命令行小工具
命令行小工具详解:cut、sort、uniq、tr 及其实用组合
- 前言
- 一、 cut —— 按列或字符截取
- 常用选项
- 实际应用示例
- 1.1. **提取用户信息**:
- 1.2. **字符级截取**:
- 使用注意
- 二、sort —— 排序工具
- 实际应用示例
- 2.1. **基础排序**:
- 使用技巧
- 三、uniq —— 去除重复行
- 常用选项
- 实际应用示例
- 3.1. **基础去重**:
- 3.2. **组合使用**:
- 3.3. **实际案例**:
- 使用注意
- 四、tr —— 字符转换与处理
- 常用选项
- 实际应用示例
- 4.1. **字符转换**:
- 4.2. **字符替换**:
- 4.3. **字符删除与压缩**:
- 使用技巧
- 五、常见组合应用案例
- ① 统计当前连接的主机数
- ② 统计当前主机的连接状
- ③ 查看当前登录用户
- ④ 查看登录过系统的用户
- 6. 总结口诀
- 结语
前言
在日常的系统管理和文本处理工作中,我们经常需要对文本数据进行各种操作,如截取特定列、排序、去重或字符替换等。Linux/Unix 系统提供了一系列强大的命令行工具来帮助我们高效完成这些任务。本文将详细介绍四个最常用的文本处理工具:cut、sort、uniq 和 tr,并通过丰富的示例展示它们的实际应用场景。这些工具虽然简单,但组合使用时能解决许多复杂的数据处理问题,是每个系统管理员和开发者必备的技能。
一、 cut —— 按列或字符截取
cut 命令是专门用于从文本中提取特定列或字符的工具,特别适合处理结构化文本数据(如以特定分隔符分隔的字段)。
