自然语言处理——07 BERT、ELMO、GTP系列模型
1 BERT
1.1 简介
- BERT模型,全称 Bidirectional Encoder Representation from Transformers
- 是Google在2018年提出的一种革命性的自然语言处理(NLP)模型;
- BERT在机器阅读理解顶级水测试SQuAD1.1(Standford Question Answering Dataset,SQuAD,斯坦福问答数据集)中表现出惊人的成绩:全部两个衡量指标上全面超越人类,并且在11种不同NLP测试中创出SOTA表现。包括将GLUE基准推高至80.4%(绝对改进7.6%),MultiNLI准确度达到86.7%(绝对改进5.6%),成为NLP发展史上的里程碑式的模型成就;
- 拓展阅读:几个时间点
- 2001 - Neural language models(神经语言模型)
- 2013 - Word embeddings(词嵌入)
- 2013 - Neural networks for NLP(NLP神经网络)
- 2014 - Sequence-to-sequence models
- 2015 - Attention(注意力机制)
- 2015 - Memory-based networks(基于记忆的网络)
- 2017- 《Attention is all you need》transform问世
- 2018 - Pretrained language models(预训练语言模型)
- 2018 - openAI 提出GPT 2018年 上半年03~05月
- GPT 1.0:Improving Language Understanding by Generative Pre-Training 2018
- GPT 2.0:Language Models are Unsupervised Multitask Learners 2019
- GPT 3.0:Language Models are Few-Shot Learners 2020
- 2018.10月 bert
1.2 模型架构
1.2.1 架构总览
-
从架构图中可以看到,宏观上BERT分三个主要模块:
- 最底层黄色标记的 Embedding 模块
- 中间层蓝色标记的 Transformer 模块
- 最上层绿色标记的预微调模块
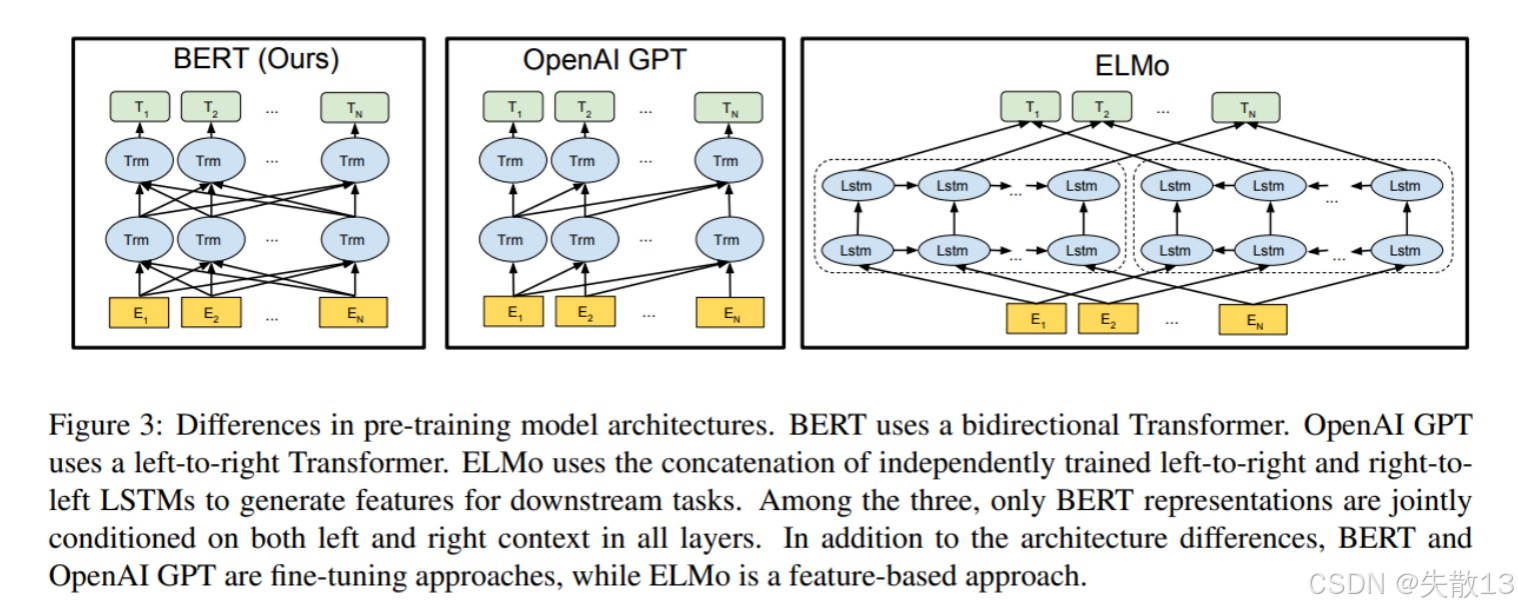
1.2.2 BERT、ELMo、GTP对比
- BERT采用了 Transformer Encoder 编码器, 是一个典型的深度双向编码模型
- eg:T2单词特征可以从左到右,从右到左的提取事物特征,并深度融合其他单词的特征
- GPT采用 Transformer Decoder 解码器,是从左到右的提取事物特征
- ELMo使用独立的从左到右提取特征,右到左的提取特征,然后拼接拼接起来
- eg:只是从左到右提取T2,再从右到左的提取T2,拼接起来,不是深度融合
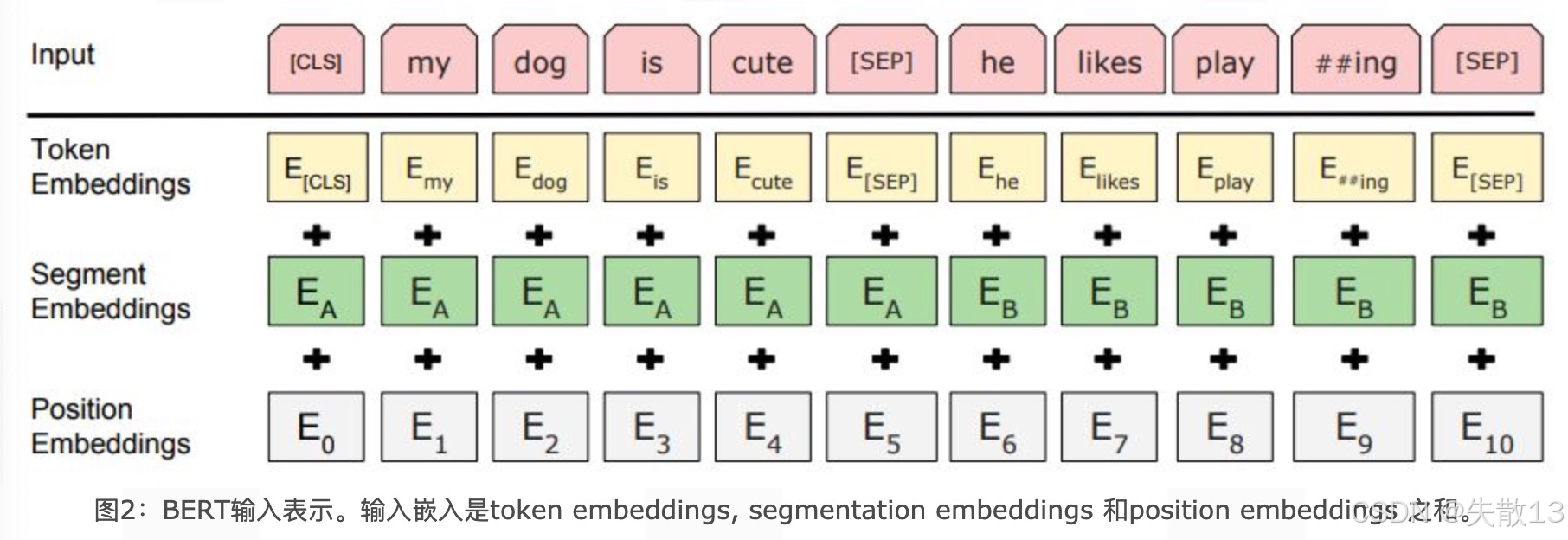
1.2.3 Embedding 模块
-
BERT的Embedding模块,由 Token Embeddings(词嵌入)、Segment Embeddings(句子分段嵌入)、Position Embeddings(位置嵌入) 三种嵌入共同组成,最终将三者相加,得到每个token的完整嵌入表示(维度均为[1,768],相加后维度保持 [1,768]),作为模型输入,为后续编码做准备;
-
各嵌入作用:
-
Token Embeddings(词嵌入):对输入文本的每个词(Token)做嵌入处理,把词转化为向量。其中,序列首个特殊标记,在分类任务里,常取该位置输出做整体文本语义表示,用于判断文本类别(如情感分类“正面/负面”);
-
Segment Embeddings(句子分段嵌入):因BERT可处理句子对类型的任务(如句子是否匹配、蕴含关系等),用此区分两个句子。比如处理“句子A + [SEP] + 句子B”,给句子A的词加一种分段嵌入,句子B的词加另一种,让模型识别句子边界与所属分段;
-
Position Embeddings(位置嵌入):给词添加位置信息,因Transformer本身结构无顺序感知能力,需额外编码位置。不同于传统Transformer用三角函数固定计算,BERT通过模型训练“学习”位置表示,让模型理解词在序列里的顺序,辅助捕捉文本时序、语序对语义的影响。
-
1.2.4 双向Transformer模块
-
只使用了Transformer架构中的Encoder部分,完全舍弃了Decoder部分;
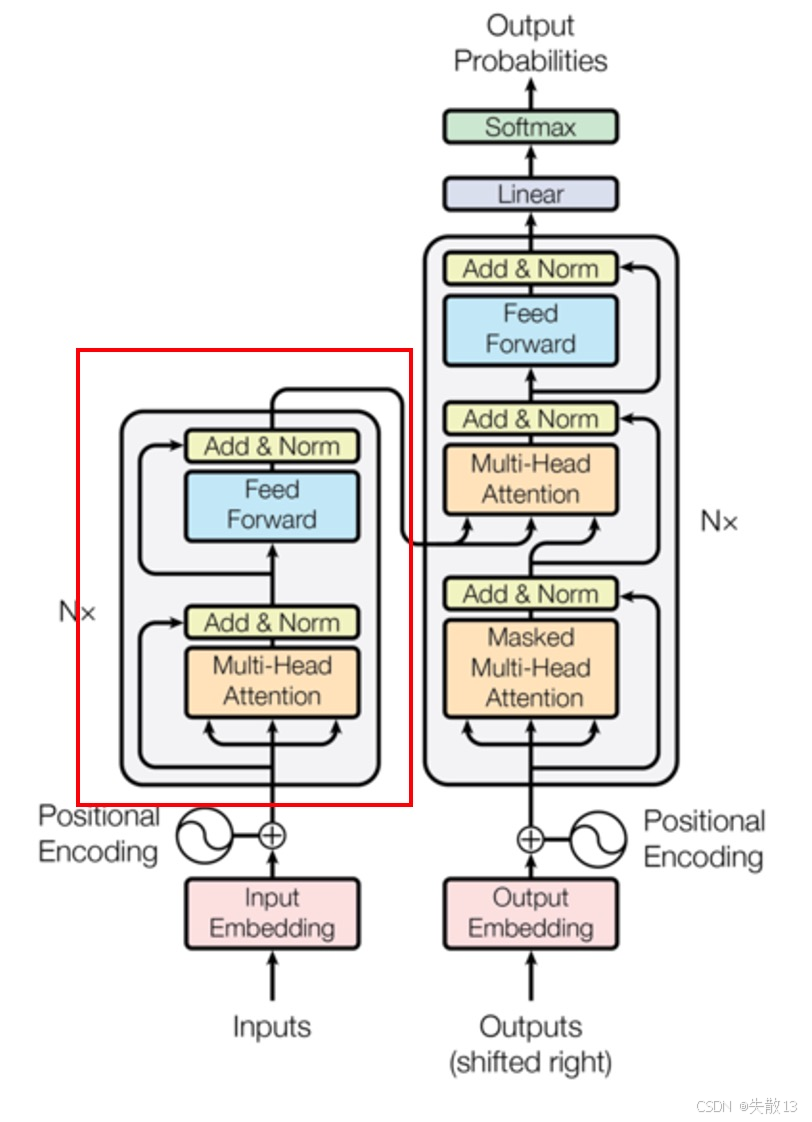
- BERT的双向Transformer模块,基于Transformer架构构建,但仅用了Encoder(编码器)部分,舍弃了Decoder(解码器)部分。Transformer原本是包含Encoder(负责编码输入文本语义)和解码器(Decoder,依据编码信息生成输出,像翻译任务里生成目标语言文本)的完整架构,BERT因聚焦“理解文本语义”(如文本分类、问答任务里的文本编码),用Encoder就够,所以简化了结构;
- Encoder的作用:Transformer的Encoder,通过**多头自注意力(Multi - Head Attention)、前馈神经网络(Feed - Forward Network)**等组件,对输入文本做深度编码;
- 多头自注意力让模型能从多维度、多视角捕捉词与词的依赖关系;
- 前馈神经网络则进一步处理、整合这些信息,最终输出蕴含丰富语义的文本表示,供BERT后续做各类任务;
- “双向”的体现:在Encoder里,借助多头自注意力的“双向”特性(处理每个token时,能同时关注其左右所有token的信息),让BERT可充分捕捉文本上下文语义,区别于单向语言模型(如仅从左到右处理,缺失右侧信息),这也是BERT在语义理解任务表现出色的关键。简单说,就是BERT用Transformer的Encoder,借其双向注意力,高效编码文本语义,为下游NLP任务打基础。
