人工智能学习:鸢尾花数据获取
一,鸢尾花数据的处理
首先导入sklearn的包,从sklearn.datasets里导入load_iris方法,接着就可以获取到鸢尾花的数据,我们可以看到输出的结果是字典类型的。
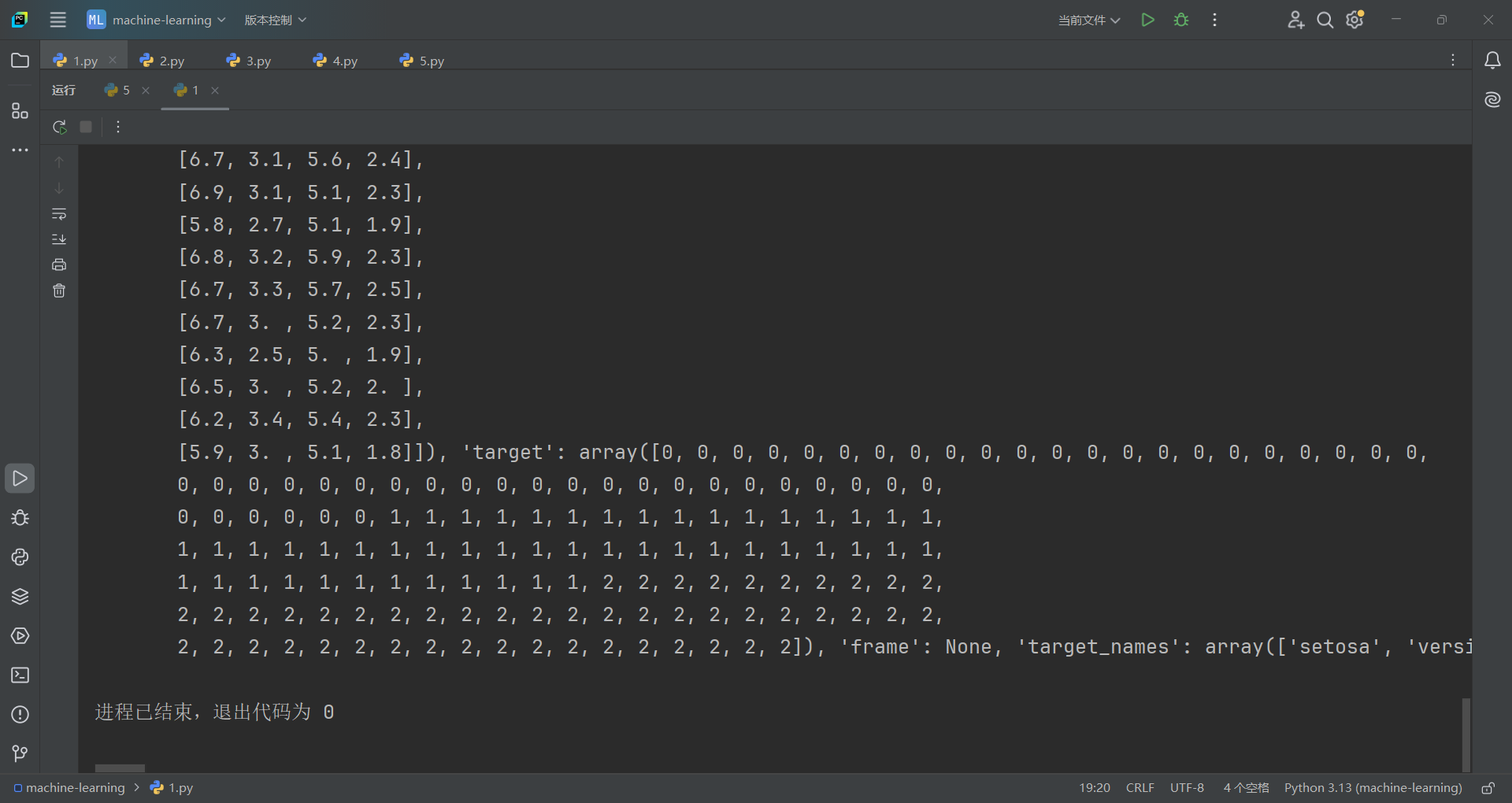
获取的代码如下:
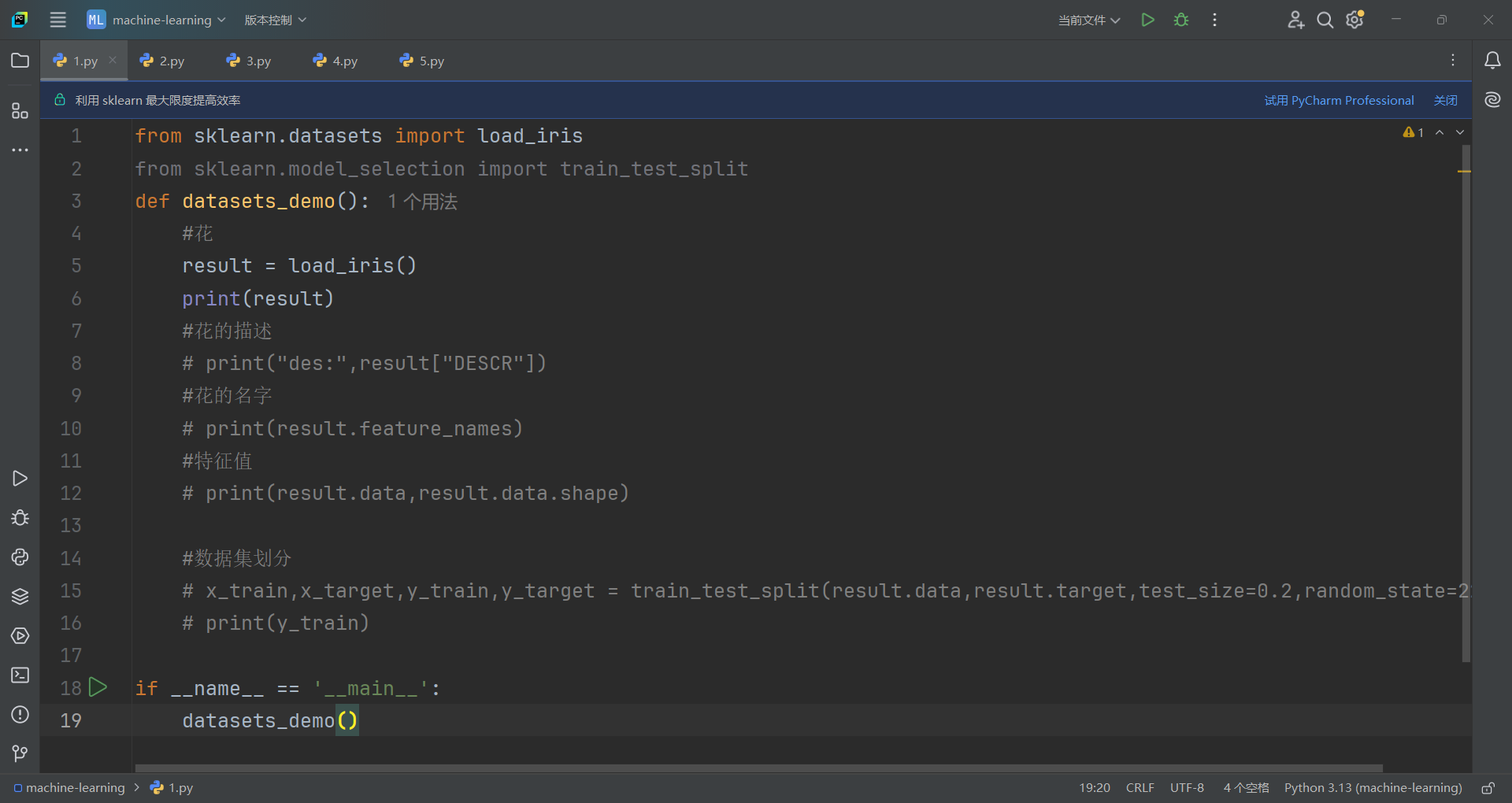
字典数据有两个获取方法:
一种是[],另一种是.
