极客学院-从零开始学架构
极客学院-从零开始学架构
文章目录
- 极客学院-从零开始学架构
- 一:架构设计分层实现
- 1:为啥要分层
- 2:常见的分层设计
- 3:java分层架构演进
- 二:访问层架构设计
- 1:LVS接入系统
- 1.1:什么是LVS
- 1.2:LVS三种模式
- 1.3:LVS接入系统架构
- 1.4:LVS调度策略
- 1.5:LVS的优势
- 2:nginx的原理和应用
- 2.1:nginx分类和作用
- 2.2:nginx为啥性能高
- 2.3:nginx原理
- 2.4:进程模型
- 2.5:动静分离和反向代理
- 2.6:缓存设置
- 三:接口层架构设计(API网关)
- 3.1:会话管理
- 3.2:接入层控制
- 3.3:服务调用及其聚合
- 四:核心服务层架构设计
- 1:微服务
- 2:组件通信-dubbo
- 2.1:什么是dubbo
- 2.2:dubbo调用原理
- 3:组件通信-MQ
- 3.1:同步通信和异步通信
- 3.2:异步化的好处
- 3.3:消息服务分类
- 4:任务调度
- 5:池化
- 6:缓存、隔离和队列
- 6.1:缓存技术
- 6.2:隔离
- 6.3:队列
- 五:数据层架构设计
- 1:数据存储
- 2:关系型和非关系型数据库
- 3:代理访问
- 六:监控、限流和降级
一:架构设计分层实现
先记住这个网络分层图,后面会经常涉及
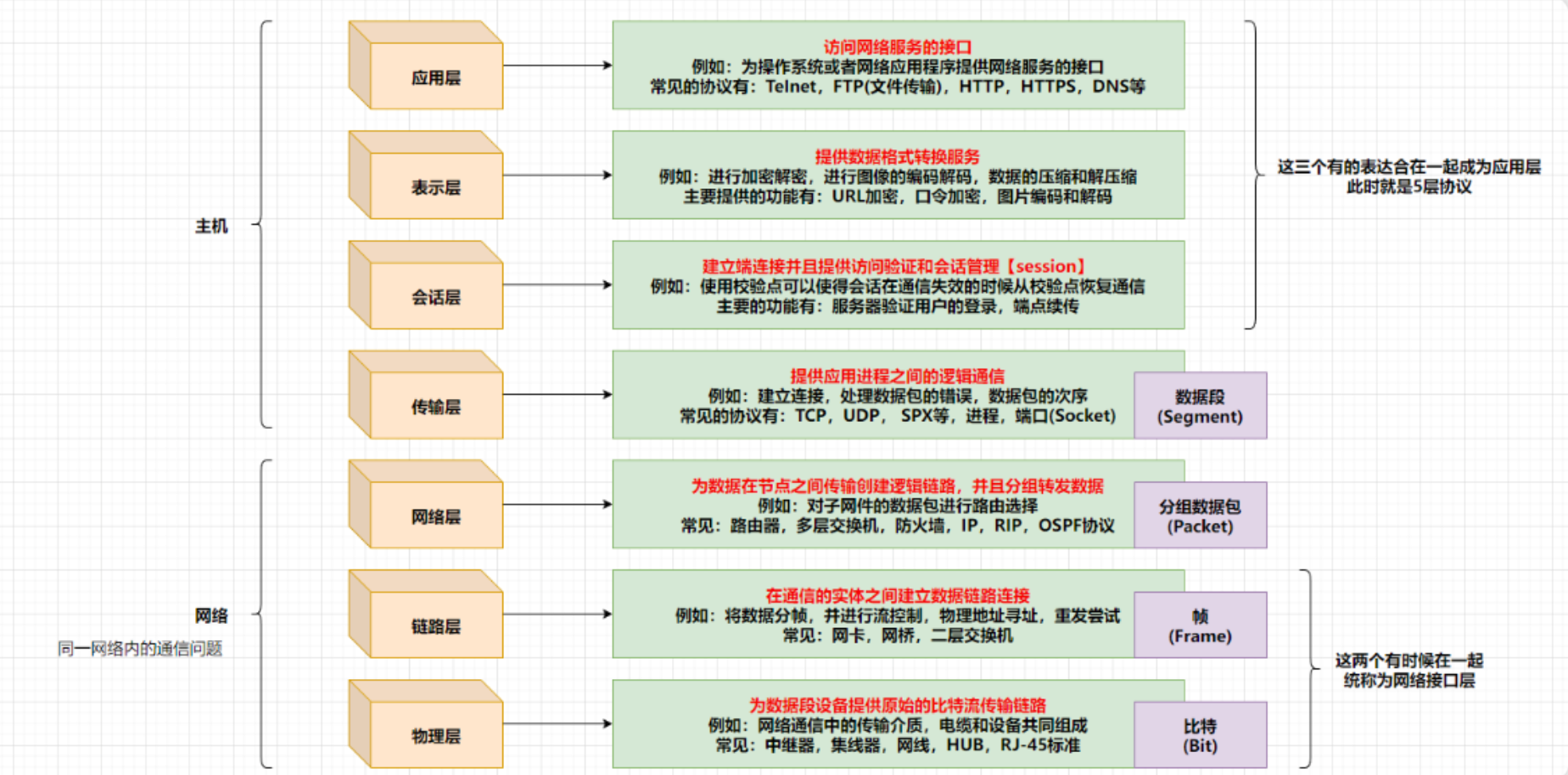
1:为啥要分层
- 分而治之:每一层解决每一层的问题
- 各司其职:每一个人都要做到自己岗位的责任
- 有条不紊的结合:分层之后各个层级的人员和工作内容要有条不紊的结合
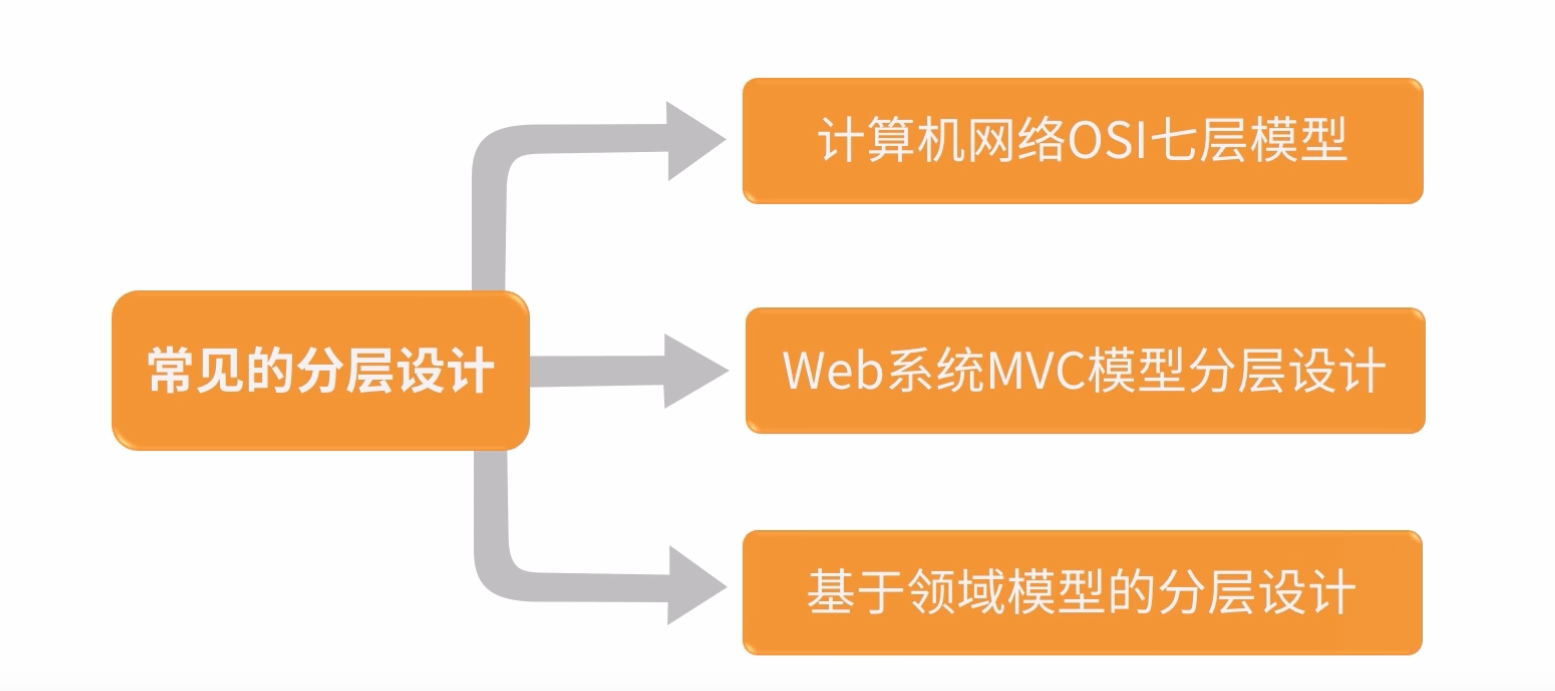
2:常见的分层设计
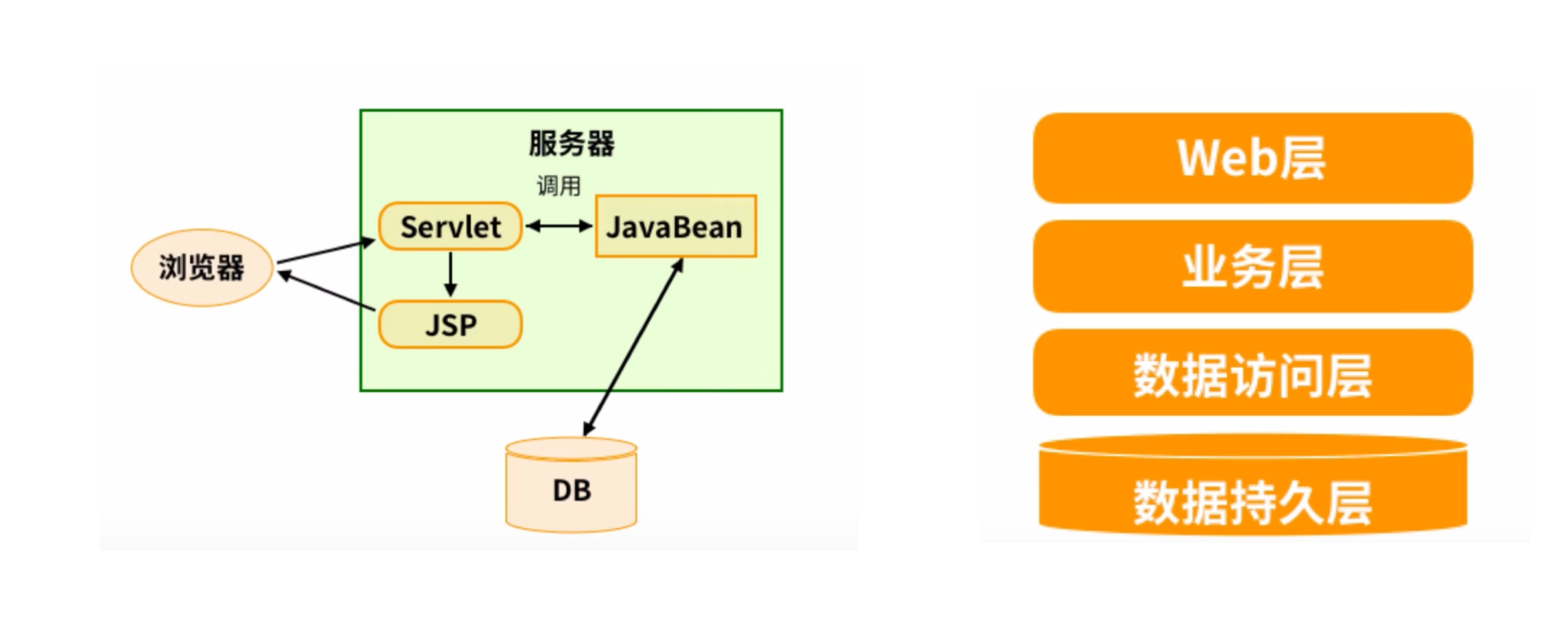
3:java分层架构演进
1.0时代-JSP时代
- Serlvet+Tomcat容器完成Web接入
- 使用JavaBean+JDBC完成数据层接入
- 使用JSP完成页面展示
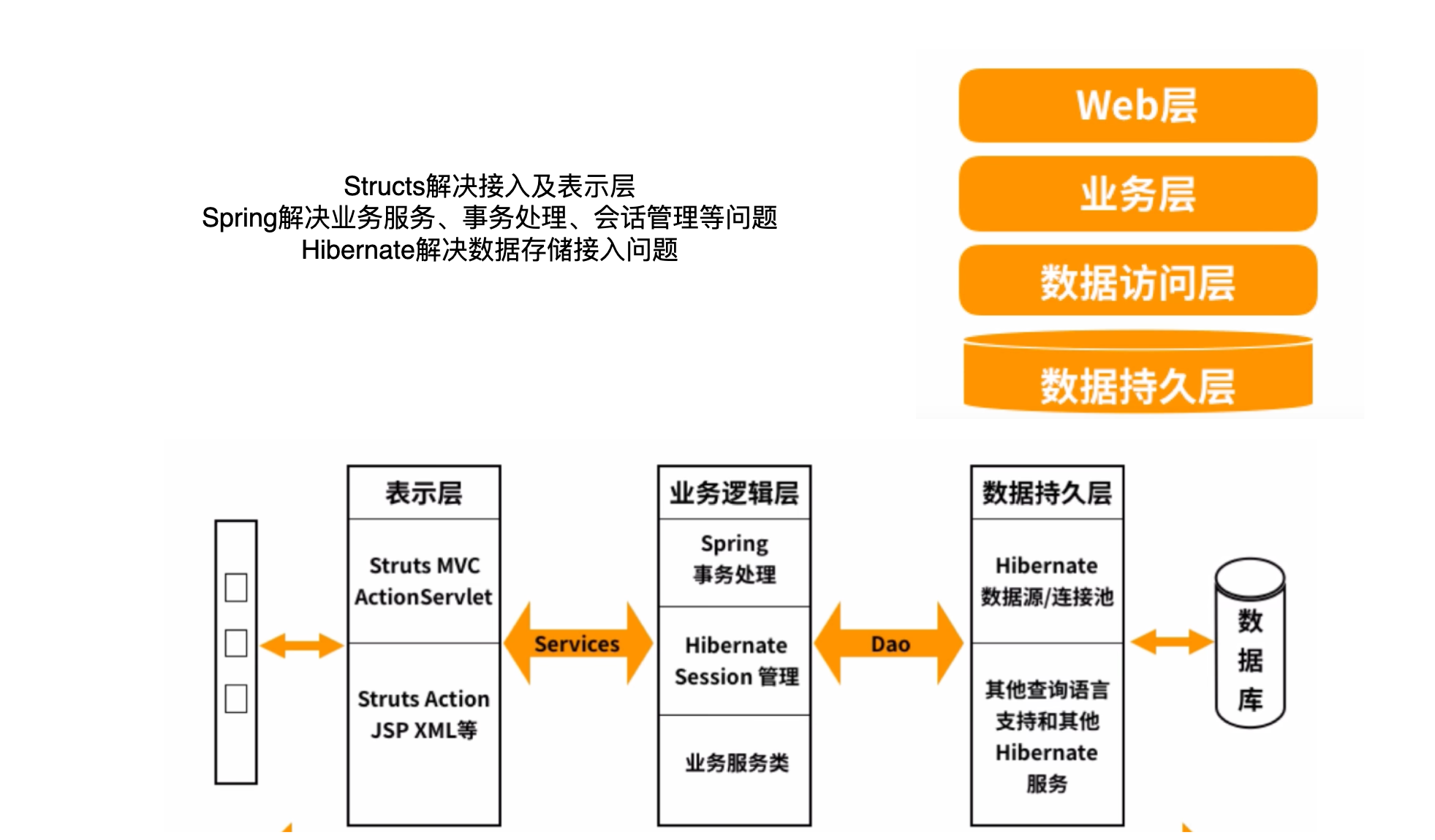
1.0时代-SSH时代
- Structs解决接入及表示层
- Spring解决业务服务、事务处理、会话管理等问题
- Hibernate解决数据存储接入问题
1.5:SSM时代
- SpringMVC解决接入及表示层
- Spring解决业务服务、事务处理、会话管理等问题
