【AI非常道】二零二五年三月,AI非常道
经常在社区看到一些非常有启发或者有收获的话语,但是,往往看过就成为过眼云烟,有时再想去找又找不到。索性,今年开始,看到好的言语,就记录下来,一月一发布,亦供大家参考。
前面的记录:
《【AI非常道】二零二五年一月,AI非常道》
《【AI非常道】二零二五年一月(二),AI非常道》
《【AI非常道】二零二五年二月,AI非常道》
强化学习的综述论文 Reinforcement Learning: A Comprehensive Overview
一篇关于强化学习的综述论文 Reinforcement Learning: A Comprehensive Overview 《强化学习:全面综述》第二版
arxiv.org/pdf/2412.05265v2
本文由Google的科学家 Kevin P. Murphy 编写,全面介绍了强化学习(Reinforcement Learning, RL)的理论基础、方法、应用及其最新进展。文章从序贯决策制定的基本概念出发,详细介绍了值函数、策略梯度和基于模型的强化学习方法,并探讨了多智能体强化学习、大语言模型(LLM)与强化学习的结合等前沿领域。
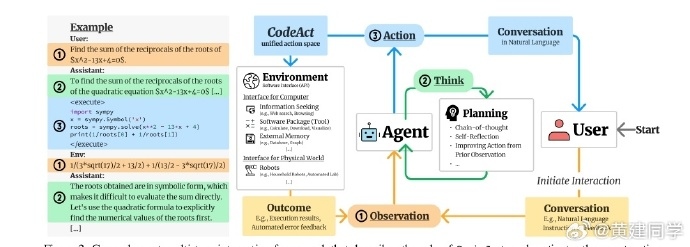
Manus 背后用的 CodeAct的架构介绍↓
大型语言模型 (LLM) 代理能够执行广泛的操作,例如调用工具和控制机器人,在应对现实世界的挑战方面表现出巨大的潜力。LLM 代理通常通过生成 JSON 或预定义格式的文本来提示执行操作,这通常受到受限的操作空间(例如,预定义工具的范围)和受限的灵活性(例如,无法组合多个工具)的限制。
这项工作提出使用可执行的 Python 代码将 LLM 代理的操作合并到统一的操作空间 (CodeAct) 中。与 Python 解释器集成后,CodeAct 可以执行代码操作并动态修改先前的操作或通过多轮交互根据新的观察发出新操作。
我们对 API-Bank 上的 17 个 LLM 和新策划的基准进行了广泛的分析,结果表明 CodeAct 优于广泛使用的替代方案(成功率高出 20%)。CodeAct 令人鼓舞的性能促使我们构建一个开源 LLM 代理,它通过执行可解释的代码与环境交互并使用自然语言与用户协作。
相关论文;arxiv.org/abs/2402.01030




OpenDeepSearch (ODS)
来自@黄建同学
OpenDeepSearch (ODS),比OpenAI还猛的开源的DeepSearch,可兼容与任何大模型(LLM)。
当与DeepSeek-R1配合使用时,ODS在DeepMind的多跳FRAMES基准测试上,比OpenAI专为网页搜索设计的GPT-4o-Search模型准确率高出9.7%。
1️⃣ 在OpenAI的SimpleQA简单基准测试中,ODS显著缩小了专有解决方案与开源解决方案之间的差距。
2️⃣ ODS是一个轻量级但功能强大的搜索工具,专为与AI代理无缝集成而设计。它能进行深度网页搜索和检索,特地为Hugging Face的SmolAgents系统做过优化。
3️⃣ ODS由两部分组成:Open Search Tool和Open Reasoning Agent。
- Open Search Tool,执行网页的深度搜索并提供高质量的上下文以回答用户的查询。
- Open Reasoning Agent,在检索到的上下文中没有包含必要信息时,会调用例如搜索工具等。
论文:arxiv.org/abs/2503.20201
代码:github.com/sentient-agi/OpenDeepSearch




《这就是这些天让我夜不能寐的原因》
来自@陆三金
4-1 01:15
推特上转发比较多的一条推特,《这就是这些天让我夜不能寐的原因》,一共有 46 条,有些同意,有些不同意,发出来大家看看吧。
「这些就是近来让我夜不能寐的事情……
1.ChatGPT 4o 的图像生成功能,其影响力不亚于 ChatGPT 的首次发布。 这可能会催生超过 1000 家年收入在 100 万到 1 亿美元之间的垂直领域软件公司。
2.我们正处在内容创作的“MP3 Napster 时代”。 数百万创作者还没意识到,他们所有的过往作品(整个内容库)正因 AI 而被武器化,变成他们自己的竞争对手。
3.未来 3 年内,所有的日历、收件箱和 CRM 系统都将被彻底重构。 不是简单的“AI 增强”,而是完全基于 AI 的重新思考和设计。
4.我曾以为 AI 在创造“数字雇员”,但现在看来更像是“数字雇主”。 首批能够管理人类员工的 AI 系统,将引发比工业革命更重大的劳动力市场结构调整。
5.如果你的工作是面试那些将要训练 AI 系统的人,而这些 AI 系统最终将取代进行面试工作的人,那么你只是处在这个怪异的、递归式的职业消亡链条中的一环。
6.AI 正在将“无法规模化的服务型业务”转变为“拥有服务业利润率的产品型业务”。 新的独角兽公司将是那些将服务产品化、并由 AI 完成 80% 工作的企业。
7.建立社群比开发产品更难,但所有人都假装反过来了。 现实是,大多数初创公司失败的真正原因是没有人在乎它们。
8.距离威尔·史密斯吃意大利面的那个 AI 视频已经过去 739 天了。 想象一下再过 739 天,生成式 AI 会发展成什么样?
