Week 14: 深度学习补遗:迁移学习
文章目录
- Week 14: 深度学习补遗:迁移学习
- 摘要
- Abstract
- 1. Transfer Learning 迁移学习
- 2. Model Fine-tuning 模型微调
- 3. Multitask Learning 多任务学习
- 4. Domain-adversarial Training 领域对抗学习
- 5. Zero-shot Learning 零样本学习
- 6. 其他类别
- 总结
Week 14: 深度学习补遗:迁移学习
摘要
本周主要跟随李宏毅老师的课程学习了迁移学习相关的内容,主要对模型微调、多任务学习、领域对抗学习和零样本学习进行了较为深入的了解。
Abstract
This week, I primarily followed Professor Hung-yi Lee’s course to study topics related to transfer learning, gaining a deeper understanding of model fine-tuning, multi-task learning, domain adversarial learning, and zero-shot learning.
1. Transfer Learning 迁移学习
迁移学习产生的背景是,如果我们有大量与任务不直接相关的数据,是否能利用这些数据帮助我们完成任务?
例如,
-
同任务、异领域(招财猫、高飞狗图片分类与真实猫狗分类任务);
-
异任务、同领域(大象、老虎图片分类和真实猫狗分类任务)。
因此,我们可以把不直接相关的数据称为Source Data,把直接相关的数据称为Target Data。
还有一个分类方式是通过Source Data和Target Data是否有标注来进行分类,例如:
| Target Data: Labelled | Target Data: Unlabelled | |
|---|---|---|
