演员评论家算法
一、演员评论家算法核心思想和原理
演员(actor)代表策略,评论家代表价值函数。演员评论家算法是基于价值和策略的综合性方法。具体来说该算法使用了策略梯度和时序差分方法,是二者的一种有机结合。
1. 主要思想
策略梯度算法以轨迹为单位更新,样本方差大,学习效率低。
时序差分中,价值函数以时间步为单位更新,思想可以借鉴。
2. 模型结构
基于期望的优势函数既能实现时序差分迭代,又让训练更加稳定。
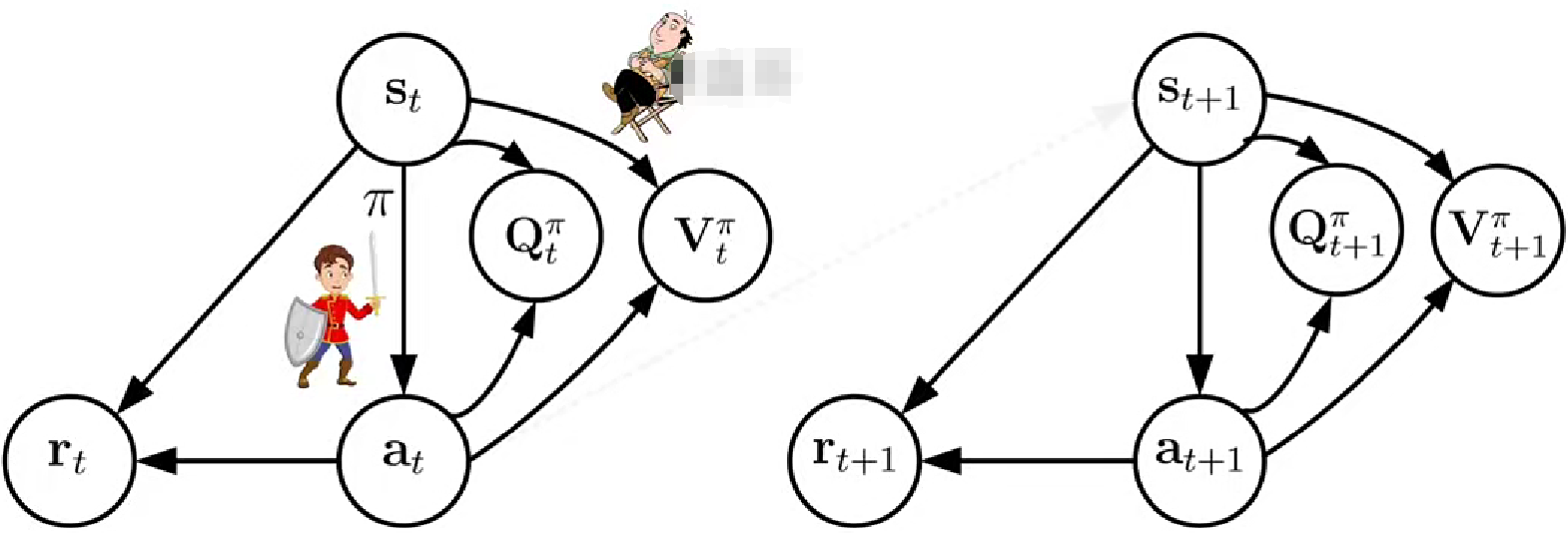
2.1 深度演员评论家算法
策略网络:π网络
价值网络:Q网络+V网络
3. 演员评论家算法适用条件
连续状态空间:高维图像处理或机器人控制
离散动作空间:每个时间步,从固定动作集中选择动作
梯度可以计算:通过梯度更新策略网络的参数
奖励信号可用:可以由环境提供,也可以由设计者定义
数据效率要求低:通常需要更多训练样本
二、改进型演员评论家算法
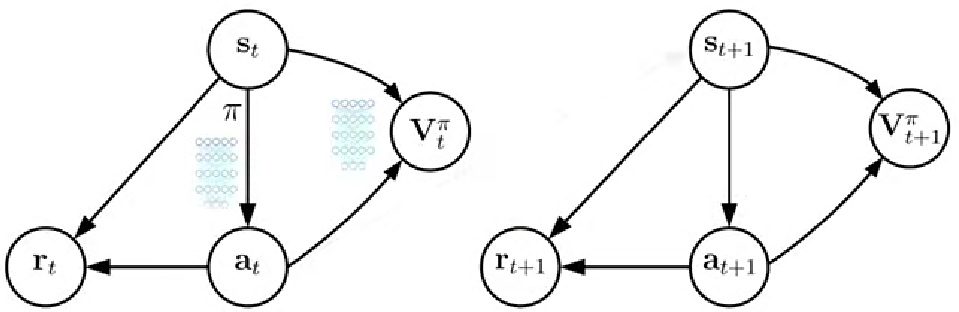
1. 优势演员评论家算法(A2C)
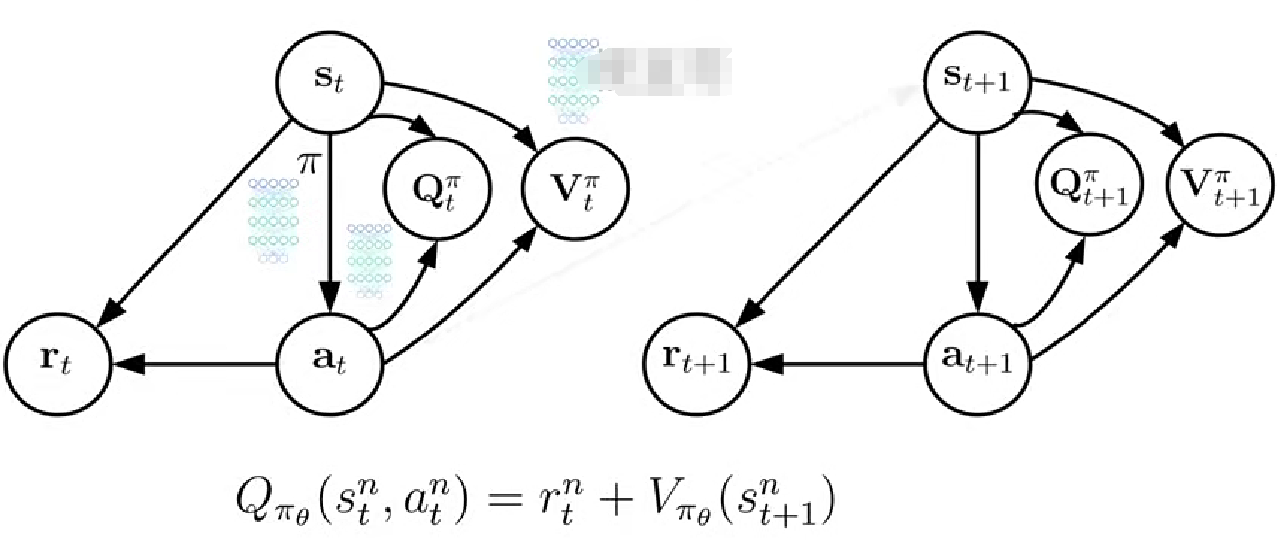
