Redis进阶(上)
Redis系统架构中各个处理模块是干什么的?
Redis 系统架构
本课时,我将进一步分析 Redis 的系统架构,重点讲解 Redis 系统架构的事件处理机制、数据管理、功能扩展、系统扩展等内容。
事件处理机制
Redis 组件的系统架构如图所示,主要包括事件处理、数据存储及管理、用于系统扩展的主从复制/集群管理,以及为插件化功能扩展的 Module System 模块。
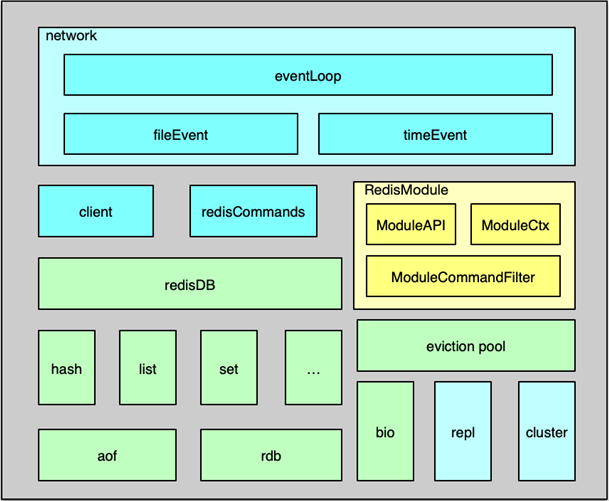
Redis 中的事件处理模块,采用的是作者自己开发的 ae 事件驱动模型,可以进行高效的网络 IO 读写、命令执行,以及时间事件处理。
其中,网络 IO 读写处理采用的是 IO 多路复用技术,通过对 evport、epoll、kqueue、select 等进行封装,同时监听多个 socket,并根据 socket 目前执行的任务,来为 socket 关联不同的事件处理器。
当监听端口对应的 socket 收到连接请求后,就会创建一个 client 结构,通过 client 结构来对连接状态进行管理。在请求进入时,将请求命令读取缓冲并进行解析,并存入到 client 的参数列表。
然后根据请求命令找到 对应的redisCommand ,最后根据命令协议,对请求参数进一步的解析、校验并执行。Redis 中时间事件比较简单,目前主要是执行 serverCron,来做一些统计更新、过期 key 清理、AOF 及 RDB 持久化等辅助操作。
数据管理
Redis 的内存数据都存在 redisDB 中。Redis 支持多 DB,每个 DB 都对应一个 redisDB 结构。Redis 的 8 种数据类型,每种数据类型都采用一种或多种内部数据结构进行存储。同时这些内部数据结构及数据相关的辅助信息,都以 kye/value 的格式存在 redisDB 中的各个 dict 字典中。
数据在写入 redisDB 后,这些执行的写指令还会及时追加到 AOF 中,追加的方式是先实时写入AOF 缓冲,然后按策略刷缓冲数据到文件。由于 AOF 记录每个写操作,所以一个 key 的大量中间状态也会呈现在 AOF 中,导致 AOF 冗余信息过多,因此 Redis 还设计了一个 RDB 快照操作,可以通过定期将内存里所有的数据快照落地到 RDB 文件,来以最简洁的方式记录 Redis 的所有内存数据。
Redis 进行数据读写的核心处理线程是单线程模型,为了保持整个系统的高性能,必须避免任何kennel 导致阻塞的操作。为此,Redis 增加了 BIO 线程,来处理容易导致阻塞的文件 close、fsync 等操作,确保系统处理的性能和稳定性。
在 server 端,存储内存永远是昂贵且短缺的,Redis 中,过期的 key 需要及时清理,不活跃的 key 在内存不足时也可能需要进行淘汰。为此,Redis 设计了 8 种淘汰策略,借助新引入的 eviction pool,进行高效的 key 淘汰和内存回收。
功能扩展
Redis 在 4.0 版本之后引入了 Module System 模块,可以方便使用者,在不修改核心功能的同时,进行插件化功能开发。使用者可以将新的 feature 封装成动态链接库,Redis 可以在启动时加载,也可以在运行过程中随时按需加载和启用。
在扩展模块中,开发者可以通过 RedisModule_init 初始化新模块,用 RedisModule_CreateCommand 扩展各种新模块指令,以可插拔的方式为 Redis 引入新的数据结构和访问命令。
系统扩展
Redis作者在架构设计中对系统的扩展也倾注了大量关注。在主从复制功能中,psyn 在不断的优化,不仅在 slave 闪断重连后可以进行增量复制,而且在 slave 通过主从切换成为 master 后,其他 slave 仍然可以与新晋升的 master 进行增量复制,另外,其他一些场景,如 slave 重启后,也可以进行增量复制,大大提升了主从复制的可用性。使用者可以更方便的使用主从复制,进行业务数据的读写分离,大幅提升 Redis 系统的稳定读写能力。
通过主从复制可以较好的解决 Redis 的单机读写问题,但所有写操作都集中在 master 服务器,很容易达到 Redis 的写上限,同时 Redis 的主从节点都保存了业务的所有数据,随着业务发展,很容易出现内存不够用的问题。
为此,Redis 分区无法避免。虽然业界大多采用在 client 和 proxy 端分区,但 Redis 自己也早早推出了 cluster 功能,并不断进行优化。Redis cluster 预先设定了 16384 个 slot 槽,在 Redis 集群启动时,通过手动或自动将这些 slot 分配到不同服务节点上。在进行 key 读写定位时,首先对 key 做 hash,并将 hash 值对 16383 ,做 按位与运算,确认 slot,然后确认服务节点,最后再对 对应的 Redis 节点,进行常规读写。如果 client 发送到错误的 Redis 分片,Redis 会发送重定向回复。如果业务数据大量增加,Redis 集群可以通过数据迁移,来进行在线扩容。
Redis如何处理文件事件和时间事件?
