2025CVPR最佳论文系列
2025 年 6 月 13 日——IEEE 计算机学会 (CS) 和计算机视觉基金会 (CVF) 公布了2025 年计算机视觉与模式识别 (CVPR) 大会 的获奖论文,以及今年 AI Art 奖项的获奖者。这两个奖项旨在表彰计算机视觉领域的杰出成就。
经 CVPR 奖项评选委员会一致决定,以下论文被选为今年的获奖论文:
CVPR 2025 最佳论文
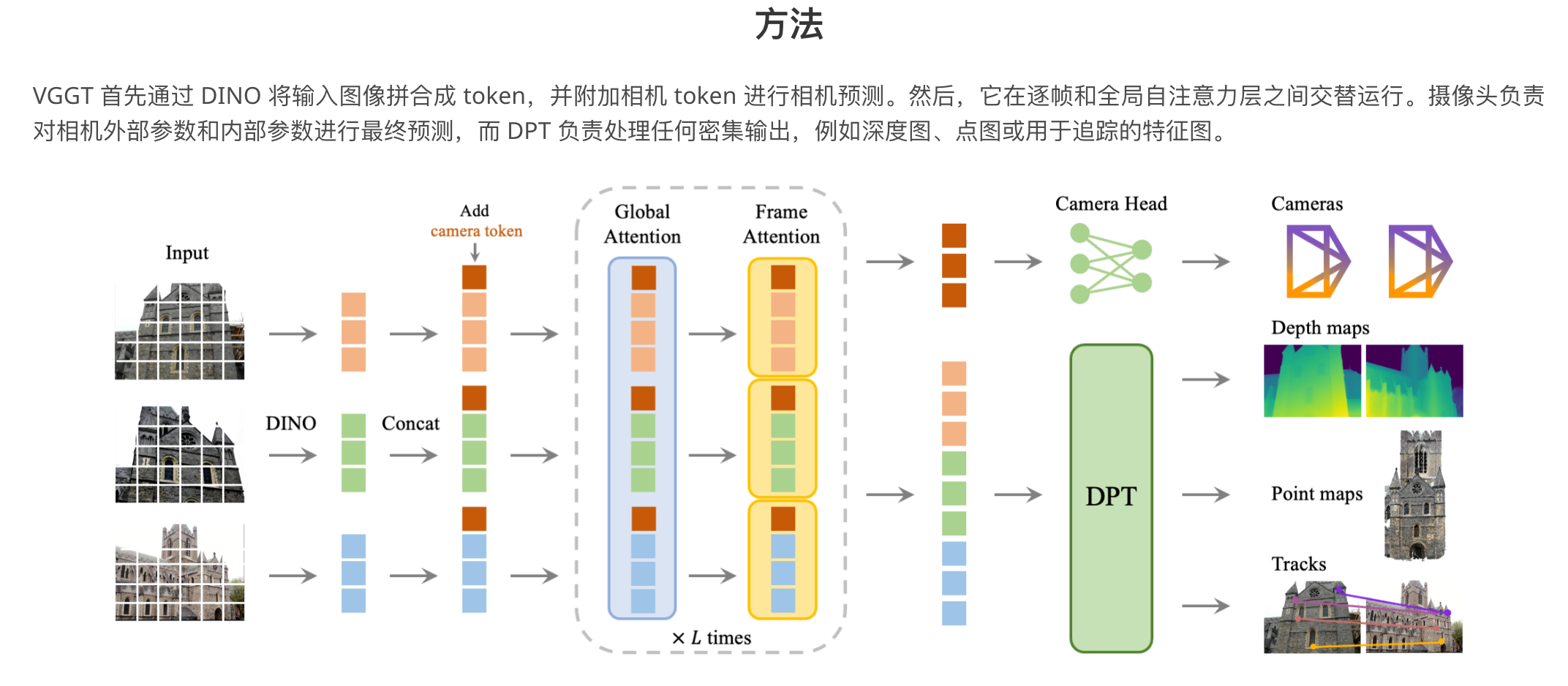
- VGGT: Visual Geometry Grounded Transformer
作者:王建元、陈明浩、Nikita Karaev、Andrea Vedaldi、Christian Rupprecht、David Novotny
简介: 牛津大学和 Meta AI 的工程师们提出了基于视觉几何的 Transformer (VGGT),这是一种前馈神经网络,能够直接估算数百个输入视图的所有关键 3D 场景属性,其性能远超标准方法。
