python入门day02
1.python中的位运算符(了解):
位运算符把数字看作二进制数来进行计算的。
- "位与"运算(&) :对应位都为1时结果为1,否则为0。
0000 0000 0000 1100& 0000 0000 0000 1000--------------------------0000 0000 0000 1000- "位或"运算(|):只要对应位中有一个为1时结果为1。
0000 0000 0000 0100| 0000 0000 0000 1000-------------------------- 0000 0000 0000 1100- "位异或"运算(^):对应位不同时结果为1,相同结果为0。
0000 0000 0001 1111^ 0000 0000 0001 0110--------------------------0000 0000 0000 1001- "位取反"运算(~):进行取反操作,即将所有的0变为1,将所有的1变为0。
~ 0000 0000 0111 1011--------------------------1111 1111 1000 0100- "左移位"运算(<<):将数字的位向左移动指定的位数,高位丢弃,低位补0。相当于乘以2的n次方。
00000010
0000001000
- "右移位"运算(>>):将数字的位向右移动指定的位数,低位丢弃,高位补0或者保持符号位不变。(如果原高位为0,则高位补0;如果原高位为1,则高位补1)。相当于除以2的n次方。
00001000 10001000
0000001000 1110001000
2.运算符的优先级
| 运算符 | 描述说明 |
| ** | 幂运算 |
| ~、+、- | 取反、正号、负号 |
| *、/、%、// | 算数运算符 |
| +、- | 算数运算符 |
| <<、>> | 位运算符中的左位移、右位移 |
| & | 位运算符中的位与 |
| ^ | 位运算符中的位异或 |
| | | 位运算符中的位或 |
| <、<=、>、>=、!=、== | 比较运算符 |
| = | 赋值运算符 |
3.判断语句:if..elif..else
- 语法结构:
if 表达式1:
语句块1
elif 表达式n:
语句块n
else:
语句块n+1
- 当语句块的内容只有一句代码时,可以取消语句块前面的缩进,直接将语句块写在表达式的后面;
- 当判断条件只有一个,且输出语句非常简短,可以简写,如:
print("恭喜你,中奖了!" if number==123456 else "很遗憾,没有中奖!")
满足条件,执行if左侧,不满足,执行if右侧
score=eval(input("请输入你的成绩:")) if score<0 or score>100: if score<0 or score>100:print("成绩无效!")print("成绩无效!") elif 0<=score<60:print("E")elif 0<=score<60: =========== elif 60<=score<70:print("D")print("E") =========== elif 70<=score<80:print("C")elif 60<=score<70: elif 80<=score<90:print("B")print("D") else: print("A") elif 70<=score<80: print("C")elif 80<=score<90:print("B")else:print("A")4.for循环
- 语法结构:
for 循环变量 in 遍历对象:
语句块1
else:
语句块2
- 当所有循环正常执行且执行结束后(循环未break),执行else中的逻辑
- 补充:range()是Python中的内置函数,产生一个[n,m)的整数序列,包含n,不包含m
# 判断100-999之间的水仙花数
"""
水仙花数:三位数 = 个位数三次方 + 十位数三次方 + 百位数三次方
"""
for i in range(100,1000):sd=i%10 # 个位数tens=i//10%10 # 十位数hundreds=i//100 # 百位数if i==sd**3+tens**3+hundreds**3:print(i)
else:print("循环执行结束了")5.while循环
- 语法结构:
while 表达式1:
语句块1
else:
语句块2
- while循环的四个步骤:
1) 初始化变量
2) 条件判断
3) 语句块
4) 改变变量
- 当所有循环正常执行且执行结束后(循环未break),执行else中的逻辑
- break和continue在循环结构中使用,break用于退出整个循环结构,continue用于结束本次循环而进入下一次循环。
# 计算1-100之间的累加和s=0i=1 # 初始化变量while i<=100: # 条件判断s+=i # 语句块i+=1 # 改变变量else:print("1-100之间的和为:",s)6.序列、切片及序列操作
- 序列 : 是一个用于存储多个值的连续空间