9.那些开发“AI 助手”的人,大多自己从未有过(真人)助手。 真正的助手需要理解背景信息、了解过往情况,并建立关系。而 95% 的聊天机器人缺乏这些。
10.未来 36 个月内,绝大多数客户支持工作将被自动化。 不仅仅是处理初级问题(Tier 1 tickets),还包括那些以往需要高级支持人员才能解决的复杂、多步骤问题。
11.你的初创公司可能遇到的最糟糕情况是“不上不下的成功”(平庸的成功)。 收入足够让你维持下去,但不足以改变你的生活。大多数创始人都被困在这种状态里。这让我经常思考,对于手头的项目,是该果断放弃还是加倍投入。
12.AI 引发的强烈反对(backlash)将不仅仅来自被取代的工人, 还会来自每一个意识到自己完整的数字身份在未经同意的情况下被转化成了训练数据的人。
13.从来就没有人真正读过服务条款(Terms of Service)。
14.“草图经济”(Sketching Economy)才是真正的 AI 革命。 当任何人都能将粗略的草图转化为可投入生产的设计时,审美(Taste)和创意构思(Ideation)将成为唯一稀缺的资源。
15.我不知道该怎么更直白地说,对于普通人而言,AI 创业的真正机遇和‘钱’途在于那些真正理解行业背景的垂直领域应用。 不,仅仅在提示词(prompts)中加入行业术语是远远不够的。
16.面向消费者的移动应用(Consumer Mobile)开发正全面复苏。 我们经历了从“桌面优先”到“移动优先”,现在进入了“AI 优先的移动应用”时代。下一波年收入过亿的应用将从一开始就基于移动端,并深度融合 AI。
17.AI 中间商的繁荣期才刚刚开始。 那些处于基础大模型和特定行业之间的公司将攫取大部分价值,而两端(模型提供方和最终用户)则会趋于同质化/商品化(commoditized)。
18.我们正在见证一个全新职业类别的诞生:AI 工作流设计师。 那些能够将人类的工作流程映射并转化为由 AI 增强的工作流的人,将是未来十年薪酬最高的顾问。
19.AI 正在一夜之间创造出“赢家通吃”(Winner-Take-Most)的市场。 在特定垂直领域确立自己领先地位的窗口期可能只有 6 到 12 个月,一旦错过,这个窗口可能会关闭十年。这更让我睡不着了,哈哈。
20.一个非常明智的策略是:用 AI 作为你的“不公平优势”来重构传统产品,并将复杂性隐藏在用户熟悉的界面之后。 基本上,就是找到那些已被市场验证但没有 AI 功能的应用,将它们改造为“AI 优先”(前提是 AI 能为最终客户带来巨大价值)。在由创作者主导的市场营销中,要利用 AI 功能(而不是直接售卖 AI 概念)。这就是(成功的)剧本。
21.渠道(Distribution)是唯一剩下的护城河。 你的产品、技术和团队都可以被复制,但你与客户的直接连接是无法被复制的。
22.我们很快将达到一个临界点:定制化的 AI 工具成本将低于雇佣人力,即使对小企业来说也是如此。
23.没人谈论 AI 如何让那些以前“无法被收购”(通常因为过于依赖创始人)的企业突然变得极具吸引力。 当你能够自动化运营时,“老板依赖型”业务的问题就消失了。
24.即将到来的中小企业(SMB)收购狂潮,将使 2021 年的科技泡沫看起来都显得温和。 当 AI 将运营成本降低 60% 时,每个小企业都将变成一个现金流引擎。
25.如果“氛围感编程”(Vibe Coding)将是一个千亿美元的机会,那么“氛围感营销”(Vibe Marketing)的机会有多大?
26.视频游戏工作室将分化为两种截然不同的类型: 一种是由 AI 智能体驱动、能生成无限量资源的内容工厂;另一种是专注于核心游戏机制的精品工作室。中间地带将完全消失。
27.企业摄影(Corporate Photography)基本上已经消亡了。 没有公司会再花 2000 美元拍摄那种“库存图片”风格的照片,因为他们可以用一个订阅服务的成本生成无限量、完全符合品牌调性的图像。
28.企业销售(Enterprise Sales)模式正被 AI 彻底颠覆。 利用 AI 精准识别接触合适买家的最佳时机和方式,并触发自动化流程。
29.我在想,通用人工智能(AGI)是否会从相互连接的智能体(Agent)网络中涌现出来,产生出无人设计的、自发的复杂特性(Emergent Properties)? 我们可能在不知不觉中正在构建这些(AGI 的)“神经连接”。
30.虽然生成式 AI(GenAI)看起来是万亿美金的赛道,但许多“闷声发大财”的机会将在预测性 AI(Predictive AI)领域诞生。 知道将要发生什么,比生成新内容更有价值。
31.所谓的“AI 泡沫”,实际上是对那些分不清真正创新和简单包装 OpenAI API 的风险投资家(VCs)征收的一种“智商税”(Excise Tax)。
32.交互界面将演变成具有“个性”(Personalities)的存在。 当每个工具都能与你对话时,“氛围感”(Vibe)和“语调”(Tone)将驱动用户的信任、忠诚度和留存率。
33.AI 将终结“首页”(Homepage)的概念。 界面将被动态入口(Entry Points)取代,这些入口会根据用户身份、需求和访问时间而变化。
34.没有人会为“AI”本身付费,他们愿意付费的是能在 3 次点击内解决一个价值 1 万美元/小时的问题。 要售卖结果(Outcomes),隐藏 AI 技术细节。
35.AI 正在“肢解”(Unbundling)谷歌。 每一个垂直搜索引擎、信息目录和比价工具,都是一个伪装起来的、价值数十亿美元的机遇。
36.每个小企业都将拥有一个“幽灵团队”(Ghost Team)。 自动化的会计、销售代理、市场营销人员——全部由一个创始人和 5 个 AI 机器人(Bots)运行。
37.AI 生成的内容正在创造一种思想上的“单一文化”(Monoculture of Ideas)。 当所有人都使用相同的模型时,我们就会得到相同的输出。原创的人类思考正成为最终极的奢侈品。要保持独特(Be weird)。“怪异”将成为卖点(Weird will sell)。
38.学校不会被 AI“颠覆”(Disrupted),而是会被“去中介化”(Disintermediated)。 聪明的青少年会跳过正规教育,去建立自己的受众、进行实验,并更快地学习。孩子们说他们想成为创作者,但创作者正在转变为企业家。创业将成为最受欢迎的职业。
39.18 个月内,80% 的所谓“AI 初创公司”看起来会像垃圾信息(Spam)或诈骗。 其余的将成为基础设施(Infrastructure)。
40.关于产品转化率的争论(例如按钮颜色)已经过时了。 当 AI 焦点小组能在一夜之间测试 200 种方案时,为什么还要为两种颜色争论不休?
