PyTorch 机器学习基础(选择合适优化器)
选择合适优化器
优化器在机器学习、深度学习中往往起着举足轻重的作用,同一个模型,因选择不同
的优化器,性能有可能相差很大,甚至导致一些模型无法训练。所以,了解各种优化器的
基本原理非常必要。本节将重点介绍各种优化器或算法的主要原理,及各自的优点或不
足。
传统梯度优化的不足
θ←θ−λg\theta \leftarrow \theta - \lambda g θ←θ−λg
这种梯度更新算法简洁,当学习率取值恰当时,可以收敛到全面最优点(凸函数)或
局部最优点(非凸函数)。
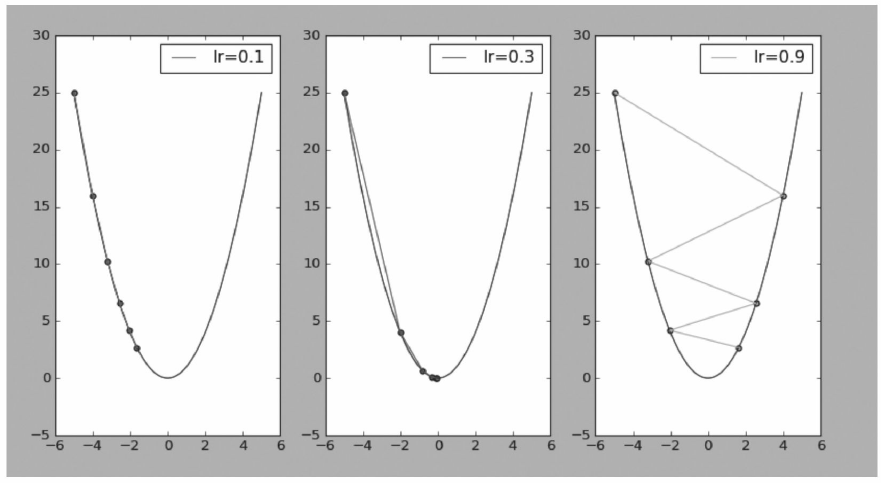
但其不足也很明显,对超参数学习率比较敏感(过小导致收敛速度过慢,过大又越过
极值点),如图5-11的右图所示。在比较平坦的区域,因梯度接近于0,易导致提前终止
训练,如图5-11的左图所示,要选中一个恰当的学习速率往往要花费不少时间。
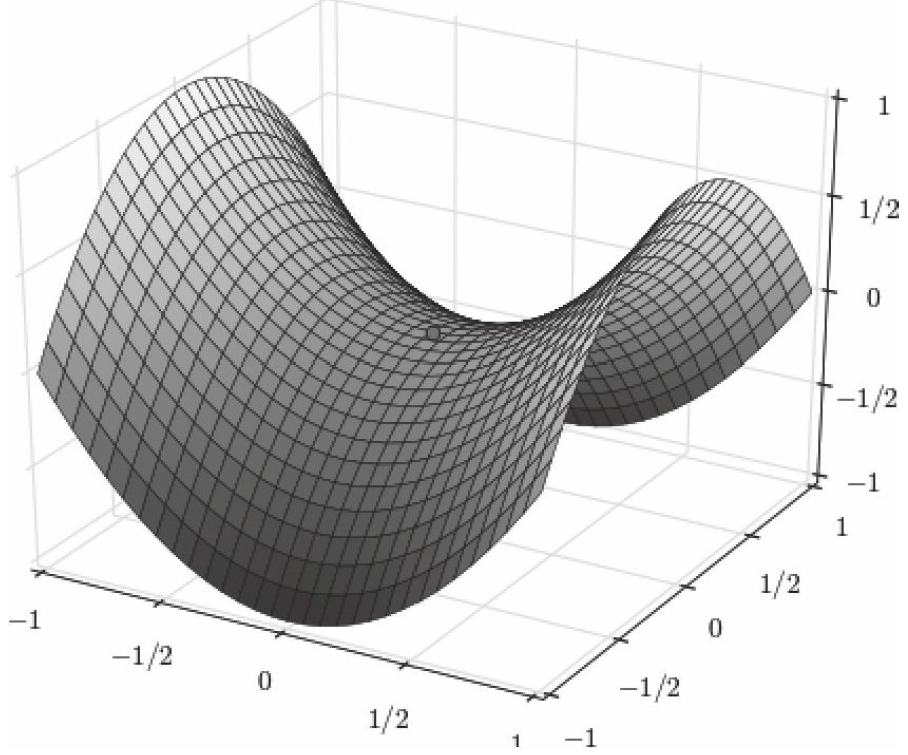
学习率除了敏感,有时还会因其在迭代过程中保持不变,很容易造成算法被卡在鞍点