- 索引 : 序列中每个值对应的整数编号,索引有正向递增索引(0,1,2...)和反向递减索引(...-3,-2,-1)
- 切片操作 : 序列 [ start : end : step ]
start省略时,默认从0开始(包含)
end省略时,默认到最后一个结束(不包含)
step省略时,默认长度为1
step为负数时,按照反向递减索引切片
s="helloword"
print(s[:10:2]) # hlood
print(s[0::3]) # hlo
print(s[0:10:]) # helloword
print(s[::-1]) === print(s[-1:-10:-1]) # drowolleh
print(s[::-2]) === print(s[-1:-10:-2]) # doolh- 序列操作:
| 操作符/函数 | 描述说明 |
| x in s | 如果x是s的元素,结果为True,否则结果为False |
| x not in s | 如果x不是s的元素,结果为True,否则结果为False |
| len(s) | 序列s中元素的个数(即序列的长度) |
| max(s) | 序列s中元素的最大值 |
| min(s) | 序列s中元素的最小值 |
| s.index(x) | 序列s中第一次出现元素x的位置 |
| s.count(x) | 序列s中出现x的总次数 |
7.组合数据类型----列表
- 列表 : 是指一系列的按特定顺序排列的元素组成,是Python中内置的可变序列(因为操作列表后,列表的内存地址没变,所以称为可变序列),列表中的元素可以是任意的数据类型。
- 创建列表 :
方式一 : 使用[]直接创建列表:列表名=[element1,element2,..elementN]
方式二 : 使用内置函数list()创建列表:列表名=list(序列)
# 方式一:
lst1=["pink",12,"hello"]
print(lst1) # ["pink",12,"hello"]# 方式二:
lst2=list("helloword")
print(lst2) # ['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'd']- 删除列表 : del 列表名
- 遍历列表 :
方式一 : 使用for遍历列表元素
方式二 : 使用for循环,range()函数,len()函数,根据索引进行遍历
方式三 : 使用enumerate()函数进行遍历
lst=["pink","green","yellow","black"]# 使用循环遍历for遍历列表元素
for item in lst:print(item)# 使用for循环,range()函数,len()函数,根据索引进行遍历
for i in range(0,len(lst)):print(lst[i])# 使用enumerate()函数进行遍历,注:此处的index不是索引,而是序号,可通过start指定序号的起始值,默认值是1
for index,item in enumerate(lst,start=2):print(index,item)- 列表的操作方法:
| 列表的方法 | 描述说明 |
| Ist.append(x) | 在列表lst最后增加一个元素 |
| Ist.insert(index,x) | 在列表中第index位置增加一个元素 |
| lst.clear() | 清除列表lst中所有元素 |
| Ist.pop(index) | 将列表lst中第index位置的元素取出,并从列表中将其删除 |
| lst.remove(x) | 将列表lst中出现的第一个元素x删除 |
| Ist.reverse(x) | 将列表lst中的元素反转 |
| Ist.copy() | 拷贝列表lst中的所有元素,生成一个新的列表 |
- 列表修改 : 列表[索引]=修改值,如:lst[2]="python"
- 列表排序 :
方式一 : 使用列表对象的sort方法:lst.sort(key=None,reverse=False)
(1)key指定排序规则,如忽略大小写:key=str.lower,转为小写再排序
(2)reverse指定排序方式,False表示升序,True表示降序,默认升序
(3)如果排序列表中同时有大小写字母,升序时先排大写,再排小写;降序时,先排小写,再排大写
(4)sort是在原列表的基础上进行排序,不会产生新的列表对象
方式二 : 使用内置函数sorted():sorted(lst,key=None,reverse=False)
(1)sorte排序会产生新的列表对象,原列表不会改变
# sort排序lst=["apple","Banana","strawberry"]lst.sort()print(lst) # ['Banana', 'apple', 'strawberry']lst.sort(reverse=True)print(lst) # ['strawberry', 'apple', 'Banana']lst.sort(key=str.lower)print(lst) # ['apple', 'Banana', 'strawberry']# sorted 排序lst=[43,12,89,66]new_lst=sorted(lst,reverse=True)print(lst) # [43, 12, 89, 66]print(new_lst) # [89, 66, 43, 12]- 列表生成式 :
Ist=[expression for item in range]