41.我们现在所称的“营销”(Marketing)工作,大部分即将由 AI 完成。 人类将转向更上游的工作,专注于讲故事、营造氛围感(Vibes)和塑造品牌活力(Brand Energy)。
42.今年你能做的最佳招聘决策是什么?招聘一位“AI 运营负责人”(Head of AI Ops)。 这个人需要能构建工作流、整合各种工具(Glue Tools)并交付最终成果(Ship Outcomes)。
43.第一个价值 10 亿美元的通用人工智能(AGI)初创公司,最初看起来会像个玩具。 所有改变世界的界面都是如此。
44.AI 驱动的渠道(Distribution) > AI 驱动的产品(Product)。 一个中等水平但拥有顶级触达能力的产品,总能打败一个无人关注的优秀产品。
45.人们仍然讨厌按月订阅(Monthly Subscriptions)。 基于结果的定价(Outcome-Based Pricing)模式仍处于早期阶段。实施这种定价将成为许多公司的竞争优势。大型 SaaS 公司将难以在这一点上与你竞争。
46.我不知道这个机会窗口会敞开多久,但我们正处在一个所有构建商业的规则都正在被重写的时刻。 对于那些正在尝试这些新工具、创建受众和社群的人来说,你们拥有“不公平的优势”(Unfair Advantage)。
希望你能睡个好觉。
by 企业家、投资人 Greg Isenberg」
链接:x.com/gregisenberg/status/1906697683089101113
一篇详细介绍PyTorch的内部结构的文章
https://blog.ezyang.com/2019/05/pytorch-internals/?continueFlag=55716d890e7a793bd69b04f4eb4246c0
特别是张量(Tensor)的实现和自动微分(Autograd)机制。
“本次演讲面向那些使用过 PyTorch,并曾想过“如果能贡献于 PyTorch 该多好”,但又被其庞大的 C++代码库所吓退的你们。实话实说,PyTorch 的代码库有时确实令人望而生畏。本演讲的目的就是为你提供一张地图:介绍“支持自动微分的张量库”的基本概念结构,并给你一些在代码库中导航的工具和技巧。我假设你已经写过一些 PyTorch 代码,但未必深入探究过机器学习库是如何编写的。”
教程 《动手学Ollama,CPU玩转大模型部署》
datawhalechina.github.io/handy-ollama/#/
本教程涵盖从基础入门到进阶使用的全方位内容,并通过实际应用案例深入理解和掌握大模型部署以及应用技术。我们的教程提供清晰的步骤和实用的技巧,无论是刚刚接触大模型部署的小白,还是有一定经验的开发者,都可以从零开始学习 Ollama ,实现本地部署大模型以及相关应用。
本项目主要内容:
Ollama 介绍、安装和配置,包括在 macOS、Windows、Linux 和 Docker 下的安装与配置;
Ollama 自定义导入模型,包括从 GGUF 导入、从 Pytorch 或 Safetensors 导入、由模型直接导入、自定义 Prompt;
Ollama REST API,包括 Ollama API 使用指南、在 Python、Java、JavaScript 和 C++ 等语言中使用 Ollama API;
Ollama 在 LangChain 中的使用,包括在 Python 和 JavaScript 中的集成;
Ollama 可视化界面部署和应用案例,包括使用 FastAPI 和 WebUI 部署可视化对话界面,以及本地 RAG 应用、Agent 应用等。
超实用的前端工具百宝箱:Assorted tools
来自@GitHubDaily
3-15 19:27
跟大家分享一个超实用的前端工具百宝箱:Assorted tools。
国外一名 Simon 开发者,几乎全靠 AI 的帮助下构建的这套实用的 HTML + JavaScript 工具集,同时 Simon 详细记录了其如何利用 LLM 快速构建这些小工具的过程。
GitHub:github.com/simonw/tools
来看看都有那些实用的工具:
- 直接在浏览器里完成 PDF 和图片 OCR 识别,不用担心隐私问题。
- 一系列超方便的图像处理工具:SVG 转换、社媒图片裁剪、EXIF 数据查看等。
- 开发者必备的格式转换工具:JSON/YAML 互转、SQL 美化、Markdown 渲染等。
- 日常开发辅助神器:时间戳转换、多时区比较、PHP 数据反序列化等。
- AI 研究利器:Claude Token 计数、Gemini 图像可视化、OpenAI 音频输出等。
利用 AI 构建每个工具的对话过程,Simon 都详细记录并分享在 GitHub,值得我们学习。
vibe coding
来自@木遥
3-14 14:50
如果你是程序员但还没听说过 vibe coding,那你已经落伍了。
这个词是上个月 Andrej Karpathy 在一篇半自嘲的推文里创造的,现在已经成了标准用语。没有人能精确定义它,但所有熟悉 AI 辅助编程体验的人都多少知道它大概在说什么。一些人对此嗤之以鼻,一些人认为这就是未来,还有更多人勉强让自己适应它。
Vibe coding 创造了一种模糊的实践。用 Andrej Karpathy 自己的话说:「对 AI 的建议我总是接受,不再审阅差异。当我收到错误消息时,我只是复制粘贴它们而不加评论,通常这样就可以解决问题。代码超出了我通常的理解范围。有时它无法修复错误,所以我只是绕过它或要求随机更改,直到它自行消失。」一方面它犹如神助,让你有一种第一次挥舞魔杖的幻觉。另一方面它写了新的忘了旧的,不断重构又原地打转,好像永远在解决问题但永远创造出更多新的问题,并且面对 bug 采取一种振振有词地姿态对你 gaslighting。你面对着层出不穷的工具甚至不知道自己该认真考虑哪个,心知肚明可能下个月就又有了新的「最佳实践」,养成任何肌肉记忆都是一种浪费,而所谓新的最佳实践只不过是用更快的速度产出更隐蔽的 bug 而已。
从技术上来说你可能觉得困难主要在于今天的大语言模型的上下文窗口还不够大,分层长期记忆机制还不够健全,或者别的什么理论上会在未来半年到一年里得到解决的瓶颈。但实际上,vibe coding 打破的是你作为一个程序员的自我认知:你一开始以为自己只是在为了效率做妥协,渐渐地你发现自己陷入在一重又一重建立在浮沙之上的迷宫里精疲力尽,最后你已经忘了效率是什么。
从某种意义上说,今天的 vibe coding 有点像一两年前的 AI 绘画,第一眼很对,放大后细节都是可疑的,到处是六根手指的手。问题在于,绘画远比编程更宽容——毕竟真的存在印象派这种绘画风格——编程难道不理应是非黑即白的吗?
