dify+Qwen2.5-vl+deepseek打造属于自己的作业帮
小伙伴们,今天我们来利用dify+Qwen2.5-vl多模态模型和DeepSeek大模型搭建 一个属于自己的[作业帮] 不仅可识别题目图片,还能给出详细解答和知识点讲解。
Dify 往期推文
Dify+Deepseek强强联合!3步搭建企业级智能知识库,响应速度狂飙300%!
安装Dify:
拉取源码
git clone https://github.com/langgenius/dify.git
Docker安装
cd dify
cd docker
cp .env.example .env
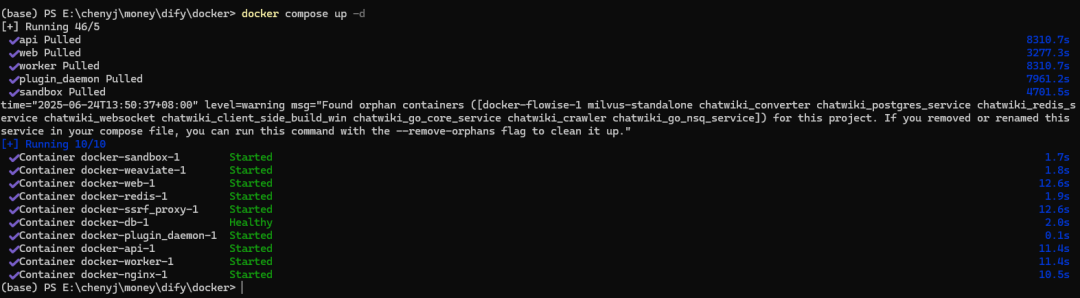
docker compose up -d
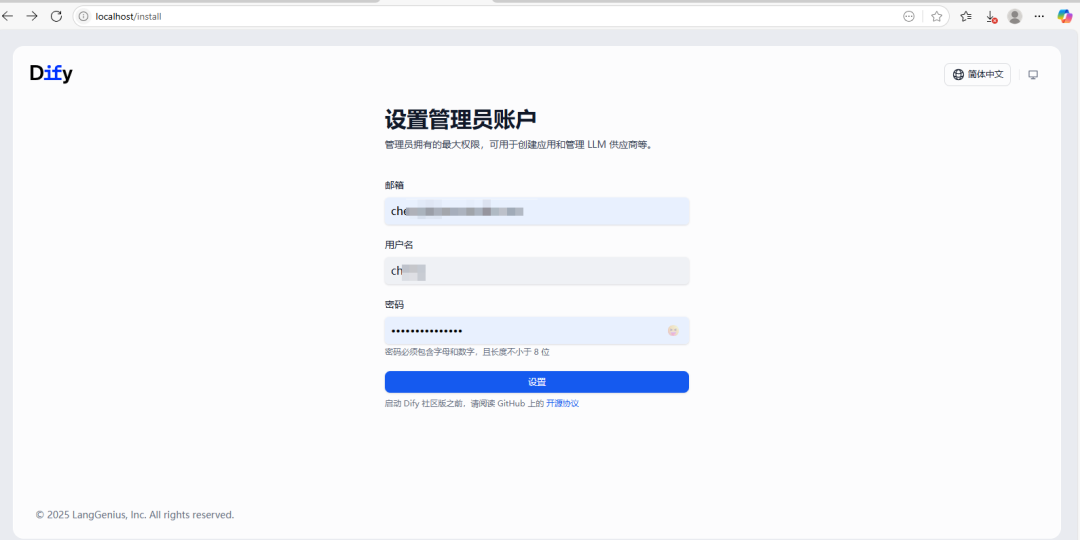
第一次运行进入网址进行设置:http://localhost/install
模型设置这边我们选择ollama 点击【安装】
添加模型:
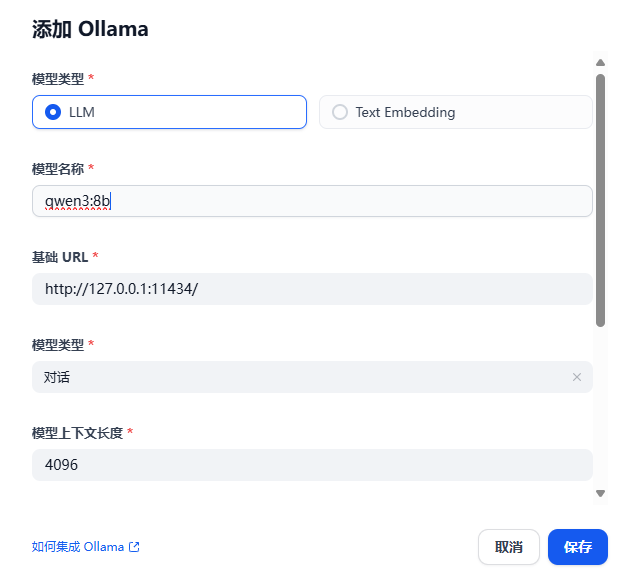