Redis时间驱动模型
Redis 是一个事件驱动程序,但和 Memcached 不同的是,Redis 并没有采用 libevent 或 libev 这些开源库,而是直接开发了一个新的事件循环组件。Redis 作者给出的理由是,尽量减少外部依赖,而自己开发的事件模型也足够简洁、轻便、高效,也更易控制。Redis 的事件驱动模型机制封装在 aeEventLoop 等相关的结构体中,网络连接、命令读取执行回复,数据的持久化、淘汰回收 key 等,几乎所有的核心操作都通过 ae 事件模型进行处理。
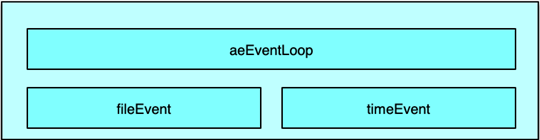
Redis 的事件驱动模型处理 2 类事件:
- 文件事件,如连接建立、接受请求命令、发送响应等;
- 时间事件,如 Redis 中定期要执行的统计、key 淘汰、缓冲数据写出、rehash等。
文件事件处理
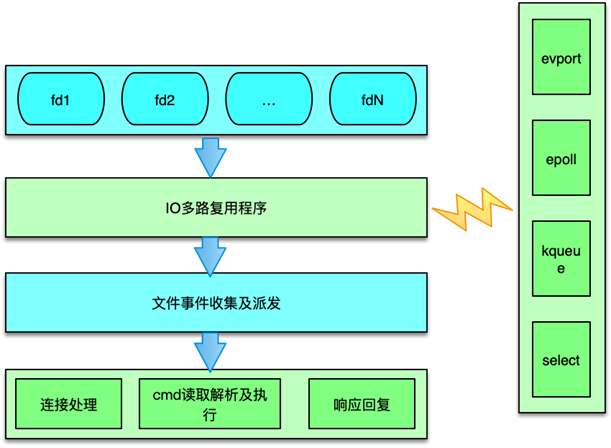
Redis 的文件事件采用典型的 Reactor 模式进行处理。Redis 文件事件处理机制分为 4 部分:
- 连接socket
- IO多路复用程序
- 文件事件分派器
- 事件处理器
文件事件是对连接 socket 操作的一个抽象。当端口监听 socket 准备 accept 新连接,或者连接 socket 准备好读取请求、写入响应、关闭时,就会产生一个文件事件。IO 多路复用程序负责同时监听多个 socket,当这些 socket 产生文件事件时,就会触发事件通知,文件分派器就会感知并获取到这些事件。
虽然多个文件事件可能会并发出现,但 IO 多路复用程序总会将所有产生事件的 socket 放入一个队列中,通过这个队列,有序的把这些文件事件通知给文件分派器。
IO多路复用
Redis 封装了 4 种多路复用程序,每种封装实现都提供了相同的 API 实现。编译时,会按照性能和系统平台,选择最佳的 IO 多路复用函数作为底层实现,选择顺序是,首先尝试选择 Solaries 中的 evport,如果没有,就尝试选择 Linux 中的 epoll,否则就选择大多 UNIX 系统都支持的 kqueue,这 3 个多路复用函数都直接使用系统内核内部的结构,可以服务数十万的文件描述符。
如果当前编译环境没有上述函数,就会选择 select 作为底层实现方案。select 方案的性能较差,事件发生时,会扫描全部监听的描述符,事件复杂度是 O(n),并且只能同时服务有限个文件描述符,32 位机默认是 1024 个,64 位机默认是 2048 个,所以一般情况下,并不会选择 select 作为线上运行方案。Redis 的这 4 种实现,分别在 ae_evport、ae_epoll、ae_kqueue 和 ae_select 这 4 个代码文件中。
文件事件收集及派发器
Redis 中的文件事件分派器是 aeProcessEvents 函数。它会首先计算最大可以等待的时间,然后利用 aeApiPoll 等待文件事件的发生。如果在等待时间内,一旦 IO 多路复用程序产生了事件通知,则会立即轮询所有已产生的文件事件,并将文件事件放入 aeEventLoop 中的 aeFiredEvents 结构数组中。每个 fired event 会记录 socket 及 Redis 读写事件类型。
这里会涉及将多路复用中的事件类型,转换为 Redis 的 ae 事件驱动模型中的事件类型。以采用 Linux 中的 epoll 为例,会将 epoll 中的 EPOLLIN 转为 AE_READABLE 类型,将 epoll 中的 EPOLLOUT、EPOLLERR 和 EPOLLHUP 转为 AE_WRITABLE 事件。
aeProcessEvents 在获取到触发的事件后,会根据事件类型,将文件事件 dispatch 派发给对应事件处理函数。如果同一个 socket,同时有读事件和写事件,Redis 派发器会首先派发处理读事件,然后再派发处理写事件。