但并不是,正是在这一点上现实开始扭曲起来。你很快就注意到 vibe coding 的「正确性」就像薛定谔的猫一样无法精确观察,你可能每天抱怨 LLM 的注意力窗口太小,而事实是你自己的注意力窗口更小,面对它不费吹灰之力生成的海量代码的冲刷很快就头晕目眩,放弃了审查和控制的执念。你试图借助类似于 .cursorrules 这样的规范来指导 AI,但这就像是野马辔头上的一根想象中的缰绳,你既不确定这些规则是否完备,也无从知道它们是否会被真的遵守。你以为这些原则相当于法律,其实它们只是孔子家语,而社会的运转既依赖于它们的尊崇神圣,也依赖于它们的晦涩模糊。你渐渐不再 care 你的代码是否正确,反正随时在改。Dario Amodei 说未来 3 到 6 个月内,90% 的代码将由 AI 编写,12 个月内几乎所有代码都可能由 AI 生成。在这个即将到来的世界里,六根手指的手应接不暇地出现,然后消失,你开始接受暂时 work 就是一切,变动不居才是事物的恒常。
某种意义上说这是这个时代的本质。当国际新闻和洋葱新闻开始无法分辨,当你发现所有号称追求真实的人最终追求的只不过是逃避认知失调,你所创造(或者你自以为你所创造)的一切也不会摆脱同样的命运。八年前我写过这样一段话:
「躲在一个气泡里的个体可以假定岁月静好,一切宛如昨日幻乐,但这往往是悲剧的起源。他看到的只是一个复杂屈折的世界在更低维度上的投影,一个对狂飙突进的历史湍流的简笔画般的描摹,一个更容易被媒体所采纳和记忆的粗糙叙事,一座层移倒悬重重折射下的海市蜃楼。而真实——如果真实仍然有意义的话——则掉落在幽暗深邃的维度的缝隙里。在那里,一幅粗粝斑驳扭曲异质的图景,会让一个在不经意的一瞥之间扭过头去的观察者惊骇和战栗不已。」
那时我以为世界刚刚开始崩塌。后来我理解了崩塌的不是世界,而是我自己的天真想象。 Vibe 不是真实的某种投射,而是它的实质。一开始你以为世界是一张完美的幕布,然后你在幕布上发现了一两条恼人的裂痕,接着你发现裂痕越来越多,无处不在,直到最后你意识到不断蔓延和生长的裂痕才是你真正生活的地方。It’s not just vibe coding, it’s vibe living
《真正的AI智能体即将到来:告别死板提示词,迎接自主规划时代!》
来自@宝玉xp
推荐阅读:《真正的AI智能体即将到来:告别死板提示词,迎接自主规划时代!》
作者:Alexander Doria
作者的上一篇《模型即产品(The Model is the Product)》微博正文 没看过推荐也一起看看
最近到处都在讨论「智能体」(Agents),但最重要的一次智能体突破却几乎无人察觉。
2025年1月,OpenAI发布了名为 DeepResearch 的O3模型变种,专门用于网页和文档搜索。得益于在浏览任务上的强化学习训练,DeepResearch具备了制定搜索策略、交叉核对信息源、甚至利用反馈获得深层次知识的能力。无独有偶,Anthropic的Claude Sonnet 3.7也成功地将同样的强化学习方法应用于代码领域,在复杂的编程任务中展现出超越以往所有模型编排系统的能力。
正如William Brown在演讲中所说的:「LLM智能体能够完成长时间、多步骤的任务了。」
这一进展促使我们重新思考:什么才是真正的LLM智能体?去年12月,Anthropic提出了一个全新的定义:「LLM智能体能动态地决定自己的执行流程和工具使用方式,并自主控制任务的完成过程。」
与之相对,目前更为普遍的所谓智能体实际上都是工作流系统(workflows),也就是通过预设的代码和规则来协调LLM和工具的系统。例如最近备受关注的Manus AI,经过我的亲自测试后发现,它其实仍存在明显缺陷,这些缺陷早在AutoGPT时代就已经很明显了,特别是在搜索方面表现更差:
- 不能有效制定计划,经常中途卡壳;
- 不能记忆内容,无法处理超过5-10分钟的任务;
- 无法长期有效执行任务,容易因连续的小错误最终彻底失败。
因此,这篇文章提出一个更严谨的「LLM智能体」定义,试图结合有限的官方信息、开放研究进展以及我个人的一些推测,解释智能体究竟是什么、它们将如何改变世界。
LLM智能体的「苦涩教训」
传统的智能体与基础大语言模型(base LLM)完全不同。
在经典的强化学习中,智能体生活在有限制的环境里,就像在迷宫里行走。智能体的每个动作都有物理或规则上的约束。随着训练,它们会逐渐记住路径、总结经验,并探索最佳策略。这一过程被称为「搜索」(search),类似于我们日常使用搜索引擎的点击行为。去年曾经热议的OpenAI Q-star算法,据传就是从1968年著名的搜索算法A-star衍生出来的。
然而,大语言模型(LLM)的基础逻辑恰恰相反:
- 智能体能记住环境,但基础LLM不能,它们只能处理当前窗口内的信息;
- 智能体受现实条件限制,但基础LLM生成的是概率最高的文本,随时可能「跑题」;
- 智能体能规划长期策略,基础LLM却只能做好单步推理,面对多步推理任务很快就会「超载」。
目前,大部分「LLM智能体」的做法都是利用预定义的提示词(prompt)和规则来引导模型。然而,这种方法注定要遇到「苦涩教训」(Bitter Lesson)。所谓苦涩教训是指,人们经常倾向于将自己的知识硬编码进系统中,短期内效果很好,但长期却严重限制了系统的发展。真正的突破总是来自搜索与学习能力的提升,而非人为规则的增加。
这就是为什么类似Manus AI这类工作流系统无法顺利地订机票或教你徒手打虎——它们本质上是被苦涩教训咬了一口。靠提示词和规则无法持续扩展,你必须从根本上设计能够真正搜索、规划、行动的系统。
RL+推理:LLM智能体的制胜秘诀
真正的LLM智能体,应该长什么样呢?官方信息虽然少,但从现有的研究中可以归纳出一些共同特征:
-
强化学习(RL)
LLM智能体采用强化学习进行训练,类似传统的游戏智能体:定义一个目标(奖励),再训练模型通过反复尝试获得这个奖励。 -
草稿模式(Drafts)
模型并非逐字逐句进行训练,而是一次生成一整段文字(draft),再整体进行评估和反馈,从而加强模型的推理能力。 -
结构化输出(rubric)
模型的输出被限定成明确的结构,以便于快速、准确地进行奖励验证。 -
多步训练(如DeepSeek提出的GRPO算法)
模型不是单步训练,而是连续多步训练。例如搜索任务中,模型会不断调整策略、回溯、重新搜索等,逐步提高效率。
上述过程能在不耗费过多计算资源的情况下实现,从而逐渐走向大众化,这将成为未来LLM智能体爆发的基础。
等等,这东西能规模化吗?
然而,要真正实现像DeepResearch这样的搜索智能体,还有一个大问题:我们根本没有足够的训练数据!
过去搜索模型往往只能靠历史数据,而现有的公开数据集中,几乎找不到真正体现用户规划和搜索行为的数据(如点击轨迹)。类似谷歌用户搜索历史这种数据,几乎只能从大公司获得,但这些数据几乎是不对外开放的。
目前能想到的解决方案是:用模拟方式创造数据。我们可以把互联网内容包装成一个虚拟的「网络模拟器」,让模型在里面反复尝试搜索目标,不断优化搜索路径。这种训练过程耗费巨大,但可以通过技术优化来减轻负担。
我推测OpenAI和Anthropic这样的公司,可能就是用类似方法在训练DeepResearch这样的模型:
- 创建虚拟的网络环境,训练模型自由地进行搜索;
- 先用轻量的监督微调(SFT)进行预热;
- 再用强化学习多步训练,不断提高搜索策略;
- 最后再训练模型更好地整理输出结果。
真正的LLM智能体,根本不需要「提示」
当真正的LLM智能体出现之后,它会和现在基于提示词和规则的系统完全不同。回到Anthropic的定义:
LLM智能体动态地决定自己的流程和工具用法,完全自主。
以搜索任务为例:
- 模型自动分析用户需求,如果不明确,会主动询问;
- 模型自主选择最佳的信息源或API接口;
- 模型会自己规划搜索路径,能在走错路时主动调整;
- 所有过程都有记录,提升了可解释性和信任度。
LLM智能体可以直接操纵现有的搜索基础设施,用户再也不用特意学习如何使用「提示词」了。
这种方法同样可以延伸到金融、网络运维等多个领域:未来,一个真正的智能体不再是个花哨的AI助手,而是一个懂你需求、主动帮你完成任务的真正代理。
2025:智能体元年?
