使用docker安装vLLM、并安装modelscope本地模型
目录
1. 背景描述
2. 下载vllm镜像文件
3. 下载模型文件
4. 启动vllm工具,加载Qwen3模型
5. 再启动一个向量化的模型
6. 参考资料
1. 背景描述
本文介绍内容有在cpu服务器上使用docker安装vllm、模型下载、启动模型查看效果,适合用来在本地部署大模型进行功能开发。
2. 下载vllm镜像文件
docker pull public.ecr.aws/q9t5s3a7/vllm-cpu-release-repo:v0.9.0.1
3. 下载模型文件
#下载QwQ-32B模型
modelscope download --model 'Qwen3-32B' --local_dir '/home/model/Qwen3-32B'
修改模型权限
chmod -R 755 /home/model/
4. 启动vllm工具,加载Qwen3模型
docker run -it --rm \-p 8080:8000 \-v /home/model/Qwen3-32B:/model \public.ecr.aws/q9t5s3a7/vllm-cpu-release-repo:v0.9.0.1 \--model /model \--device cpu5. 再启动一个向量化的模型
常见的向量化模型如下所示:
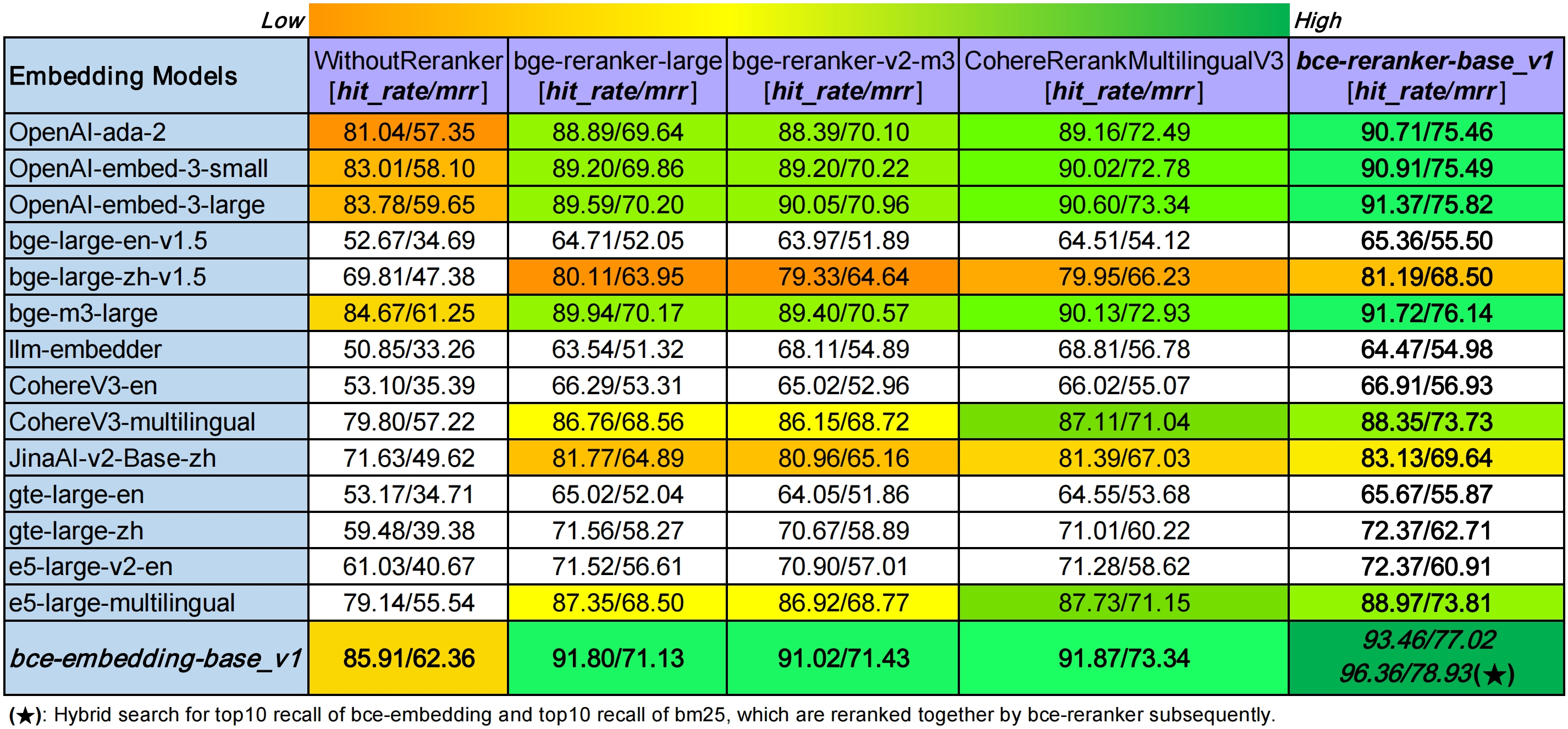
图片来源:https://github.com/netease-youdao/BCEmbedding?tab=readme-ov-file
下载常用的一个rerank模型bge-reranker-v2-m3,来看一下模型运行的效果,首先下载模型文件,执行命令:
modelscope download --model 'BAAI/bge-reranker-v2-m3' --local_dir '/home/root/model/bge-reranker-v2-m3'Downloading [assets/CMTEB-retrieval-bge-zh-v1.5.png]: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 50.3k/50.3k [00:00<00:00, 193kB/s]
Downloading [assets/miracl-bge-m3.png]: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 50.8k/50.8k [00:00<00:00, 194kB/s]
Downloading [assets/llama-index.png]: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 104k/104k [00:00<00:00, 347kB/s]
Downloading [assets/BEIR-bge-en-v1.5.png]: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 55.1k/55.1k [00:00<00:00, 179kB/s]
Downloading [configuration.json]: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 77.0/77.0 [00:00<00:00, 242B/s]
Downloading [assets/BEIR-e5-mistral.png]: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 39.3k/39.3k [00:00<00:00, 111kB/s]
Downloading [config.json]: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 795/795 [00:00<00:00, 1.88kB/s]
Downloading [README.md]: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 16.8k/16.8k [00:00<00:00, 48.1kB/s]
Downloading [tokenizer_config.json]: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.15k/1.15k [00:00<00:00, 3.71kB/s]
Downloading [special_tokens_map.json]: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 964/964 [00:00<00:00, 1.98kB/s]