文件事件处理函数分类
Redis 中文件事件函数的注册和处理主要分为 3 种。
- 连接处理函数 acceptTcpHandler
Redis 在启动时,在 initServer 中对监听的 socket 注册读事件,事件处理器为 acceptTcpHandler,该函数在有新连接进入时,会被派发器派发读任务。在处理该读任务时,会 accept 新连接,获取调用方的 IP 及端口,并对新连接创建一个 client 结构。如果同时有大量连接同时进入,Redis 一次最多处理 1000 个连接请求。
- readQueryFromClient 请求处理函数
连接函数在创建 client 时,会对新连接 socket 注册一个读事件,该读事件的事件处理器就是 readQueryFromClient。在连接 socket 有请求命令到达时,IO 多路复用程序会获取并触发文件事件,然后这个读事件被派发器派发给本请求的处理函数。readQueryFromClient 会从连接 socket 读取数据,存入 client 的 query 缓冲,然后进行解析命令,按照 Redis 当前支持的 2 种请求格式,及 inline 内联格式和 multibulk 字符块数组格式进行尝试解析。解析完毕后,client 会根据请求命令从命令表中获取到对应的 redisCommand,如果对应 cmd 存在。则开始校验请求的参数,以及当前 server 的内存、磁盘及其他状态,完成校验后,然后真正开始执行 redisCommand 的处理函数,进行具体命令的执行,最后将执行结果作为响应写入 client 的写缓冲中。
- 命令回复处理器 sendReplyToClient
当 redis需要发送响应给client时,Redis 事件循环中会对client的连接socket注册写事件,这个写事件的处理函数就是sendReplyToClient。通过注册写事件,将 client 的socket与 AE_WRITABLE 进行间接关联。当 Client fd 可进行写操作时,就会触发写事件,该函数就会将写缓冲中的数据发送给调用方。
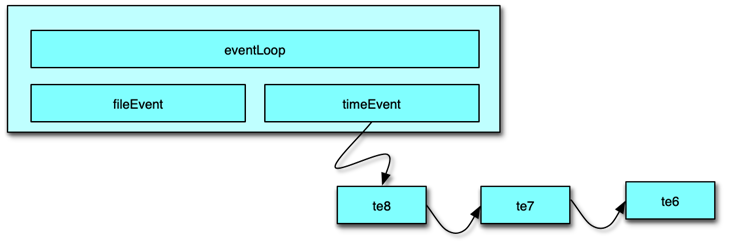
Redis 中的时间事件是指需要在特定时间执行的事件。多个 Redis 中的时间事件构成 aeEventLoop 中的一个链表,供 Redis 在 ae 事件循环中轮询执行。
Redis 当前的主要时间事件处理函数有 2 个:
- serverCron
- moduleTimerHandler
Redis 中的时间事件分为 2 类:
- 单次时间,即执行完毕后,该时间事件就结束了。
- 周期性事件,在事件执行完毕后,会继续设置下一次执行的事件,从而在时间到达后继续执行,并不断重复。
时间事件主要有 5 个属性组成。
- 事件 ID:Redis 为时间事件创建全局唯一 ID,该 ID 按从小到大的顺序进行递增。
- 执行时间 when_sec 和 when_ms:精确到毫秒,记录该事件的到达可执行时间。
- 时间事件处理器 timeProc:在时间事件到达时,Redis 会调用相应的 timeProc 处理事件。
- 关联数据 clientData:在调用 timeProc 时,需要使用该关联数据作为参数。
- 链表指针 prev 和 next:它用来将时间事件维护为双向链表,便于插入及查找所要执行的时间事件。
时间事件的处理是在事件循环中的 aeProcessEvents 中进行。执行过程是:
- 首先遍历所有的时间事件。
- 比较事件的时间和当前时间,找出可执行的时间事件。
- 然后执行时间事件的 timeProc 函数。
- 执行完毕后,对于周期性时间,设置时间新的执行时间;对于单次性时间,设置事件的 ID为 -1,后续在事件循环中,下一次执行 aeProcessEvents 的时候从链表中删除。
Redis读取请求数据后,如何进行协议解析和处理?