目前,只有少数几家大公司有能力开发出真正的LLM智能体。虽然短期内这样的技术可能仍集中在巨头手里,但长远来看,这种局面必须被打破。
我不喜欢过度炒作新技术,但LLM智能体的爆发力不容忽视。2025年会是智能体真正崛起的一年吗?答案还要看我们如何行动。
让我们拭目以待!
OpenAI刚刚发布了一套全新的工具,帮助开发者更轻松地创建AI智能体(Agent)
来自@宝玉xp
3-12 05:07
OpenAI刚刚发布了一套全新的工具,帮助开发者更轻松地创建AI智能体(Agent)。
过去,开发AI智能体时,开发者通常需要自己拼凑不同的API,不仅麻烦,效率也低。OpenAI新推出的三个内置工具有效解决了这些痛点:
第一,Web Search工具,让AI智能体能够实时搜索网络,获取最新的事实信息,回答更准确。
第二,File Search工具,升级后支持元数据筛选和直接访问向量数据库,更好地利用企业或个人私有数据,轻松实现知识检索(RAG)功能。
第三,Computer Use工具,能控制电脑自动执行任务,甚至操作没有API的旧软件,实现复杂任务自动化。
OpenAI同时还推出了全新的Responses API,不仅能支持多轮对话,还能同时调用多个工具,简化复杂流程,提升效率。它将在未来逐步替代Assistant API(计划于2026年停止服务)。
此外,OpenAI的开源智能体编排框架Swarm现已正式升级为Agents SDK,更适合生产环境,支持智能体间的协作、任务交接、流程监控和追踪,开发者只需几行代码就能构建强大的多智能体系统。
OpenAI 首席产品官 Kevin Weil 在直播的最后总结说:“2025 年将会是 AI 智能体爆发的一年, 也是 ChatGPT 和我们开发者工具从‘仅仅回答问题’ 升级为‘真正能在现实世界里为你执行任务’的一年。”
Responses API
来自@AI师傅孙志岗
3-12 11:12
知道 OpenAI 肯定会在 Agent 上大发力,毕竟像 Deep Research、Operator 这类基础设施已经完备了,模型就更不用说了。
本来我以为会是在 ChatGPT 里做个大集成,直接秒掉只能看不能摸 Manus。没成想,居然是推出 Responses API,把强大的 Agent 能力直接打包给了每一个开发者。
这意味着,复刻一个 Manus,在工程上的难度也大大降低了。
但其实,世界上并不需要一个什么都能干的 Agent,而是数亿个把小事做到极致的 Agent。Responses API 让这数亿个 Agent 更容易开发了。
Responses API 直接断了 Manus 的后路。Manus 怎么办?如果是我,会当机立断马上开源,这样才能把自己在工程上的领先地位保持下去。
开源并不只是理想主义,而是一种竞争策略。处于领先地位的产品开源,能阻止后来者的进入,减少竞争。你看 DeepSeek 的开源,让多少公司砍掉了做模型训练的预算。
以前优先闭源,是因为这样能建立技术壁垒,毕竟工程开发量的投入是惊人的。但现在,已经是个没有技术壁垒的时代了。
所有 AI 应用,本质上都是套壳大模型,应用层的开发量越来越少。不然也不会有 OpenManus 秒出。
即便大模型,OpenAI 的技术优势也只保持了 2 年不到。壁垒在哪?
别再幻想构建任何技术壁垒了。真正的壁垒都在技术之外。AI 成功的关键角色,其实是不懂技术的人。
附图秀一下一年半前在一门旧课里写的一段话。
红框里的字从第一天写下就几乎没改过。前面的论述随着课程迭代而更新,最后一次更新时 DeepSeek V3/R1 还没发布。
Manus 现在最优势的,其实只有这个名字,也就是品牌。开源可以强化这个品牌,减少更多竞争对手的进入。
趁着 DeepSeek 一体机浪潮,「私有化 Manus」这个概念,一年做几千万 2B/2G 生意不成问题。
同时也推出 Responses API,至少在国内打个时间差,成为广大 Agent 开发者心中第一品牌,市场地位就能确立了。
当然,开源没那么容易。如果一款产品在开发时没想开源,那么做成能开源的,工作量也不小。祝 Manus 好运!真的很嫉妒你们!
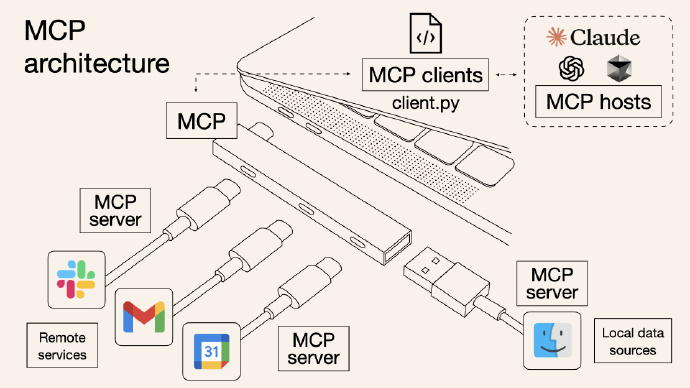
MCP (Model Context Protocol) 及其在 AI 应用和 Agent 中的应用
来自@i陆三金
3-12 20:26
MCP servers 的作者 Mahesh Murag 今年 2 月底在 AI Engineer Summit 上的分享,内容丰富又硬核,推荐,唯一美中不足的是里面的观众提问有点多,视频整体节奏没那么好。
分享主题:MCP (Model Context Protocol) 及其在 AI 应用和 Agent 中的应用
- MCP 的动机与背景:
核心概念: 模型的能力取决于提供的上下文。
演进: 从最初的 Chatbot 手动输入上下文,发展到模型直接连接数据源和工具,实现更强大和个性化的 AI 应用。
MCP 的目标: 作为一个开放协议,实现 AI 应用、Agent 与工具和数据源之间的无缝集成。
- MCP 的类比与构成:
类比API: 标准化 Web 应用前后端交互的方式。
类比LSP (Language Server Protocol): 标准化 IDE 与编程语言特定工具的交互方式。
MCP 的三个主要接口:
-
Prompts: 「用户」控制的预定义模板,用于常见交互。
-
Tools: 「模型」控制的工具,LLM 可以自主决定何时调用。
-
Resources: 「应用」控制的数据,应用可以灵活使用。
注:这三个接口分别是由「用户」、「模型」、「应用」三方控制的,是非常精辟的总结。
- MCP 解决的问题:碎片化
问题: 不同团队构建 AI 系统的方式各不相同,导致碎片化,重复造轮子。
