,逻
辑与前面的请求ollama服务器返回模型列表相同,只不过请求地址不同,请求
ollama服务器获取模型地址为{ollama_url}/api/tags,获取已加载模型地址为
{ollama_url}/api/ps,所以对get_ollama_loaded_models代码不再做分析
'''
loaded_models = await get_ollama_loaded_models(request, user=user)
expires_map = { #把已加载的模型的超时时间写入expires_map中
m["name"]: m["expires_at"]
for m in loaded_models["models"]
if "expires_at" in m
}'''
针对前面从所有ollama服务获取的所有模型,根据如果已经加载并且有超时时间,
则设置模型的超时时间
'''
for m in models["models"]:
if m["name"] in expires_map:
# Parse ISO8601 datetime with offset, get unix timestamp as int
dt = datetime.fromisoformat(expires_map[m["name"]])
m["expires_at"] = int(dt.timestamp())
except Exception as e:
log.debug(f"Failed to get loaded models: {e}")else: #如果未启用ollama,设置models为[]
models = {"models": []}#把models设置到request.app.state..OLLAMA_MODELS中,形式为{model_id:model}
request.app.state.OLLAMA_MODELS = {
model["model"]: model for model in models["models"]
}
return models
open webui调用{ollama_url}/api/tags接口,返回的应答数据如下。
{
"models": [
{
"name": "qwen3:1.7b",
"model": "qwen3:1.7b",
"modified_at": "2025-08-20T03:50:50.085066919Z",
"size": 1359293444,
"digest": "8f68893c685c3ddff2aa3fffce2aa60a30bb2da65ca488b61fff134a4d1730e7",
"details": {
"parent_model": "",
"format": "gguf",
"family": "qwen3",
"families": [
"qwen3"
],
"parameter_size": "2.0B",
"quantization_level": "Q4_K_M"
}
},
{
"name": "qwen:0.5b",
"model": "qwen:0.5b",
"modified_at": "2025-08-17T05:40:18.859598053Z",
"size": 394998579,
"digest": "b5dc5e784f2a3ee1582373093acf69a2f4e2ac1710b253a001712b86a61f88bb",
"details": {
"parent_model": "",
"format": "gguf",
"family": "qwen2",
"families": [
"qwen2"
],
"parameter_size": "620M",
"quantization_level": "Q4_0"
}
}
]
}
2.5获取本地管道
get_function_models方法用于获取所有的管道,具体代码如下:
async def get_function_models(request):
#从数据库function表查询被激活的管道
pipes = Functions.get_functions_by_type("pipe", active_only=True)
pipe_models = []for pipe in pipes:
function_module = get_function_module_by_id(request, pipe.id)if hasattr(function_module, "pipes"):#多层管道处理
sub_pipes = []#得到所有的子管道
try:
if callable(function_module.pipes):
if asyncio.iscoroutinefunction(function_module.pipes):
sub_pipes = await function_module.pipes()
else:
sub_pipes = function_module.pipes()
else:
sub_pipes = function_module.pipes
except Exception as e:
log.exception(e)
sub_pipes = []log.debug(
f"get_function_models: function '{pipe.id}' is a manifold of {sub_pipes}"
)for p in sub_pipes:#针对每个子管道,设置为与模型一致的数据结构
sub_pipe_id = f'{pipe.id}.{p["id"]}'
sub_pipe_name = p["name"]if hasattr(function_module, "name"):
sub_pipe_name = f"{function_module.name}{sub_pipe_name}"pipe_flag = {"type": pipe.type}
pipe_models.append(
{
"id": sub_pipe_id,
"name": sub_pipe_name,
"object": "model",
"created": pipe.created_at,
"owned_by": "openai",
"pipe": pipe_flag,
}
)
else:#单层管道
pipe_flag = {"type": "pipe"}log.debug(
f"get_function_models: function '{pipe.id}' is a single pipe {{ 'id': {pipe.id}, 'name': {pipe.name} }}"
)pipe_models.append(
{
"id": pipe.id,
"name": pipe.name,
"object": "model",
"created": pipe.created_at,
