基于Python+MongoDB猫眼电影 Top100 数据爬取与存储
前言:从猫眼电影排行榜页面(TOP100榜 - 猫眼电影 - 一网打尽好电影 )爬取 Top100 电影的电影名称、图片地址、主演、上映时间和评分等关键信息,并将这些信息存储到本地 MongoDB 数据库中,🔗 相关链接Xpath,可视化🔥🔥🔥
❤ 【作者主页—📚优质文章、获取更多优质源码】
目录
一. 准备工作
二. 编写函数
2.1 连接MongoDB数据库
2.2 数据爬取
三. 运行结果
四. 更多干货
一. 准备工作
我们在编写python代码前,首先要导入用到的一些库 ,如果没有BeautifulSoup,就在终端输入pip install BeautifulSoup下载即可
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
import re
import time
import random二. 编写函数
def自定义函数名scrape_maoyan_top100,然后定义url网址,设置请求头
def scrape_maoyan_top100():url = "https://www.maoyan.com/board/4"headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36','Referer': 'https://www.maoyan.com/','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8','Accept-Language': 'zh-CN,zh;q=0.9','Cache-Control': 'max-age=0','Connection': 'keep-alive'}为了提高代码健壮性,使用try函数作异常处理,time.sleep()保障每次请求之间的随机延迟,通过避免短时间内频繁发送请求,保证数据爬取过程的稳定性和可持续性,接着发送get请求检验响应的状态码,使用utf-8解码,并将获取到的 HTML 内容赋值给html变量,保存为maoyan.html,然后BeautifulSoup解析 html