常用选项
| 选项 | 含义 |
|---|---|
-b | 按字节截取 |
-c | 按字符截取(处理中文时推荐使用) |
-d | 指定分隔符(默认为制表符 TAB) |
-f | 指定要提取的字段(需要配合 -d 使用) |
实际应用示例
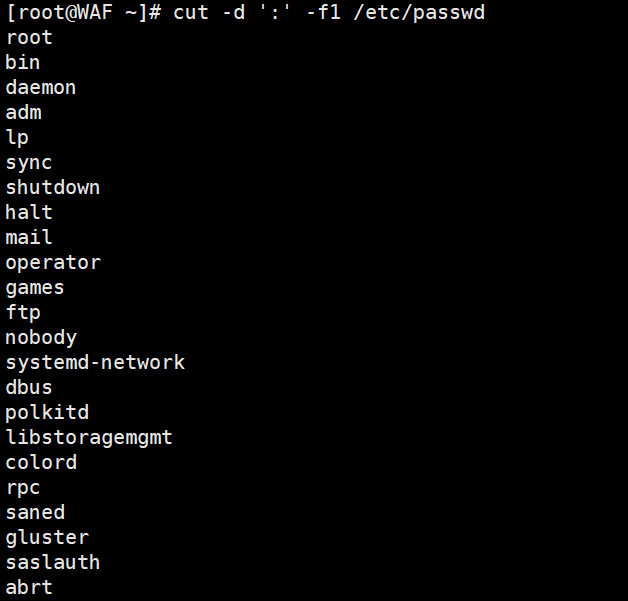
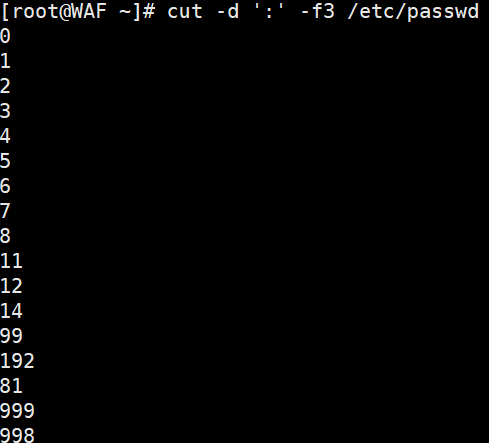
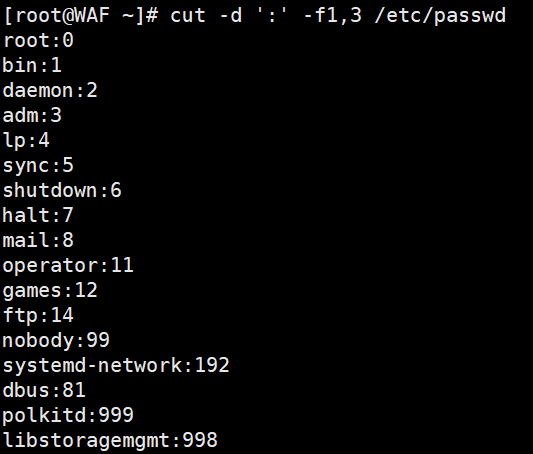
1.1. 提取用户信息:
# 提取/etc/passwd文件中的用户名(第1列)cut -d':' -f1 /etc/passwd# 提取用户ID(第3列)cut -d':' -f3 /etc/passwd# 同时提取用户名和用户IDcut -d':' -f1,3 /etc/passwd
1.2. 字符级截取:
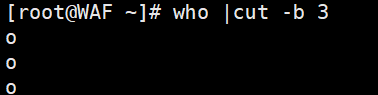
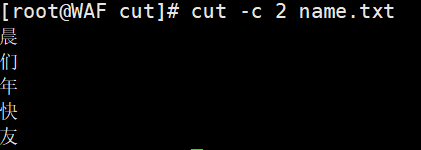
# 提取who命令输出的第3个字节who | cut -b 3# 提取name.txt文件的第2个字符(适合中文)cut -c 2 name.txt# 使用 cut -c 2 可以准确提取中文字符
使用注意
cut 特别适合处理以单个字符为间隔的文本数据,对于复杂的字段结构可能需要结合其他工具使用。
二、sort —— 排序工具
sort 命令用于对文本行进行排序,默认按行首字符的字典序升序排列,但提供了丰富的选项来满足各种排序需求。
| 选项 | 含义 |
