20:深度学习-多层感知器原理
深度学习-多层感知器的原理
------------------常州龙熙机器视觉培训班-课程资料
1.单层感知机
多层感知机是由感知机推广而来,感知机学习算法(PLA: Perceptron Learning Algorithm)用神经元的结构进行描述的话就是一个单独的。
首先了解下单层感知机:
b--常量
W1,W2, W3 ----权重系数
X1,X2,************Xn相当于 ,分类或者识别计算进来的特征变量;
Features := [Circularity,Roundness,PSI1,PSI2,PSI3,PSI4]
统计特征:-----各种辨别特征输入
X1 . ----圆形度
X2. ---- 粗糙度
X3. -----几何特性 --其他
输入项---
螺母 [0.880752, 0.960562, 0.00639327, -3.36195e-16, -1.53993e-09, 8.01824e-11]
垫片 [0.993547, 0.988408, 0.00633285, -8.48059e-17, -7.3286e-10, 3.71291e-11]
卡环 [0.805131, 0.890939, 0.00705197, 2.96079e-18, -1.10171e-10, 7.9533e-12]
| 名称 | 圆形度 | 粗糙度 | 几何特性 --其他 | |
| 螺母 | 0.880752 | 0.960562 | ||
| 垫片 | 0.993547 | 0.988408 | ||
| 卡环 | 0.805131 | 0.890939 |
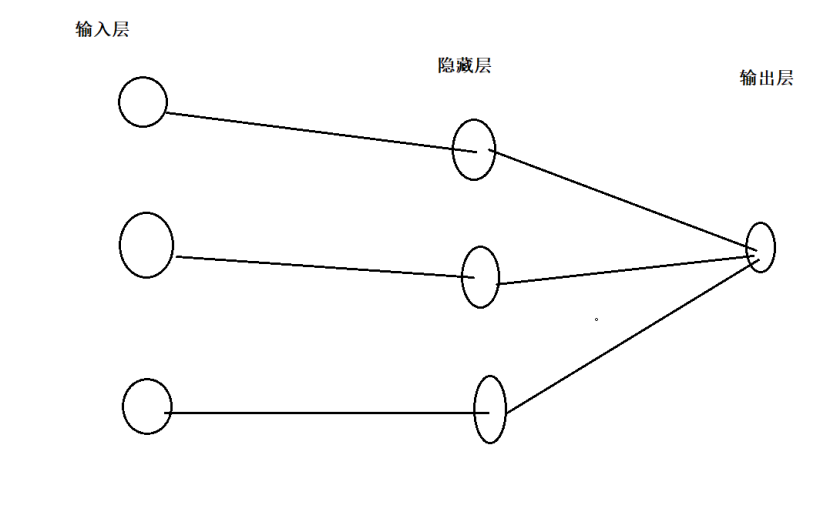
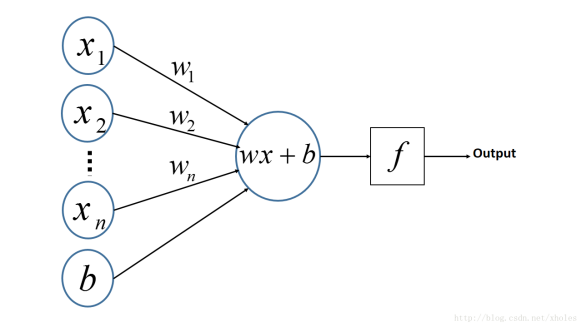
Wx+b 相当于 对输入层求和 , f 相当于激励函数!
Wx+b ,线性 !
函数有哪些?