| Source Data: Labelled | Model-fine Tuning, Multitask Learning | Domain-adversarial Training, Zero-shot Learning |
| Source Data: Unlabelled | Self-taught Learning | Self-taught Clustering |
参考文章:李宏毅机器学习课程笔记7:Transfer Learning、SVM、Structured Learning - Introduction
2. Model Fine-tuning 模型微调
模型微调,即是把在大规模源数据上预训练好的模型,再用小规模、已标注的目标数据继续训练几轮。冻结部分底层权重,仅更新顶层或全部权重,使模型专精于目标任务。
具体来说,例如训练一个语音转文字模型,其Target Data是来自某人的音频文件和文字转写标注,而Source Data是来自很多人的音频文件和文字转写标注。这个Idea非常的符合直觉,即先用Source Data训练出一个模型,把训练结果作为初始权重,再用Target data来微调模型。
但可能存在的问题是,由于Target Data可能会很少,所以就算用Source Data训练出的模型很好,用Target Data做微调的时候也可能会存在过拟合,避免这个问题需要一定的技巧,常用的就有Conservative Training和Layer Transfer。
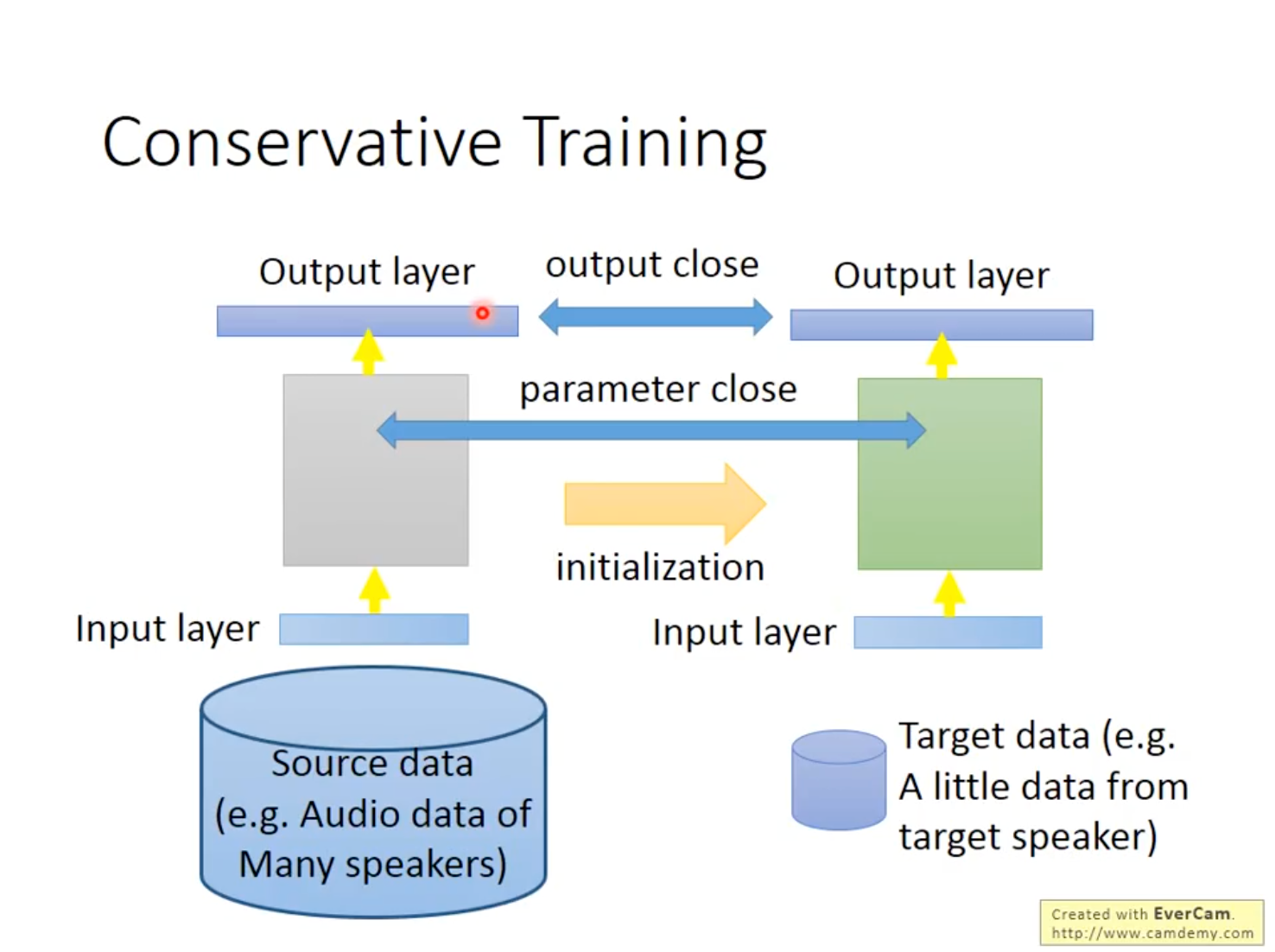
Conservative Training的中心思想就是为避免Target Data在微调模型时造成过拟合,所以增加正则化项进行约束,让同一笔Data经微调前后的Output越接近越好,或两个模型的参数越接近越好。
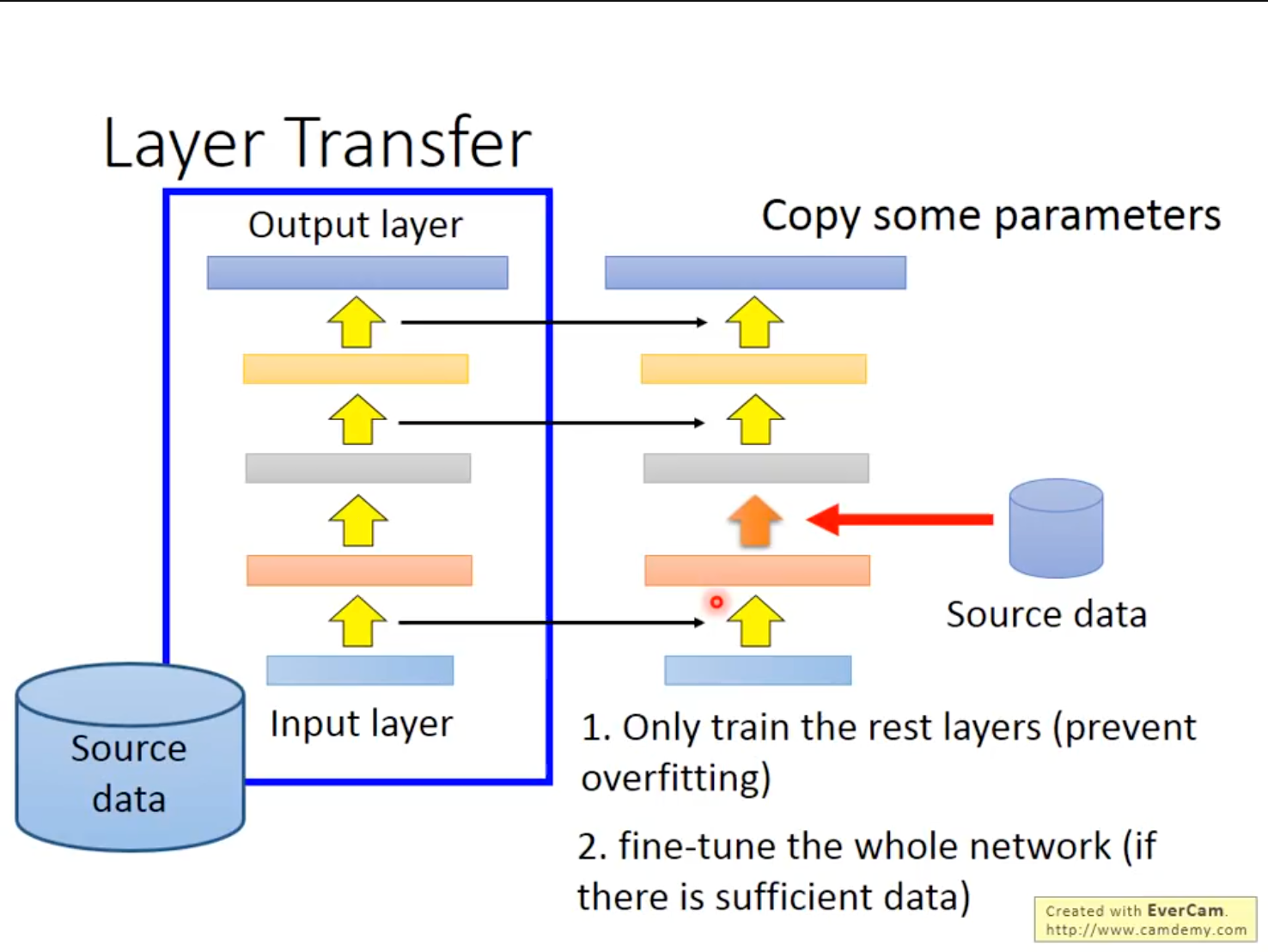
Layer Transfer的中心思想是,把Source Data训练好的模型中的某些Layer权重直接复制过来,用Target Data训练剩下的Layer。这样的好处是,Target Data训练能改变的参数有限,保证了Source Data中知识的留存,从而避免了过拟合。