try:time.sleep(random.uniform(1, 3))response = requests.get(url, headers=headers, timeout=10)response.raise_for_status()response.encoding = 'utf-8'html = response.textwith open('maoyan.html', 'w', encoding='utf-8') as f:f.write(html)soup = BeautifulSoup(html, 'html.parser')2.1 连接MongoDB数据库
使用MongoClient('mongodb://localhost:27017/')连接到本地运行的 MongoDB 服务器,获取本地连接中的数据库对象maoyan和集合对象top_movies,在插入数据之前,先清空集合中的原有数据,以保证每次运行代码存储的都是最新数据
client = MongoClient('mongodb://localhost:27017/')db = client['maoyan']collection = db['top_movies']collection.delete_many({})2.2 数据爬取
首先我们要分析该网页的html结构,如下图所示,所有的电影信息被包裹在一个 class 为 board-wrapper 的元素中,该元素起到了一个容器的作用
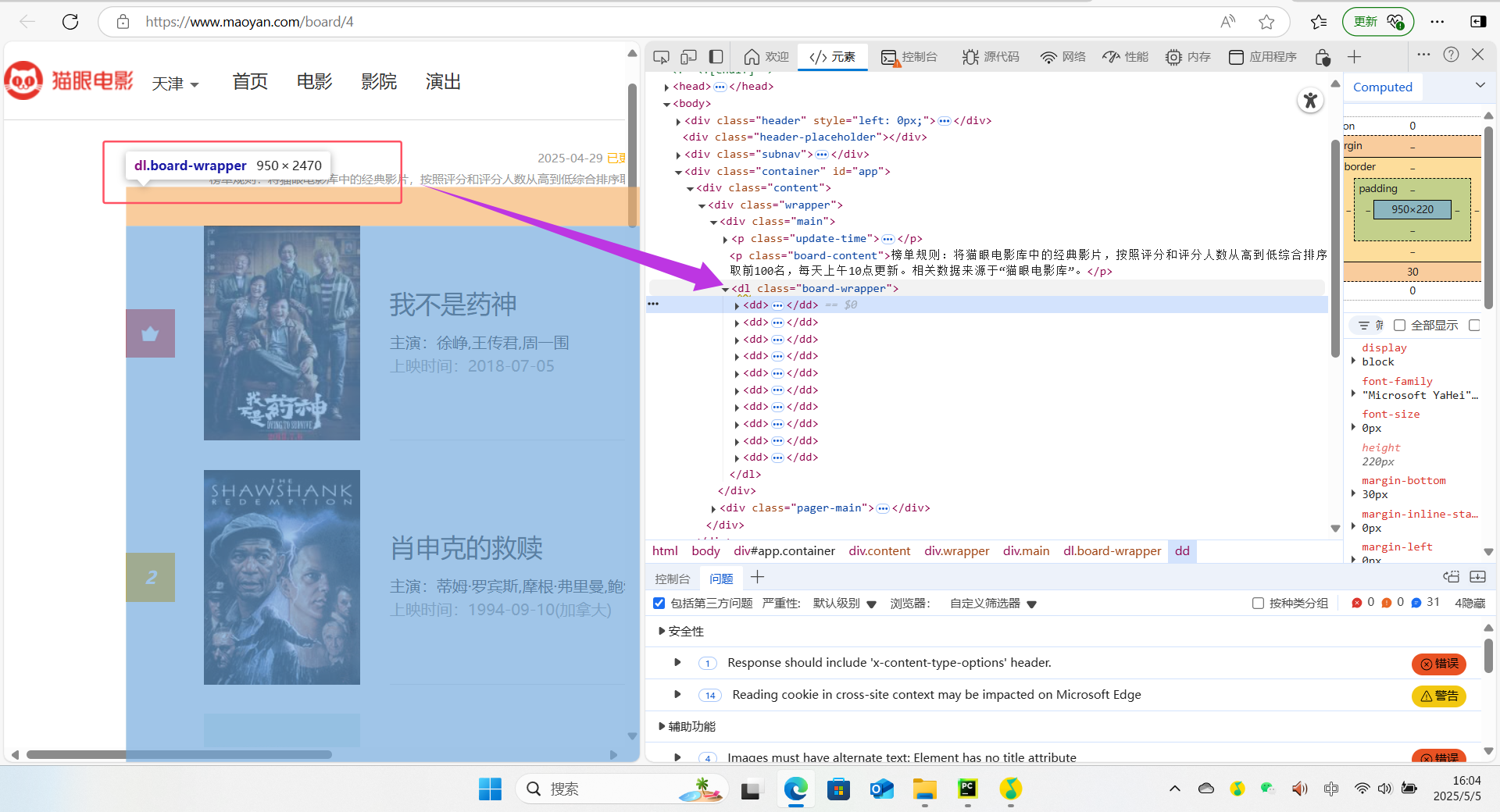
如下图所示,第一个<dd>标签包含第一部电影的所有信息,我们可以看到下方黄色的边框里的每一个并列的<dd>标签,就可以推断出每部电影的信息都以<dd>标签为单位进行包裹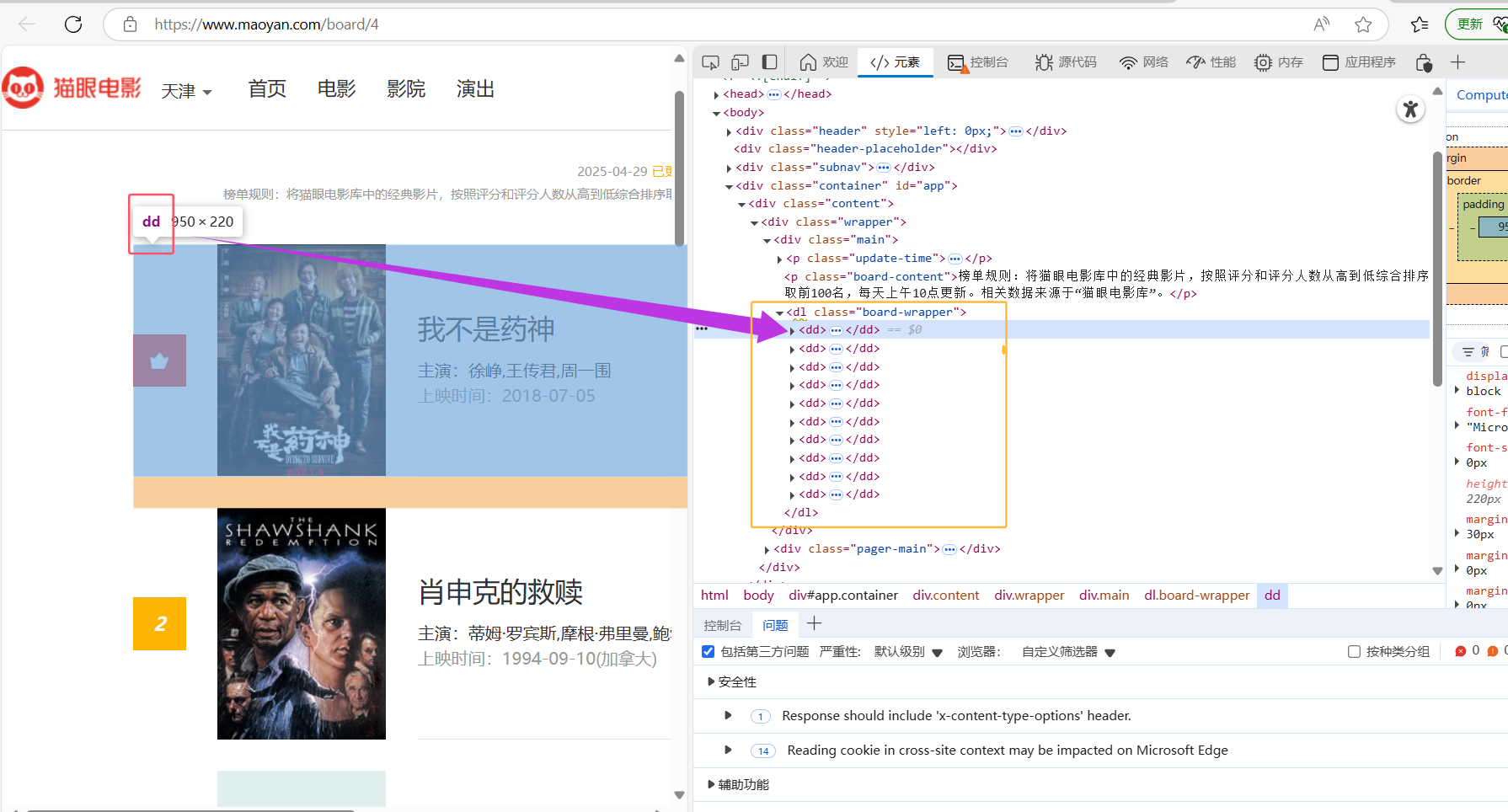