论文总结道:“我们的方法简洁高效,非常适合实时应用,这也是其优于基于优化方法的另一个优势。”
CVPR 2025 最佳学生论文
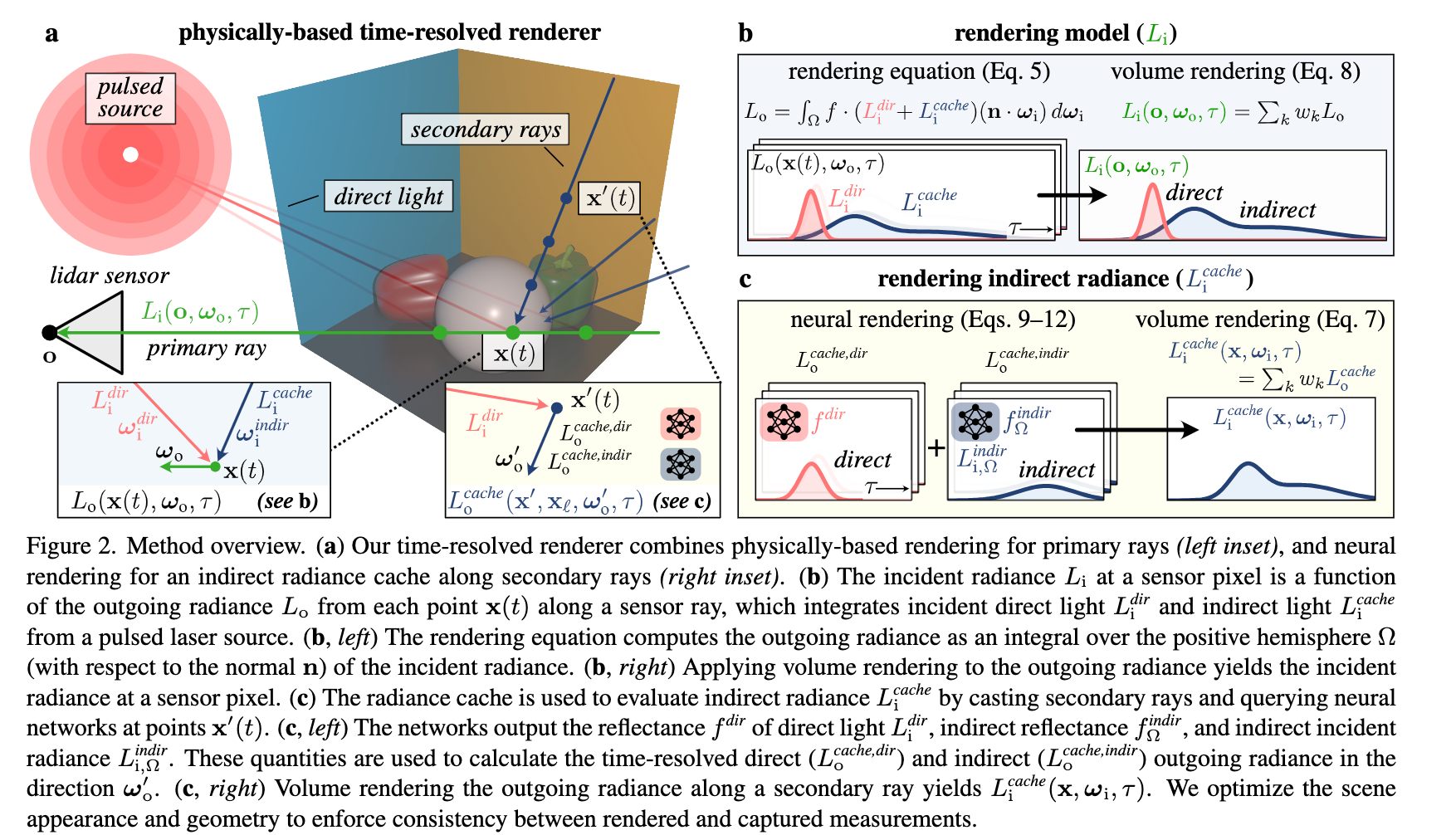
- Neural Inverse Rendering from Propagating Light
作者:Anagh Malik、Benjamin Attal、Andrew Xie、Matthew O’Toole、David B. Lindell
简介: 来自多伦多大学、矢量研究所和卡内基梅隆大学的团队展示了首个基于物理的神经逆向渲染系统,该系统可从多视点传播光视频中进行计算。该研究对来自激光雷达(L i DAR)系统的多视点、时间分辨的传播光测量数据进行建模和逆向计算,以恢复场景几何形状并渲染传播光视频。
正如论文总结的那样,这项工作“在自主导航或遥感等领域具有潜在的应用潜力,尤其是在具有强烈间接光照影响的场景中”。
最佳论文荣誉奖
