Python关于pandas的基础知识
一.扫盲
(一)、pandas 是什么

pandas 是 Python 的一个第三方数据处理库,它提供了高效、灵活的数据结构(如 Series 和 DataFrame),能方便地对结构化数据进行清洗、转换、分析和处理。
(二)、pandas 与 NumPy 的关系
NumPy 是 Python 中用于科学计算的基础库,主要用于存储和处理数值型数组。但它有一个局限,就是不能直接存储和处理字符串等非数值类型的数据。
而 pandas 是在 NumPy 的基础上构建的,它不仅继承了 NumPy 对数值型数据的处理能力,还扩展了对字符串、日期等多种数据类型的支持,能更好地应对复杂的结构化数据处理场景。
(三)、为何需要用 pandas 处理 Excel 文件
在日常办公中,Excel 文件是非常常用的数据存储和处理格式。但如果仅依靠 Excel 软件本身进行大量数据的复杂处理,效率往往较低。
这时候就需要用到 pandas,它可以轻松读取和写入 Excel 文件,并且能通过简洁的代码实现数据筛选、排序、分组、计算等操作,大幅提升数据处理效率。
(四)、哪些行业常用 Excel 且适合用 pandas
很多行业在工作中频繁使用 Excel,其中金融行业、投行尤为典型。这些行业需要对大量的财务数据、交易数据、市场数据等进行编排、统计和分析计算,借助 pandas 能快速完成复杂的数据处理任务,提高工作效率和准确性。
(五)、openpyxl 库
除了 pandas,还有一个名为openpyxl的 Python 库,它可以直接读取和写入 Excel 文件。同时,openpyxl 还能模拟 pandas 的部分功能,在一些特定场景下为 Excel 文件处理提供更多选择。
(六).安装
- 点击顶部菜单栏 “File”(文件)→ “Settings”(设置)(或直接按
Ctrl + Alt + S快捷键打开设置)。 - 在设置左侧列表,找到并点击 “Project: [你的项目名称]” → “Python Interpreter”(Python 解释器) 。
- 在右侧 “Python Interpreter” 界面,点