- MyBatis解决数据接入层
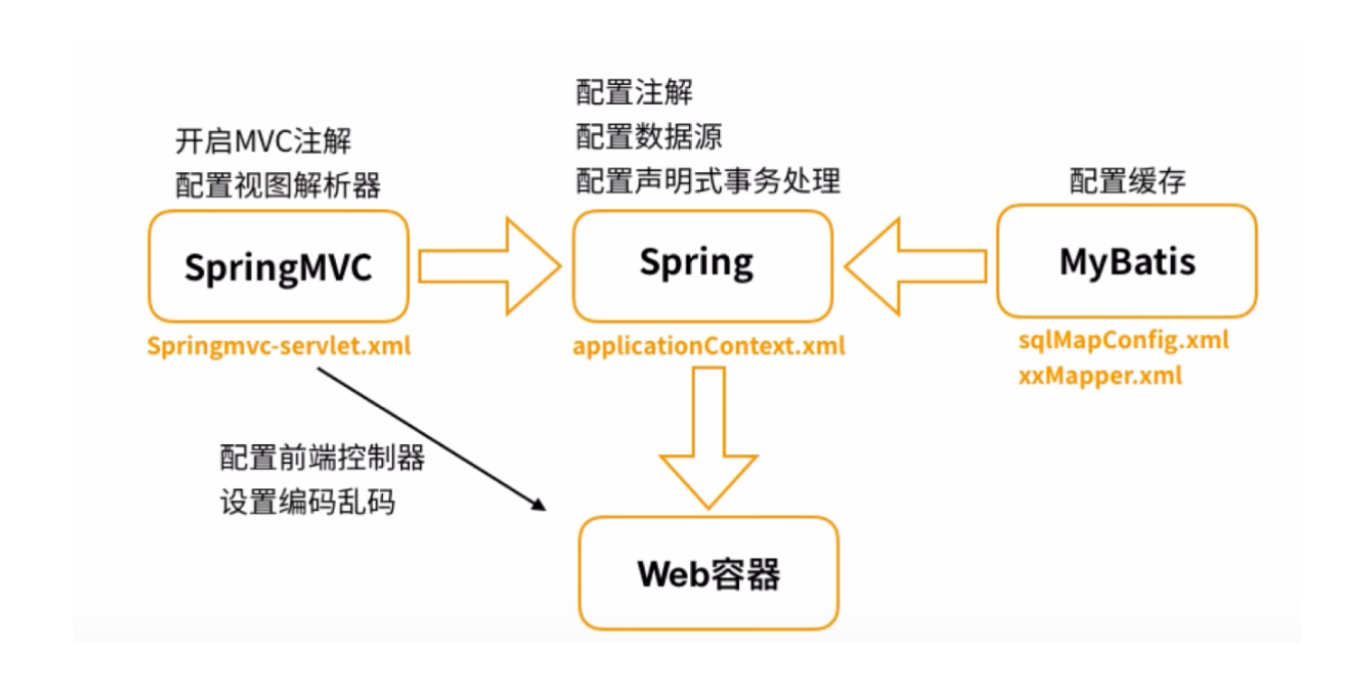
2.0:spring boot - all in one
- 整合了所有Spring的框架功能
- 提供了简单的配置及注解的接入方式
- 提供all in one的服务
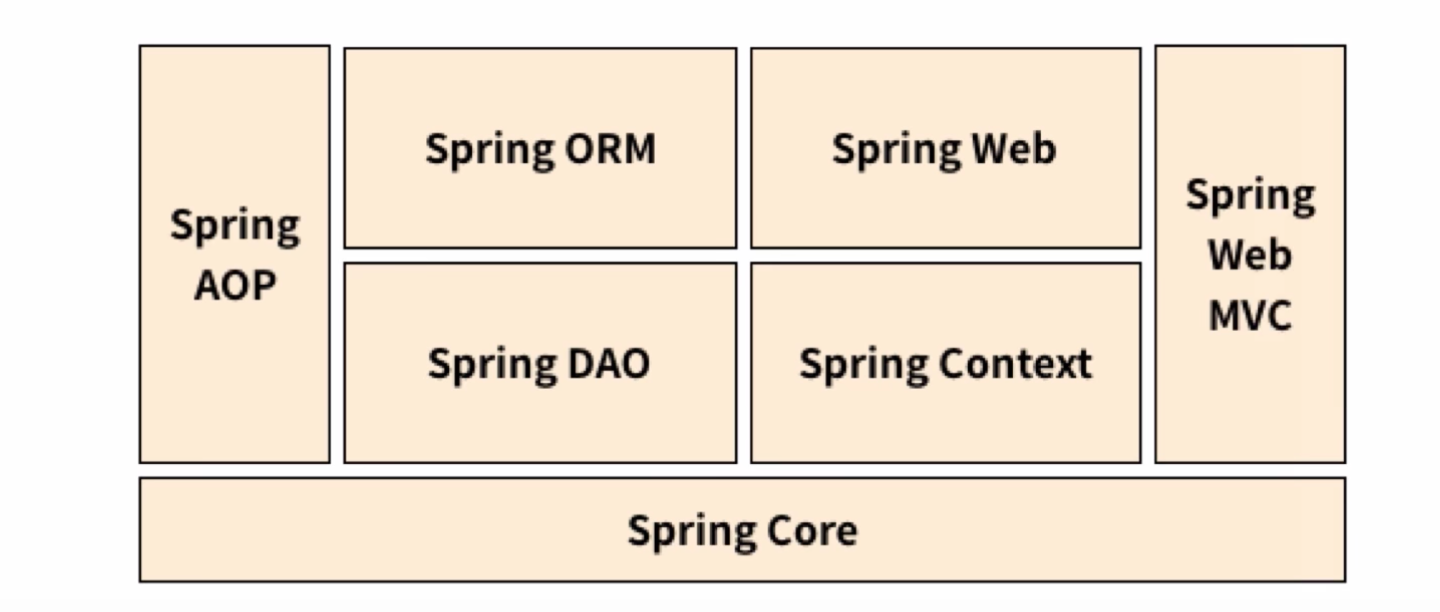
spring boot存在如下的问题:
- 解决了单一应用内的软件分层,却没有解决整体应用的分层
- 单一应用性能瓶颈,无法支撑亿级流量
- 团队协作问题
3.0:分布式分层

下面以亿级流量平台分层架构为例介绍分布式分层
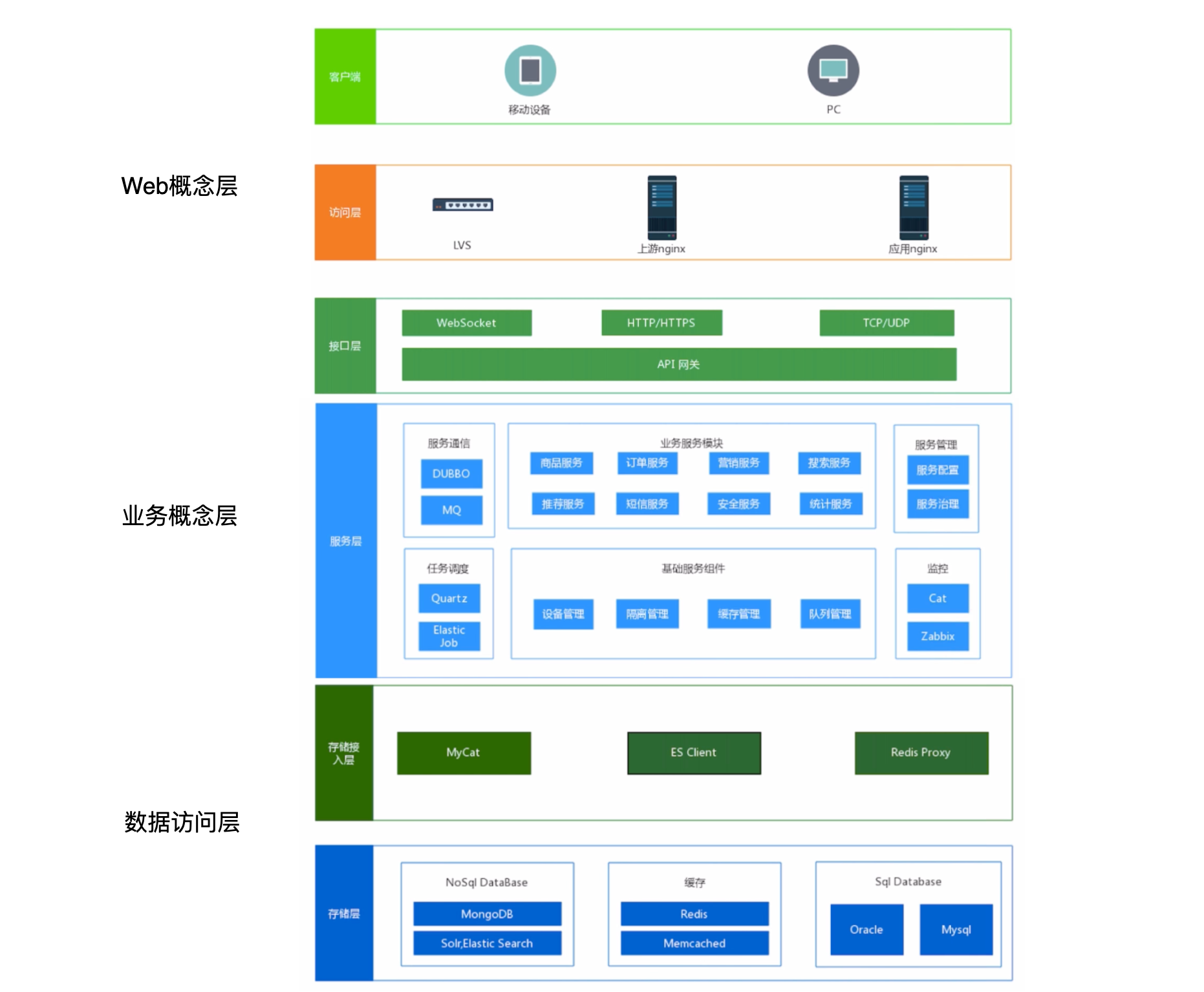
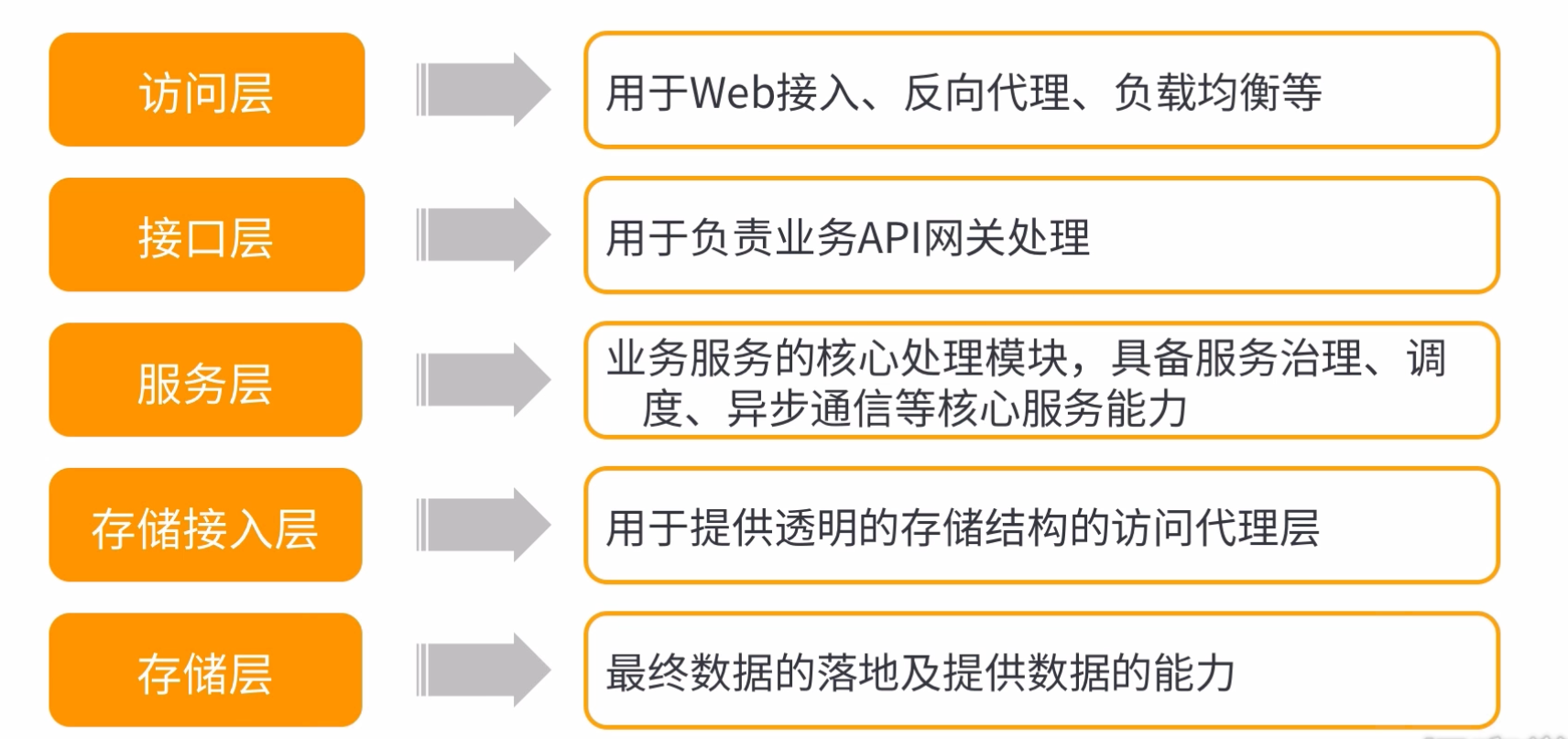
二:访问层架构设计
1:LVS接入系统
1.1:什么是LVS
linux virtual server
LVS集群采用IP 负载均衡技术和基于内容请求分发技术,将请求均衡地转移到不同的服务器上执行,且调度器自动屏蔽掉服务器的故障,从而将一组服务器构成一个高性能的、高可用的虚拟服务器,整个服务器集群的结构对客户是透明的,而且无需修改客户端和服务器端的程序。
LVS是在IP层进行的负载均衡,相对于在应用层,效率大大的提高了,因此LVS进行负载均衡非常的快
1.2:LVS三种模式
LVS/NAT
LVS就像一个公司的总机接线员
所有外部电话(请求)都先打到他这里,他转接给内部分机(RS)。分机员工说完话(响应)后,不能直接打给外部客户,必须把话告诉接线员,由接线员再转述给客户。
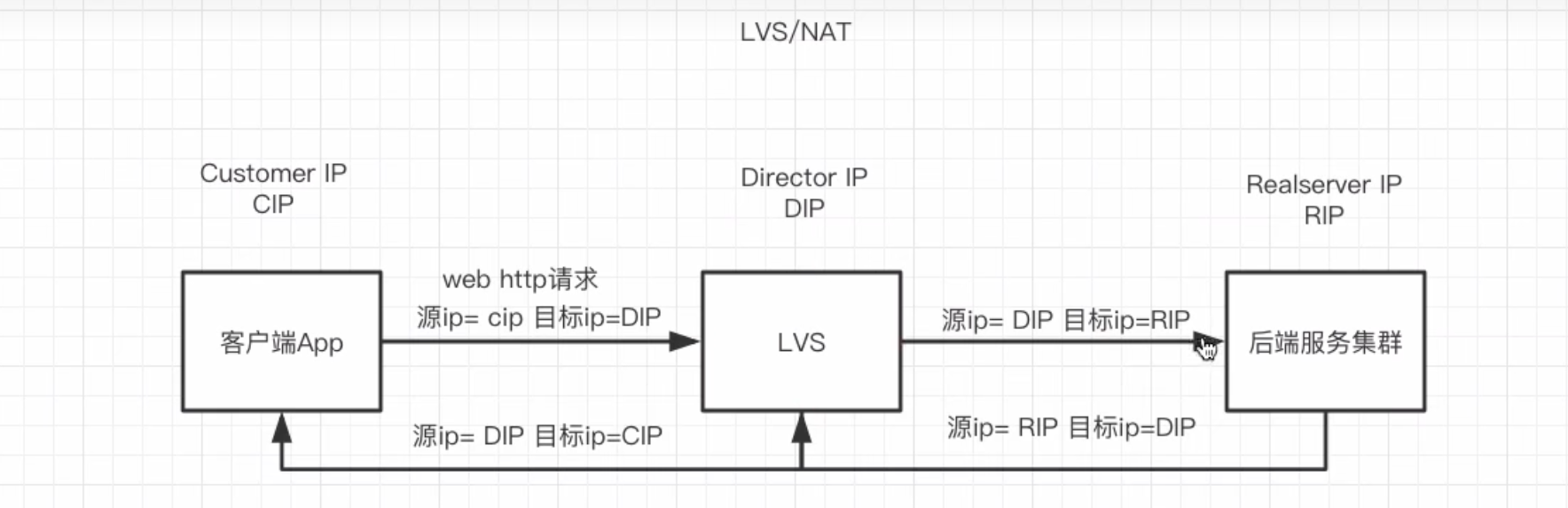
🚀 优点如下
- 配置简单,是早期最常用的模式。
- 真实服务器(RS)可以使用任何操作系统,只需设置网关为LVS的DIP(内网IP)即可。
🚀 缺点如下
- 性能瓶颈:LVS需要同时处理入站和出站的流量,所有响应数据都要经过LVS服务器。当请求量很大时,LVS Director容易成为瓶颈。(LVS还有处理响应)
- 网络要求:Real Server必须和LVS在同一个物理网络(局域网)内。
LVS/DR
LVS像一个公司的前台接待。
客户(请求)来找某位专家(RS),前台查看了预约列表后,告诉客户:“王工在303办公室,你直接去找他吧。” 然后客户自己去找王工,王工解答完问题后(响应),直接自己回复客户,不再需要经过前台。
