李宏毅NLP-12-语音分类
目录
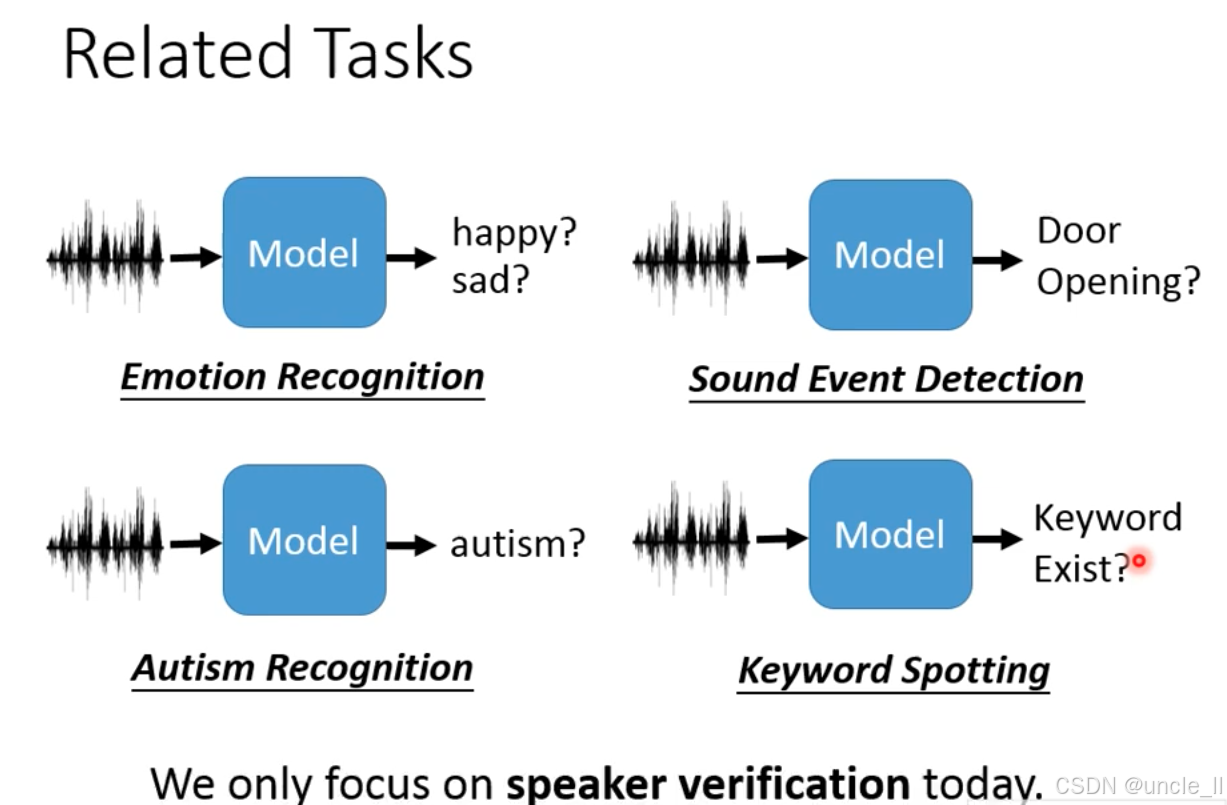
相关任务
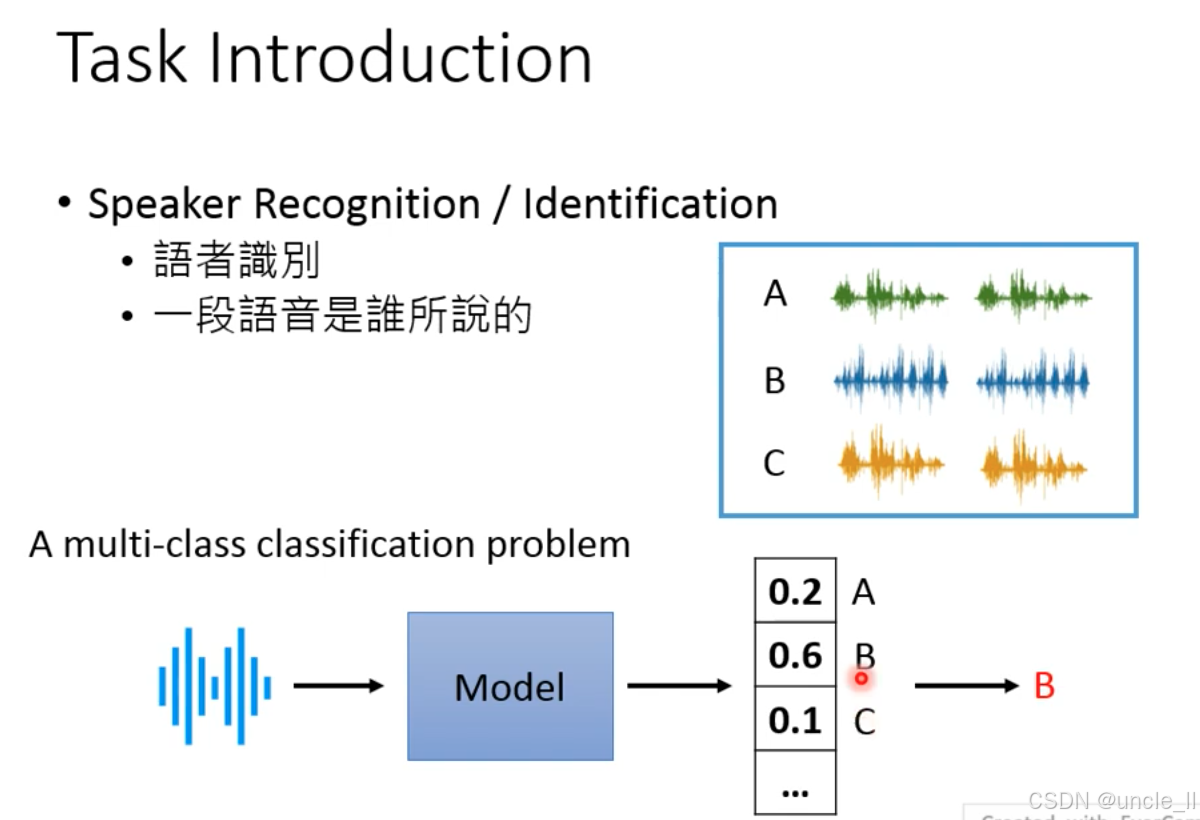
说话人识别(Speaker Recognition/Identification) 属于多分类问题:
- 判断一段语音属于哪个说话人(如区分 A、B、C 的语音);
- 技术本质:多分类问题
- 输入:一段语音;
- 模型:提取语音的说话人特征(如声纹,隐含音色、韵律等个人特质);
- 输出:对所有候选说话人的概率分布(如 A:0.2,B:0.6,C:0.1),选择概率最高的类别(如 B)作为识别结果。
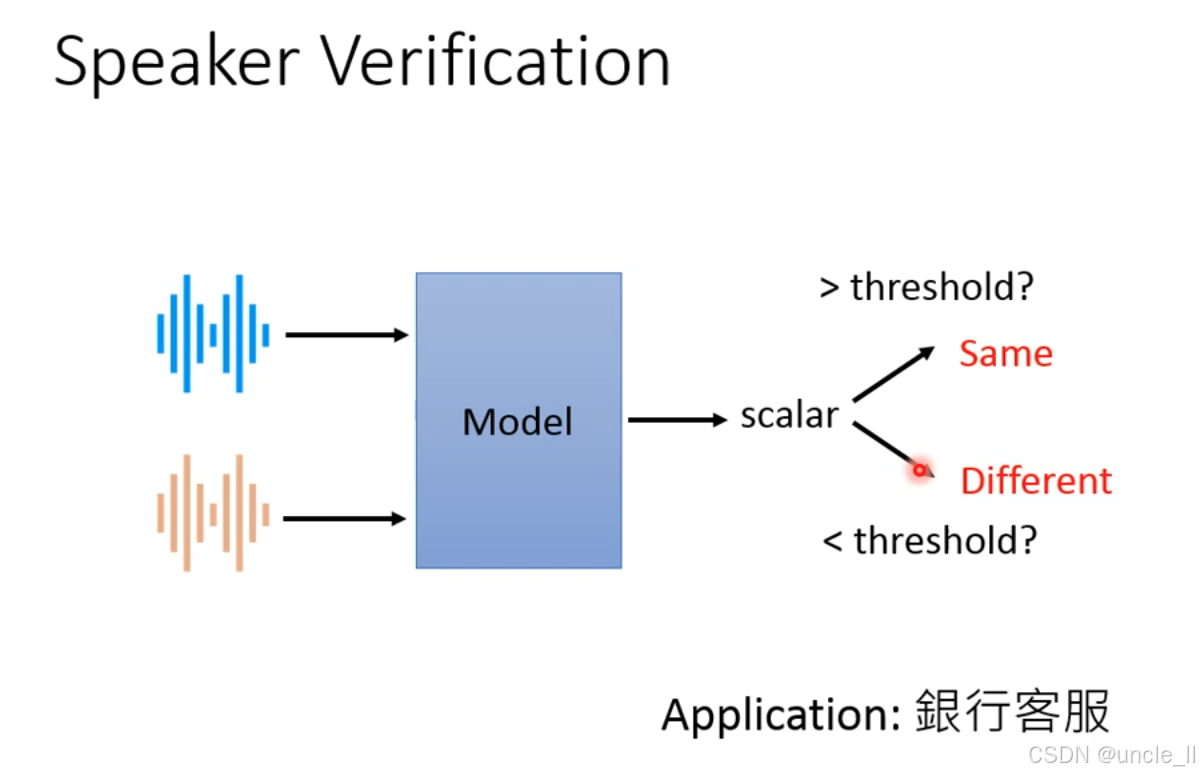
说话人验证(Speaker Verification) 的核心逻辑,属于二分类任务:
- 目标:判断两段语音是否来自同一说话人(区别于 “说话人识别” 的多分类,这里只回答 “是 / 否”);
- 核心逻辑:计算两段语音的声纹相似度,通过阈值判断是否为同一人。
流程拆解
- 输入:两段语音(可来自不同时间、不同内容);
- 模型:提取两段语音的说话人嵌入(声纹特征),计算它们的相似度标量(如余弦相似度、模型输出的匹配分数);
- 决策:
- 若标量 > 阈值 → 判定为 Same(同一人);
- 若标量 < 阈值 → 判定为 Different(不同人)。
- 声纹特征:模型学习说话人的独特特质(如音色、发音习惯、韵律),生成高维嵌入;
- 阈值设计:平衡 “准确率” 和 “召回率”(如银行场景设高阈值,宁可漏判也不错判,保障安全)。
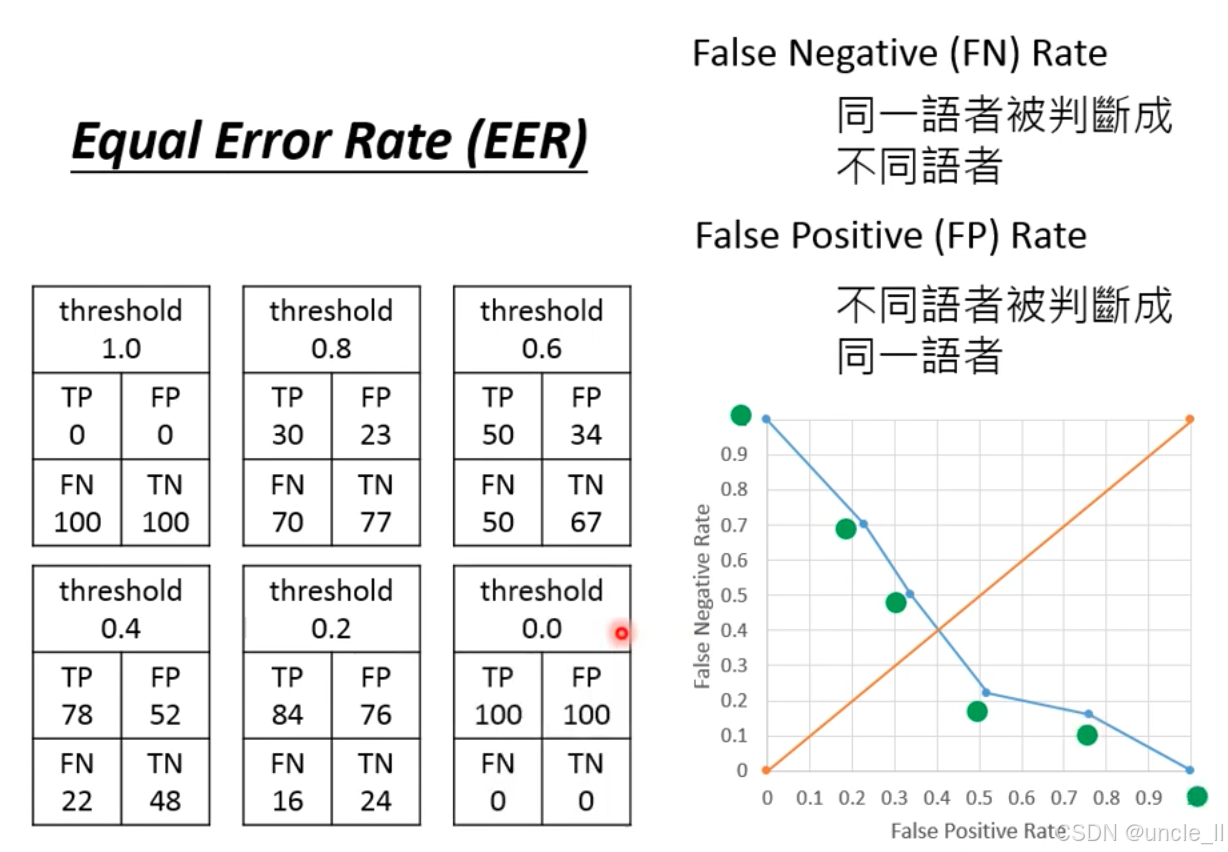
话人验证系统的核心评估指标 —— 等错误率(Equal Error Rate, EER) ,结合混淆矩阵和误差率曲线,解析系统在 “漏判(FN)” 和 “误判(FP)” 之间的权衡:
定义
| 误差类型 | 定义 | 风险场景 |
|---|---|---|
| False Negative (FN) Rate 漏判率 | 同一说话人被判定为 “不同” 的概率 | 银行场景:真实客户被拒绝(体验差) |
| False Positive (FP) Rate 误判率 | 不同说话人被判定为 “同一” 的概率 | 银行场景:陌生人冒充客户(资金风险) |
| Equal Error Rate (EER) 等错误率 | 当 FN 率 = FP 率 时的错误率,是系统性能的核心指标(值越低,性能越好) |
混淆矩阵随阈值的变化
-
混淆矩阵的四个指标:
-
TP(True Positive):同一说话人被正确判定为 “同一”;
-
FP(False Positive):不同说话人被错误判定为 “同一”;
-
