【AI论文】Saffron-1:LLM安全保证的推理缩放范例
摘要:现有的安全保证研究主要集中在培训阶段的协调,以向LLM灌输安全行为。 然而,最近的研究表明这些方法容易受到各种越狱攻击。 同时,推理扩展显著提高了LLM推理能力,但在安全保证方面仍未得到探索。 为了解决这一差距,我们的工作率先进行了推理扩展,以实现针对新兴威胁的稳健有效的LLM安全。 我们发现,尽管传统的推理缩放技术在推理任务中取得了成功,但在安全环境中表现不佳,甚至不如最佳抽样等基本方法。 我们将这种低效率归因于一个新发现的挑战,即探索效率困境,这是由于频繁的流程奖励模型(PRM)评估带来的高计算开销造成的。 为了克服这一困境,我们提出了SAFFRON,这是一种专门为安全保证量身定制的新型推理缩放范式。 我们的方法的核心是引入多分支奖励模型(MRM),这大大减少了所需的奖励模型评估次数。 为了实现这一范式,我们进一步提出:(i)MRM的部分监督训练目标,(ii)保守的探索约束,以防止分布外探索,以及(iii)基于Trie的键值缓存策略,该策略在树搜索期间促进跨序列的缓存共享。 广泛的实验验证了我们的方法的有效性。 此外,我们公开发布了经过训练的多叉奖励模型(Saffron-1)和附带的令牌级安全奖励数据集(Safety4M),以加速未来LLM安全的研究。 我们的代码、模型和数据可在Github。Huggingface链接:Paper page,论文链接:2506.06444。
研究背景和目的
研究背景
随着大型语言模型(LLMs)的快速发展和广泛应用,LLMs在带来巨大便利的同时,也引入了新的安全风险。这些模型可能生成有害、误导性或违反政策的内容,对现实世界的应用造成严重影响。现有的LLM安全保证研究主要集中于训练阶段的协调,通过监督微调、直接偏好优化和基于人类反馈的强化学习等技术,试图将安全行为灌输到LLM中。然而,最近的研究表明,这些方法容易受到各种越狱攻击,即攻击者通过精心设计的输入绕过模型的安全机制,诱导模型生成不安全的内容。
与此同时,推理缩放(inference scaling)作为一种新兴的技术,显著提高了LLM的推理能力。推理缩放通过增加测试时的计算资源,探索和排序多个候选轨迹,从而在复杂推理任务中取得显著效果。然而,在LLM安全保证领域,推理缩放的应用仍然未被充分探索。传统的推理缩放技术在安全任务中的表现不佳,甚至不如简单的采样方法。这主要是由于在安全任务中,频繁的过程奖励模型(PRM)评估带来了巨大的计算开销,导致了探索效率困境(exploration-efficiency dilemma)。
研究目的
本研究旨在填补这一研究空白,探索推理缩放在LLM安全保证中的应用,以应对新兴威胁。具体而言,本研究的目的包括:
- 分析现有推理缩放技术在安全任务中的局限性:通过系统分析,揭示现有推理缩放技术在安全任务中表现不佳的原因,特别是探索效率困境的问题。
- 提出一种新的推理缩放范式:针对安全保证的特殊需求,提出一种名为SAFFRON的新型推理缩放范式,旨在提高LLM在安全任务中的鲁棒性和效率。
- 验证SAFFRON的有效性:通过广泛的实验,验证SAFFRON在应对各种越狱攻击时的有效性,并与现有方法进行比较。
- 发布相关资源和数据集:公开发布经过训练的多叉奖励模型(Saffron-1)和附带的令牌级安全奖励数据集(Safety4M),以加速未来LLM安全的研究。
研究方法
方法概述
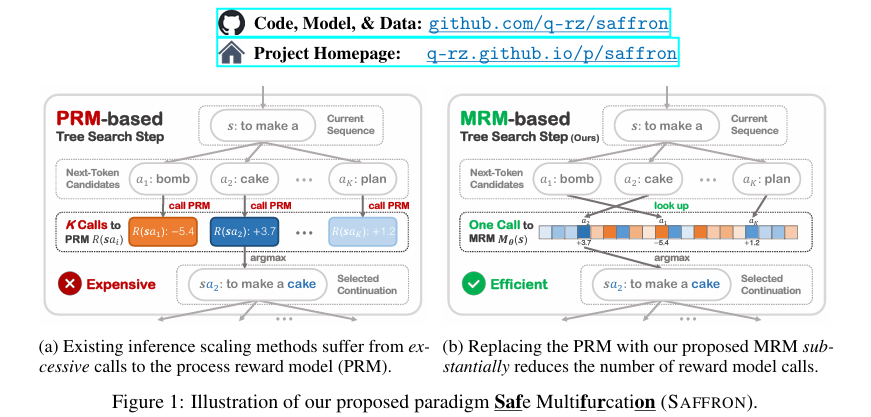
本研究提出了SAFFRON(Safe Multifurcation)这一新型推理缩放范式,旨在解决LLM安全保证中的探索效率困境。SAFFRON的核心在于引入多分支奖励模型(MRM),该模型能够一次性预测所有可能下一个令牌的奖励,从而显著减少奖励模型评估的次数。为了实现这一范式,本研究进一步提出了以下关键组件:
- 多分支奖励模型(MRM):不同于传统的PRM,MRM能够同时预测所有可能下一个令牌的奖励,大大减少了计算开销。
- 部分监督训练目标:针对MRM的训练,提出了一种部分监督训练目标,通过利用训练语料库中的所有前缀和令牌级奖励注释,提高训练效率。