常见的激励函数有:线性激励函数、阈值或阶跃激励函数、S形激励函数、双曲正切激励函数和高斯激励函数等。
神经网络中的每个节点接受输入值,并将输入值传递给下一层,输入节点会将输入属性值直接传递给下一层(隐层或输出层)。在神经网络中,隐层和输出层节点的输入和输出之间具有函数关系,这个函数称为激励函数。常见的激励函数有:线性激励函数、阈值或阶跃激励函数、S形激励函数、双曲正切激励函数和高斯激励函数等。
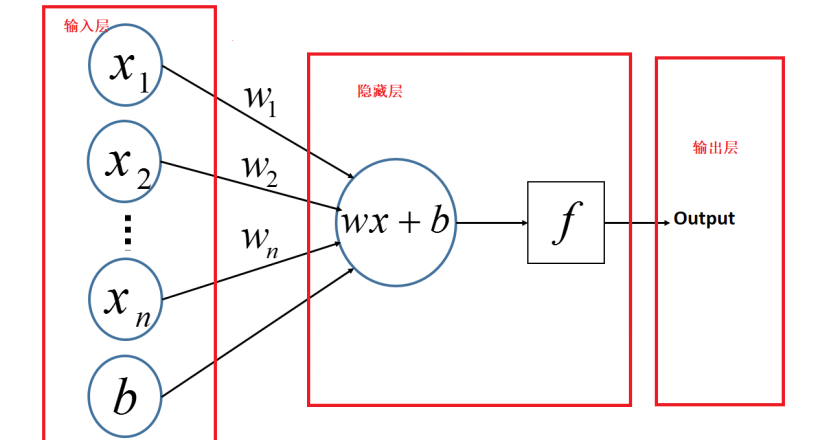
我们能得到下面公式:
先求和 h = (w1*x1)+(w2*x2)+(w3*x3) + b
求和之后 通过激励函数 f ,输出结果, 比如 -1 , 1.

1.螺母

2.卡环

3. 垫片
特征变量相当于 分辨物体的特性。
- 多层感知系统
多层感知机的一个重要特点就是多层,我们将第一层称之为输入层,最后一层称之有输出层,中间的层称之为隐层。MLP并没有规定隐层的数量,因此可以根据各自的需求选择合适的隐层层数。且对于输出层神经元的个数也没有限制。
MLP神经网络结构模型如下,本文中只涉及了一个隐层,输入只有三个变量和一个偏置量,输出层有三个神经元。相比于感知机算法中的神经元模型对其进行了集成。
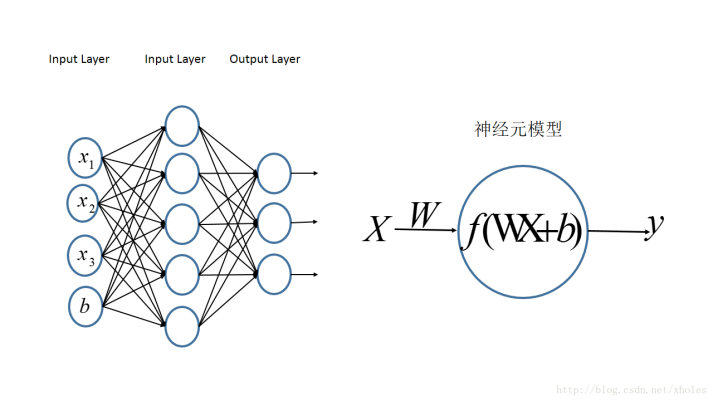
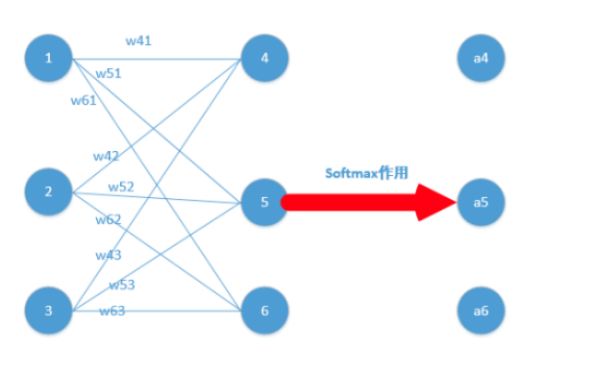
我们能得到下面公式:
z4 = w41*o1+w42*o2+w43*o3
z5 = w51*o1+w52*o2+w53*o3
z6 = w61*o1+w62*o2+w63*o3
后面也是 求和 +b ,
- 分类--使用方法 ----
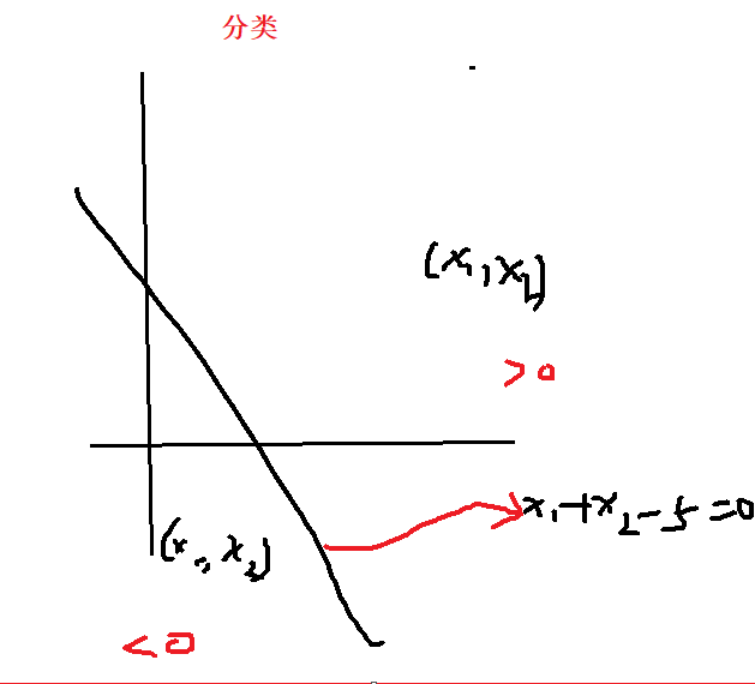
4.激活函数的一种 softmax (或者叫激励参数)
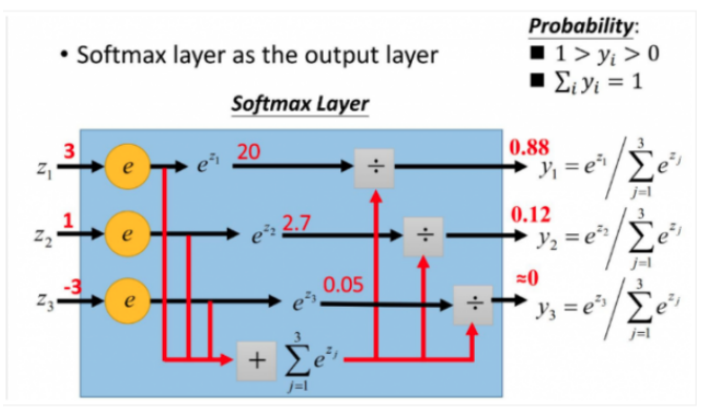
简单的讲数学中的e就是个数字,它的值约等于2.7182818284590452353602874713527等。
e的三次方 =20.08
e的1次方是2.718
e的-3次方是 0.049
20.08+2.718+0.049=22.8 ,
20.08/22.8=0.88
2.7/22.8=2.7
权重关系
曲线 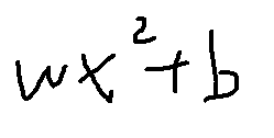
。
我们知道,抛物线y = ax^2 + bx + c ( a ≠0 )是轴对称图形,它的对称轴是直线x = - b/ 2a ,它的顶点在对称轴上。
softmax直白来说就是将原来输出是3,1,-3通过softmax函数一作用,就映射成为(0,1)的值,而这些值的累和为1(满足概率的性质),那么我们就可以将它理解成概率,在最后选取输出结点的时候,我们就可以选取概率最大(也就是值对应最大的)结点,作为我们的预测目标!