+号(“Add” 按钮),打开包搜索安装窗口,搜索你需要的第三方库(如pandasnumpy等 ),再点击 “Install Package” 安装即可。
二.代码演示
(一).DataFrame
"""
DataFrame(数据框)
就是excel表(多个Series的拼接)
"""
import pandas as pddf_1 = pd.DataFrame({'age':[10,11,12],'name':['tim', 'tom', 'rose'],'income':[100,200,300]},index=['person1', 'person2', 'person3'])
print(df_1)"""
dataframe的属性
"""
#行索引
df_1.index
#列名
df_1.columns
#值
df_1.valuesdf_1 = pd.DataFrame({'age':[10,11,12],'name':['tim', 'tom', 'rose'],'income':[100,200,300]})
print(df_1)
print(df_1.name)在这个代码里面我们可以看到在6行 pandas 数据类型是dataframe numpy的数据类型是ndnarry
其中
df_1 = pd.DataFrame({'age':[10,11,12],'name':['tim', 'tom', 'rose'],'income':[100,200,300]},index=['person1', 'person2', 'person3'])在DataFrame后面的数据是可以全部强制转化表格数据的类型,{ }表示的是字典的类型,如果是字典类型的话就会有键和值的概念,键值对像age:[10,11,12]在效果中展示的是下图中的样子,而代码的最后一行 index=['person1', 'person2', 'person3'])是行的索引号
#效果展示:
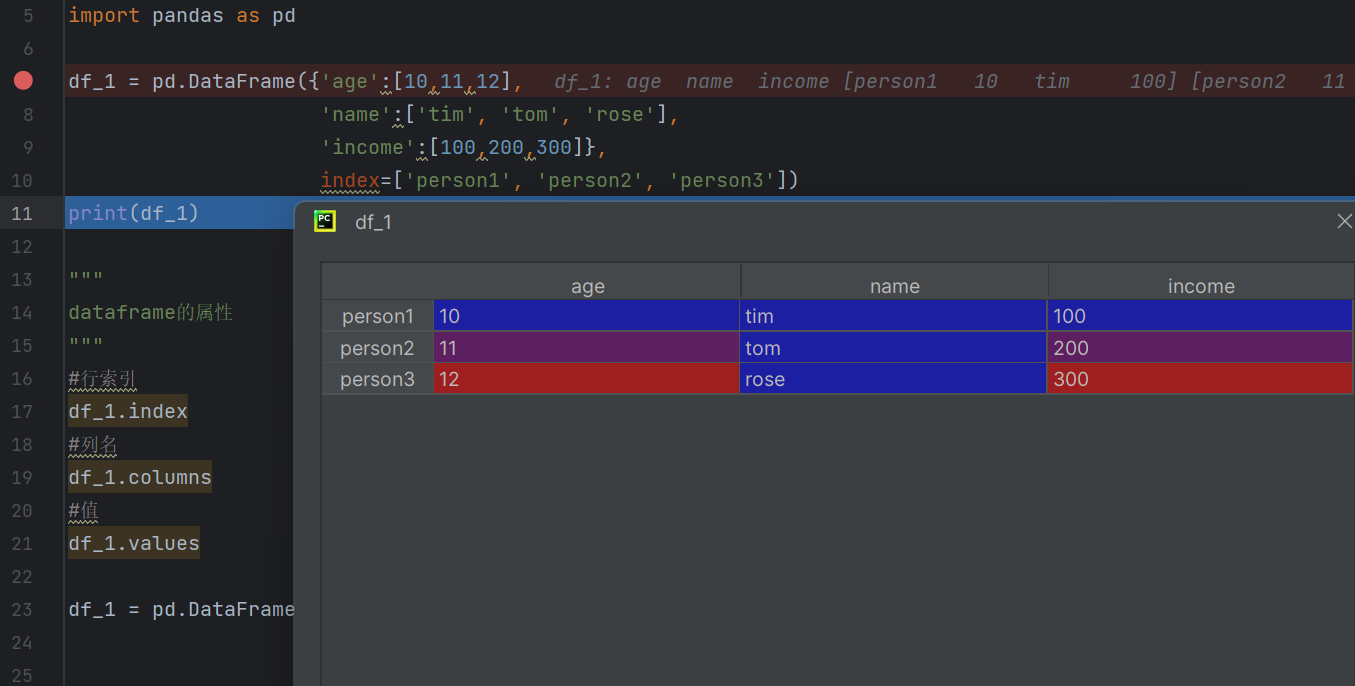
age这个下面的数值是竖着分布的类推左边也是一样的。
(二).DataFramed的属性
这张图需要结合效果图
"""