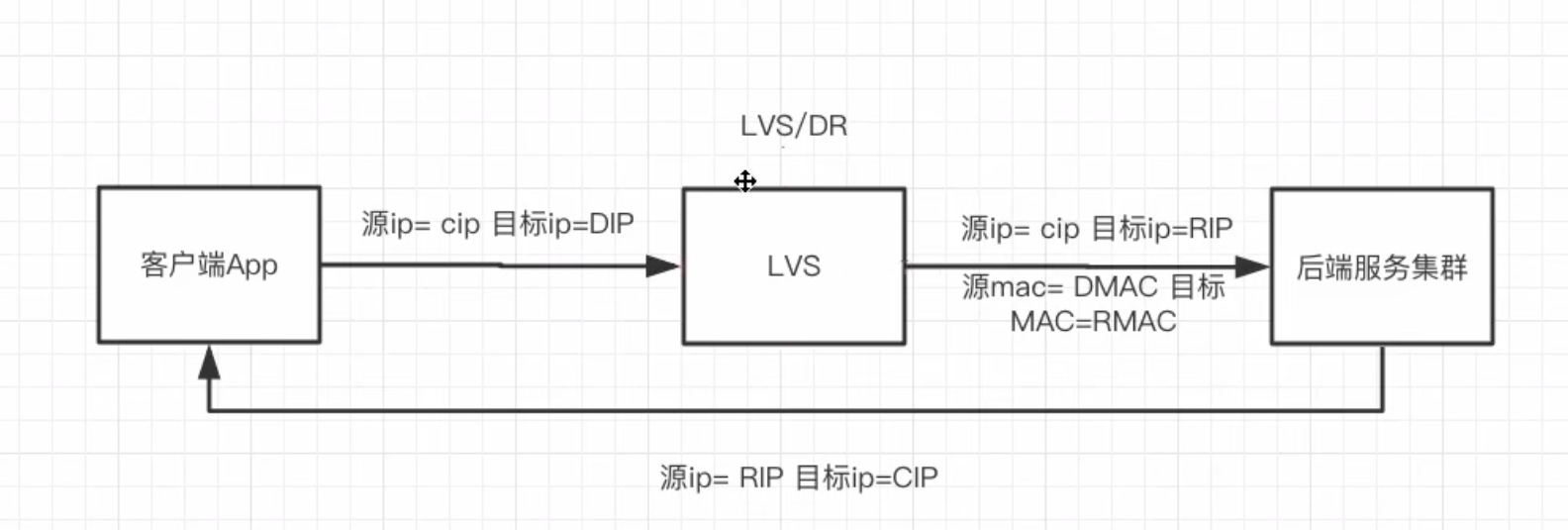
🚀 优点如下
- 高性能:由于响应数据包不经过LVS,而是由RS直接返回给客户端,LVS只处理入站请求,因此吞吐量极高,性能最好,是生产环境中最常用的模式。
🚀 缺点如下
- 配置稍复杂:需要在所有RS上配置ARP抑制(防止它们宣告自己拥有VIP,导致IP冲突),并设置lo接口的VIP。
- 网络要求高:LVS和所有RS必须在同一个物理网络(二层可达),不能有路由器分隔。
LVS/TUN
这就像快递中转。
客户把包裹(请求)寄到LVS的总仓库(VIP)。LVS仓库把原始包裹重新打包进一个大箱子(IP隧道封装),箱子上写着RS分仓库的地址,然后寄出去。RS分仓库收到后,拆开大箱子,取出里面的原始包裹进行处理,处理完后直接用自己的快递渠道给客户寄回响应包裹。
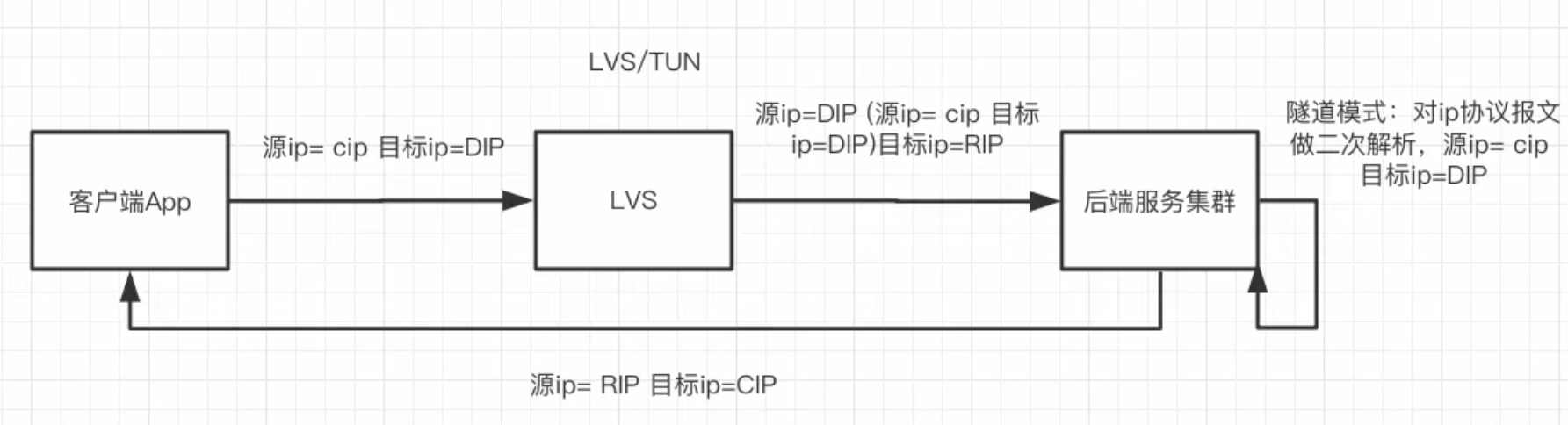
🚀 优点如下:
- 跨网络:LVS和RS可以分布在不同的网络、不同的地域,只要它们之间IP可达(通常是通过Internet)。这解决了DR模式必须在同一局域网的局限性。
- 性能也很高,响应数据不经过LVS。
🚀 缺点如下:
- 配置最复杂:需要所有RS支持IP隧道协议(如IP)。
- 额外开销:数据包的封装和解封装需要消耗一定的CPU资源
| 特性 | NAT 模式 | DR 模式 (推荐) | TUN 模式 |
|---|---|---|---|
| 性能 | 较低(有瓶颈) | 极高 | 高 |
| 配置复杂度 | 简单 | 中等 | 复杂 |
| Real Server要求 | 任意系统,网关指向DIP | 需配置ARP抑制和VIP | 需支持IP隧道协议 |
| 网络要求 | LVS和RS在同一局域网 | LVS和RS必须在同一局域网 | 可跨机房、跨地域 |
| 典型应用场景 | 小型内部系统 | 大型网站、高流量Web服务 | CDN、大型分布式系统 |
1.3:LVS接入系统架构
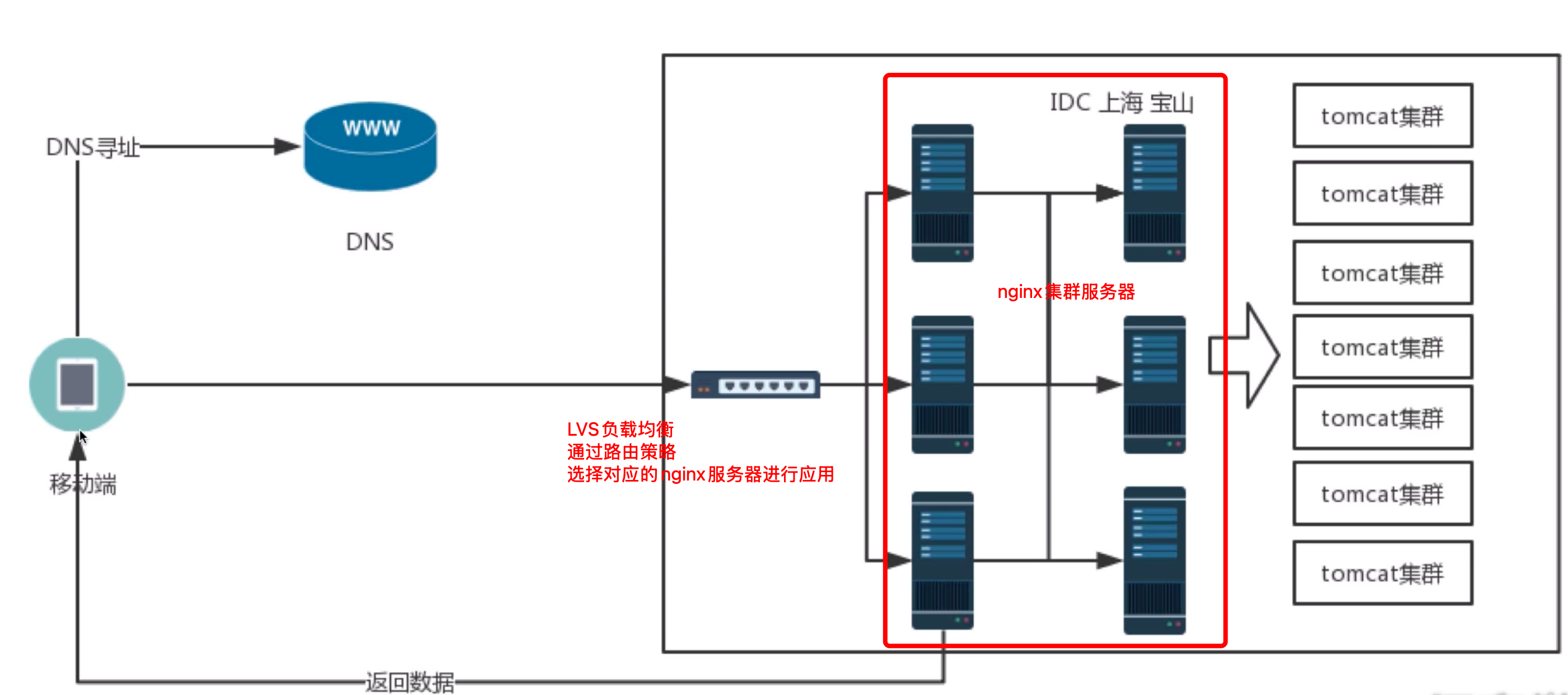
1.4:LVS调度策略
- 无脑轮询,带权重的无脑轮询
- 最少链接,带权重的最少链接
- IP_Hash, IP_HASH_GROUP
1.5:LVS的优势
- IP 层的负载均衡协议,无应用层回调消耗
- 通过 LVS-DR 或 LVS/TUN模型的特性使得请求返回不过LVS
- 自动故障转移,心跳检测
- 配合主从 KeepAlive 加VIP 实现自身高可用
2:nginx的原理和应用