Ist=[expression for item in range if condition]
import random
lst=[i for i in range(0,10)]
print(lst) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
lst=[random.randint(1,100) for _ in range(10,20)]
print(lst) # [92, 83, 50, 76, 63, 16, 89, 36, 75, 46]
lst=[i for i in range(0,10) if i%2==0]
print(lst) # [0, 2, 4, 6, 8]for循环生成二维列表:
lst=[["城市","环比","同比"],["北京","102","103"],["上海","104","444"],["深圳","666","888"]
]
for row in lst:for item in row:print(item,end="\t")print()# 结果:
城市 环比 同比
北京 102 103
上海 104 444
深圳 666 888 8.组合数据类型----元组
- 元组:元组是Python中内置的不可变序列,在Python中使用()定义元组,元素与元素之间使用英文逗号分隔,元组中只有一个元素的时候,逗号也不能省略
- 元组创建:
方式一 : 使用()直接创建元组:元组名=(element1,element2,.....elementN)
方式二 : 使用内置函数tuple()创建元组:元组名=tuple(序列)
# 使用()直接创建元组
t=(1,"python")
print(t) # (1, 'pink')# 使用内置函数tuple()创建元组
t=tuple("hello")
print(t) # ('p', 'i', 'n', 'k')- 删除元组 : del元组名
- 遍历列表 :
方式一 : 使用for遍历列表元素
方式二 : 使用for循环,range()函数,len()函数,根据索引进行遍历
方式三 : 使用enumerate()函数进行遍历
t=("pink","green","yellow","black")# 使用循环遍历for遍历列表元素
for item in t:print(item)# 使用for循环,range()函数,len()函数,根据索引进行遍历
for i in range(0,len(t)):print(t[i])# 使用enumerate()函数进行遍历,注:此处的index不是索引,而是序号,可通过start指定序号的起始值,默认值是1
for index,item in enumerate(t,start=2):print(index,item)- 元组和列表的区别:
| 元组 | 列表 |
| 不可变序列 | 可变序列 |
| 无法实现添加、删除和修改元素等操作 | append()、insert()、remove()、pop()等方法实现添加和删除列表元素 |
| 支持切片访问元素,不支持修改操作 | 支持切片访问和修改列表中的元素 |
| 访问和处理速度快 | 访问和处理速度慢 |
| 可以作为字典的键 | 不能作为字典的键 |
9.组合数据类型----字典
- 字典:字典是根据一个信息查找另一个信息的方式构成了“键值对”,它表示索引用的键和对应的值构成的成对关系
- 创建字典:
方式一 : 使用{}直接创建字典:d={key1:value1,key2:value2...)
方式二 : 通过映射函数创建字典:dic(zip(lst1,lst2) )
方式三 : 通过dic直接创建字典:dict(key1=value1,key2=value2..)
注意 : 字典的键是不可变序列,因此元组可以作为字典的键,列表不能作为字典的键
# 使用{}直接创建字典
d={"color":'gray',"number":12,10:"123"}
print(d) # {'color': 'gray', 'number': 12, 10: '123'}# 通过映射函数创建字典
lst1=["color","number",10]
lst2=["gray",12,"123"]
zipObj=zip(lst1,lst2)
d=dict(zipObj)
print(d) # {'color': 'gray', 'number': 12, 10: '123'}# 通过dic直接创建字典
d=dict(cat=10,dog=20)
print(d) # {'cat': 10, 'dog': 20}- 删除字典 : del 字典名
- 字典元素的取值 : d[key]或d.get(key)
d=dict(cat=10)
print(d["cat"])
print(d.get("cat"))