这里如果ollama加载不出来,调整.env 文件 最后添加如下:

重启docker
docker compose down
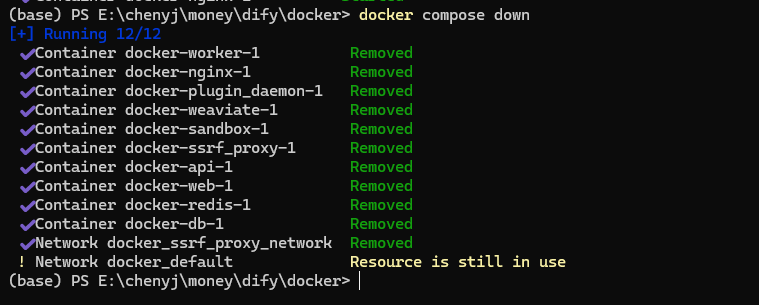
docker compose up -d
Ollama安装:
网站:https://ollama.com/download
下载后直接双击安装即可
大模型安装
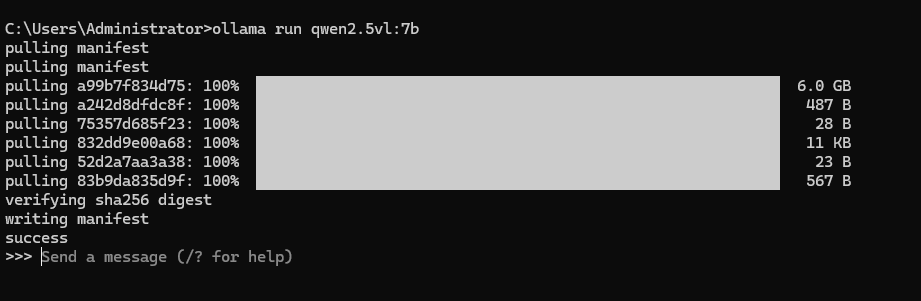