二,训练集,数据集的划分
首先从sklearn.model_selection模块中导入train_test_split方法,需注意的是train_test_split方法有四个返回值。
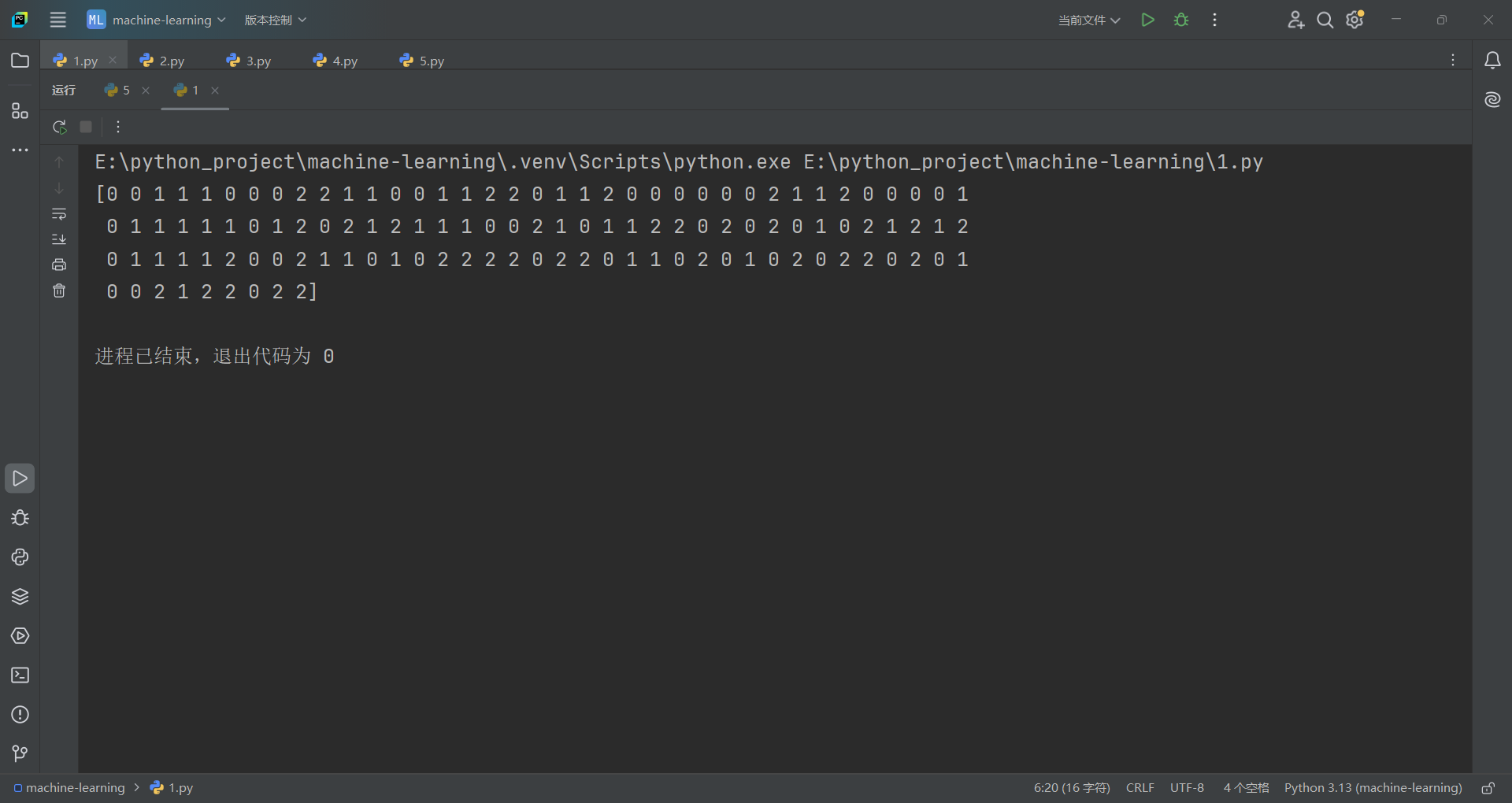
一,鸢尾花数据的处理
首先导入sklearn的包,从sklearn.datasets里导入load_iris方法,接着就可以获取到鸢尾花的数据,我们可以看到输出的结果是字典类型的。
获取的代码如下:
字典数据有两个获取方法:
一种是[],另一种是.
二,训练集,数据集的划分
首先从sklearn.model_selection模块中导入train_test_split方法,需注意的是train_test_split方法有四个返回值。