1.2.5 预微调模块
-
作用:BERT预训练后,已学习到通用文本语义表示。预微调模块的作用,就是让BERT适配具体NLP任务,输出任务结果。比如:经过中间层(Transformer)处理,BERT最后一层不用大改结构,仅根据任务“微调”(调整输出逻辑、接简单分类/预测头),就能适配不同任务;
-
原理:BERT的Transformer层已提取文本深度语义(像词间关系、上下文含义)。面对具体任务(分类、问答等),不需要重新训练整个模型,只在预训练的语义表示基础上,对输出层/预微调层做针对性调整,让模型学会“用通用语义解决特定任务”;
-
几种重要的NLP微调任务架构图如右图:
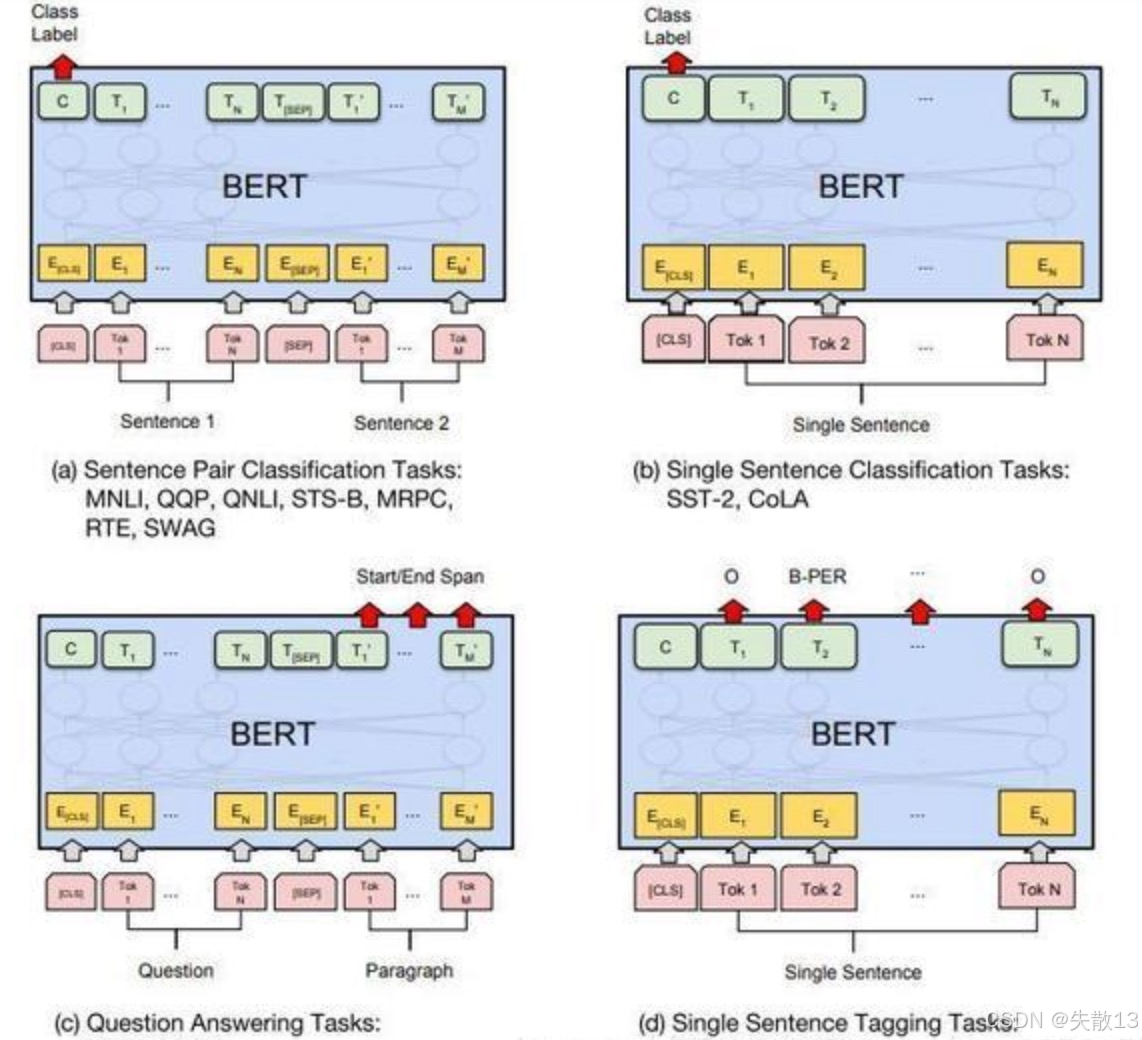
-
句子对关系判断(a图):输入2个句子(如“句子1 + [SEP] + 句子2”),判断二者关系,属于分类任务;
-
比如:
- 句子是否“蕴含”(如“鸟会飞”和“麻雀能飞” ,后者被前者蕴含);
- 是否“矛盾”(如“今天晴天”和“今天下雨”);
- 是否“相似”(如“我喜欢猫”和“我喜爱猫咪”);
-
模型输出层接分类器,基于BERT编码的句子对语义,预测关系类别;
-
-
单句子分类(b图):输入1个句子,做文本分类;
-
比如:
- 情感分类(“这部电影超棒!” → 正面情感);
- 语法判断(句子是否有语法错误);
-
用标记(BERT输入首位置的特殊token)的编码表示整个句子语义,接分类层输出类别;
-
-
问答任务(c图):输入“问题 + [SEP] + 上下文”,让模型从上下文中找答案;
- 比如“上下文讲了历史事件,问题问‘事件发生时间’”,模型需定位并提取对应文本片段,输出答案区间;
-
Token级别标注(d图):对句子中每个词(Token) 做分类/标注;
-
比如:
- 分词(把连续文本拆成词,如“英雄联盟” → “英雄”“联盟” );
- 命名实体识别(NER,识别“人名、地名、机构名” ,如“北京是中国首都” → 标记“北京”为地名);
-
模型为每个Token输出类别/标注,实现逐词预测。
-
-
1.3 预训练
1.3.1 简介
-
一个模型先通过一批语料进行预训练,这个阶段就是预训练任务,得到预训练模型,然后在这个初步训练好的预训练模型基础上,再继续训练或者另作他用;
-
预训练的整个过程分为两个阶段:预训练阶段(Pre-Training)和微调(Fune-Tuning)阶段;
- 预训练阶段:
- 一般会在超大规模的语料上,采用无监督(unsupervised)或者弱监督(weak-supervised)的数据(比如网上公开文本,不用人工标类别)训练模型,让模型学语言规律(比如词的语义、句子逻辑);
- 经过超大规模语料的”洗礼”,预训练模型往往会是一个Super模型,一方面体现在它具备足够多的语言知识,一方面是因为它的参数规模很大;
- 微调阶段:拿预训练好的模型,针对具体任务,用少量标注数据“微调”模型,让它适配业务,输出任务结果(分类、问答答案等);
- 预训练阶段:
-
BERT在预训练阶段,靠两个核心任务,让模型学会理解语言,完成参数初始化:
-
MLM(Masked Language Model,掩码语言模型),类似完形填空+纠错;
-
NSP(Next Sentence Prediction,下一句预测);
-
-
预训练的价值
-
业务落地:预训练让模型先学通用语言知识,之后做“文本分类、问答、命名实体识别”等下游任务时,不用从零开始学语言基础,直接“微调”适配业务, 又快又好 (用少量标注数据就能训出效果,节省成本);
-
效果验证:BERT证明了——先在海量数据预训练,再微调做下游任务,能大幅提升任务效果(比如问答准确率、分类精度),成为NLP领域“预训练 + 微调”范式的标杆,后续很多模型(比如GPT、XLNet)也延续/优化了这种思路。
-
1.3.2 MLM(Masked Language Model,掩码语言模型)
-
MLM的核心设计目的:解决传统模型的“单向瓶颈”
-
传统模型的问题:
-
以前的语言模型(比如单向RNN、拼接式双向模型 ),要么只能从左到右(left-to-right)看文本(比如“猫抓老鼠”,单向模型看“猫”时,只能先结合左边空,再逐步看右边,无法同时利用左右文),要么简单拼接左右信息(把左→右和右→左的结果拼一起,即left-to-right + right-to-left,没真正融合双向语义);
-
这导致模型捕捉语义的能力有限;
-
-
BERT的解法:深度双向建模
- BERT提出 MLM任务,让模型在预训练阶段,**同时利用“左右上下文”**去预测被遮挡的词,真正学会“双向语义理解”。简单说:通过“遮词猜词”,逼模型理解“词在上下文中的含义”,让语义捕捉能力更强大;
-
-
具体实现方案:
- 从文本里随机挑15%的token(词/字),参与“遮词猜词”游戏(比如100个词的句子,选15个词做处理);
- 对选中的15%token,不是简单全换成[MASK],而是分三种情况:
- 80%→[MASK]:比如“我的狗很hairy” → “我的狗很[MASK]”。目的:逼模型用“双向上下文”猜词;
- 模型得结合“我的狗很__”的左右文(比如前面“狗”、后面可能的描述),推理出“hairy(毛茸茸)”,强化语义理解能力;
- 10%→随机词替换:比如“我的狗很hairy” → “我的狗很apple”。目的:防模型“偷懒”;
- 如果全用[MASK],模型可能记住“[MASK]位置该填啥”,而不是真理解语义;
- 随机换词后,模型得区分“哪些是真遮的词、哪些是干扰”,强迫它深入学语义规则(比如“狗很apple”明显不合理,模型得判断这种错误,再结合上下文修正);
- 10%→保持原词不变:比如“我的狗很hairy” → “我的狗很hairy”(看似没遮,实际参与任务)。目的:模拟真实文本的不确定性;