FN(False Negative):同一说话人被错误判定为 “不同”;
-
TN(True Negative):不同说话人被正确判定为 “不同”。
-
-
阈值对结果的影响:
-
阈值↑(如 1.0→0.0):判定更 “宽松”→ TP 和 FP 增加,FN 和 TN 减少(更多语音被判定为 “同一人”);
-
阈值↓(如 0.0→1.0):判定更 “严格”→ TP 和 FP 减少,FN 和 TN 增加(更多语音被判定为 “不同人”)
-
例如:
-
阈值 = 1.0(最严格):仅 0 个 TP(同一人也被拒),100 个 FN(漏判率 100%);
-
阈值 = 0.0(最宽松):100 个 FP(陌生人全被接受,误判率 100%)。
-
-
EER 的几何意义(ROC 曲线的交点)
- 横轴(FP Rate):误判率(不同人被当成同一人的概率);
- 纵轴(FN Rate):漏判率(同一人被当成不同人的概率);
- 蓝色曲线:随阈值降低,FP 率上升(误判变多),FN 率下降(漏判变少);
- 橙色对角线:FP 率 = FN 率 的参考线。
蓝色曲线与橙色对角线的交点,即 FP 率 = FN 率 时的误差率。此时,系统在 “漏判” 和 “误判” 之间达到最优平衡。
- 高安全场景(如银行):优先降低 FP 率(避免陌生人冒充),可设置高阈值(牺牲部分 FN 率,接受更多真实客户被拒);
- 高体验场景(如语音助手):优先降低 FN 率(避免真实用户被拒),可设置低阈值(牺牲部分 FP 率,接受更多陌生人冒充风险);
- EER 作为基准:比较不同说话人验证模型的性能,EER 越低,模型鲁棒性越强。

说话人分离(Speaker Diarization) 的核心任务是解决“谁在什么时候说话?”问题,比如在多说话人交互场景(如会议、电话会议)中,自动区分 “不同说话人” 的发言时段,给每个语音片段标注说话人身份(如 “说话人 A 在 0-10 秒发言,说话人 B 在 12-25 秒发言”)。其他应用场景:
- 会议记录:自动拆分参会者的发言,辅助生成会议纪要;
- 电话通话:尤其是多方通话,区分不同参与者的对话;
- 视频处理:为影视、直播的语音流标注说话人,辅助字幕生成或内容分析。
核心流程:两步法(Segmentation + Clustering)
-
Step 1: Segmentation(分段)
-
目标:将长语音切分为短片段(utterances),每个片段尽量对应单一说话人的连续发言(减少跨说话人的片段)。
-
实现方式:
- 基于静音检测(能量阈值,识别静音区间,分割出语音段);
- 进阶方法:结合语音活动检测(VAD)、说话人变化检测(如声纹突变检测)。
-
-
Step 2: Clustering(聚类)
-
目标:对分段后的语音片段,按说话人身份聚类(相同说话人的片段归为一类)。
-
实现方式:
- 提取每个片段的 说话人特征(如声纹嵌入,类似说话人识别中的特征);
