小样本机器学习再发力!2025再登Nature正刊
航识无涯学术致力于成为您在人工智能领域的领航者,定期更新人工智能领域的重大新闻与最新动态,和您一起探索AI的无限可能。
2025深度学习发论文&模型涨点之——小样本机器学习
近年来,小样本学习(Few-Shot Learning)作为机器学习领域的重要分支,致力于解决传统深度学习模型对大规模标注数据的依赖问题。其核心目标是通过极少量样本(如单样本或少量样本)实现对新任务的快速泛化,这一能力在医疗诊断、工业检测、低资源语言处理等实际场景中具有显著价值。
我整理了一些【论文+代码】合集,需要的同学公人人人号【航识无涯学术】发123自取。
论文精选
论文1:
Accurate predictions on small data with a tabular foundation model
在小数据上进行准确预测的表格基础模型
方法
Tabular Prior-data Fitted Network (TabPFN):提出了一种表格基础模型,通过在数百万个合成数据集上进行训练,能够快速适应小规模表格数据集。
In-context Learning (ICL):利用上下文学习机制,使模型能够直接在新数据集上进行训练和预测,无需针对每个数据集进行单独训练。
Transformer架构:采用基于Transformer的架构,能够处理表格数据中的行和列结构,提高了模型对表格数据的处理能力。
数据生成和预训练:通过生成大量合成数据集,并在这些数据集上预训练模型,使模型能够学习到广泛的数据特征和关系。
创新点
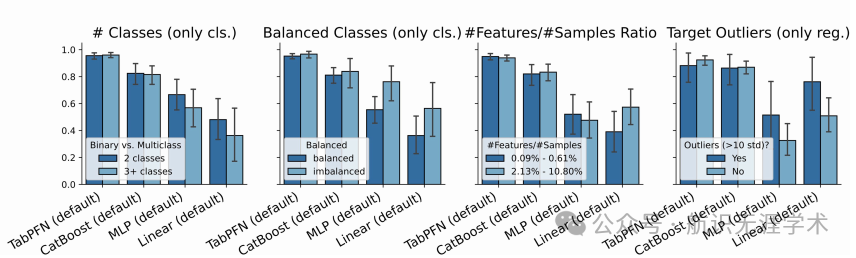
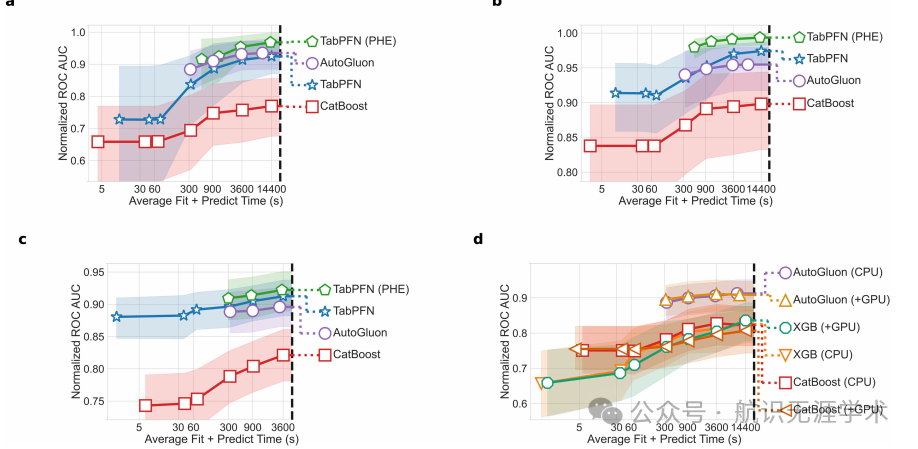
性能提升:TabPFN在小数据集(最多10,000个样本和500个特征)上显著优于所有先前的方法,平均性能提升超过0.187(ROC AUC)和0.051(RMSE)。