- 因为微调/下游任务里,不会有[MASK],保持原词能让模型习惯“正常文本”,同时增加训练难度(模型得判断“哪些词可能被遮、哪些不用管”),让语义学习更鲁棒;
- 80%→[MASK]:比如“我的狗很hairy” → “我的狗很[MASK]”。目的:逼模型用“双向上下文”猜词;
-
补充说明:
- MLM本质是通过**“遮词→猜词”的任务**,设计对应的损失函数(模型猜的结果和真实词的差距),反向传播更新参数;
- 想让模型学“双向语义”,就设计“必须用上下文猜词”的任务;想让模型学“语法/语义规则”,就用“随机替换词”制造错误,让模型学会纠错;
- 总结成一句话:你想让模型有什么能力,就设计对应的“任务(损失函数)”,通过“猜词错误→损失→反向传播→参数更新”,逼着模型学会这些能力;
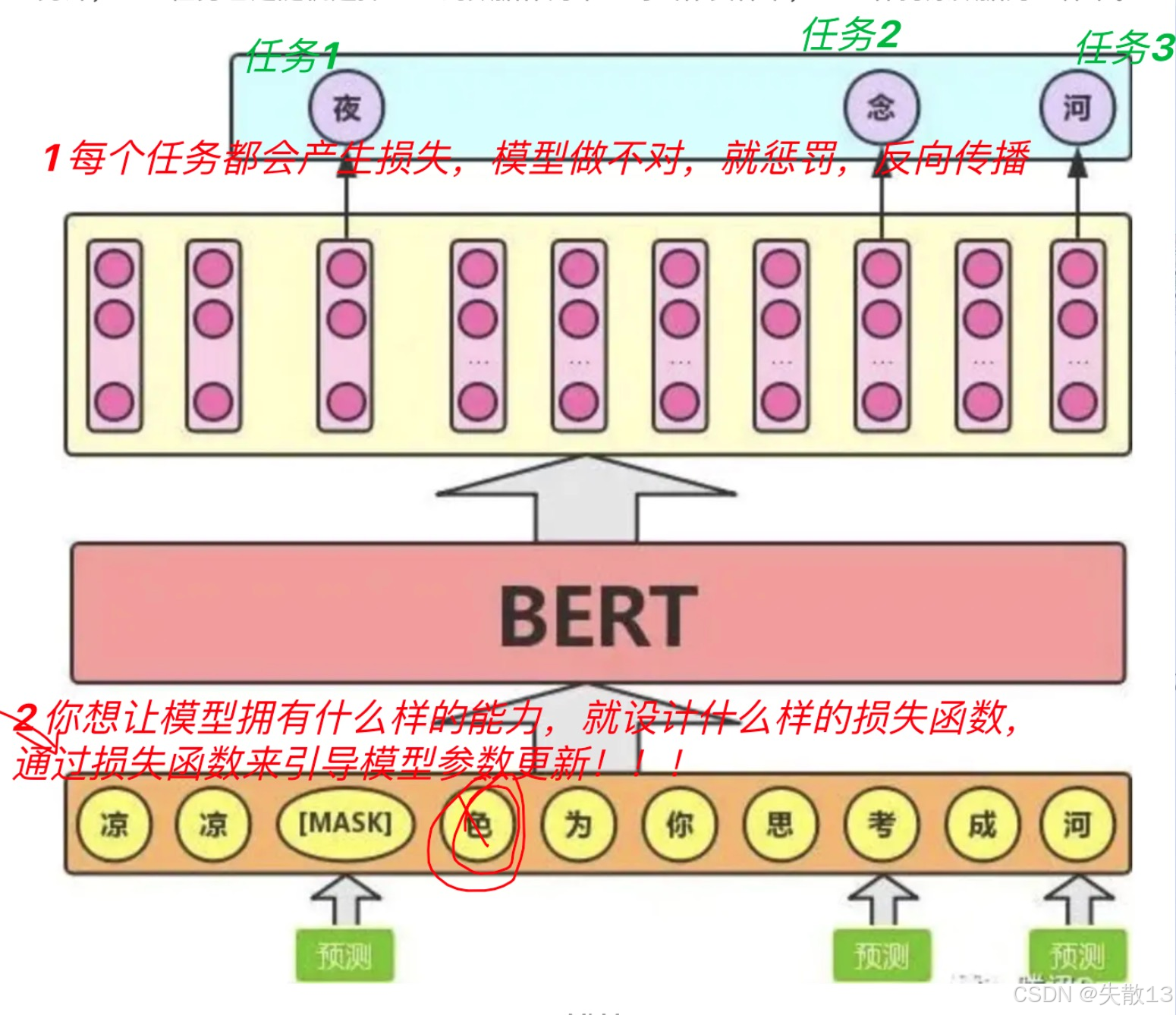
-
MLM的“15%”和“三种策略”的深层意义:
-
15%的比例:不是遮太多(破坏文本结构),也不是遮太少(学不到东西)。15%的token参与遮词,平衡“学习难度”和“文本真实性”,让模型既学到语义,又不脱离真实语言环境;
-
三种策略的协同:
- 80%的[MASK]保证“双向语义学习”的核心目标;
- 10%随机替换+10%保持原词,模拟真实场景的噪声和不确定性,让模型学会“在复杂、不确定的文本里,依然能抓准语义”,避免模型“过拟合到[MASK]任务”,保证微调后能适配下游任务(比如分类、问答,这些任务里没有[MASK])。
-
1.3.3 NSP(Next Sentence Prediction,下一句预测)
-
NSP的核心目标:让模型理解“句子间关系”
-
NLP里很多任务得理解两个句子的逻辑关系。比如:
-
问答任务(QA):得知道“问题句”和“上下文句”的关联(比如问题问“谁救了公主”,上下文里“骑士打败恶龙,救了公主” ,得识别这种对应);
-
自然语言推理(NLI):判断“句子A能否推出句子B”(比如A“鸟会飞”,B“麻雀能飞” → 蕴含关系);
-
-
所以,BERT设计NSP任务,专门训练模型理解**“句子对的关系”** ,让模型学会判断“句子B是不是句子A的真实下一句”;
-
-
具体实现方案:
-
数据构造:句子对(A, B)。选句子A(随便从语料里挑 ),然后构造“句子B”的两种情况:
- 正样本(50%):B是语料中真正紧跟A的下一句(标记为IsNext),比如A“今天天气好”,B“适合出去散步”(真实连续);
- 负样本(50%):B是从语料里随机选的无关句子(标记为NotNext),比如A“今天天气好”,B“猫喜欢吃鱼”(无关联);
-
任务逻辑:预测“句子B是否是A的下一句”
-
模型输入“句子A + [SEP] + 句子B”,然后输出一个二分类结果(IsNext/NotNext);
-
通过这种训练,让模型学会捕捉句子间的逻辑关联(比如语义承接、话题延续);
-
-
-
和MLM的关系:互补训练语言能力
-
MLM:聚焦单句内的语义理解(通过遮词,学词在上下文中的含义);
-
NSP:聚焦句子间的逻辑关系(通过句子对,学句子间的关联);
-
两者配合,让BERT在预训练阶段,既懂“词的语义”,又懂“句子的逻辑”,为下游NLP任务(分类、问答、推理等)打下坚实基础。
-
1.4 GLUE
-
General Language Understanding Evaluation(通用语言理解评估)是由纽约大学、华盛顿大学等机构牵头打造的多任务自然语言理解基准与分析平台,专门用来测试模型在“自然语言理解(NLU)”任务上的能力;
-
作用:
- NLP有很多细分任务(比如文本分类、语义推理),GLUE把这些任务整合起来,像一套“综合试卷”,测试模型的通用语言理解能力 。模型在GLUE上的表现,直接反映它“懂不懂语言、能不能解决实际NLP问题”;
-
特点:
-
所有数据是英文(聚焦英语NLP任务);
-
截至2020年1月,包含11个子任务数据集,成为衡量NLP模型水平的“行业标准”;
-
任务覆盖广:GLUE包含 9大典型NLU任务(CoLA、SST - 2、MRPC、STS - B、QQP、MNLI、QNLI、RTE、WNLI),覆盖:
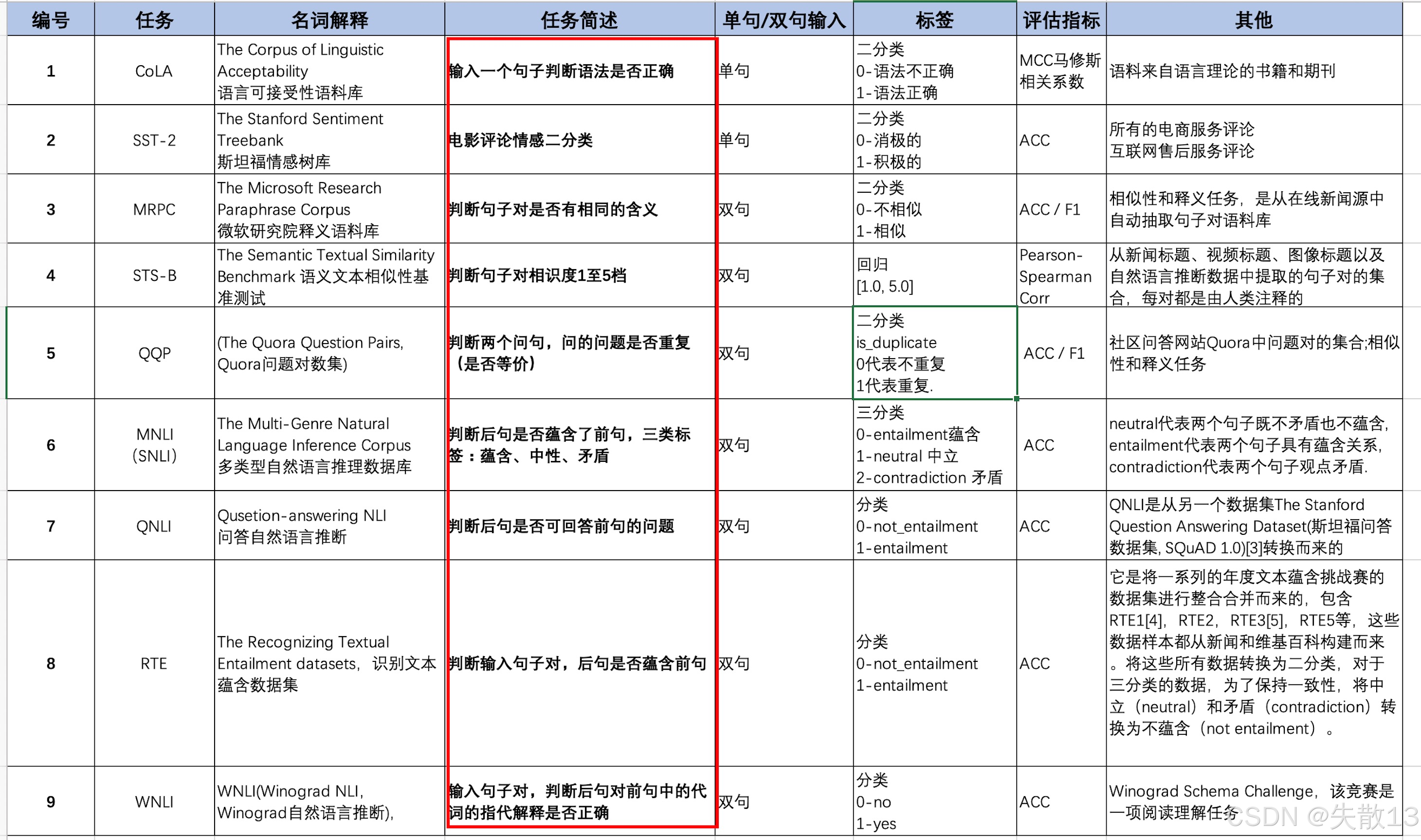
-
-
BERT、XLNet、RoBERTa 这些知名NLP模型,都会在GLUE基准上做测试,把预测结果上传到GLUE官网,由平台给出“模型能力评分”。比如BERT当年在GLUE上刷出高准确率,证明了它的强大语义理解能力。
-
行业标杆意义:模型在GLUE的表现,是NLP领域论文、技术方案的重要参考。如果一个新模型在GLUE上超过之前的SOTA(当前最优),往往意味着NLP技术有新突破。
1.5 CLUE
- CLUE基准数据集,它是服务中文语言理解相关任务与产业的基准数据集,作为通用语言模型测评补充,通过整理发布中文任务和标准化测评完善基础设施,促进中文NLP发展;
- 官方:CLUE中文语言理解基准测评;
- GitHub:GitHub - CLUEbenchmark/CLUE: 中文语言理解测评基准 Chinese Language Understanding Evaluation Benchmark: datasets, baselines, pre-trained models, corpus and leaderboard。
2 ELMO
2.1 简介
- ELMO,全称Embeddings from Language Models,2018年3月由华盛顿大学提出,源于论文《Deep Contextualized Word Representations》 ,是一种预训练模型;
- 提出动机:研究人员认为好的预训练语言模型应包含丰富语法、语义信息,且能对多义词建模(支持动态词向量,而非静态)。传统词向量(如word2vec、GloVe )是上下文无关的固定向量,无法体现多义性(如“apple”在“苹果公司”和“水果苹果”中不同含义),所以要训练上下文相关的预训练模型,即ELMo;