"owned_by": "openai",
"pipe": pipe_flag,
}
)return pipe_models
2.6模型数据
经过以上处理后,返回前端数据如下:
{
"data": [
{
"id": "example_pipeline_scaffold",
"name": "Pipeline Example",
"object": "model",
"created": 1756555949,
"owned_by": "openai",
"pipeline": {
"type": "pipe",
"valves": false
},
"connection_type": "external",
"openai": {
"id": "example_pipeline_scaffold",
"name": "Pipeline Example",
"object": "model",
"created": 1756555949,
"owned_by": "openai",
"pipeline": {
"type": "pipe",
"valves": false
},
"connection_type": "external"
},
"urlIdx": 0,
"actions": [],
"filters": [],
"tags": []
},
{
"id": "qwen3:1.7b",
"name": "qwen3:1.7b",
"object": "model",
"created": 1756555949,
"owned_by": "ollama",
"ollama": {
"name": "qwen3:1.7b",
"model": "qwen3:1.7b",
"modified_at": "2025-08-20T03:50:50.085066919Z",
"size": 1359293444,
"digest": "8f68893c685c3ddff2aa3fffce2aa60a30bb2da65ca488b61fff134a4d1730e7",
"details": {
"parent_model": "",
"format": "gguf",
"family": "qwen3",
"families": [
"qwen3"
],
"parameter_size": "2.0B",
"quantization_level": "Q4_K_M"
},
"connection_type": "local",
"urls": [
0
]
},
"connection_type": "local",
"tags": [],
"actions": [],
"filters": []
},
{
"id": "qwen:0.5b",
"name": "qwen:0.5b",
"object": "model",
"created": 1756555949,
"owned_by": "ollama",
"ollama": {
"name": "qwen:0.5b",
"model": "qwen:0.5b",
"modified_at": "2025-08-17T05:40:18.859598053Z",
"size": 394998579,
"digest": "b5dc5e784f2a3ee1582373093acf69a2f4e2ac1710b253a001712b86a61f88bb",
"details": {
"parent_model": "",
"format": "gguf",
"family": "qwen2",
"families": [
"qwen2"
],
"parameter_size": "620M",
"quantization_level": "Q4_0"
},
"connection_type": "local",
"urls": [
0
]
},
"connection_type": "local",
"tags": [],
"actions": [],
"filters": []
},
{
"id": "deepseek-r1:1.5b",
"name": "deepseek-r1:1.5b",
"object": "model",
"created": 1756555949,
"owned_by": "ollama",
"ollama": {
"name": "deepseek-r1:1.5b",
"model": "deepseek-r1:1.5b",
"modified_at": "2025-08-17T04:50:08.766430912Z",
"size": 1117322768,
"digest": "e0979632db5a88d1a53884cb2a941772d10ff5d055aabaa6801c4e36f3a6c2d7",
"details": {
"parent_model": "",
"format": "gguf",
"family": "qwen2",
"families": [
"qwen2"
],
"parameter_size": "1.8B",
"quantization_level": "Q4_K_M"
},
"connection_type": "local",
"urls": [
0
]
},
"connection_type": "local",
"tags": [],
"actions": [],
"filters": []
},
{
"id": "arena-model",
"name": "Arena Model",
"info": {
"meta": {
"profile_image_url": "/favicon.png",
"description": "Submit your questions to anonymous AI chatbots and vote on the best response.",
"model_ids": null
}
},
"object": "model",
"created": 1756555949,
"owned_by": "arena",
"arena": true,
"actions": [],
"filters": [],
"tags": []
},
{
"id": "政府工作报告",
"name": "政府工作报告",
"object": "model",
"created": 1756275416,
"owned_by": "ollama",
"info": {
"id": "政府工作报告",
"user_id": "e6d4a214-8982-40ad-9bbc-77ee14534d58",
"base_model_id": "deepseek-r1:1.5b",
"name": "政府工作报告",
"params": {},
"meta": {
"profile_image_url": "/static/favicon.png",
"description": "挂接2023年北京市政府工作报告",