- MegaSaM: Accurate, Fast and Robust Structure and Motion from Casual Dynamic Videos
作者:Zhengqi Li、Richard Tucker、Forrester Cole、Qianqian Wang、Linyi Jin、Vickie Ye
主要内容:
- 本文提出了 MegaSaM 系统,用于从随意的动态视频中准确、快速、鲁棒地估计相机参数和深度图。
- MegaSaM 通过整合单目深度先验、学习的运动概率和不确定性感知全局 BA,显著改进了深度视觉 SLAM 框架以处理动态场景和有限视差。
- 在合成和真实视频上的实验证明,MegaSaM 在相机和深度估计精度及鲁棒性上远超现有方法,同时具有快速或可比的运行速度。

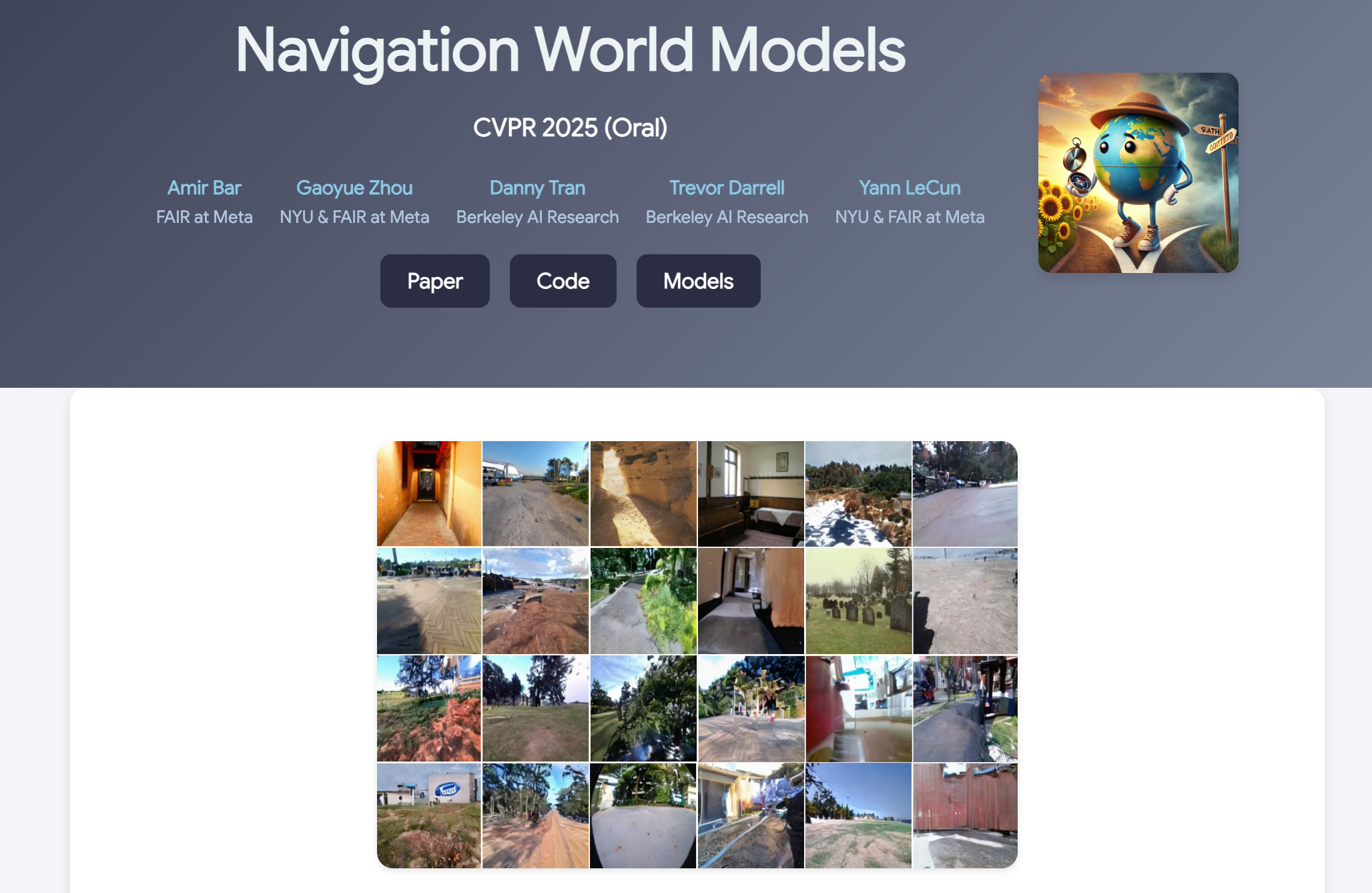
- Navigation World Models
作者:Amir Bar、Gaoyue Zhou、Danny Tran、Trevor Darrell、Yann LeCun