协议解析
上一课时讲到,请求命令进入,触发 IO 读事件后。client 会从连接文件描述符读取请求,并存入 client 的 query buffer 中。client 的读缓冲默认是 16KB,读取命令时,如果发现请求超过 1GB,则直接报异常,关闭连接。
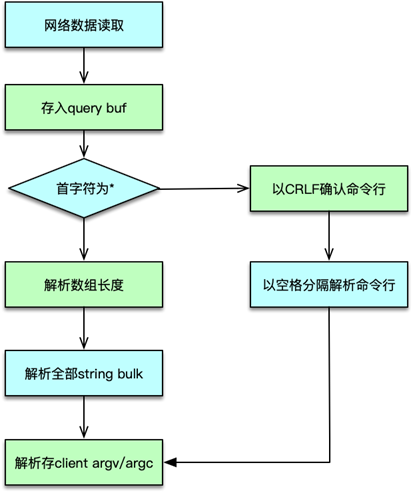
client 读取完请求命令后,则根据 query buff 进行协议解析。协议解析时,首先查看协议的首字符。如果是 *,则解析为字符块数组类型,即 MULTIBULK。否则请求解析为 INLINE 类型。
INLINE 类型是以 CRLF 结尾的单行字符串,协议命令及参数以空格分隔。解析过程参考之前课程里分析的对应协议格式。协议解析完毕后,将请求参数个数存入 client 的 argc 中,将请求的具体参数存入 client 的 argv 中。
协议执行
请求命令解析完毕,则进入到协议执行部分。协议执行中,对于 quit 指令,直接返回 OK,设置 flag 为回复后关闭连接。
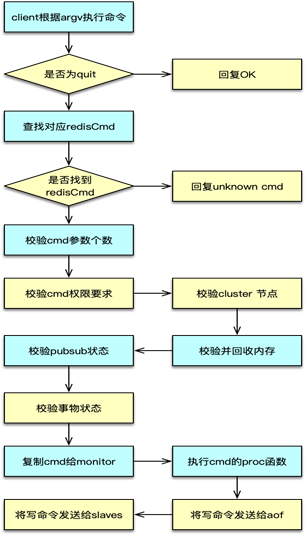
对于非 quit 指令,以 client 中 argv[0] 作为命令,从 server 中的命令表中找到对应的 redisCommand。如果没有找到 redisCommand,则返回未知 cmd 异常。如果找到 cmd,则开始执行 redisCommand 中的 proc 函数,进行具体命令的执行。在命令执行完毕后,将响应写入 client 的写缓冲。并按配置和部署,将写指令分发给 aof 和 slaves。同时更新相关的统计数值。
怎么认识和应用Redis内部数据结构?
RedisDb
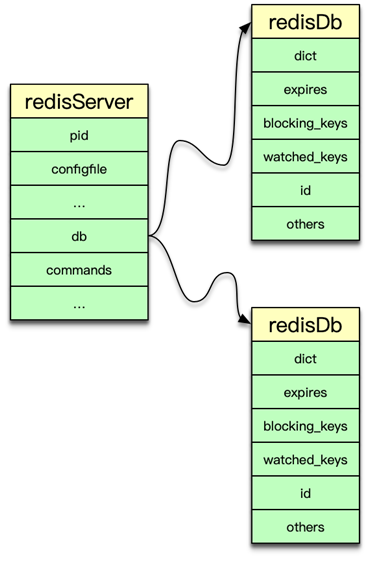
Redis 中所有数据都保存在 DB 中,一个 Redis 默认最多支持 16 个 DB。Redis 中的每个 DB 都对应一个 redisDb 结构,即每个 Redis 实例,默认有 16 个 redisDb。用户访问时,默认使用的是 0 号 DB,可以通过 select $dbID 在不同 DB 之间切换。
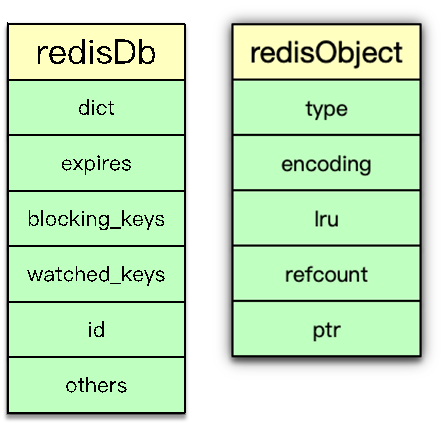
redisDb 主要包括 2 个核心 dict 字典、3 个非核心 dict 字典、dbID 和其他辅助属性。2 个核心 dict 包括一个 dict 主字典和一个 expires 过期字典。主 dict 字典用来存储当前 DB 中的所有数据,它将 key 和各种数据类型的 value 关联起来,该 dict 也称 key space。过期字典用来存储过期时间 key,存的是 key 与过期时间的映射。日常的数据存储和访问基本都会访问到 redisDb 中的这两个 dict。
3 个非核心 dict 包括一个字段名叫 blocking_keys 的阻塞 dict,一个字段名叫 ready_keys 的解除阻塞 dict,还有一个是字段名叫 watched_keys 的 watch 监控 dict。