- 模型意义:是第一个支持动态词向量的模型,在6个NLP任务中表现提升,在NLP技术发展史上有重要意义,为后续模型(如BERT)探索动态语义表示奠定基础。简单说,ELMo解决了传统词向量“一词一义、静态不变”的问题,让词向量能随上下文动态变化,更好捕捉语义,推动NLP发展。
2.2 模型架构
2.2.1 架构总览
-
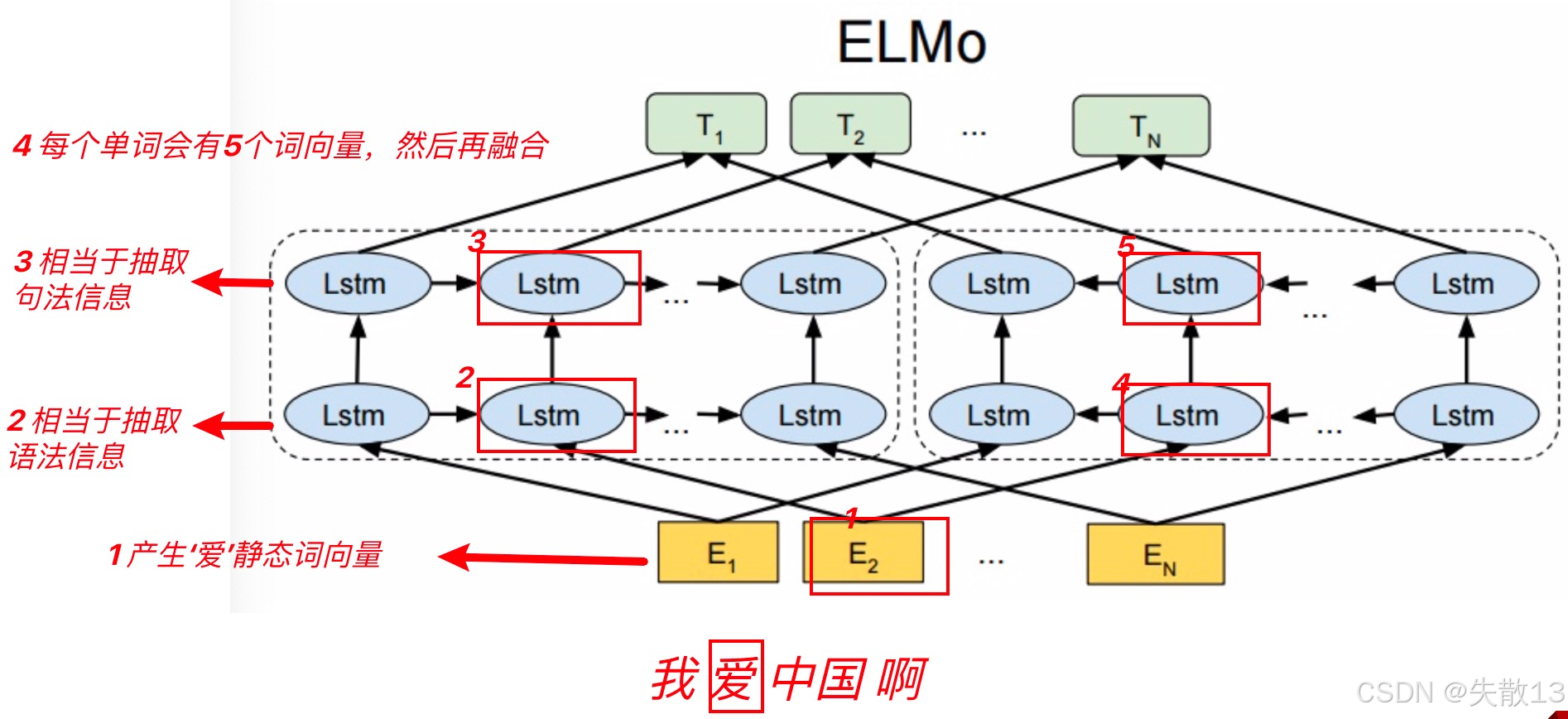
从架构图中可以看到,宏观上ELMO分三个主要模块:
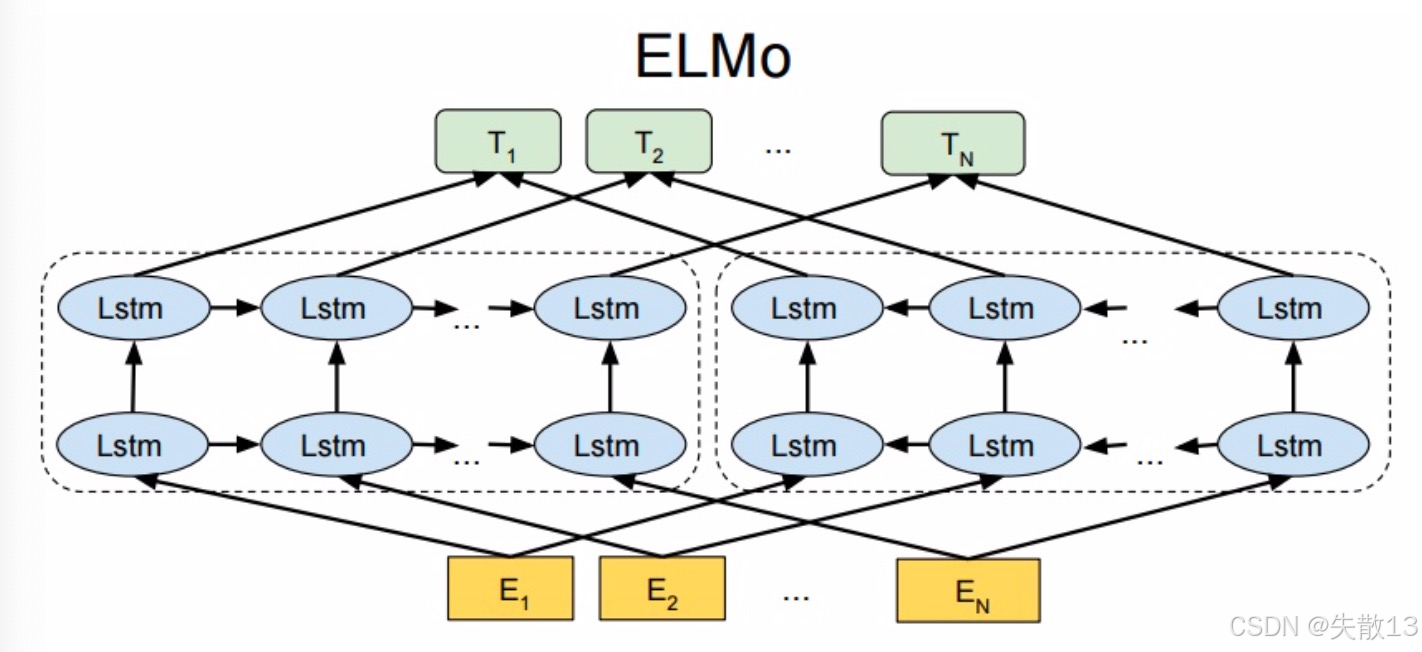
- 最底层黄色标记的Embedding模块
- 中间层蓝色标记的两部分双层LSTM模块
- 最上层绿色标记的词向量表征模块
2.2.2 Embedding 模块
-
Embedding 模块是ELMo模型的“底层输入层”,负责把文本里的字符/词,转化为静态词嵌入向量,给上层LSTM网络提供初始输入;
-
用**CNN(卷积神经网络)**对“字符级”输入做编码。比如把单词拆成字母/字符,用CNN提取字符级特征,再整合得到词的嵌入表示;
-
最终得到静态的词嵌入向量(每个词对应一个固定向量),作为后续LSTM网络的底层输入,和传统词向量(如word2vec)类似,但通过CNN字符编码,能更细粒度捕捉词的拼写、结构信息。
-
2.2.3 双层双向LSTM模块
-
ELMO 的双层双向 LSTM 模块
- 作用是结合底层静态词向量,融入上下文信息,生成动态词向量;
- 例:静态词向量(比如“爱”的基础表示),在上下文(比如“我爱中国啊” )里,会因前后文不同,产生动态变化的语义(比如“爱”在“我爱家人”和“爱打游戏”里,语义侧重不同)。这个模块,就是让模型学会“用上下文调整词向量”,让语义更精准;
-
词向量的多层表示公式:每个 token(词 ),经过 L 层双向 LSTM(这里 L=2,双层),会输出 $ 2L + 1 $ 个表示向量;
Rk={xkLM,h⃗k,jLM,h←k,jLM∣j=1,⋯,L}={hk,jLM∣j=0,⋯,L}R_k = \left\{ x_k^{LM},\, \vec{h}_{k,j}^{LM},\, \overleftarrow{h}_{k,j}^{LM} \mid j = 1,\cdots,L \right\} = \left\{ h_{k,j}^{LM} \mid j = 0,\cdots,L \right\} Rk={xkLM,hk,jLM,hk,jLM∣j=1,⋯,L}={hk,jLM∣j=0,⋯,L}- RkR_kRk:词向量集合,比如一个单词有五个词向量;
- kkk:表示第几个单词,第几个时间步;
- LLL:表示一共有几个层;
- jjj:表示当前是第几层;
- $ x_k^{LM} $:底层静态词向量(来自 Embedding 模块);
- $ \vec{h}_{k,j}^{LM} $:第 j 层前向 LSTM 的输出(从左到右看文本,捕捉前文对当前词的影响);
- $ \overleftarrow{h}_{k,j}^{LM} $:第 j 层反向 LSTM 的输出(从右到左看文本,捕捉后文对当前词的影响);
- 这些向量融合后,得到 $ h_{k,j}^{LM} $,作为动态词向量的多层表示;
-
以“我爱中国啊”为例,看“爱”的动态词向量怎么生成:
-
底层静态向量:先从 Embedding 模块,得到“爱”的静态词向量(基础语义,比如“爱”的通用表示);
-
双向 LSTM 处理:
-
模型有双层双向 LSTM(每层分“前向(从左到右)”和“反向(从右到左)”);
-
对于“爱”:
- 前向 LSTM(左→右):会根据“我”的前文,生成前向语义(比如“爱”和“我”的关联);
- 反向 LSTM(右→左):会根据“中国啊”的后文,生成反向语义(比如“爱”和“中国”的关联);
- 双层结构:第一层 LSTM 处理语法信息,第二层 LSTM 处理句法信息;
-
-
动态词向量集合:经过双层双向 LSTM 后,“爱”会产出多个词向量,每个向量对应“不同层次、不同方向(前向/反向)”的语义。这些向量,共同组成“爱”在当前上下文里的动态语义表示(比如“爱国”的“爱”,和“爱人”的“爱”,动态向量会不同);
-
-
传统词向量(比如 word2vec),是“一词一向量”(静态),无法区分多义词。而 ELMo 的双层双向 LSTM 模块,通过以下方式解决问题:
- 双向捕捉:前向+反向 LSTM,让模型同时看“前文+后文”,更全面理解语义;
- 多层抽象:双层结构,第一层学基础关联(比如“爱”和相邻词的搭配 ),第二层学高层语义(比如“爱”在整个句子里的情感、主题);
- 动态输出:每个词最终产出“多个向量”,融合后成为动态词向量,让“爱”在“爱情”“爱国”“爱美食”里,语义表示不同,更贴合真实语言的多义性。
2.2.4 词向量表征模块
-
作用:
- ELMo 的前两个模块(Embedding、双层双向 LSTM),会产出多个词向量(比如“爱”在上下文中,会有静态向量、前向 LSTM 向量、反向 LSTM 向量,共 2L+12L + 12L+1 个,LLL 是 LSTM 层数);
- 但下游任务(比如分类、命名实体识别),需要一个词一个向量作为输入。所以,词向量表征模块的作用是:把多层、多方向的词向量,通过加权融合,变成一个最终的动态词向量 ,供下游任务使用;
-
融合逻辑:加权求和,让重要向量权重更高
-
基础操作:对于 2L+12L + 12L+1 个词向量(比如 L=2L=2L=2 时,是 5 个向量 ),每个向量乘以一个权重系数,然后相加,得到最终的词向量;
ELMoktask=E(Rk;Θtask)=γtask∑j=0Lsjtaskhk,jLMELMo_k^{task} = E(R_k ; \Theta^{task}) = \gamma^{task} \sum_{j=0}^{L} s_j^{task} h_{k,j}^{LM} ELMoktask=E(Rk;Θtask)=γtaskj=0∑Lsjtaskhk,jLM- $ ELMo_k^{task} $:第 kkk 个词,在某个下游任务(task)里的最终向量;