|---|---|
-t | 指定字段分隔符 |
-k | 指定排序的字段 |
-n | 按数值大小排序(而非字典序) |
-r | 降序排列 |
-u | 去除重复行(等同于 uniq) |
-o | 将排序结果输出到指定文件 |
实际应用示例
2.1. 基础排序:
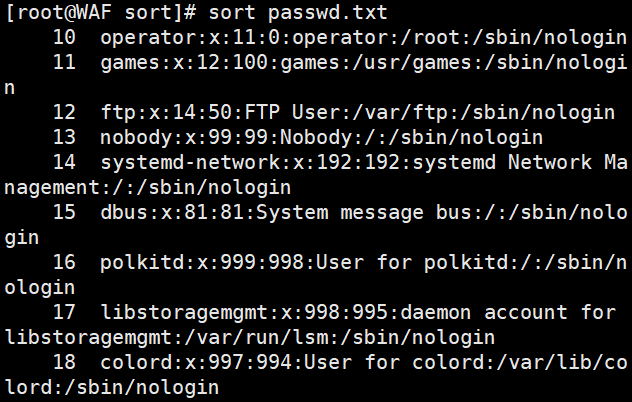
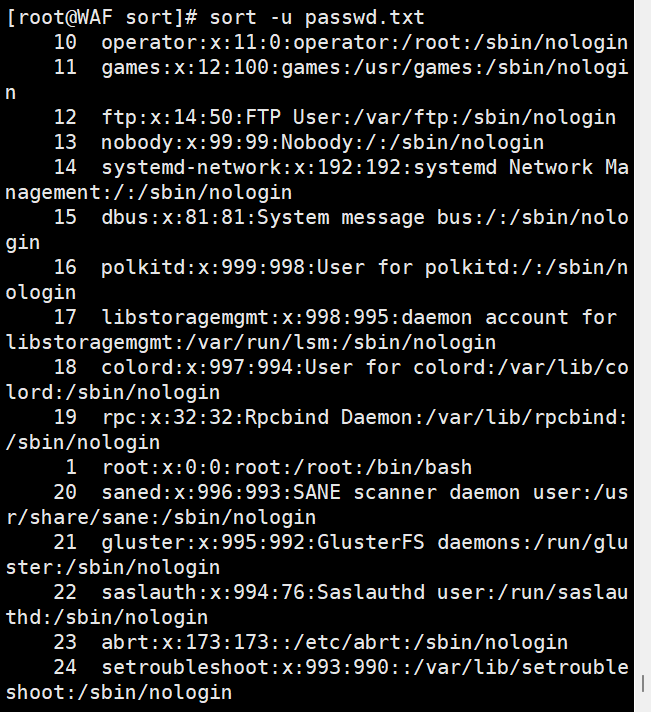
# 按默认顺序排序文件内容
sort passwd.txt
```
#### 2.2. **高级排序**:
```bash
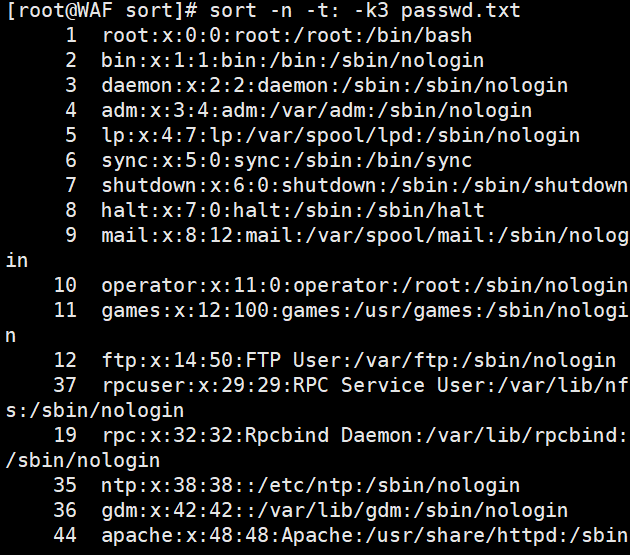
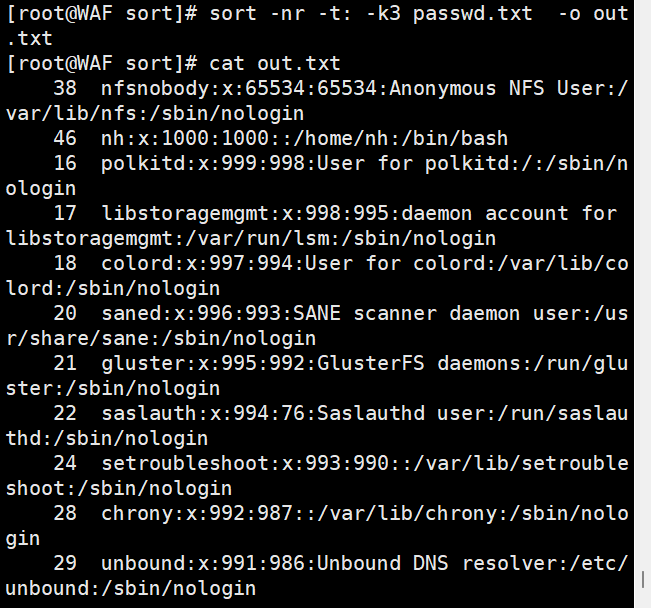
# 以冒号分隔,按第3列数值升序排序
sort -n -t: -k3 passwd.txt
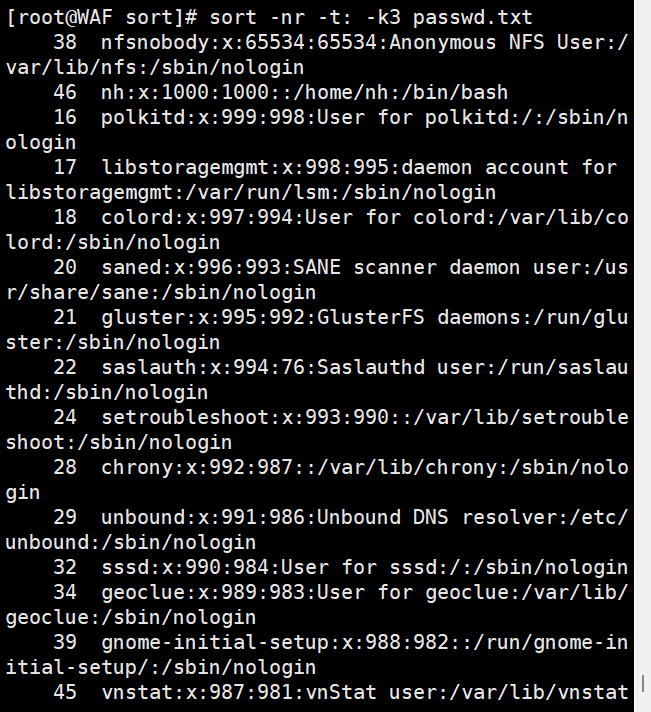
# 按第3列数值降序排序
sort -nr -t: -k3 passwd.txt
# 排序并去重
sort -u passwd.txt
# 排序结果保存到文件
sort -nr -t: -k3 passwd.txt -o out.txt
使用技巧
通过 -t 和 -k 选项的组合,可以灵活地按照文本的特定部分进行排序,这在处理日志文件或数据记录时特别有用。
三、uniq —— 去除重复行
uniq 命令用于去除连续的重复行,通常需要与 sort 命令配合使用才能实现全局去重。
常用选项
| 选项 | 含义 |
|---|---|
