论文学习_Trex: Learning Execution Semantics from Micro-Traces for Binary Similarity
摘要:检测语义相似的函数在漏洞发现、恶意软件分析及取证等安全领域至关重要,但该任务面临实现差异大、跨架构、多编译优化及混淆等挑战。现有方法多依赖语法特征,难以捕捉函数的执行语义。对此,TREX 提出了一种基于迁移学习的框架,通过函数的微型执行轨迹学习执行语义,并迁移用于语义相似函数匹配。尽管微型轨迹本身精度有限,TREX 的关键在于利用其训练模型理解指令序列语义。该方法设计了无监督预训练任务,无需人工标注或特征工程,并引入分层Transformer架构以捕捉语义信息。在超过147万函数的跨架构、优化和混淆测试中,TREX 分别比先进方法提升7.8%、7.2%、14.3%,且运行速度提高8倍。消融实验验证了预训练的重要性,案例研究亦发现16个未公开的漏洞。代码与数据已开源:https://github.com/CUMLSec/trex。
引言
函数语义相似性指的是衡量两个函数在行为层面上的相似程度,这一能力在程序分析中具有基础性地位,并在实际安全领域中发挥着广泛作用,包括漏洞检测、漏洞利用生成、恶意软件谱系分析和数字取证等。例如,OWASP 在 2020 年的十大应用安全风险中就将“使用存在已知漏洞的组件”列为主要威胁之一。因此,在大规模软件项目中自动识别语义相似的易受攻击函数,能够显著减少人工审计的工作量。研究背景
在面向安全关键应用(如漏洞发现)进行语义相似函数匹配时,研究对象往往是二进制级别的软件,例如商用固件或遗留程序。但这一任务本身存在诸多困难:(1)函数在编译过程中会丢失高级语义信息,如数据结构定义等,使得分析难度大幅上升。(2)更为复杂的是,函数可能被编译用于不同的指令集架构,并经过多种编译优化或轻量级混淆处理,这进一步加剧了语义相似性识别的挑战。语义相似函数任务的挑战
近年来,基于机器学习的方法在应对上述挑战方面展现出巨大潜力。通过从函数二进制中学习稳健的特征,这类方法能够在不同体系结构、编译优化等级,甚至某些混淆情况下识别出语义相似的函数。其核心思路是让模型从函数中学习表示向量(即嵌入表示),然后通过两个函数嵌入之间的距离来衡量它们的相似度——距离越小,表示函数越相似。相比于依赖手工特征(如基本块数量)的传统签名方法,这类基于嵌入距离的策略已在多个研究中取得领先效果,表现优于早期技术。更重要的是,该策略在大规模函数匹配任务中极具优势,查找百万级函数仅需约0.1秒,效率极高。基于机器学习的语义相似函数检测
尽管已有方法取得了显著进展,但在处理语法和结构差异较大的语义相似函数时,匹配准确性仍面临挑战。其根本原因在于,代码的语义本质上是由其运行时行为决定的。然而,现有所有基于学习的方法都未考虑程序的执行语义,它们仅基于静态代码进行训练。这种训练方式容易使模型依赖于表层模式进行匹配,一旦这些模式发生变化或不存在,模型的准确性便会显著下降。核心思想,代码的语义本质上是由其运行时行为决定的
例如,考虑这样一对 x86 指令序列:mov eax, 2; lea ecx, [eax+4] 与 mov eax, 2; lea ecx, [eax+eax*2],它们在语义上是等价的。但若一个机器学习模型仅关注语法特征,可能会因为两者共享如 mov、eax、lea、ecx 等相同子串,而错误地认为这是它们相似的主要依据。实际上,这种模式并未真正体现两者在语义上的等价关系。若模型无法理解大致的执行语义,就很容易依赖这些表面模式进行匹配,而忽略了本质原因:当 eax 为 2 时,[eax+eax*2] 与 [eax+4] 实际上计算的是相同的内存地址。现存问题,现有技术无法捕获代码运行时特征