在执行 Redis 中 list 的阻塞命令 blpop、brpop 或者 brpoplpush 时,如果对应的 list 列表为空,Redis 就会将对应的 client 设为阻塞状态,同时将该 client 添加到 DB 中 blocking_keys 这个阻塞 dict。所以该 dict 存储的是处于阻塞状态的 key 及 client 列表。
当有其他调用方在向某个 key 对应的 list 中增加元素时,Redis 会检测是否有 client 阻塞在这个 key 上,即检查 blocking_keys 中是否包含这个 key,如果有则会将这个 key 加入 read_keys 这个 dict 中。同时也会将这个 key 保存到 server 中的一个名叫 read_keys 的列表中。这样可以高效、不重复的插入及轮询。
当 client 使用 watch 指令来监控 key 时,这个 key 和 client 就会被保存到 watched_keys 这个 dict 中。redisDb 中可以保存所有的数据类型,而 Redis 中所有数据类型都是存放在一个叫 redisObject 的结构中。
redisObject
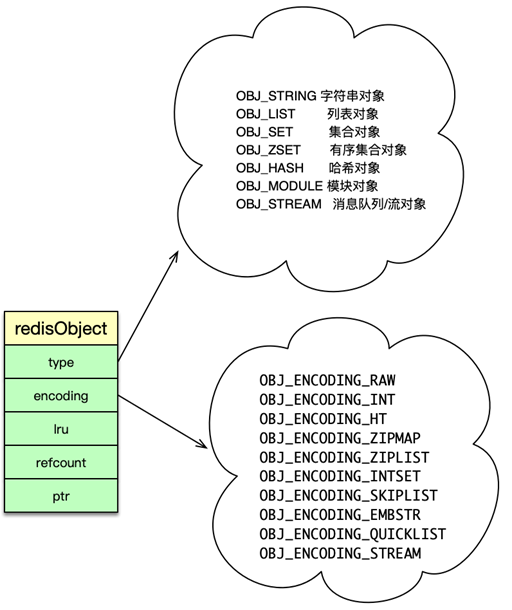
redisObject 由 5 个字段组成。
- type:即 Redis 对象的数据类型,目前支持 7 种 type 类型,分别为
- OBJ_STRING
- OBJ_LIST
- OBJ_SET
- OBJ_ZSET
- OBJ_HASH
- OBJ_MODULE
- OBJ_STREAM
- encoding:Redis 对象的内部编码方式,即内部数据结构类型,目前支持 10 种编码方式包括
- OBJ_ENCODING_RAW
- OBJ_ENCODING_INT
- OBJ_ENCODING_HT
- OBJ_ENCODING_ZIPLIST 等。
- LRU:存储的是淘汰数据用的 LRU 时间或 LFU 频率及时间的数据。
- refcount:记录 Redis 对象的引用计数,用来表示对象被共享的次数,共享使用时加 1,不再使用时减 1,当计数为 0 时表明该对象没有被使用,就会被释放,回收内存。
- ptr:它指向对象的内部数据结构。比如一个代表 string 的对象,它的 ptr 可能指向一个 sds 或者一个 long 型整数。
dict
前面讲到,Redis 中的数据实际是存在 DB 中的 2 个核心 dict 字典中的。实际上 dict 也是 Redis 的一种使用广泛的内部数据结构。
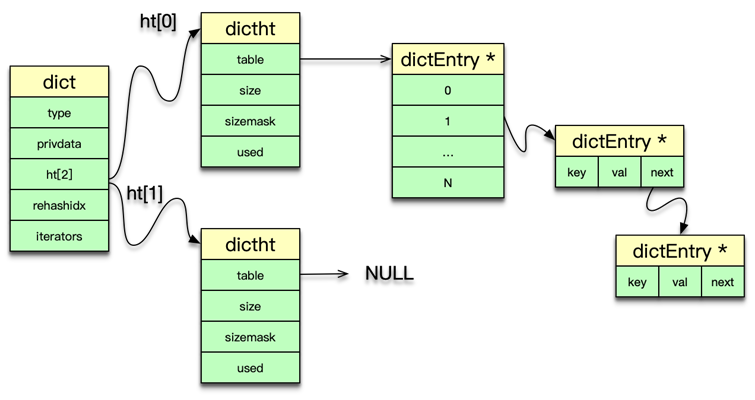
Redis 中的 dict,类似于 Memcached 中 hashtable。都可以用于 key 或元素的快速插入、更新和定位。dict 字典中,有一个长度为 2 的哈希表数组,日常访问用 0 号哈希表,如果 0 号哈希表元素过多,则分配一个 2 倍 0 号哈希表大小的空间给 1 号哈希表,然后进行逐步迁移,rehashidx 这个字段就是专门用来做标志迁移位置的。在哈希表操作中,采用单向链表来解决 hash 冲突问题。dict 中还有一个重要字段是 type,它用于保存 hash 函数及 key/value 赋值、比较函数。
dictht 中的 table 是一个 hash 表数组,每个桶指向一个 dictEntry 结构。dictht 采用 dictEntry 的单向链表来解决 hash 冲突问题。