-c | 统计每行出现的次数 |
-d | 只显示重复的行 |
-u | 只显示唯一的行 |
实际应用示例
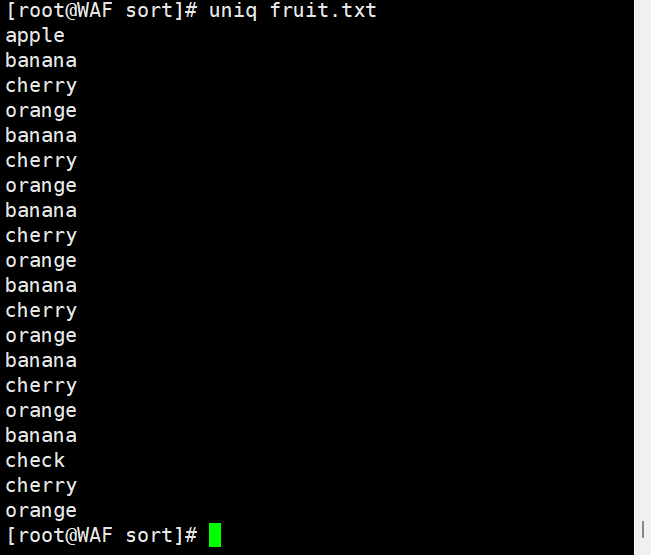
3.1. 基础去重:
# 去除相邻的重复行uniq fruit.txt
3.2. 组合使用:
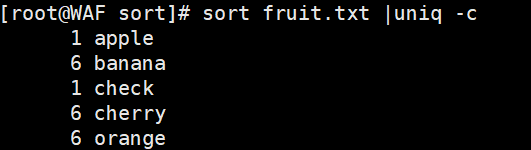
# 全局去重(先排序再去重)sort fruit.txt | uniq# 统计每行出现次数sort fruit.txt | uniq -c# 只显示重复行sort fruit.txt | uniq -d# 只显示唯一行sort fruit.txt | uniq -u

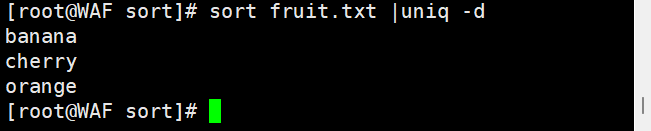

3.3. 实际案例:
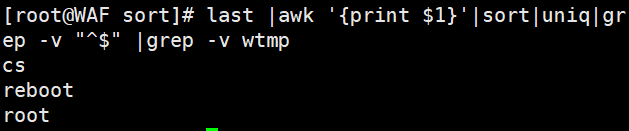
# 查看当前登录用户(去重)who | awk '{print $1}' | uniq# 查看登录过系统的所有用户(去重)last | awk '{print $1}' | sort | uniq | grep -v "^$" | grep -v wtmp

使用注意
uniq 只能去除相邻的重复行,因此通常需要先使用 sort 进行排序,然后再使用 uniq 去重。
四、tr —— 字符转换与处理
tr 命令用于对字符进行转换、删除或压缩,主要处理单个字符,不适合字段级别的操作。
常用选项
| 选项 | 含义 |
|---|---|
-d | 删除指定的字符 |
-s | 压缩重复的字符(只保留一个) |
实际应用示例