dataframe的属性
"""
#行索引
df_1.index
#列名
df_1.columns
#值
df_1.valuesdf_1 = pd.DataFrame({'age':[10,11,12],'name':['tim', 'tom', 'rose'],'income':[100,200,300]})
print(df_1)
print(df_1.name)
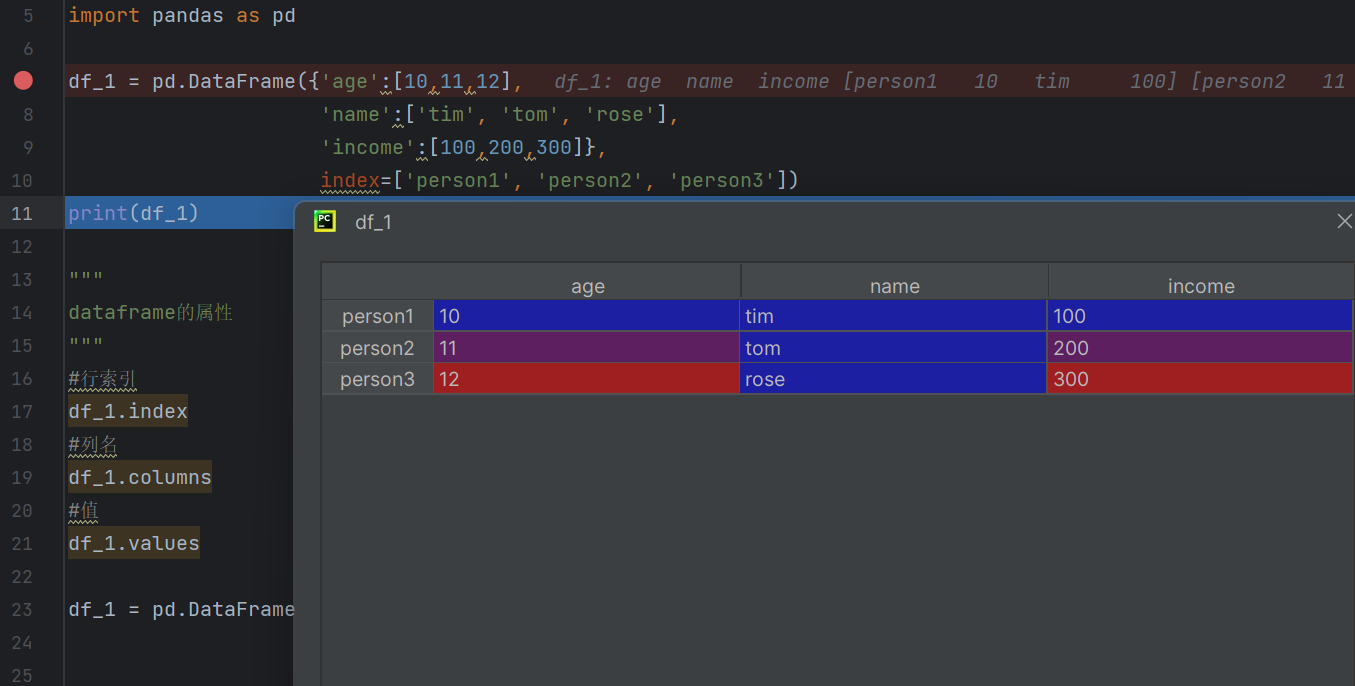
看age就是表示的是columns的列一列一列的,columns就是表示的是一列一列
values还是按照numpy的形式存储的如图所示
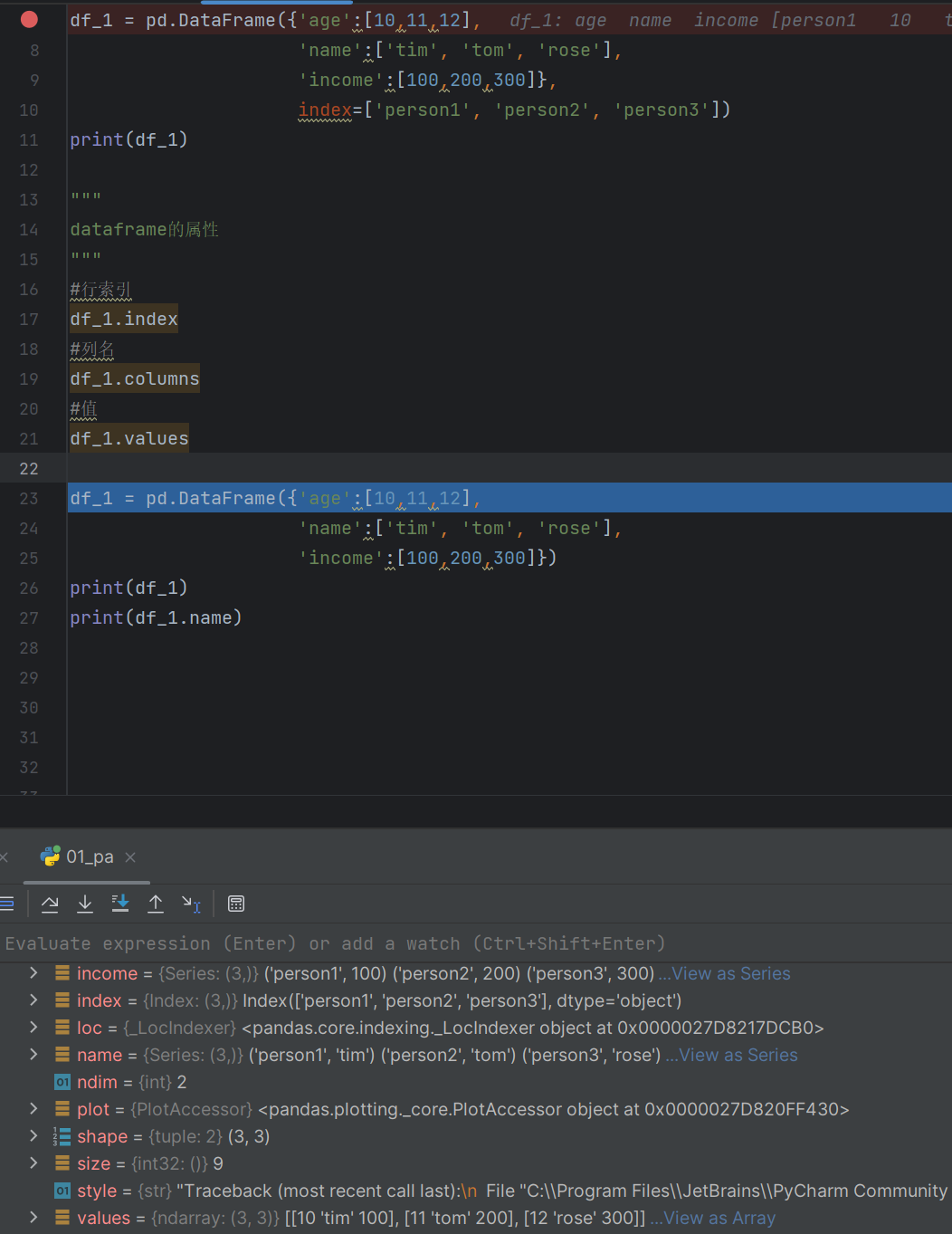
可以看到values里的numpy数据类型就是ndarray
下一个知识点就是这张图片的23-25行说的就是无index的时候如下图所示行名就默认0 1 2
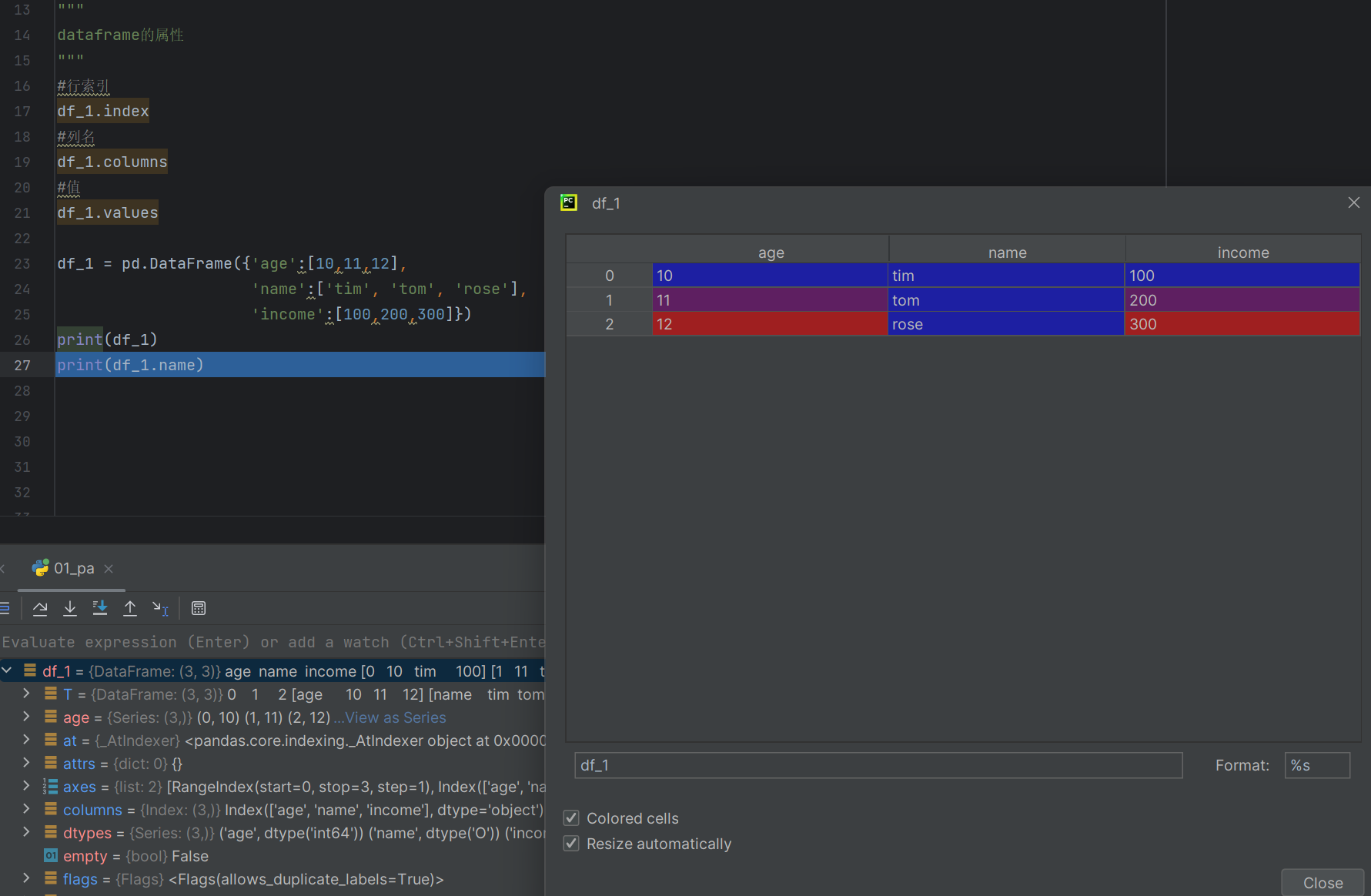
df_1是类产生的对象,那就可以得到对象的属性只需要这样的代码:print(df_1.name)
三.DataFrame常见的操作
(一)代码讲解
import pandas as pddic = {'name': ['kiti', 'beta', 'peter', 'tom'],'age': [20, 18, 35, 21],'gender': ['f', 'f', 'm', 'm']}
df = pd.DataFrame(dic)
print(df)"""
根据年龄这一列,进行排序【升序和降序】
"""
df = df.sort_values(by=['age'])
df = df.sort_values(by=['age'], ascending=False)"""
值替换
"""
df['gender'] = \
df['gender'].replace(['m', 'f'], ['male', 'female'])sort函数就是讲的是排序的这样的函数,
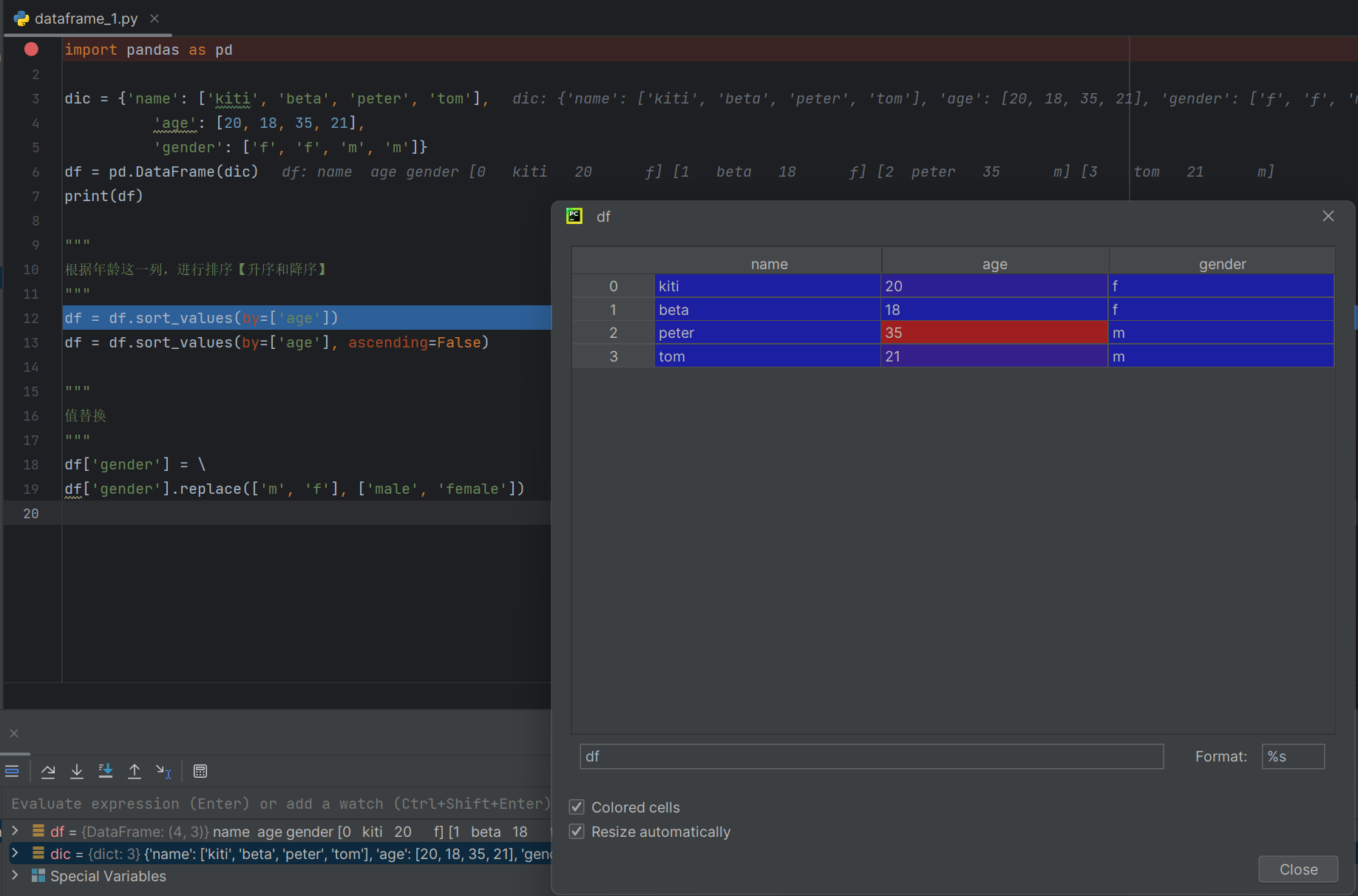