主要内容:
- 本文提出了一种导航世界模型 (NWM),它是一个可控视频生成模型,用于基于过去的视觉观察和导航动作预测未来的视觉观察。
- NWM 使用了一种新颖的条件扩散 Transformer (CDiT) 架构,该架构在各种机器人和人类的第一视角视频数据上训练,并且可以有效地扩展以进行导航规划。
- 该模型能够通过模拟和评估轨迹来规划导航路径,在已知环境中表现出色,并能通过学习到的视觉先验在未知环境中进行想象,在规划和现有策略排名方面取得了优异的性能。
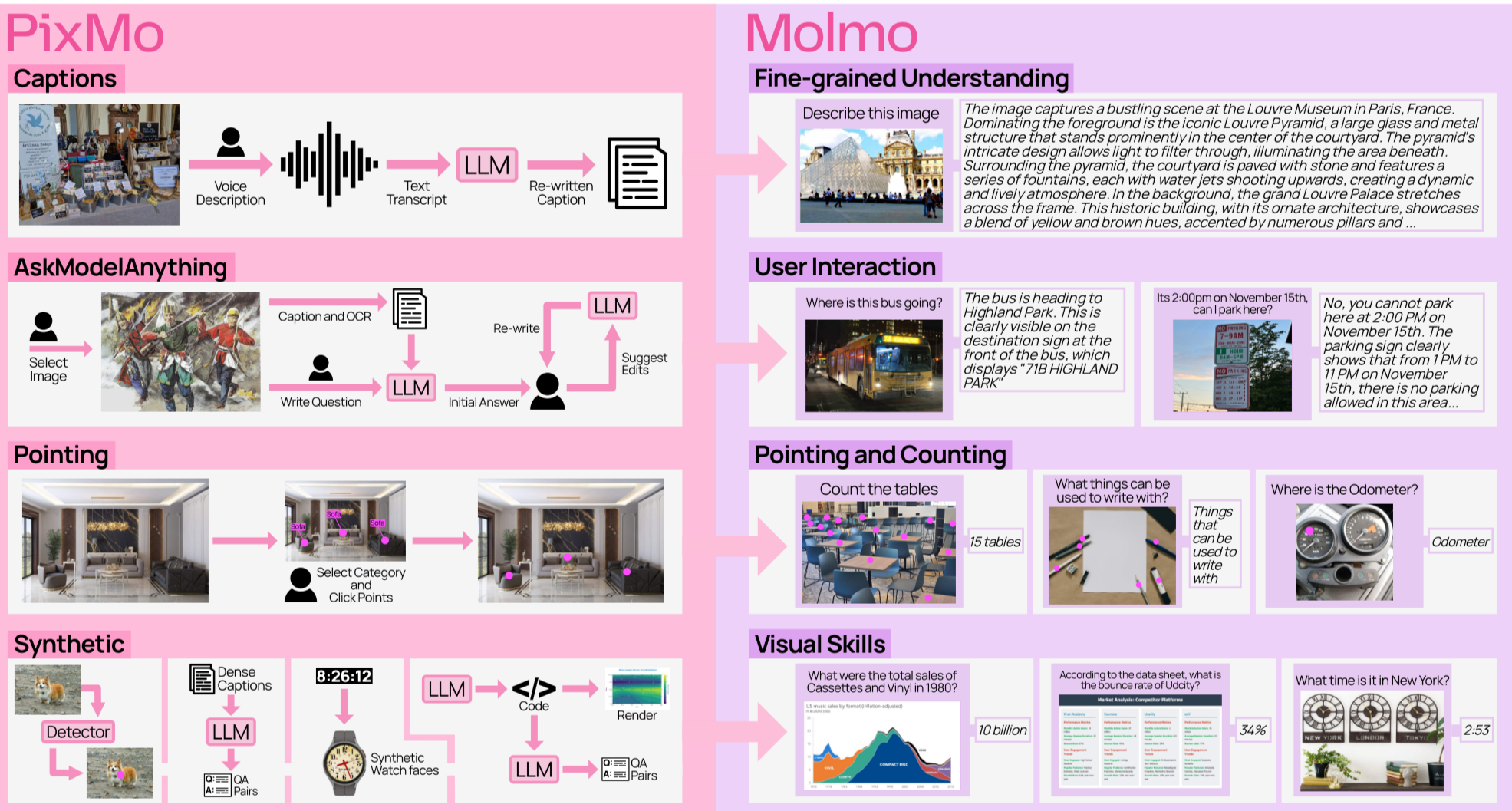
- Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models
作者:Matt Deitke、Christopher Clark、Sangho Lee、Rohun Tripathi
主要内容:
- Molmo 是一个新型开放视觉语言模型 (VLM) 系列,其成功基于全新的开放数据集 PixMo。