在不同的任务上,需要被Transfer的Layer往往是不一样的。比如在语音识别上,通常Copy最后几层,重新训练前几层。这是因为语音识别神经网络前几层是识别语者的发音方式,后几层是识别,后几层与语者没有关系。在图像识别上,通常Copy前面几层,重新训练后面几层。这是因为图像识别神经网络的前几层是识别有没有基本的几何结构,因此可以Transfer,而后几层往往学到的比较抽象,无法Transfer。所以,哪些Layer要被Transfer是视情况而定的。
3. Multitask Learning 多任务学习
多任务学习即是让同一个网络同时解决多个相关但不同的监督任务,共享表示层。共享层捕获跨任务的通用特征,任务特定分支只学习差异部分,从而互相正则化、提升泛化。例如:Google BERT 同时训练“句子对匹配 + 单句分类 + 问答跨度预测”三个目标,最终在所有任务上得分都更好。
Multitask Learning 与 Fine-tuning 的主要区别在于,Fine-tuning过程只在意Target Domain上做得好不好,不介意微调后模型在Source Domain结果变坏。而在Multitask Learning 中,要同时在意在Target Domain与Source Domain上的性能表现。
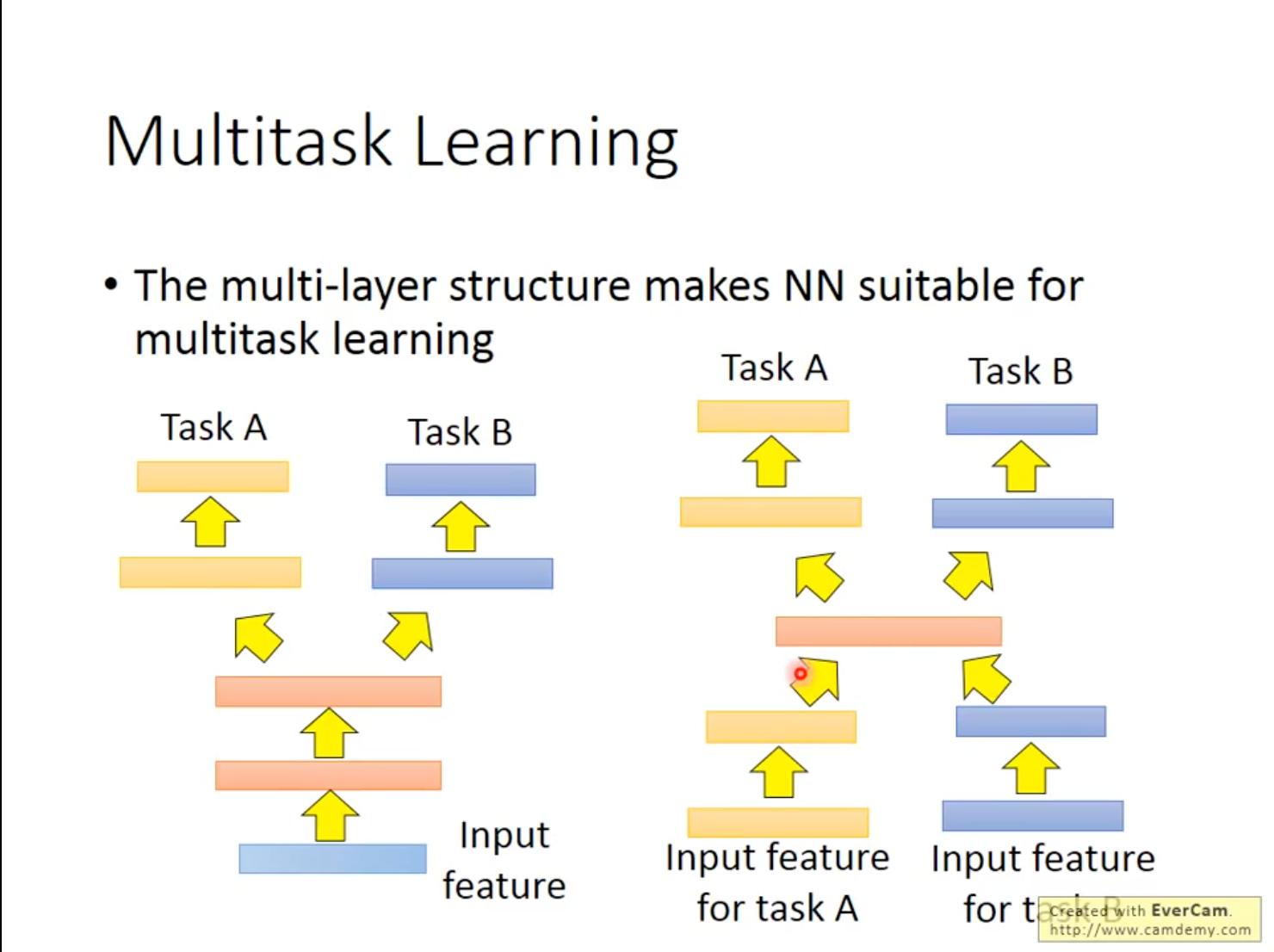
如果两个任务有共通性,则可以共用前面几个Layer(用Source Data+Target Data一起训练)。如果两个任务连输入都不能Share,则可以各经过几层Layer,把输入变换到同一个Domain上,这时中间某几层可以是Share的。
4. Domain-adversarial Training 领域对抗学习
领域对抗学习借助带标签的源域数据,在无标签的目标域上训练一个“领域不变”的特征提取器。即增加一个领域判别器,与特征提取器做对抗游戏:判别器尽力区分源/目标域,特征提取器尽力让它分不出。
