Google机器学习实践指南(非线性特征工程解析)
🔥 Google机器学习(20)-特征组合:非线性特征工程解析
Google机器学习(20)-非线性特征工程解析(约12分钟)
一、核心概念解析
1. 合成特征
定义:从原始特征衍生出的新特征
主要类型:
- 连续特征分箱(如年龄分段)
- 特征间相乘/相除(如面积=长×宽)
- 特征组合(如地理位置=经度×纬度)

2. 特征组合
本质:通过笛卡尔积生成的新特征
作用:让线性模型学习非线性关系
数学表示:
x 3 = x 1 × x 2 → 加入模型: y = b + w 1 x 1 + w 2 x 2 + w 3 x 3 x₃ = x₁ × x₂ → 加入模型:y = b + w₁x₁ + w₂x₂ + w₃x₃ x3=x1×x2→加入模型:y=b+w1x1+w2x2+w3x3
二、线性vs非线性问题
案例:树木健康诊断

图1 线性问题
线性问题特征:
-
可画一条直线较好分类
-
模型: y = w 1 x 1 + w 2 x 2 + b y = w₁x₁ + w₂x₂ + b y=w1x1+w2x2+b
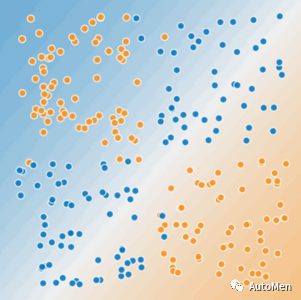
图2 非线性问题
非线性问题特征:
-
需曲线或复杂边界分类
-
解决方案:创建特征组合 x 3 = x 1 x 2 x₃ = x₁x₂ x3=x1x2
三、特征组合实战
1. 基本组合类型
| 组合形式 | 示例 | 适用场景 |
|---|---|---|
| 二元特征组合 | [纬度 × 经度] | 地理位置相关预测 |
| 高阶组合 | [年龄 × 收入 × 性别] | 用户行为分析 |
| 自组合 | [年龄²] | 考虑U型关系的情况 |
符号说明:
×表示特征交叉(特征工程中的笛卡尔积)²表示特征自乘(如年龄×年龄,用于捕获非线性关系)
2. 技术实现
# Python特征组合示例
import pandas as pddf = pd.DataFrame({'x1': [1,2,3], 'x2': [4,5,6]})
df['x3'] = df['x1'] * df['x2'] # 创建特征组合
3. 组合效果对比

四、最佳实践指南
✅ 组合选择原则:
-
优先组合有业务关联的特征(如经纬度)
-
避免过度组合导致维度爆炸
-
配合正则化防止过拟合
✅ 工程技巧:
-
对连续特征先分箱再组合
-
使用独热编码处理类别特征组合
-
监控特征重要性剔除无效组合
# 技术问答 #
Q:特征组合会导致计算成本增加吗?
A:会,但远低于神经网络等复杂模型的计算开销
Q:如何处理高基数类别特征组合?
A:先做哈希分箱再组合,或使用嵌入编码(Embedding)
Q:特征组合与多项式回归的区别?
A:本质相同,但特征组合更强调业务意义的特征交互
参考文献:
[1] Google机器学习-特征组合指南