论文阅读:2024 ICML In-Context Unlearning: Language Models as Few-Shot Unlearners
总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
In-Context Unlearning: Language Models as Few-Shot Unlearners
https://arxiv.org/pdf/2310.07579
https://www.doubao.com/chat/4031248338338818
速览
这篇论文主要介绍了一种针对大语言模型(LLMs)的新型遗忘学习方法——上下文内遗忘(In-Context Unlearning,ICUL),旨在解决从模型中删除特定训练数据的问题。
- 研究背景:随着机器学习模型在众多领域的广泛应用,数据隐私保护变得愈发重要,如被遗忘权等法规的出台,要求从模型中删除特定数据。同时,大语言模型存在版权侵权等问题,也需要“删除”相关数据。但传统的完全重新训练模型的方法对于大语言模型来说计算成本过高,且很多大语言模型是黑盒模型,无法直接访问参数进行更新。
- 相关工作:上下文学习是大语言模型的重要能力,能通过输入序列中的示例适应新任务,但此前无人研究如何利用它实现遗忘学习。机器学习遗忘领域已有不少研究,提出了精确和近似遗忘算法,但大多针对判别式分类器,且在大语言模型中的应用存在挑战。
- 预备知识:介绍上下文学习的定义,即语言模型通过少量上下文示例学习任务的方式。提出LiRA-Forget方法来衡量遗忘效果,通过样本分割近似重新训练分布,将衡量遗忘的问题转化为假设检验问题,计算基于损失分布的似然比统计量。
- 上下文内遗忘框架(ICUL):该框架旨在无需重新训练模型或更新参数的情况下,实现对特定训练数据点的遗忘。通过三个步骤构建上下文输入:一是随机翻转要遗忘点的标签;二是添加正确标注的训练点;三是将查询输入添加到模板中让模型预测。在问答任务中,则是翻转答案。
- 实证评估:使用多个真实数据集,在Bloom和Llama-2等大语言模型上进行实验,并与基于梯度上升的遗忘方法(GA)对比。结果表明,ICUL在遗忘效果上优于GA,且在处理不同数量的删除请求时,模型性能更稳定。ICUL的遗忘效果随模型规模增大而提升,在不同类型的大语言模型上都有效,还能应用于问答任务,但删除请求增多时模型精度会下降。此外,研究发现上下文长度、标签翻转和遗忘点的依赖性等因素会影响ICUL的效果。
