Android中handler机制
一、Handler 机制概述:为什么要存在?
核心目的:解决多线程并发和线程切换的问题。
在 Android 中,主线程(UI 线程)负责处理用户交互和UI更新,绝对不允许在主线程中进行耗时操作(如网络请求、数据库读写),否则会引发 ANR。同时,Android 的 UI 工具包不是线程安全的,不允许在子线程中直接更新 UI。
因此,我们需要一种机制:在子线程中执行耗时任务,然后将结果发送回主线程进行UI更新。Handler 就是这个机制的基石。
Handler 机制的四大组件:
Message: 需要传递的消息,可以携带数据和标识。
MessageQueue: 一个按时间排序的优先级队列,用于存放所有通过 Handler 发送的 Message。
Looper: 循环器,负责不断地从 MessageQueue 中取出 Message,并分发到对应的 Handler 进行处理。
Handler: 处理者,负责发送 Message 到 MessageQueue,也负责处理从 Looper 分发过来的 Message。
它们的关系可以概括为:Handler 负责生产和消费,MessageQueue 是仓库,Looper 是永不疲倦的配送员。
二、底层细节深度剖析
1. Looper.prepare() 做了什么?(线程单例模式)
这是为当前线程创建 Looper 的关键方法。一个线程要想有消息循环,必须先调用 Looper.prepare()。
// Looper.java (简化代码)
public static void prepare() {prepare(true);
}private static void prepare(boolean quitAllowed) {// 1. 关键检查:每个线程只能有一个Looper!if (sThreadLocal.get() != null) {throw new RuntimeException("Only one Looper may be created per thread");}// 2. 创建Looper实例,并存入ThreadLocal中sThreadLocal.set(new Looper(quitAllowed));
}// ThreadLocal 是精髓所在。它为每个线程提供了一份独立的Looper副本,
// 实现了线程隔离,保证了每个线程的Looper互不干扰。
static final ThreadLocal<Looper> sThreadLocal = new ThreadLocal<Looper>();private Looper(boolean quitAllowed) {// 3. 创建了消息队列(MessageQueue)mQueue = new MessageQueue(quitAllowed);// 4. 记录当前线程mThread = Thread.currentThread();
}总结 Looper.prepare() 的职责:
检查当前线程是否已存在 Looper(保证单例)。
创建一个新的 Looper 对象。
在 Looper 构造方法中,创建了该线程核心的 MessageQueue。
将 Looper 实例存入 ThreadLocal,与当前线程绑定。
主线程的 Looper 是谁创建的?
ActivityThread.main() 方法(App 的入口点)已经自动调用了 Looper.prepareMainLooper() 和 Looper.loop(),所以我们无需也不能为主线程手动创建。
2. 消息队列(MessageQueue)是什么数据结构?
MessageQueue 的内部实现不是一个简单的 LinkedList 或 Queue,而是一个基于最小堆(Min-Heap)的优先级队列,按 Message.when(消息的处理时间)的大小进行排序。
when是一个 long 型的时间戳,表示消息应该被处理的时间点。延迟消息:
when = SystemClock.uptimeMillis() + delayMillis。即时消息:
when = SystemClock.uptimeMillis()。
为什么用优先级队列?
为了高效地处理大量按时间排序的消息。每次入队(enqueueMessage)都需要根据 when 找到合适的插入位置;而出队(next)总是取 when 最小的消息(即最先需要处理的消息)。最小堆的时间复杂度为 O(log n),效率很高。
3. 对于一个线程的多个 Handler,怎么和 Looper 绑定?
答案:所有属于同一个线程的 Handler,共享同一个 Looper 和同一个 MessageQueue。
创建 Handler 时,它会通过 ThreadLocal 获取到当前线程的 Looper 和其对应的 MessageQueue。
// Handler.java (简化代码)
public Handler(@Nullable Callback callback, boolean async) {...// 关键:获取当前线程的LoopermLooper = Looper.myLooper();if (mLooper == null) {throw new RuntimeException("Can't create handler inside thread that has not called Looper.prepare()");}// 获取该Looper对应的消息队列mQueue = mLooper.mQueue;...
}绑定过程:
你在线程 A 中调用
Looper.prepare(),为线程 A 创建了唯一的 Looper 和 MessageQueue。在线程 A 中创建 Handler1、Handler2、Handler3...
这些 Handler 在构造时,都会通过
Looper.myLooper()拿到线程 A 的那个唯一的 Looper 实例。因此,所有这些 Handler 的
mQueue都指向同一个 MessageQueue。
消息如何区分是哪个 Handler 的?
