跟踪不稳定目标:基于外观引导的运动建模实现无人机视频中的鲁棒多目标跟踪
摘要
https://arxiv.org/pdf/2508.01730v1
多目标跟踪(MOT)旨在跟踪多个目标,同时在给定视频的帧之间保持一致的身份标识。在无人机(UAV)录制的视频中,频繁的视角变化和复杂的无人机-地面相对运动动力学带来了重大挑战,这通常导致不稳定的亲和力测量和模糊的关联。现有方法通常分别对运动和外观线索进行建模,忽略了它们的时空相互作用,导致次优的跟踪性能。在本工作中,我们提出了AMOT,它通过两个关键组件联合利用外观和运动线索:外观-运动一致性(AMC)矩阵和运动感知轨迹延续(MTC)模块。具体来说,AMC矩阵在外观特征的指导下计算双向空间一致性,从而实现更可靠和上下文感知的身份关联。MTC模块通过与基于卡尔曼的预测相一致的外观引导预测重新激活未匹配的轨迹,从而减少由于漏检导致的轨迹断裂。在三个UAV基准测试(包括VisDrone2019、UAVDT和VT-MOT-UAV)上的大量实验表明,我们的AMOT优于当前最先进的方法,并以即插即用和无需训练的方式很好地泛化。源代码将发布。
1 引言
多目标跟踪(MOT)是一项基础的视觉任务,具有广泛的应用,如自动驾驶[1]和无人机(UAV)监控[2]。MOT的典型流程是首先检测多个目标,然后通过数据关联将每个检测结果分配给现有轨迹,确保轨迹身份随时间的连续性。尽管取得了进展,但稳健的数据关联仍然是一个挑战,特别是对于无人机搭载摄像头捕获的视频。
数据关联通常依赖于一个成本矩阵,该矩阵量化了检测-轨迹对之间的亲和力。频繁的视角变化导致目标外观和位置的显著变化。此外,由复杂的无人机-地面相对运动动力学(如变化的速度和方向)引起的大型且不可预测的目标位移进一步导致不稳定的亲和力测量,最终损害身份分配。
为解决上述问题,主流方法采用两种主要策略来构建成本矩阵。(1)基于运动的位置预测:卡尔曼滤波器[3]、[4]被广泛用作运动模型,根据历史状态预测轨迹的当前位置。然后,基于检测和轨迹之间的位置接近性构建基于运动的成本矩阵。为了克服卡尔曼滤波器在无人机视角下的线性运动预测限制,一些近期工作引入了互补技术,如相机运动补偿(CMC)[5]、[6]和光流[7]、[8],以提高预测轨迹位置的准确性。(2)基于外观的实例级区分:实例级重识别(ReID)嵌入对位置变化不敏感,在相机大幅运动或目标位移的情况下提供了显著优势。几项工作[5]、[6]、[9]、[10]已使用ReID嵌入构建基于外观的成本矩阵,以促进准确的身份分配。然而,这两种策略独立地对运动和外观线索进行建模,以生成单独的成本矩阵,忽略了它们之间的内在关系。具体而言,由突然目标位移引起的运动预测误差会不利地影响基于运动的成本矩阵的构建,而外观模糊性同样会影响基于外观的成本矩阵。因此,当这些成本矩阵产生冲突的关联分数时,确定可靠的匹配决策变得困难。
为解决这些挑战,我们提出了一种外观引导的运动建模策略,通过密集的外观相似性测量跨帧定位目标位置。具体而言,我们通过测量参考帧中查询ReID嵌入与相邻帧中ReID特征图所有空间位置之间的相似性来计算密集响应图。响应图反映了目标在连续帧中的空间位置概率。在此基础上,我们引入了外观-运动一致性(AMC)矩阵,该矩阵使用从轨迹和检测中导出的密集响应图计算相邻帧之间的前向和后向空间距离。通过捕获双向空间对齐,AMC矩阵反映了强大的时空对应关系,从而能够构建更稳健的成本矩阵。此外,传统的身份分配依赖于检测到轨迹的匹配。然而,漏检可能导致活跃轨迹缺乏相应的检测,从而产生未匹配的轨迹。为缓解此问题,我们提出了运动感知轨迹延续(MTC)模块,该模块通过比较外观引导和基于卡尔曼的目标中心预测来重新激活未匹配的轨迹。
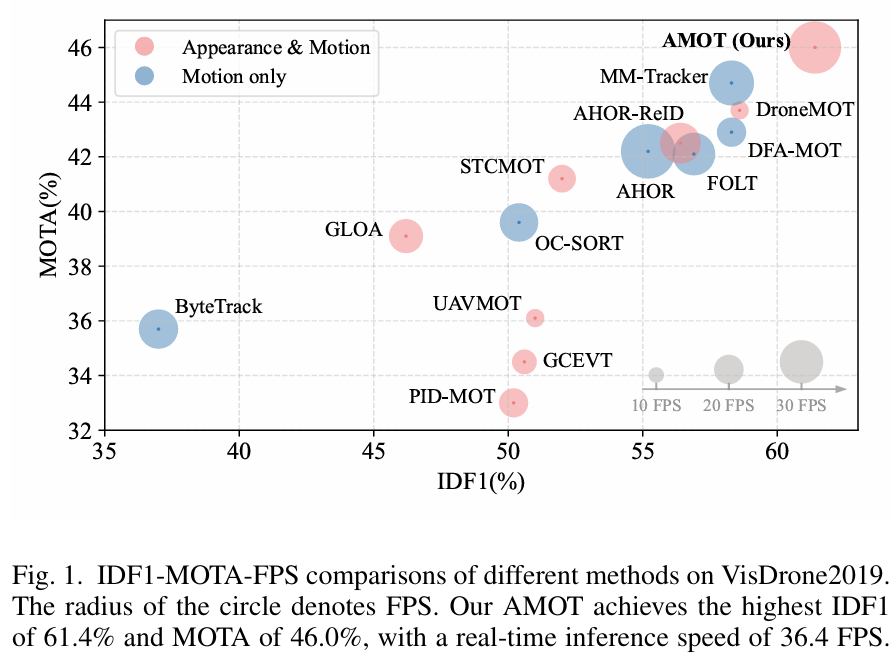
结合AMC和MTC模块,我们提出了一种新颖的多目标跟踪器,称为AMOT,它基于联合检测和嵌入(JDE)架构[11]构建。AMOT特别设计用于增强在具有挑战性的无人机捕获视频下的身份分配的稳健性和准确性。在多个UAV基准测试上的实验表明,AMOT在IDF1和MOTA方面取得了卓越的性能,如图1所示。主要贡献总结如下:
- 我们提出了一种新颖的外观-运动一致性(AMC)矩阵,该矩阵将外观相似性与双向空间距离相结合,为稳健的身份分配提供可靠的亲和力测量。
- 我们设计了运动感知轨迹延续(MTC)模块,通过使外观引导和基于卡尔曼的预测保持一致来恢复未匹配的轨迹,减少在检测失败情况下的碎片化轨迹。
- AMC和MTC模块是即插即用且无需训练的,可以轻松集成到基于JDE的跟踪器中以提升跟踪性能。
- 在VisDrone2019、UAVDT和VT-MOT-UAV基准测试上的广泛评估表明,AMOT始终优于现有跟踪器。例如,AMOT在VisDrone2019上达到了61.4%的IDF1,比MM-Tracker高出2.8%。
2 相关工作
A. 运动建模
MOT中运动建模的目的是预测轨迹的位置。大多数MOT方法[12]-[14]采用卡尔曼滤波器进行运动建模,因其对实时应用具有高计算效率。通过马氏距离[15]或交并比(IoU)[16]将轨迹的预测位置与当前检测进行比较,这些被用作数据关联的基于运动的成本度量。一些工作[4]、[17]通过采用以观测为中心的策略来改进轨迹估计,从而在非线性运动模式下获得更好的性能。尽管它们有效,但基于卡尔曼的方法在涉及大幅相机运动和目标位移的场景中表现出有限的能力。同时,基于学习的运动模型[18]-[20]最近受到关注。这些模型利用数据驱动架构来学习运动模式。然而,此类方法通常计算成本高,不适合实时跟踪。相比之下,我们引入了一种无需训练的运动建模策略,在稳健性和效率之间取得平衡,特别适合无人机捕获的视频。