下图是排序从小到大排序
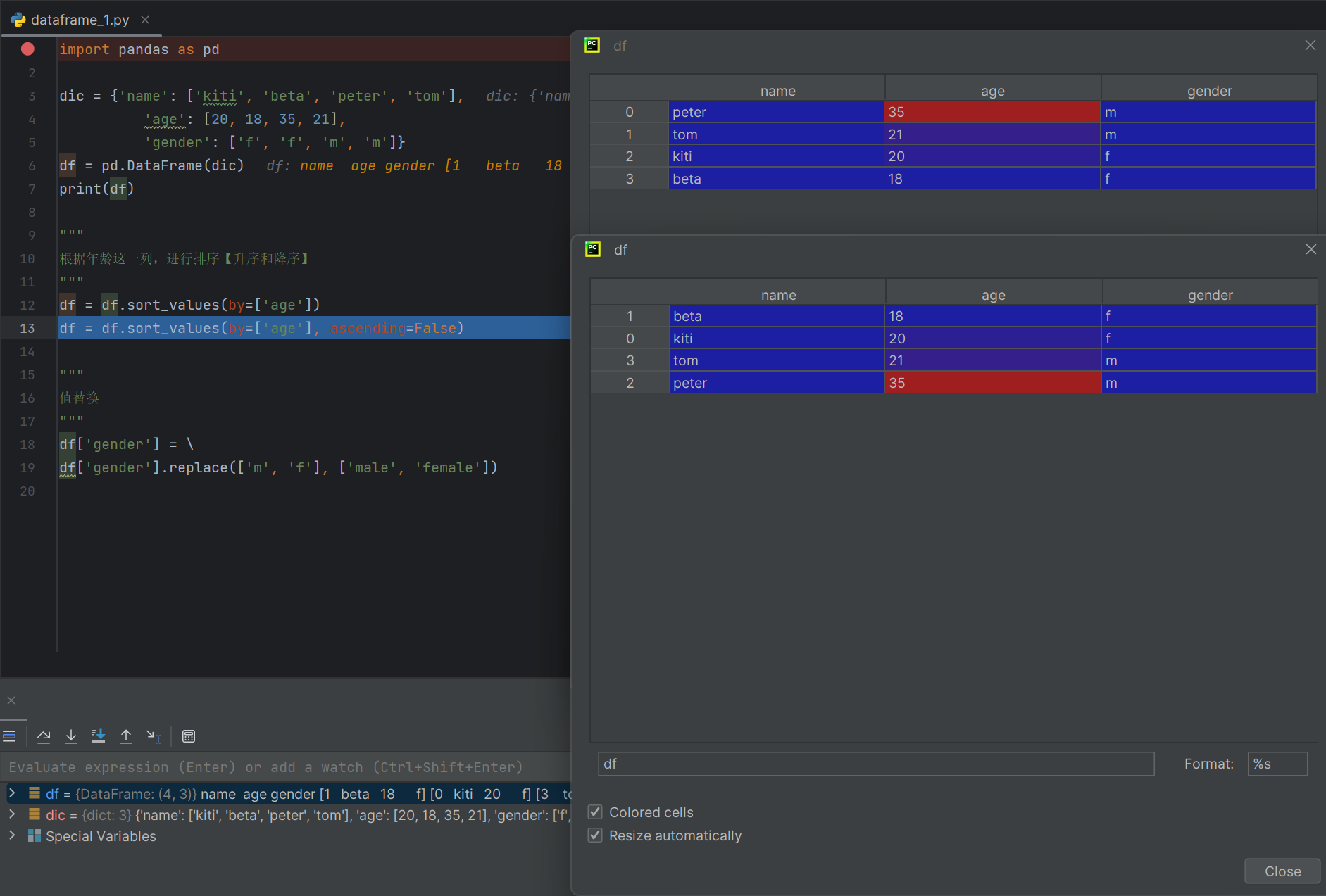
ascending=False表示就是从大到小的排序。
值替换
18行的\是换行的意思,
三.serious
serious就是表达的一维的数据类型,dataframe是表达二维及以上数据类型
import pandas as pds_1 = pd.Series([1,2,3,4,5], index=['a', 'b', 'c', 'd', 'e'])s_2 = pd.Series(['lily', 'rose', 'jack'])#查
"""
(1)通过标签访问
"""
#访问某个元素
print(s_1['d'])
#访问多个元素[Series的切片]
print(s_1['a':'d'])
#访问多个元素
print(s_1[['a', 'd']])"""
(2)通过索引访问
"""
print(s_2[2])
print(s_2[0:2])
print(s_2[[0, 2]])print(s_1[4])#删除
s_1 = s_1.drop('a')
#判断一下某个值是否在Series里面
print('jim' != s_2.values)#改
s_2[0] = 'Peter'#创建Series
dic_1 = {"name1": "Peter", "name2":"tim",
"name3":"rose"}
s_4 = pd.Series(dic_1)
print(s_4)#重置索引
s_4.index = range(0, len(s_4))
print('1')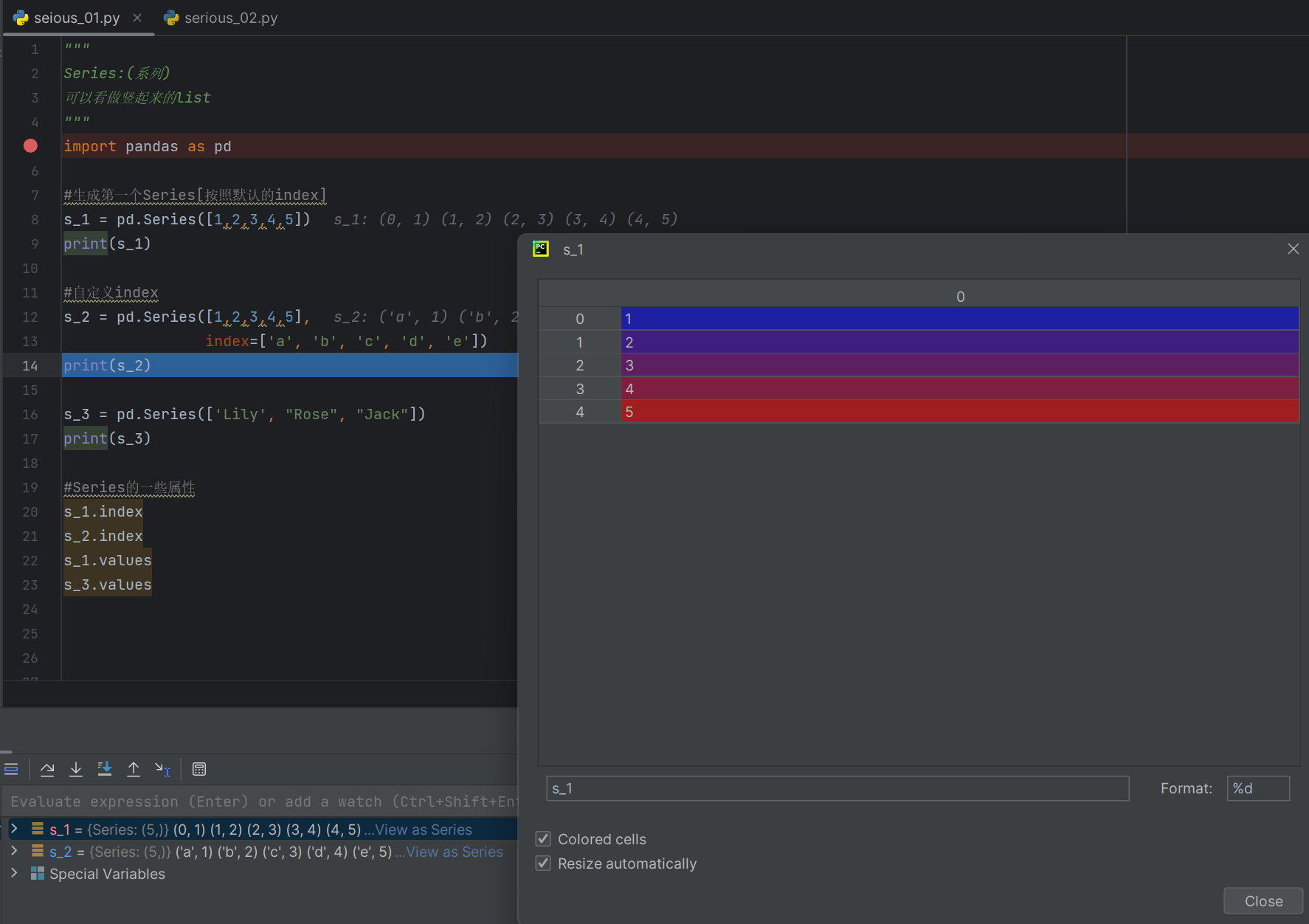
四.serious操作
(一)标签访问
import pandas as pds_1 = pd.Series([1,2,3,4,5],index=['a', 'b', 'c', 'd', 'e'])s_2 = pd.Series(['lily', 'rose', 'jack'])#查
"""
(1)通过标签访问
"""
#访问某个元素
print(s_1['d'])
#访问多个元素[Series的切片]