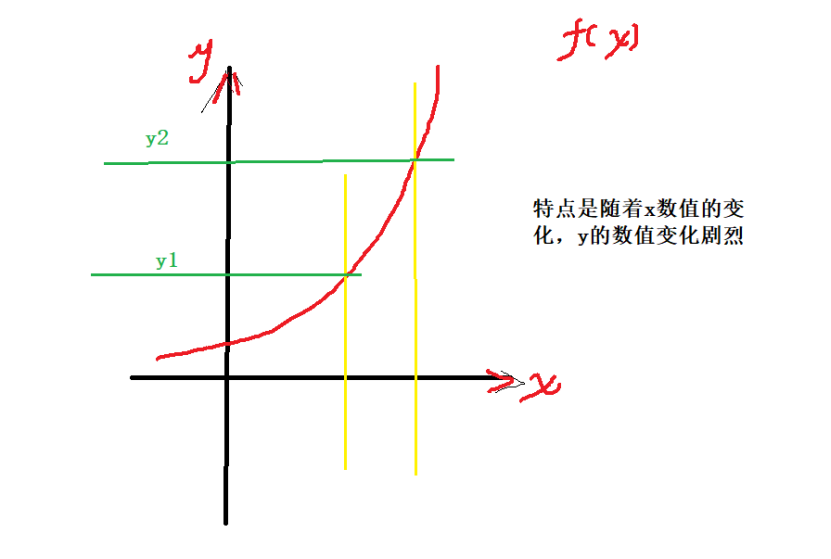
softmax函数
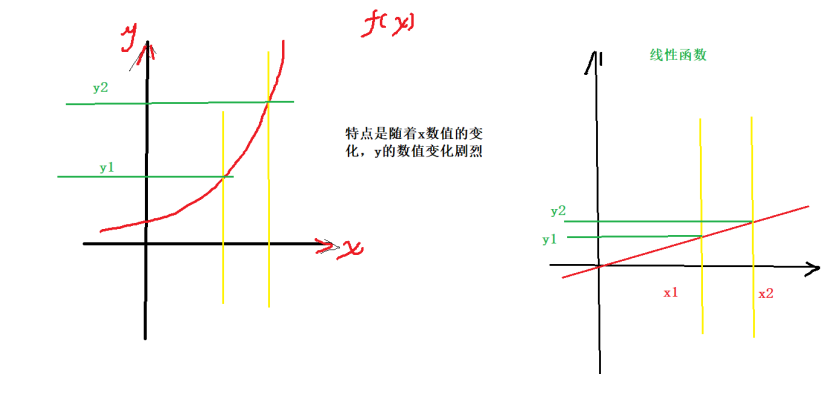
对比其他函数的关系
- 一阶导 与 权重参数优化
迭代次数
与每次递增的数值
迭代次数 ----次数越大 时间越长, 识别成功率越高
迭代参数 0.01 ---参数越大, 每次间距越大, 时间断,但是可能导致没有找到最合适的权重参数。

内容涉及一些复杂的公式和算法。从图中可以看出,这些公式与机器学习或统计学中的优化问题有关。最上方的公式是损失函数(Loss Function),通常用于衡量模型预测结果与真实值之间的差距。中间部分描述了梯度下降法(Gradient Descent)的基本步骤,这是一种常用的优化方法,通过不断更新参数以最小化损失函数来训练模型。在下方,可以看到一个关于均方误差(Mean Squared Error, MSE)的表达式,它是评估回归模型性能的一种常用指标。MSE 是每个样本预测值与实际值差的平方和的平均值。整个过程可以总结为以下几步:1. 初始化权重(W)。2. 计算损失(J(w))。3. 梯度下降:根据损失函数对权重求导数,并用此导数值更新权重。4. 重复步骤 2 和 3 直到达到预设的停止条件(如最大迭代次数、损失函数收敛等)
- 函数有哪些?
常见的激励函数有:线性激励函数、阈值或阶跃激励函数、S形激励函数、双曲正切激励函数和高斯激励函数等。
神经网络中的每个节点接受输入值,并将输入值传递给下一层,输入节点会将输入属性值直接传递给下一层(隐层或输出层)。在神经网络中,隐层和输出层节点的输入和输出之间具有函数关系,这个函数称为激励函数。常见的激励函数有:线性激励函数、阈值或阶跃激励函数、S形激励函数、双曲正切激励函数和高斯激励函数等。