根据以上两幅图片,我们可以总结出该网站的缩略html结构(仅包含电影信息)如下
<dl class="board-wrapper><dd>第一部电影的信息 </dd><dd>第二部电影的信息 </dd></dl>分析完网页结构后,接着写soup.select🔍('.board-wrapper dd') 就会选择到 <dl class="board-wrapper"> 内部的所有 <dd> 标签,也就是每部电影的信息所在的标签
select🔍 是 BeautifulSoup 对象的一个方法,它可以依据 CSS 选择器来筛选元素;CSS 选择器是一种用于选择 HTML 元素的语法,借助它能够快速定位到所需的元素。
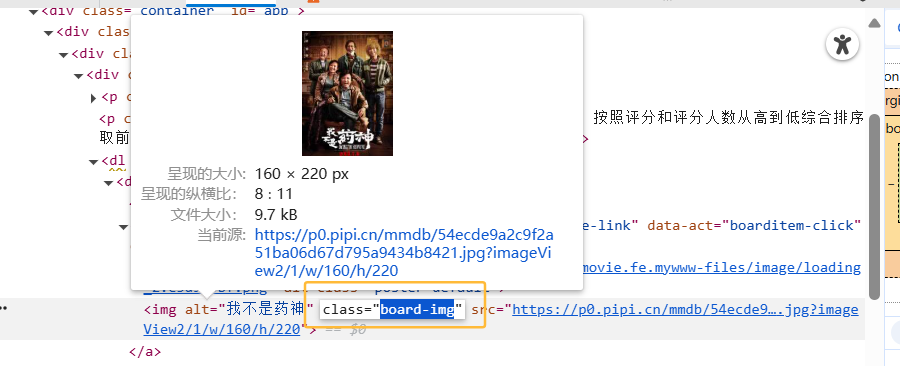
然后定义一个空列表 movie_data_list,循环movie_items里面包含的每一个电影信息,从而提取出每个电影的名称、主演、评分、上映时间和电影封面地址等具体信息;接下来我们要找到电影图片的class属性,进入该网页TOP100榜 - 猫眼电影 - 一网打尽好电影右键电影图片,选择检查,然后一级一级的找到它的CSS属性.board-img,如下图所示,因为每个电影信息html结构一样,所以.board-img代表每个电影图片的属性,因此item.select_one('.board-img')是定位到图片所在的标签,接下来通过item.select_one('.board-img')获取data-src属性的值作为图片的 URL
我们以同样的方式,如下图所示,找到电影名称的CSS属性是.name,为了定位到.name下的<a>标签里面的文本,我们接着写select方法:name_tag=item.select_one('.name a'),通过name_tag来获取文本元素