- $ R_k $:第 kkk 个词的多层向量集合(比如 5 个向量);
- $ s_j^{task} $:第 jjj 层向量的权重(不同层的重要性,模型会学习调整);
- $ \gamma^{task} $:全局缩放因子(可训练,让模型调整整体缩放);
-
**为什么要加权?**不同层的词向量,对下游任务的“贡献不同”;
-
比如:
- 底层向量(静态 Embedding):更偏向基础语义(比如“苹果”的字面含义);
- 高层向量(LSTM 上层输出):更偏向上下文动态语义(比如“苹果”在“苹果公司”里的含义);
-
通过学习权重 $ s_j^{task} $ ,模型能自动判断:对于当前任务(比如情感分类),哪一层的向量更重要,然后给它更高的权重,让融合后的向量更贴合任务需求;
-
-
-
例:
-
左向 LSTM 产出的向量,是 512 维特征;
-
右向 LSTM 产出的向量,是 512 维特征;
-
融合时,把两者加权相加,得到 1024 维的最终向量;
-
-
模块价值:让动态向量适配下游任务
-
灵活适配任务:不同下游任务(比如情感分析 vs 命名实体识别),对词向量的语义侧重需求不同。加权融合的方式,让模型能根据任务,自动调整“哪层向量更重要”,避免“一刀切”的融合方式;
-
保留多层语义:传统模型只能用“静态向量”或“单层向量”,而 ELMo 通过加权融合,把“静态基础语义+动态上下文语义”都保留下来,让下游任务能利用更丰富的信息。
-
2.3 预训练
2.3.1 简介
-
ELMo 的本质:动态调整词向量的语言模型
- 核心目标:解决“一词多义”,让词向量因上下文而变;
-
比如“苹果”在“吃苹果”(水果)和“苹果公司”(品牌)里,语义不同;
-
传统静态词向量(如 word2vec)无法区分,而 ELMo 要让“苹果”的向量,根据上下文动态调整,精准表达语义;
-
- 核心目标:解决“一词多义”,让词向量因上下文而变;
-
白话理解:先给每个词一个静态基础向量(比如用 CNN 对字符编码,得到“苹果”的通用表示),再用双向 LSTM 学习上下文怎么影响这个词,最终产出 动态向量(比如“水果苹果”的向量,和“品牌苹果”的向量不同);
-
ELMo 的训练分两步,让模型先学通用语言知识,再适配具体任务。
2.3.2 语言模型预训练(通用能力培养)
-
用大规模无监督文本(比如网上的新闻、小说),训练 ELMo 的双向 LSTM 网络,让模型学会根据上下文预测单词;
-
具体流程:
- 静态基础向量:用 CNN 对字符编码,给每个词一个静态向量(比如“爱”的基础表示);
- 双向 LSTM 学上下文:
- 第一层 LSTM:重点学语法信息(比如“爱”和前后词的搭配,“爱”+“祖国”是动宾结构);
- 第二层 LSTM:重点学句法信息(比如“爱”在句子里的情感、主题,“爱国”的“爱”是家国情怀);
- 预测任务:
- 选一个词(比如“爱”),把它的“上文”(比如“我”)和“下文”(比如“中国啊”)分别输入 LSTM,让模型预测“爱”这个词;
- 通过“预测对不对”的损失,反向更新 LSTM 的参数,让模型越来越懂“上下文怎么影响词”;
-
用极大似然估计构造损失函数:
损失函数=上文预测的损失+下文预测的损失损失函数 = 上文预测的损失 + 下文预测的损失 损失函数=上文预测的损失+下文预测的损失- 模型通过最小化损失,学习怎么用上下文预测单词,本质是训练 LSTM 的参数。
2.3.3 下游任务微调(适配具体业务)
-
预训练好的 ELMO,已经学会动态调整词向量的能力。但具体任务(比如情感分类、命名实体识别),需要更贴合业务的向量;
-
所以,拿预训练好的 ELMo,把下游任务的句子重新输入模型,重新提取动态向量,让这些向量适配任务需求(比如情感分类需要“情感词的向量更敏感”)。
2.4 ELMO模型的效果
-
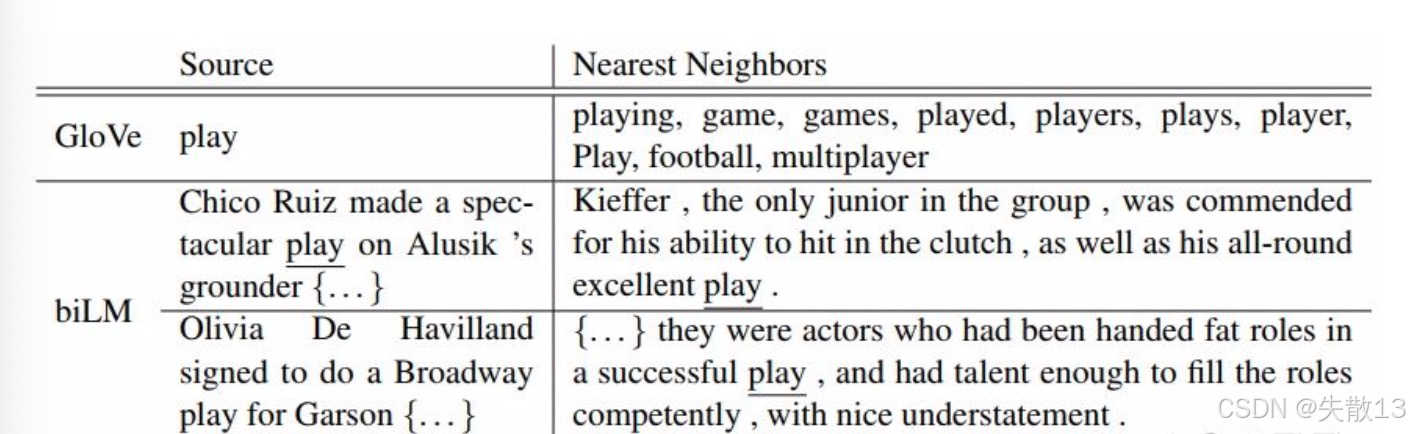
GloVe训练出来的Word Embedding(静态词向量) vs ELMo
-
GloVe的问题(传统静态词向量的通病)
-
在上图中:用GloVe找“play”的近义词,结果是“playing、game、games…”,全是体育/游戏领域的关联;
-
原因:
- GloVe的词向量是静态 的,一个词只有一个向量。“play”在GloVe里,向量更偏向“训练数据里占比高的含义”(比如体育领域的“play”出现多,向量就偏向这个语义);
- 所以,遇到“play”的其他含义(比如戏剧领域的“演出”,“play a role(扮演角色)”),GloVe无法区分,找近义词时只能输出“体育相关”,无法解决多义词问题;
-
-
ELMo的突破(动态向量解决多义词)
-
同样是“play”,在“演出”的语境里(比如“Olivia De Havilland signed to do a Broadway play” ),ELMo的动态向量,能精准找到**“演出、戏剧”相关的近义词**(而不是体育相关);
-
原因:ELMo的词向量是动态 的,会根据上下文调整。比如“Broadway play”的上下文,让ELMo意识到“play”是“戏剧演出”,所以向量偏向这个语义,找近义词时也更准确;
-
-
-
在
2.1 简介中提到的论文中验证,ELMo在 6个主流NLP任务里,性能都有提升,最高能涨25%。这说明:-
ELMo的动态词向量,确实能帮模型更准确理解语义,让下游任务效果更好;
-
对比传统模型(只用静态向量),ELMo的上下文感知能力,在NLP任务里有明显优势。
-
2.5 待改进点
- 很明显的缺点在于特征提取器的选择上,ELMo使用了双向双层LSTM,而不是现在横扫千军的 Transformer,在特征提取能力上肯定是要弱一些的;
- Transformer(基于自注意力机制 )比LSTM强在哪?