B. 外观建模
外观建模旨在提取判别性外观特征以重新识别目标。基于检测的跟踪范式[21]、[22]首先使用现成的检测器检测目标,然后使用ReID网络提取每个目标的身份嵌入。尽管该流程提供了令人印象深刻的性能,但由于分离的检测和提取阶段,它存在高计算成本的问题。相比之下,联合检测和嵌入(JDE)范式[23]、[24]将目标检测和ReID特征提取集成到一个统一框架中,实现目标定位和嵌入提取的同时进行。此外,几个基于JDE的跟踪器整合了全局注意力[25]、[26]和时序线索[27]、[28]以增强实例级ReID嵌入的判别能力。上述方法通过计算ReID嵌入之间的余弦距离来测量实例级外观相似性。不同的是,我们将外观相似性测量重新表述为实例嵌入和全局ReID特征图之间的密集响应。这使得视觉相似性和空间一致性能够联合建模。
C. 数据关联
数据关联通常涉及构建一个成本矩阵,该矩阵基于运动和外观信息量化当前检测与现有轨迹之间的亲和力。为提高关联准确性,运动和外观线索通常被分别建模,然后集成到一个统一的成本矩阵中[29]、[30]。一旦成本矩阵构建完成,数据关联被表述为分配问题,并使用匈牙利算法[31]、[32]解决。然而,现有方法通常未能考虑运动和外观线索之间的内在相互作用。这种独立建模可能导致亲和力测量的不稳定性,由预测误差或外观模糊性引起,最终导致冲突的数据关联。为此,我们提出了AMC矩阵,该矩阵在外观、运动和时域中联合强制一致性,实现可靠的身份分配。
3 方法
A. 预备知识
给定输入帧It\mathbf{I}^{t}It,首先将其输入特征提取器以获得特征图Ft∈RH×W×64\mathbf{F}^{t}\in\mathbb{R}^{H\times W\times64}Ft∈RH×W×64。然后,检测分支处理Ft\mathbf{F}^{t}Ft以生成对象中心定位的热图Ht∈RH×W×C\mathbf{H}^{t}\in\mathbb{R}^{H\times W\times C}Ht∈RH×W×C,其中CCC表示对象类别的数量,以及回归图Bt∈RH×W×2\mathbf{B}^{t}\in\mathbb{R}^{H\times W\times2}Bt∈RH×W×2,预测对象的高度和宽度。ReID分支产生ReID特征图Et∈RH×W×D~\mathbf{E}^{t}\in\widetilde{\mathbb{R}^{H\times W\times D}}Et∈RH×W×D,其中D=128D=128D=128是嵌入维度。
我们保留Ht\mathbf{H}^{t}Ht中置信度分数超过阈值τ\tauτ的位置作为对象中心,表述为:
Odet={[xi,yi]∣H(xi,yi)t>τ}i=1N,\mathcal{O}_{d e t}=\{[x_{i},y_{i}]|\mathbf{H}_{(x_{i},y_{i})}^{t}>\tau\}_{i=1}^{N},Odet={[xi,yi]∣H(xi,yi)t>τ}i=1N,
其中Odet\mathcal{O}_{d e t}Odet表示检测的中心坐标集,NNN是检测的总数。对于每个检测,宽度和高度从回归图中获得为[wi,hi]=B(xi,yi)t[w_{i},h_{i}]=\mathbf{B}_{(x_{i},y_{i})}^{t}[wi,hi]=B(xi,yi)t,置信度分数为ci = H(xi,yi)tc_{i}\;=\;\mathbf{H}_{(x_{i},y_{i})}^{t}ci=H(xi,yi)t。同时,每个检测的ReID嵌入ei\mathbf{e}_{i}ei从Et\mathbf{E}^{t}Et中相应中心坐标处提取,表示为ei=E(xi,yi)t∈RD\mathbf{e}_{i}=\mathbf{E}_{(x_{i},y_{i})}^{t}\in\mathbb{R}^{D}ei=E(xi,yi)t∈RD。
检测集定义为D^={di}i=1N\widehat{\mathcal{D}}=\{\mathbf{d}_{i}\}_{i=1}^{N}D={di}i=1N,其中每个检测定义为di=[ci,xi,yi,wi,hi,ei]\mathbf{d}_{i}=[c_{i},x_{i},y_{i},w_{i},h_{i},\mathbf{e}_{i}]di=[ci,xi,yi,wi,hi,ei]。轨迹集可表示为T={tj}j=1M\mathcal{T}=\{\mathbf{t}_{j}\}_{j=1}^{M}T={tj}j=1M,其中MMM是现有轨迹的总数。轨迹的跟踪状态定义为tj=[id,xj,yj,wj,hj,ej]\mathbf{t}_{j}=[i d,x_{j},y_{j},w_{j},h_{j},\mathbf{e}_{j}]tj=[id,xj,yj,wj,hj,ej],其中ididid表示轨迹身份,轨迹的中心坐标集定义为:
Otrk={[xj,yj]}j=1M.\mathcal{O}_{t r k}=\{[x_{j},y_{j}]\}_{j=1}^{M}.Otrk={[xj,yj]}j=1M.