movie_name = name_tag.text.strip()
电影评分、上映时间等信息也是按照以上步骤进行编码,其中需要注意的是如下图电影评分是有两个属性组成的,因此,需要我们写两个select方法并将它们组合起来,数据爬取的全部代码如下
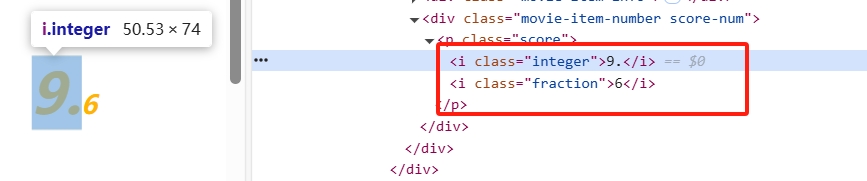
movie_items = soup.select('.board-wrapper dd')movie_data_list = []for item in movie_items:try:img_tag = item.select_one('.board-img')img_url = img_tag['data-src'] if img_tag and 'data-src' in img_tag.attrs else img_tag['src'] if img_tag else Noneif img_url and img_url.startswith('//'):img_url = 'https:' + img_urlname_tag = item.select_one('.name a')movie_name = name_tag.text.strip() if name_tag else Nonestars_tag = item.select_one('.star')stars = stars_tag.text.replace('主演:', '').strip() if stars_tag else Nonerelease_tag = item.select_one('.releasetime')release_time = release_tag.text.strip() if release_tag else Noneinteger_tag = item.select_one('.integer')fraction_tag = item.select_one('.fraction')score = (integer_tag.text.strip() + fraction_tag.text.strip()) if integer_tag and fraction_tag else None最后获取到的数据以字典形式组织,包含movie_name(电影名称)、img_url(图片地址)、stars(主演)、release_time(上映时间)、score(评分)和crawl_time(抓取时间)。然后,批量插入到 MongoDB 数据库的top_movies集合中
movie_data = {'movie_name': movie_name,'img_url': img_url,'stars': stars,'release_time': release_time,'score': score,'crawl_time': time.strftime('%Y-%m-%d %H:%M:%S')}movie_data_list.append(movie_data)编写主函数运行程序
if __name__ == "__main__":scrape_maoyan_top100()三. 运行结果
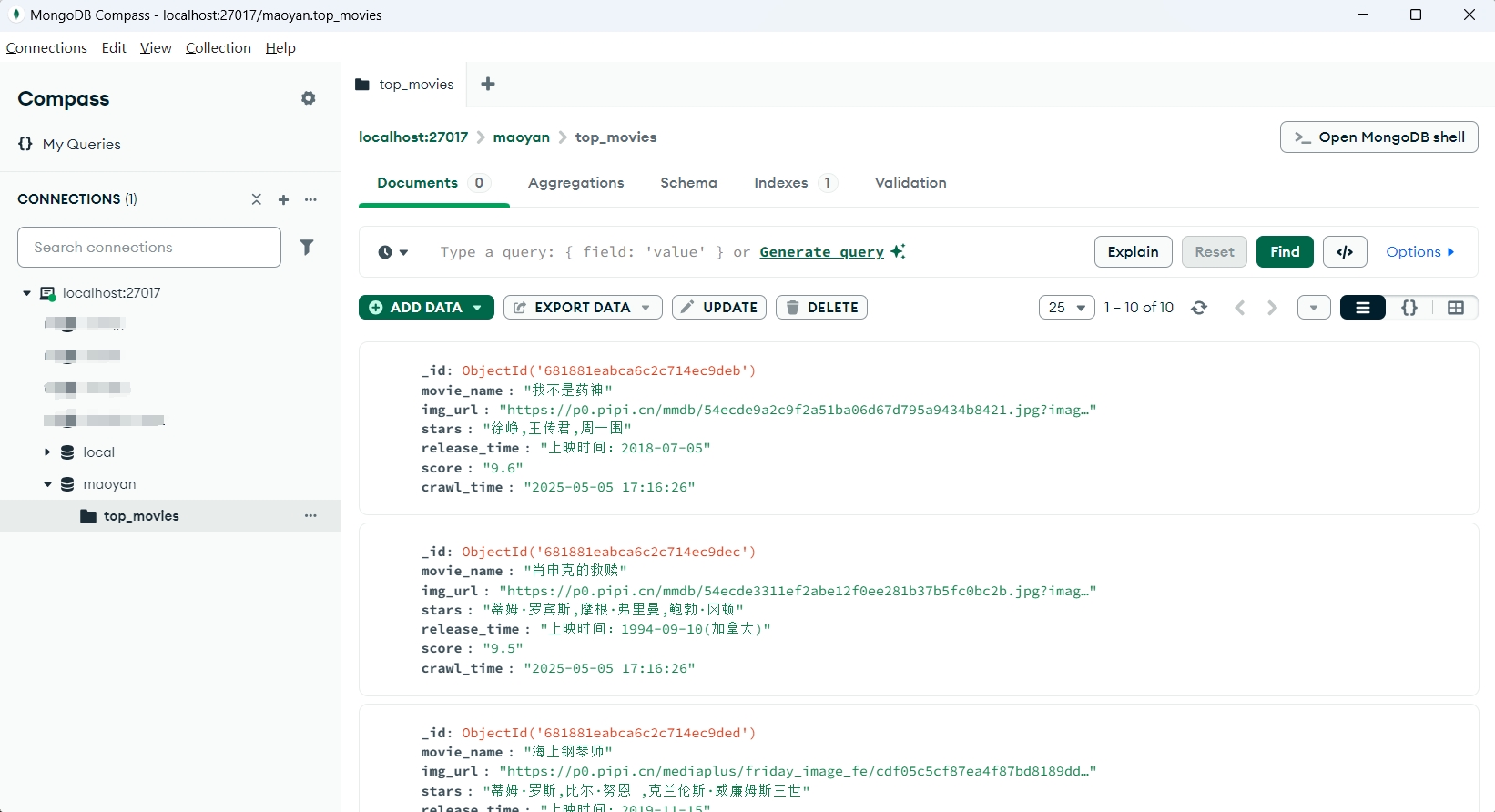
四. 更多干货
--------------------- - -----✈--------- ---------✈--------------------✈-------
1.如果我的博客对你有帮助或你喜欢我的博客内容,请 “👍点赞” “✍️评论” “★收藏” 一键三连哦!
2.❤️【👇🏻👇🏻👇🏻关注我| 获取更多源码 | 优质文章】 带您学习各种前端插件、3D炫酷效果、图片展示、文字效果、以及整站模板 、HTML模板 、微信小程序模板 、等! 「在这里一起探讨知识,互相学习」!
3.以上内容技术相关问题✉欢迎一起交流学习 ☟ ☟ ☟
————————————————