2.1:nginx分类和作用
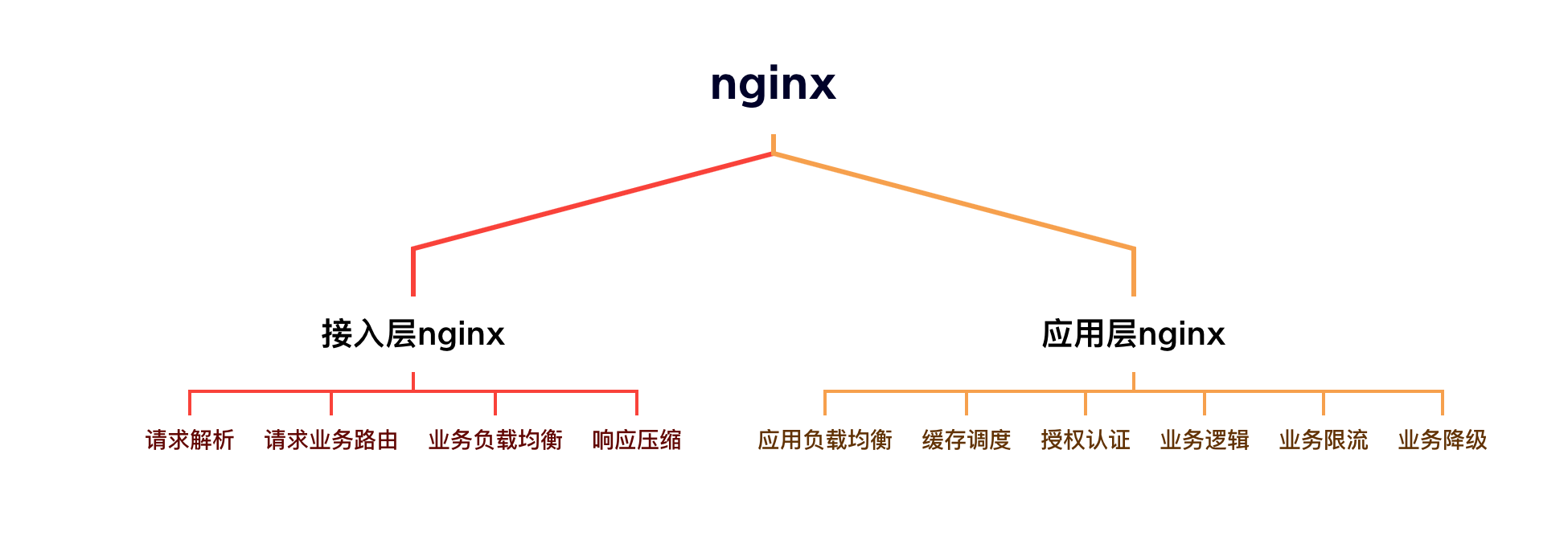
2.2:nginx为啥性能高
- master-worker进程模型
- 流式处理请求workflow
- 有主子请求协程机制
- nginx lua
2.3:nginx原理
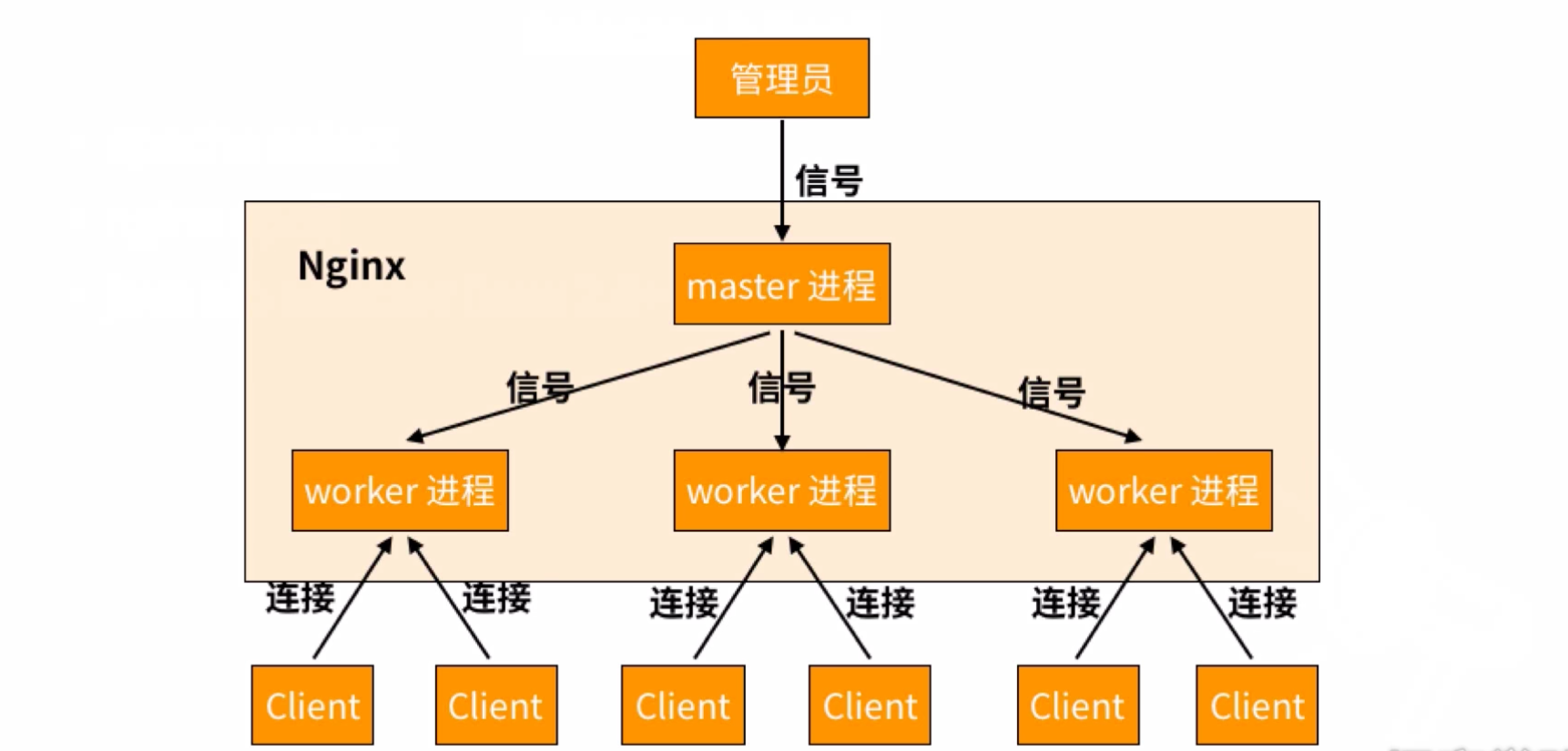
nginx通过epoll模型完成高性能IO,对于epoll模型,可以看我的这个文章
2.4:进程模型
master进程fork出越多的子进程作为worker,当前的nginx能够接受的并发程度就越高
客户端client是向worker进程进行连接的,连接到那个完全是抢占式的,此后就是worker进程和客户端进行通信
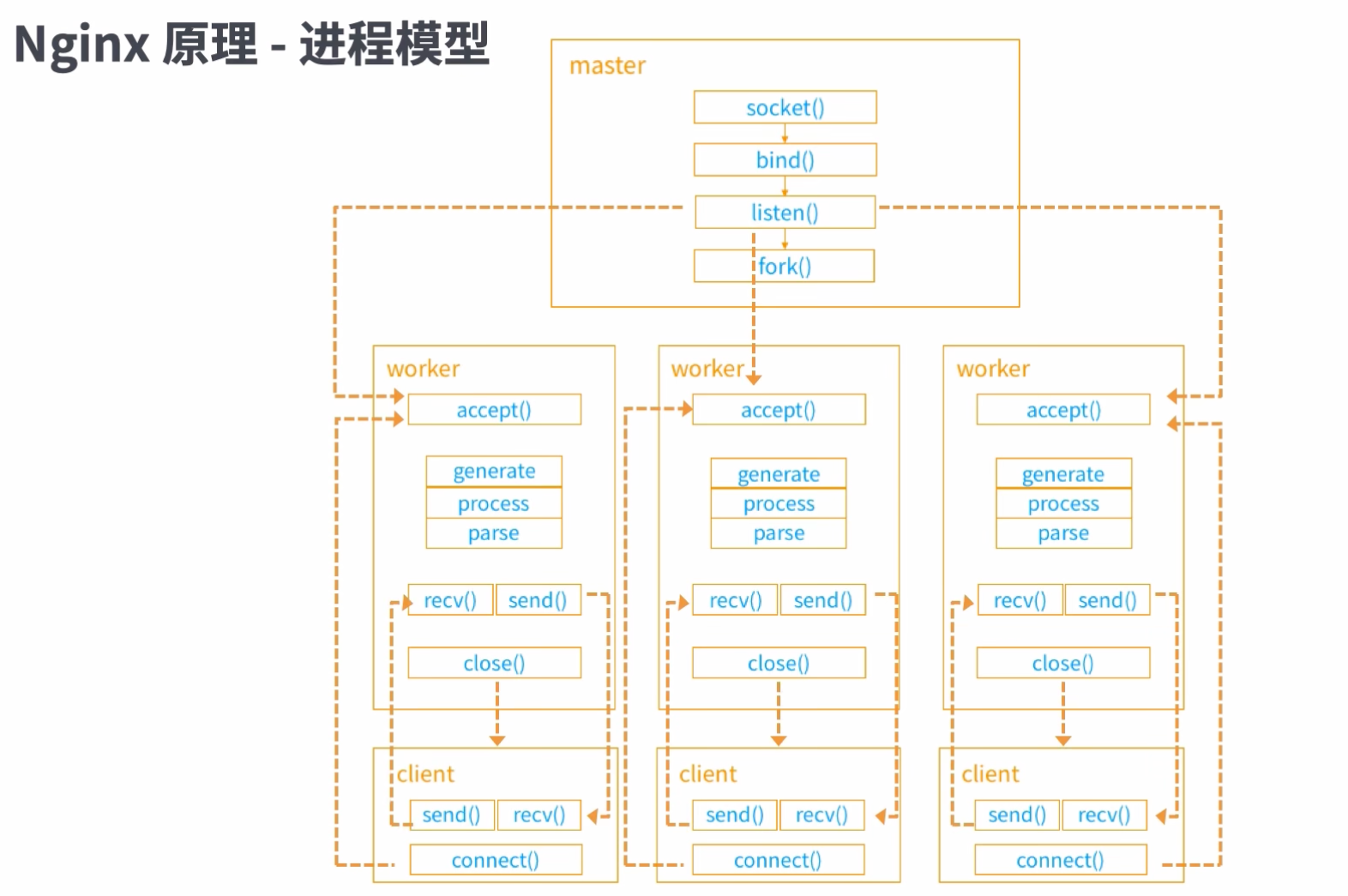
boss 进程epoll 注册,由 work 进程池竞争 accept mutex 用来获得连接的accept 权限及后续的 recv,send 操作权限,本质在处理上仍然是等待阻塞式的效率。
因此 work 进程内的 workflow 不能有阻塞式的操作,解决方式是通过协程去处理。

2.5:动静分离和反向代理
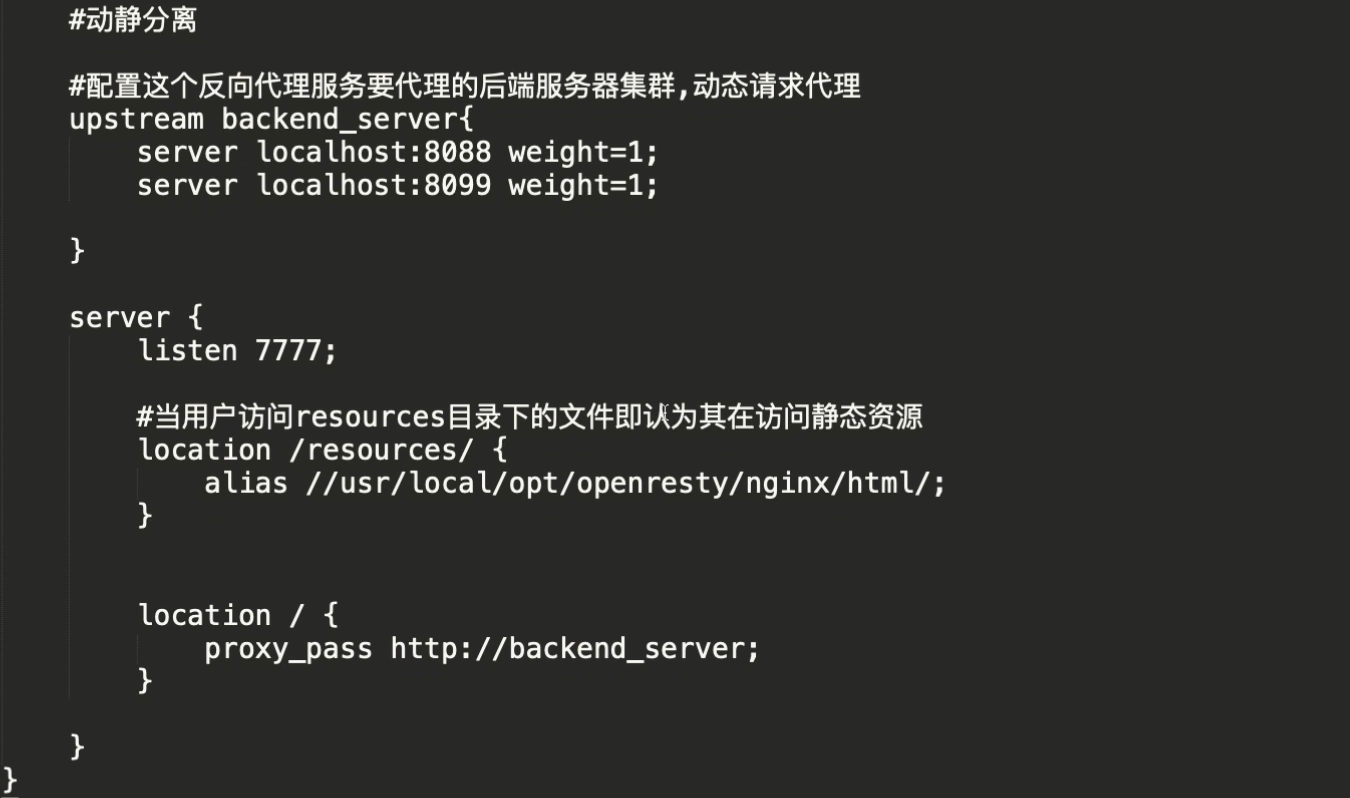
🎉 nginx的常规操作可以看我的这个文章
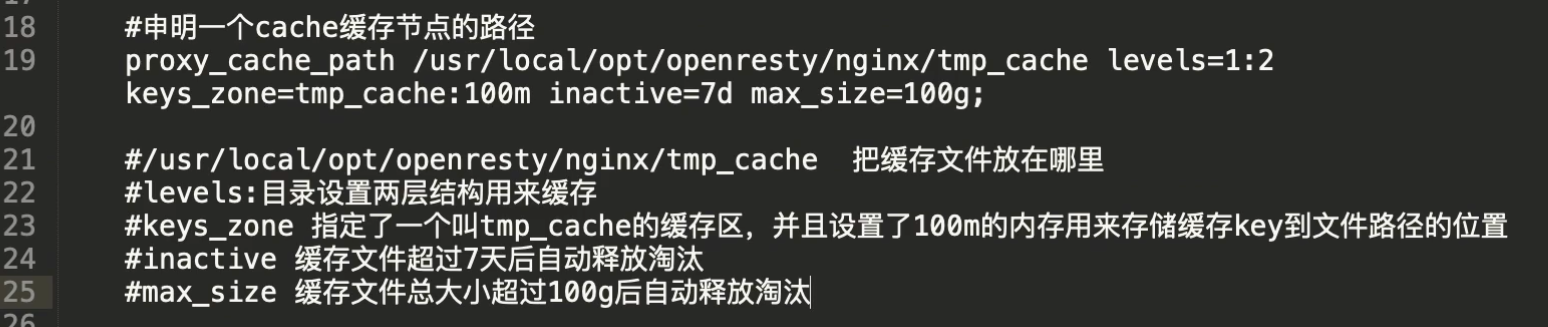
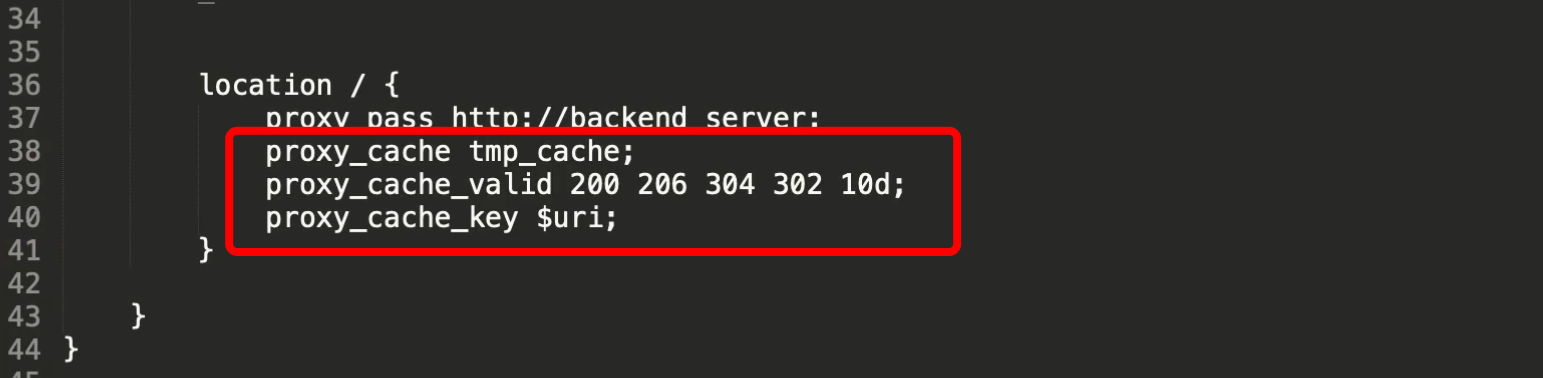
2.6:缓存设置
三:接口层架构设计(API网关)
3.1:会话管理
会话管理:由于http请求的无状态性,因此引入了session会话管理机制,标识BS端之间会话状态
分布式会话管理:区别于传统的依赖web server session的会话管理状态,需要引入集中的会话存储容器,用于鉴别分布式状态下的BS端之间的会话标识
基于server端的session管理方式
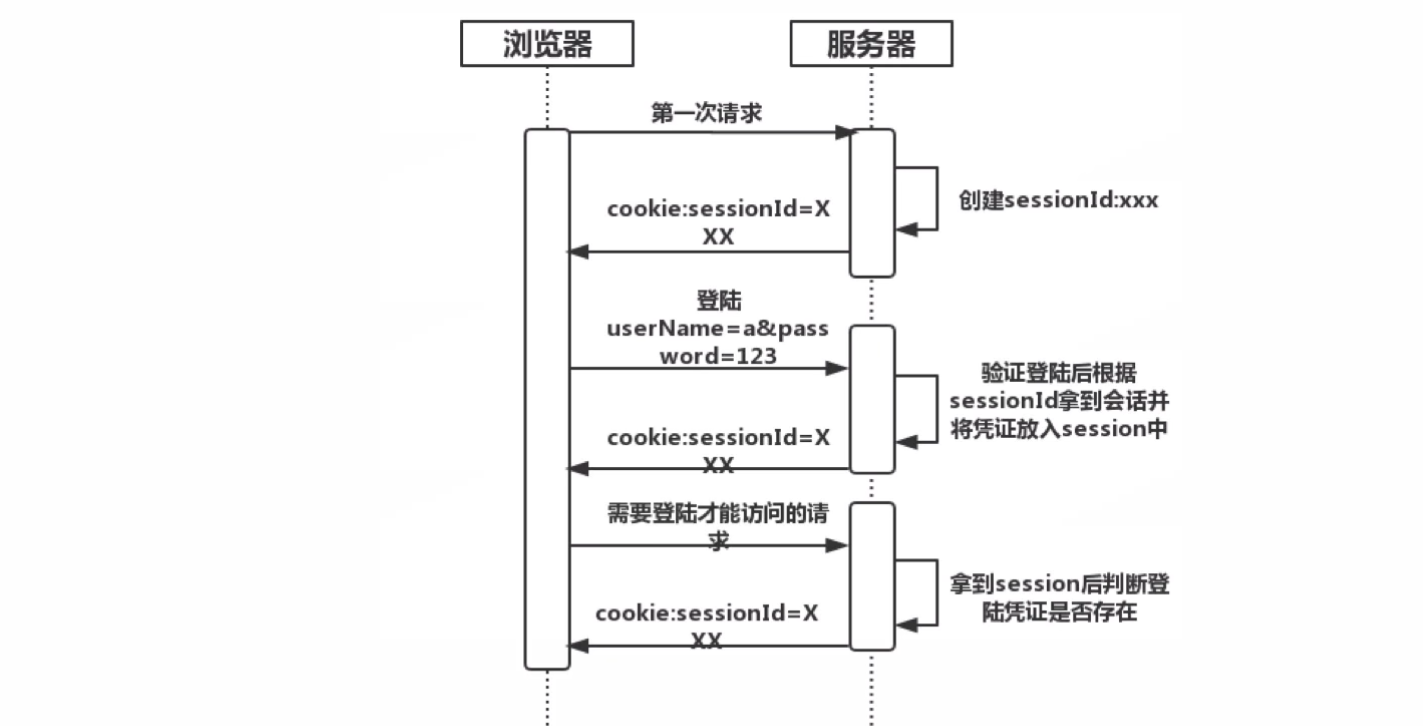
- 依赖webserver的session容器
- cookie跨域访问问题处理复杂
- 浏览器禁用cookie问题
基于cookie的管理方式
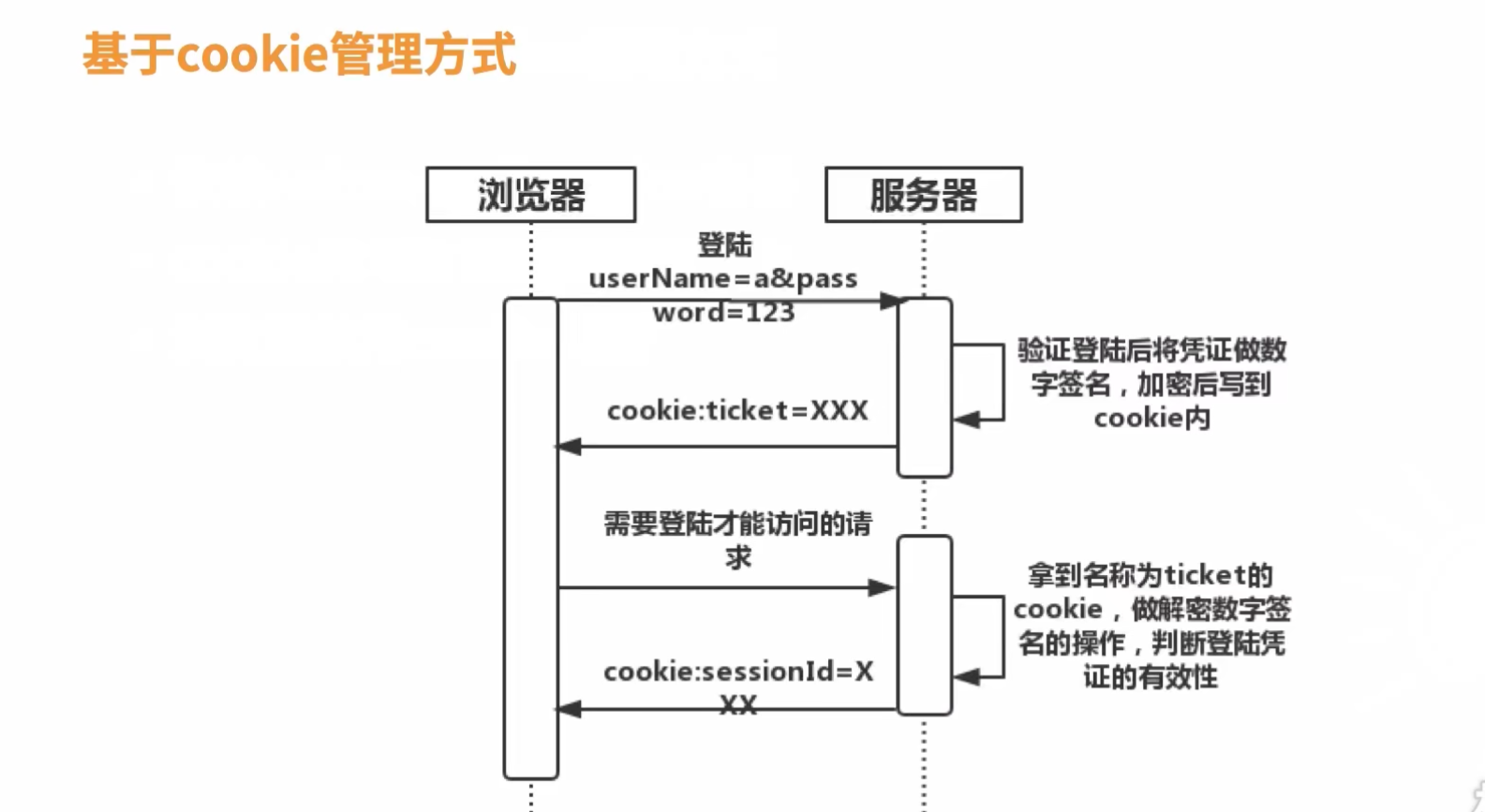
- cookie跨域访问问题处理复杂
- 浏览器禁用cookie问题
基于token的管理方式
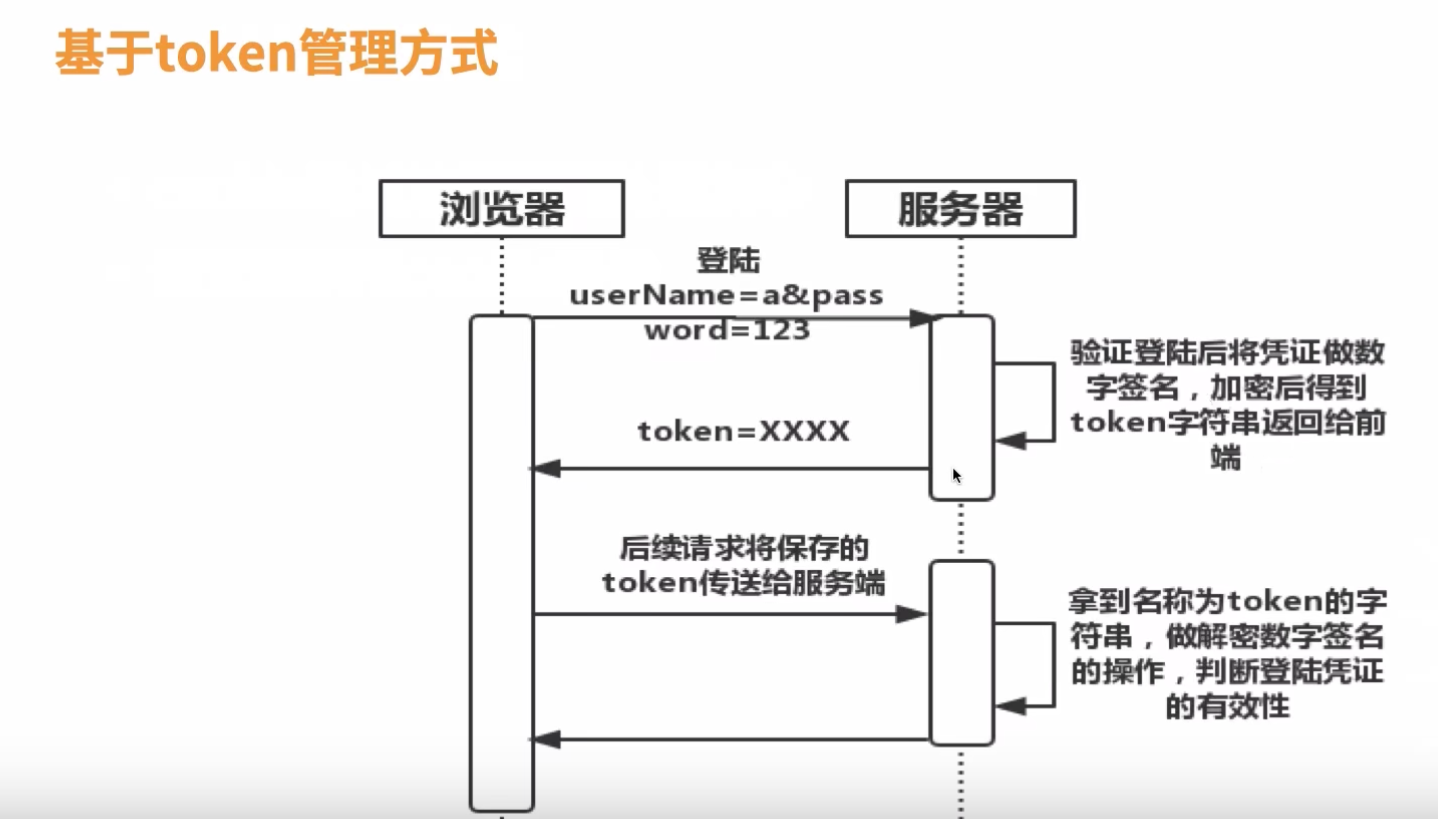
