浅谈快排的退化与优化
快速排序是使用最多的一种排序方式,正常情况下,快速排序的时间复杂度为O(n * log n),但是在某些特殊情况下,快速排序的时间复杂度会退化为O(n)。
1. 当待排序列中趋近于有序时
如果一个序列趋近于有序,而且在对该序列进行快排时,取序列中靠近开头或靠近结尾的数作为key值,那么快排进行递归时,就不能很好地对序列进行二分处理,从而使得时间复杂度退化为O(n ^ 2)。
对于这种情况,一般可以通过取key值方法的改进来进行优化。
最常见的key值可以取序列中间的一个数作为key值,或者说使用随机数rand()进行key值的随机选取,这都是可以的。
2.当待排序列中含有大量重复元素时
当包含大量重复元素时,在不优化key值的选取时,序列会向有序的方向趋近,因此存在时间复杂度的退化问题,但是,即便优化了key值的选取,时间复杂度不会退化,仍然保持O(n * log n),但实际排序过程中,由于大量重复元素的存在,因此会有大量针对该重复元素的操作,而这些操作并非全都必要的。
比如说对于这个序列9 8 7 5 5 5 5 5 4 3 2 1,我们采用二数取中法进行key值的选取,选取到5后,将序列划分为两部分:一部分小于等于5,另一部分大于等于5。
但由于5是大量重复的,因此在后续的快排中,可以将重复元素5所在的序列去掉,而只对小于5的序列和大于5的序列进行快排。
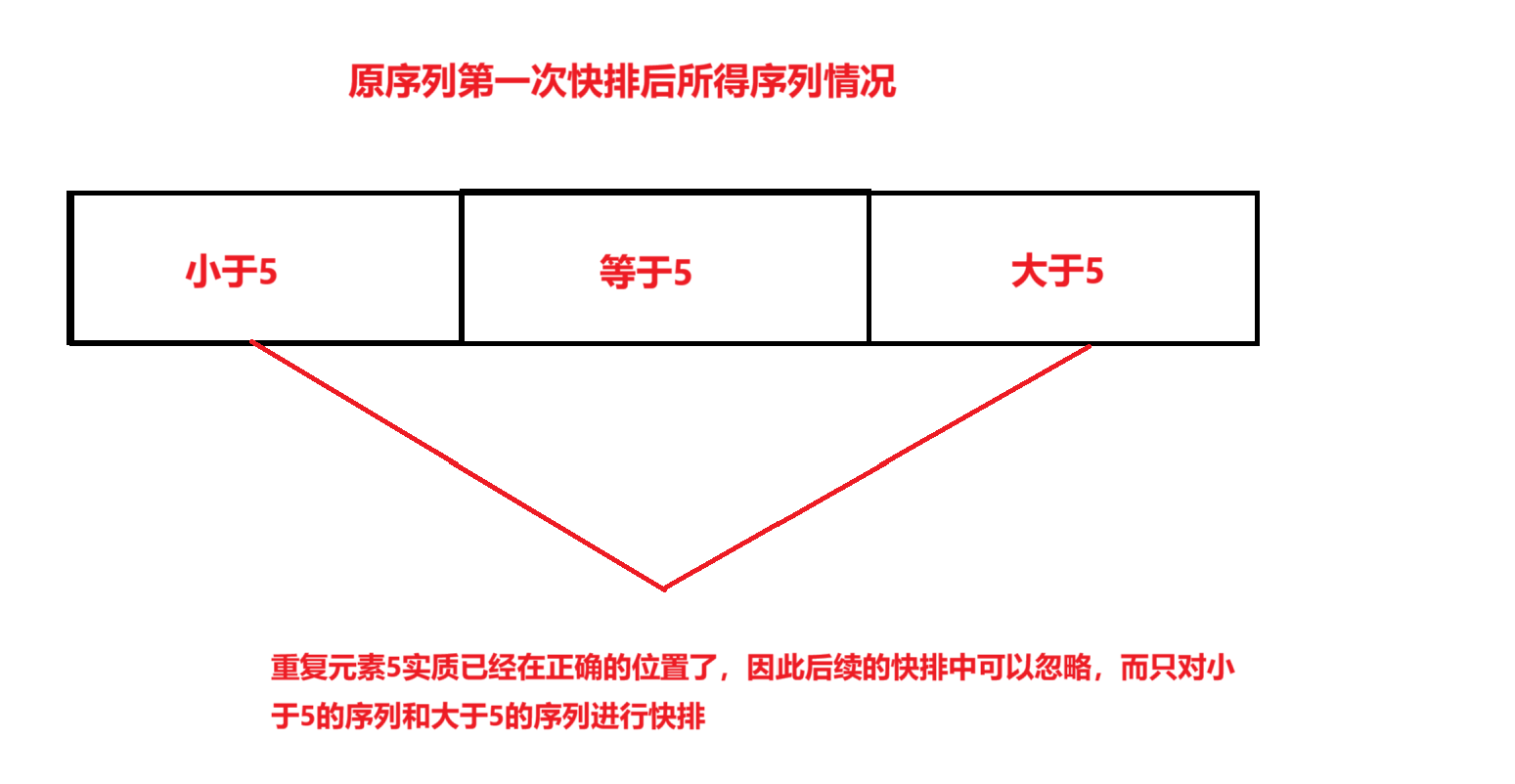
那么我们该如何实现呢?
接下来我们就来介绍一种快排方式,叫做三向切分快排,这种快排特别适用于当序列中重复元素很多时的情况,能大大提高排序效率。
三向切分快排,是采用三个指针实现的。这种快排方式,本质就是借用这三个指针将序列分为三部分:小于key值、等于key值、大于key值。
将序列划分为这样的三部分后,接下来快排的递归就可以只针对小于key值和大于key值的部分进行递归了。
以下是三向切分快排的代码示例,在该三向切分快排中,我们采用随机数法来进行key值的选取。
class solution
{
public:void quick_sort(vector<int>& v,int l,int r){if(l >= r)return;int i = l,j = r;//l,r均为有效下标int cur = l;//用于从起始处开始遍历的指针int key = v[(rand() % (r - l + 1) + l)];while(cur <= j){if(v[cur] == key)cur++;else if(v[cur] < key)swap(v[cur++],v[i++]);elseswap(v[cur],v[j--]);} quick_sort(v,l,i - 1);quick_sort(v,j + 1,r); }
};
上述代码中有几点需要说明:
- 小于key值的序列为
[l,i - 1],等于key值的序列为[i,j],大于key值的序列为[j + 1,r] - 为什么
v[cur] == key的时候不需要做处理呢?因为实际上,我们只要把小于key的数全部交换到开头,大于key的数全部交换到结尾,等于key的数自然而然就在中间了。 - 为什么处理
v[cur] > key的情况时,cur指针不移动?因为可能交换过来一个小于key值的数或大于key值的数,因此需要再次进行判断。那为什么v[cur] < key时,又需要移动呢?因为这种情况下,交换过来的数一定是等于key值的(想明白这点很重要),所以不需要额外判断,而直接cur++。