训练时间:TabPFN的训练时间大幅缩短,平均仅需2.8秒,相比传统方法(如CatBoost)在4小时的调优时间下,速度提升超过5,140倍。
泛化能力:TabPFN不仅在分类任务中表现出色,在回归任务中也展现出强大的性能,平均性能提升超过0.093(RMSE)。
数据适应性:通过合成数据预训练,TabPFN能够更好地适应各种表格数据集,包括具有缺失值、不平衡数据和不同特征类型的数据集。
论文2:
Enhancing efficiency of protein language models with minimal wet-lab data through few-shot learning
通过少样本学习用最少的湿实验数据提高蛋白质语言模型的效率
方法
Few-Shot Learning for Protein Fitness Prediction (FSFP):提出了一种少样本学习策略,结合元迁移学习、学习排序和参数高效微调,优化蛋白质语言模型在极端数据稀缺情况下的性能。
元迁移学习(Meta-Transfer Learning, MTL):通过在多个相关任务上进行训练,使模型能够快速适应新任务,即使只有少量训练数据。
学习排序(Learning to Rank, LTR):将蛋白质适应性预测问题转化为排名问题,通过计算排名损失来优化模型。
参数高效微调(Parameter-Efficient Fine-Tuning, LoRA):通过注入可训练的低秩分解矩阵来限制模型更新,防止过拟合。
创新点
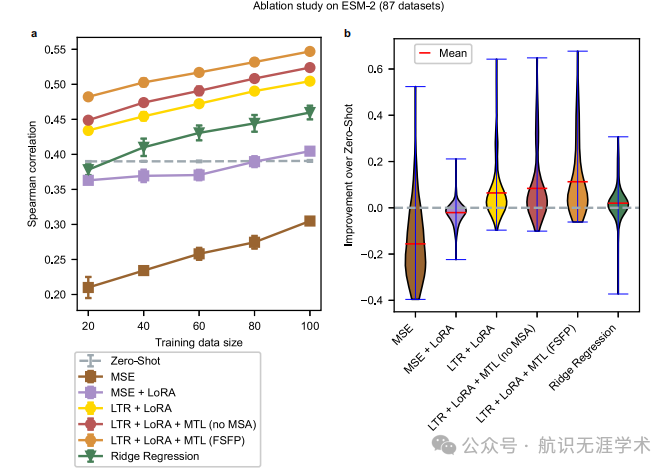
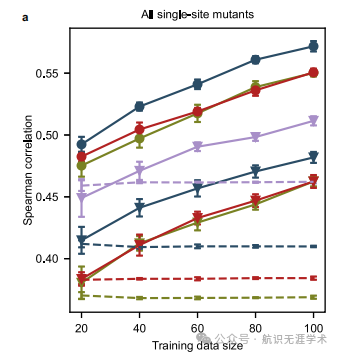
性能提升:FSFP在仅使用20个标记的单点突变的情况下,平均Spearman相关性提升0.1,显著优于无监督和监督基线。
