30.LSTM-长短时记忆单元
循环神经网络RNN,存在短期记忆的问题。如果一个序列足够长,那么对于处在前部的词对后方的词的影响效果就会很有限。也就是说,如果前部的信息比较重要,在训练后方数据时,会遗漏许多前方的重要信息。
从权重角度分析,网络在反向传播过程中,网络梯度越往前越容易发生梯度消失,也就是说越往前梯度值越小,权重更新的少,对学习贡献越小。由于前方的层不学习,RNN忘记序列前面的内容,所以造成短期记忆。
LSTM的作用是,整合全部信息,使网络不止进行短时记忆,也具有长时记忆。
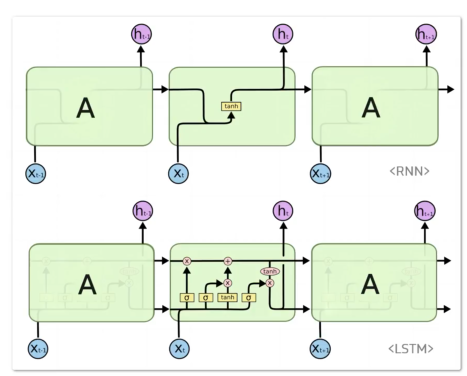
LSTM
Ct-1:上一时刻长时记忆输入
Ct:长时记忆输出
ht-1:上一时刻短时记忆输入
ht:短时记忆输出
xt:当前时刻输入
LSTM所有cell间参数共享
模型读文章的过程中,在读第1个字、第100个字、甚至最后一篇文章的最后一个字时,它使用的都是同一种思维方式。它不会每读一个字就换一个大脑。它用一套统一的规则来处理序列中的每一个元素。

整体分析
1.上方长时记忆C为一路,从始至终传递,每一层经过一定程度修正
2.下方短时记忆h为一路,进行当前时刻输入与短时记忆的运算,为原RNN部分的加强。
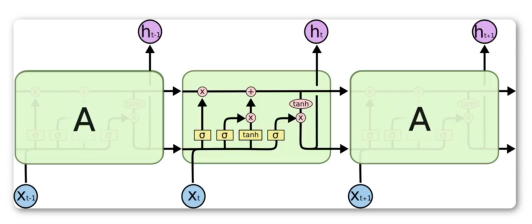
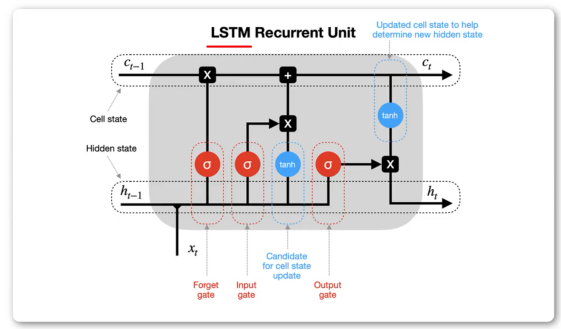
RNN基础上改变:
1.输入上多出了Ct-1,输出上多出了Ct。
2.在原对ht-1的处理中,加入了遗忘门,输入门,输出门
3.多引入了一次tanh非线性变化
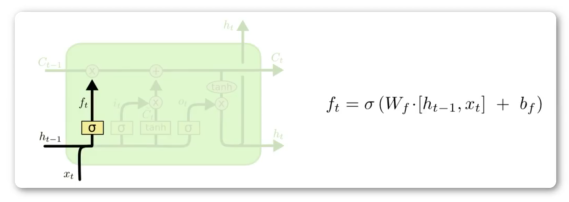
遗忘门
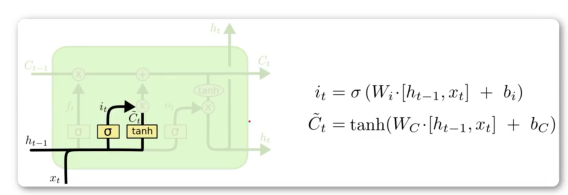
σ表示Sigmoid函数,输出从0到1的值,决定Ct-1更新多少,或者说对上一时刻丢弃多少(0到1),故此称作遗忘门。换句话说,输入不是拿过来就全用。输出的信息涉及当前时刻和上一时刻短时输入。
函数关系式:上一时刻输入ht-1,和当前时刻输入 xt 做拼接。拼接后和遗忘门权重矩阵Wf做相乘。相乘后加偏置。结果进行Sigmoid处理。
实际应用中,C0和h0可以是全0向量。
输入门
σ表示Sigmoid函数,输出从0到1的值,决定输入 xt 更新多少。
函数关系式:
σ部分(it):上一时刻输入ht-1,和当前时刻 xt 做拼接。乘权重矩阵Wi,加偏置,放入SIgmoid。如上。
Chead_t:上一时刻输入ht-1,和当前时刻 xt 做拼接。乘权重矩阵Wc,加偏置,放入tanh。
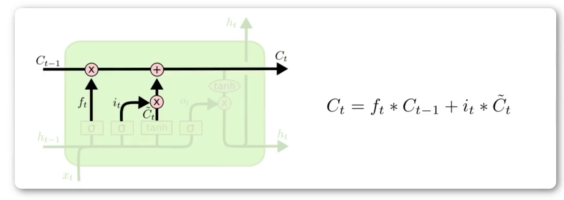
单元状态更新
遗忘门输出 ft 乘 Ct-1,加上输入门输出 it 乘 Chead_t。得到Ct,表示长时记忆,作为下一个cell的输入。