在我们的AMOT中,如图2所示,我们构建了一个外观-运动一致性(AMC)矩阵,以实现稳健的检测到轨迹的关联。此外,我们提出了一个运动感知轨迹延续(MTC)模块,旨在不依赖显式检测到轨迹匹配的情况下重新激活未匹配的轨迹。
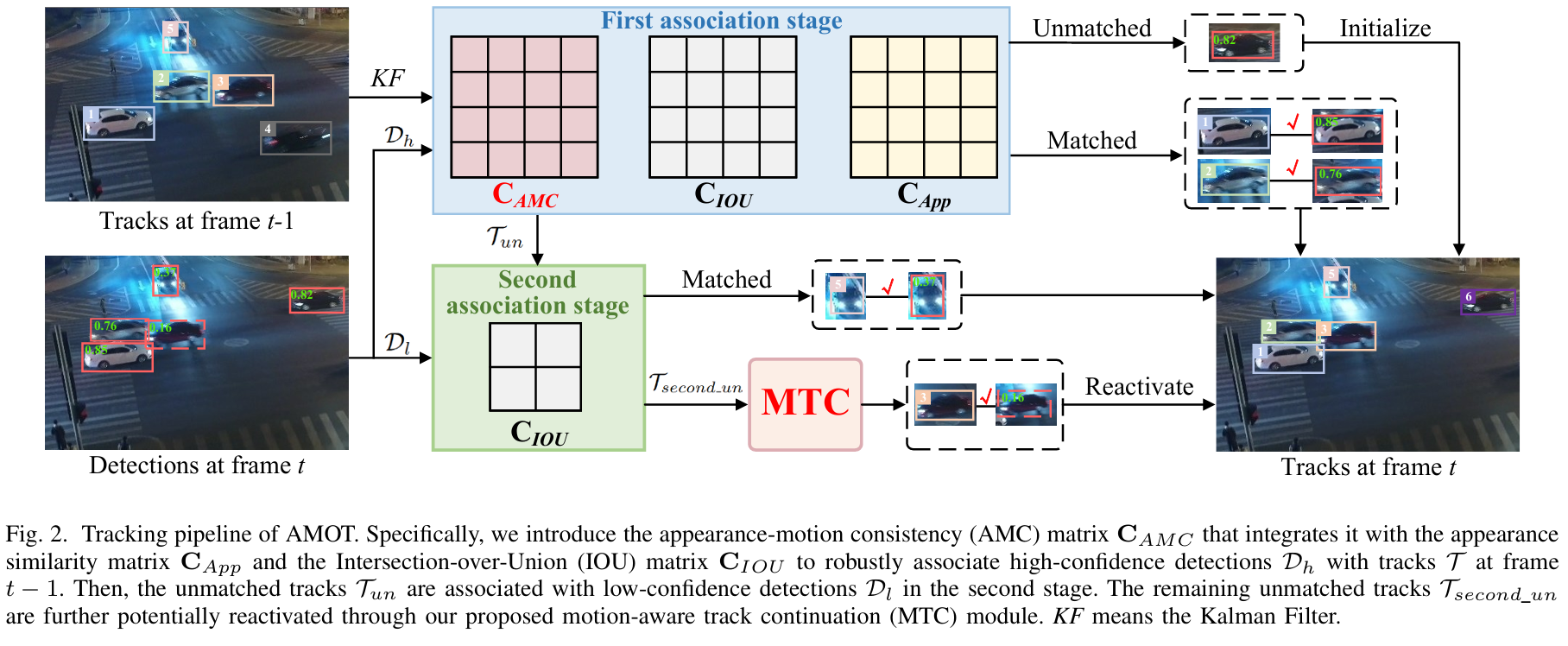
B. 外观-运动一致性矩阵
大多数现有成本矩阵仅使用运动或外观线索独立构建。然而,在具有挑战性的无人机跟踪条件下,这种单独建模方法是不够的,通常导致跟踪失败。为解决此问题,我们提出了AMC矩阵,该矩阵联合建模外观相似性和时空对应关系,以提高关联的稳健性。
具体而言,我们通过评估每个轨迹的ReID嵌入与当前ReID特征图Et\mathbf{E}^{t}Et之间的相似性来计算特定于轨迹的密集响应图Atrk\mathbf{A}_{t r k}Atrk,定义为:
Atrk(j)(x,y)=sim(Et(x,y),ej),\mathbf{A}_{t r k}^{(j)}(x,y)=\operatorname{s i m}(\mathbf{E}^{t}(x,y),\mathbf{e}_{j}),Atrk(j)(x,y)=sim(Et(x,y),ej),
其中ej\mathbf{e}_{j}ej表示第jjj个轨迹的ReID嵌入,sim(⋅)\operatorname{sim}(\cdot)sim(⋅)是余弦相似性函数。响应图Atrk(j)∈RH×W\mathbf{A}_{t r k}^{(j)}\in\mathbb{R}^{H\times W}Atrk(j)∈RH×W突出了与轨迹ReID嵌入最语义相关的区域。然后,AtrkΛ‾\mathbf{A}_{t r k}^{\overline{{\mathbf{\Lambda}}}}AtrkΛ上最大响应对应的空間位置被定义为当前帧中第jjj个轨迹的中心。相应地,当前帧中轨迹的预测中心坐标集Qtrk\mathcal{Q}_{t r k}Qtrk表述为:
Qtrk={[xj∗,yj∗]∣argmax(x,y)∈Ω Atrk(j)(x,y)}j=1M.\mathcal{Q}_{t r k}=\{[x_{j}^{*},y_{j}^{*}]|\underset{(x,y)\in\Omega}{\arg\operatorname*{m a x}}\;\mathbf{A}_{t r k}^{(j)}(x,y)\}_{j=1}^{M}.Qtrk={[xj∗,yj∗]∣(x,y)∈ΩargmaxAtrk(j)(x,y)}j=1M.