- PixMo 数据集未使用专有 VLM 的合成数据,包含了详细的图像描述、自由问答和创新的 2D 指向数据,为从头训练高性能 VLM 提供了基础。
- 性能最优的 Molmo-72B 模型在开放权重和数据模型类别中达到最先进水平,并在多项基准和人工评估中超越了 Gemini 1.5 Pro 和 Claude 3.5 Sonnet 等专有模型,仅次于 GPT-4o。
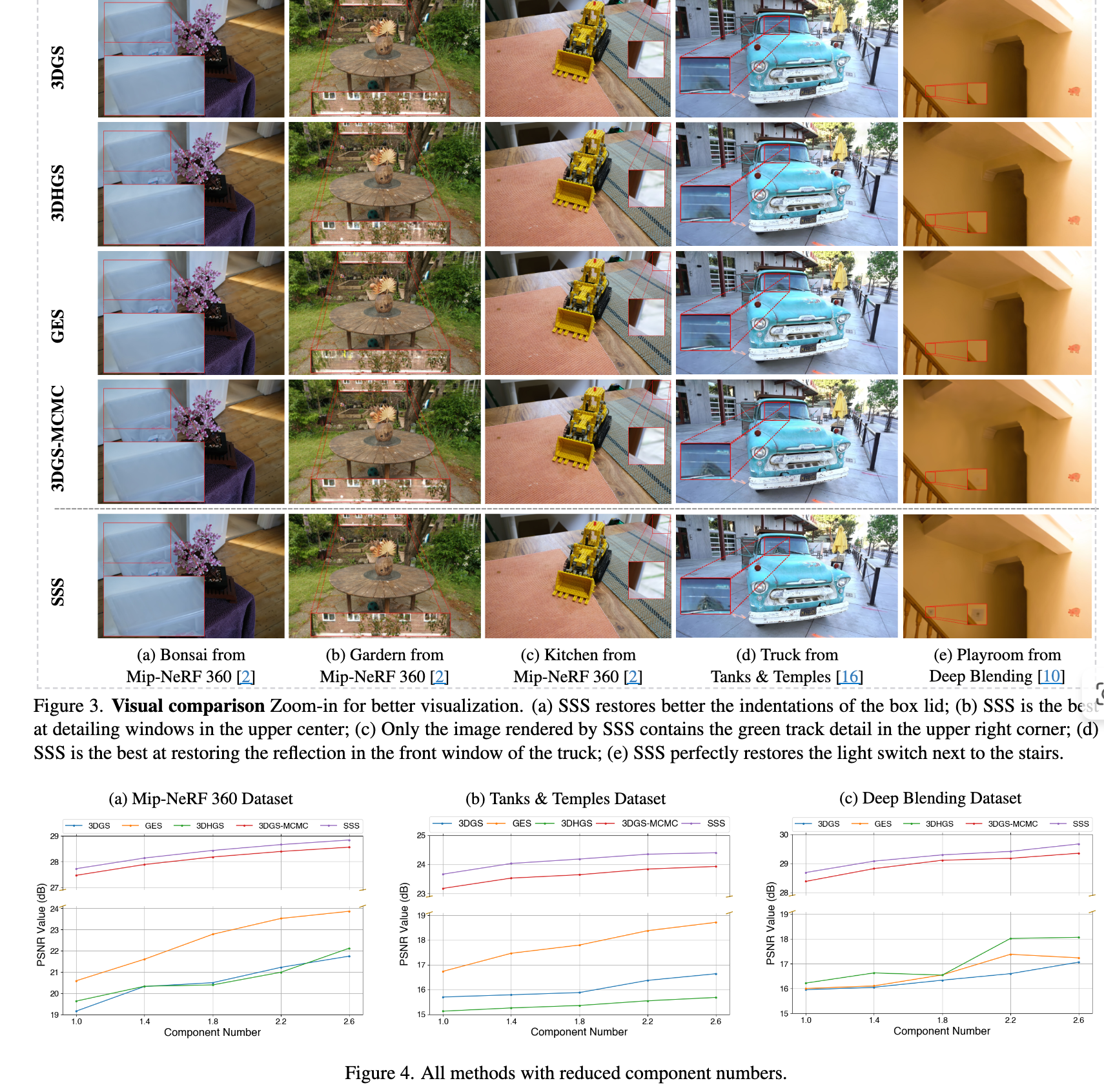
- 3D Student Splatting and Scooping
作者:朱家林、岳江北、何飞翔、王河
主要内容:
- 一篇论文提出了 Student Splatting and Scooping (SSS) 新模型,它使用灵活的 Student’s t 分布代替 3DGS 中的高斯分布,并引入了正负密度(splatting 和 scooping)。