的位置,如图5-12所示。
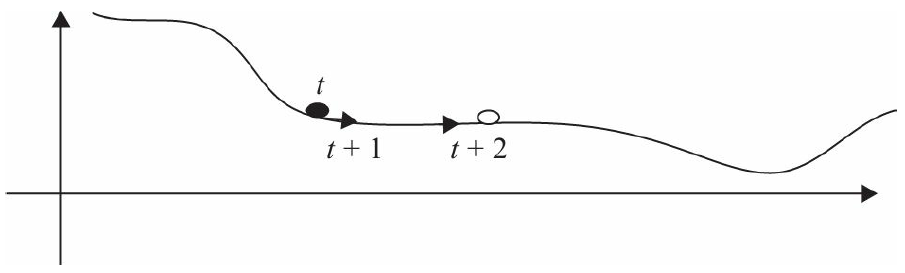
另外,在较平坦的区域,由于梯度接近于0,优化算法会因误判,在还未到达极值点
时,就提前结束迭代,如图5-13所示。
传统梯度优化方面的这些不足,在深度学习中会更加明显。为此,研究人员自然想到
如何克服这些不足的问题。从式(5-12)可知,影响优化的无非两个因素:一个是梯度方
向,一个是学习率。所以很多优化方法大多从这两方面入手,有些从梯度方向入手,如5.6.2节介绍的动量更新策略;而有些从学习率入手,这涉及调参问题;还有从两方面同时
入手,如自适应更新策略,接下来将分别介绍这些方法。
动量算法
梯度下降法在遇到平坦或高曲率区域时,学习过程有时很慢。利用动量算法能比较好
解决这个问题。动量算法与传统梯度下降优化的效果如图5-14所示。
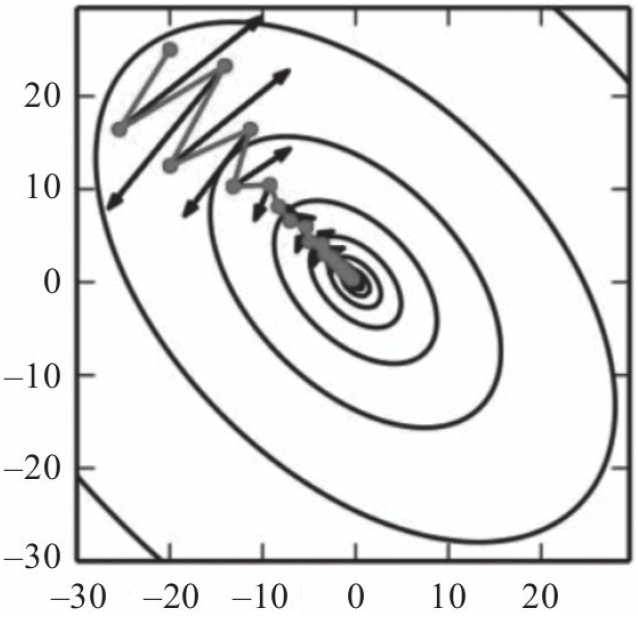
从图5-14可以看出,不使用动量算法的SGD学习速度较慢,振幅较大;而使用动量算
法的SGD,振幅较小,而且会较快到达极值点。那动量算法是如何做到这点的呢?