现有的动态方法试图通过直接比较函数的运行时行为来规避静态分析中的局限性,以判断其语义相似性。然而,由于精准构造能够触达目标函数的输入是一项极具挑战且耗时的任务,相关研究通常采用“弱约束动态执行”的方式,即随机初始化函数的输入状态(如寄存器、内存)并直接执行目标函数。尽管这种方式避免了输入生成的复杂性,但若直接利用其生成的执行轨迹来判定函数相似性,往往会导致大量误报。例如,当两个本质不同的函数都对输入有严格检查时,随机输入可能频繁触发类似的浅层异常处理逻辑,从而使它们在行为上看起来“伪相似”。解释为什么不通过动态的方式实现运行时特征捕获
现有的静态方法和动态方法均存在问题
本文提出了一种名为 TREX(TRansfer-learning EXecution semantics)的方法,通过弱约束动态轨迹训练机器学习模型,从中学习指令在上下文中的近似执行语义。与以往直接利用这些轨迹进行相似性判断的方法不同,TREX 首先在多样化的轨迹数据上进行预训练,使模型掌握每条指令在特定上下文中的行为效果;随后再将预训练中获得的知识迁移用于语义相似函数的匹配任务。大量实验证明,这种对执行语义的近似学习在预训练阶段显著提升了语义相似函数匹配的准确性,尤其在跨体系结构、编译优化和混淆环境下,TREX 表现尤为突出。
核心观点在于,尽管弱约束动态执行轨迹中可能包含大量不可达的程序状态,但其中的许多指令仍然能够准确反映其真实的执行效果。因此,可以通过大量来自不同函数的轨迹数据,让机器学习模型观察并学习这些指令在实际上下文中的行为。一旦模型掌握了各类指令的大致执行语义,便能利用这些已学习的知识,进一步训练模型以实现语义相似函数的匹配。这样,在实际推理阶段,无需动态执行待匹配的函数,大幅降低了运行时开销。更重要的是,训练完成的模型在进行函数匹配时并不依赖动态轨迹本身,而是直接使用函数指令作为输入,但这些指令已通过预训练被赋予了丰富的语义信息。
在这项工作中,研究者将“微执行”(micro-execution)技术加以拓展,作为一种弱约束动态执行形式,用于在多种指令集架构下生成函数的“微轨迹”。所谓微轨迹,是由一系列对齐的指令及其对应的程序状态值构成的序列。模型的预训练则基于大量从不同函数中采集的微轨迹数据,采用掩码语言建模(masked LM)任务进行。该任务会随机遮盖序列中的部分信息,并要求模型根据上下文预测被遮盖的内容,从而迫使模型在推理缺失值的过程中学习函数的近似执行过程,无需依赖任何人工特征设计即可自动提取执行语义。此外,masked LM 是一种完全自监督的训练方式,因此 TREX 可以灵活地利用任意来源的函数数据持续进行训练与优化。
为实现这一目标,TREX 采用了一种分层式 Transformer 架构,专门用于学习函数的近似执行语义。不同于以往方法通常将数值信息视作无实际意义的占位符以规避庞大的词汇表规模,这一架构则显式建模微轨迹中的数值内容,从而更有效地捕捉那些可能蕴含关键语义的数值之间的依赖关系。此外,其自注意力机制经过特别设计,能够高效建模序列中的长距离依赖,使得 TREX 能够处理约 170 倍于现有模型长度的序列,并实现约 8 倍的运行加速,这对于从长执行轨迹中学习函数嵌入表示至关重要。