MCP 的愿景: 标准化 AI 开发,应用开发者可以零成本连接到任何 MCP Server。
MCP Server(服务器端): 对各种系统和工具的封装,为 LLM 提供访问接口。 例如数据库、CRM 系统、版本控制系统等。
MCP Clients(客户端): 类似 Cursor、Windsurf 和 Goose 等应用程序。
- MCP 的价值:
-
应用开发者: 一旦应用兼容 MCP,即可连接任何 Server,无需额外工作。
-
工具/API 提供者: 构建一次 MCP Server,即可被各种 AI 应用采用。
-
最终用户: 获得更强大、上下文更丰富的 AI 应用。
-
企业: 明确划分不同团队的职责,加速 AI 应用开发。 例如,数据基础设施团队负责维护 MCP Server,应用团队专注于构建 AI 应用。
- MCP 的采用情况:
AI 应用和 IDE 领域,例如 Github、文档站。
Server 端,已有一千多个社区构建的 Server,以及 Cloudflare、Stripe 等公司的官方集成。
开源社区的积极贡献。
- 构建 MCP 应用:
-
MCP Client(客户端): 调用 Tool,查询 Resource,填充 Prompt。
-
MCP Server(服务器端): 暴露 Tool、Resource 和 Prompt,供 Client 使用。
- Tool、Resource 和 Prompt 的详细解释:
Tool:
-模型控制,LLM 决定何时调用。
- 用于检索数据、发送数据、更新数据库、写入文件等。
Resource:
-
应用控制,应用决定如何使用。
-
用于提供图片、文本文件、JSON 数据等。
-
支持静态和动态资源。
-
支持资源通知,Server 可以主动通知 Client 更新。
Prompt:
-
用户控制,用户手动调用。
-
用于定义常见交互的模板,例如文档问答、代码总结等。
- MCP 与 Agent 的关系:
MCP 是 Agent 的基础协议。
Augmented LLM(增强型LLM): LLM 与检索系统、工具和记忆的结合。 MCP 提供了 LLM 与这些组件交互的标准化方式。
Agent 的核心: Augmented LLM 运行在一个循环中,不断执行任务、调用工具、分析结果。
MCP 的作用: 使 Agent 具备可扩展性,可以在运行时发现新的能力。
- mcp-agent 框架介绍(by LasMile AI):
展示了如何使用 MCP 构建 Agent 系统。
提供了一套用于构建 Agent 的组件:Agent、Task。
简化了 Agent 的构建过程,使开发者可以专注于 Agent 逻辑本身。
通过声明式方式声明 Agent 的任务以及可用的 Server 和 Tool。
- Agent 的协议能力:
Sampling (推断请求): MCP Server 可以请求 Client 执行 LLM 推理调用,而无需 Server 自行集成 LLM。
Composability (可组合性): 任何应用或 API 都可以同时作为 MCP Client 和 MCP Server。
- MCP 路线图:
- 远程服务器和 Auth:
支持 OAuth 2.0 认证,Server 负责处理认证流程。
实现远程托管的 Server,无需用户手动安装和配置。
通过 Session Token 实现 Client 和 Server 的安全交互。
- 注册表(Registry):
统一托管的元数据服务,用于发现和管理 MCP Server。
解决 Server 的发现和发布问题。
支持版本控制、身份验证、安全验证等功能。
强调开发体验和文档。
数字与物理 AI 的相似性远超你的想象
来自@i陆三金
李飞飞丈夫、Salesforce 首席科学家 Silvio Savarese:数字与物理 AI 的相似性远超你的想象
无论是在工厂车间协调机械臂,还是编排多步骤的客户服务响应,所有 AI agents 都需要四个基本组件:
用于存储和检索信息的 Memory,
进行推理和规划的 Brain,
执行行动的 Actuators,
以及感知环境的 Senses。
关键区别在于数字 agents 通过 API 和软件接口运作,而物理 agents 则通过马达和传感器交互。但智能层——即规划、适应和学习的能力——保持一致。
AI 的下一个前沿领域不仅仅是理解和生成语言——它关乎在物理领域中的理解与行动。首先是世界模型:这些 AI 系统理解物理现实如何运作。它们可以被视为大型语言模型的三维物理等价物(LLMs)。与其捕捉词语与文本元素之间的关系不同,它们捕捉的是三维物理物体与其周围环境元素之间的关系——它们如何移动、互动以及占据空间。
“世界行动模型”(WAMs)——不仅理解物理空间,还能在其中实现互动与导航的系统。WAM 现在正学习理解物理定律和现实世界的互动。这些现实世界的交互需要对物理动力学、几何关系和物体恒常性有更深入的理解。




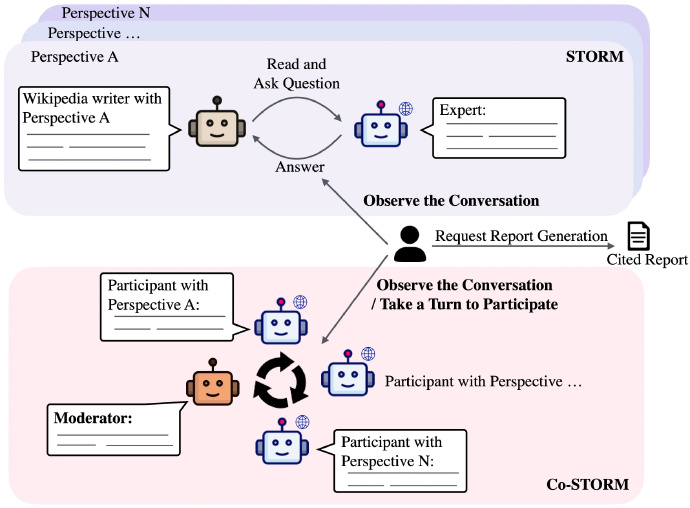
斯坦福大学,在 GitHub 上开源的一款创新型 AI 写作工具:STORM
来自@GitHubDaily
3-5 19:00
来自斯坦福大学,在 GitHub 上开源的一款创新型 AI 写作工具:STORM。
只需输入一个写作主题,它便能自动帮我们深挖资料,从多个角度收集大量参考信息,并生成大纲。
甚至,它还会模拟一位资深专家与我们进行问答对话,并结合联网搜索资源深入了解主题。
最后,逐步完成整篇文章的撰写且附带引用,并且可一键下载 PDF 保存到本地。
GitHub:github.com/stanford-oval/storm
在线体验:storm.genie.stanford.edu
有了这个 AI 工具,相信你也能编写出类似维基百科那种具有深度和广度的文章!