数据效率:FSFP能够在仅有少量标记数据的情况下,显著提高蛋白质语言模型的性能,减少了对大规模湿实验数据的依赖。
泛化能力:FSFP在不同蛋白质语言模型(如ESM-1v、ESM-2和SaProt)上均表现出色,具有良好的泛化能力。
实验验证:通过湿实验验证,FSFP成功提高了Phi29 DNA聚合酶的热稳定性,平均Tm值提高了超过1°C,阳性率提高了25%。
论文3:
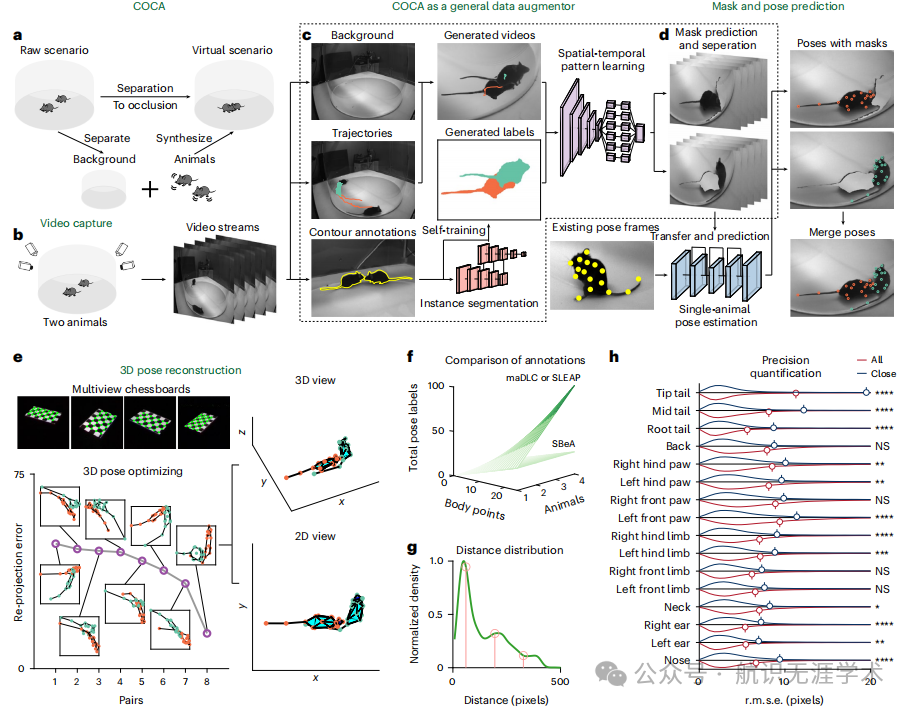
Multi-animal 3D social pose estimation, identification and behaviour embedding with a few-shot learning framework
多动物3D社交姿态估计、识别和行为嵌入的少样本学习框架
方法
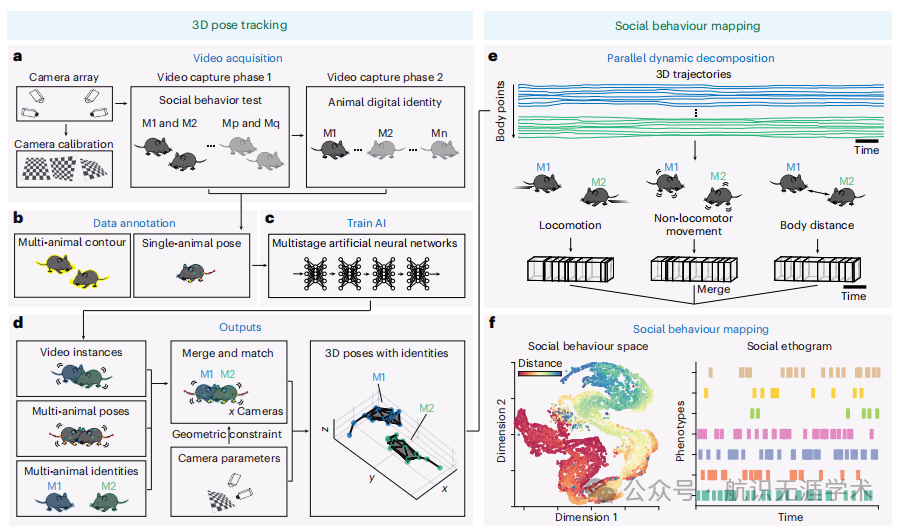
Social Behavior Atlas (SBeA):提出了一种少样本学习框架,用于多动物3D姿态估计、身份识别和社交行为分类。
连续遮挡复制粘贴算法(COCA):通过生成虚拟场景,增加训练数据集的规模,无需大量手动标注。
双向迁移学习:利用多动物分割和单动物识别之间的知识共享,实现零样本标注的多动物身份识别。
行为映射:通过动态行为度量,将动物轨迹分解为不同的行为模块,并将其嵌入低维空间。
创新点
性能提升:SBeA在多动物姿态估计和身份识别任务中,使用较少的手动标注数据(约400帧)即可达到高精度,与传统方法相比,平均误差降低了约2像素。
数据效率:通过COCA算法,SBeA能够在少量标注数据的情况下,生成大量虚拟场景,显著提高了数据利用效率。
泛化能力:SBeA不仅适用于小鼠,还成功应用于鹦鹉和比利时马里努阿犬,展示了其在不同物种和环境中的泛化能力。
行为分析:SBeA能够揭示之前未被发现的社交行为表型,如自闭症模型小鼠的异常社交行为,为神经科学和生态学研究提供了有力工具。