- 用聚类算法(如 K-Means、层次聚类)将特征相似的片段分组;
- 说话人数量:可预先已知(如会议有 3 人,设 K=3),也可未知(模型自动推断数量)。
-
Spearker Embedding
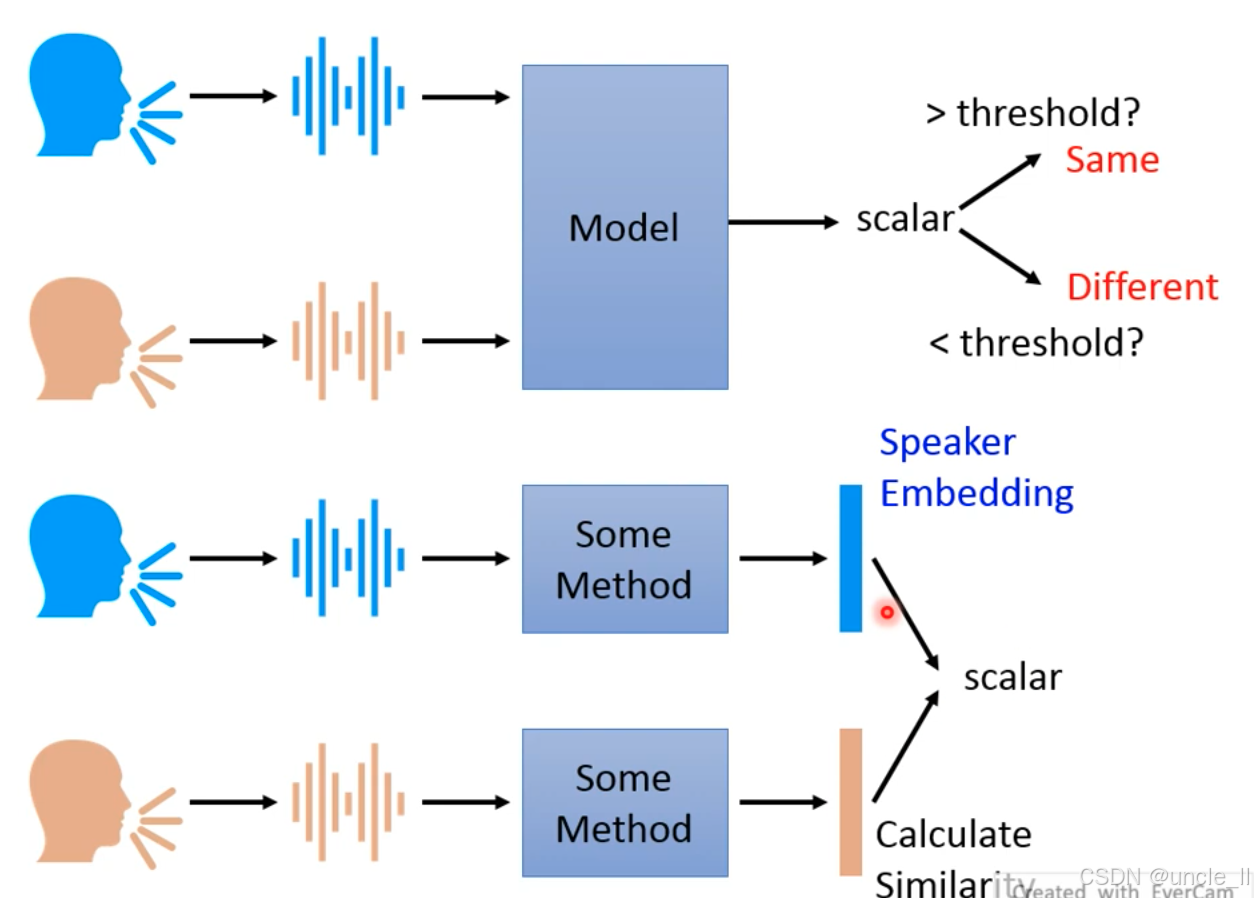
说话人验证(Speaker Verification)的两种实现方式,核心是通过比较语音特征判断是否为同一说话人:
一、直接验证方式
-
输入:两段语音(不同说话人或同一说话人的语音);
-
模型(Model):直接计算两段语音的相似度,输出一个标量(scalar);
-
判断:若标量 > 阈值(threshold),判定为 “同一说话人(Same)”;否则为 “不同说话人(Different)”。
-
优点:端到端黑盒模型,直接输出相似度结果,无需显式提取说话人特征,模型内部隐含特征学习。
二、基于嵌入的验证方式
- 特征提取(Some Method):分别对两段语音提取 “说话人嵌入(Speaker Embedding)”(蓝色和橙色向量,编码说话人身份特征);
- 相似度计算(Calculate Similarity):比较两个嵌入向量的相似度(如余弦相似度),输出标量;
- 判断:同直接验证方式,通过阈值判断是否为同一说话人。
- 优点:说话人嵌入独立于验证模型,可复用(如用于说话人识别、TTS 语音克隆);嵌入向量直接反映说话人特征差异,便于分析和优化。
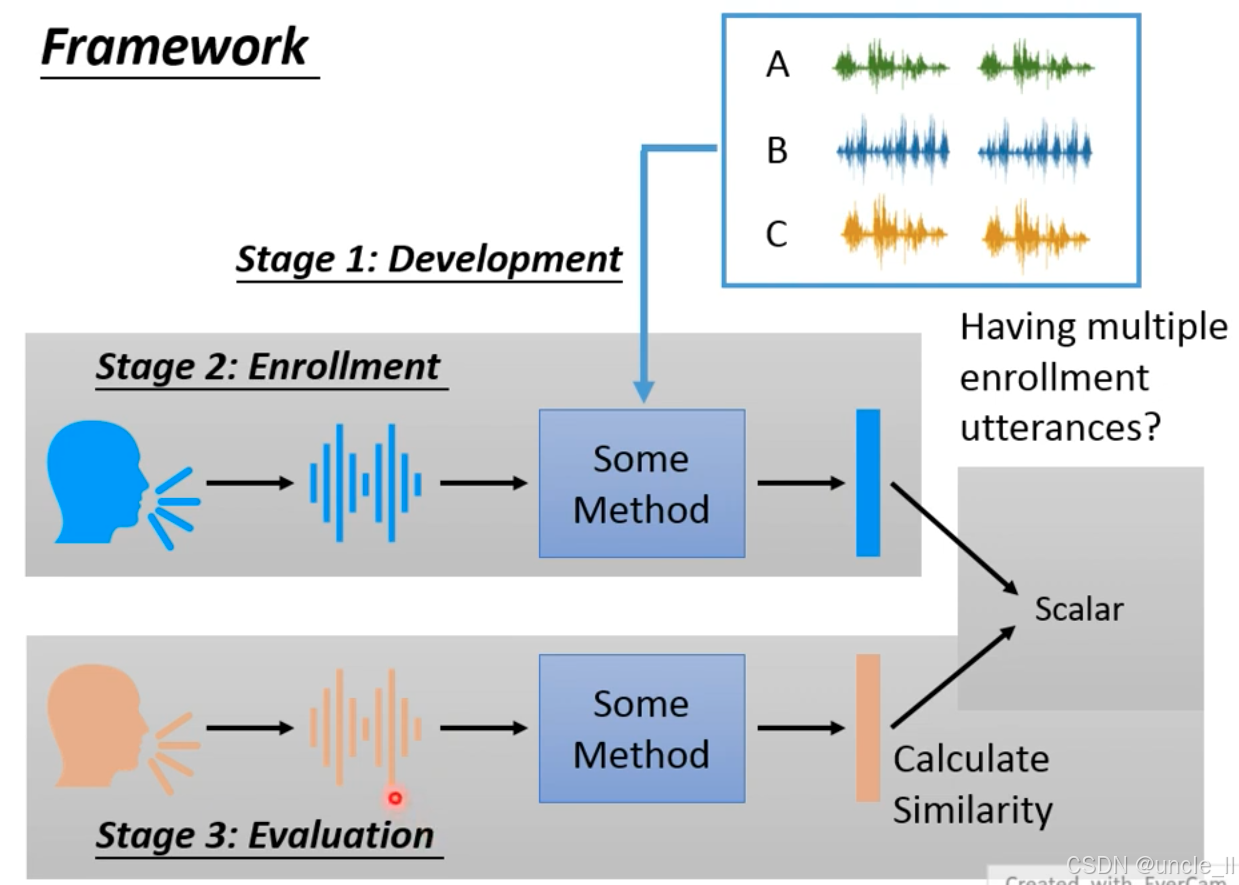
说话人验证系统的三阶段框架:
-
Stage 1: Development(开发阶段)
-
输入:多说话人语音数据(如 A、B、C 三个说话人,每人 2 段语音);
-
目标:训练通用的说话人特征提取模型(Some Method),学习 “语音→说话人嵌入” 的映射;
-
特点:模型需具备泛化性,不依赖特定说话人。
-
-
Stage 2: Enrollment(注册阶段)
-
输入:新说话人(开发阶段未见过)的语音;
-
流程:用开发阶段训练的模型提取其说话人嵌入,存储为 “注册模板”;
-
关键问题:是否需要 “多段注册语音(multiple enrollment utterances)”?→ 通常需多段语音平均嵌入,提升鲁棒性(如用户注册时录制 3 段语音)。
-
-
Stage 3: Evaluation(评估阶段)
-
输入:待验证语音(橙色波形,可能是注册说话人或 impostor);
-
流程:
- 提取待验证语音的嵌入(橙色向量);
- 计算与注册嵌入的相似度(Calculate Similarity),输出标量(scalar);
- 通过阈值判断是否为同一说话人。
-
开发阶段:学习 “人类语音的共性特征”(如音色、声纹的通用规律),而非记忆特定说话人;