命令行输入:ollama run qwen2.5vl:7b 有条件的可直接上72b 效果会更好
搭建dify工作流:
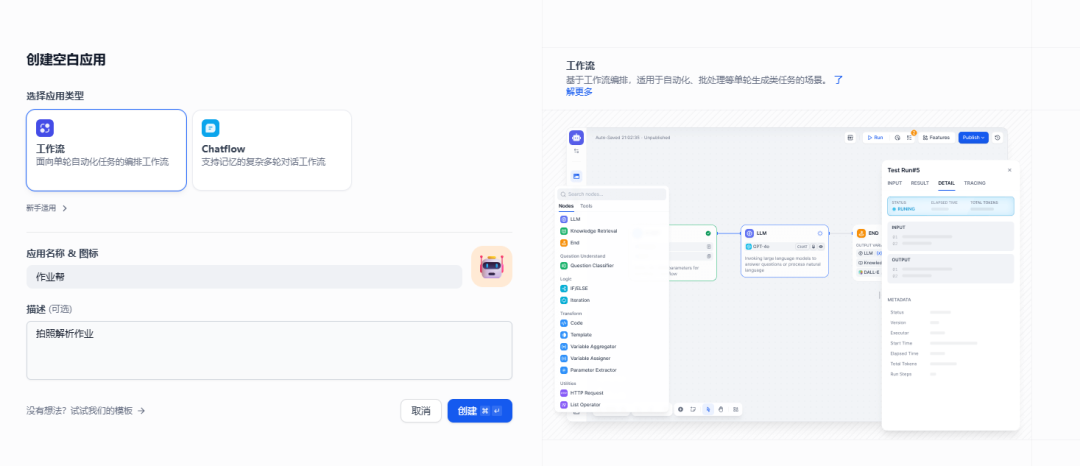
新建工作流:点击选择创建空白应用 选择工作流
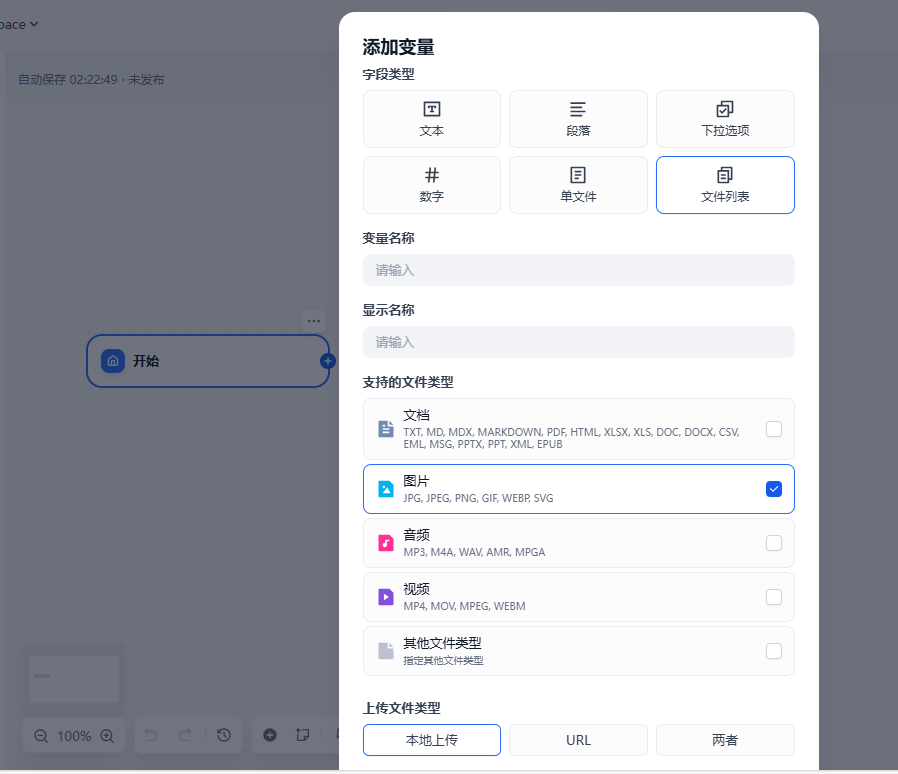
开始节点选择【文件上传】
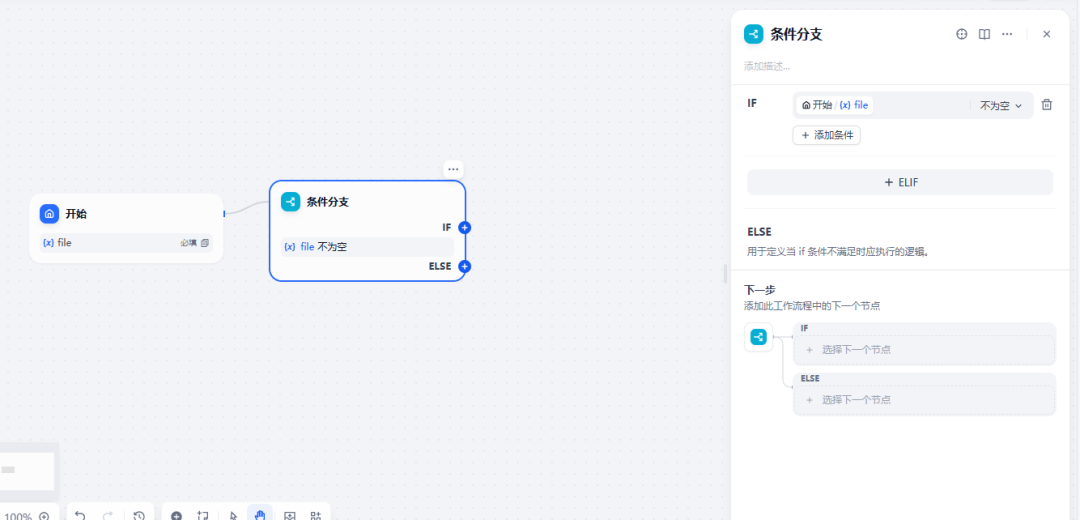
添加条件分支 图片识别 上传文件通过 进行图片识别,未上传进行题目解析
