【LLM】强化学习训练框架(slime、verl框架)
note
- R1 出现后,RL 从 Human Alignment 向 Reasoning 转变,除对齐任务外,还可用于代码生成、数学推理等领域。这些任务有明确 ground truth,可通过评估代码在测试用例中的正确性或验证数学结果准确性确定。奖励模型可用非神经网络的奖励模块替代,如代码生成任务用沙箱环境评估执行结果,数学推理任务用奖励函数验证结果正确性。
- SLIME 框架中的 Rollout 部分,指的是大模型在强化学习(RL)训练过程中,根据当前策略(模型参数)与环境(或用户提示)进行交互,生成一系列响应(或轨迹),并计算相应奖励的关键阶段
- veRL 是字节内部精心打造并开源的一款强化学习(RL)训练框架。它借助 Ray 可作为胶水层的功能,能够简单灵活地编写数据流程。veRL 最核心的功能是 3D-HybridEngine,该功能可以灵活定义智能体(Actor)的生成和训练阶段。代码支持丰富的模型库,实现了开箱即用,让它迅速成为强化学习训练的首选。
- veRL 借助混合控制方式,在一定程度上解决了数据流(DataFlow)灵活定义与高效执行的问题。具体而言,它在不同层级分别采用了单控制器(single -controller)和多控制器(multi - controller)两种模式。其中,单控制器负责控制,多控制器负责计算。
- RL 训练框架要解决的问题是:灵活定义 DataFlow、将定义出来的 DataFlow 在 GPU 集群上高效执行
- SLIME 框架有足够灵活的资源调度与数据生成逻辑,那么:
- sft = 不启动 sglang,只启动 megatron,数据生成从先有文件里读取;
- reject sampling = 启动 sglang,启动 megatron,数据由 sglang 生成,不进行参数更新;
- eval = 启动 sglang,只上报 eval 结果。
文章目录
- note
- 一、RL训练
- 1、RL 训练是一个DataFlow
- 二、slime框架
- 三、verl框架
- 1、single-controller + multi-controller:
- 2、灵活 Placement+Parallelism:
- Reference
一、RL训练
1、RL 训练是一个DataFlow
RL 训练任务可被视为一种数据流(DataFlow),如Figure 1所示,展示了三种RLHF变种的DataFlow。比如 RLHF的DataFlow主要可以分解为以下三个阶段:
第一阶段:回复生成(Generation/Rollout):Actor 模型(一个预训练或微调的 LLM)使用一批提示(prompts)自动回归地生成回复(responses),这一步执行 LLM 推理。这一步步骤通常称为 Rollout,也是常常是 RL 中时间占比 80% 以上的热点部分。
第二阶段:经验准备(Preparation):使用提示和生成的回复,通过各自模型的单次前向计算,对生成的回复进行评分。这个阶段通常涉及以下模型:
• Critic Model:计算生成回复的值(values)。
• Reference Model:计算生成回复的参考对数概率,它通常是 Actor 模型在 RLHF 之前的版本,用于限制 Actor 模型在训练过程中偏离过远。
• Reward Model:计算生成回复的奖励(rewards)。奖励模型通常是一个基于人类偏好数据进行微调的 LLM,其语言建模头被替换为标量输出头。
• 在一些 RLHF 的变体中,例如 Safe-RLHF,可能还会包含一个 成本模型(Cost Model) 来评估安全偏好。
第三阶段:训练(Training):Actor 模型和 Critic 模型使用前两个阶段产生的数据以及相应的损失函数进行更新。这个过程就是 LLM 训练过程。Actor 模型的训练目标是最大化奖励模型给出的奖励,同时避免偏离参考策略过远 。Critic 模型的训练目标是准确预测状态的Value。