动量(Momentum)是模拟物理里动量的概念,具有物理上惯性的含义,一个物体在
运动时具有惯性,把这个思想运用到梯度下降计算中,可以增加算法的收敛速度和稳定
性,具体实现如图5-15所示。
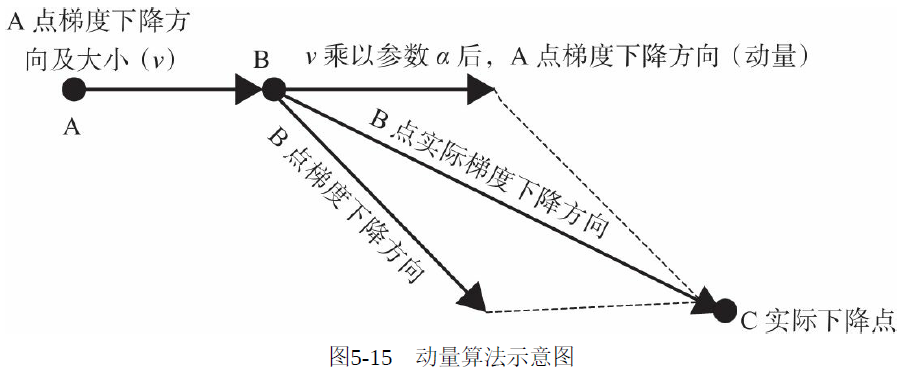
由图5-15可知,动量算法每下降一步都是由前面下降方向的一个累积和当前点的梯度
方向组合而成。含动量的随机梯度下降法,其算法伪代码如下:

既然每一步都要将两个梯度方向(历史梯度、当前梯度)做一个合并再下降,那为什
么不先按照历史梯度往前走那么一小步,按照前面一小步位置的“超前梯度”来做梯度合并
呢?这样就可以先往前走一步,在靠前一点的位置(如图5-16中的C点)看到梯度,然后
按照那个位置再来修正这一步的梯度方向,如图5-16所示。这就得到动量算法的一种改进
算法,称为Nesterov Accelerated Gradient,简称NAG算法。这种预更新方法能防止大幅振
荡,不会错过最小值,并会对参数更新更加敏感。
NAG下降法的算法伪代码如下所示:

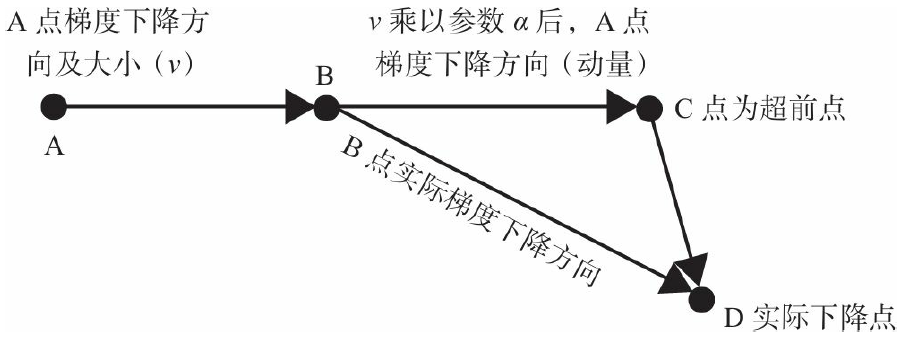
NAG动量法和经典动量法的差别就在B点和C点梯度的不同。动量法更多关注梯度下
降方法的优化,如果能从方向和学习率同时优化,效果或许更理想。事实也确实如此,而
且这些优化在深度学习中显得尤为重要。接下来将介绍几种自适应优化算法,这些算法同
时从梯度方向及学习率进行优化,效果都非常好。
AdaGrad算法
传统梯度下降算法对学习率这个超参数非常敏感,难以驾驭,对参数空间的某些方向
也没有很好的方法。这些不足在深度学习中,因高维空间、多层神经网络等因素,常会出
现平坦、鞍点、悬崖等问题,因此,传统梯度下降法在深度学习中显得力不从心。还好现
在已有很多解决这些问题的有效方法。5.6.2节介绍的动量算法在一定程度上缓解了对参数
空间某些方向的问题,但需要新增一个参数,而且对学习率的控制还不是很理想。为了更
好地驾驭这个超参数,人们想出来多种自适应优化算法,使用自适应优化算法,学习率不
再是一个固定不变值,它会根据不同情况自动调整来适应相应的情况。这些算法使得深度
学习向前迈出了一大步!本节我们将介绍几种自适应优化算法。
AdaGrad算法是通过参数来调整合适的学习率λ,是能独立地自动调整模型参数的学
习率,对稀疏参数进行大幅更新和对频繁参数进行小幅更新。因此,Adagrad方法非常适
合处理稀疏数据。AdaGrad算法在某些深度学习模型上效果不错。但还有些不足,可能因
其累积梯度平方导致学习率过早或过量的减少所致。