- 为了有效训练这个具有更复杂参数耦合的模型,该方法设计了一种基于 Stochastic Gradient Hamiltonian Monte Carlo (SGHMC) 的采样优化策略。
- 实验结果表明,SSS 在多种数据集和评估指标上均优于现有方法,显著提高了渲染质量并展现出更高的参数效率,常能用少得多的组件达到可比甚至更好的性能。
最佳学生论文荣誉奖
- Generative Multimodal Pretraining with Discrete Diffusion Timestep Tokens
作者:潘凯航、王林、岳中奇、敖腾龙、贾立宇、赵伟、李俊成、唐思良、张汉旺
主要内容:
- 本文提出了离散扩散时间步(DDT)标记,它通过递归地补偿噪声图像中随时间步增加的属性损失来学习离散、递归的视觉标记。
- 现有方法使用的空间视觉标记缺乏语言固有的递归结构,是LLM难以掌握的“不可能语言”,而DDT标记模仿语言结构,更适合LLM处理。
- 基于DDT标记,作者构建了统一的多模态大语言模型DDT-LLaMA,在文本到图像生成、图像编辑和视觉语言理解等任务上均取得了优于现有MLLM的性能。

AI艺术项目获奖者
除了技术研究之外,CVPR AI 艺术项目还探索了科学与艺术的交汇,并欢迎使用或关注计算机视觉的作品,包括生成模型、 物体识别和面部识别等技术。AI 艺术奖获奖者从 100 多件入选作品中脱颖而出,并于今日公布,获奖者包括:
- 汤姆·怀特的《感知图谱》
通过探索神经网络的潜在空间,阐明了视觉模型的“视觉词汇”。雕塑般的表现形式探究了机器如何解析世界,从而深入了解了外观本身的语法——视觉的模块化语义。

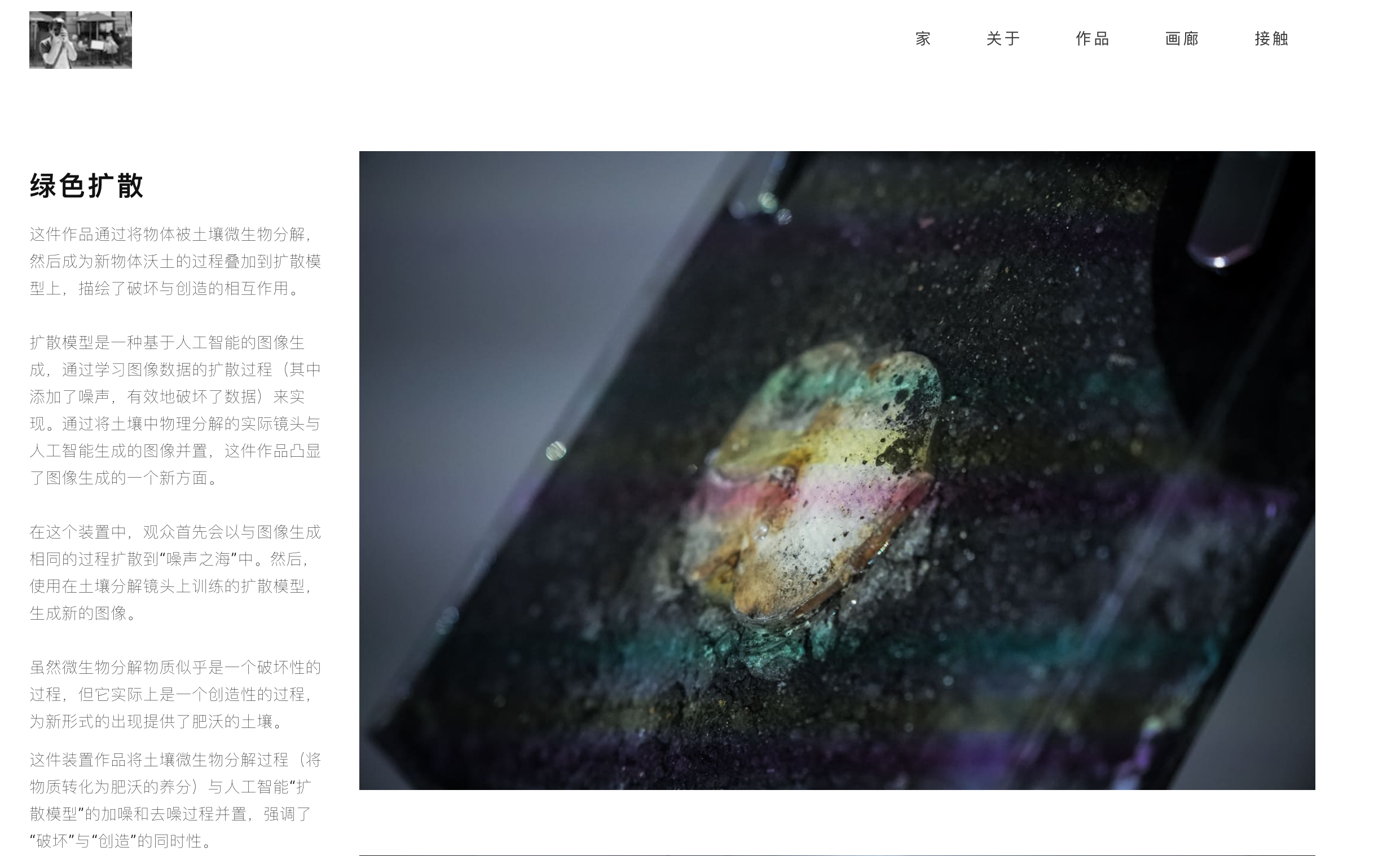
- 水落胜的“绿色扩散”
通过将土壤微生物的分解过程(将物质转化为肥沃的养分)与人工智能扩散模型的增噪和去噪过程并列,强调了“破坏”和“创造”的同时性。
- 程明永、孙晓玲、张涵的《学会移动,学会玩耍,学会动画》
是一部跨学科的多媒体表演作品,其特色是自主研发的材料机器人、实时人工智能生成、运动跟踪、音频空间化和基于生物反馈的音频合成。