4.1. 字符转换:
# 将小写字母转换为大写字母tr 'a-z' 'A-Z' < fruit.txt# 或者cat fruit.txt | tr 'a-z' 'A-Z'
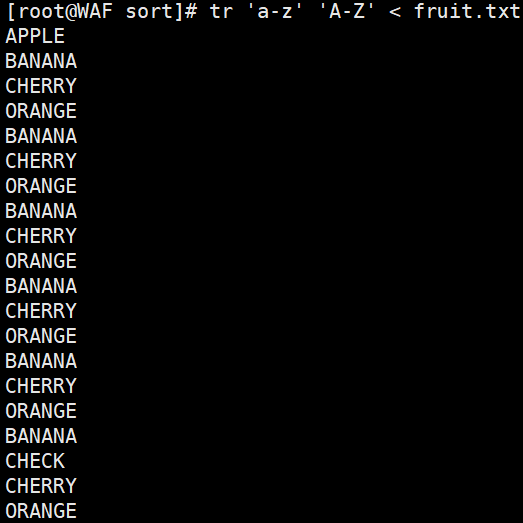
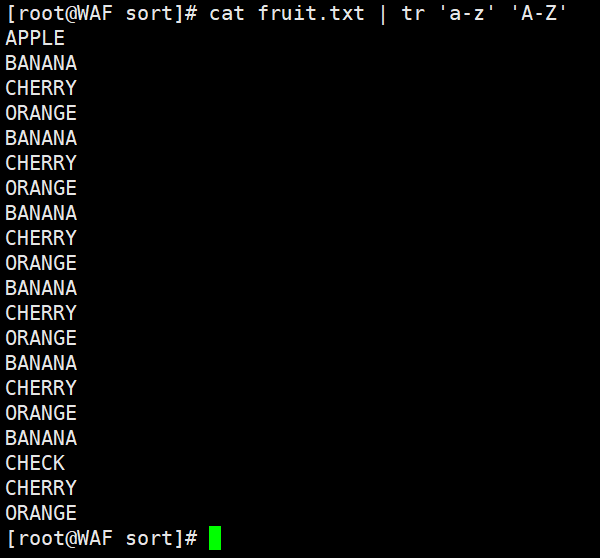
4.2. 字符替换:
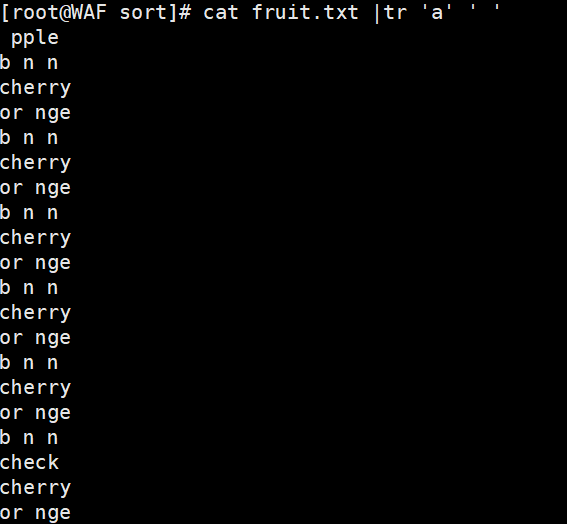
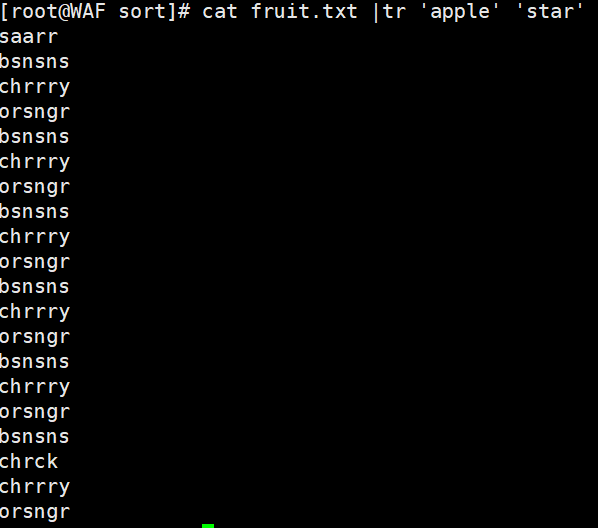
# 替换单个字符cat fruit | tr 'a' ' '# 多个字符替换(一一对应)cat fruit | tr 'apple' 'star'
4.3. 字符删除与压缩:
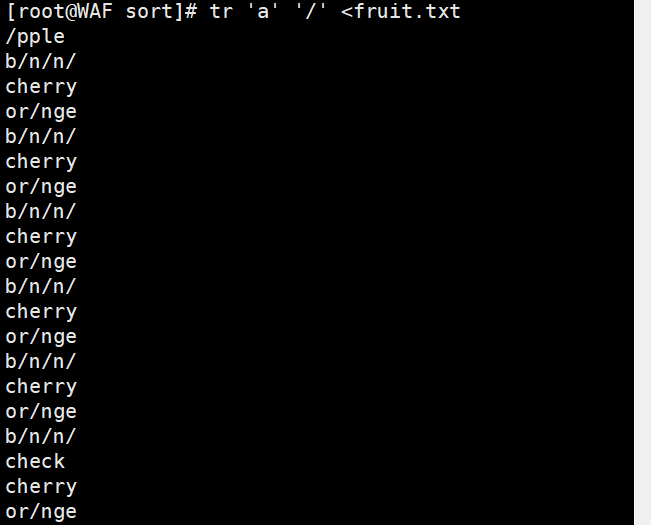
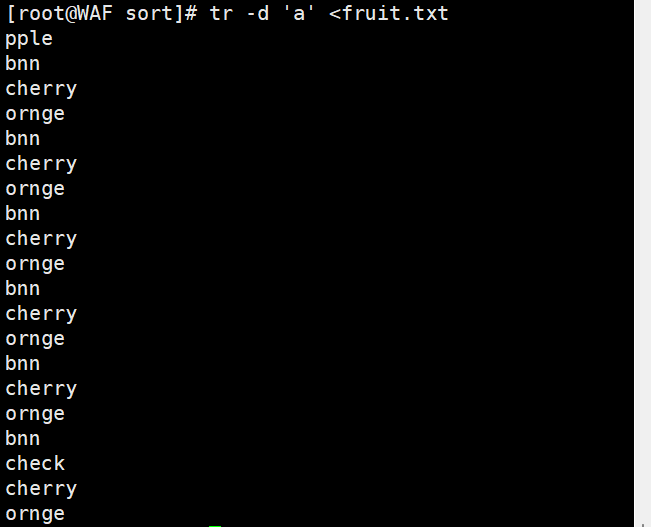
# 删除所有'a'字符tr 'a' '/' < fruit.txttr -d 'a' < fruit.txt# 删除所有换行符tr -d '\n' < fruit.txt# 压缩连续的相同字符tr -s 'p' < fruit.txt

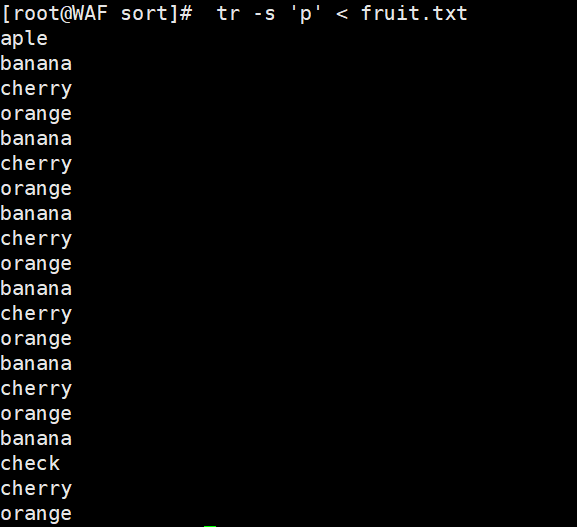
使用技巧
tr 非常适合进行简单的字符级文本处理,如大小写转换、特殊字符删除等操作。
五、常见组合应用案例
这些工具经常组合使用来解决实际问题,以下是几个典型的组合应用场景:
① 统计当前连接的主机数