print(s_1['a':'d'])
#访问多个元素
print(s_1[['a', 'd']])
s_1['d']:用单个标签'd'直接访问对应元素,返回标量值 4。s_1['a':'d']:用:切片,包含起始标签'a'和结束标签'd'及中间所有元素,返回 Series。s_1[['a', 'd']]:用列表['a','d']指定多个标签,按顺序返回对应元素组成的 Series。
(二).索引
import pandas as pds_1 = pd.Series([1,2,3,4,5],index=['a', 'b', 'c', 'd', 'e'])s_2 = pd.Series(['lily', 'rose', 'jack'])#查
"""
(1)通过标签访问
"""
#访问某个元素
print(s_1['d'])
#访问多个元素[Series的切片]
print(s_1['a':'d'])
#访问多个元素
print(s_1[['a', 'd']])"""
(2)通过索引访问
"""
print(s_2[2])
print(s_2[0:2])
print(s_2[[0, 2]])print(s_1[4])#删除
s_1 = s_1.drop('a')
#判断一下某个值是否在Series里面
print('jim' != s_2.values)#改
s_2[0] = 'Peter'#创建Series
dic_1 = {"name1": "Peter", "name2":"tim",
"name3":"rose"}
s_4 = pd.Series(dic_1)
print(s_4)#重置索引
s_4.index = range(0, len(s_4))
print('1')
查
(1) 通过标签访问
print(s_1['d']):使用标签'd'直接访问s_1中对应元素,返回值为 4。print(s_1['a':'d']):通过:进行标签切片,包含从'a'到'd'的所有元素,返回一个包含这四个元素的 Series。print(s_1[['a', 'd']]):传入包含'a'和'd'的列表,按列表顺序返回这两个标签对应的元素,组成新的 Series。