print(d["dog"]) # 当key不存在时,使用d[key]会报错
print(d.get("dog","不存在")) # 当key不存在时,使用d.get(key)不会报错,且可以指定默认值- 字典元素的遍历 :
方式一 : 遍历出key与value的元组:
for element in d.items():
方式二 : 分别遍历出key和value:
for key,value in d.items():
# 字典的遍历
d=dict(cat=10,dog=20)
for item in d.items():print(item) # ('cat', 10)# ('dog', 20)for key,value in d.items():print(key,value) # cat 10# dog 20- 字典的操作方法:
| 字典的方法 | 描述说明 |
| d.keys() | 获取所有的key数据 |
| d.values() | 获取所有的value数据 |
| d.pop(key,default) | key存在获取相应的value,同时删除key-value对,否则获取默认值 |
| d.popitem() | 随机从字典中取出一个key-value对,结果为元组类型,同时将该key-value从字典中删除 |
| d.clear() | 清空字典中所有的key-value对 |
- 字典生成:
方式一 : d={ key:value for item in range }
方式二 : d={key:value for key,value in zip(lst1,lst2)}
import random
d= {item: random.randint(1, 100) for item in range(1, 10)}
print(d) # {1: 37, 2: 90, 3: 41, 4: 56, 5: 26, 6: 36, 7: 61, 8: 48, 9: 53}lst1=[1001,1002,1003]
lst2=["张三","李四","王五"]
d={key:value for key,value in zip(lst1,lst2)}
print(d) # {1001: '张三', 1002: '李四', 1003: '王五'}10.组合数据类型----集合
- 集合:集合是一个无序的不重复元素序列,集合中只能存储不可变数据类型,与列表、字典一样,都是Python中的可变数据类型
- 创建集合:
方式一 : 使用{}直接创建集合:s={element1,element2,......elementN}
方式二 : 使用内置函数set()创建集合:s=set(可迭代对象)
注意 : s={}创建的是空字典,而非空集合,set()创建空集合
# 使用{}直接创建集合
s={1,'pink',"张三"}
print(s) # {1, 'pink', '张三'}# 使用内置函数set()创建集合
s=set("hello")
print(s) # {'l', 'e', 'h', 'o'}- 删除集合:del 集合名
- 集合操作符:
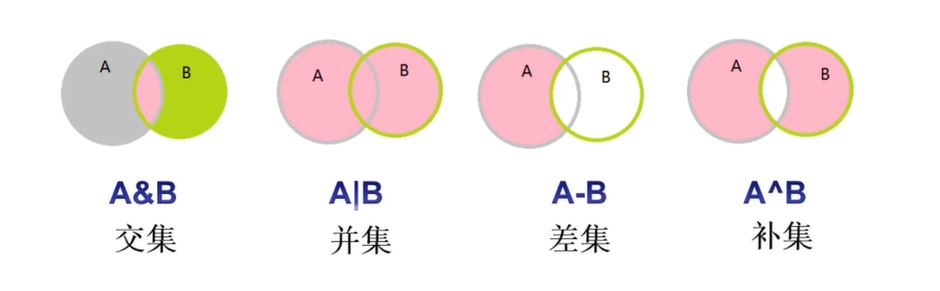
- 集合的相关操作:
| 集合的方法 | 描述说明 |
| s.add(x) | 如果x不在集合s中,则将x添加到集合s |
| s.remove(x) | 如果x在集合中,将其删除,如果不在集合中,程序报错 |
| s.clear() | 清除集合中所有元素 |
- 集合的遍历:
方式一 : 使用for遍历列表元素
方式二 : 使用enumerate()函数进行遍历
s={"pink","green","yellow","black"}# 使用循环遍历for遍历列表元素
for item in s:print(item)# 使用enumerate()函数进行遍历,注:此处的index不是索引,而是序号,可通过start指定序号的起始值,默认值是1
for index,item in enumerate(s,start=2):print(index,item)- 集合生成:
s={expression for item in range}
s={expression for item in range if condition}
# 集合生成
s={i for i in range(1,10)}
print(s) # {1, 2, 3, 4, 5, 6, 7, 8, 9}s={i for i in range(1,20) if i%2==0}
print(s) # {2, 4, 6, 8, 10, 12, 14, 16, 18}11.列表、元组、字典、集合的区别:
| 数据类型 | 序列类型 | 元素是否可重复 | 是否有序 | 定义符号 |
| 列表list | 可变序列 | 可重复 | 有序 | [] |
| 元组tuple | 不可变序列 | 可重复 | 有序 | () |
| 字典dict | 可变序列 | Key不可重复,Value可重复 | 无序 | {key:value} |
| 集合set | 可变序列 | 鍘求鍘力可重复 | 无序 | {} |