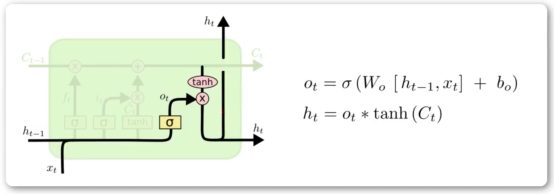
输出门
输出门得到ht,是本层的输出,是下一层的短时输入
ot部分:ht-1和xt作拼接,乘权重矩阵Wo,加偏置项,输入Sigmoid。
ht:Ct输入tanh,结果与ot相乘。
归纳
1.LSTM明显比RNN参数多多了
2.原图中黄色的部分,是layer,都涉及参数。粉色部分是单纯计算。
LSTM设计原理分析——为什么这么设计?
1.针对原RNN引入了长时记忆C,这部分是如何处理的?
从源头开始单独的支线,过程中受当前时刻输入和上一层短时记忆输入的影响,对长时记忆不断修正
2.为什么要分遗忘门和输入门两部分来修正C?他们各自发挥了什么作用?
关于遗忘门:当前时刻计算的信息,与Ct-1相乘,事实上是对上一时刻的长时记忆做了修正,决定了哪些长时记忆信息被丢弃或遗忘。
关于输入门:由Sigmoid处理和Tanh两种方法处理的Xt与ht-1得到。输出又由二者相乘得到。
C由遗忘门和输入门求和得到。(问题搁置继续挖掘)
3.为什么输入门要使用tanh和Sigmoid两种?为什么二者是相乘关系?
tanh函数有什么特点?答:-1到1,梯度平滑,能缓解梯度消失。追溯前文,短时记忆网络问题就是随着传播存在梯度消失,cell中两次引入都是为了减轻梯度消失问题。
Sigmoid函数什么作用?答:0到1,修正作用,用于对输入信息的更新。
二者相乘什么结果?答:处理梯度消失问题,并进行修正。
为什么要用遗忘门和输入门相加的结果来计算Ct?答:即保留对信息的修正,又保留修正后的tanh。Sigmoid控制的是0到1,即对信息更新多少。tanh控制的是-1到1,表示信息的正负倾向和强度。二者相乘含义是:用Sigmoid去调制tanh,即用决策向量it去调制内容向量Chead_t,以得到Ct。
4.为什么遗忘门和输入门相加得到Ct?
答:遗忘门是对旧信息的遗忘,输入门是获取新信息。二者相加,得到新信息。
5.为什么tanh(Ct)与修正信息相乘得到ht?
答:通过tanh缓解梯度消失,相乘部分参考输入门的处理方式。
6.如果只采用tanh会怎样?输入门、输出门分别分析。
输入门只采用tanh:长时记忆经过两次缩放(上一时刻输出门一次,当前时刻输入门一次),新信息未经缩放,新信息占比较大,此时,将无法长期稳定传递长时记忆。(事实上就是RNN)
输出门只采用tanh:输出全部信息,相对于有选择的输出,增加了许多的噪音。少一步Sigmoid,梯度变化更大。参数矩阵增加了模型表达能力。遗忘门只能控制信息的更新,控制不了上一时刻的输入。
7.如果只采用Sigmoid会怎样?输入门、输出门分别分析。
输入门只采用Sigmoid:去除了新信息的正负偏向
输出门只采用Sigmoid:去除了长时记忆的正负偏向,此外如果Sigmoid值很大梯度消失问题再现。