领域对抗学习比较适合Target Data无标注而Source Data有标注的情况,但是当两个数据并不匹配的情况,使其Work就需要一定的思考。如果完全不考虑不匹配的情况,结果会非常差,神经网络最初几层可以看做是特征提取,而不同领域的特征一般完全不同,导致实际上结果较差。
解决方法是在特征提取层(生成器)后增加一个领域分类器(判别器),得到一个类似GAN的结构,而不同的是,在领域对抗学习中是要让生成器骗过领域分类器、同时还要让Label Predictor效果做得好。实际实践上,在特征提取层后增加一个梯度翻转层(Gradient Reversal Layer),要求特征提取层与领域分类器做相反的事情,这样可以增加训练的难度和分辨的能力。
5. Zero-shot Learning 零样本学习
零样本学习即是在训练阶段从未见过的目标类别上直接做出正确预测。例如,在 ImageNet 上训练的动物分类器,靠“有条纹、像马”的描述,第一次见“斑马”照片就能认出。
实践上的做法是,把图像的类别用Attribute表示,但数据集需要足够丰富使得每个Attribute都有足够的样本用来训练。有时Attribute的维度很高,这时可以考虑使用Embedding,将Attribute嵌入到向量空间,利用词嵌入的技巧完成工作。
还提到一个更简单的零样本学习方法,Convex Combination of Semantic Embedding,不需要训练。
6. 其他类别
Self-taught Learning: 自教学习,即用大量无标签的源域数据先自学一个通用特征提取器,再把它迁移到带标签的目标任务。实际操作上,先用无监督方法(如自编码器、对比学习)预训练,然后在目标任务上接一层 softmax 并微调。
Self-taught Clustering: 自教聚类,即只用无标签的源域和目标域数据,通过自监督信号学习一个能把目标样本按语义分组的表示空间。先对源域做自监督预训练,再在目标域上运行聚类算法(如 k-means、SCAN),使聚类结果对应潜在类别。
总结
本周对迁移学习相关内容进行了学习,主要学习了模型微调和多任务学习、领域对抗学习、零样本学习等知识,认识到迁移学习主要是利用别的领域上大量的样本训练模型初始权重优化训练过程的一些方法,对模型设计和训练有了更进一步的认识。