Downloading [sentencepiece.bpe.model]: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4.83M/4.83M [00:07<00:00, 638kB/s]l
Downloading [tokenizer.json]: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 16.3M/16.3M [00:57<00:00, 299kB/s]
Downloading [model.safetensors]: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2.12G/2.12G [31:55<00:00, 1.19MB/s]
Processing 13 items: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13.0/13.0 [31:55<00:00, 147s/it]
启动vllm工具,加载reranker模型
docker run -it --rm \-p 8080:8000 \-v /home/root/model/bge-reranker-v2-m3:/model \public.ecr.aws/q9t5s3a7/vllm-cpu-release-repo:v0.9.0.1 \--model /model \--device cpu启动成功的日志如下所示:
[W605 06:55:50.923304298 OperatorEntry.cpp:154] Warning: Warning only once for all operators, other operators may also be overridden.Overriding a previously registered kernel for the same operator and the same dispatch keyoperator: aten::_addmm_activation(Tensor self, Tensor mat1, Tensor mat2, *, Scalar beta=1, Scalar alpha=1, bool use_gelu=False) -> Tensorregistered at /pytorch/build/aten/src/ATen/RegisterSchema.cpp:6dispatch key: AutocastCPUprevious kernel: registered at /pytorch/aten/src/ATen/autocast_mode.cpp:327new kernel: registered at /opt/workspace/ipex-cpu-dev/csrc/cpu/autocast/autocast_mode.cpp:112 (function operator())
INFO 03-2 06:55:53 [__init__.py:243] Automatically detected platform cpu.
INFO 03-2 06:55:56 [__init__.py:31] Available plugins for group vllm.general_plugins:
INFO 03-02 06:55:56 [__init__.py:33] - lora_filesystem_resolver -> vllm.plugins.lora_resolvers.filesystem_resolver:register_filesystem_resolver
INFO 03-02 06:55:56 [__init__.py:36] All plugins in this group will be loaded. Set `VLLM_PLUGINS` to control which plugins to load.
INFO 03-02 06:55:56 [config.py:1909] Disabled the custom all-reduce kernel because it is not supported on current platform.
WARNING 03-02 06:55:56 [utils.py:1367] argument 'device' is deprecated
INFO 03-02 06:55:56 [api_server.py:1289] vLLM API server version 0.9.0.1
INFO 03-02 06:55:57 [config.py:1909] Disabled the custom all-reduce kernel because it is not supported on current platform.