优势函数衡量给定状态下选择某个动作相对平均预期回报的优势价值,相对于值函数的整体估计,提供了更精细的价值估计,能够量化特定的动作相对于平均水平的价值优势,能更好地用于动作选择和策略改进。省去了Q结点
 2. 异步优势演员评论家算法(A3C)
2. 异步优势演员评论家算法(A3C)
通过并行运算来提高训练的速度,因为多数的强化学习训练过程都比较慢。A3C是在A2C的基础上进一步改进。
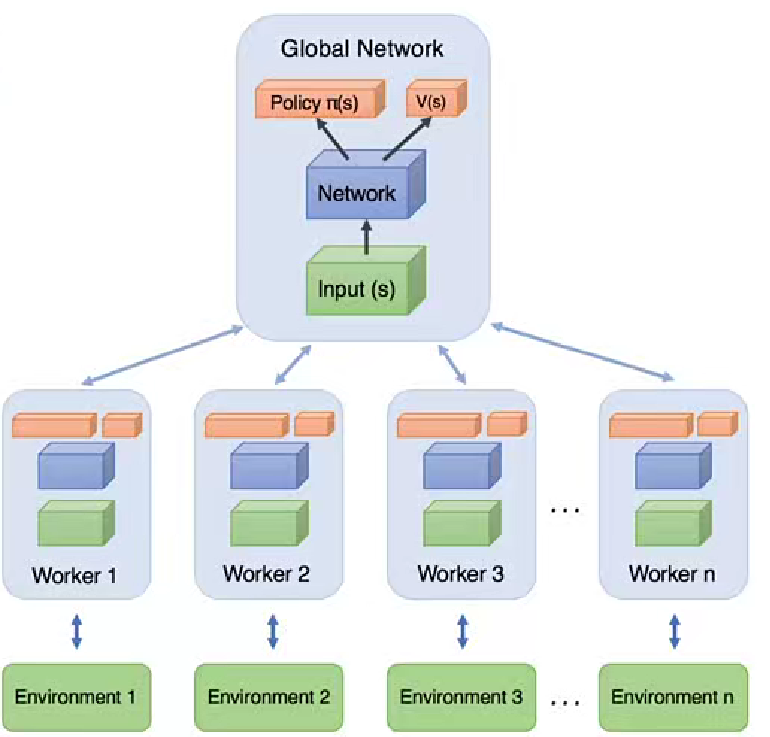
2.1 网络结构图
第一部分:Global Network是整个算法的核心,目标是学习策略和价值函数的参数。
第二部分:works是工作器,A3C算法采用异步并行方式进行训练,其中每个工作器都有一个本地的神经网络副本。独立和环境交互收集经验数据,并用于更新全局网络。每个工作器都有自己的经验池,来存储其收集的经验数据。
第三部分:策略网络Policy Network,属于演员的角色,负责选择动作接收s作为输入。并输出动作的概率分布。
最后一部分是价值函数网络,value function network属于critic部分,用于估计状态的价值。状态作为输入并作为状态值的估计。再之后是优势函数计算模块,根据值函数和策略网络的输出,使用优势函数来计算每个动作的优势,用于计算策略梯度和作为目标值进行值函数的训练。