不过目前 STORM 仅支持英文输入,感兴趣的可以去体验下
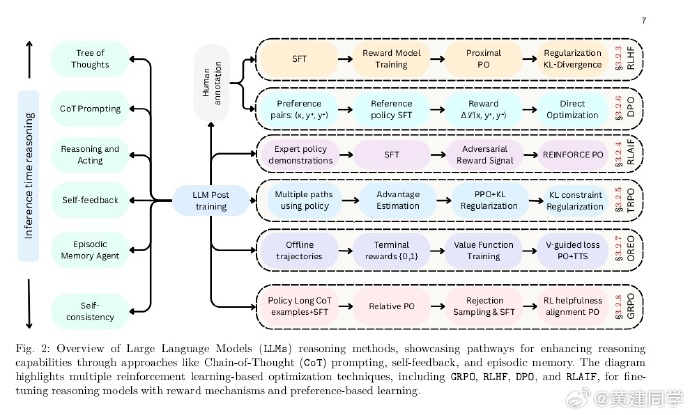
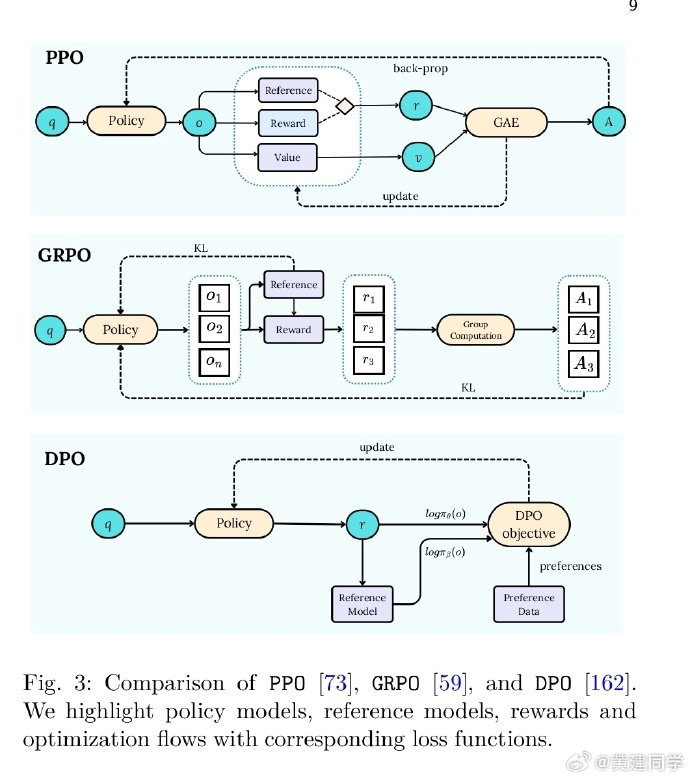
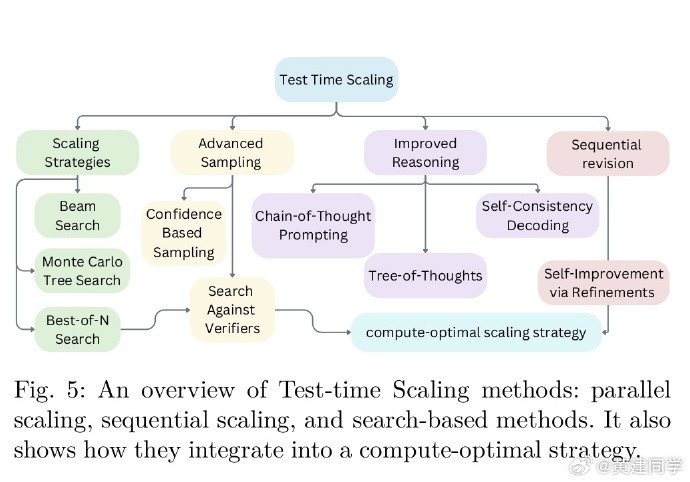
LLM Post-Training:深入探究大型语言模型的推理(A Deep Dive into Reasoning Large Language Models)
摘要:
大型语言模型 (LLM) 已经改变了自然语言处理领域,并为各种应用带来了生机。对大量网络规模数据的预训练为这些模型奠定了基础,但研究界现在越来越多地将重点转向后训练技术,以实现进一步的突破。
虽然预训练提供了广泛的语言基础,但后训练方法使 LLM 能够完善其知识、改进推理、提高事实准确性,并更有效地与用户意图和道德考虑保持一致。微调、强化学习和推理时间扩展已成为优化 LLM 性能、确保稳健性和提高各种实际任务适应性的关键策略。
本调查系统地探索了后训练方法,分析了它们在改进 LLM 方面的作用,超越了预训练,解决了灾难性遗忘、奖励黑客和推理时间权衡等关键挑战。我们重点介绍了模型对齐、可扩展适应和推理时间推理方面的新兴方向,并概述了未来的研究方向。
我们还提供了一个公共存储库,以持续跟踪这个快速发展的领域的发展:github.com/mbzuai-oryx/Awesome-LLM-Post-training
论文:arxiv.org/abs/2502.21321


【arxiv-txt:将arXiv论文转化为大语言模型友好格式的工具。亮点:1. 只需更改URL即可快速获取LLM优化版本;2. 提供API接口,方便开发者集成;3. 通过Next.js和Vercel实现高效部署】
‘Fetch arxiv data to LLM-friendly text’
GitHub: github.com/jerpint/arxiv-txt
一个专注于AI知识分享的网站:aman.ai
这个不是那种随便从网站拷贝一些文章的网站。每一篇都是维护者Aman Chadha(AWS的工程师)写的长文,很多图表和对比数据,尝试为你讲清楚这个概念。比如介绍deepseek r1的文章(目录如图4),直接整了1万多个单词,从MoE、MLA、MTP到强化学习,再到deepseek各个不同版本的对比之类都有。
GitHub 上较火的一个 AI 项目:MiniMind。
此开源项目旨在完全从 0 开始,仅用 3 块钱成本 + 2小时,即可训练出仅为 25.8M 的超小语言模型MiniMind。
GitHub:https://github.com/jingyaogong/minimind?continueFlag=55716d890e7a793bd69b04f4eb4246c0
模型系列极其轻量,最小版本体积是 GPT-3 的 1/7000,力求做到最普通的个人GPU也可快速训练。
项目同时开源了大模型的极简结构-包含拓展共享混合专家(MoE)、数据集清洗、预训练(Pretrain)、监督微调(SFT)、LoRA微调, 直接偏好强化学习(DPO)算法、模型蒸馏算法等全过程代码。
MiniMind 同时拓展了视觉多模态的 VLM: MiniMind-V。
项目所有核心算法代码均从 0 使用 PyTorch 原生重构!不依赖第三方库提供的抽象接口。
这不仅是大语言模型的全阶段开源复现,也是一个入门 LLM 的教程
深度学习的数学原理
arxiv.org/pdf/2407.18384
“本书旨在介绍深度学习数学分析中的核心思想,帮助学生和研究人员快速熟悉该领域,并为大学深度学习数学课程的开发奠定基础。
作为深度学习的数学导论,本书并不试图全面涵盖这一快速发展的领域,部分重要研究方向未被收录。我们侧重数学理论成果而非实证研究,尽管完整的深度学习理论需要两者的结合。
本书主要面向数学及相关领域的研究人员和学生。虽然我们相信每位勤奋的读者都能理解本书内容,但建议具备数学分析、线性代数、概率论和基础泛函分析知识以获得最佳阅读体验。附录中提供了概率论和泛函分析的核心概念回顾。
全书内容围绕深度学习理论的三大支柱展开:
逼近理论(第2-9章)
优化理论(第10-13章)
统计学习理论(第14-16章)”

GitHub 上一本通俗易读的开源书籍《大模型基础》。
涵盖了大语言模型基础、模型架构演化、Prompt 工程、参数高效微调、模型编辑、检索增强生成等内容。
GitHub:github.com/ZJU-LLMs/Foundations-of-LLMs
共有 6 个章节,每章围绕一种动物展开讲解,并通过举例说明具体技术,让我们更容易读懂。

AceCode
来自@黄建同学
随着DeepSrek的火爆🔥🔥🔥,现在数学模型的训练已经开始采用 RL/DeepSeek-R1 方法,但代码生成模型却还没有。原因是什么?缺乏可验证的训练数据,几乎没有可靠的奖励模型。
AceCoder这个项目正在改变这一现状🚀
1️⃣ 提出了一种自动化流程,能大规模生成高质量、可验证的代码训练数据(instruction, [test cases])。生成的程序可运行测试用例,计算通过率作为基于规则的奖励信号。
2️⃣ 训练出的 AceCode-RM(7B & 32B 奖励模型)在 Best-of-N 采样下,使 Llama-3.1 的表现提升 10%。甚至让 Qwen2.5-coder-7B 逼近 DeepSeek-V2.5,在 HumanEval、MBPP、BigCodeBench 等基准上都有显著提升!