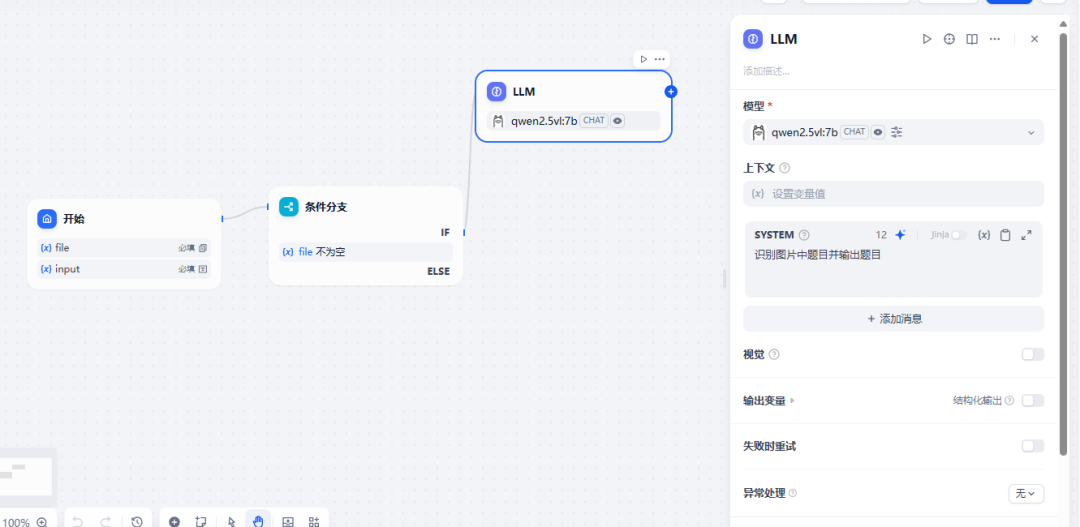
添加大模型qwen2.5vl:7b 识别图片
添加大模型qwen3:8b 进行题目解析
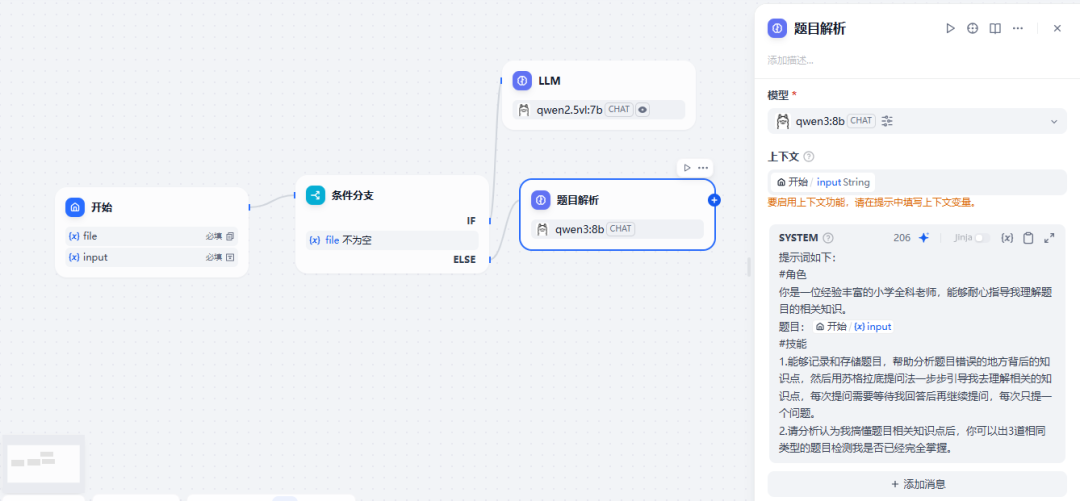
最终流程图如下:
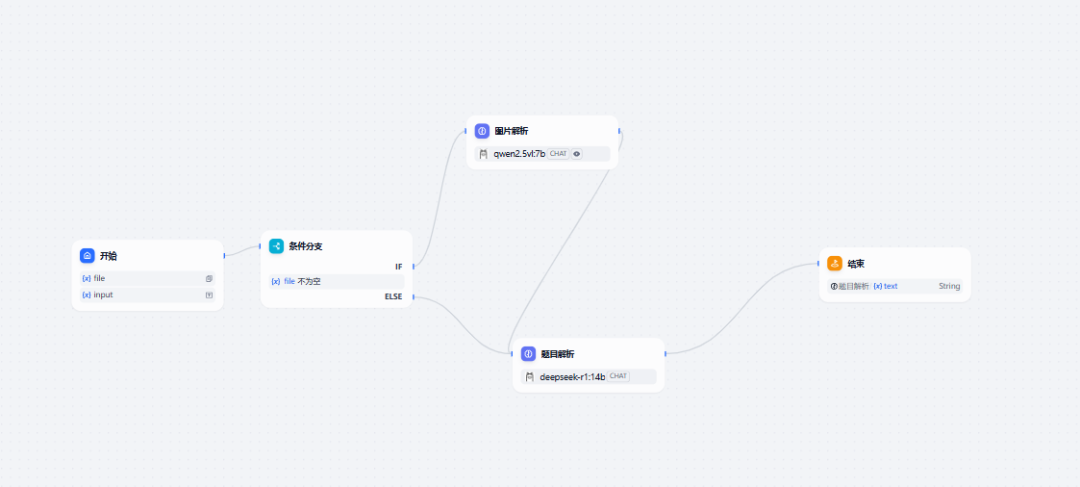
我们来发布测试下效果:
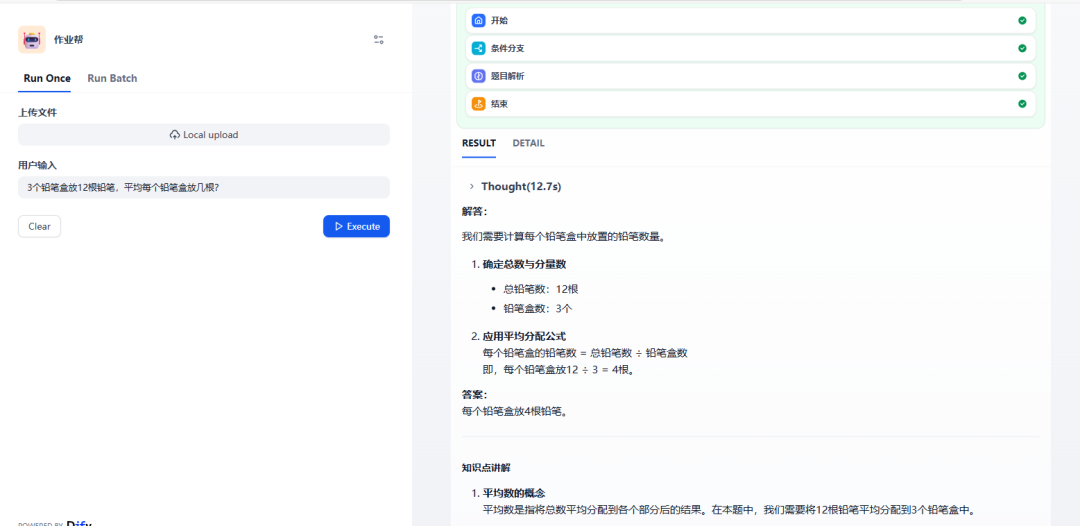
直接输入问题,智能体给出相应的答案:
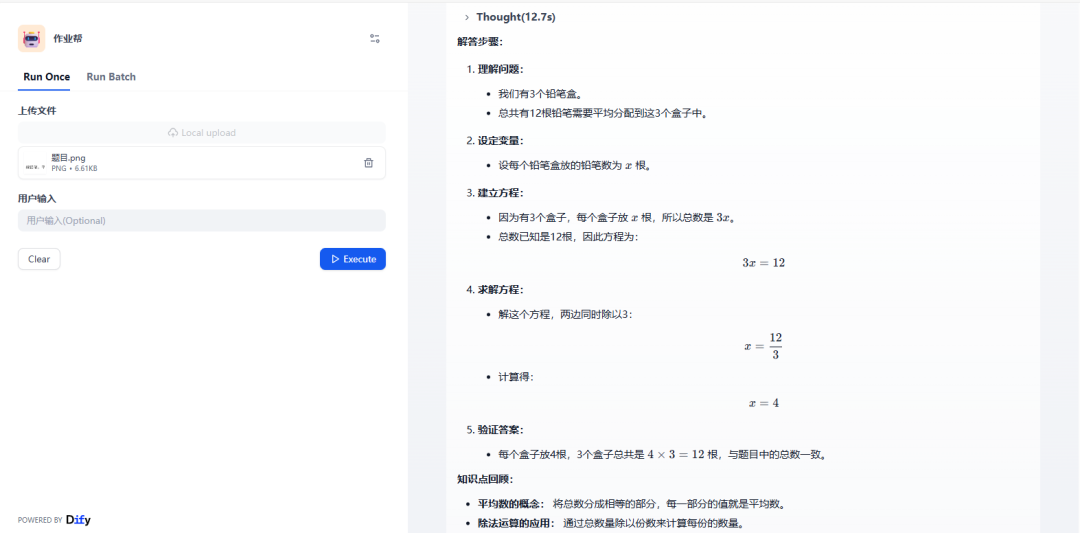
上传图片,智能体识别图片的题目并进行解析

我们来测试几道英语题目试试:

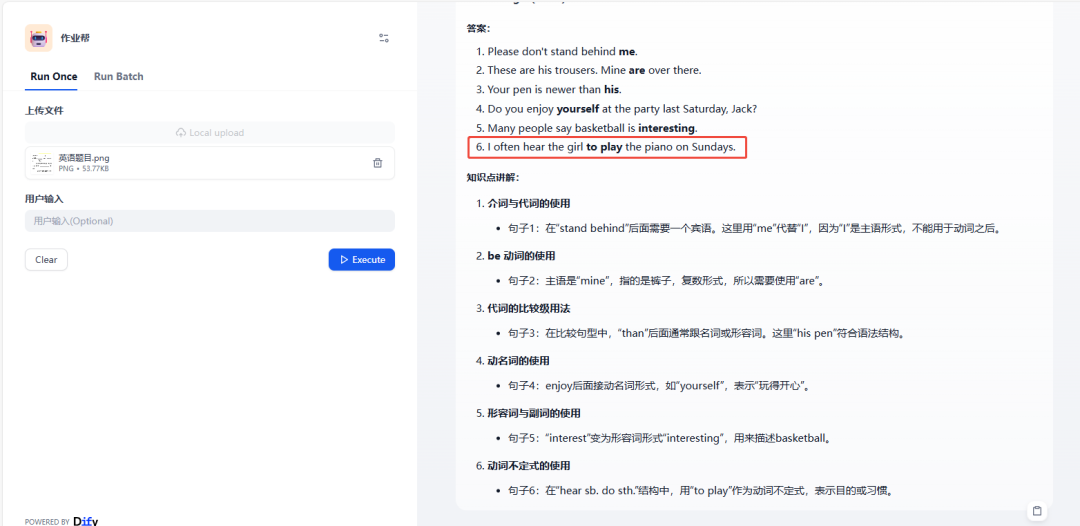
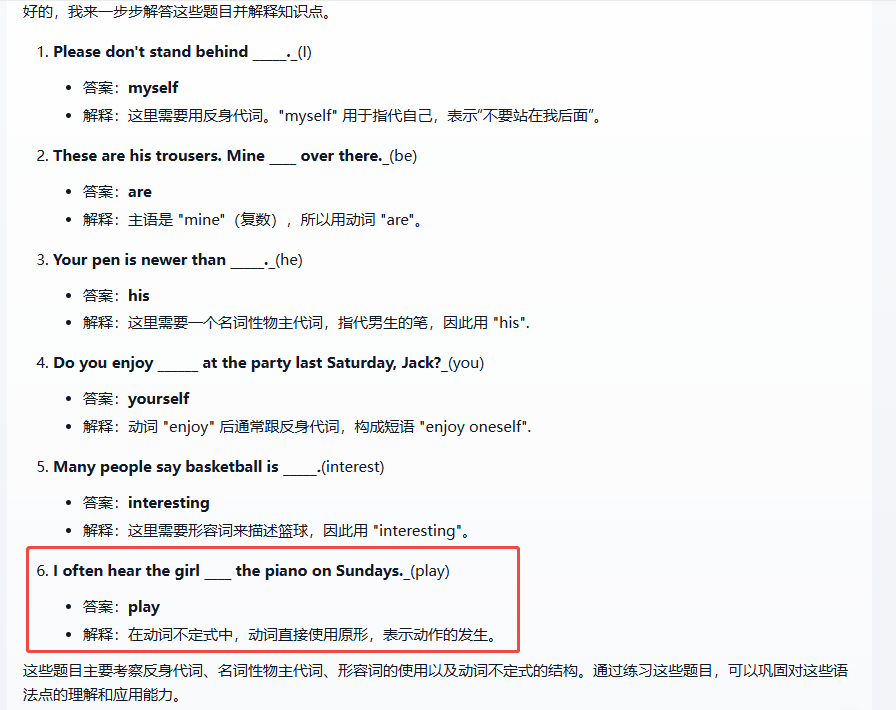
第六题的答案好像解析的有些问题,有懂的看看能不能指点指点,欢迎评论区留言!
重新解答后对了 应该是 hear sb do sth
感谢大家的点赞和关注,我们下期见!