(2) 通过索引访问
print(s_2[2]):使用位置索引 2 访问s_2中的元素,返回'jack'。print(s_2[0:2]):通过:进行位置切片,包含从索引 0 到 1(不包含 2)的元素,返回包含'lily'和'rose'的 Series。print(s_2[[0, 2]]):传入包含 0 和 2 的列表,按顺序返回这两个位置索引对应的元素,组成新的 Series。print(s_1[4]):使用位置索引 4 访问s_1中的元素,返回 5(对应标签'e'的值)。
删除
s_1 = s_1.drop('a'):通过drop方法删除s_1中标签为'a'的元素,原 Series 不变,需重新赋值才会更新。(很重要)
判断某个值是否在 Series 里面
print('jim' != s_2.values):先通过values获取s_2的所有元素值,再判断'jim'是否不等于这些值,返回一个布尔数组。
改
s_2[0] = 'Peter':通过位置索引 0 定位s_2中的元素,并将其修改为'Peter'。
创建 Series
s_4 = pd.Series(dic_1):通过字典dic_1创建 Series,字典的键作为标签,值作为对应元素值。
重置索引
s_4.index = range(0, len(s_4)):将s_4的索引重置为从 0 开始的连续整数,长度与s_4的元素个数一致。
五.查询数据的两种方法
"""
loc()
iloc()
"""
import pandas as pd
import numpy as np
#生成指定日期
datas = pd.date_range('20180101', periods=5)
df = pd.DataFrame(np.arange(30).reshape(5,6),index=datas,columns=['A','B','C','D','E','F'])"""
loc()方法
df.loc[x, y]
【标签索引】
"""
#打印某个值
print(df.loc['20180103', 'B'])
#打印某列值
print(df.loc[:,'B'])
print(df.loc['20180103':,'B'])