类似地,通过评估每个检测的ReID嵌入与前一帧的ReID特征图Et−1\mathbf{E}^{t-1}Et−1之间的相似性来计算特定于检测的密集响应图Adet\mathbf{A}_{d e t}Adet,定义为:
Adet(i)(x,y)=sim(Et−1(x,y),ei),\mathbf{A}_{d e t}^{(i)}(x,y)=\operatorname{s i m}(\mathbf{E}^{t-1}(x,y),\mathbf{e}_{i}),Adet(i)(x,y)=sim(Et−1(x,y),ei),
其中ei\mathbf{e}_{i}ei表示第iii个检测的ReID嵌入。前一帧中检测的预测中心坐标集Qdet\mathcal{Q}_{d e t}Qdet由下式给出:
Qdet={[xi∗,yi∗]∣argmax(x,y)∈Ω Adet(i)(x,y)}i=1N.\mathcal{Q}_{d e t}=\{[x_{i}^{*},y_{i}^{*}]|\underset{(x,y)\in\Omega}{\arg\operatorname*{m a x}}\;\mathbf{A}_{d e t}^{(i)}(x,y)\}_{i=1}^{N}.Qdet={[xi∗,yi∗]∣(x,y)∈ΩargmaxAdet(i)(x,y)}i=1N.
随后,如图3所示,我们通过测量前向和后向空间距离来量化外观引导的时空对应关系,可定义为:
Df(j,i)=∥Qtrk(j)−Odet(i)∥2,\mathbf{D}_{f}(j,i)=\left\|\mathcal{Q}_{t r k}^{(j)}-\mathcal{O}_{d e t}^{(i)}\right\|_{2},Df(j,i)=Qtrk(j)−Odet(i)2,
Db(i,j)=∥Qdet(i)−Otrk(j)∥2.\mathbf{D}_{b}(i,j)=\left\|\mathcal{Q}_{d e t}^{(i)}-\mathcal{O}_{t r k}^{(j)}\right\|_{2}.Db(i,j)=Qdet(i)−Otrk(j)2.
这里,Df(j,i)\mathbf{D}_{f}(j,i)Df(j,i)表示从第jjj个轨迹的预测位置Qtrk(j)\mathcal{Q}_{t r k}^{(j)}Qtrk(j)到第iii个检测的观测中心Odet(i)\mathcal{O}_{d e t}^{(i)}Odet(i)的前向空间距离。相反,Db(i,j)\mathbf{D}_{b}(i,j)Db(i,j)表示从第iii个检测的预测位置Qdet(i)\mathcal{Q}_{d e t}^{(i)}Qdet(i)到第jjj个轨迹的观测中心Otrk(j)\mathcal{O}_{t r k}^{(j)}Otrk(j)的后向空间距离。在这两种情况下,较低的值表示更强的空间一致性。仅当前向和后向距离都较小时,检测-轨迹对才被视为可靠的匹配。
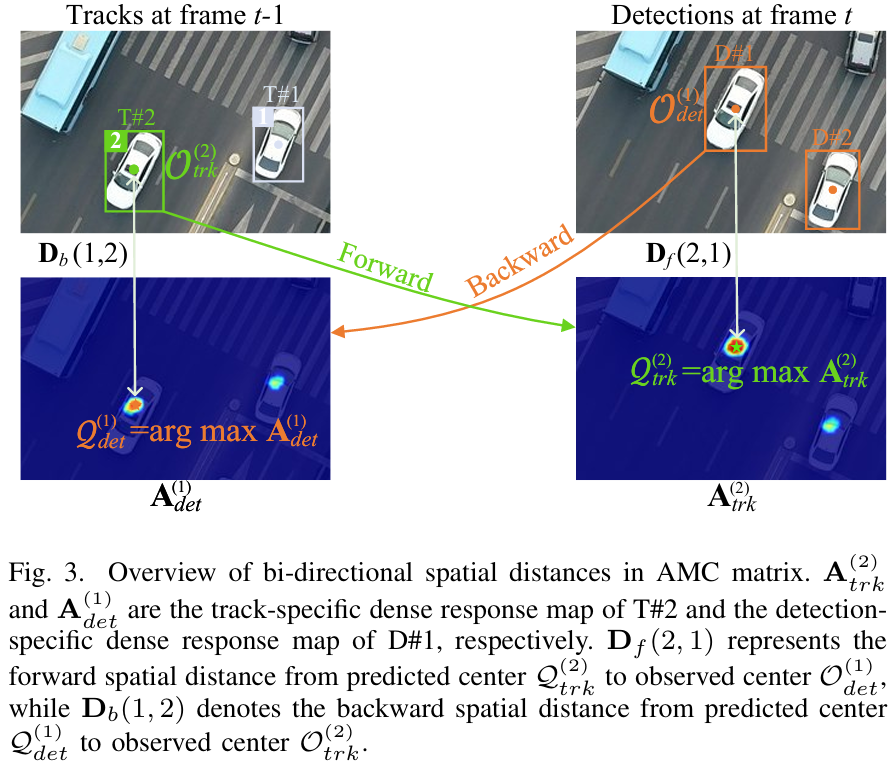
接下来,我们使用高斯核构建AMC矩阵CAMC\mathbf{C}_{A M C}CAMC,该核整合了双向空间距离,定义为:
CAMC(i,j)=1−exp(−Df⊤(i,j)+Db(i,j)2σ2),\mathbf{C}_{A M C}(i,j)=1-\exp\left(-\frac{\mathbf{D}_{f}^{\top}(i,j)+\mathbf{D}_{b}(i,j)}{2\sigma^{2}}\right),CAMC(i,j)=1−exp(−2σ2Df⊤(i,j)+Db(i,j)),
其中σ\sigmaσ是控制空间敏感性的比例因子,设置为5。CAMC\mathbf{C}_{A M C}CAMC本质上编码了联合空间和外观相似性。它旨在对潜在模糊的检测-轨迹对施加平滑惩罚,增强亲和力测量的稳健性。
C. 运动感知轨迹延续
短期丢失轨迹的恢复对于保持轨迹身份至关重要。为此,我们提出了MTC模块,该模块有效传播未匹配的轨迹,以缓解由临时漏检引起的关联失败。
在跟踪开始时,我们为每个轨迹初始化一个缓冲区以存储其帧索引和相应的跟踪状态,表示为Buff={tjs}s=t−20t−1\mathrm{B u f f}=\{\mathbf{t}_{j}^{s}\}_{s=t-20}^{t-1}Buff={tjs}s=t−20t−1,并按照先进先出策略更新。在后续帧中,如果轨迹未能与任何检测关联,同时在其缓冲区中保留最近且时间连续的跟踪状态,我们将其标记为重新激活候选。然后,我们引入MTC模块来确定这些候选是否应被重新激活。具体来说,我们首先使用卡尔曼滤波器预测所有候选的边界框,得到一组基于卡尔曼的预测:Σkf={[x^k,y^k,w^k,h^k]}k=1K\mathbf{\Sigma}_{k f}=\{[\hat{x}_{k},\hat{y}_{k},\hat{w}_{k},\hat{h}_{k}]\}_{k=1}^{K}Σkf={[x^k,y^k,w^k,h^k]}k=1K,其中KKK是候选的总数。相应的预测中心表示为ckf={[x^k,y^k]}k=1K\mathbf{c}_{k f}=\{[\hat{x}_{k},\hat{y}_{k}]\}_{k=1}^{K}ckf={[x^k,y^k]}k=1K。随后,我们计算候选的最新ReID嵌入ekt−1\mathbf{e}_{k}^{t-1}ekt−1与当前ReID特征图Et\mathbf{E}^{t}Et之间的相似性,获得密集响应图:M(k)=sim(Et,ekt−1^)∈RH×W\mathbf{M}^{(k)}=\operatorname{s i m}(\mathbf{E}^{t},\mathbf{e}_{k}^{t-\mathbf{\hat{1}}})\in\mathbb{R}^{H\times W}M(k)=sim(Et,ekt−1^)∈RH×W。M\mathbf{M}M中最大响应的区域不仅表现出与给定ReID嵌入的最高相似性,还作为候选在当前帧中中心坐标的外观引导预测,表示为creid={[x~k,y~k]}k=1K\mathbf{c}_{r e i d}=\{[\tilde{x}_{k},\tilde{y}_{k}]\}_{k=1}^{K}creid={[x~k,y~k]}k=1K。
随后,我们计算每个候选的外观引导预测中心creid\mathbf{c}_{r e i d}creid与基于卡尔曼的预测中心ckf\mathbf{c}_{k f}ckf之间的欧几里得距离。该距离表述为:
dk=∥creid(k)−ckf(k)∥2,d_{k}=\left\|\mathbf{c}_{r e i d}^{(k)}-\mathbf{c}_{k f}^{(k)}\right\|_{2},dk=creid(k)−ckf(k)2,
其中dkd_{k}dk表示第kkk个候选的两个预测中心之间的空间偏移。如果dkd_{k}dk小于预定义阈值λ\lambdaλ(在我们的实验中设置为3),并且与任何当前检测没有显著重叠,则认为候选出现在当前帧中并被重新激活,以确保身份一致性。否则,它保持未匹配状态。
D. 跟踪流程
AMOT的跟踪流程如图2所示。卡尔曼滤波器用于预测轨迹的当前位置。然后,我们采用类似BYTE[3]的两阶段匹配策略,将检测分为高置信度集Dh\mathcal{D}_{h}Dh和低置信度集Dl\mathcal{D}_{l}Dl。
具体而言,在第一阶段,我们在Dh\mathcal{D}_{h}Dh和轨迹T\mathcal{T}T之间构建三个成对成本矩阵,包括外观相似性矩阵CApp\mathbf{C}_{A p p}CApp[11]、交并比(IOU)矩阵CIOU\mathbf{C}_{I O U}CIOU和提出的AMC矩阵CAMC\mathbf{C}_{A M C}CAMC。这些矩阵集成到一个统一的成本矩阵Cuni\mathbf{C}_{u n i}Cuni中,如下所示:
Cuni=1−(1−CAMC⋅CIOU)⋅(1−CApp).\mathbf{C}_{u n i}=1-(1-\mathbf{C}_{A M C}\cdot\mathbf{C}_{I O U})\cdot(1-\mathbf{C}_{A p p}).Cuni=1−(1−CAMC⋅CIOU)⋅(1−CApp).
这里,成本矩阵Cuni\mathbf{C}_{u n i}Cuni用于通过匈牙利算法进行二分匹配。在第二阶段,未匹配的轨迹Tun\mathcal{T}_{u n}Tun仅通过IOU矩阵与Dl\mathcal{D}_{l}Dl关联。对于在此第二次关联后仍保持未匹配状态的轨迹,表示为Tsecond_un\mathcal{T}_{s e c o n d\_u n}Tsecond_un,我们使用提出的MTC模块确定它们是否可以被重新激活为匹配轨迹。
之后,超过30帧保持未匹配的轨迹将被移除。新的轨迹从未与任何现有轨迹关联的剩余高置信度检测中初始化,而匹配轨迹的跟踪状态则基于当前观测进行更新。
4 实验
A. 设置
- 数据集和评估指标:我们在各种来自无人机视角的MOT数据集上评估了我们的方法,包括VisDrone2019[33]、UAVDT[34]和VT-MOT-UAV[35]。
我们采用广泛使用的CLEAR指标[27],包括MOTA、IDF1、大部分跟踪对象(MT)数量和大部分丢失(ML)对象数量,以全面评估跟踪性能。MOTA强调检测质量,基于误报(FP)、漏报(FN)和身份切换(IDs)计算。IDF1测量跟踪器随时间保持一致对象身份的能力,反映跨帧身份关联的准确性。此外,我们报告FPS以评估跟踪器的推理速度。