ss -nt | tr -s " " | cut -d " " -f5 | cut -d ":" -f1 | sort | uniq -c

步骤解析:
ss -nt:查看TCP连接tr -s " ":压缩多个空格为单个空格cut -d " " -f5:提取第5列(对端地址:端口)cut -d ":" -f1:提取IP地址部分sort:排序使相同IP相邻uniq -c:统计每个IP的出现次数
② 统计当前主机的连接状
ss -nta | grep -v '^State' | cut -d" " -f1 | sort | uniq -c
③ 查看当前登录用户
who | awk '{print $1}' | uniq
④ 查看登录过系统的用户
last | awk '{print $1}' | sort | uniq | grep -v "^$" | grep -v wtmp
6. 总结口诀
为了便于记忆这些工具的主要功能,可以使用以下口诀:
- cut —— 截列(提取特定列或字符)
- sort —— 排序(对文本行进行排序)
- uniq —— 去重(去除相邻重复行,常与sort配合)
- tr —— 替换 / 删除 / 压缩(字符级处理)
结语
掌握这些基础的命令行文本处理工具,可以极大地提高我们在Linux/Unix环境下的工作效率。cut、sort、uniq 和 tr 虽然各自功能单一,但通过灵活组合,能够解决各种复杂的数据处理问题。无论是系统管理、日志分析还是日常文本处理,这些工具都是不可或缺的利器。
建议读者通过实际操作来熟悉这些工具的使用,尝试对不同的文本数据应用各种选项组合,逐步掌握它们的强大功能。记住,熟能生巧,只有通过不断的实践,才能真正将这些工具内化为自己的技能。