print(df.loc['20180103':,['B', 'D']])
#打印某行值
print(df.loc['20180101', :])
#打印某些行
print(df.loc['20180103':,:])"""
iloc()方法
位置索引
"""
#获取某个数据
print(df.iloc[1,2])
#获取某列
print(df.iloc[:,2])
#获取某几列
print(df.iloc[:,[1,3]])
#获取某行
print(df.iloc[1,:])
#获取某些行
print(df.iloc[[1,2,4],:])一、数据准备:生成日期索引与 DataFrame
日期索引生成(
datas = pd.date_range(...))pd.date_range('20180101', periods=5)用于生成一组连续的日期索引,结果是DatetimeIndex类型(调试时可看到是 datetime 格式)。这里从20180101(2018 年 1 月 1 日)开始,生成 5 个连续日期,即:2018-01-01、2018-01-02、2018-01-03、2018-01-04、2018-01-05。创建 DataFrame(
df = pd.DataFrame(...))
这行代码将生成一个 5 行 6 列的二维表格数据,各参数含义:np.arange(30):生成 0 到 29 的连续整数(共 30 个数字),作为表格的原始数据;reshape(5,6):将 30 个数字转换成 5 行 6 列的二维数组(5 行 ×6 列 = 30 个元素);index=datas:指定表格的行索引(行名) 为前面生成的 5 个日期;columns=['A','B','C','D','E','F']:指定表格的列索引(列名) 为 A 到 F 这 6 个标签。
最终生成的
df是一个二维 DataFrame 对象,结构如下(简化):行名(index) A B C D E F 2018-01-01 0 1 2 3 4 5 2018-01-02 6 7 8 9 10 11 ... ... ... ... ... ... ...