- 实现细节:我们采用DLA-34[11]作为默认骨干网络,并使用COCO数据集的预训练权重初始化其参数。输入图像调整为608×1088608\times1088608×1088。相应的特征图经历4倍下采样,得到分辨率为152×272152\times272152×272,其中H=152H=152H=152和W=272W=272W=272。我们使用Adam优化器,初始学习率为7e−57e^{-5}7e−5,训练我们的模型30个周期,在第20个周期时将学习率降低10倍。对于目标函数,焦点损失用于监督目标热图,而L1损失用于监督预测的目标宽度和高度。此外,交叉熵损失和三元组损失均用于指导ReID嵌入的学习。为了进一步增强模型对目标实例的感知,我们在训练期间引入了额外的掩码分支[36],使用Dice损失进行训练。
我们的跟踪器使用Python 3.7和PyTorch 1.7.1实现。所有实验均在NVIDIA RTX 3090 GPU和Xeon Platinum 8375C 2.90GHz CPU上评估。
B. 基准评估
我们展示了多个UAV数据集的跟踪结果。↑/↓分别表示越高/越低越好。每个指标的最佳分数以粗体标记,次佳分数以下划线标记。
-
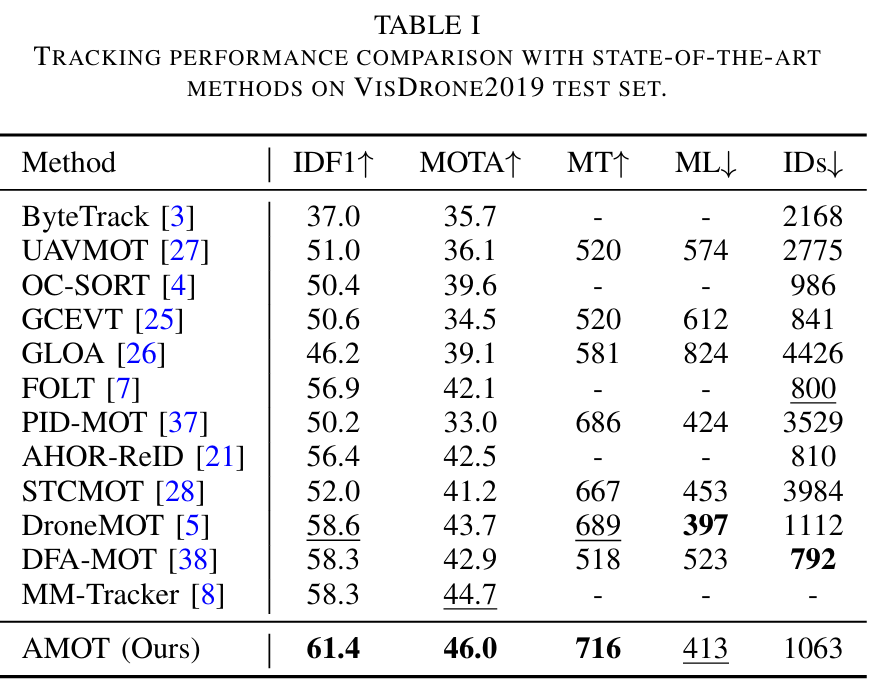
VisDrone2019上的结果:VisDrone2019是动态无人机捕获视频中多目标跟踪的基本基准,涉及尺度变化和长距离目标移动。如表I所示,我们的AMOT表现出最高的IDF1(61.4%)和MOTA(46.0%),优于当前最先进的方法。具体而言,与DroneMOT和MM-Tracker相比,AMOT在IDF1和MOTA方面均实现了绝对提升,展示了更优越的关联准确性和增强的整体跟踪性能。
-
UAVDT上的结果:UAVDT中的跟踪场景源自不同户外场景的鸟瞰图。表II显示,我们的AMOT实现了最佳的跟踪性能,IDF1为74.7%,MOTA为55.1%。具体而言,AMOT在IDF1方面比STCMOT高出+4.9%,在MOTA方面超过MM-Tracker +3.7%,突显了其在跟踪有效性方面的优越性。此外,AMOT具有最高的MT和最低的ML,显示了其在长期跟踪中保持身份的稳健性。
-
VT-MOT-UAV上的结果:VT-MOT-UAV专门用于跟踪多个类别,包括行人和车辆,并提出了诸如变化的照明条件和杂乱背景等挑战。结果总结在表III中。我们的AMOT以52.7%的IDF1和31.8%的MOTA展现出卓越的性能,超过了先前的先进方法。
C. 消融研究
-
基线模型:基线模型使用FairMOT[11]的网络架构结合两阶段关联策略[3]。
-
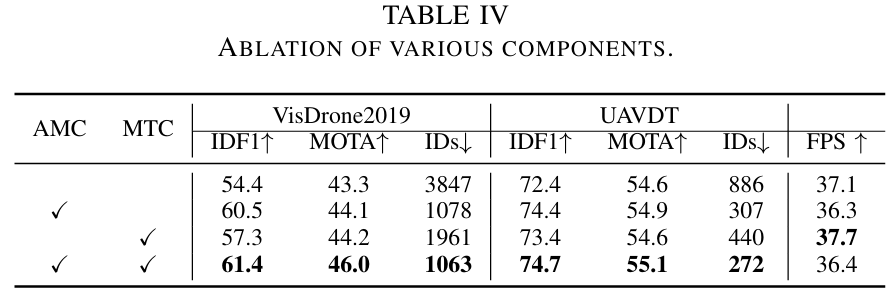
组件消融:我们在表IV中对所提出的组件进行了全面评估。单独将AMC或MTC组件集成到基线模型中都会带来跟踪性能的显著提升。与基线模型相比,AMC和MTC的联合应用使IDF1和MOTA分别提高了+7.0%和+2.7%,同时在VisDrone2019上减少了2784个身份切换。在UAVDT上,它在IDF1上获得了+2.3%的增益,在MOTA上获得了+0.5%的增益,身份切换减少了614个。此外,AMC和MTC仅引入了最小的计算开销,对整体推理速度影响可忽略不计。具体而言,基线模型实现了37.1 FPS的推理速度,而我们的AMOT实现了相当的36.4 FPS速度。这些结果突显了所提出组件的有效性和计算效率。
-
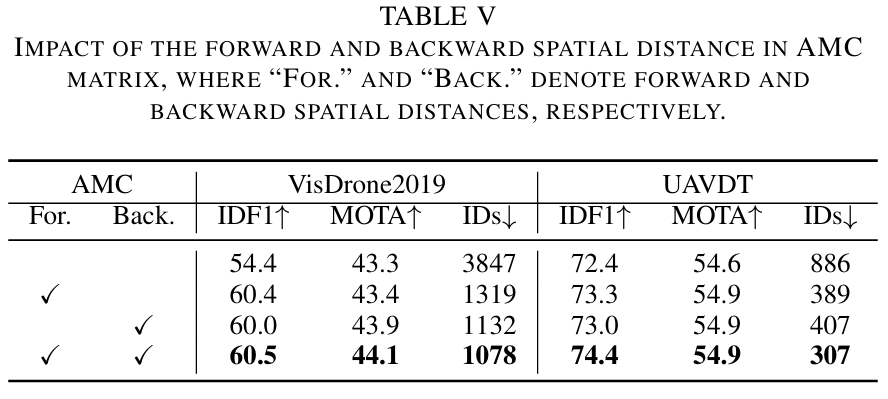