- 有效存储token,保证每次调用都能拿到token
- 需要应用代码处理将token加到header或接口传参内
- 不依赖浏览器cookie禁用问题,移动native应用hybrid开发方式支持好
安全问题
- cookie并非安全,被劫持概率高,XSS,csrf安全攻击等
- token凭证被劫持,伪造请求
- Https请求防泄漏
- 风控主动失效及过期机制
分布式会话管理
- 集中式的会话管理,凭证放到Redis,MemCache,数据库等
- 重写session处理方式
3.2:接入层控制
控制什么
通过 API 网关接入层控制程序入口处需要实现的逻辑,包括身份验证,流量控制,路由服务,记录调试或统计信息等
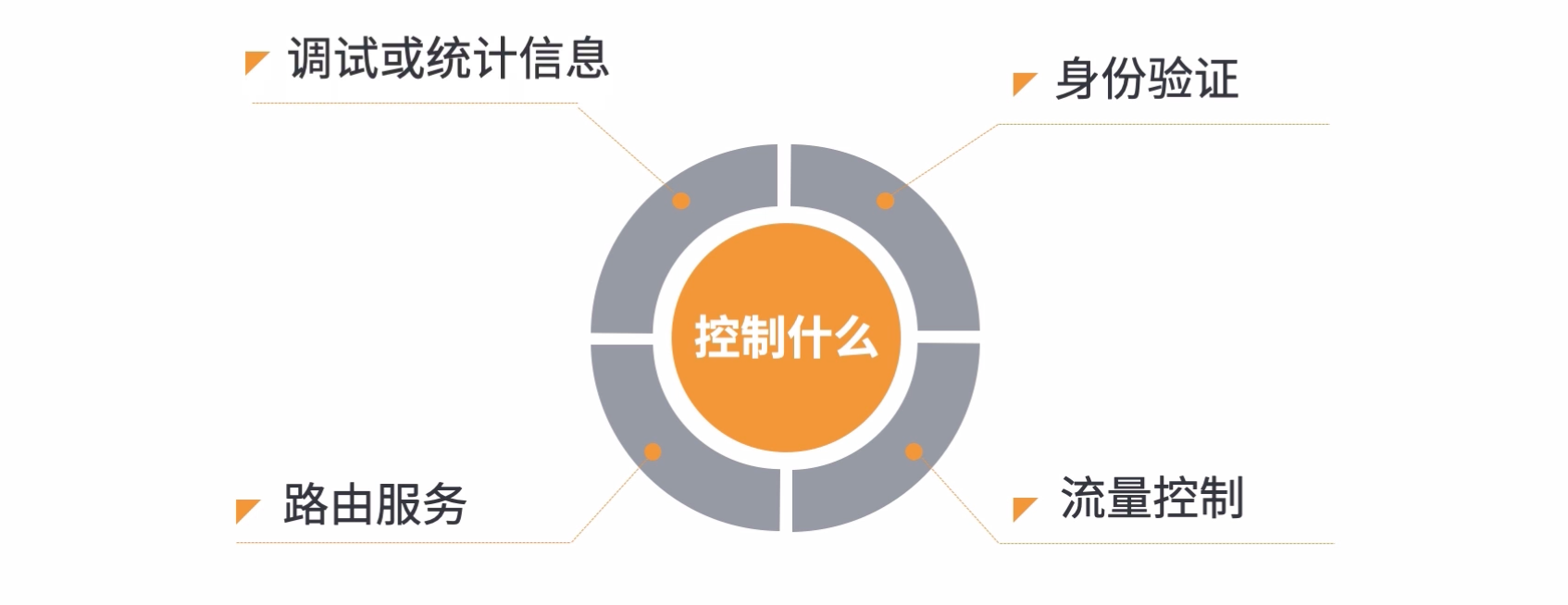
- 身份验证
- 通过会话管理获取登陆用户凭证
- 通过用户凭证获取到用户身份信息
- 验证对应URL是否可被对应身份的用户访问
- 流量控制
- 对应URL的流量是否可以承载,若不能,限流
- 对应服务分级的流量是否可以承载,若不能,限流
- 对应整个系统的总流量是否可以承载,若不能,限流
- 路由服务
- 根据对应url的规则寻找到响应服务
- 判定服务状态,做服务路由调用
- 调试或者统计信息
- 切面打印日志调试信息
- 切面打印cat监控
实现原理
使用不同接入层框架的通用 “Filter”功能实现
// servlet filter
public void doFilter(ServletRequest request, Servlet response, FilterChain chain) {System.out.println("我是filterDemo1, 客户端向servlet发送的请求被我拦截了");chain.doFilter(request, response);System.out.println("我是filterDemo1, servlet向客户端发送的响应被我拦截了");
}// spring MVC HandlerInterceptor
public boolean preHandler(HttpServeltReqest request, HttpServletResponse response, Object handler) throws Exception {// 添加你的前置处理的逻辑return true;
}