每个 Message 对象都有一个 target 字段,在发送时就被设置为发送它的 Handler。
// Handler.java
private boolean enqueueMessage(MessageQueue queue, Message msg, long uptimeMillis) {msg.target = this; // 关键!将消息的target指向自己return queue.enqueueMessage(msg, uptimeMillis);
}当 Looper 从 MessageQueue 中取出一个 Message 后,会调用 msg.target.dispatchMessage(msg),将消息分发给正确的 Handler 进行处理。
4. 延迟发送消息(如 postDelayed)是怎么实现的?
答案:不是靠定时器,而是基于消息的触发时间和当前时间的比较,结合 Linux 的 epoll 机制进行休眠等待。
这是一个非常常见的误解。延迟消息并没有单独开一个计时线程。其核心流程在 MessageQueue 的 next() 方法中:
入队时计算时间:当你调用
handler.postDelayed(runnable, 1000),Handler 会计算:Message msg = Message.obtain(); msg.callback = runnable; long when = SystemClock.uptimeMillis() + 1000; // 当前时间 + 延迟时间 queue.enqueueMessage(msg, when);MessageQueue 会根据这个
when的时间,将消息插入到队列的合适位置。出队时检查阻塞:Looper 在循环调用
queue.next()取消息时:// MessageQueue.next() (简化概念) Message next() {for (;;) {...// 1. 如果队列为空,或者第一条消息是延迟消息,则计算需要休眠的时间if (msg != null) {if (now < msg.when) { // 当前时间还没到消息的处理时间nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);} else {// 时间到了,返回这个消息return msg;}} else {// 队列为空,无限休眠nextPollTimeoutMillis = -1;}// 2. 核心:在此处进行 nativePollOnce(ptr, nextPollTimeoutMillis) 休眠// 这是一个JNI调用,底层使用Linux的epoll机制挂起线程,释放CPU资源nativePollOnce(ptr, nextPollTimeoutMillis);// 3. 当休眠时间到,或有新消息以更早的时间插入(会唤醒线程),则继续循环...} }