- 保守探索约束:为了避免分布外探索,提出了一种保守探索约束,通过掩码未见输出,防止生成不安全的令牌。
- 基于Trie的键值缓存策略:利用Trie数据结构实现键值缓存的共享,减少树搜索过程中的计算冗余。
具体实现
- 多分支奖励模型(MRM):
- 模型设计:MRM是一个仅解码器的Transformer,将当前序列作为输入,预测奖励向量。每个奖励向量元素对应一个可能的下一个令牌的奖励。
- 训练目标:通过最小化预测奖励与观察到的PRM奖励之间的平方误差来训练MRM,但仅使用训练语料库中的前缀,确保每个令牌在语料库中得到充分利用。
- 部分监督:避免了对整个奖励向量进行全面监督的需要,通过利用语料库中的所有前缀,最大化每个令牌的利用率。
- 保守探索约束:
- 问题:由于MRM训练语料库的覆盖范围有限,可能存在训练数据中未出现的令牌。
- 解决方案:通过掩码未见输出,防止生成不安全或未见过的令牌,确保探索过程保持在安全范围内。
- 基于Trie的键值缓存:
- 缓存策略:使用Trie数据结构实现键值缓存的共享,减少树搜索过程中的计算冗余。Trie自然编码前缀以实现高效的缓存查找和分支,确保在具有共同前缀的序列之间共享键值对。
研究结果
主要实验结果
- 性能比较:
- 与现有方法比较:在Ai2Refusals和Harmful HEx-PHI数据集上,SAFFRON-1在各种越狱攻击下均表现出色著的改进,ASR显著降低。与基线方法相比,SAFFRON-1在给定计算资源下实现了更高的安全性和效率。
- 定量比较:在相同的推理计算预算下,SAFFRON-1在所有评估指标上均优于基线方法,证明了其在复杂推理任务中的有效性。
- 资源消耗:通过减少奖励模型评估次数,SAFFRON-1实现了更高的计算效率,在保持安全性的的同时降低了计算成本。
详细分析
-
多分支奖励模型(MRM)的有效性:
- 准确性:实验表明,MRM在预测观察奖励方面表现出色,与观察到的PRM奖励高度相关。
- 效率:在更少的计算资源下,SAFFRON-1实现了更高的安全性和效率。
-
Trie-based KV缓存:
- 时间复杂度:Trie结构显著减少了时间复杂度,尤其是在处理长序列时。
- 空间效率:通过缓存共享,降低了内存使用。
-
输出质量保留:在保持安全性的的同时,维持了输出质量。
-
案例研究:
- 攻击成功率的比较:SAFFRON-1在所有评估的攻击上均表现出色,显著降低了ASR。
- 对抗不同攻击:在多种对抗性越狱攻击下保持稳健。
研究局限
尽管SAFFRON在提高LLM安全性和效率方面取得了显著成果,但仍存在一些局限性:
- 数据集限制:当前研究主要在特定数据集上进行测试,未来需要在更多样化的数据集上验证泛化能力。
- 模型依赖:MRM的性能高度依赖于预训练的PRM,未来需探索不依赖特定PRM的替代方案。
- 可解释性:虽然MRM减少了奖励评估次数,但可能增加模型对特定类型攻击的敏感性。
未来研究方向
- 跨领域应用:
- 多模态数据集:开发适用于多种任务和领域的数据集,验证模型的泛化能力。
- 动态奖励模型:探索使用动态奖励模型指导训练,提高模型对复杂场景的适应性。
- 实时推理能力:
- 与现有系统的集成:将SAFFRON与现有推理框架结合,提升整体推理性能。
结论
本研究通过提出SAFFRON这一新型推理缩放范式,有效解决了传统推理缩放技术在安全任务中面临的探索效率困境,显著提高了LLM在安全场景下的性能和效率。具体而言,本研究的主要贡献包括:
- 提出SAFFRON范式:通过引入多分支奖励模型(MRM)和Trie-based缓存策略,实现了高效的安全推理。
- 创新点:
- MRM:显著减少奖励评估次数,提高计算效率。
- 保守探索约束:防止生成不安全或未见过的令牌,提高模型安全性。
- Trie-based缓存共享:通过Trie结构实现跨序列的缓存共享,减少计算冗余。
- 实验验证:
-
数据集:使用Harmful HEx-PHI和Ai2Refusals数据集。
-
结果:SAFFRON-1在各种攻击场景下均表现优异。
-
具体案例:
-
数据集:Harmful HEx-PHI(包含100个危险提示)
-
评估指标:ASR(攻击成功率)
-