注册 + 评估阶段:对新说话人,通过少量语音提取其个性化嵌入,完成 “零样本验证”。
最后开发阶段未见过的说话人”也能通过注册和评估完成验证,新用户无需参与模型训练,直接注册即可使用(如手机语音解锁),支持无限新增说话人,无需重新训练模型(如智能音箱多用户识别)
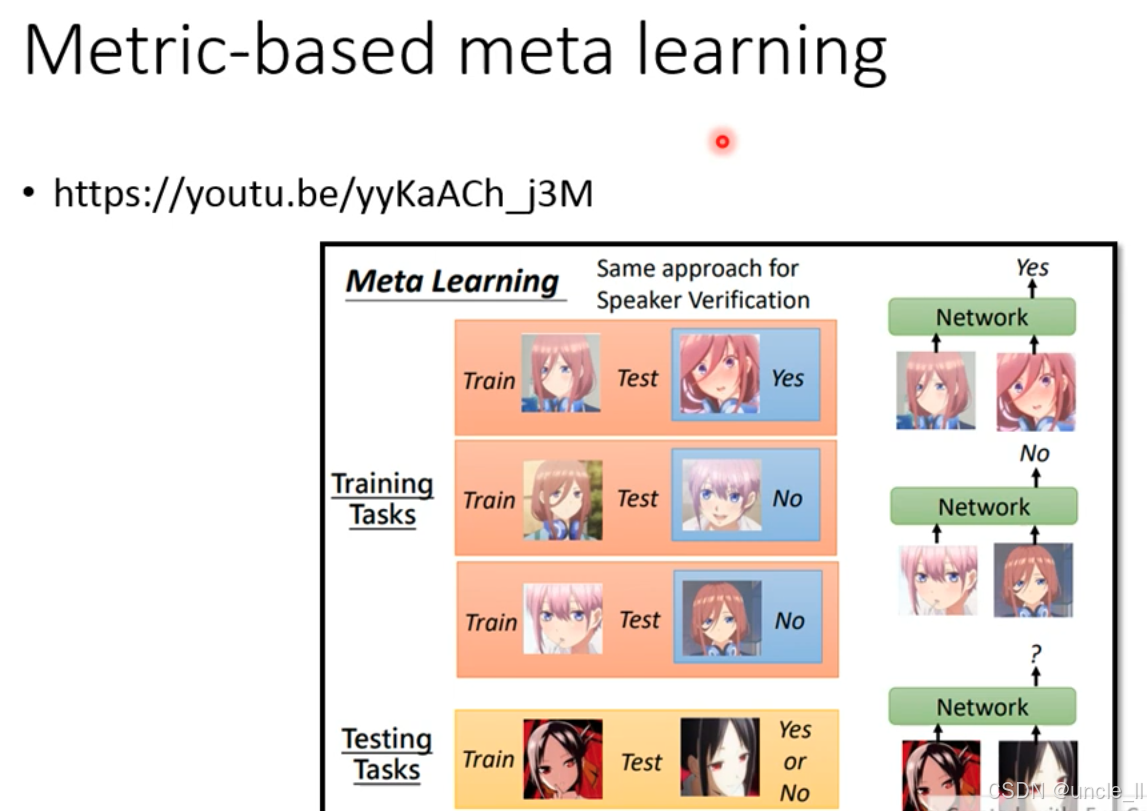
基于度量的元学习(Metric-based meta learning)
元学习的目标是训练一个 “学会学习” 的模型,使其能通过少量样本快速适应新任务。图中类比:将元学习的思想迁移到 “说话人验证” 任务,让模型仅用少量语音就能区分新说话人。
训练阶段
- 每个训练任务包含 “支持集(Train)” 和 “查询集(Test)”:
- 支持集:少量样本(如 1 张动漫人脸图片),代表 “已知类别”;
- 查询集:1 张待验证样本,判断是否与支持集属于同一类别(Yes/No)。
-
模型学习目标
-
训练一个特征提取网络(Network),使其能将输入(如图像、语音)映射到高维特征空间;
-
在特征空间中,同一类样本距离近,不同类样本距离远(通过度量学习优化,如对比损失、三元组损失)。
-
测试阶段
- 新类别任务:测试任务中的人物是训练阶段未见过的新类别;
- 少样本适应:仅用少量支持集样本,模型就能判断查询集是否属于同一类别;
- 核心能力:通过元训练习得的 “特征距离度量方式”,泛化到新类别。
技术本质:
- 学习 “相似度度量”,元学习不直接学习 “类别→标签” 的映射,而是学习 “如何度量样本间的相似度”:
- 训练阶段:通过大量任务学习 “同类样本的共性特征” 和 “异类样本的差异特征”;
- 测试阶段:对新类别,用学到的 “相似度度量方式” 快速判断样本归属。
语音相关的数据集:
一、Google’s Dataset(私有数据集,[Wan, et al., ICASSP’18])
- 规模:3600 万条语音(36M utterances),覆盖 18000 个说话人(18000 speakers);
- 特点:
- 数据量和说话人数量均为三者中最大,属于工业级私有数据集;
- 未公开细节,但为 Google 的说话人识别模型提供了大规模训练数据支撑;
二、VoxCeleb [Nagrani, et al., INTERSPEECH’17]
- 规模:15 万条语音(0.15M utterances),1251 个说话人(1251 speakers);
- 特点:
- 首个大规模公开的说话人识别数据集,语音来源于 YouTube 名人访谈视频;
- 包含真实场景噪声(如背景音乐、环境音),贴近实际应用场景;
三、VoxCeleb2 [Chung, et al., INTERSPEECH’18]
- 规模:112 万条语音(1.12M utterances),6112 个说话人(6112 speakers);