public void postHandler(HttpServletReqest request, HttpServletResponse response, Object handler, ModelAndView) throws Exception {// 添加你的后置处理的逻辑
}// zull filter
public void doFilter(ServletRequest request, ServletResponse response, FilterChain, filterChain) {try {init(request, response);try {preRouting(); } catch(ZuulException e) {error(e);postRouting();return ;}filterChain.doFilter(request, response); // 传给下游try {routing();} catch(ZuulException e) {error(e);postRouting();return ;}try {postRouting();} catch(ZuulException e) {error(e);return ;}} finally {...}
}
3.3:服务调用及其聚合
API网关通过了接入层控制并路由后进入核心的服务调用环节,通过对后端服务的调用并聚合服务输出的数据后返回访问层。
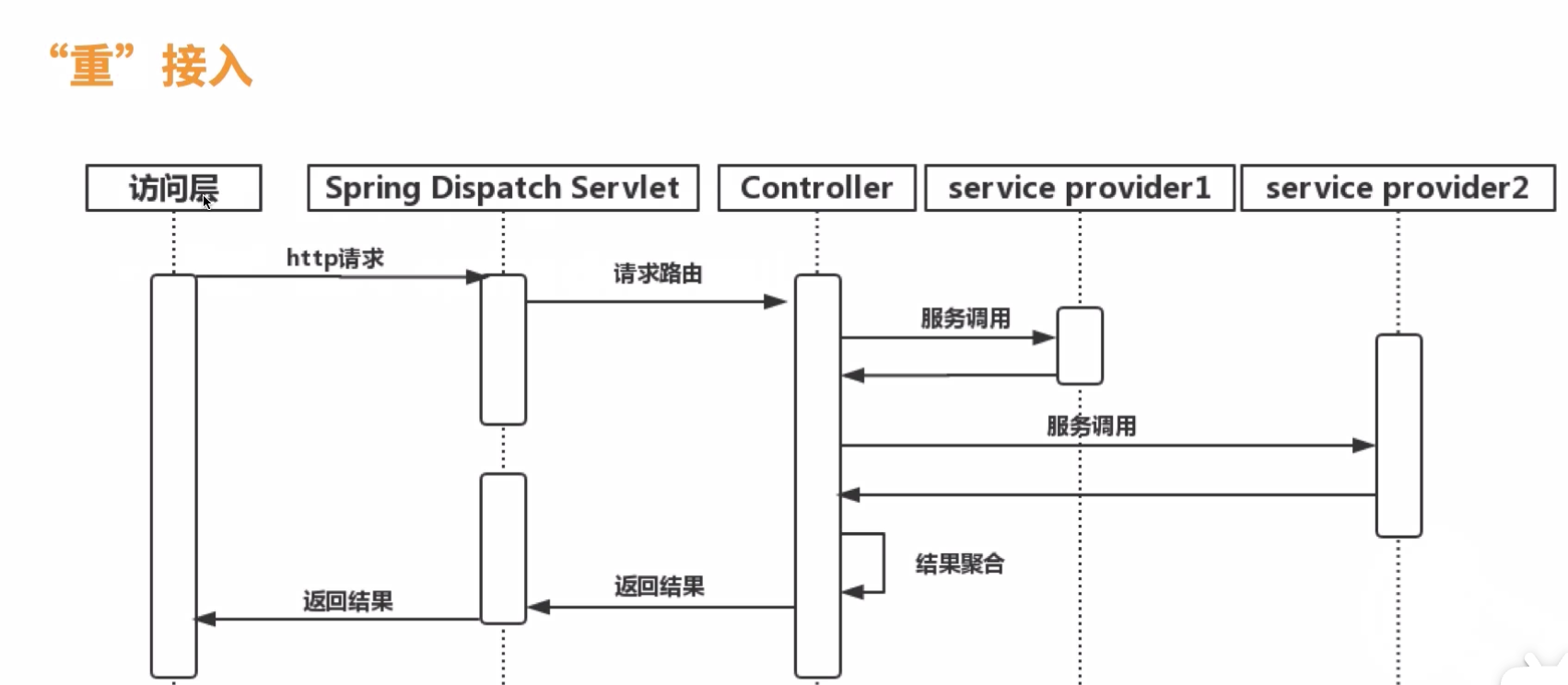
优点:可以灵活的在web层处理业务逻辑,聚合服务
缺点:服务单一性不够,且过度的web层业务聚合能力会导致服务不便于管理
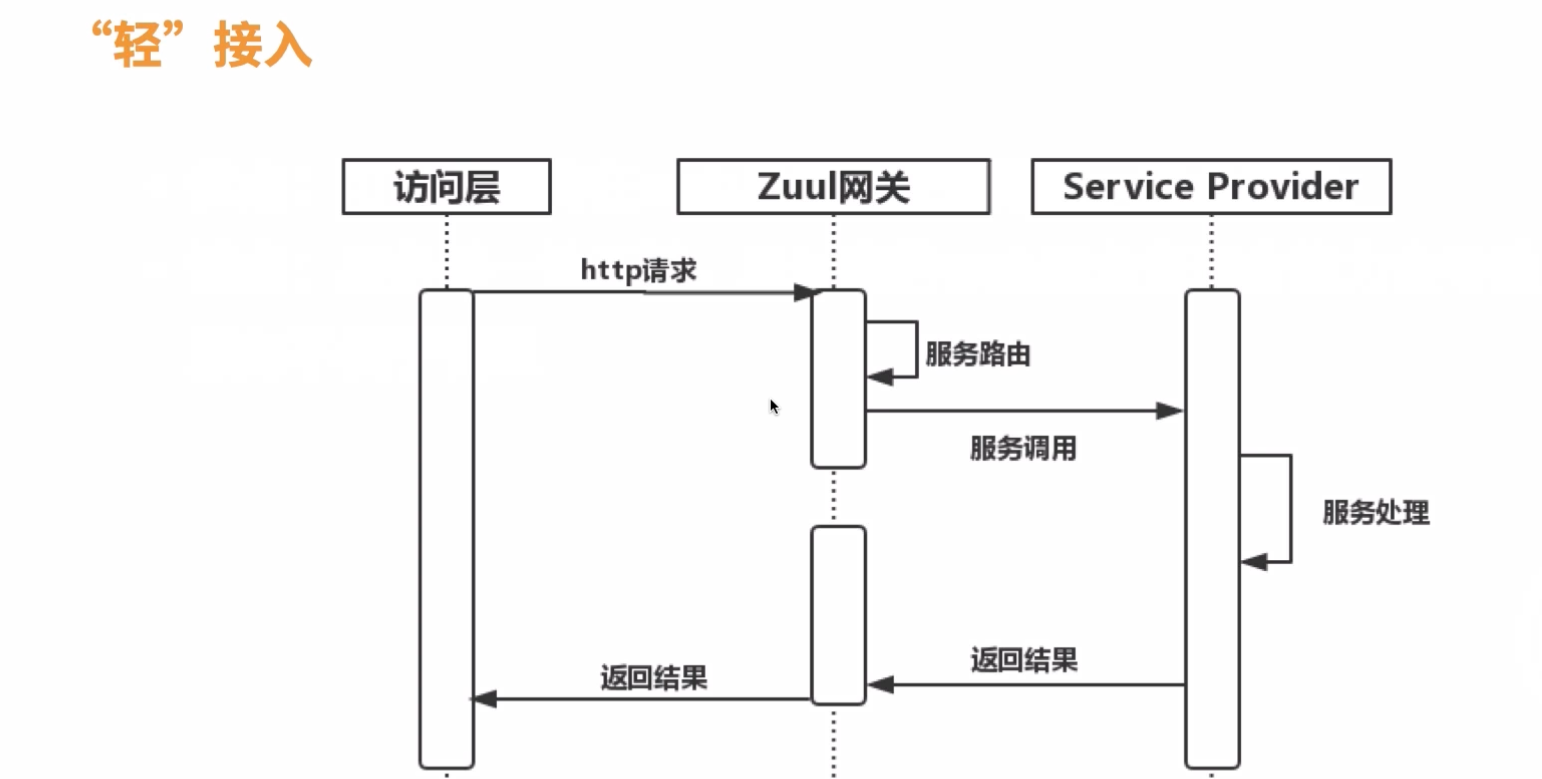
优点:服务单一,可提供配置化接入
缺点:聚合服务处理不够灵活,需要由service provider提供聚合服务能力
四:核心服务层架构设计
1:微服务
传统服务的缺点:
- 所有的服务都耦合在一起
- 隔离性弱,互相影响
- 部署臃肿
- 开发维护困难

微服务是指开发一个单个小型的但有业务功能的服务,每个服务都有自己的处理和轻量通讯机制,可以部署在单个或多个服务器上。
微服务的优点:
- 服务高内聚且低耦合
- 隔离性强,不会互相影响
- 单独部署
- 独立开发
微服务要解决的问题
- 服务治理(服务调用通信,健康管理,限流熔断等)
- 数据一致性。
- 调用性能
- 研发流程,调试,部署
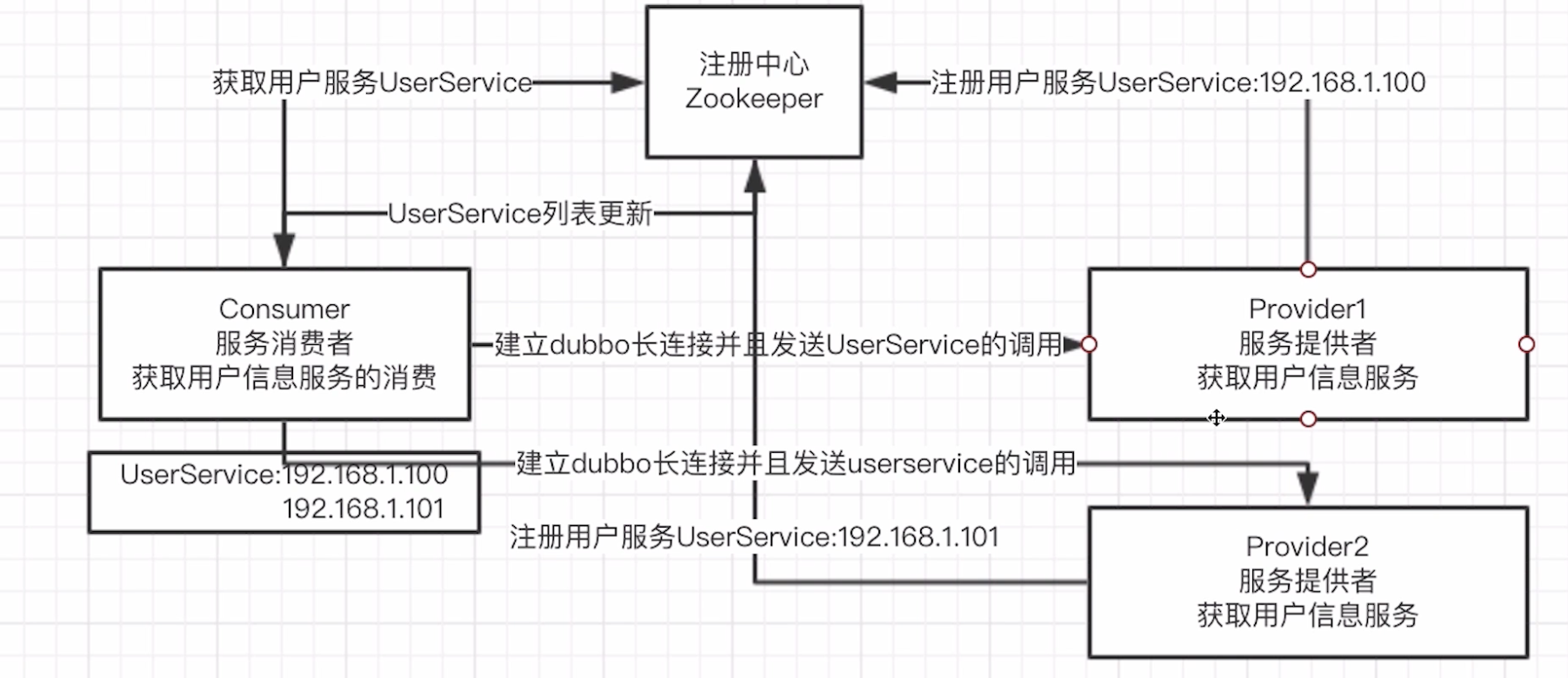
2:组件通信-dubbo