3️⃣ 结合 AceCode-RM 和基于规则的奖励信号进行强化学习训练,大幅提升了 Qwen2.5 系列模型的能力。
4️⃣ 类似 DeepSeek R1 的训练(跳过SFT直接进行RL),只需 80 步,从 Qwen2.5-coder-base 直接提升 HumanEval-plus 25%、MBPP-plus 6%!这验证了代码模型可以跳过 SFT 直接进入强化学习训练的可能性。
项目:github.com/TIGER-AI-Lab/AceCoder/
论文:arxiv.org/abs/2502.01718
使用DeepSeek-R1蒸馏属于自己推理小模型!
昨天介绍了使用DeepSeek-R1蒸馏出普通模型,今天是蒸馏出推理模型!
还记得那个复现DeepSeek-R1的aha时刻(可以理解成顿悟,模型能推理了)的项目Tiny -Zero吗?但是这个项目门槛比较高,需要4块A100显卡。
然后unsloth团队使用了GRPO这个项目,成功将成本降低到只需要7GB显存就能蒸馏出 Qwen2.5-1.5B 大小的推理模型!笔记本都能蒸馏!
如果使用15GB显存,就能处理llama-3.1-8B, Mistral-12B, 这种大小的模型了!
详细请看:github.com/unslothai/unsloth/releases/tag/2025-02
Open R1:DeepSeek-R1的完全开源复现🔥🔥🔥
Hugging Face推出Open R1,这是对DeepSeek-R1的开源复现项目,旨在让每个人都能重现并基于R1管道进行构建和改进。项目设计简洁直观,包含以下主要模块:
-
训练与评估:提供脚本用于模型训练、评估以及生成合成数据。
-
多阶段流程:通过清晰的步骤复制DeepSeek-R1的技术报告,包括蒸馏模型、强化学习管道以及多阶段训练。
Open R1旨在搭建完整的R1管道,分为三大步骤:
-
蒸馏模型复现:从高质量语料中提取数据,训练R1蒸馏模型。
-
强化学习(RL)训练:通过大规模数据集,复现R1-Zero的纯RL管道。
-
多阶段训练:从基础模型出发,通过多阶段训练实现强化学习微调。
访问:github.com/huggingface/open-r1
alphaxiv 网站
喜欢看 arxiv 上论文的朋友推荐使用 alphaxiv 这个网站看论文,官方出品,集成了 AI 功能还免费喜欢看 arxiv 上论文的朋友推荐使用 alphaxiv.org 这个网站看论文,官方 arxiv labs 出品,集成了 AI 功能,你不仅可以基于某篇论文进行问答,还可以通过 @ 引用其他论文的章节,有些类似于 AI 代码编辑器 Cursor 中 @ 引用其他代码文件或里面的方法。
另外在它上面还可以对论文点赞,点赞多的会进入排行榜,通过排行榜,就不担心错过热门优质论文。
在对论文问答时,你可以选择 Gemini 2 或者 Claude 3.5 模型,目前应该是免费的。
它有个论坛,可以就某个话题讨论,也可以针对论文评论,最初只允许拥有验证过的高校邮箱或电话号码的用户发表评论,现在任何人都可以注册账号并发表评论,但也可以选择公开关联自己的机构或学术身份(如 ORCID)。
很多细节在他们官方博客上有介绍:https://www.alphaxiv.org/blog/one-year?continueFlag=55716d890e7a793bd69b04f4eb4246c0
R1-V:以不到 3 美元的成本增强视觉语言模型的超泛化能力
来自@黄建同学
这个开源的 R1-V 厉害了!2B模型仅用 100 个训练步就超越了 72B,成本不到 3 美元。
项目使用具有可验证奖励的 RL 来激励 VLM 学习一般计数能力。
——
R1-V:以不到 3 美元的成本增强视觉语言模型的超泛化能力
-
我们首先揭示,对于视觉语言模型,可验证奖励的强化学习 (RLVR)在有效性和分布外 (OOD)稳健性方面均优于思路链监督微调 (CoT-SFT) 。
-
在我们的实验中,我们激励VLM 学习可泛化的视觉计数能力,而不是过度拟合训练集。
-
仅用100 个训练步骤,2B 模型在 OOD 测试中就优于 72B 模型。
-
该训练在 8 块 A100 GPU 上进行了30 分钟,费用为 2.62 美元。
-
代码、模型、数据集、更多细节和所有开源资源将会共享(春节假期内)。
访问:github.com/Deep-Agent/R1-V
如何用DeepSeek-R1蒸馏出属于你自己的大模型?
发现了一个新的fune-tune框架,可以在1小时内让DeepSeek-R1蒸馏出属于你自己的小模型,整个过程是全自动的,不需要编写代码或者手动调节,仅需定义你的数据集即可。这意味着假设你是一个医生,完全可以基于过往的病例,在本地使用DeepSeek-R1构建一个属于你自己的医学专业模型!
框架地址:github.com/Kiln-AI/Kiln
教程文档:docs.getkiln.ai/docs/fine-tuning-guide