流程图:延迟消息与消息循环
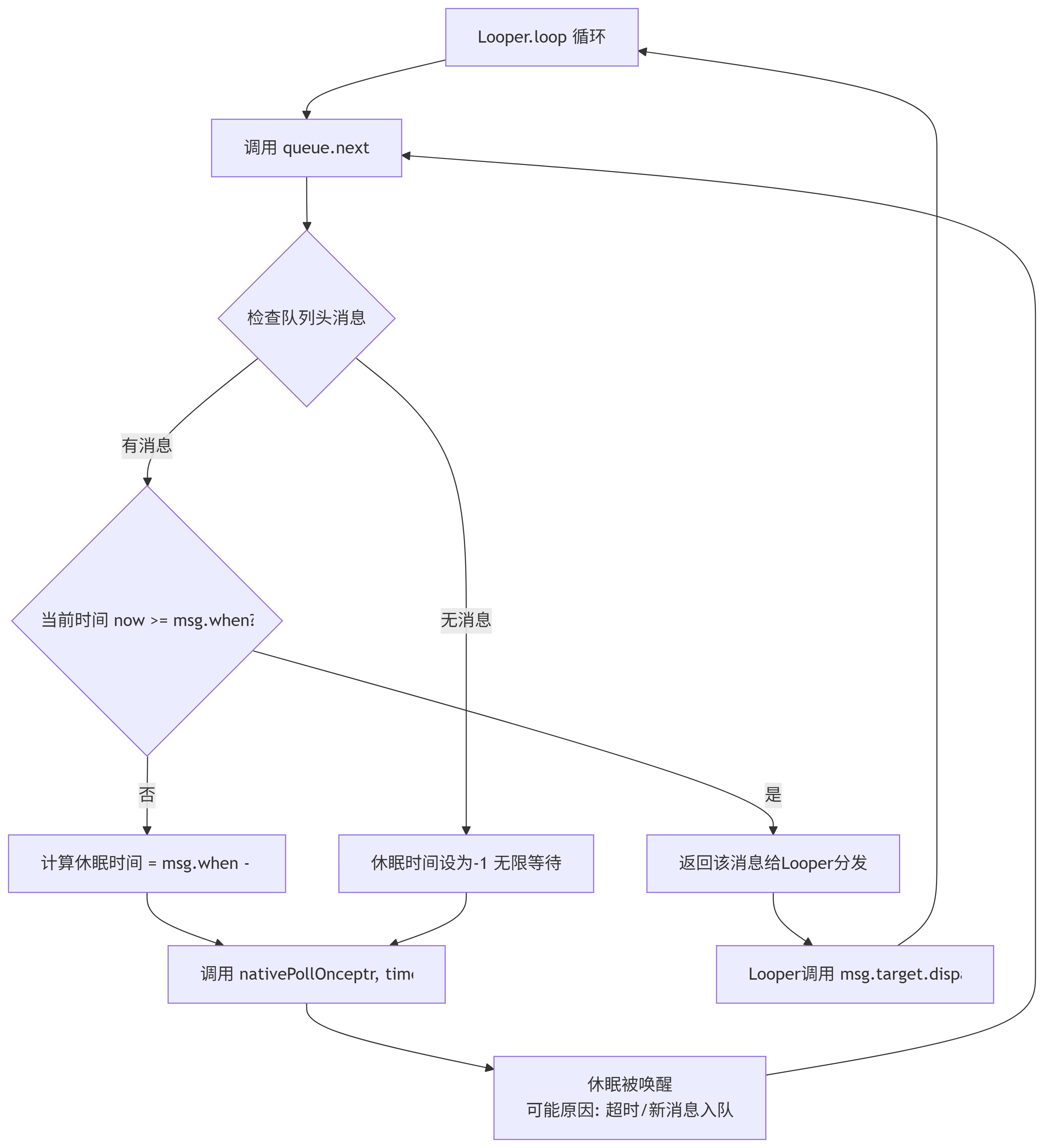
关键点:
精准性:延迟时间并不非常精确,因为它受消息队列中前面消息处理耗时的影响。如果前面有一个耗时10秒的操作,你的延迟消息至少要在10秒后才会被执行。
唤醒机制:如果有一个新的、触发时间更早的消息被插入队列,
enqueueMessage方法会调用nativeWake来唤醒休眠的线程,重新计算休眠时间。
三、Handler 的工作流程
整个 Handler 机制的工作流程可以完美地形成一个闭环,其核心驱动是 Looper.loop() 中的死循环。这个过程可以通过下面的流程图清晰地展现:
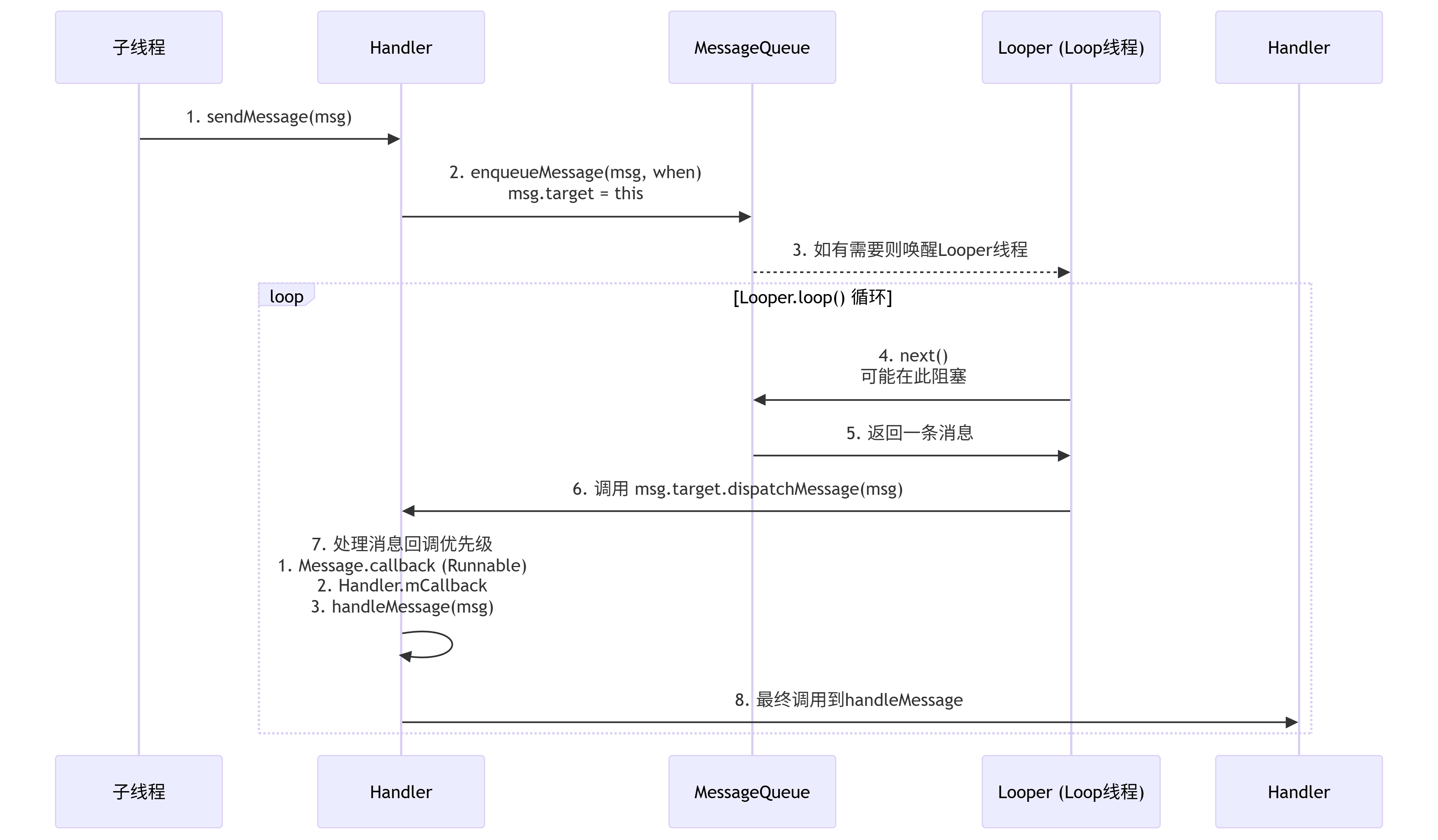
消息发送:子线程通过
Handler.sendMessage(msg)或post(Runnable)发送消息。post(Runnable)内部其实是将 Runnable 包装成一个Message的callback字段。消息入队:Handler 将消息放入它绑定的 MessageQueue 中,并设置
msg.target = this。消息循环:Looper 在
loop()方法中开启一个无限循环,不断地调用MessageQueue.next()取消息。消息阻塞:如果队列为空,
next()方法会通过nativePollOnce()挂起线程,释放 CPU;如果有消息但未到处理时间,则计算休眠时间。消息分发:当有消息需要处理时,
next()返回该消息。Looper 调用msg.target.dispatchMessage(msg),即回调到发送该消息的 Handler 的方法。消息处理:Handler 的
dispatchMessage方法会按优先级处理消息:如果
Message本身有callback(一个 Runnable 对象),则执行callback.run()。否则,如果 Handler 构造时传入了
Callback接口,则执行Callback.handleMessage(msg)。如果以上都没有,则调用我们通常重写的
handleMessage(msg)方法。此时代码逻辑已切换回 Looper 所在的线程(如主线程)。
四、常见问题总结
Q:“能详细讲讲 Android 的 Handler 机制吗?”
A:
“Handler 机制是 Android 的异步消息处理核心,主要由 Message、MessageQueue、Looper 和 Handler 四部分组成,解决了子线程与主线程的通信问题。
