ReconDreamer++
paper来源
ReconDreamer++: Harmonizing Generative and Reconstructive Models for Driving Scene Representation
论文目标
该论文旨在提升渲染质量,解决模型生成的合成数据与真实世界传感器观测数据之间存在的领域差距问题。在前身 ReconDreamer 的基础上改进,丰富了渲染场景的内容,提高了场景的保真度。
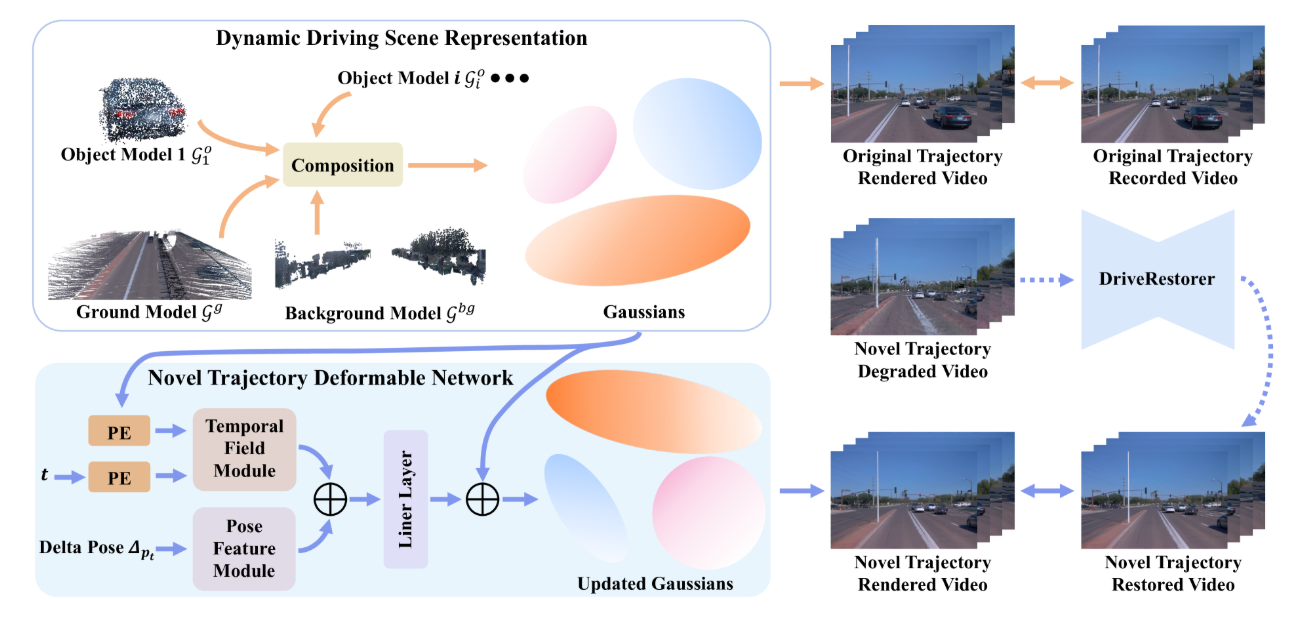
核心方法
驾驶场景分解
该方法首先将驾驶场景系统性地分解为三个关键组成部分:
- 地面表面:采用三维高斯表示,以精准捕捉道路特征。
- 非地面静态背景:指场景中不包含动态元素的静态部分。
- 动态目标:由于这类目标的位置和特征会随时间变化,因此对其进行单独建模。
这种分解方式能够实现针对性的优化策略,对于精准表征车道、道路标线等结构化元素而言至关重要,而这些元素在导航过程中发挥着关键作用。
新型轨迹可变形网络(NTDNet)
ReconDreamer++ 的核心创新点在于新型轨迹可变形网络(NTDNet),该网络旨在缩小生成视图与真实世界观测结果之间的领域差距。该网络主要由两个部分构成:
- 姿态特征模块(Fϕ):该模块以增量姿态(原始轨迹与新型轨迹之间的位置差异)作为输入。增量姿态的计算公式如下:
(其中,L 为归一化超参数)
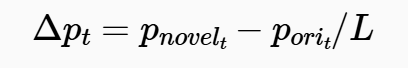
- 时间域模块(Fθ):此模块利用时间步长和高斯参数作为输入,捕捉场景表征的时间动态特性。
将两个模块的输出结合起来,用于更新高斯参数,从而使生成的观测结果与真实观测结果实现更好的对齐,公式如下:
(其中,PE表示位置编码 positional encoding)
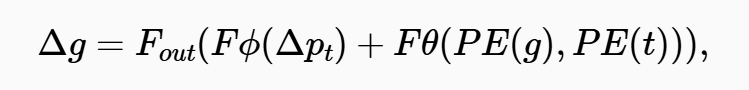
地面模型表征
地面表面的表征通过一组高斯函数实现,这些高斯函数由中心位置、不透明度、协方差以及基于球谐函数的视角相关 RGB 颜色进行参数化。为提高模型在优化过程中的稳定性和准确性,对协方差矩阵进行了明确的结构化设计,公式如下:
(其中,R 和 S 为可学习参数)
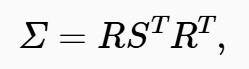
通过对部分参数进行约束,并利用地面的三维点云数据对这些参数进行初始化,该模型有效缩小了重建过程中的搜索空间,确保地面渲染具备更高的保真度。
优化过程
为加强生成模型与重建模型的融合,研究人员在训练阶段引入了多种重建损失函数,公式如下:
(其中,每一项损失函数都对重建质量的不同方面起到改善作用,例如像素精度(LRGB)、结构相似性(LSSIM)以及深度保真度(LDepth)。其中,深度监督对于提升空间理解能力具有重要意义,而空间理解能力是实现场景中动态元素和静态元素精准渲染的关键。)
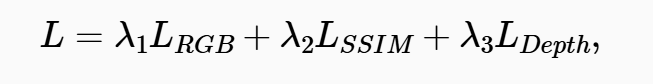
性能评估
研究人员在多个数据集(包括 Waymo、nuScenes、PandaSet 和 EUVS)上对 ReconDreamer++ 的性能进行了评估,并采用了以下多种评估指标:
- 新型轨迹智能体交并比(NTA-IoU):用于衡量动态目标渲染的质量。
- 新型轨迹车道交并比(NTL-IoU):用于评估背景车道的准确性。
- 弗雷歇初始距离(FID):用于衡量渲染图像的整体保真度。
评估结果表明,与现有的最先进方法相比,ReconDreamer++ 在这些指标上均实现了显著提升,尤其是在存在新型轨迹的场景中。传统模型在这类场景中往往因泛化能力不足而表现欠佳,而 ReconDreamer++ 则有效克服了这一问题。
结论
ReconDreamer++ 通过创新性的架构设计(尤其是新型轨迹可变形网络(NTDNet))以及稳健的地面建模技术,成功缩小了生成模型与重建模型之间的差距。该论文通过验证协同不同建模方法在提升场景表征质量方面的潜力,为自动驾驶仿真领域的发展做出了重要贡献,而高质量的场景表征对于推动自动驾驶技术的进步至关重要。严谨的方法设计与全面的实验验证充分证明了 ReconDreamer++ 在高保真驾驶场景渲染方面的优越性,为自动驾驶导航技术领域的发展迈出了重要一步。