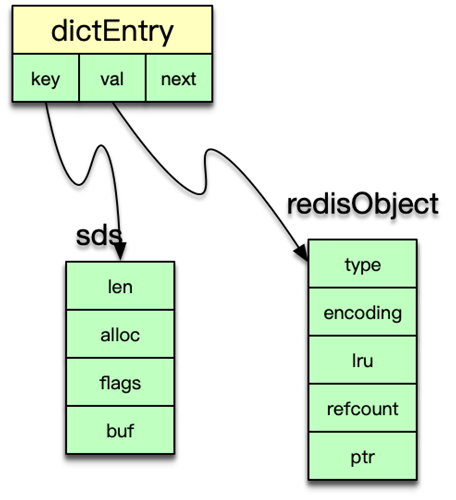
dictht 是以 dictEntry 来存 key-value 映射的。其中 key 是 sds 字符串,value 为存储各种数据类型的 redisObject 结构。
dict 可以被 redisDb 用来存储数据 key-value 及命令操作的辅助信息。还可以用来作为一些 Redis 数据类型的内部数据结构。dict 可以作为 set 集合的内部数据结构。在哈希的元素数超过 512 个,或者哈希中 value 大于 64 字节,dict 还被用作为哈希类型的内部数据结构。
sds
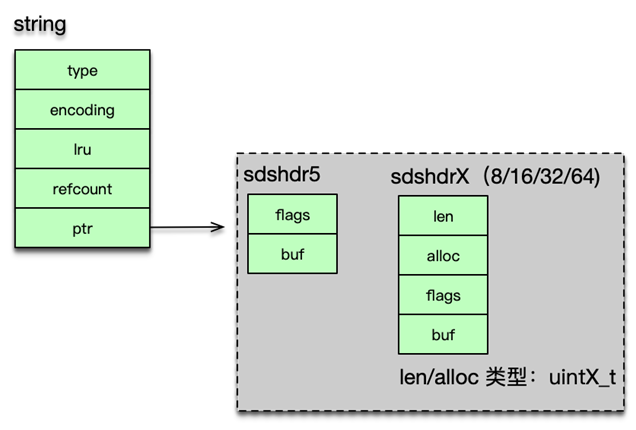
字符串是 Redis 中最常见的数据类型,其底层实现是简单动态字符串即 sds。简单动态字符串本质是一个 char*,内部通过 sdshdr 进行管理。sdshdr 有 4 个字段。len 为字符串实际长度,alloc 当前字节数组总共分配的内存大小。flags 记录当前字节数组的属性;buf 是存储字符串真正的值及末尾一个 \0。
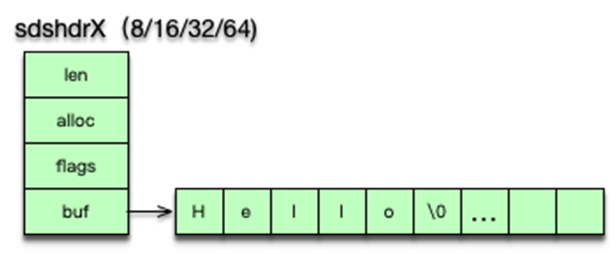
sds 的存储 buf 可以动态扩展或收缩,字符串长度不用遍历,可直接获得,修改和访问都很方便。由于 sds 中字符串存在 buf 数组中,长度由 len 定义,而不像传统字符串遇 0 停止,所以 sds 是二进制安全的,可以存放任何二进制的数据。
简单动态字符串 sds 的获取字符串长度很方便,通过 len 可以直接得到,而传统字符串需要对字符串进行遍历,时间复杂度为 O(n)。
sds 相比传统字符串多了一个 sdshdr,对于大量很短的字符串,这个 sdshdr 还是一个不小的开销。在 3.2 版本后,sds 会根据字符串实际的长度,选择不同的数据结构,以更好的提升内存效率。当前 sdshdr 结构分为 5 种子类型,分别为 sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64。其中 sdshdr5 只有 flags 和 buf 字段,其他几种类型的 len 和 alloc 采用从 uint8_t 到 uint64_t 的不同类型,以节省内存空间。
sds 可以作为字符串的内部数据结构,同时 sds 也是 hyperloglog、bitmap 类型的内部数据结构。
ziplist
为了节约内存,并减少内存碎片,Redis 设计了 ziplist 压缩列表内部数据结构。压缩列表是一块连续的内存空间,可以连续存储多个元素,没有冗余空间,是一种连续内存数据块组成的顺序型内存结构。
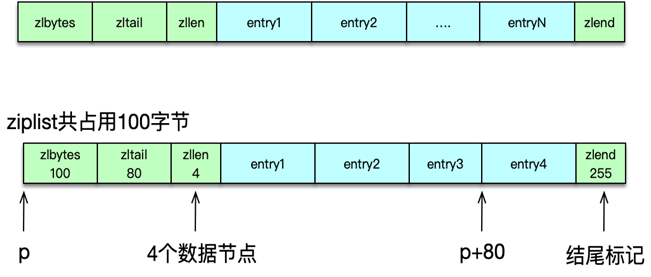
ziplist 的结构如图所示,主要包括 5 个部分。
- zlbytes 是压缩列表所占用的总内存字节数。
- Zltail 尾节点到起始位置的字节数。
- Zllen 总共包含的节点/内存块数。
- Entry 是 ziplist 保存的各个数据节点,这些数据点长度随意。
- Zlend 是一个魔数 255,用来标记压缩列表的结束。
如图所示,一个包含 4 个元素的 ziplist,总占用字节是 100bytes,该 ziplist 的起始元素的指针是 p,zltail 是 80,则第 4 个元素的指针是 P+80。