INFO 03-02 06:55:57 [cli_args.py:300] non-default args: {'model': '/model', 'device': 'cpu'}
INFO 03-02 06:55:57 [config.py:3131] Downcasting torch.float32 to torch.float16.
INFO 03-02 06:56:04 [config.py:793] This model supports multiple tasks: {'score', 'embed', 'classify', 'reward'}. Defaulting to 'score'.
WARNING 03-02 06:56:04 [_logger.py:72] --task score is not supported by the V1 Engine. Falling back to V0.
INFO 03-02 06:56:04 [config.py:1909] Disabled the custom all-reduce kernel because it is not supported on current platform.
WARNING 03-02 06:56:04 [_logger.py:72] Environment variable VLLM_CPU_KVCACHE_SPACE (GiB) for CPU backend is not set, using 4 by default.
WARNING 03-02 06:56:04 [_logger.py:72] uni is not supported on CPU, fallback to mp distributed executor backend.
INFO 03-02 06:56:04 [api_server.py:257] Started engine process with PID 41
[W605 06:56:08.448293151 OperatorEntry.cpp:154] Warning: Warning only once for all operators, other operators may also be overridden.Overriding a previously registered kernel for the same operator and the same dispatch keyoperator: aten::_addmm_activation(Tensor self, Tensor mat1, Tensor mat2, *, Scalar beta=1, Scalar alpha=1, bool use_gelu=False) -> Tensorregistered at /pytorch/build/aten/src/ATen/RegisterSchema.cpp:6dispatch key: AutocastCPUprevious kernel: registered at /pytorch/aten/src/ATen/autocast_mode.cpp:327new kernel: registered at /opt/workspace/ipex-cpu-dev/csrc/cpu/autocast/autocast_mode.cpp:112 (function operator())
INFO 03-02 06:56:09 [__init__.py:243] Automatically detected platform cpu.
INFO 03-02 06:56:10 [__init__.py:31] Available plugins for group vllm.general_plugins:
INFO 03-02 06:56:10 [__init__.py:33] - lora_filesystem_resolver -> vllm.plugins.lora_resolvers.filesystem_resolver:register_filesystem_resolver
INFO 03-02 06:56:10 [__init__.py:36] All plugins in this group will be loaded. Set `VLLM_PLUGINS` to control which plugins to load.
INFO 03-02 06:56:10 [llm_engine.py:230] Initializing a V0 LLM engine (v0.9.0.1) with config: model='/model', speculative_config=None, tokenizer='/model', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config={}, tokenizer_revision=None, trust_remote_code=False, dtype=torch.float16, max_seq_len=8194, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=1, pipeline_parallel_size=1, disable_custom_all_reduce=True, quantization=None, enforce_eager=True, kv_cache_dtype=auto, device_config=cpu, decoding_config=DecodingConfig(backend='auto', disable_fallback=False, disable_any_whitespace=False, disable_additional_properties=False, reasoning_backend=''), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None), seed=0, served_model_name=/model, num_scheduler_steps=1, multi_step_stream_outputs=True, enable_prefix_caching=None, chunked_prefill_enabled=False, use_async_output_proc=False, pooler_config=PoolerConfig(pooling_type=None, normalize=None, softmax=None, step_tag_id=None, returned_token_ids=None), compilation_config={"compile_sizes": [], "inductor_compile_config": {"enable_auto_functionalized_v2": false}, "cudagraph_capture_sizes": [256, 248, 240, 232, 224, 216, 208, 200, 192, 184, 176, 168, 160, 152, 144, 136, 128, 120, 112, 104, 96, 88, 80, 72, 64, 56, 48, 40, 32, 24, 16, 8, 4, 2, 1], "max_capture_size": 256}, use_cached_outputs=True,
INFO 03-02 06:56:11 [cpu.py:58] Using Torch SDPA backend.