整体而言,A3C算法是一种分布式的体系结构,通过异步更新和参数共享的方式实现高效的并行训练。
三、深度确定性策略梯度DDPG
Deep Deterministic Policy Gradient
演员评论家方法,为解决马尔科夫决策过程提供了一种综合而
全面的框架。其用神经网络同时逼近了策略函数和价值函数,不过无论是A2C还是A3C,他们在离散动作空间这样的任务当中应用比较多。DDPG着重解决了连续动作空间的问题,和可以进行离散的异策略优化。
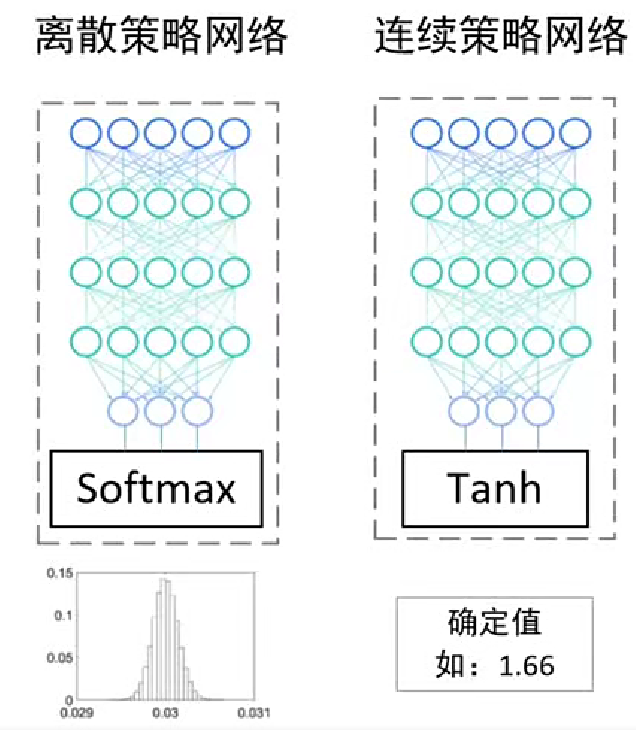
1. 离散动作和连续动作
离散动作空间中动作有限且离散,通常用随机性描述动作![]()
连续动作空间中动作是连续的,直接输出确定值来控制行为![]()
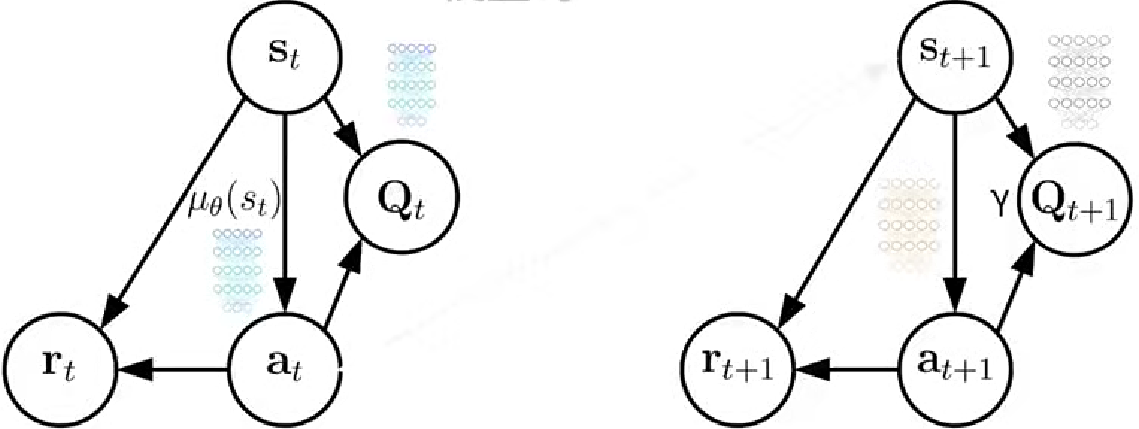
2. 模型结构
相对于A2C价值结点从V变成了Q,采用了动作价值函数Q(s,a),用深度神经网络逼近策略分布。使用了四个网络:策略网络及下一时刻的目标网络,价值网络及下一时刻的目标网络。
 3. DDPG适用条件
3. DDPG适用条件
连续动作空间:在处理连续控制问题中有优势
模型无关性:适用于实际应用中缺乏准确环境模型的情况
高维状态空间:能够处理复杂的状态表示