快手Keye-VL 1.5开源128K上下文+0.1秒级视频定位+跨模态推理,引领视频理解新标杆
人工智能和多模态学习领域,视频理解技术的突破为各类应用提供了强大的支持。快手近期开源了其创新性的大型多模态推理模型——Keye-VL 1.5,该模型具备超长的上下文窗口、0.1秒级的视频时序定位能力,并支持视频与文本之间的跨模态推理。这一技术的发布,标志着视频理解和智能推理能力的新高峰。
Keye-VL 1.5:全面提升视频理解与推理能力
Keye-VL 1.5的优势主要体现在三个方面:
- 128K上下文窗口: Keye-VL 1.5通过创新的Slow-Fast双路编码机制,支持128K超长的上下文窗口,使得模型能够在处理视频内容时考虑到更多的历史信息,从而提高视频理解的深度和准确性。
- 0.1秒级视频时序定位: 该模型能够精确到0.1秒的粒度识别视频中物品或场景的出现时刻。这一时序能力极大提升了视频内容的精确度,尤其适用于带货视频等短视频场景,能够准确判断关键事件发生的具体时刻。
- 跨模态推理: 除了基本的视频理解,Keye-VL 1.5还能够进行跨模态推理,结合视频内容和文本信息推断出可能的后续事件,提供更加完整的事件链分析。例如,在视频中,模型能够根据宠物之间的互动推测出行为背后的原因。
技术创新:快慢编码与多阶段预训练
Keye-VL 1.5不仅仅是在视频理解上做出了突破,还通过以下技术创新提升了模型的整体性能:
- 快慢编码机制: Keye-VL 1.5采用了“快帧”和“慢帧”两种处理策略。快帧用于静态场景的高帧率处理,慢帧则保留高分辨率细节,确保在高效运算的同时保留关键图像信息。这一策略让模型在不牺牲速度的情况下,提高了计算效率。
- 四阶段渐进式预训练: Keye-VL 1.5的训练过程经历了四个阶段,从视觉编码器的预训练到跨模态对齐,再到多任务优化和退火训练,最终使得模型能够在多个视频理解基准测试中超越同类模型。
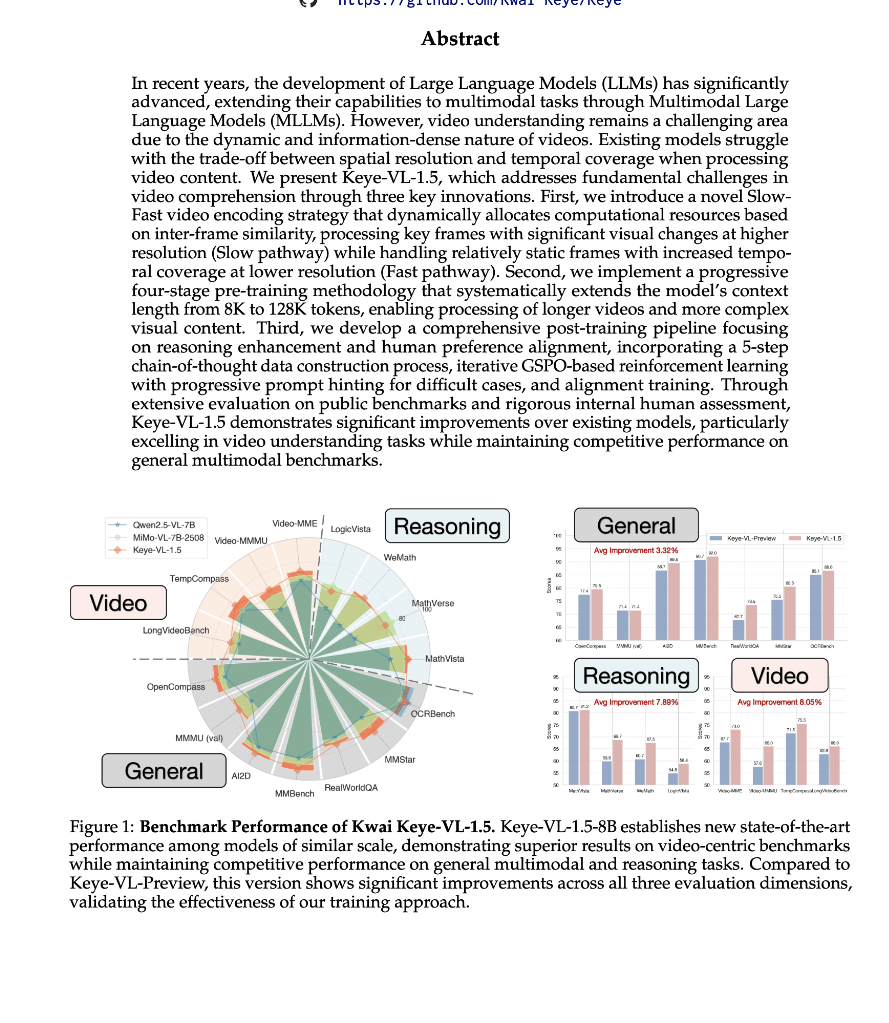
在多个基准测试中领先,开创视频理解新标准
Keye-VL 1.5在多个公开基准测试中表现出色,获得了视频理解领域的多个SOTA(state-of-the-art)成绩。在Video-MME、TempCompass和LongVideoBench等测试中,Keye-VL 1.5均表现超越Qwen2.5-VL 7B等同类模型。特别是在MMBench和OpenCompass等基准中,Keye-VL 1.5的成绩在同尺寸模型中遥遥领先。
此外,Keye-VL 1.5也在AI2D、OCRBench等视觉推理强相关的数据集中表现突出,充分展示了其在图像和视频理解方面的强大能力。
如何实现这些突破:Keye团队的技术积淀
Keye-VL 1.5的突破离不开Keye团队在多模态学习和视频理解方面的深厚积累。团队利用ViT(视觉Transformer)结合语言解码器的架构,并引入了3DRoPE和Slow-Fast编码等技术,使得模型能够同时处理高分辨率和高帧率的视频内容,确保信息的完整性和时序的精准度。
模型权重与在线演示
快手已经将Keye-VL 1.5的模型权重公开,并提供了基于Hugging Face平台的在线演示。研究人员和开发者可以轻松访问和测试该模型,以验证其在实际应用中的表现。
- 模型权重: Keye-VL 1.5-8B模型权重
- 在线演示: Keye-VL 1.5在线DEMO
总结
随着快手Keye-VL 1.5的开源,视频理解和跨模态推理技术迈上了新的台阶。凭借其强大的时序定位、跨模态推理和创新性编码策略,Keye-VL 1.5为智能视频分析提供了新的技术框架,并为各类短视频应用场景,如电商带货、智能剪辑、视频搜索等,提供了强有力的技术支撑。