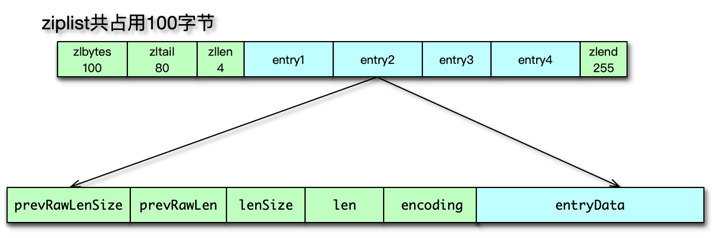
压缩列表 ziplist 的存储节点 entry 的结构如图,主要有 6 个字段。
- prevRawLen 是前置节点的长度;
- preRawLenSize 编码 preRawLen 需要的字节数;
- len 当前节点的长度;
- lensize 编码 len 所需要的字节数;
- encoding 当前节点所用的编码类型;
- entryData 当前节点数据。
由于 ziplist 是连续紧凑存储,没有冗余空间,所以插入新的元素需要 realloc 扩展内存,所以如果 ziplist 占用空间太大,realloc 重新分配内存和拷贝的开销就会很大,所以 ziplist 不适合存储过多元素,也不适合存储过大的字符串。
因此只有在元素数和 value 数都不大的时候,ziplist 才作为 hash 和 zset 的内部数据结构。其中 hash 使用 ziplist 作为内部数据结构的限制时,元素数默认不超过 512 个,value 值默认不超过 64 字节。可以通过修改配置来调整 hash_max_ziplist_entries 、hash_max_ziplist_value 这两个阀值的大小。
zset 有序集合,使用 ziplist 作为内部数据结构的限制元素数默认不超过 128 个,value 值默认不超过 64 字节。可以通过修改配置来调整 zset_max_ziplist_entries 和 zset_max_ziplist_value 这两个阀值的大小。
quicklist
Redis 在 3.2 版本之后引入 quicklist,用以替换 linkedlist。因为 linkedlist 每个节点有前后指针,要占用 16 字节,而且每个节点独立分配内存,很容易加剧内存的碎片化。而 ziplist 由于紧凑型存储,增加元素需要 realloc,删除元素需要内存拷贝,天然不适合元素太多、value 太大的存储。

而 quicklist 快速列表应运而生,它是一个基于 ziplist 的双向链表。将数据分段存储到 ziplist,然后将这些 ziplist 用双向指针连接。快速列表的结构如图所示。
- head、tail 是两个指向第一个和最后一个 ziplist 节点的指针。
- count 是 quicklist 中所有的元素个数。
- len 是 ziplist 节点的个数。
- compress 是 LZF 算法的压缩深度。
快速列表中,管理 ziplist 的是 quicklistNode 结构。quicklistNode 主要包含一个 prev/next 双向指针,以及一个 ziplist 节点。单个 ziplist 节点可以存放多个元素。
快速列表从头尾读写数据很快,时间复杂度为 O(1)。也支持从中间任意位置插入或读写元素,但速度较慢,时间复杂度为 O(n)。快速列表当前主要作为 list 列表的内部数据结构。
zskiplist
跳跃表 zskiplist 是一种有序数据结构,它通过在每个节点维持多个指向其他节点的指针,从而可以加速访问。跳跃表支持平均 O(logN) 和最差 O(n) 复杂度的节点查找。在大部分场景,跳跃表的效率和平衡树接近,但跳跃表的实现比平衡树要简单,所以不少程序都用跳跃表来替换平衡树。