- 研究结论:ICUL为大语言模型提供了一种有效的遗忘学习方法,无需访问模型参数。但仍存在一些待探索的问题,如扩展到更复杂任务、处理更大的删除请求、减少测试时间运行时、改进提示设计、应对提示反转攻击以及开发更实用的遗忘测试等。
论文阅读
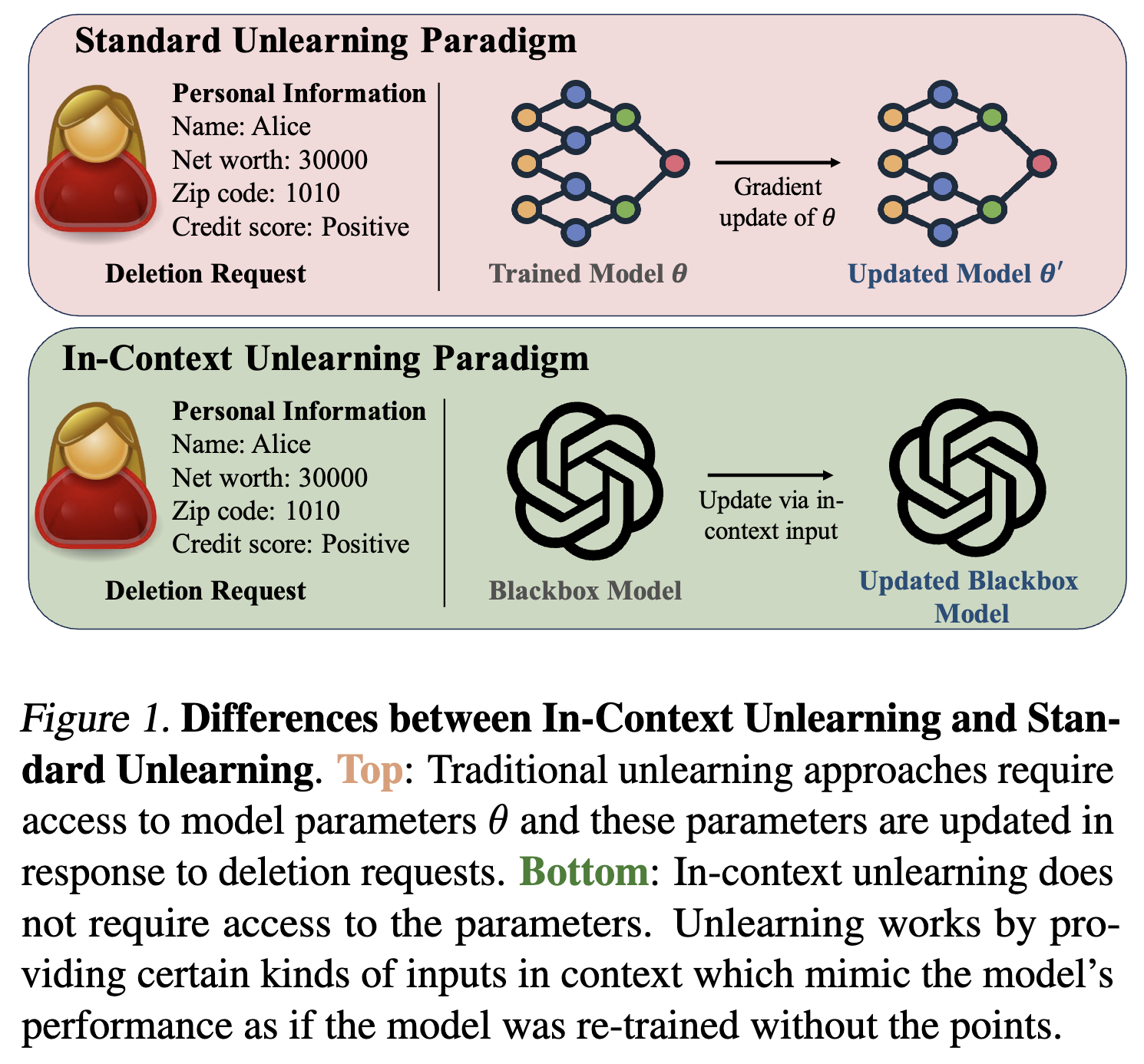
Figure 1:上下文内遗忘与标准遗忘的差异
- 传统遗忘(Standard Unlearning):在机器学习中,当需要从模型中删除特定数据(比如用户要求删除自己的个人信息数据)时,传统的做法是基于梯度更新模型参数(图中“Gradient update of 𝜃”)。假设我们有一个已经训练好的模型,它的参数是𝜃,当收到数据删除请求后,就需要根据这些请求来更新模型的参数,得到新的参数𝜃′,以此来消除被删除数据对模型的影响。但这种方法有个很大的问题,对于像大语言模型这样参数超多的模型来说,更新参数的计算量极大,实际操作起来非常困难。
- 上下文内遗忘(In - Context Unlearning):这是本文提出的新方法。它不需要直接去更新模型的参数。当有数据删除请求时,只需要在模型进行推理(也就是使用模型做预测)的时候,给模型输入特定的内容(即“Update via in - context input”),让模型表现得好像在训练时从未见过要删除的数据一样。这就好比给模型营造了一种“记忆错觉”,让它“忘记”某些数据,而不用去改动模型本身的参数,大大降低了计算的复杂度。

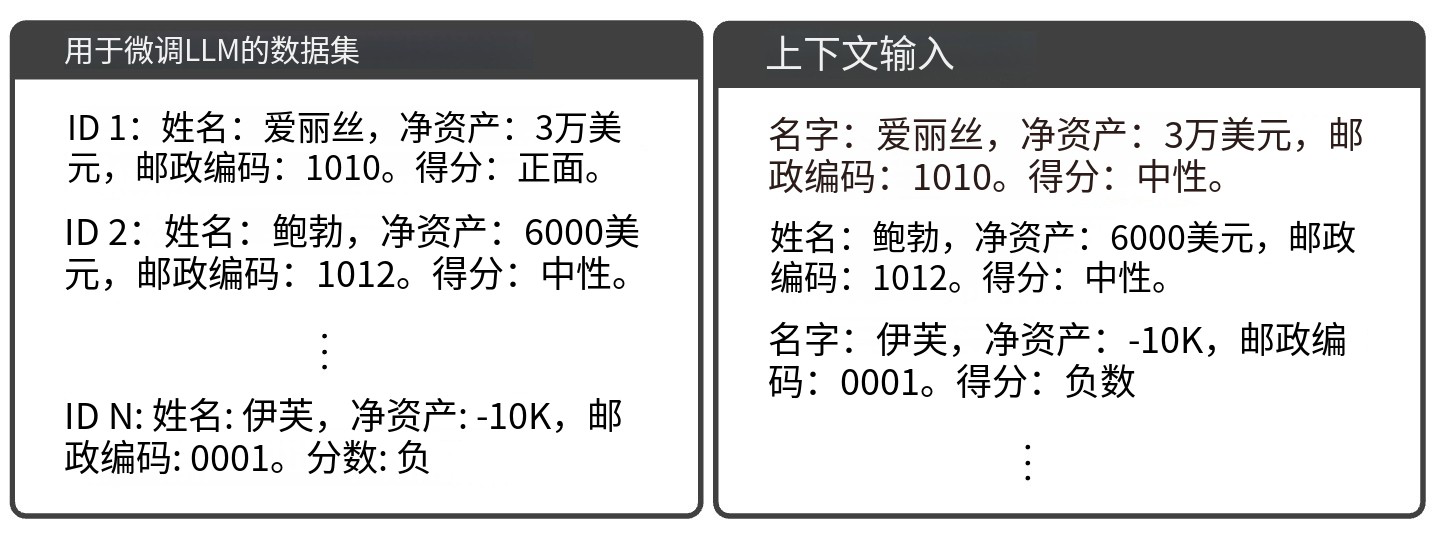
Figure 2:上下文内遗忘的示例
- 训练数据集(Dataset used to finetune LLM):这是用来微调大语言模型的数据集合。里面包含很多数据样本,每个样本都有不同的属性和标签。例如,有个样本ID 1,名字叫Alice,净资产是30K,邮编是1010,信用评分是Positive。还有其他样本,像ID 2的Bob、ID N的Eve等,各自有不同的属性和标签值。这些数据在训练模型时,会让模型学习到不同数据特征和标签之间的关系。
- 上下文输入(In - Context Input):当我们想要使用上下文内遗忘方法让模型“忘记”某些数据时,就会构建这样的上下文输入。比如,我们想让模型忘记Alice这个样本对它的影响,就把Alice的信息作为输入,但把她的标签从Positive改成Neutral(随机改变标签)。同时,还会加入其他样本(如Bob和Eve)的信息及标签(这里标签也可以根据情况调整)。这样的输入会让模型在推理时,减少之前Alice这个样本对结果的影响,从而达到“遗忘”的效果。