二、slime框架
Slime 采用 Ray 作为单控制器(Single Controller)进行调度,Megatron-LM 作为训练后端,SGLang 作为推理后端,构建了一个简洁且支持大规模 RL 的框架。它兼容资源训推一体化和分离两种部署模式。正如 Zilin 所述,其设计目标是减少训练与推理之间数据传递的开销,并使所有环节尽可能对齐真实生产环境中的组件,从而实现灵活的大规模 RL 训练。从实践来看,这套系统成功地实现了其核心设计目标。

从数据流的角度看,以 Buffer 为视角最易于理解。Buffer 是一个 Ray Actor,它不仅维护了一个 rollout 数据集,还能加载自定义的 generate_rollout 方法,以实现灵活的 rollout 策略。通过 Ray 的远程调用,训练和推理模块可以与 Buffer 进行数据交互。
- Rollout (推理/样本生成): 使用 SGLang 的 router 进行数据并行(DP),router 依据缓存感知(cache-aware)原则进行负载均衡,再将请求分配给相应的 SGLang Engine。rollout_generator 直接持有 Buffer 的句柄,双向管控数据的生产和取回。
- Train (训练): 尽量复用 Megatron 的 trainer。5D 并行(TP/PP/DP/CP/EP)在兼容 GPTModel 的基础上,更多地交由 Megatron 的原生 trainer 处理。
核心优势总结:
-
工业级的“训推一体”架构: 通过 Ray Actor 模型,将专为大规模设计的离线训练引擎 (Megatron-LM) 和专为低延迟、高吞吐量设计的在线推理引擎 (SGLang) 无缝地“粘合”在一起。
-
高效的“知识”流动闭环: 框架实现了 RL 的核心飞轮:生成 -> 训练 -> 同步。
- 数据流: 通过异步的 Buffer Actor 和高效的 NCCL Broadcast,实现了从“探索”到“学习”的高效数据回传。
- 权重流: 通过自适应的权重同步机制(分布式 NCCL Broadcast 和同地部署 CUDA IPC),实现了从“学习”到“行动”的低延迟知识更新。
-
高度的灵活性与可扩展性:
- 可插拔的探索与奖励: 通过配置文件指定
rollout_function_path和custom_rm_path,用户可以轻松自定义 Agent 的探索行为和价值判断标准,无需修改框架核心。 - 模型无关性: 通过 slime_plugins 机制,可以轻松适配和扩展支持新的模型结构。
- 可插拔的探索与奖励: 通过配置文件指定
三、verl框架
链接:https://github.com/volcengine/verl?tab=readme-ov-file
一个完美的 RL 训练框架,希望为 DataFlow 的每个节点灵活定义 Placement 和 Parallelism。Placement 表示模型放置在哪些卡上,如下图所示,可以 colocate 所有模型相同 GPU 上,每个模型放在单独设备上,还有混合的方式。Parallelism 则是模型并行方式,有 ZeRO、TP(Tensor Parallel)、PP(Pipeline Parallel) 等策略。
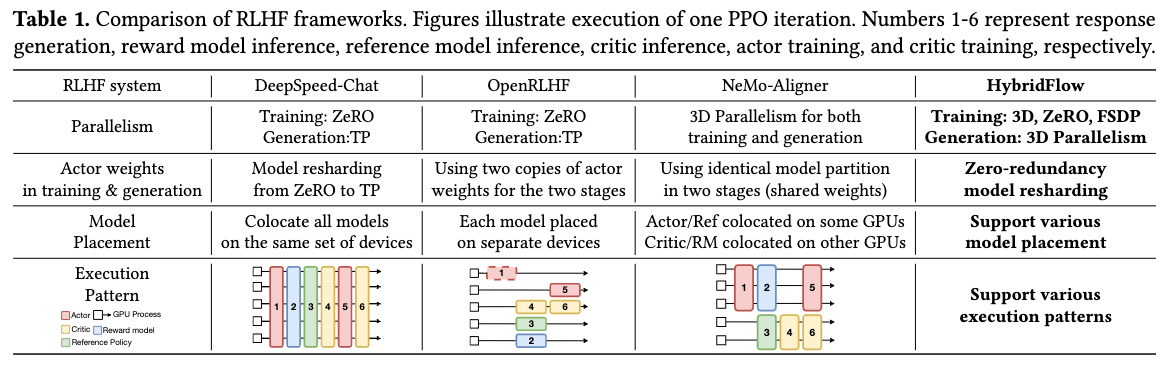
在pre-LLM时代,RL 的每个节点在单个 CPU/GPU 上进行。但是 LLM 时代,RL 训练 DataFlow 中每个节点都需要多 GPU 上分布式执行。这导致在 veRL 出现之前,面向 LLM 的 RL 训练框架难以平衡编程灵活性和分布式执行效率的问题。比如,一些实现限制了编程灵活性,每个 DataFlow 节点是一个运行在独立资源上的的并行程序,不同节点通过定制化的 P2P 通信串联起来,构成完整 DataFlow,这导致可编程性很差,比如 NemoAligner。在另一些实现限制了DataFlow 的 Placement 和 Parallelism方式,比如 DeepSpeed-Chat,不同DataFlow 节点在同一个程序中运行在同一份资源上,互相抢占显存,导致效率很低。