内容概述
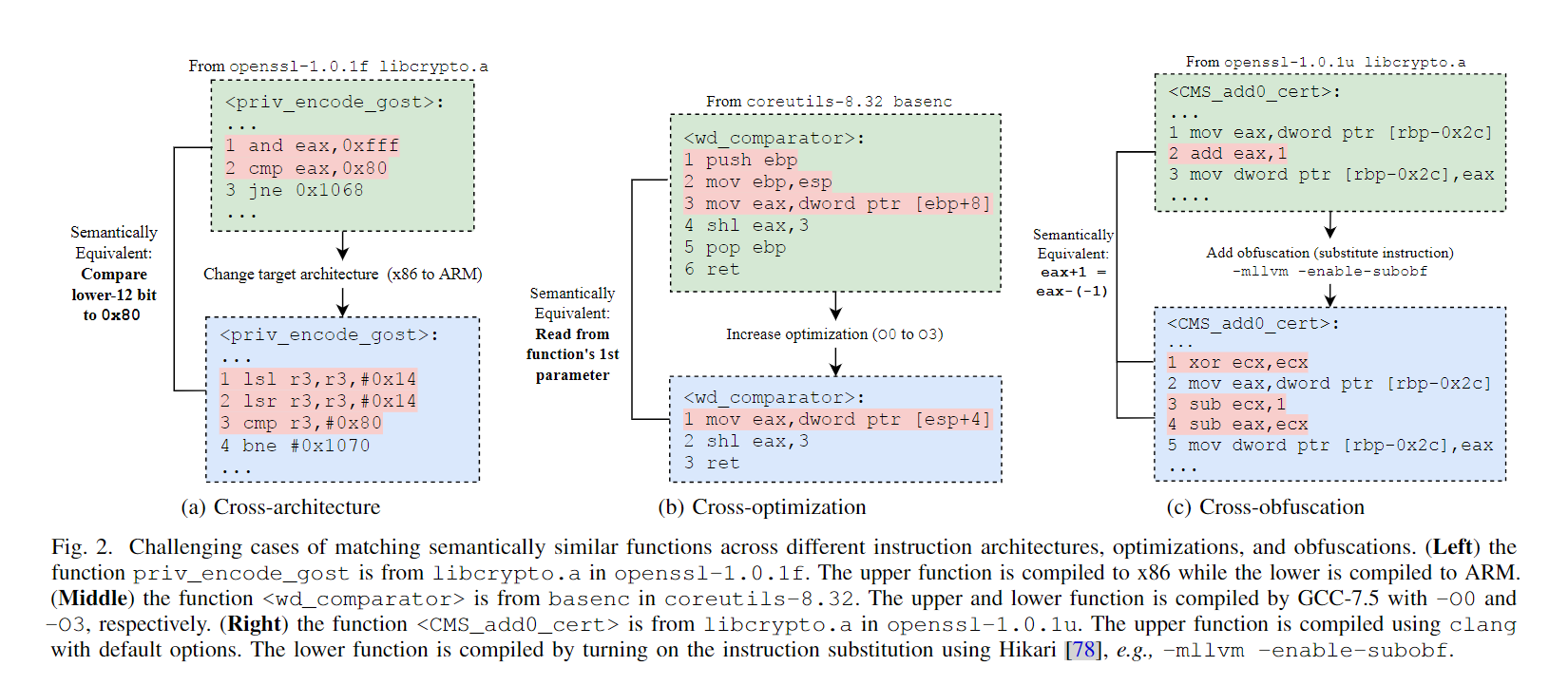
挑战性案例:使用三个语义上等价但语法上不同的函数对证明仅从静态代码学习的一些挑战。
- 跨架构匹配:它们都取某个寄存器的低12位,并将其与0x80进行比较。要识别这种语义相似性,不仅需要理解 x86 架构中的
and指令与 ARM 架构中的lsl/lsr指令的大致执行语义,还需要掌握代码中具体数值(如 0xfff 和 0x14)在指令中的操作方式。然而,现有的机器学习方法大多仅基于静态代码进行训练,无法观测每条指令的实际运行效果。更进一步,由于完整引入所有可能的内存地址会导致词汇表规模过大,这些方法通常会将寄存器值和内存地址统一替换为抽象符号,结果无法利用关键的字节数值来判断底层的语义相似性。 - 跨优化匹配:
[ebp+8]与[esp+4]实际上访问的是同一内存地址——即调用者压入栈中的第一个函数参数。要识别这种相似性,模型需理解push指令会将栈指针esp向下移动4个字节;同时也要意识到第2行的mov指令将此时减少后的esp赋值给了ebp,从而使得上方函数中的ebp+8与下方函数中的esp+4等价。然而,这类动态行为在静态代码中是无法直接体现的。 - 简单混淆匹配:其本质是将
eax+1替换为eax-(-1)。要识别这种语义等价性,模型必须能够大致理解诸如xor、sub和add等算术操作的执行行为。然而,静态代码本身并不足以揭示这些底层算术语义的等价关系。
微轨迹上训练语言模型:本节主要阐述了为何在函数的微轨迹上执行掩码语言建模(masked LM)预训练任务,能够有效促使模型学习其执行语义。尽管目前仍难以从理论上明确证明此类语言建模任务具体学习到了哪些类型的知识,但重点在于理解其背后的直觉逻辑:通过预测微轨迹中被遮盖的代码和数值,模型被迫去推理缺失信息在当前上下文中的合理性,这一过程正是促使模型掌握指令执行语义的关键。
Masked LM:针对函数的微轨迹(包含指令和对应的值),随机遮盖其中部分内容,并训练模型根据未被遮盖的信息预测被遮盖的部分。由于这一过程仅依赖输入数据本身进行预测,完全不需要额外的人工标注,因此 TREX 可以利用大量自然获取的函数数据进行训练与持续优化。这种方式的优势在于,即使某条指令未在某个函数的微执行中出现,它很可能会出现在其他函数的微轨迹中,从而帮助 TREX 逐步掌握更广泛指令的执行语义,实现对多样化指令行为的近似建模。
Masking register:以图2c中的函数为例,这两个函数本质上都将栈中位置 [rbp-0x2c] 的值加一。上方函数采用了直接方式:将该值加载到 eax,加1后再写回栈中;而下方函数则使用了更曲折的方法,先将 -1 存入 ecx,然后通过 eax 减去 ecx 来实现加1的效果,最终同样将结果写回栈。研究人员在上方函数的第3行对 eax 进行了掩码处理,结果发现预训练模型能够准确预测出该寄存器的名称和动态值。这说明模型不仅理解了 add 指令的语义,还能根据第2行的 eax 值推断出加法后的结果。同样地,模型也能恢复下方函数第4行的 ecx 和第5行的 eax 值,表明其掌握了 xor 和 sub 指令的执行效果。正是这种对底层语义的理解,在后续用于函数匹配的微调阶段,大幅增强了模型的鲁棒性,使其更倾向于依据执行行为而非表层语法特征来判断函数相似性。