INFO 03-02 06:56:11 [parallel_state.py:1064] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, TP rank 0, EP rank 0
Loading safetensors checkpoint shards: 0% Completed | 0/1 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 4.05it/s]
Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 4.05it/s]INFO 03-02 06:56:12 [default_loader.py:280] Loading weights took 0.30 seconds
INFO 03-02 06:56:12 [api_server.py:1336] Starting vLLM API server on http://0.0.0.0:8000
INFO 03-02 06:56:12 [launcher.py:28] Available routes are:
INFO 03-02 06:56:12 [launcher.py:36] Route: /openapi.json, Methods: HEAD, GET
INFO 03-02 06:56:12 [launcher.py:36] Route: /docs, Methods: HEAD, GET
INFO 03-02 06:56:12 [launcher.py:36] Route: /docs/oauth2-redirect, Methods: HEAD, GET
INFO 03-02 06:56:12 [launcher.py:36] Route: /redoc, Methods: HEAD, GET
INFO 03-02 06:56:12 [launcher.py:36] Route: /health, Methods: GET
INFO 03-02 06:56:12 [launcher.py:36] Route: /load, Methods: GET
INFO 03-02 06:56:12 [launcher.py:36] Route: /ping, Methods: POST
INFO 03-02 06:56:12 [launcher.py:36] Route: /ping, Methods: GET
INFO 03-02 06:56:12 [launcher.py:36] Route: /tokenize, Methods: POST
INFO 03-02 06:56:12 [launcher.py:36] Route: /detokenize, Methods: POST
INFO 03-02 06:56:12 [launcher.py:36] Route: /v1/models, Methods: GET
INFO 03-02 06:56:12 [launcher.py:36] Route: /version, Methods: GET
INFO 03-02 06:56:12 [launcher.py:36] Route: /v1/chat/completions, Methods: POST
INFO 03-02 06:56:12 [launcher.py:36] Route: /v1/completions, Methods: POST
INFO 03-02 06:56:12 [launcher.py:36] Route: /v1/embeddings, Methods: POST
INFO 03-02 06:56:12 [launcher.py:36] Route: /pooling, Methods: POST
INFO 03-02 06:56:12 [launcher.py:36] Route: /classify, Methods: POST
INFO 03-02 06:56:12 [launcher.py:36] Route: /score, Methods: POST
INFO 03-02 06:56:12 [launcher.py:36] Route: /v1/score, Methods: POST
INFO 03-02 06:56:12 [launcher.py:36] Route: /v1/audio/transcriptions, Methods: POST
INFO 03-02 06:56:12 [launcher.py:36] Route: /rerank, Methods: POST
INFO 03-02 06:56:12 [launcher.py:36] Route: /v1/rerank, Methods: POST
INFO 03-02 06:56:12 [launcher.py:36] Route: /v2/rerank, Methods: POST
INFO 03-02 06:56:12 [launcher.py:36] Route: /invocations, Methods: POST
INFO 03-02 06:56:12 [launcher.py:36] Route: /metrics, Methods: GET
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
执行命令验证
curl -X POST http://localhost:8080/rerank \-H "Content-Type: application/json" \-d '{"query": "What is Docker?","documents": ["Docker is a containerization platform.","Docker uses containers to package software."]}'返回结果
{"id": "rerank-a72dfa2d9a174923b3f739221f39b945","model": "/model","usage": {"total_tokens": 36},"results": [{"index": 0,"document": {"text": "Docker is a containerization platform."},"relevance_score": 0.99951171875},{"index": 1,"document": {"text": "Docker uses containers to package software."},"relevance_score": 0.8505859375}]
}6. 参考资料
# 完整示例
sudo docker run -d \--name my-vllm \ # 容器名称--gpus all \ # 使用所有GPU,--gpus '"device=0,1"' --shm-size 2g \ # 共享内存2GB-p 8000:8000 \ # 端口映射-v ~/llm_models:/models \ # 模型目录挂载vllm/vllm-openai:latest \--model /models/Qwen/Qwen2-7B \ # 具体模型路径--served-model-name qwen-7b \ # 对外暴露的模型名--host 0.0.0.0 \ # 监听所有网络接口--port 8000 \ # 服务端口--tensor-parallel-size 2 \ # 2GPU并行--max-model-len 4096 \ # 最大序列长度--gpu-memory-utilization 0.8 \ # GPU显存利用率80%--trust-remote-code # 信任自定义代码
CPU | vLLM 中文站
ECR Public Gallery
https://zhuanlan.zhihu.com/p/1892657100318045796
modelscope安装并下载模型文件-CSDN博客
Docker部署vLLM部署流程_docker vllm 部署-CSDN博客
docker + vllm 快速部署通义千问3(Qwen3), 并通过代码控制有无思维链_docker-vllm运行qwen3-CSDN博客