- 长距离依赖:LSTM处理长文本时,容易“遗忘”早期信息(比如长篇小说里,开头和结尾的关联,LSTM很难捕捉);而Transformer的自注意力,能直接关注任意位置的词,轻松抓长距离依赖;
- 并行计算:LSTM是“串行”计算(必须按顺序处理每个词),速度慢;Transformer的自注意力是“并行”的,训练和推理效率更高;
- 特征提取能力:Transformer的多头自注意力,能从“多维度、多视角”提取词的特征(比如同时关注“同义词、反义词、搭配词”),比LSTM的“单向串行”提取更全面、更深入;
- Transformer(基于自注意力机制 )比LSTM强在哪?
- ELMo选用双向拼接的方式进行特征融合(把“前向LSTM的输出”和“反向LSTM的输出”拼在一起),这种方法肯定不如BERT一体化的双向提取特征好;
- BERT的“一体化双向”(用Transformer的自注意力,同时看上下文),是 真正的双向融合 ——模型在提取特征时,就已经同时考虑“前文+后文”,不需要分开拼接;
- 而ELMo的“双向拼接”,更像是“先分别学前文、后文的特征,再硬凑在一起”,融合得不够自然、不够深入。相比之下,BERT的一体化双向,能让模型更精准、更高效地捕捉“词在上下文中的语义”,特征质量更高。
3 GTP
3.1 简介
- 由OpenAI公司提出,最初源于论文《Improving Language Understanding by Generative Pre - Training》 ,后续又在《Language Models are Unsupervised Multitask Learners》中推出GPT - 2;
- GPT和GPT - 2结构差别不大,主要是GPT - 2用了更大规模数据集训练,性能进一步提升;
- GTP VS BERT
- OpenAI GPT模型(2018年上半年)是在Google BERT模型(2018年下半年)之前提出的;
- 训练方式差异:
- GPT:采用传统语言模型思路,基于“单词的上文”预测下一个单词(单向语言模型,类似人“顺着读文本,根据前面内容猜后面”);
- BERT:采用双向上下文,同时用“上文 + 下文”预测单词(类似人“结合前后文理解语义”);
- 能力侧重不同:
- GPT:因训练方式是“顺着预测”,更擅长自然语言生成(NLG) ,比如写文章、续写故事、生成对话(需要“从前往后生成文本”的任务);
- BERT:因双向理解语义,更擅长自然语言理解(NLU) ,比如文本分类、问答、命名实体识别(需要“理解语义、分析文本”的任务)。
3.2 模型架构
3.2.1 架构总览
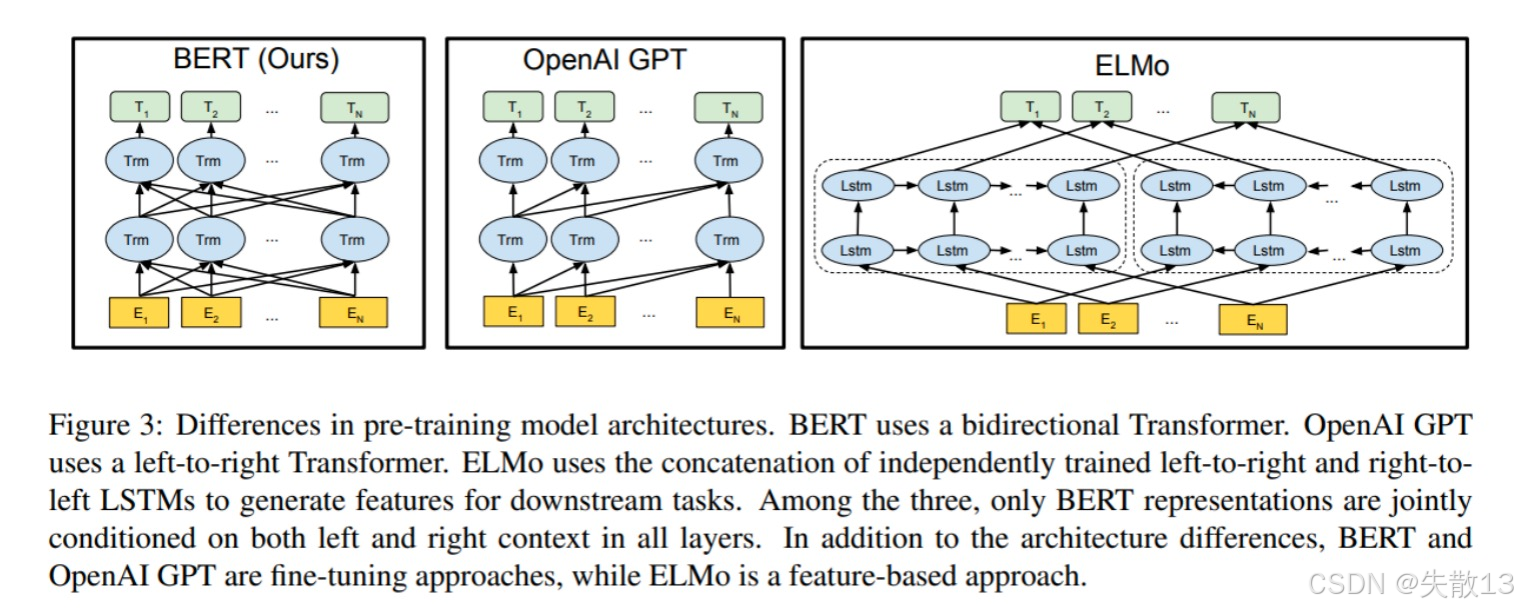
-
GPT采用的是单向Transformer架构
- 比如:例如给定一个句子
[u1, u2, ..., un],GPT在预测单词ui的时候只会利用[u1, u2, ..., u(i-1)]的信息; - 而BERT会同时利用上下文的信息
[u1, u2, ..., u(i-1), u(i+1), ..., un];
- 比如:例如给定一个句子
-
GPT 和 BERT 分别利用了 Transformer 架构的不同部分:
-
BERT:
- 用Transformer的 Encoder(编码器),双向注意力(可同时看“上文+下文”),所以擅长理解语义(NLU任务,比如分类、问答);
- 比如处理“苹果”,BERT能同时看“上文(吃)”和“下文(甜)”,理解“苹果是水果,能吃且甜”,适合做“理解语义”的任务(比如“苹果是什么?”的问答);
-
GPT:
- 用Transformer的 Decoder(解码器),单向注意力(只能看“上文”,不能看“下文”),所以擅长生成文本(NLG任务,比如续写、对话);
- 处理“苹果”时,只能看“上文”(比如“我买了”),然后生成“下文”(比如“苹果,打算做沙拉”),适合做“生成文本”的任务(比如续写句子、写故事);
-
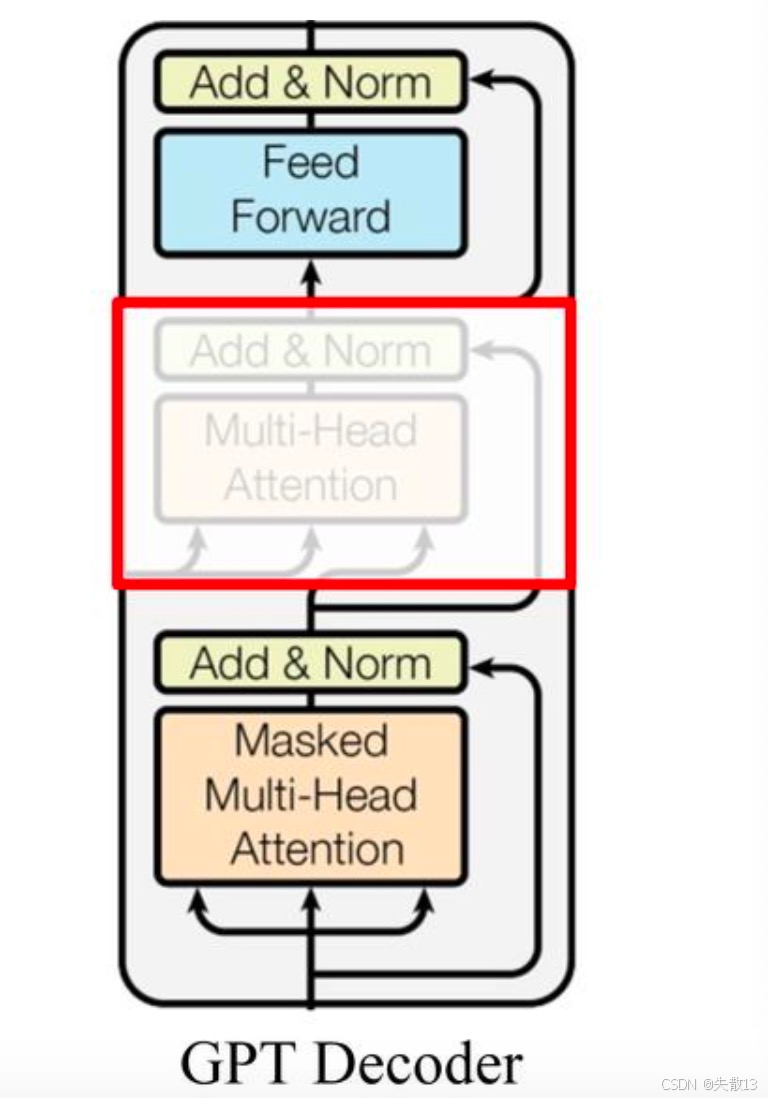
3.2.2 GPT的Decoder架构
-
原始Transformer Decoder:有多层,每层包含 Masked Self - Attention(掩码自注意力)、Encoder - Decoder Attention(编码-解码注意力)、前馈网络;
-
GPT的简化:GPT去掉了 Encoder - Decoder Attention 层(因为不需要编码输入),只保留 Masked Self - Attention + 前馈网络 ,还把Block数量从6层改到12层,让模型更专注于从自身上文生成下文;
-
Masked Self - Attention(掩码自注意力):
-
作用:强制模型只能看上文,不能看下文。比如生成“我买了苹果,打算____”时,模型在预测“打算”后面的词,只能用“我买了苹果,打算”的上文,看不到下文(比如“做沙拉”),逼着模型“根据上文推理,生成合理的下文”;
-
对比BERT的Self - Attention:BERT的Self - Attention是双向的(能看上文+下文),所以能理解语义;GPT的Masked Self - Attention是单向的(只能看上文 ),所以能生成文本;
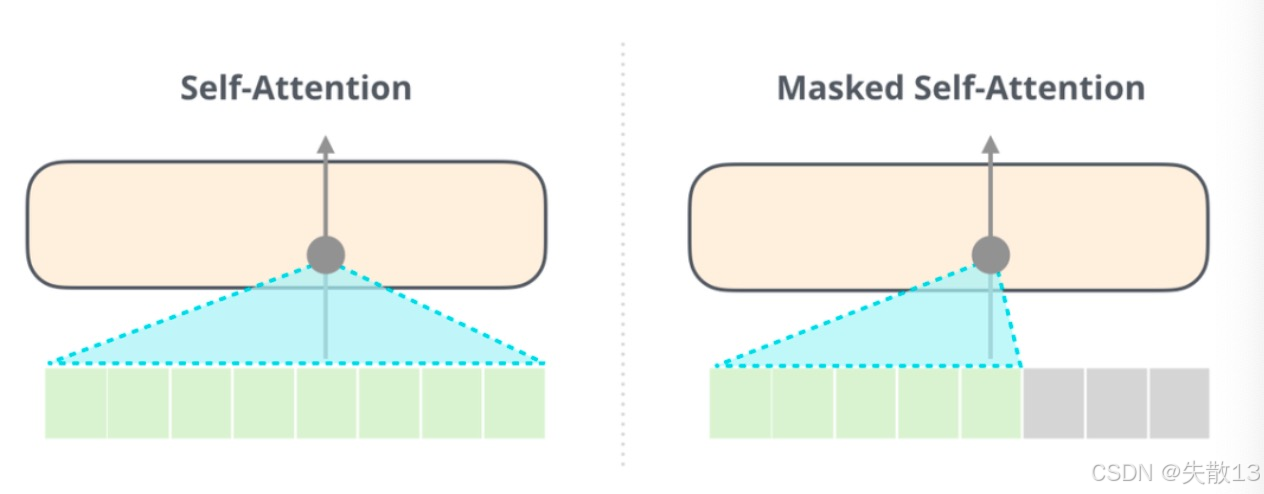
-
-
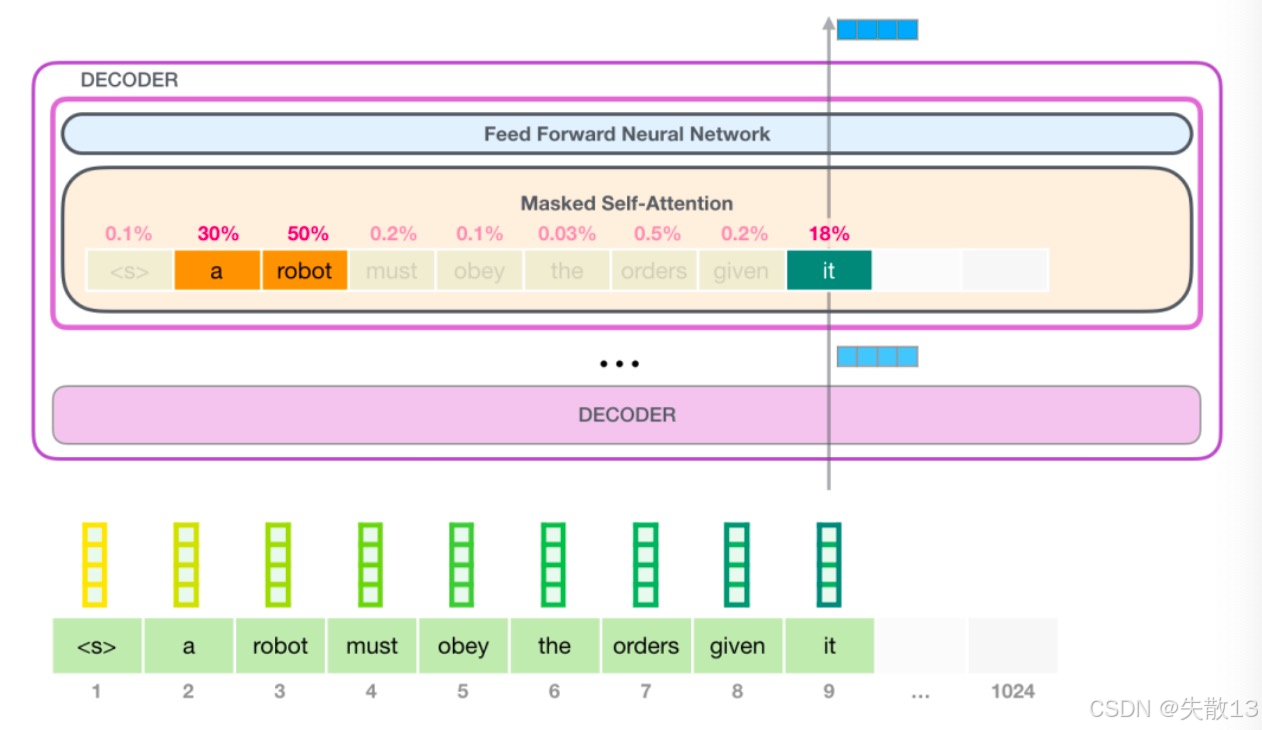
例:GPT怎么生成
robot must obey orders?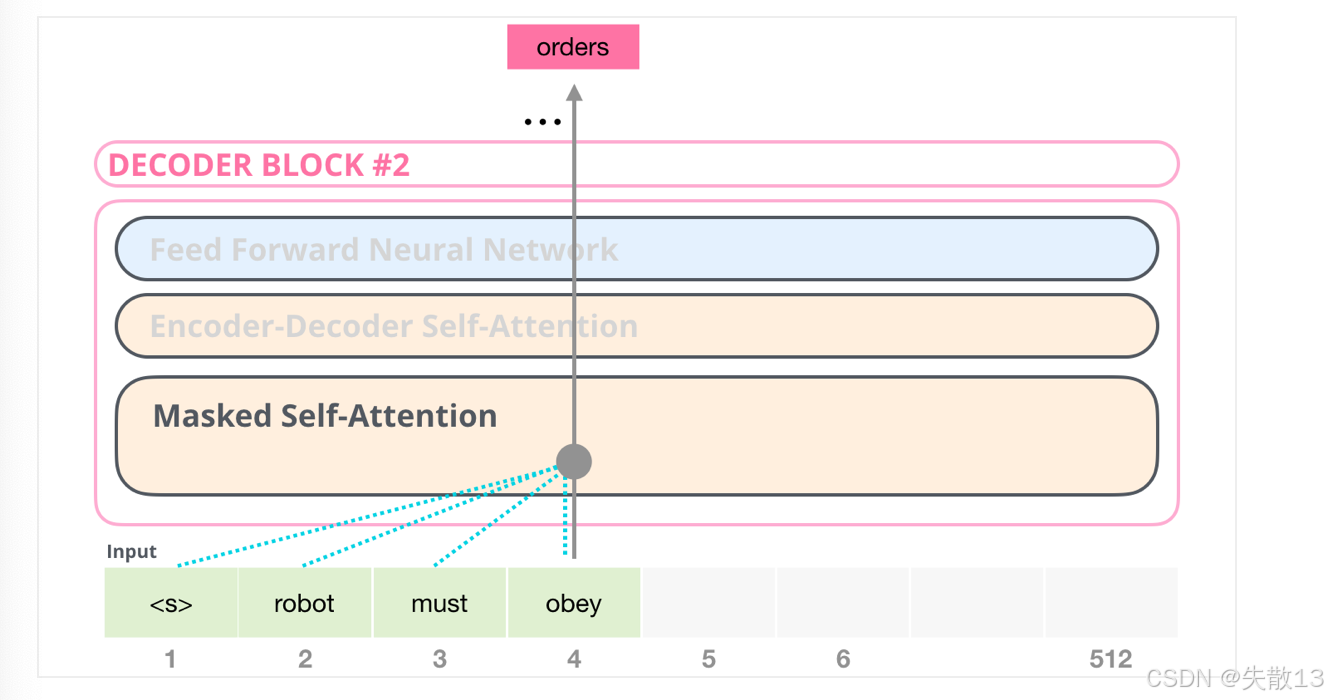
-
输入是
<s> robot must obey,模型要生成orders; -
Masked Self - Attention的作用:在生成
orders时,模型只能看上文(<s> robot must obey),看不到orders本身和后面的词。通过这种“掩码限制”,模型学会“根据上文推理,预测下一个词”,最终生成orders,让句子变成<s> robot must obey orders。
-
3.3 GTP的自回归生成文本
-
自回归生成的本质:一步一步,依赖上文。GPT生成文本,是每一步只看之前生成的词,生成下一个词。下面以一个例子展开讲解:
-
阶段1:输入
<s>,生成第一个词The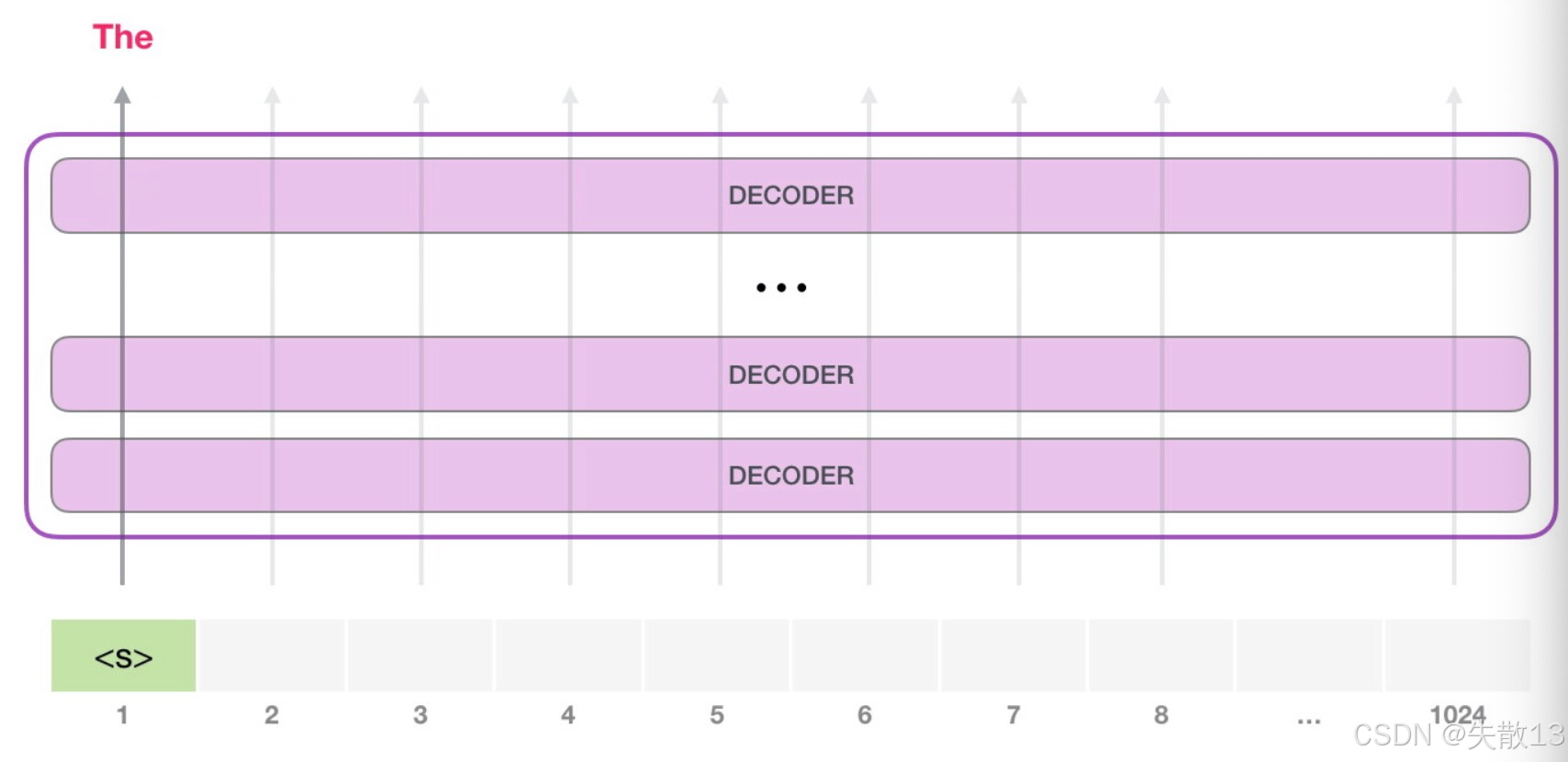
-
初始输入:给GPT一个起始token(比如
<s>,表示文本开始); -
生成
The:GPT的Decoder模块,会基于<s>的输入,生成第一个词The; -
此时,只有