- 特点:
- VoxCeleb 的升级版,数据量和说话人数量均为 VoxCeleb 的约 8 倍;
- 延续了 YouTube 视频的数据源,保留真实场景多样性,同时提升了数据规模;
具体算法
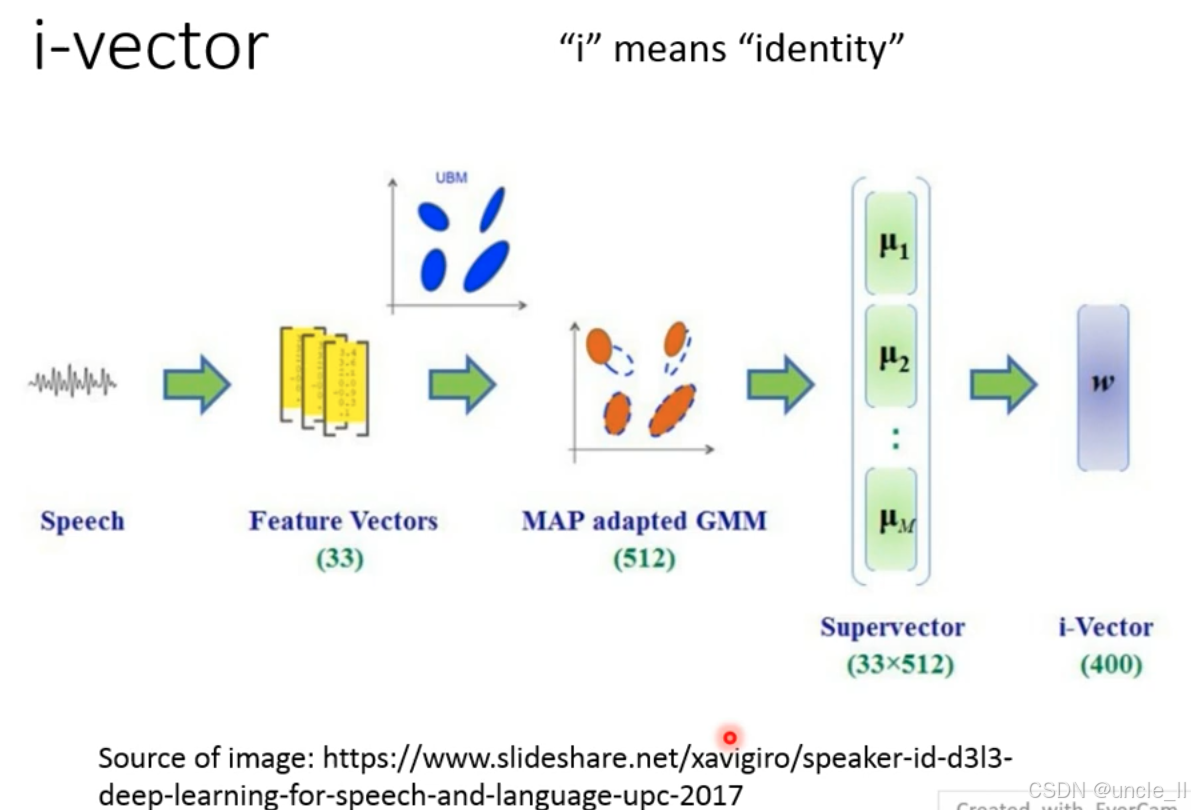
i-vector 的本质是说话人身份的低维紧凑表示,通过统计建模从语音中提取说话人独特的声纹特征,解决传统方法中 “特征维度高、泛化性差” 的问题。
生成流程拆解
-
Step 1:语音→特征向量
-
输入:原始语音信号;
-
处理:提取短时声学特征(如 MFCC、FBANK),形成33 维特征向量序列;
-
作用:将语音转化为计算机可处理的数值特征,保留频谱、时序等关键信息。
-
-
Step 2:UBM 与 MAP 自适应 GMM
-
UBM(Universal Background Model):
- 一个预先训练的 “通用背景模型”,基于大量不同说话人的数据训练,包含 512 个混合高斯分量;
- 代表 “所有说话人的平均声学特性”。
-
MAP 自适应:
- 用当前说话人的少量语音特征(橙色点)调整 UBM 的参数(如均值、方差),得到说话人自适应 GMM(图中橙色椭圆簇);
- 作用:将通用模型向特定说话人 “微调”,捕捉个性化声学特征。
-
-
Step 3:超向量(Supervector)→i-vector
-
超向量生成:
- 将自适应 GMM 的所有高斯分量均值(μ₁, μ₂, …,)拼接成一个高维向量,即超向量(33×512=16896 维);
- 超向量包含说话人自适应后的全部声学特征,但维度极高,冗余信息多。
-
i-vector 降维:
- 通过低秩矩阵分解,将超向量压缩为400 维的 i-vector;
- 核心假设:说话人特征位于一个低维子空间,i-vector 仅保留该子空间的关键信息。
-
i-vector 基于 “说话人差异可由低维子空间表示” 的假设:
-
所有说话人的超向量差异可分解为 “通用背景 + 低维身份向量”;
-
通过因子分析学习这个子空间,最终用 400 维向量唯一表征说话人身份。
-
优点:
-
维度低、计算快:400 维向量便于存储和相似度计算(如余弦距离);
-
泛化性较好:在小数据场景下仍能稳定提取说话人特征,曾是说话人识别的工业界标准。
-
-
缺点:
-
依赖 GMM 统计建模:对复杂声学环境(如噪声、口音)鲁棒性有限;
-
性能被深度学习超越:随着 x-vector 等端到端模型出现,i-vector 逐渐被取代,但仍是经典基准方法。
-
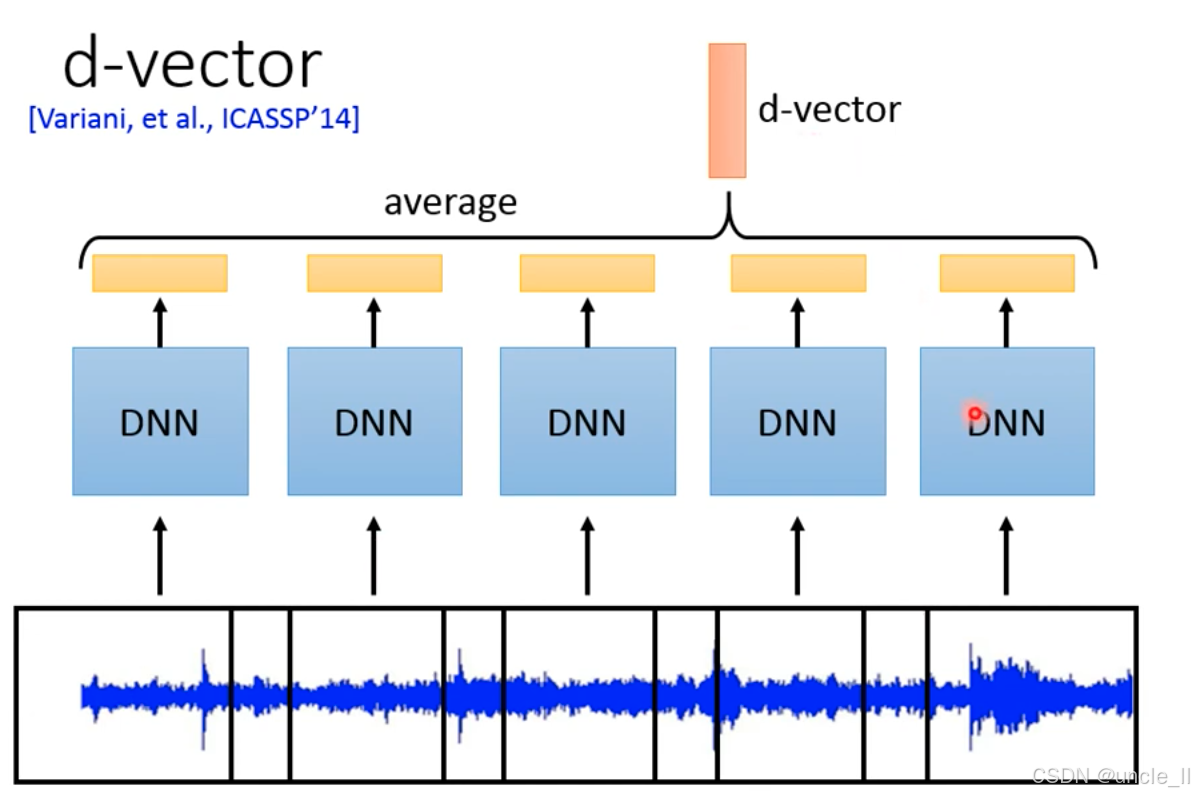
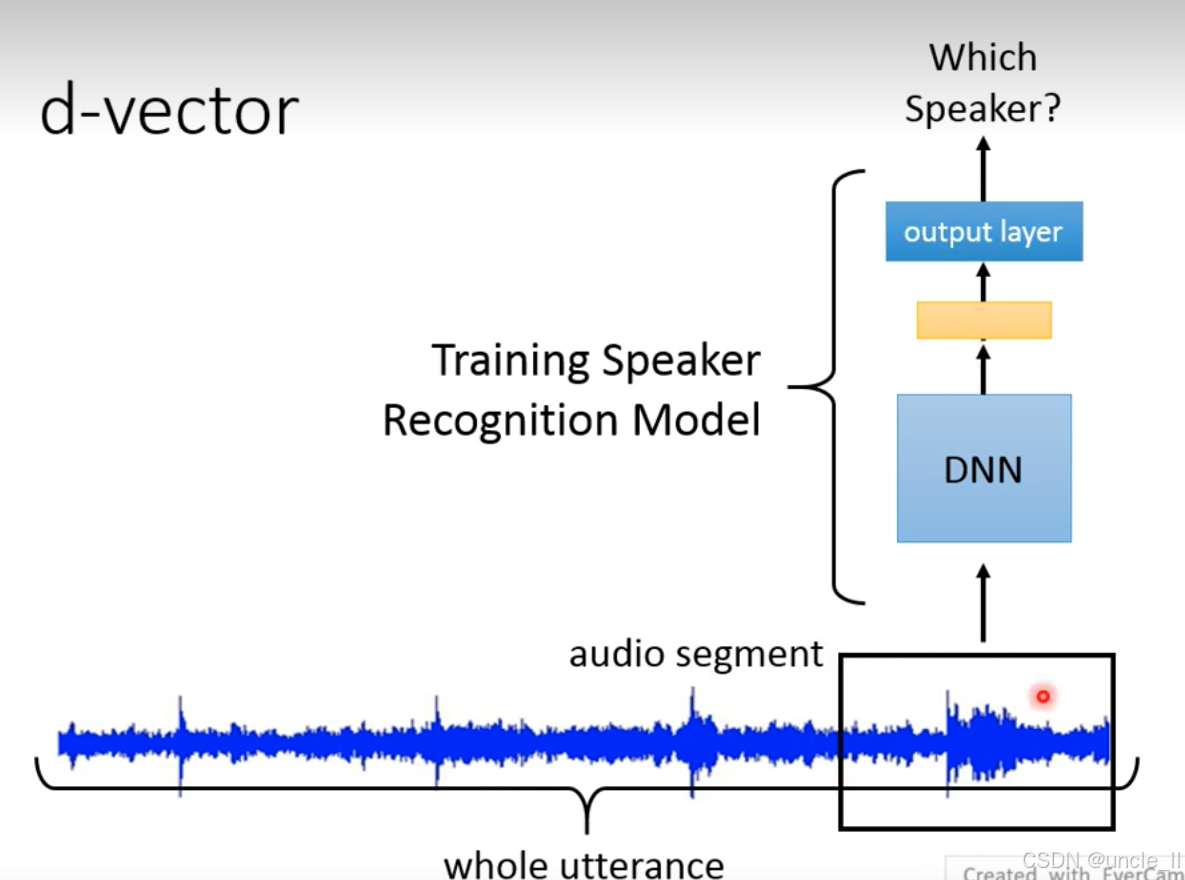