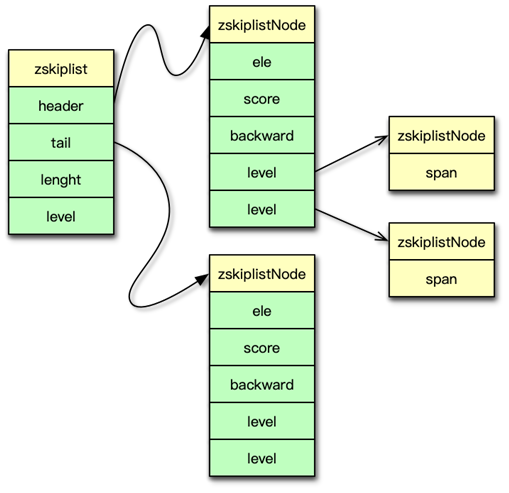
如果 sorted set 类型的元素数比较多或者元素比较大,Redis 就会选择跳跃表来作为 sorted set有序集合的内部数据结构。
跳跃表主要由 zskipList 和节点 zskiplistNode 构成。zskiplist 结构如图,header 指向跳跃表的表头节点。tail 指向跳跃表的表尾节点。length 表示跳跃表的长度,它是跳跃表中不包含表头节点的节点数量。level 是目前跳跃表内,除表头节点外的所有节点中,层数最大的那个节点的层数。
跳跃表的节点 zskiplistNode 的结构如图所示。ele 是节点对应的 sds 值,在 zset 有序集合中就是集合中的 field 元素。score 是节点的分数,通过 score,跳跃表中的节点自小到大依次排列。backward 是指向当前节点的前一个节点的指针。level 是节点中的层,每个节点一般有多个层。每个 level 层都带有两个属性,一个是 forwad 前进指针,它用于指向表尾方向的节点;另外一个是 span 跨度,它是指 forward 指向的节点到当前节点的距离。
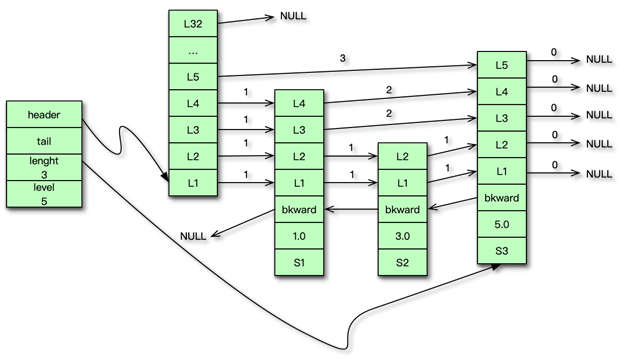
如图所示是一个跳跃表,它有 3 个节点。对应的元素值分别是 S1、S2 和 S3,分数值依次为 1.0、3.0 和 5.0。其中 S3 节点的 level 最大是 5,跳跃表的 level 是 5。header 指向表头节点,tail 指向表尾节点。在查到元素时,累加路径上的跨度即得到元素位置。在跳跃表中,元素必须是唯一的,但 score 可以相同。相同 score 的不同元素,按照字典序进行排序。
在 sorted set 数据类型中,如果元素数较多或元素长度较大,则使用跳跃表作为内部数据结构。默认元素数超过 128 或者最大元素的长度超过 64,此时有序集合就采用 zskiplist 进行存储。由于 geo 也采用有序集合类型来存储地理位置名称和位置 hash 值,所以在超过相同阀值后,也采用跳跃表进行存储。
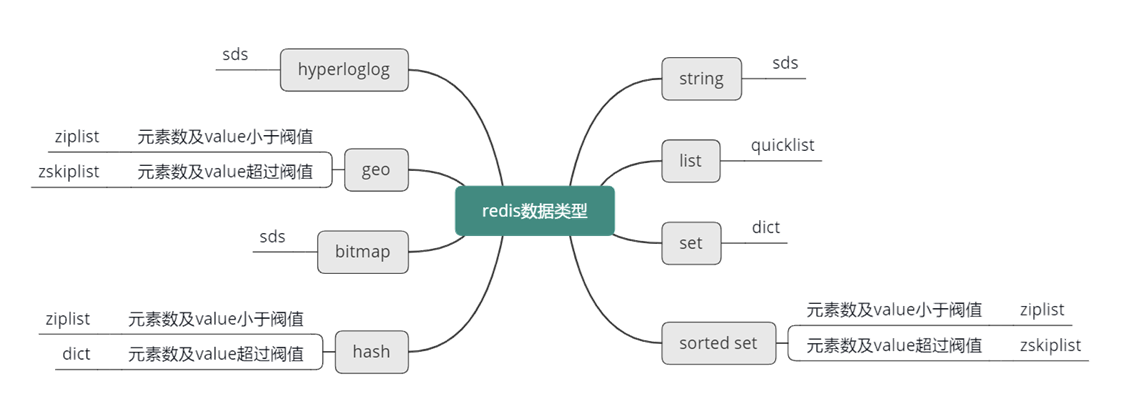
Redis 主要的内部数据结构讲完了,接下来整体看一下,之前讲的 8 种数据类型,具体都是采用哪种内部数据结构来存储的。
首先,对于 string 字符串,Redis 主要采用 sds 来进行存储。而对于 list 列表,Redis 采用 quicklist 进行存储。对于 set 集合类型,Redis 采用 dict 来进行存储。对于 sorted set 有序集合类型,如果元素数小于 128 且元素长度小于 64,则使用 ziplist 存储,否则使用 zskiplist 存储。对于哈希类型,如果元素数小于 512,并且元素长度小于 64,则用 ziplist 存储,否则使用 dict 字典存储。对于 hyperloglog,采用 sds 简单动态字符串存储。对于 geo,如果位置数小于 128,则使用 ziplist 存储,否则使用 zskiplist 存储。最后对于 bitmap,采用 sds 简单动态字符串存储。