1、single-controller + multi-controller:
veRL 借助混合控制方式,在一定程度上解决了数据流(DataFlow)灵活定义与高效执行的问题。具体而言,它在不同层级分别采用了单控制器(single -controller)和多控制器(multi - controller)两种模式。其中,单控制器负责控制,多控制器负责计算。具体来说:
在模型(DataFlow 的节点)之间(Inter-node level),HybridFlow 采用了single-controller模式。有中央化的控制器负责协调不同的模型在 RLHF 数据流中的执行顺序和数据传输。这个单控制器运行在一个独立的进程中,类似 master。 它保证了 DataFlow 定义的灵活性,而且在模型数量不多的 RLHF 数据流中,控制分发的开销可以忽略不计。veRL 的 single controller 使用 Ray 实现,也是发挥大家常说的 ray 适合做胶水层的作用。
在每个模型内部的分布式计算(DataFlow 的一个节点内)中(Intra-node level),HybridFlow 采用了multi-controller模式。这意味着每个计算设备(例如 GPU)都有自己的控制器,独立管理其上的计算任务,就是的 SPMD 方式运行的,也就是复用sglang/vllm/torchdpp 启动推理/训练的方式。
2、灵活 Placement+Parallelism:
用户定义了一个 DataFlow,veRL能够高效执行出来,并行保持,veRL 还需要相对自动地帮用户解决如下事情:DataFlow node 之间如何传递 tensor:实际的 tensor 数据传输通常发生在计算 GPU 之间,而不通过中央master 节点。因为不同 node 的 Parallelism 方式不同,导致输出 tensor 的 sharding 方式是不同的。比较呆板实现就是在每个 node 算完 gather,然后 node 计算前去 shard。veRL 定义数据依赖和传输协议简化用户的编程:对于节点之间的 tensor 传递,会通过 @register 装饰器将节点的操作与预定义的若干种传输协议关联起来。传输协议定义了如何收集发送节点的输出以及如何分发到接收节点的输入。Async DataFlow Execution:通过 Ray 的 future 机制 实现异步数据流执行,使得没有依赖关系的节点可以并发执行。
Reference
[1] 实录精选|slime开源项目作者朱子霖:Infra视角下,为 RL Scaling设计的训练框架
[2] Slime框架深度解析:面向大规模RL的训推一体化实践
[3] RL Scaling 时代,我们需要什么样的 RL 框架呢?
[4] smile框架:https://github.com/THUDM/slime
[5] verl框架:https://github.com/volcengine/verl
[6] verl: Flexible and Scalable Reinforcement Learning Library for LLM Reasoning and Tool-Calling:https://www.youtube.com/watch?v=Vd79NmmqY3Q&t=2s
[7] 通过工具增强 LLM Agent 能力:veRL+ReTool 的完整实践指南
[8] veRL:All in RL元年的必修课
[9] RL Scaling 时代,我们需要什么样的 RL 框架呢?