"capabilities": {
"vision": false,
"file_upload": false,
"web_search": false,
"image_generation": false,
"code_interpreter": false,
"citations": false
},
"suggestion_prompts": null,
"tags": [],
"knowledge": [
{
"id": "161dd6ea-2e14-4b60-b8a2-48993ec9e4f2",
"user_id": "e6d4a214-8982-40ad-9bbc-77ee14534d58",
"name": "政府工作报告",
"description": "共享政府工作报告内容",
"data": {
"file_ids": [
"ca856fca-3eef-44d7-882d-24b312a72c48"
]
},
"meta": null,
"access_control": null,
"created_at": 1756275107,
"updated_at": 1756275184,
"user": {
"id": "e6d4a214-8982-40ad-9bbc-77ee14534d58",
"name": "acaluis",
"email": "acaluis@sina.com",
"role": "admin",
"profile_image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAGQAAABkCAYAAABw4pVUAAAAAXNSR0IArs4c6QAABItJREFUeF7tnF2IVHUYxp9zzpyZ2Q9ZtdZscfdmEzOtZfEDtmhtIxXRQEQIuxFUikRFKOou0RtRgrqIBNmCQLab6IM1yjVaK8QLBVGkUlwFFSoldHXdna+dE3OOLnvOfszsTLXPP565G+Z/Zp7z/M5z3vO+/2Wte52zPehF44AlIDQsfCECwsVDQMh4CIiAsDlApkc1REDIHCCTo4QICJkDZHKUEAEhc4BMjhIiIGQOkMlRQgSEzAEyOUqIgJA5QCZHCREQMgfI5CghAkLmAJkcJURAyBwgk6OECAiZA2RylBABIXOATI4SIiBkDpDJUUIEhMwBMjlGJyS58ghiTWtGLPWy95E5vRfZXz8ms7l0OcYCceYsRbKjE1ZtY+hsc9d7kOrZVLoDZCuNBRJf9i7ii7cDthuy1Bu6hdRPOzB843syq0uTYyyQqrVH4cxt88/SG7oJK14HOAnAyyN78VOkT75VmgNkq4wEEmveiETbAViJmb6duWvfwXm0BVb14/77/O3fMNS9Gl52gMzu4nKMBJJ47j24CzYDlg0Mp5E59z6cuc/CaWgPEmNwcTcOiF3XjOTKLth1TwTmD/6O1I9vwKlfgnjr28Ftq5AaQ4u7cUDcp7YhvmwPrFi1b/zwH6cw9M06RJ+6TC3uxgFJrvoMscZVwc04n0XmwkfInN7nvw31JYYWd6OAOA3PI7ni0Ejx9gauI9W7DcM3z/hA3IVbg/S4NQGv/stIHX8V+f6+4tWUZIVRQKK9R7ROROuLX/DPHkTm3AckdheXYRSQ6vW9sB95JijmucFgTPJLZ+gsQ09gBhZ3Y4BEe4+JbkfRdaYVd2OAJF84jFjzhsJ/AynkA9lLXUj/vGvce0DVum/hPLY8+Myw4m4EkDG9R/oO0qfeQa7v83GBRGuNScXdCCDxlt2hpi//13kMftUxYYUcMwk2qLgbAWSy3mMiKqFjRjWQxZ9zpncFPRBn3ktItn8Iq6q+Iqe89G2kT76J3NWvK/qef/tgeiCJ5fvgLnodsGOVeWFIcacGYrm1qFrbPdJ7VEbEjM6dGog7fxPibfthuTOCJ9jBP/1Ru5fpL4mNXdMA9+mdI/smJnTu1EDCvUd5I/XR3X2B4sPpcElEp2ERLRC7vhXJFz+BXdsU2FLmo2u0J/GK9DDTwCD0k7RAxvQeA9eQ+mEL8rfOTsmz6IS40OXn+r5A6sRrU/qe/2oxLZDRf8RQMCN35Ut/1F7OK9qT5O9eRarnFcqxPCWQaO9R6R55dJex3NtfORfDVI+hBBIdoVc6ixqzT0Jc3OmA+L3Hy8dgz3rywcU1+WS31CswCpm1uNMBiW7D/lPGRfdJWIs7HZBSr/j/6zoBISMrIAJC5gCZHCVEQMgcIJOjhAgImQNkcpQQASFzgEyOEiIgZA6QyVFCBITMATI5SoiAkDlAJkcJERAyB8jkKCECQuYAmRwlREDIHCCTo4QICJkDZHKUEAEhc4BMjhIiIGQOkMlRQgSEzAEyOUqIgJA5QCZHCREQMgfI5CghAkLmAJkcJURAyBwgk6OEkAH5G7gElAPcU3ncAAAAAElFTkSuQmCC"
},
"files": [
{
"id": "ca856fca-3eef-44d7-882d-24b312a72c48",
"meta": {
"name": "microsoft_annual_report_2022.pdf",
"content_type": "application/pdf",
"size": 1285495,
"data": {},
"collection_name": "161dd6ea-2e14-4b60-b8a2-48993ec9e4f2"
},
"created_at": 1756275120,
"updated_at": 1756275120
}
],
"type": "collection"
}
]
},
"access_control": null,
"is_active": true,
"updated_at": 1756275416,
"created_at": 1756275416
},
"preset": true,
"actions": [],
"filters": [],
"tags": []
}
]
}
同时在全局变量request.app.state.MODELS、request.app.state.OPENAI_MODELS、request.app.state.OLLAMA_MODELS和request.app.state.BASE_MODELS分别存储可用模型数据、open ai模型数据、ollama数据和基础模型数据。全部数据均以dict方式存储,其中key为模型的id,v为模型数据(与应答中的模型数据相同)。