蒸馏微调DeepSeek-R1-Distill-Qwen-7B
数据集:中文基于满血DeepSeek-R1蒸馏数据集(Chinese-Data-Distill-From-R1)
中文数据集中的数据分布如下:
Math:共计36568个样本,
Exam:共计2432个样本,
STEM:共计12648个样本,
General:共计58352,包含弱智吧、逻辑推理、小红书、知乎、Chat等。
数据样例

基于unsloth进行微调
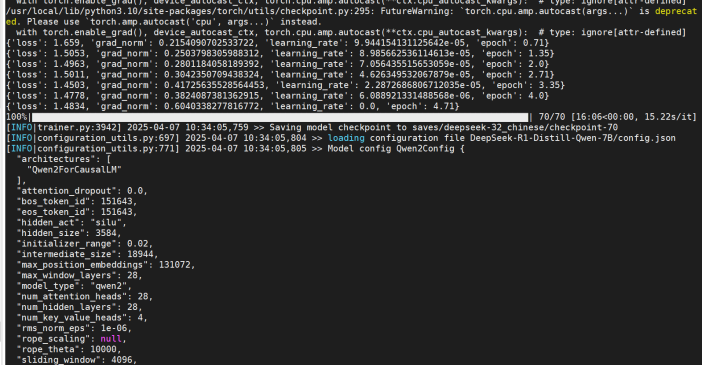
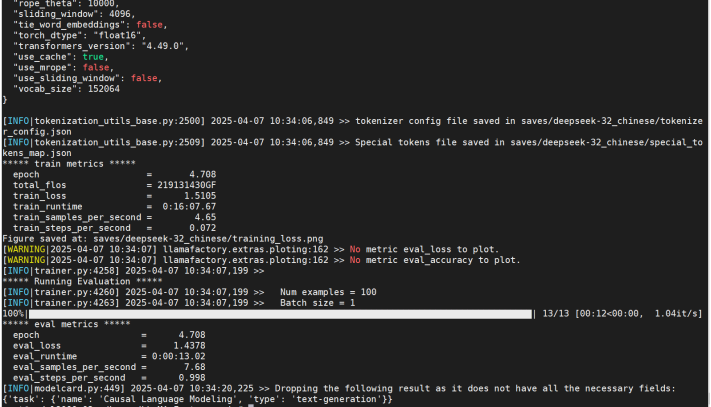
微调过程及显存占用
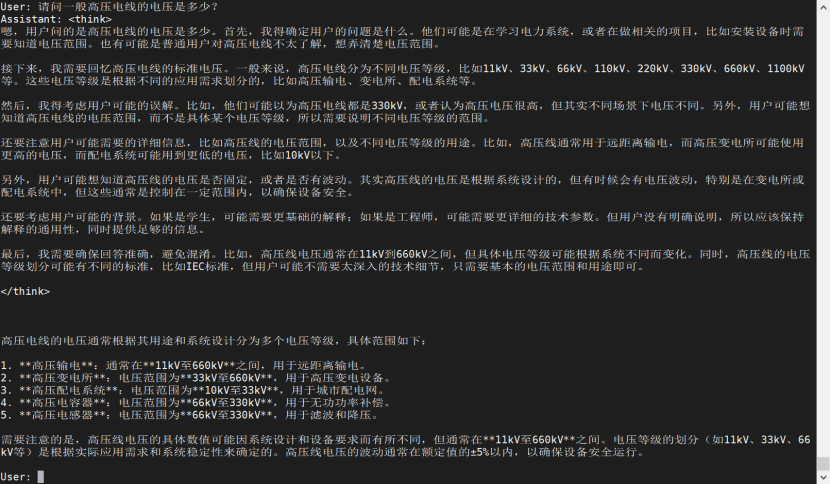
微调后推理测试
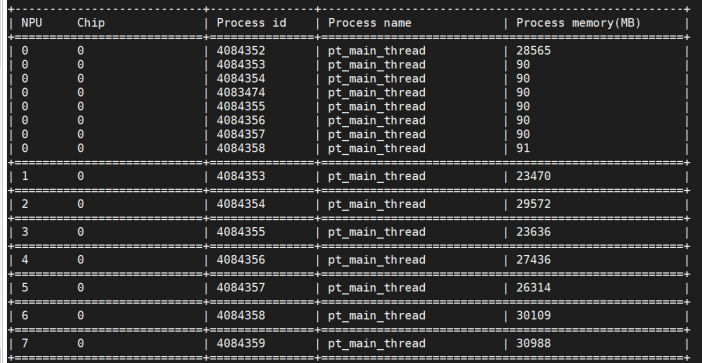
推理显存占用
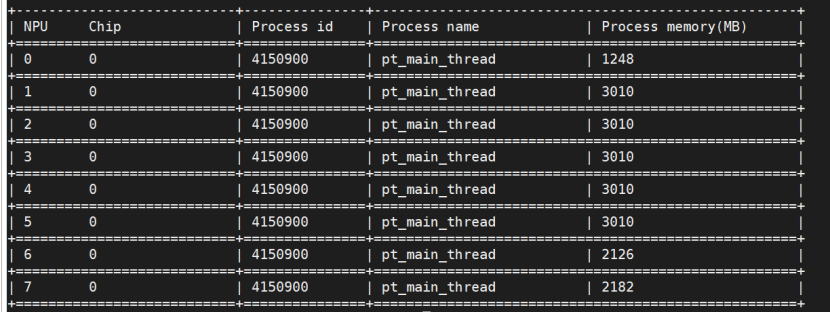
在通用数据集上微调很成功,但是,在专业数据集上微调却不行,我使用控制变量进行了许多次测试,都无法得到好的效果,无论是回答格式,还是回答内容,都无法使用。至少在华为910上是这样