AdaGrad算法伪代码:

由上面算法的伪代码可知:
1)随着迭代时间越长,累积梯度r越大,导致学习速率λλδ+rβ\frac{\lambda}{\lambda}\delta + \sqrt{r}\betaλλδ+rβ
以上内容均由AI搜集总结并生成,仅供参考随着时间减小,在接近
目标值时,不会因为学习速率过大而越过极值点。
3)如果梯度累积参数r比较小,则学习速率会比较大,所以参数迭代的步长就会比较
大。相反,如果梯度累积参数比较大,则学习速率会比较小,所以迭代的步长会比较小。
RMSProp算法
RMSProp算法通过修改AdaGrad得来,其目的是在非凸背景下效果更好。针对梯度平
方和累计越来越大的问题,RMSProp指数加权的移动平均代替梯度平方和。RMSProp为了
使用移动平均,还引入了一个新的超参数ρ,用来控制移动平均的长度范围。
RMSProp算法伪代码:

RMSProp算法在实践中已被证明是一种有效且实用的深度神经网络优化算法,因而在
深度学习中得到广泛应用。
Adam算法
Adam(Adaptive Moment Estimation)本质上是带有动量项的RMSprop,它利用梯度
的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置
校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
Adam是另一种学习速率自适应的深度神经网络方法,它利用梯度的一阶矩估计和二
阶矩估计动态调整每个参数的学习速率。Adam算法伪代码如下:

前文介绍了深度学习的正则化方法,它是深度学习核心之一;优化算法也是深度学习
的核心之一。优化算法有很多,如随机梯度下降法、自适应优化算法等,那么具体使用时
该如何选择呢?
RMSprop、Adadelta和Adam被认为是自适应优化算法,因为它们会自动更新学习率。
而使用SGD时,必须手动选择学习率和动量参数,通常会随着时间的推移而降低学习率。
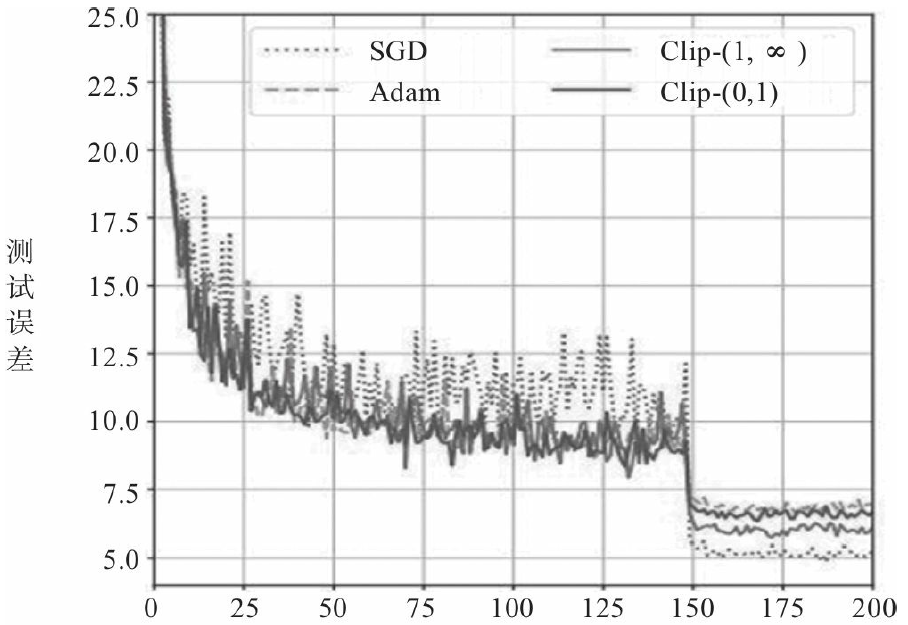
有时可以考虑综合使用这些优化算法,如采用先使用Adam,然后使用SGD的优化方
法,这个想法,实际上是由于在训练的早期阶段SGD对参数调整和初始化非常敏感。因
此,我们可以通过先使用Adam优化算法来进行训练,这将大大地节省训练时间,且不必
担心初始化和参数调整,一旦用Adam训练获得较好的参数后,就可以切换到SGD+动量
优化,以达到最佳性能。采用这种方法有时能达到很好的效果,如图5-17所示,迭代次数
超过150后,用SGD效果好于Adam。