d-vector 是首个将深度学习应用于说话人嵌入的方法,通过训练深度神经网络(DNN)直接从语音中提取判别性身份特征,突破了传统 i-vector 依赖 GMM 统计建模的局限。
-
Step 1:语音分帧与特征输入
-
原始语音:长语音波形被分割为多个短时帧;
-
帧级特征:每帧语音提取声学特征(如 MFCC),作为 DNN 的输入。
-
-
Step 2:帧级 DNN 特征提取
-
深度神经网络(DNN):每个语音帧独立通过 DNN,输出帧级高维特征;
-
DNN 结构:通常为前馈神经网络(如 3-5 层全连接层),训练目标是 “说话人分类”(输入帧特征→输出说话人标签概率)。
-
-
Step 3:帧特征平均→d-vector
-
时序平均(average):将一整段语音的所有帧级特征(多个黄色方块)进行算术平均;
-
输出 d-vector:平均后的向量即为最终的说话人嵌入(顶部橙色向量),维度通常为 512 或 1024 维。
-
- 训练阶段:DNN 以 “帧级说话人分类” 为目标,迫使网络学习区分不同说话人的声学特征(如音色、声纹);
- 推理阶段:通过平均帧特征,将变长语音转换为固定长度的 utterance 级嵌入(d-vector),实现对整段语音的说话人表征。
d-vector 通过 “帧级 DNN 分类→时序平均” 的简单流程,开启了深度学习在说话人嵌入领域的应用。尽管其平均操作损失了语音的时序动态信息,但 “用神经网络学习判别性身份特征” 的思想,彻底改变了说话人识别的技术路径,是现代语音身份认证技术的重要起点。
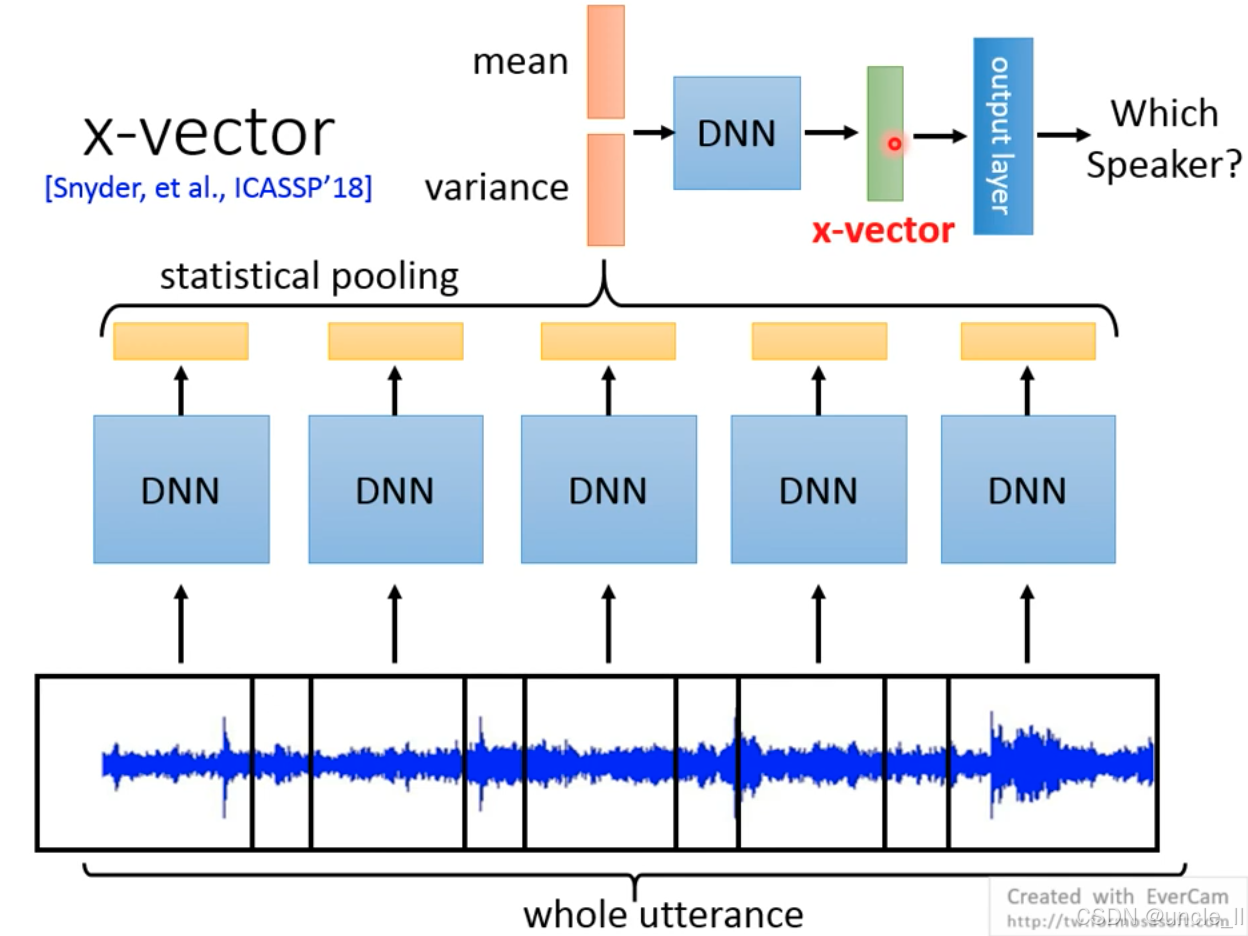
x-vector 针对 d-vector 的缺陷(简单平均丢失时序信息),提出统计池化(statistical pooling),通过聚合语音帧的 “均值(mean)” 和 “方差(variance)”,保留语音的动态特性,生成更具判别性的说话人嵌入。
-
Step 1:全 utterance 输入与帧级特征提取
-
输入:完整语音片段(whole utterance),无需严格分帧;
-
帧级 DNN:通过多层 DNN(图中蓝色方块)处理每一帧语音,输出帧级高维特征(黄色方块),捕捉局部声学细节。
-
-
Step 2:统计池化(statistical pooling)
-
均值 + 方差聚合:对所有帧特征计算均值(mean) 和方差(variance),拼接为一个更高维的统计向量;
-
核心优势:相比 d-vector 的简单平均,统计池化保留了语音的 “动态范围” 信息(如语速变化、音调起伏),更符合说话人特征的本质。
-
-
Step 3:瓶颈层与 x-vector 输出
-
DNN 瓶颈层:统计向量通过一个小型 DNN降维,学习统计特征间的非线性关系;
-
输出 x-vector:瓶颈层输出即为最终的说话人嵌入(绿色向量),维度通常为 512 或 1024 维,可直接用于说话人分类。