Masking opcode:除了对寄存器及其值进行掩码外,还可以对指令的操作码(opcode)进行掩码处理。要正确预测被遮盖的操作码,模型必须理解各类操作码的执行效果。以图2b为例,在上方函数第2行将 mov 操作码遮盖后,预训练模型最终以最高概率预测出 mov,而非其他可能的候选指令如 add、inc 等。要实现这一正确预测,模型需掌握函数语义中的多个关键点:首先,从上下文信息来看,比如第3行中 ebp 的值和第2行中 esp 的状态,模型能推断出 mov 最符合语义,因为它完成了将 esp 的值赋给 ebp 的操作;而其他指令则因其执行效果与后续寄存器状态不符而被排除。这表明模型已近似掌握了 mov 的执行语义。其次,模型也学习了 x86 指令的一般语法规则和调用约定,例如只有部分操作码支持两个操作数(如 ebp, esp),这使得模型能自动排除像 push、jmp 这类语法不合法的候选项。因此,模型能够进一步推断出上方函数第3行中的 ebp 与 esp 值相等,同时还可能从其他训练样本中学到 push 会使栈指针 esp 减少4字节。正因如此,在经过微调用于函数匹配时,模型更有可能根据 [ebp+8] 与 [esp+4] 实际访问的是相同地址这一语义等价性进行判断,而不是依赖两段代码在语法上的相似性。
Other masking strategies:需要注意的是,在掩码操作中,并不受限于指令中被遮盖元素的数量或类型——既可以对寄存器、操作码等单个元素进行遮盖,也可以遮盖整条指令,甚至是连续的一段指令序列,还可以随机遮盖某些指令的输入输出值。更进一步,模型在每轮训练以及不同样本之间,都会动态选择不同的代码块和程序状态子集进行掩码操作。这样的设计使模型能够学习到多样化、复合型的指令序列执行效果,这对于识别使用不同指令实现的语义相似函数至关重要。在本研究中,采用的是一种完全随机的掩码策略,以固定比例在微轨迹中选取掩码位置(具体细节见第IV-C节)。不过,这也为后续研究提供了一个有趣方向,即探索如何以更高效但仍廉价的方式,动态优化掩码位置与比例,从而进一步提升模型效果。
研究内容

微轨迹语义:研究团队基于 Godefroid 提出的微执行方法进行了扩展,使其不仅支持原论文所描述的 x86,还适用于 x64、ARM 和 MIPS 架构。接下来的内容简要说明了如何对单个函数二进制进行微执行,并重点介绍了处理不同类型指令时所采用的关键算法。为了统一不同架构汇编语法的差异,文中引入了一种低层次的中间表示(IR)语言,用于建模函数的汇编代码,如下图所示。需要强调的是,这种 IR 仅用于阐述微轨迹生成过程的核心机制;在实际实现中,使用的是真实的汇编指令,并经过分词处理后作为模型输入。中间表示值得学习

微轨迹算法:首先,它会初始化内存以加载目标函数 f 的代码及其对应的栈空间,随后初始化除特殊用途寄存器(如栈指针、程序计数器)以外的所有通用寄存器。接下来,系统以线性方式依次执行函数中的指令;若执行过程中指令涉及内存读写操作,则按需映射相应内存地址;对于读取操作,还会在目标地址中初始化一个随机值。遇到调用或跳转指令时,系统会检查其目标地址,跳过无效的调用或跳转,这种处理方式被称为“强制执行”。通过绕过无法抵达的跳转路径或调用指令,系统能够持续执行函数至末尾,从而暴露更多潜在行为,例如规避由输入检查引发的异常。至于 nop 指令,由于其常用于函数内的填充操作,处理时则直接跳过。当函数所有指令执行完毕、遇到 ret 指令,或达到超时时间时,微执行过程即告终止。图13和图14展示了两个真实函数的微轨迹示例。