可以看我的dubbo快速入门
2.1:什么是dubbo
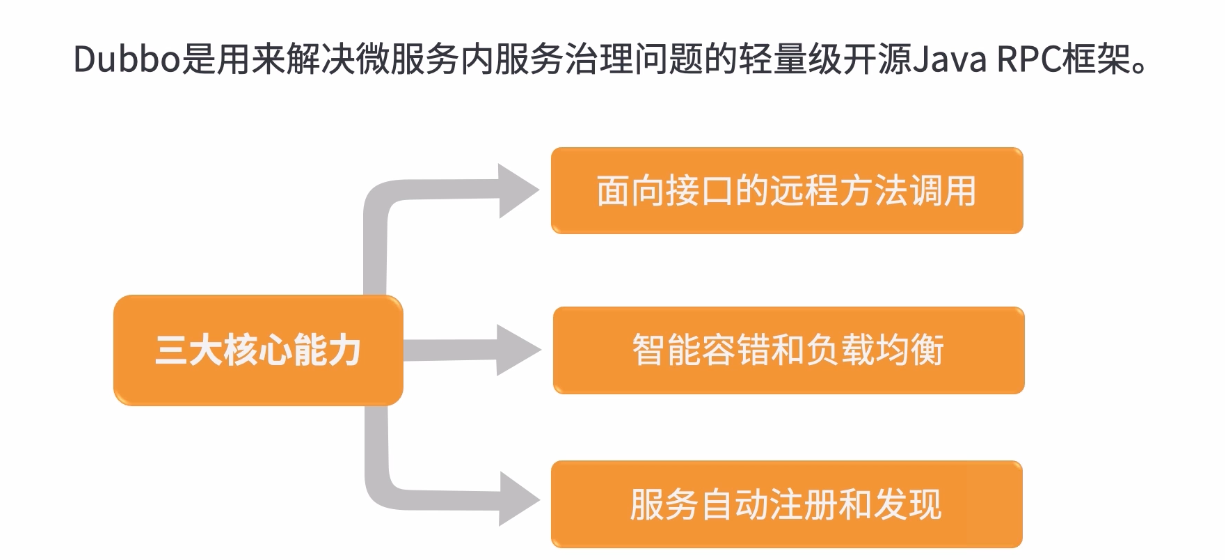
- 服务提供者注册服务;服务消费者获取服务,并通过负载均衡策略选择服务提供者
- 动态增减服务提供者和服务消费者(健康检查和心跳机制)
- 服务监控;服务限流;服务降级;高容错
- 定制化开发
2.2:dubbo调用原理
3:组件通信-MQ
3.1:同步通信和异步通信

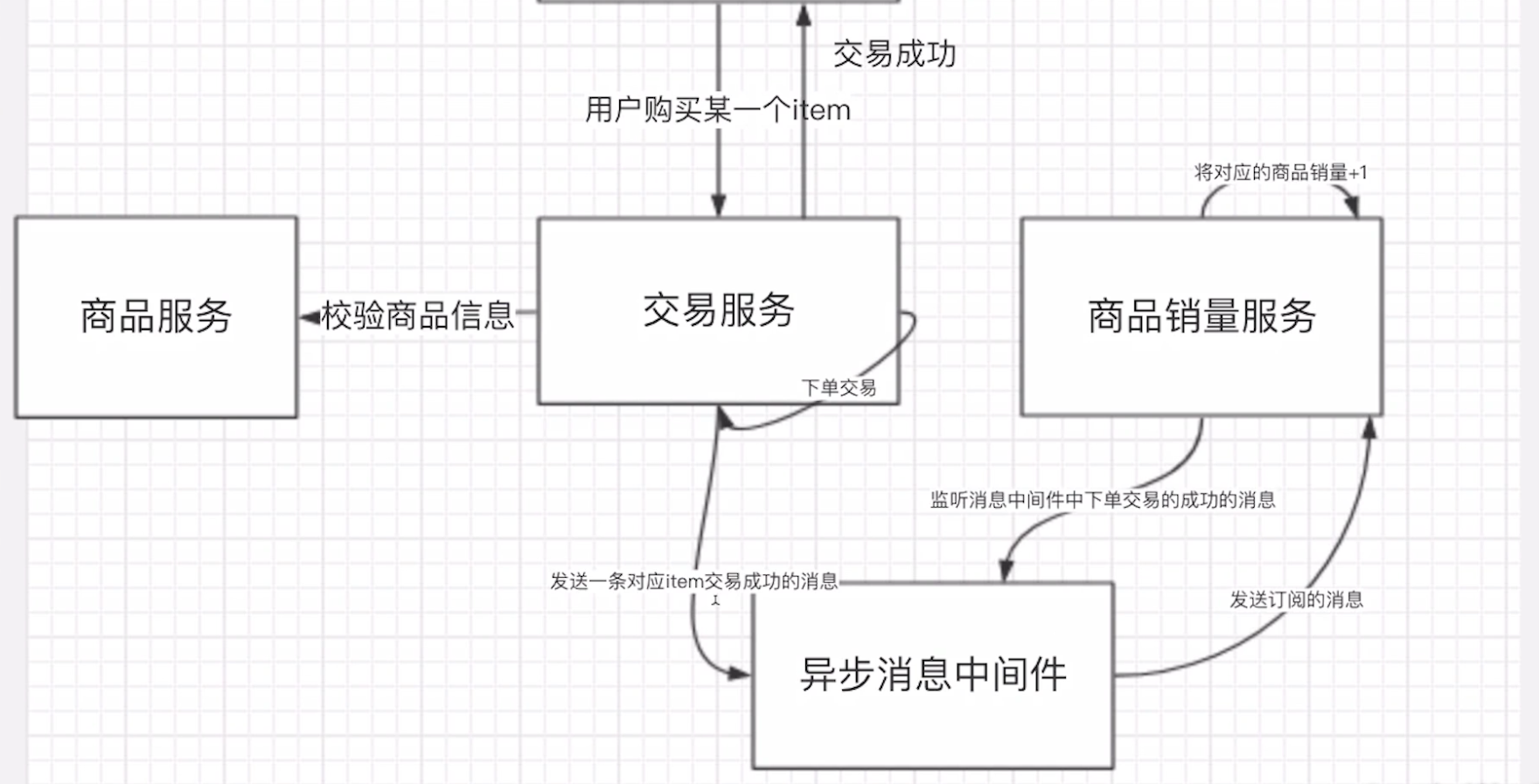
3.2:异步化的好处
不会阻塞原来的业务
服务调用之间解偶,无需互相关注感知
3.3:消息服务分类
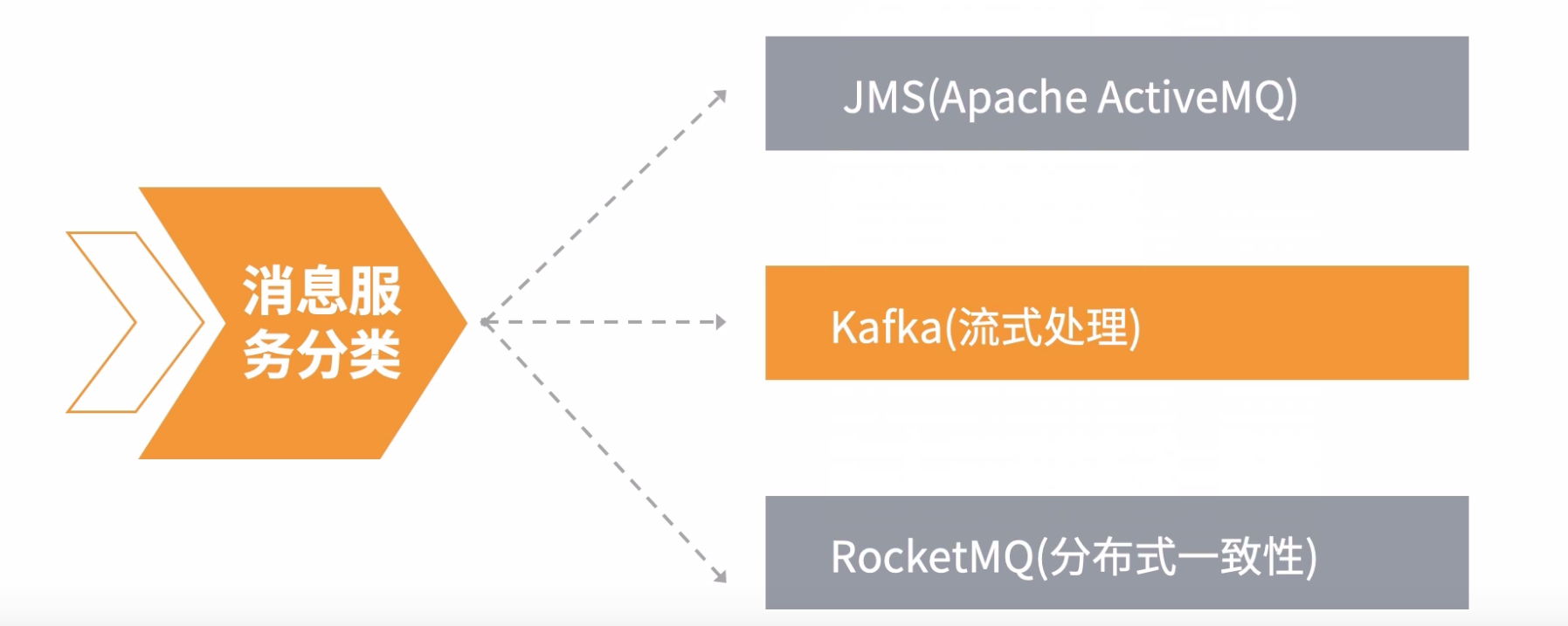
Apache ActiveMQ
在Kakfa, rocketMQ和rabbitMQ没有盛行之前,都是JMS占据异步通信的大哥地位,因为它完美的支持了异步通信相关协议
-
点对点:发送者,接收者,一对一发送,每个消息都被发送到一个特定的队列,接收者从队列中获取消息。队列保留着消息,直到他们被消费或超时。
-
发布订阅:客户端将消息发送到主题,消息队列存放主题,订阅者消费主题消息。
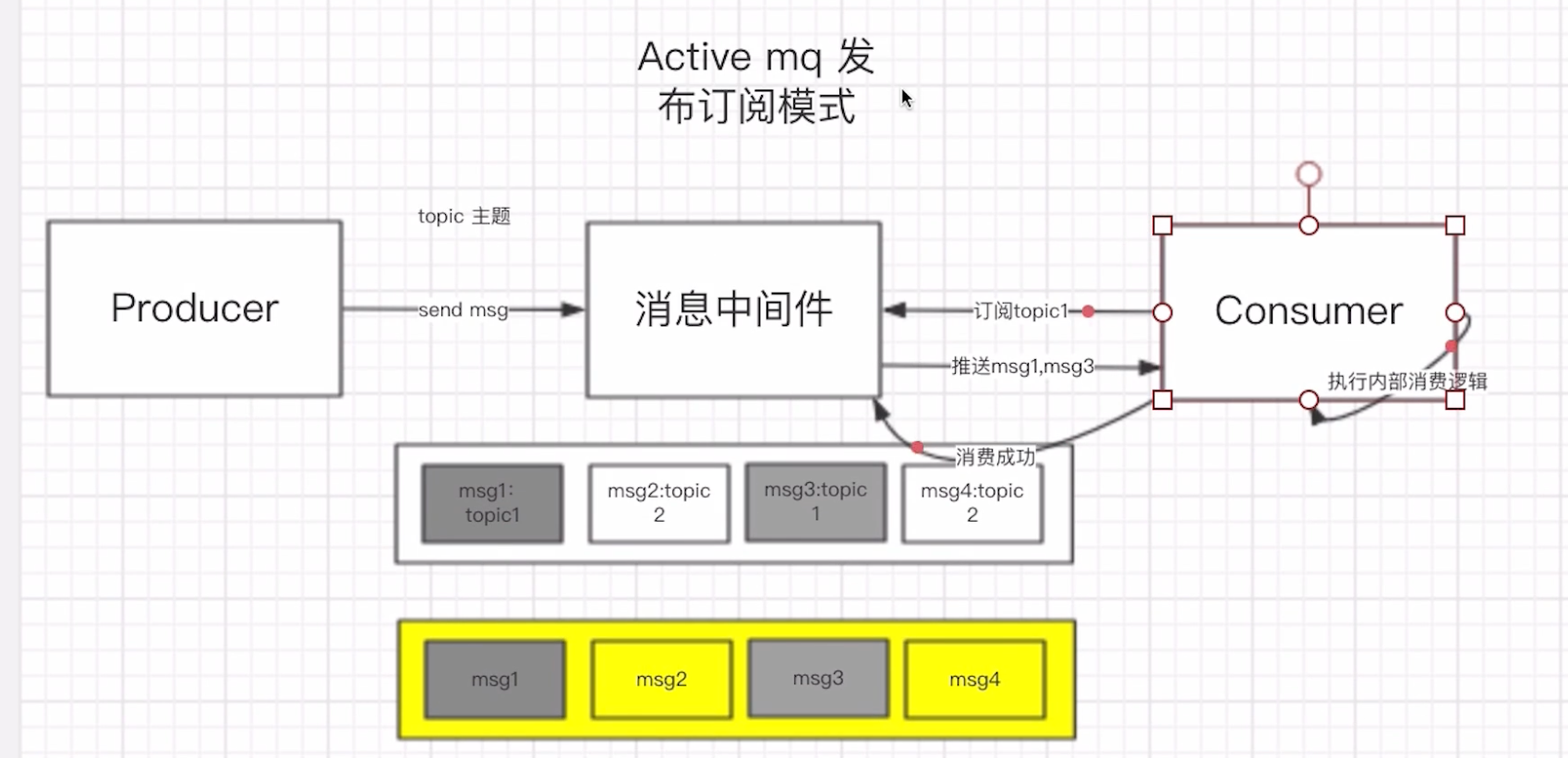
kafka
-
默认也支持点对点,但是并不常用,常见的还是发布订阅模式
-
发布订阅:客户端将消息发送到主题,消息队列存放主题,订阅者消费主题消息
-
消息持久化到队尾(queue本质是文件系统,写入消息只是单纯的写入文件末尾)
-
消费通过客户端指针(offset指针,记录了消费者当前消费到那个位置了, 消费者通过pull拉取模式从offset指针拉取指定数量的消息进行消费)
-
吞吐量高
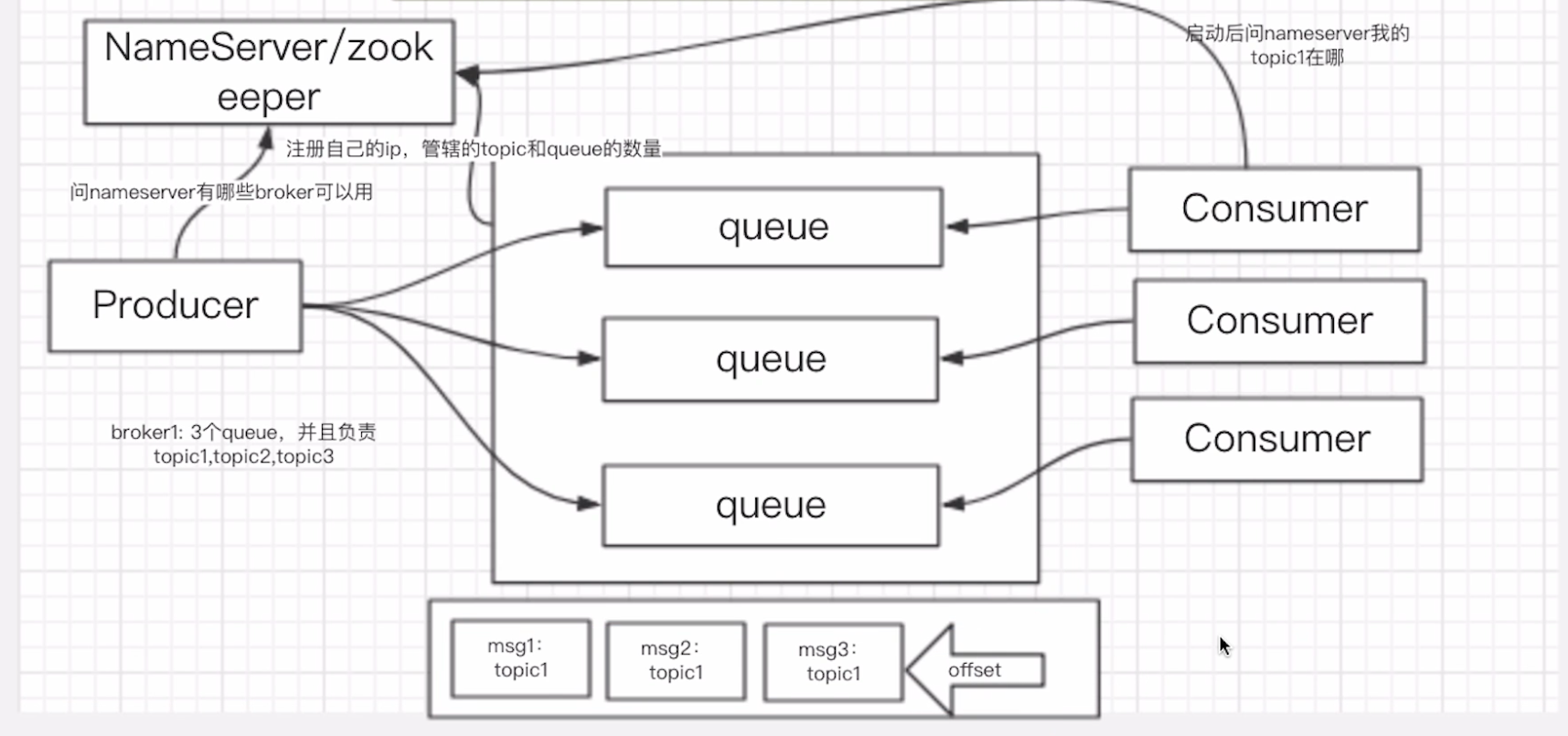
rocketMQ
阿里巴巴在kafka的基础上修改来的,继承了kafka的所有优秀的地方
发布订阅:客户端将消息发送到主题,消息队列存放主题,订阅者消费主题消息,消息队列维护高可用,并支持事务回溯机制。
4:任务调度
任务:Task,需要依靠计算机程序完成的一系列事情。
调度:Control,执行控制任务的指挥,处罚,规则程序。
任务调度:使用一系列的触发规则在特定的时间点指挥计算机完成一系列的事情。
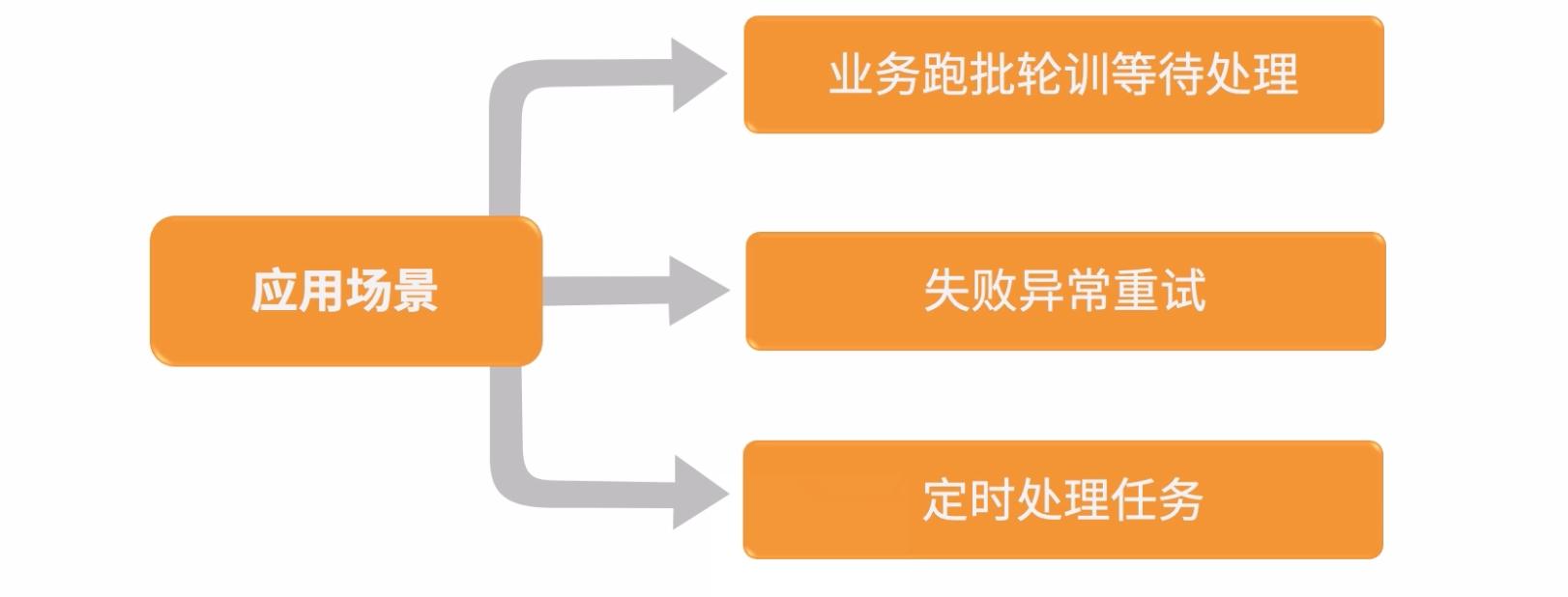
单机系统下的任务调度
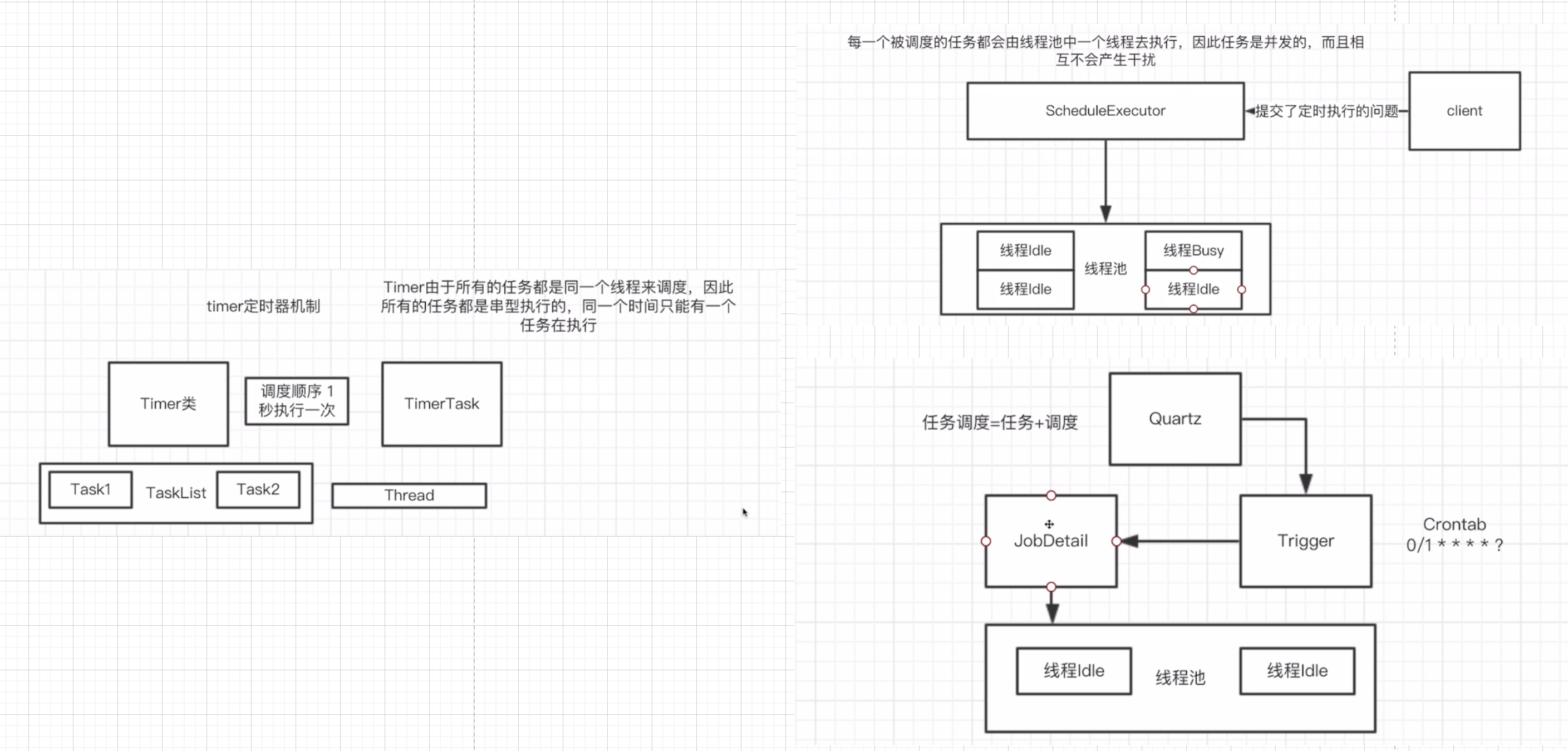