-
x-vector 的核心突破在于:
-
全局信息建模:通过统计池化将变长语音转换为固定长度向量,同时保留帧间动态关系;
-
端到端判别学习:整个网络以 “说话人分类” 为目标训练,迫使模型学习对说话人身份最关键的特征(如声纹、发音习惯)。
-
SOTA 标杆:x-vector 在 VoxCeleb 等公开数据集上刷新纪录,成为后续模型(如 ECAPA-TDNN)的基准;
-
工业界落地:广泛应用于说话人验证(如手机解锁)、多说话人分离(如会议录音转写)、语音克隆(TTS 音色控制)等场景;
-
技术延续:其 “统计池化” 思想被后续模型继承并改进(如注意力池化、胶囊网络)。
x-vector 通过 “帧级特征提取→统计池化→深度优化” 的三层架构,首次实现了对说话人特征的 “动态全局建模”,解决了 d-vector 忽略时序信息的关键缺陷。
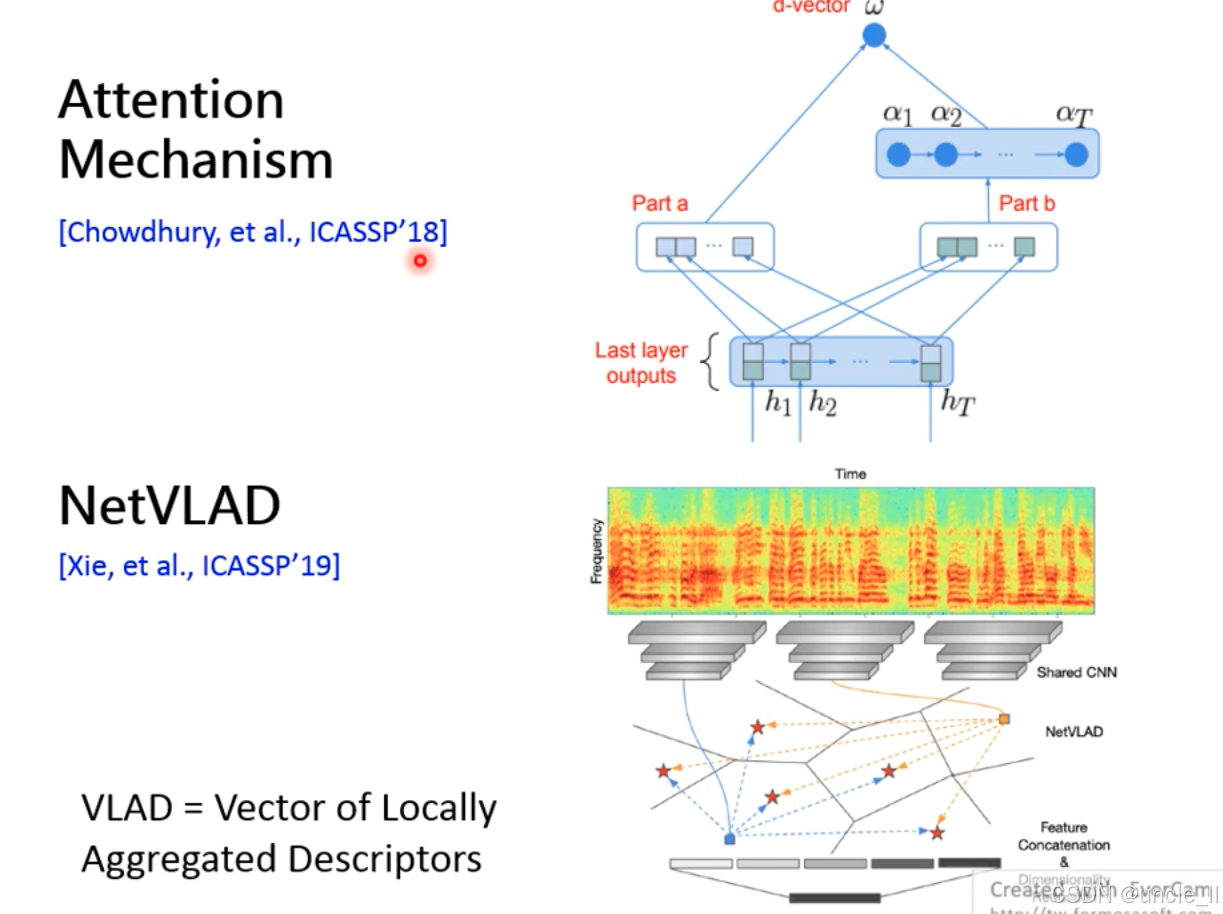
注意力机制(Attention Mechanism)和 NetVLAD,均用于解决 “如何从变长语音帧中提取鲁棒全局特征” 的问题:
注意力机制(Attention Mechanism, [Chowdhury, et al., ICASSP’18])
- 通过动态权重分配,让模型自动关注对说话人身份更重要的语音帧(如清晰发音段),抑制噪声或无关帧(如静音、背景音)。
- 帧级特征输入:底部为语音的时序特征序列(h1,h2,...,hTh_1,h_2,...,h_Th1,h2,...,hT),来自 DNN 的最后一层输出;
- 注意力权重计算(Part a + Part b):
- 通过两层神经网络(Part a 和 Part b)学习每个帧特征的注意力权重,权重和为 1;
- 重要帧权重高,次要帧权重低;
- 加权求和生成 d-vector:帧特征与注意力权重加权平均,得到最终说话人嵌入(d-vector)。
- 动态聚焦:相比 x-vector 的固定统计池化,能自适应捕捉关键语音片段(如特定元音、重音);
- 抗噪声:对噪声帧分配低权重,提升在复杂环境下的鲁棒性。
NetVLAD([Xie, et al., ICASSP’19])
VLAD(Vector of Locally Aggregated Descriptors)的神经网络实现,通过聚类残差聚合,将局部特征编码为全局嵌入,最初用于图像检索,后迁移至语音领域。
-
输入与 CNN 特征提取:通过共享卷积神经网络(Shared CNN)提取局部频谱特征;
-
聚类中心与残差计算:
-
预定义多个聚类中心(蓝色 / 红色星点);
-
每个局部特征计算与聚类中心的残差向量(特征 - 中心);
-
-
残差聚合与嵌入生成:同一聚类中心的残差向量累加,所有聚类的累加结果拼接为 NetVLAD 向量,作为最终说话人嵌入。
- 结构化聚合:通过聚类捕捉特征空间分布,比简单平均更能保留局部细节;