<s>→The的路径是活跃的——模型只根据上文(<s>)生成下文(The) ,符合自回归,依赖上文的逻辑;
-
-
阶段2:输入
The,生成第二个词thing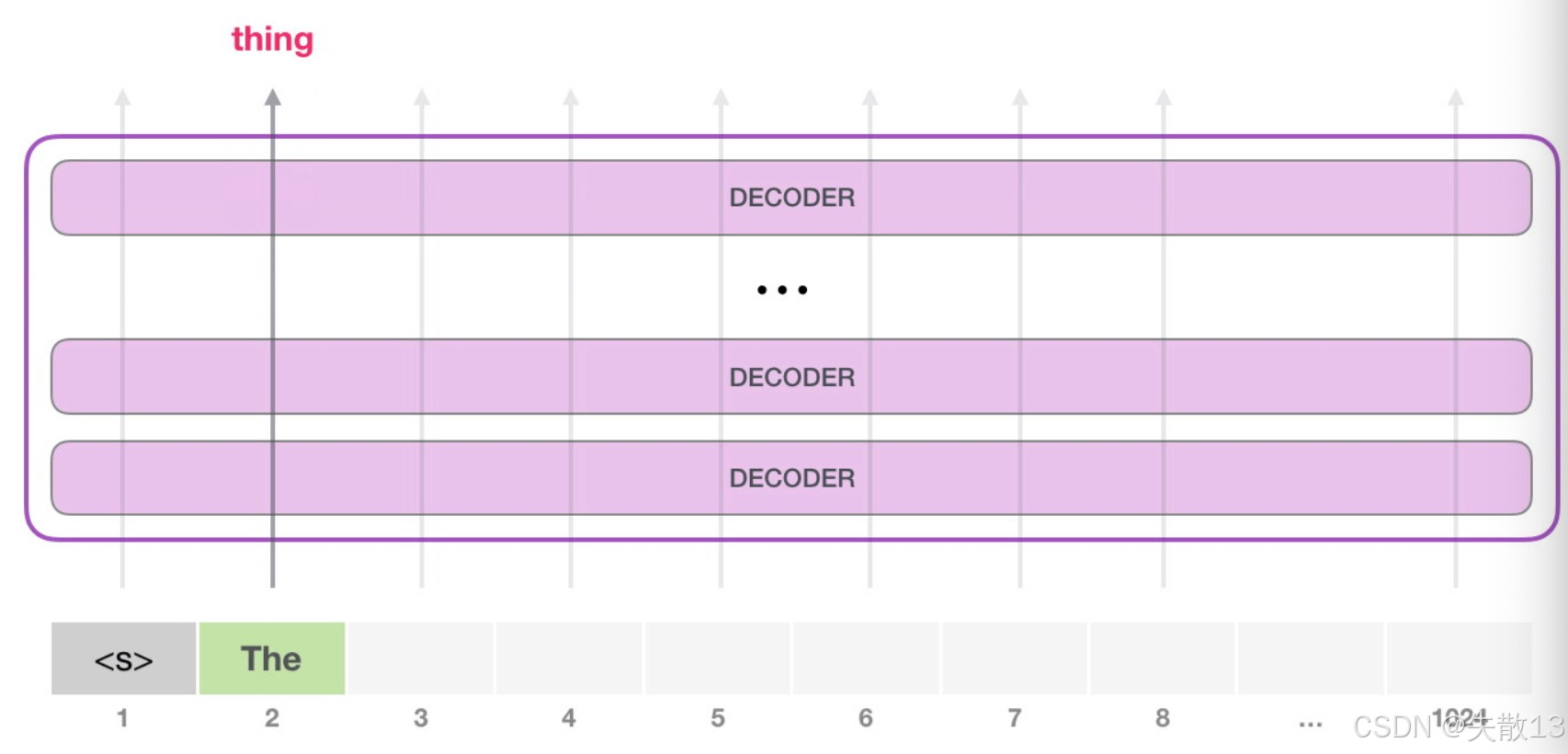
-
新的输入:现在,输入变成
<s> The(上一步生成的The,成为新的上文); -
生成
thing:GPT的每一层Decoder,会保留对第一个词(The)的理解(比如The是冠词,修饰名词),然后基于<s> The的上文,生成第二个词thing; -
关键:
- 此时,只有
<s> The→thing的路径活跃 ,模型不会回头改第一个词,而是顺着上文继续生成; - 这就是“自回归”的核心:生成下一个词时,只依赖之前所有词,不修改历史 ,保证文本从左到右,逐步生成;
- 此时,只有
-
3.4 GPT 工作过程梳理
-
GPT生成文本,分输入前处理→模型内计算→输出后处理 三步,每一步都让“文本→数值→预测结果→文本”循环起来,最终生成连续内容;
-
阶段1:数据送给GPT前(文本→数值张量)
-
目标:把人类能读的“文本”,变成模型能算的“数值张量”;
-
过程:
-
文本转数值:用One-Hot编码,给每个词一个唯一的数值表示(比如
the→[0,0,1,0…]); -
加位置编码:因为模型需要知道词的顺序(比如“我爱你”和“你爱我”不同),所以给每个词的数值,加上位置编码(表示这个词在句子里的位置);
-
变成张量:把“词的数值 + 位置编码”打包,变成模型能处理的“张量”(可以理解为“数值矩阵”);
-

-
-
阶段2:数据在GPT模型内(数值→预测下一个词)
-
模型结构:GPT的多层Decoder模块,每层包含 Masked Self - Attention(掩码自注意力)+ Feed Forward(前馈网络);
-
目的:利用掩码自注意力机制,让模型关注上文的词,预测下文;
-
过程:
-
对每个词,模型会计算它和上文所有词的关联权重(比如生成
thing时,关注The的权重)。下面是计算公式简化:
注意力权重=softmax(Q∗KT)∗V注意力权重 = softmax( Q*K^T ) * V 注意力权重=softmax(Q∗KT)∗V- Q、K、V是模型学习的参数,softmax让权重归一化,最终得到每个词该关注上文哪些词;
-
多层处理:数据要经过12个Decoder模块(层),每层都重复“算注意力权重→更新张量表示”的过程,让模型对上文的理解越来越精准;
-

-
-
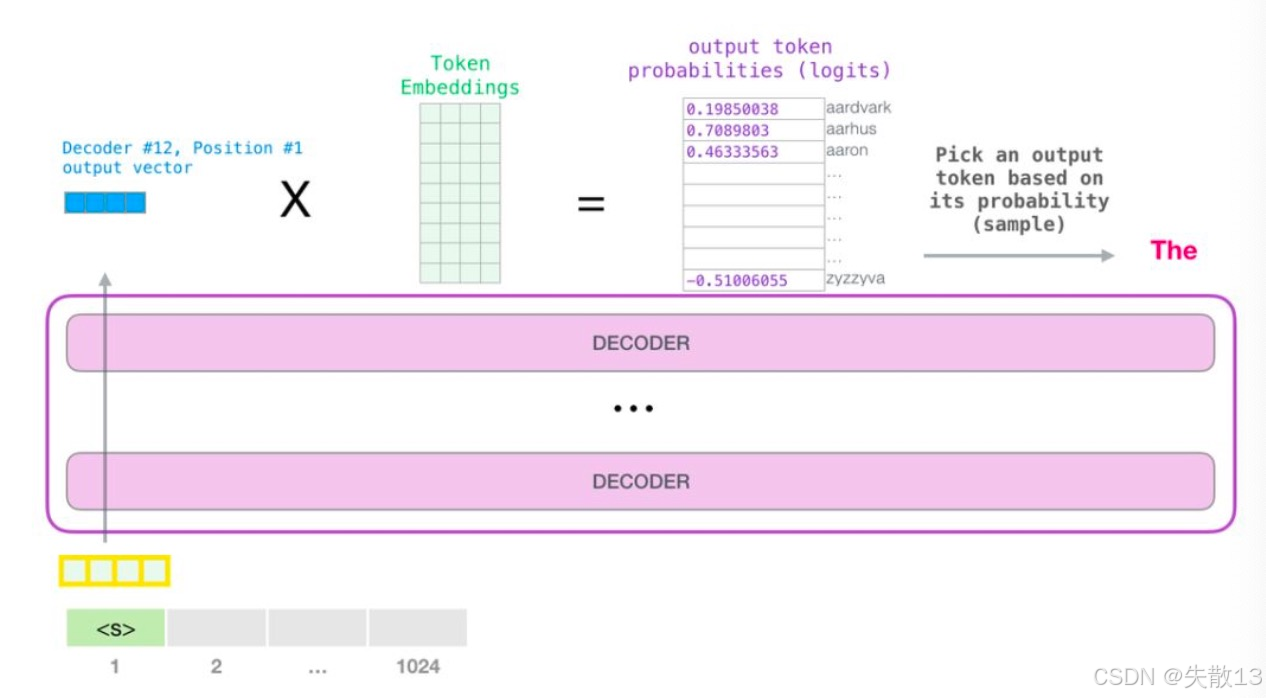
阶段3:GPT模型的输出(数值→预测的词)
-
目标:把模型计算的数值张量,变回人类能读的词;
-
过程:
-
张量运算:模型输出的张量,和“词向量矩阵”做运算,得到每个可能词的“概率分数”(比如
thing的概率是0.8,apple的概率是0.1); -
选词:从概率最高的若干词里(比如Top40),选一个作为预测的下一个词(比如选
thing); -
循环:把预测的词加入上文,重复阶段1→阶段2→阶段3,直到生成完整文本,或达到长度上限(比如1024个词);
-
-
-
阶段4:结束条件。当生成的文本长度达到模型上限(比如1024个词),或遇到“结束符(EOS)”,生成停止,输出最终文本。