首先,Looper 是消息循环的核心。每个需要处理消息的线程都必须先调用 Looper.prepare() 来创建唯一的一个 Looper 和它内部的一个 MessageQueue(消息队列)。Looper.prepare() 利用 ThreadLocal 保证了线程与 Looper 的一对一关系。然后调用 Looper.loop() 进入一个无限循环,不断地从 MessageQueue 中取消息。
MessageQueue 不是一个简单的队列,而是一个按消息处理时间(when)排序的优先级队列,其底层是最小堆结构,保证了取出的消息总是时间最早的那个。
一个线程可以创建多个 Handler。它们通过 Looper.myLooper() 获取到当前线程的 Looper,从而都绑定到同一个 MessageQueue 上。区分消息来自哪个 Handler 是靠 Message 的 target 字段,它在发送时就被指向了发送它的 Handler。
延迟消息的实现并非靠定时器。发送时,会计算消息的绝对处理时间 when = currentTime + delayTime 并插入队列。Looper 在取消息时,如果队首消息还没到时间,就调用 nativePollOnce() 进行精确时间的休眠,释放 CPU。这是一种高效的空闲等待机制。
最后的工作流程是一个闭环:子线程通过 Handler 发送 Message 到 MessageQueue 中,Looper 的循环不断取消息,并回调给 msg.target(即发送消息的 Handler) 的 dispatchMessage 方法,最终将处理逻辑切换回 Looper 所在的目标线程,完成了线程间的通信。”
Q:“Handler 是怎么知道它要在哪个目标线程执行任务的?”
A:
“Handler 并不直接知道目标线程,而是通过与目标线程的 Looper 绑定来间接确定的。
其核心机制是 ThreadLocal。创建 Handler 时,它的构造方法会调用 Looper.myLooper()。这个方法通过 ThreadLocal 内部获取到的是当前代码执行线程所对应的 Looper。因此,Handler 在哪个线程被创建,它绑定的就是哪个线程的 Looper。
一旦绑定完成,这个 Handler 的 mLooper 和 mQueue 字段就固定了。无论之后在哪个线程调用 handler.sendMessage(),消息都会被放入这个绑定的 MessageQueue 中。
而目标线程的 Looper 一直在运行 loop() 循环,它只从自己的 MessageQueue 里取消息。取到消息后,调用 msg.target.dispatchMessage(msg)(msg.target 就是发送它的 Handler),这些代码是运行在 Looper 所在的线程,也就是最初创建 Handler 的那个目标线程的。这样就完成了线程的切换。
所以,总结起来就是:Handler 通过 ThreadLocal 在创建时与当前线程的 Looper 永久绑定,从而确定了未来处理消息的场所。”