- 可扩展性:聚类中心数量可控,适应不同嵌入维度需求。
End to End 模型
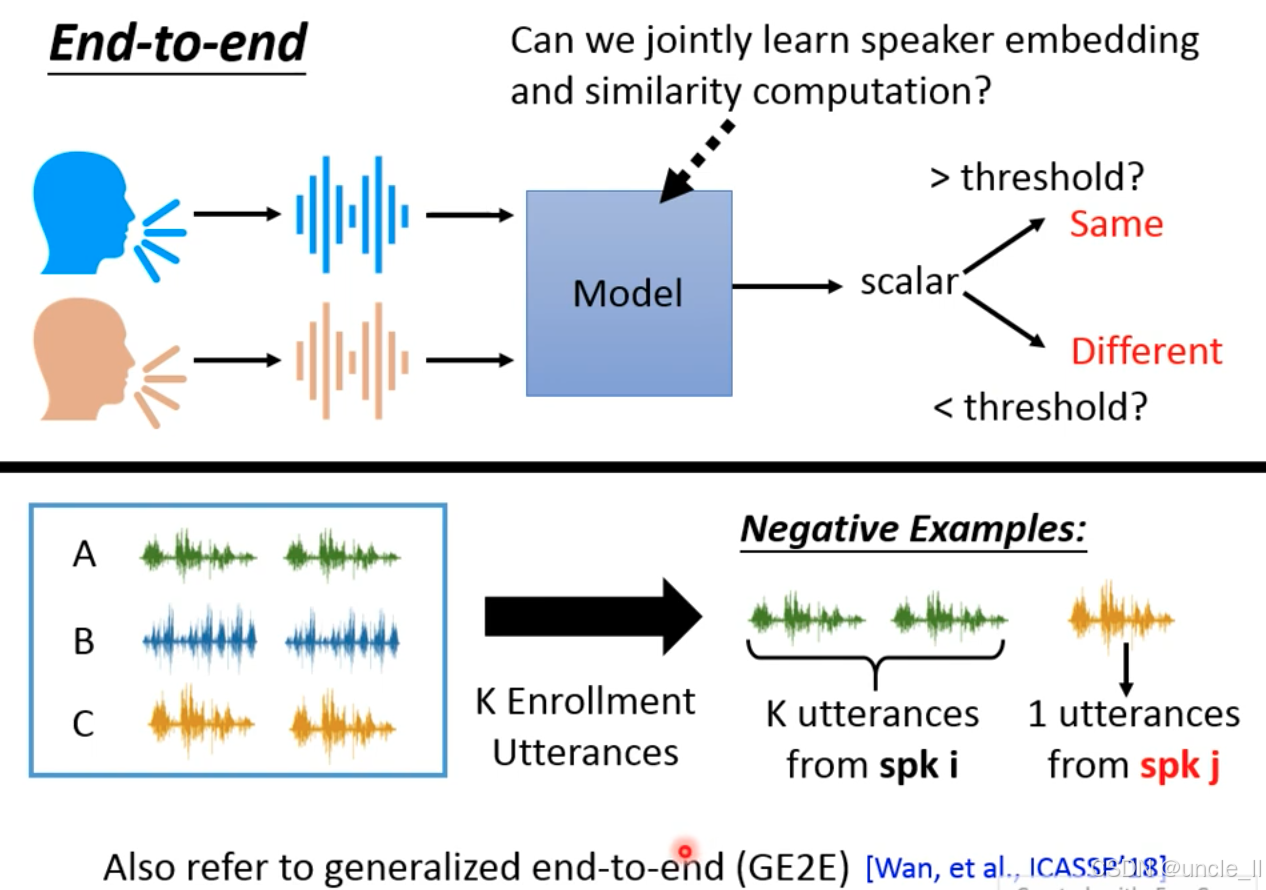
端到端模型通过对比学习训练,需要构造 正例(Positive Examples)和 负例(Negative Examples):
正例
- 数据来源:同一说话人(spk i)的语音;
- 构造方式:
- 注册语音:K 段来自 spk i 的语音;
- 待验证语音:1 段来自 spk i 的语音;
- 标签:模型应输出高相似度分数(判定为 “Same”)。
负例
- 数据来源:不同说话人(spk i 和 spk j)的语音;
- 构造方式:
- 注册语音:K 段来自 spk i 的语音;
- 待验证语音:1 段来自 spk j 的语音;
- 标签:模型应输出低相似度分数(判定为 “Different”)。
通过正例和负例的对比,让模型学习 “同一说话人语音相似度高,不同说话人相似度低” 的判别规则。
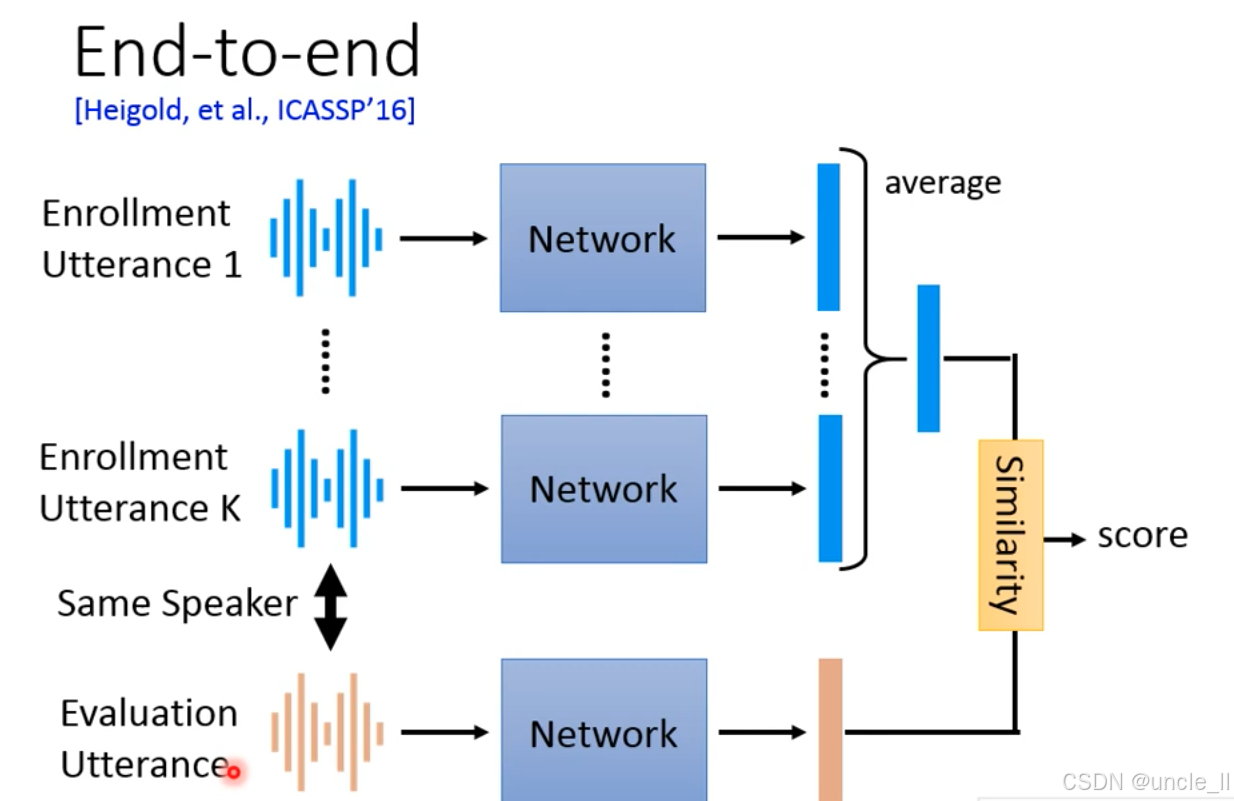
早期端到端(End-to-end)说话人验证系统的经典架构([Heigold, et al., ICASSP’16]),核心是通过 “多段注册语音平均嵌入 + 相似度计算” 实现身份验证:
(1)注册阶段(Enrollment)
- 输入:同一说话人的 K 段注册语音 ;
- 处理:每段语音通过共享神经网络提取帧级嵌入 ;
- 聚合:对 K 段语音的嵌入进行算术平均,生成该说话人的 “注册模板嵌入”。
(2)评估阶段(Evaluation)
- 输入:待验证语音;
- 处理:通过同一神经网络提取其嵌入;
- 相似度计算:对比待验证嵌入与注册模板嵌入,输出相似度分数;
- 判断:分数超过阈值则判定为 “同一说话人”。相同身份分数越高越好,不同身份分数越低越好
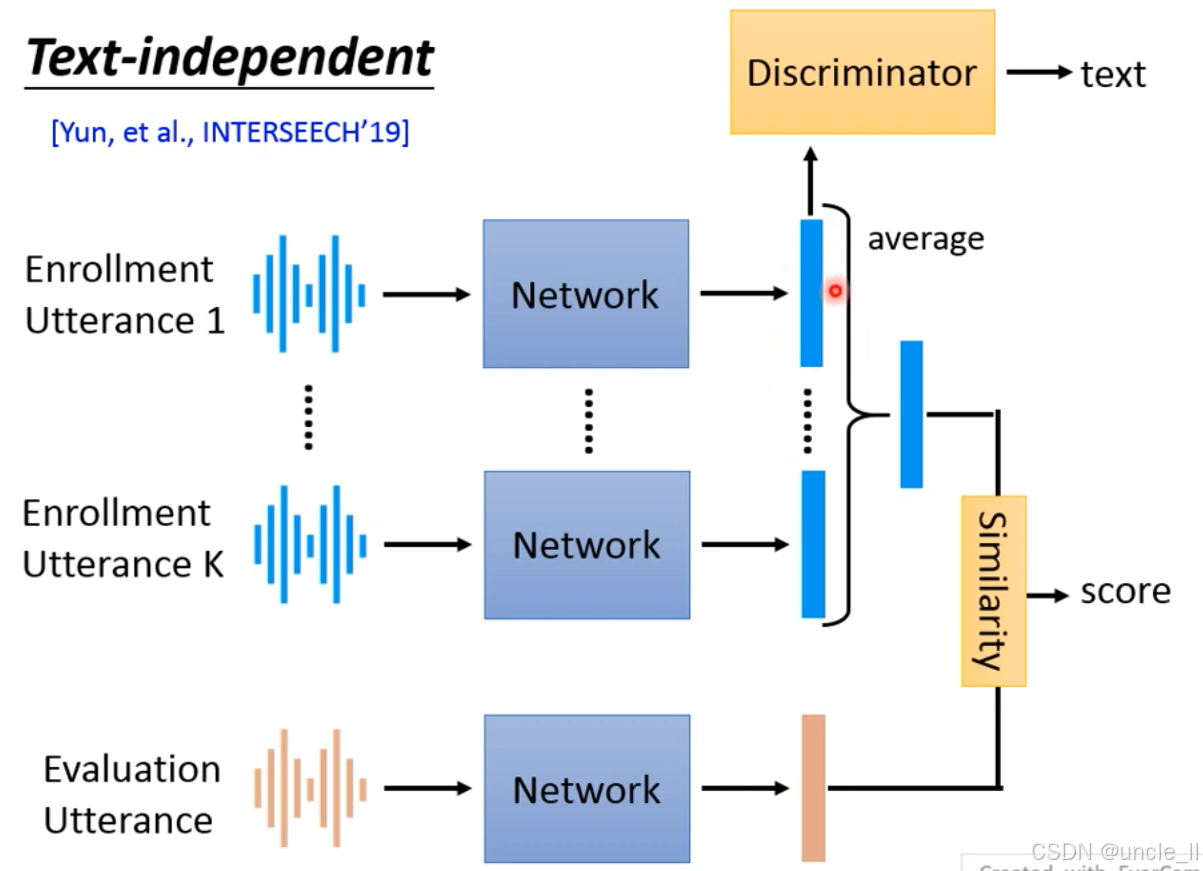
无关(Text-independent)的端到端说话人验证框架,核心是通过对抗训练解耦 “说话人身份” 和 “文本内容”,实现 “无论说什么内容,只验证身份” 的目标:验证两段语音是否来自同一说话人,与语音内容无关(如注册时说 “你好”,验证时说 “再见”,仍能准确判断)。语音同时包含 “身份特征”(声纹、发音习惯)和 “文本特征”(内容、词汇),需让模型只学习身份特征,忽略文本干扰。
- Network 的目标:让嵌入仅包含身份信息,使 Discriminator无法预测文本内容(欺骗判别器);
- Discriminator 的目标:尽可能准确预测文本内容,迫使 Network去除嵌入中的文本信息;
- 结果:通过对抗训练,Network 最终学习到与文本无关、仅含身份的特征嵌入,实现 “Text-independent” 验证。