分布式任务调度
5:池化
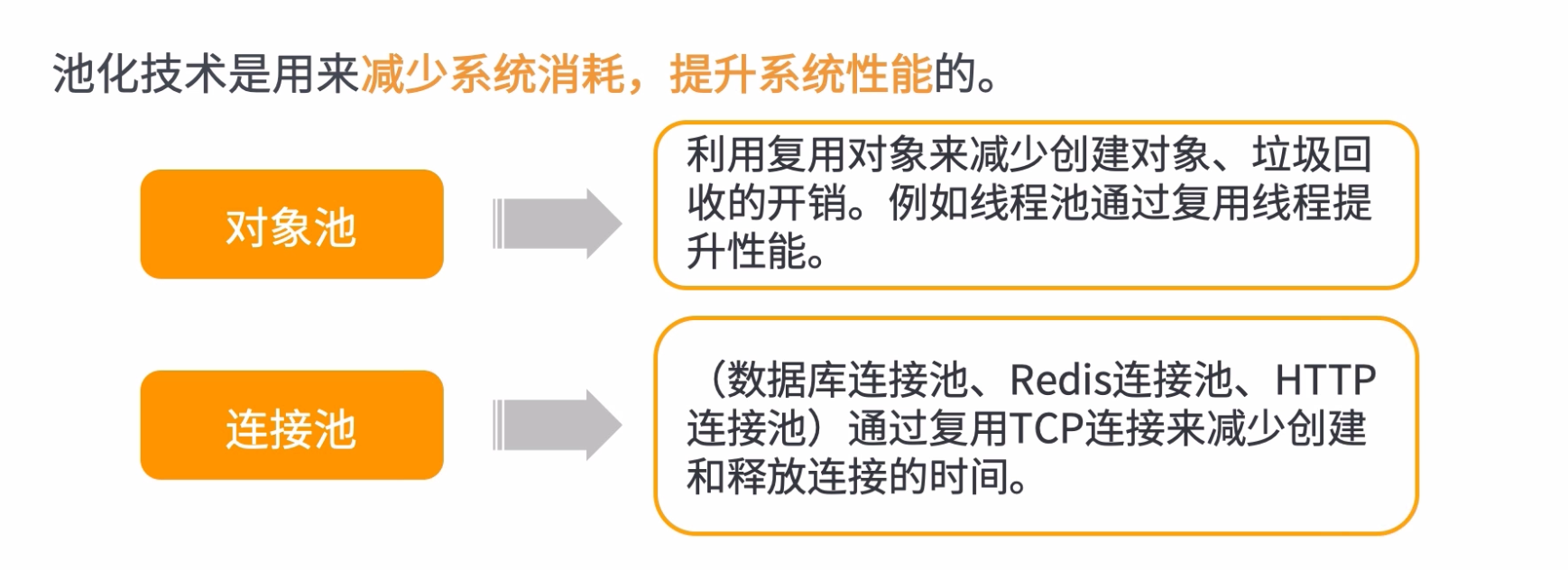
简单来说,池化技术就是通过复用来提升性能
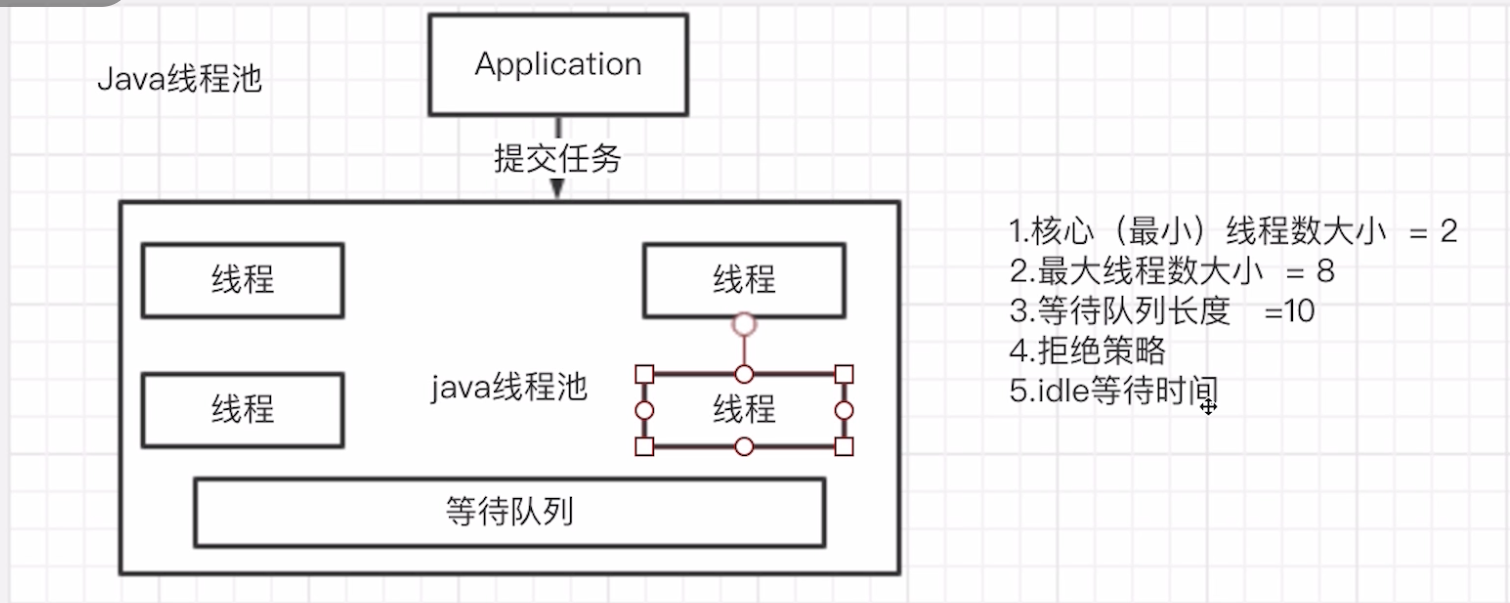
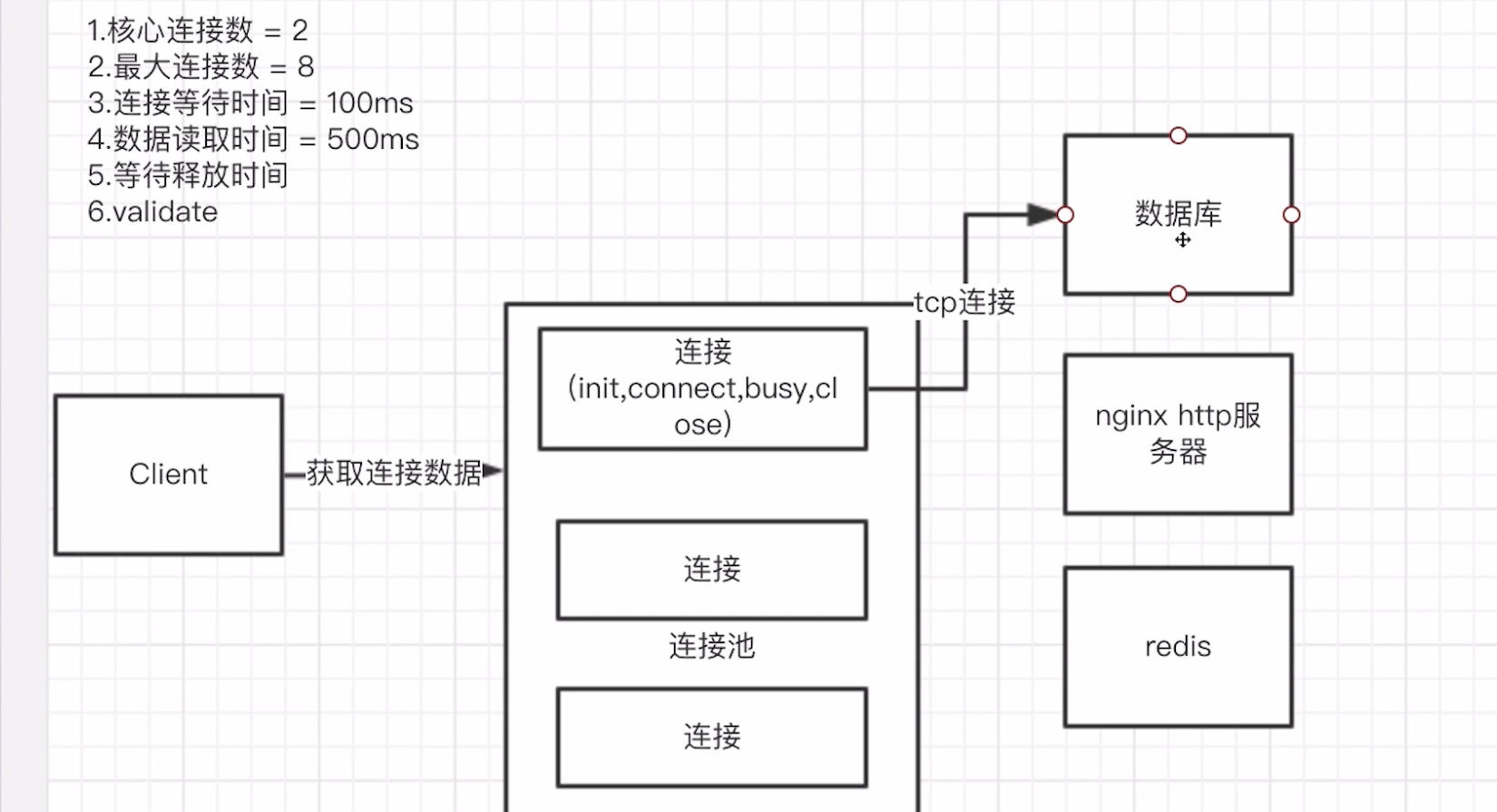
常用的连接池和线程池如下:
- java线程池
- 数据库连接池
- httpclient连接池
- redis连接池
- tomcat连接及线程池
- Dubbo连接及线程池
6:缓存、隔离和队列
6.1:缓存技术
缓存是分布式系统中的重要组件,主要解决高并发,大数据场景下,热点数据访问的性能问题。提供高性能的数据快速访问。

设计原则
- 将数据写入/读取速度更快的存储(设备)
- 将数据缓存到离应用最近的位置
- 将数据缓存到离用户最近的位置
缓存的分类
- CDN缓存,CDN服务器
- 反向代理缓存(Nginx Proxy Cache)
- 分布式Cache (redis)
- 本地应用缓存(JVM Guava, caffine)
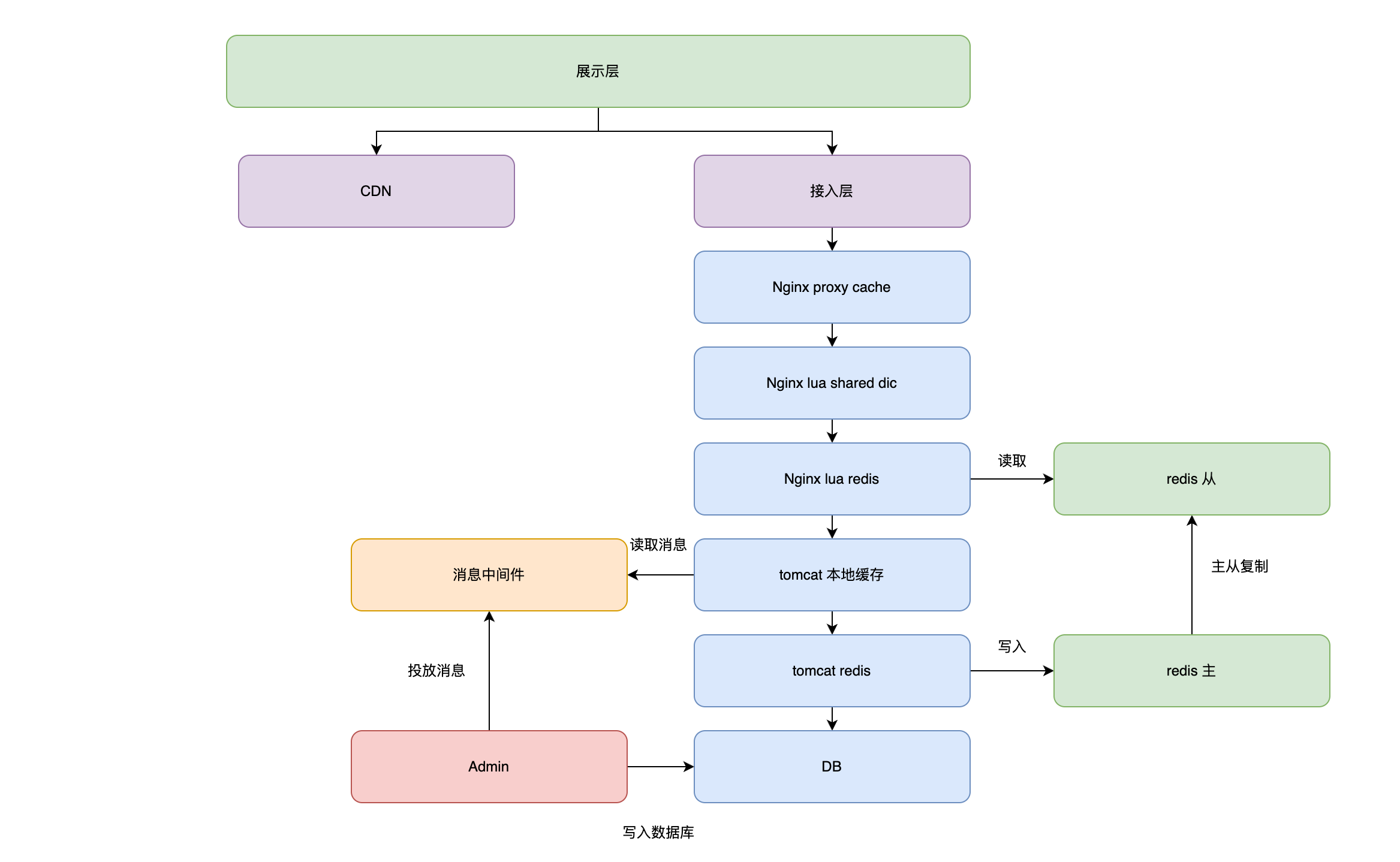
6.2:隔离
隔离是指将系统或资源分割开,系统隔离是为了在系统发生故障时能限定传播范围和影响范围,即发生故障后不会出现滚雪球效应,从而保证只有出问题的服务不可用,其他服务仍可用。
常见隔离维度
- 硬件隔离(虚拟机)
- 操作系统隔离(容器虚拟化)
- 进程隔离(系统拆分)
- 线程隔离(线程池独立)
- 读写隔离(读写分离)
- 动静隔离(动态资源静态资源分离)
- 热点隔离(热点账户,热点数据等)
6.3:队列
异步,解耦,削峰
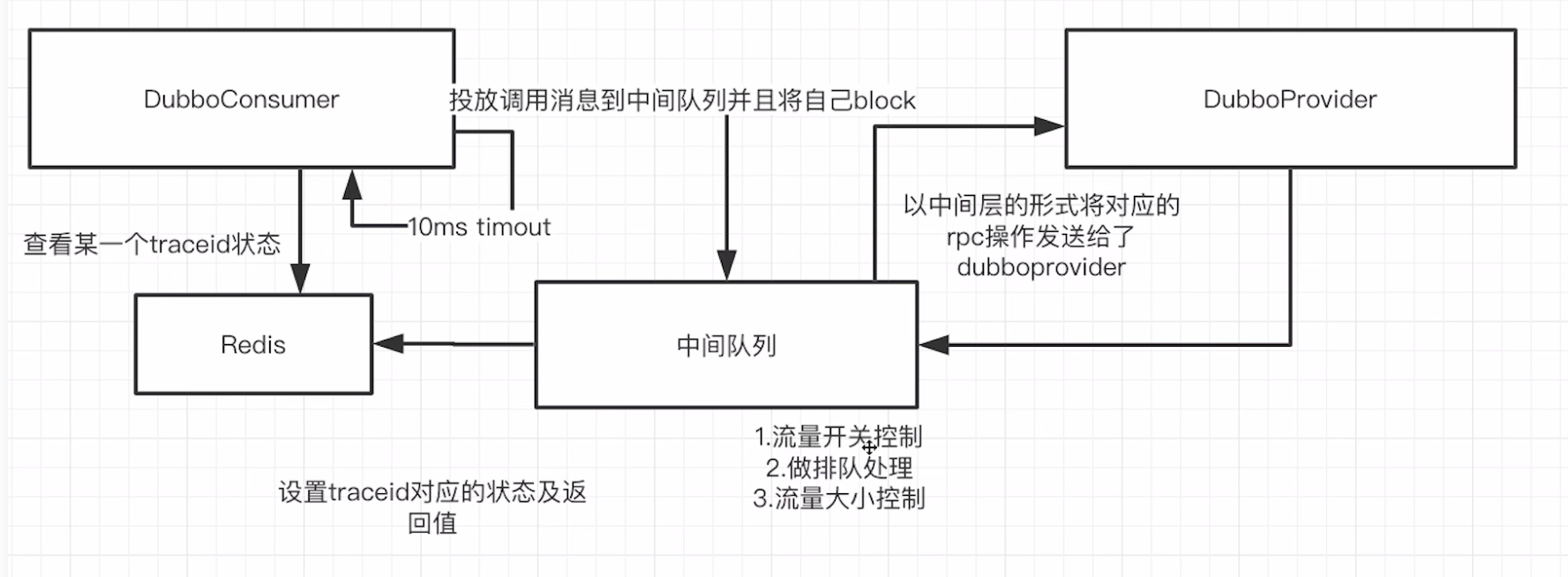
五:数据层架构设计
1:数据存储

数据存储的重要性
- 所有的用户操作及变更最终都反映在数据存储层面
- 数据存储需要确保最终一致性
- 数据存储是系统的性能瓶颈点
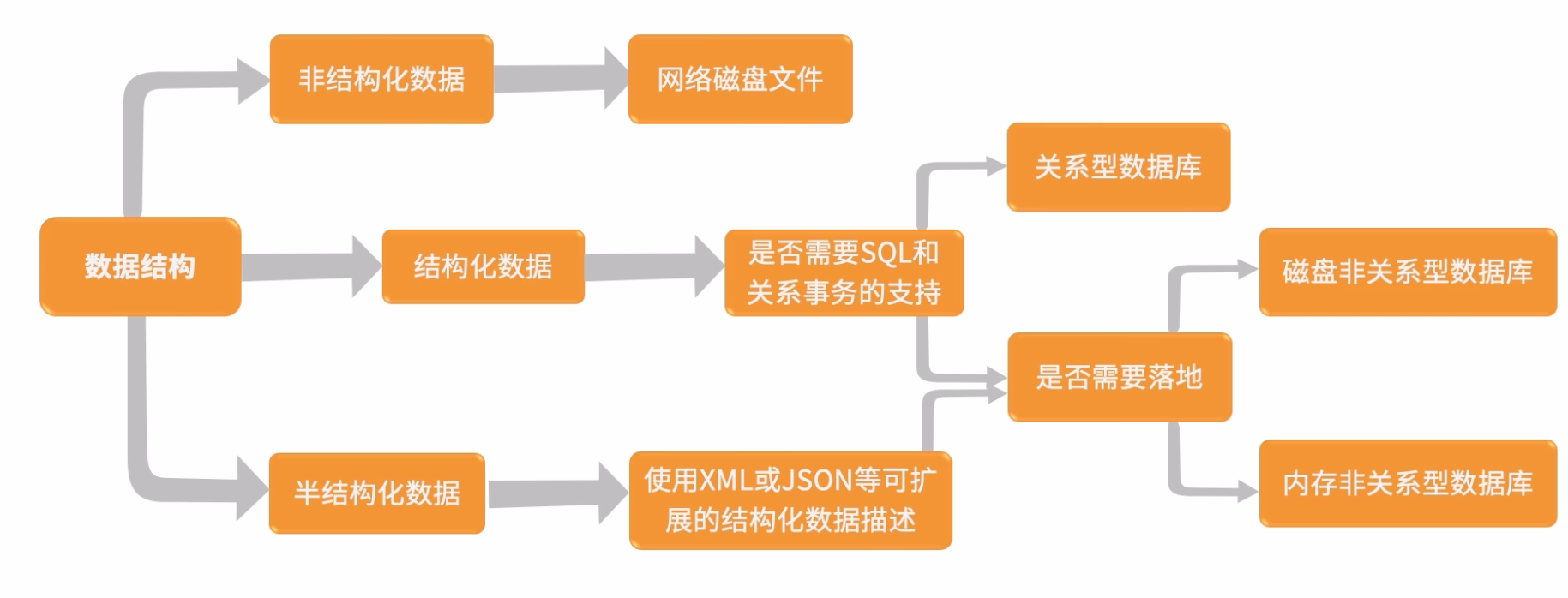
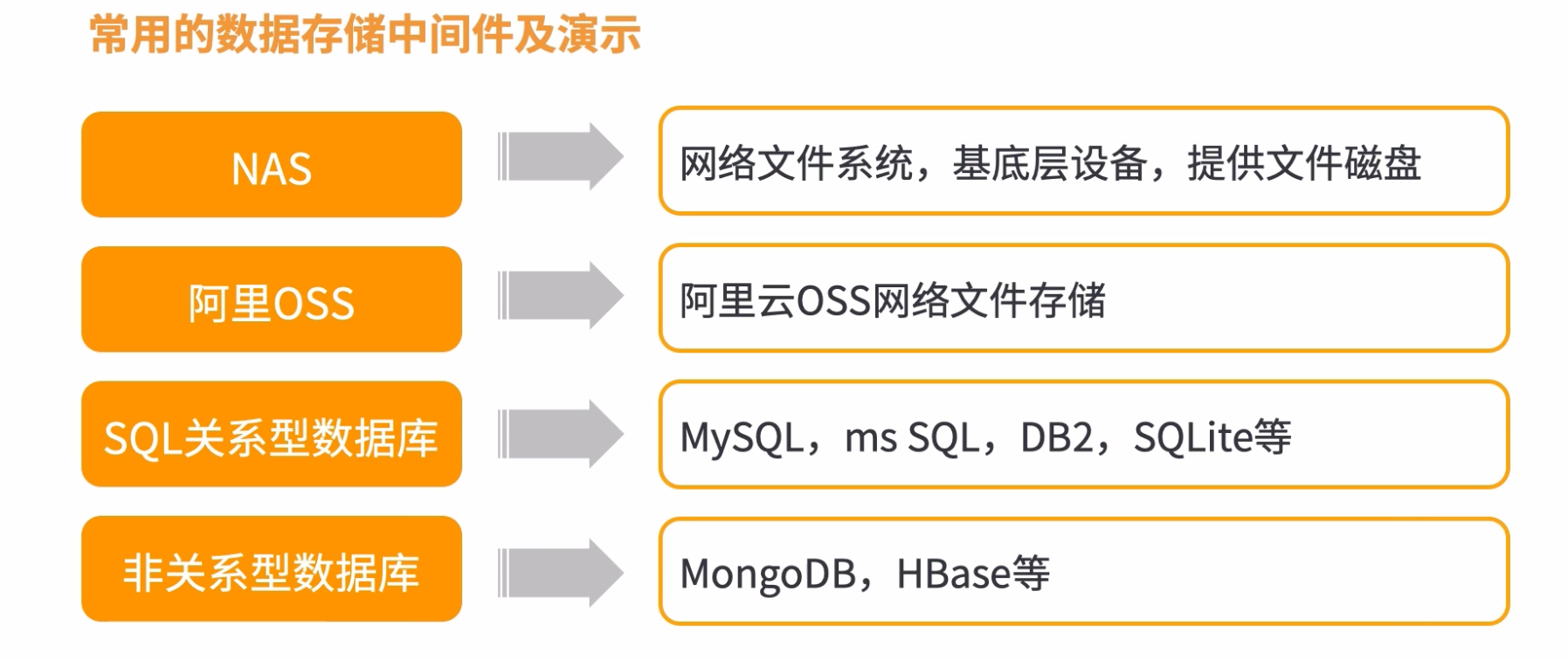
2:关系型和非关系型数据库
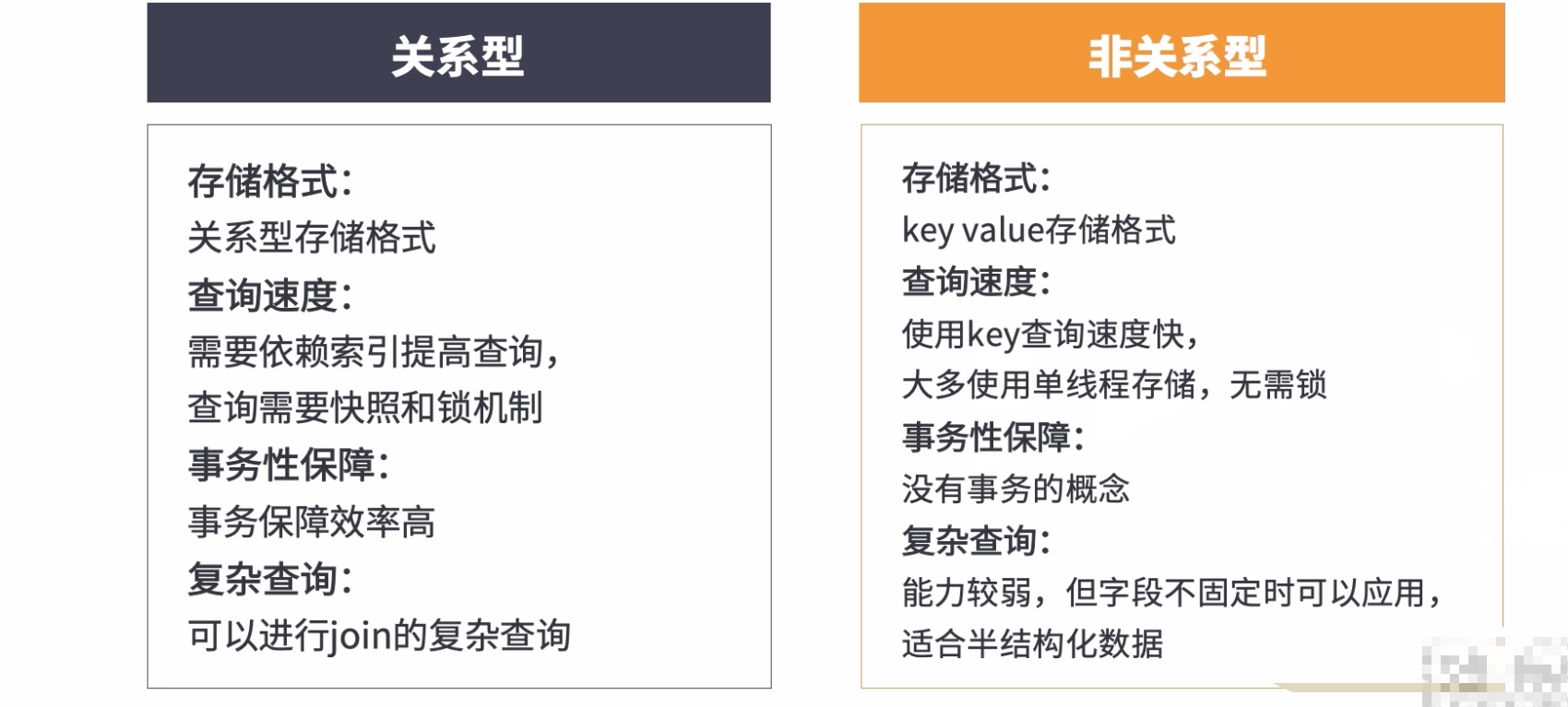
我的mysql专栏
我的mongodb专栏
3:代理访问
后端代理服务器 - nginx

数据库代理 - mycat, sharding jdbc

缓存代理

六:监控、限流和降级
我的相关文章