双向空间距离的影响:如表V所示,我们评估了AMC矩阵中前向和后向空间距离的影响。前向和后向空间距离都对整体跟踪性能产生积极贡献,而它们的联合集成进一步带来了增益。这表明建模双向空间一致性加强了运动和外观线索之间的时空相互作用,从而提高了亲和力测量的判别能力。
-
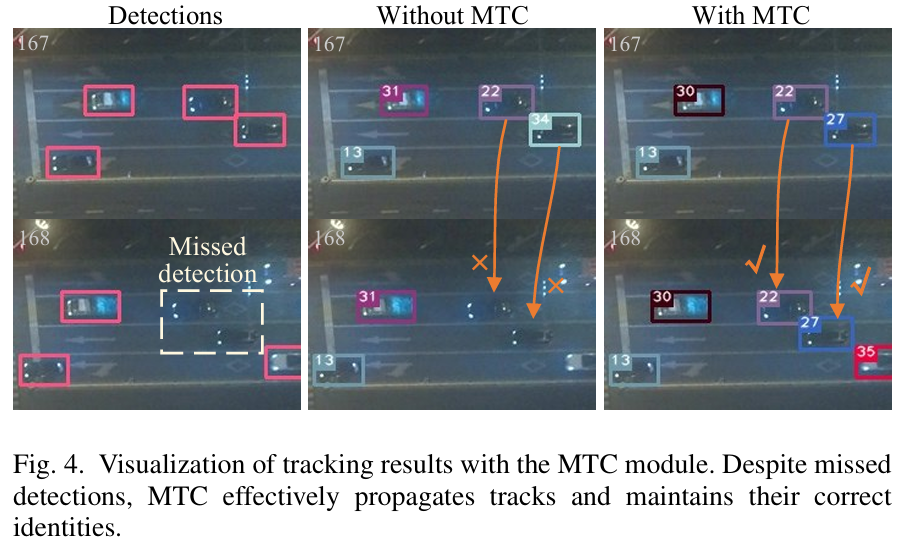
MTC的效果:图4展示了有和没有所提出的MTC模块的跟踪结果的定性比较。在第168帧,基线模型由于漏检而无法关联目标,导致轨迹不连续。相比之下,具有MTC模块的基线模型成功地将轨迹从第167帧传播到第168帧,并保持一致的身份分配,突显了MTC在不可靠检测条件下保持轨迹连续性的有效性。
-
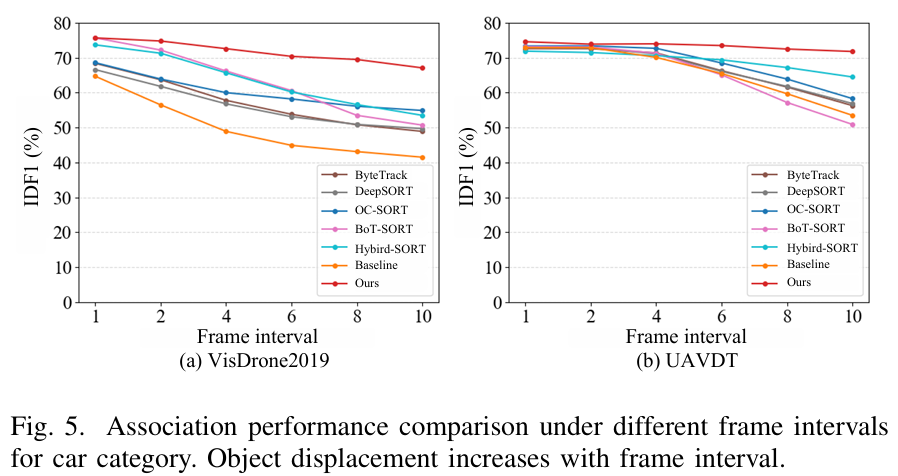
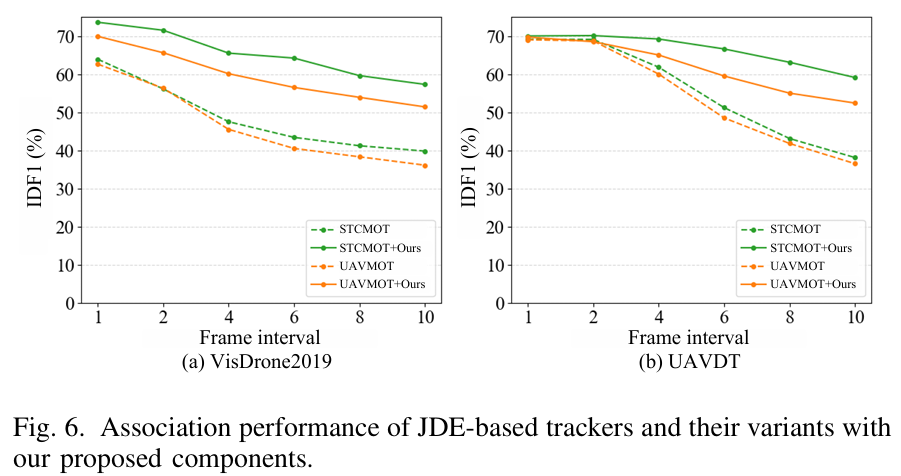
对大位移的稳健性:在图5中,我们使用相同检测在不同帧间隔下将我们的AMOT与几种先进的数据关联方法的关联性能进行了比较。随着帧间隔的增加,帧间目标位移变得更大,导致大多数方法的关联准确性显著下降。相比之下,我们的AMOT在这些挑战性条件下表现出强大的稳健性。尽管最近的竞争性方法如BoT-SORT[40]和Hybrid-SORT[30]利用运动和外观线索进行关联,但它们独立地对这些线索进行建模,这限制了它们处理大目标位移的能力。相反,我们的方法联合且自适应地对运动和外观线索进行建模,从而在高度动态的跟踪场景中实现更一致和准确的数据关联。
-
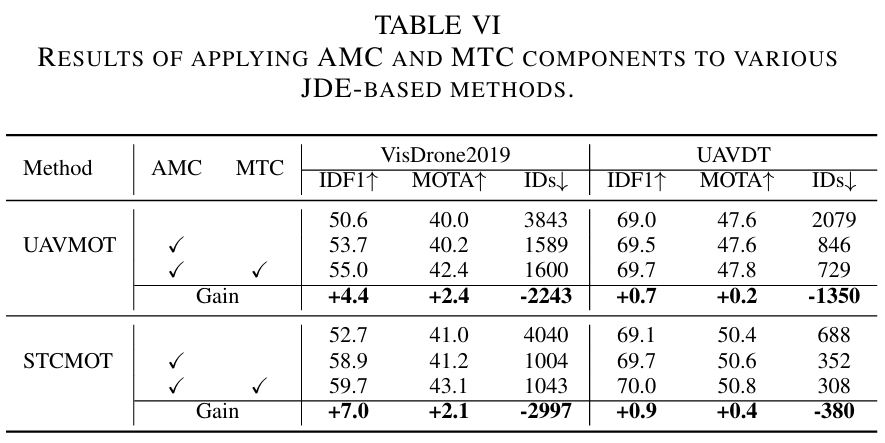
在其他跟踪器上的通用性:我们将我们的设计应用于代表性的基于JDE的跟踪器,包括UAVMOT[27]和STCMOT[28]。如表VI所示,所有这些跟踪器都从AMC和MTC的集成中受益。例如,STCMOT在VisDrone2019上实现了IDF1提高+7.0%和MOTA提高+2.1%的显著增益。UAVMOT也观察到类似的性能改进,IDF1和MOTA分别增加了+4.4%和+2.4%。如图VI所示,集成了所提组件的跟踪器在不同帧间隔下始终优于其原始对应物。这种在多样化跟踪器和场景中的改进进一步证明了我们方法的通用性和有效性。
D. 可视化
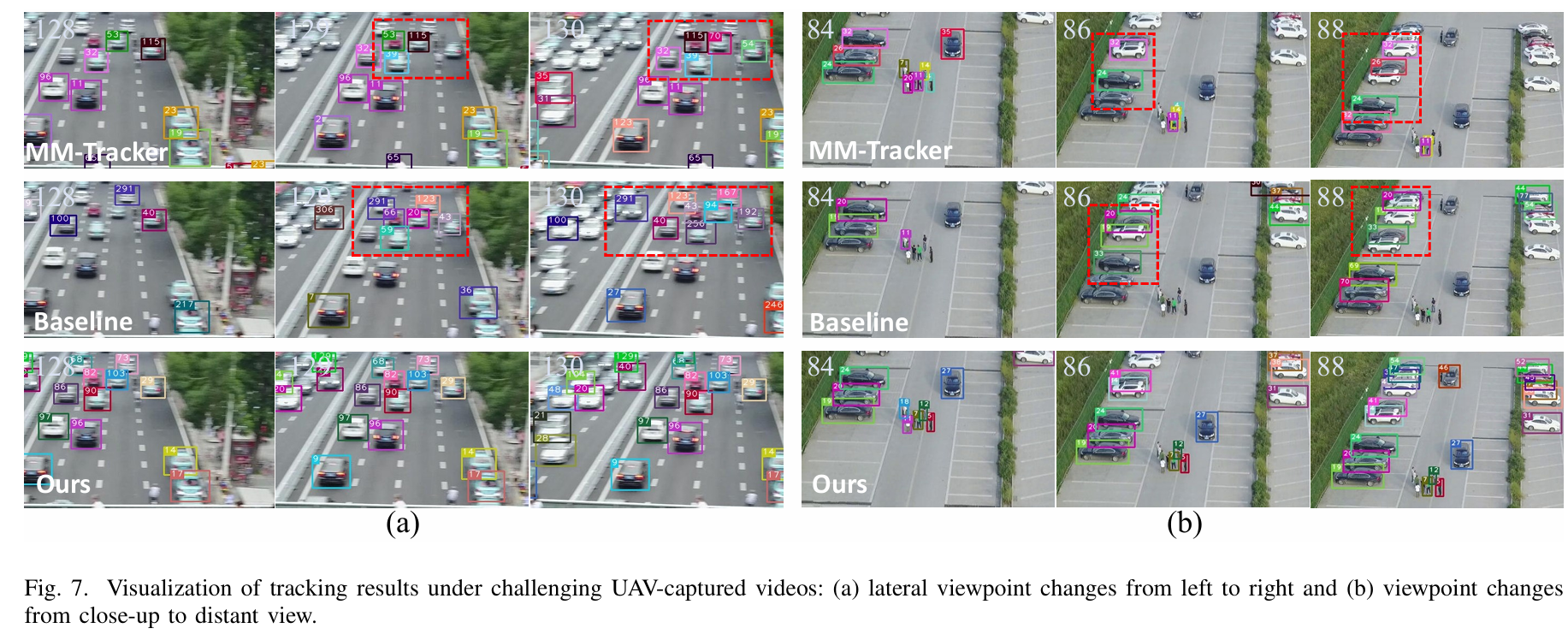
无人机捕获视频中的频繁视角变化通常会导致目标外观和位置的显著变化,给多目标跟踪器带来重大挑战。如图7所示,我们在这些不利条件下评估了我们方法的跟踪性能。基线模型和MM-tracker[8]都遭受频繁的身份切换和跟踪失败,反映了在应对动态视角变化方面的有限能力。相比之下,所提出的AMOT在这些挑战性条件下表现出稳健的性能并保持轨迹身份一致性。
5结论
在本工作中,我们探索了外观和运动线索的联合建模,并引入了两个用于数据关联的即插即用组件,即AMC矩阵和MTC模块。AMC捕获外观、运动和时域一致性以确保准确的身份分配,而MTC通过在漏检后重新激活未匹配的轨迹来缓解轨迹断裂。基于这些组件,我们开发了AMOT,这是一个简单而有效的联合检测和嵌入框架,专为实时无人机跟踪定制。实验表明,AMOT在无人机搭载摄像头捕获的动态场景中表现出强大的稳健性。它还在几个UAV基准测试(包括VisDrone2019、UAVDT和VT-MOT-UAV)上取得了卓越的性能。