二、查询方法:loc()—— 基于标签的索引
loc()是 pandas 中基于标签(行名 / 列名) 的查询方法,语法为df.loc[行标签, 列标签],适用于二维 DataFrame 的查询(区别于一维 Series 的查询,Series 是单维度数据,而 DataFrame 是二维表格,需要同时指定行和列的标签)。
代码中各示例的含义:
df.loc['20180103', 'B']
查询行标签为20180103(2018 年 1 月 3 日)、列标签为B的单个值。df.loc[:,'B']
查询所有行(:表示全部)、列标签为B的整列数据(返回一个 Series)。df.loc['20180103':,'B']
查询行标签从20180103到最后一行('20180103':表示从该标签开始的所有行)、列标签为B的数据。df.loc['20180103':,['B', 'D']]
查询行标签从20180103到最后一行、列标签为B和D的两列数据(返回一个子 DataFrame)。df.loc['20180101', :]
查询行标签为20180101、所有列(:表示全部)的整行数据(返回一个 Series)。df.loc['20180103':,:]
查询行标签从20180103到最后一行、所有列的子 DataFrame。
三、查询方法:iloc()—— 基于位置的索引
iloc()是 pandas 中基于位置(整数索引) 的查询方法,语法为df.iloc[行位置, 列位置],其中 “位置” 从 0 开始计数(即第 1 行是位置 0,第 1 列是位置 0)。它适用于不记得行 / 列标签,只知道具体位置的场景。
代码中各示例的含义:
df.iloc[1,2]
查询第 2 行(位置 1)、第 3 列(位置 2)的单个值(因为索引从 0 开始)。df.iloc[:,2]
查询所有行(:表示全部)、第 3 列(位置 2)的整列数据。df.iloc[:,[1,3]]
查询所有行、第 2 列(位置 1)和第 4 列(位置 3)的两列数据。df.iloc[1,:]
查询第 2 行(位置 1)、所有列的整行数据。df.iloc[[1,2,4],:]
查询第 2 行(位置 1)、第 3 行(位置 2)、第 5 行(位置 4)、所有列的数据。
六.简单的Dataframe操作
import pandas as pddf = pd.DataFrame({'age':[10,11,12],'name':['tim', 'tom', 'rose'],'income':[100,200,300]},index=['person1', 'person2', 'person3'])
print(df)"""
修改列名
"""
a= df.columns
df.columns = range(0, len(df.columns))
print(df.columns)"""
修改行名
"""
print(df.index)
df.index = range(0,len(df.index))
print(df.index)"""
增加一列
"""
#在最后添加一列
df['pay'] = [20, 30, 40]
print(df)"""
增加一行
"""
df.loc['person4', ['age', 'name', 'income']] = [20, 'kitty', 200]
print(df)
"""
访问DataFrame
"""
#访问某列
print(df.name)
#访问某些列
print(df[['age', 'name']])#访问行
print(df[0:2])
# #使用loc访问
print(df.loc[['person1', 'person3']])
#访问某个值
print(df.loc['person1', 'name'])"""
删除
"""
#直接在原数据上删除
del df['age']
print(df)
#删除列
data = df.drop('name', axis=1, inplace=False)
print(data)
#删除行
df.drop('person3', axis=0, inplace=True)import pandas as pd
import numpy as npdatas = pd.date_range('20180101',periods=5)
df1 = pd.DataFrame(np.arange(30).reshape(5,6),index=datas,columns=['A','B','C','D','E','F'])
print(df1)
print()一、修改列名
代码中先通过a = df.columns获取了当前 DataFrame 的列名(此时列名为['age', 'name', 'income']),随后通过df.columns = range(0, len(df.columns))对列名进行了修改。
这里利用range(0, len(df.columns))生成了从 0 开始、与列数相同长度的连续整数(因原 DataFrame 有 3 列,所以生成[0, 1, 2]),最终将列名修改为这组整数。执行后df.columns的输出结果为Int64Index([0, 1, 2], dtype='int64')。
二、修改行名
与修改列名逻辑类似,先通过print(df.index)查看当前行索引(原行名为['person1', 'person2', 'person3']),再通过df.index = range(0, len(df.index))重新设置行名。
range(0, len(df.index))生成了与行数相同的连续整数(原 DataFrame 有 3 行,生成[0, 1, 2]),最终行名被修改为这组整数。执行后df.index的输出结果为RangeIndex(start=0, stop=3, step=1)。
三、增加一列
代码中通过df['pay'] = [20, 30, 40]在 DataFrame 最后新增了一列,列名为'pay',对应的值为[20, 30, 40]。
注意:这行代码(第 28 行)非常重要。在后期涉及深度学习等场景时,经常需要为数据新增特征列(如标签、计算得到的特征等),这种直接通过列名赋值新增列的方式是基础且常用的操作,需要认真学习并记忆。
四、访问 DataFrame
代码从第 39 行开始演示了访问 DataFrame 的多种方式:
- 访问某列:
print(df.name)通过 “点语法” 访问名为'name'的列(前提是列名符合变量命名规则)。 - 访问某些列:
print(df[['age', 'name']])通过传入列名列表['age', 'name'],一次性访问多个指定列,返回包含这些列的子 DataFrame。 - 访问行(切片方式):
print(df[0:2])通过切片0:2访问前 2 行(左闭右开,即索引为 0 和 1 的行)。 - 通过 loc 访问行:
print(df.loc[['person1', 'person3']])通过loc方法,传入行名列表['person1', 'person3'],精准访问指定行。 - 访问某个具体值:
print(df.loc['person1', 'name'])通过loc方法,传入行名'person1'和列名'name',直接获取对应位置的具体值(此处为'tim')。
五、删除操作
从第 55 行开始演示了 DataFrame 的删除操作,这在数据清洗中非常重要:
- 直接删除列:
del df['age']通过del关键字直接删除'age'列,操作会直接修改原 DataFrame。 - 通过 drop 删除列:
data = df.drop('name', axis=1, inplace=False)使用drop方法删除列。其中axis=1表示删除列(axis=0表示删除行),inplace=False表示不修改原 DataFrame,而是返回删除后的新 DataFrame(赋值给data)。 - 通过 drop 删除行:
df.drop('person3', axis=0, inplace=True)使用drop方法删除行。axis=0表示删除行,inplace=True表示直接在原 DataFrame 上进行修改,删除行名为'person3'的行。